用于确定估计的传感器数据的系统、方法和计算机程序与流程
1.示例涉及一种用于使用时间序列投影来确定估计的传感器数据的系统、方法和计算机程序。
背景技术:
2.现代交通工具包括多个分布式和嵌入式系统。例如,气候控制单元和马达单元是单独的嵌入式系统。这些系统中的每个系统都可以包括一个或多个传感器和电子控制单元(ecu)。ecu通常经由总线系统连接和交换信息。总线通信可能需要时间,因此,一旦许多测量到达ecu,所述测量就被延迟。
技术实现要素:
3.可能存在对于处理局部延迟的传感器测量的改进的构思的期望。
4.这种期望通过独立权利要求的主题来解决。
5.本公开的实施例基于以下发现:在交通工具中,由各种传感器产生的传感器数据经常是不同步的,例如,由于在交通工具的总线系统上传输相应的传感器数据而引入的延迟所导致,或者由于对传感器数据进行编码和解码以用于总线的传输而引入的延迟所导致。在这样的系统中出现的延迟经常是确定性的,即,所述延迟具有固定的值。实施例使用时间序列投影来将传感器数据的趋势投影到未来,以用于填补由于上述延迟而引入的缺口。本公开的实施例因此可以使用时间序列预测来补偿在信号传输中的时间延迟。
6.本公开的实施例提供一种用于确定传感器的估计的传感器数据的系统。所述系统包括处理电路,所述处理电路配置为用于获取传感器的传感器数据的多个采样。所述处理电路配置为用于,获取关于在传感器的传感器数据与参考时间之间的时间偏移的信息。所述处理电路配置为用于,基于传感器数据的所述多个采样来执行时间序列投影。使用自回归统计模型来执行时间序列投影。所述处理电路配置为用于,基于时间序列投影并且基于在传感器数据与参考时间之间的时间偏移来确定针对参考时间的对传感器数据的估计。因此,时间序列投影可以用于填补在传感器的传感器数据与参考时间之间的时间偏移。
7.存在各种类型的自回归统计模型。自回归统计模型的一个子集基于“移动平均”的概念。换句话说,自回归统计模型可以是自回归移动平均模型。在移动平均模型中,输出值线性地取决于随机项的当前值和一个或多个过去值。具体地说,回归误差可以是当前的错误项和先前的错误项的线性组合。
8.在一些实施例中,所述自回归模型应用于传感器数据的所述多个采样的微分。使用所述微分,可以使传感器数据静止,所以其不取决于传感器数据被观察的时间。例如,所述自回归模型应用于传感器数据的所述多个采样的一次求导(once-derived)的版本上,所述一次求导的版本证实为适合于通过所提出的方法处理的传感器数据类型。
9.例如,所述自回归模型可以是以下模型中的一个模型:自回归整合移动平均(arima)模型或自回归移动平均(arma)模型。特别是,arima模型已经证实为提供在预测准
确度与计算工作量之间良好的折中。
10.例如,可以使用所述传感器的传感器数据的至少20个采样和/或至多60个采样来执行时间序列投影。较少数量的采样可以产生较低的计算复杂度,而较多数量的采样可以产生提高的准确度。在对所提出的方法的评价中,发现40个采样的数量产生高的预测准确度。
11.例如,所述传感器的传感器数据可以与电动交通工具的动力传动系的电流有关。在电动交通工具(ev)中,动力传动系的传感器数据可以被实时地处理以改进电池管理和管理动力传动系的功耗。
12.在各种实施例中,处理电路配置为用于执行所述时间序列投影,使得通过所述时间序列投影来填补在传感器数据与参考时间之间的时间偏移。所述处理电路可以配置为用于输出对传感器数据的估计。因此,时间偏移可以被补偿,并且另一个ecu可以使用针对参考时间估计的传感器数据。
13.例如,所述处理电路可以配置为用于以如下投影范围来执行时间序列投影,所述投影范围匹配于在传感器数据与参考时间之间的时间偏移。换句话说,时间序列投影可以旨在将传感器数据投影到参考时间。
14.一般来说,可以估计传感器数据以允许传感器数据与第二传感器的传感器数据的同步,例如以便消除在这两组传感器数据之间的时间偏移。例如,参考时间可以基于第二传感器的传感器数据。第二传感器的传感器数据可以包括多个第二采样。处理电路可以配置为用于确定对传感器数据的估计,使得对传感器数据的所述估计与第二传感器的传感器数据的最新的采样在时间上同步。因此,在这两组传感器数据之间的时间偏移可以被消除。
15.例如,所述处理电路可以配置为用于获取所述第二传感器的传感器数据。所述处理电路可以配置为用于,基于所述第二传感器的传感器数据并且基于所述传感器的传感器数据来获取在所述传感器的传感器数据与参考时间之间的时间偏移。换句话说,所述处理电路可以确定时间偏移并且针对所确定的时间偏移进行补偿。备选地,时间偏移可以是预先定义的或者由另一个系统确定。
16.在各种实施例中,处理电路配置为用于输出所述传感器的所估计的传感器数据的和所述第二传感器的传感器数据的在时间上同步的版本。因此,可以便利于对这两组传感器数据的后续处理。
17.本公开的实施例进一步提供一种相应的用于确定估计的传感器数据的方法。所述方法包括获取传感器的传感器数据的多个采样。所述方法包括获取关于在传感器的传感器数据与参考时间之间的时间偏移的信息。所述方法包括基于传感器数据的所述多个采样来执行时间序列投影。使用自回归统计模型来执行时间序列投影。所述方法包括,基于所述时间序列投影并且基于在传感器数据与参考时间之间的时间偏移来确定针对参考时间的对传感器数据的估计。
18.本公开的实施例进一步提供一种相应的计算机程序,所述计算机程序具有程序代码,所述程序代码用于当所述计算机程序在计算机、处理器或可编程硬件组件上运行时执行以上方法。
附图说明
19.下面将仅作为示例、参照附图来描述设备和/或方法的一些示例,图中:
20.图1a示出用于确定估计的传感器数据的系统的实施例的框图;
21.图1b示出包括用于确定估计的传感器数据的系统的交通工具的实施例的框图;
22.图1c示出用于确定估计的传感器数据的方法的流程图;
23.图2a和图2b示出与传感器数据的可用性相关的曲线图;
24.图3示出嵌套交叉验证流程的按时间顺序的表示;以及
25.图4a和图4b示出所评价的算法获得的预测和运行时间性能得分概览的表格。
具体实施方式
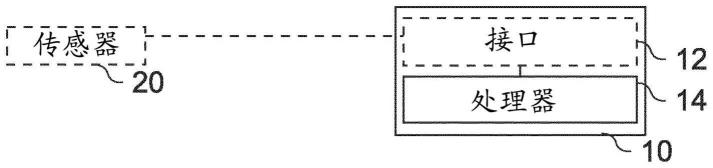
26.现在将参照附图来更充分地描述各种示例,在附图中示出了一些示例。在附图中,为了清楚起见,可能放大线条、层和/或区域的厚度。
27.因此,虽然另一些实施例能够具有各种修改和替代形式,但是它们中的一些特定示例在附图中示出,并且随后将详细描述。然而,该详细描述不会将另一些示例限制为所描述的特定形式。另一些实施例可以涵盖落入本公开范围内的所有修改方案、等同方案和替代方案。在整个附图描述中,相同或类似的附图标记表示相同或类似的元件,这些元件当彼此比较时可以相同地实现或以修改的形式实现,但提供相同或类似的功能。
28.应当理解,当提到一个元件“连接”或“联接”到另一个元件时,这些元件可以直接连接或通过一个或多个中间元件联接。除非明确地或隐含地另外限定,如果两个元件a和b使用“或”组合,则这应理解为公开了所有可能的组合,即仅a、仅b以及a和b。相同组合的另一种表述为“a和b中的至少一个”或“a和/或b”。经过必要的变通,这同样适用于两个以上元件的组合。
29.本文用于描述特定示例的术语并不旨在用于限制另一些实施例。每当使用诸如“一个”和“所述”等单数形式并且仅使用单个元件既不明确地又不隐含地限定为强制性的,另一些实施例也可以使用多个元件来实现相同的功能。同样地,当随后将功能描述为使用多个元件实现时,另一些示例可以通过使用单个元件或处理实体实现相同的功能。还应理解的是,术语“包括”和/或“具有”在使用时规定存在所阐述的特征、整数、步骤、操作、过程、动作、元件和/或部件,但不排除存在或添加一个或多个其他的特征、整数、步骤、操作、过程、动作、元件、组件和/或它们的任何组合。
30.除非另有限定,否则本文使用的所有术语(包括技术术语和科学术语)具有其在示例所属技术领域中的普通含义。
31.图1a示出用于确定传感器20的估计的传感器数据的系统10的实施例的框图。系统10包括处理电路14。可选地,所述系统还包括耦联到处理电路14的接口12。一般来说,所述系统的功能性由处理电路14、例如与接口12结合地提供。例如,处理电路配置为用于获取传感器20的传感器数据的多个采样。处理电路配置为用于获取关于在传感器的传感器数据与参考时间之间的时间偏移的信息。处理电路配置为用于基于传感器数据的所述多个采样来执行时间序列投影。使用自回归统计模型来执行时间序列投影。处理电路配置为用于,基于时间序列投影并且基于在传感器数据与参考时间之间的时间偏移来确定用于参考时间的(即,参照参考时间或被投影到参考时间的)对传感器数据的估计。
32.例如,系统10可以用于处理交通工具的传感器20的传感器数据。因此,图1b示出交通工具100的实施例的框图,所述交通工具包括系统10和传感器20。可选地,交通工具可以进一步包括第二传感器30和/或电子控制单元40。系统10、传感器20和可选的第二传感器30和/或可选的电子控制单元40可以经由交通工具的通信系统(例如,总线系统)(例如,经由以太网、经由控制器区域网络总线(can总线)或本地互连网络(lin))进行通信。例如,交通工具100可以是陆地交通工具、公路交通工具、轿车、汽车、越野交通工具、机动车、卡车或货运汽车。一般来说,交通工具可以不限于公路。例如,交通工具可以是火车、轮船或飞机。虽然实施例是以交通工具设想的,但实施例也可以应用于其他领域、例如工业机械。实施例因此提供工业机械、例如包括系统10的发电厂或制造厂。
33.图1c示出相应的用于确定估计的传感器数据的方法的流程图。所述方法包括:获取110传感器的传感器数据的多个采样。所述方法包括:获取120关于在传感器的传感器数据与参考时间之间的时间偏移的信息。所述方法包括:基于传感器数据的所述多个采样来执行130时间序列投影。使用自回归统计模型来执行时间序列投影。所述方法包括:基于时间序列投影并且基于在传感器数据与参考时间之间的时间偏移来确定140针对参考时间的对传感器数据的估计。
34.以下描述既涉及图1a和/或图1b的系统又涉及图1c的方法。结合图1a和/或图1b的系统描述的特征也可以应用于图1c的方法。
35.本公开的实施例涉及一种用于确定估计的传感器数据的系统、方法和计算机程序。如前面已经阐述的,所述系统、方法和计算机程序可以用于在传感器数据落后于参考时间(例如,由传感器所执行的信号处理而导致,或者由传感器数据在系统内、例如在交通工具100内的传输而引入的延迟导致)的情况下确定估计的传感器数据。
36.处理电路配置为用于,获取传感器20的传感器数据的多个采样。一般来说,传感器的传感器数据的所述多个采样可以是由传感器20生成的采样。所述多个采样在时间上可以是等距的,即,在采样之间有预定的时间间隔。例如,所述多个采样的定时可以基于传感器20的预定的采样速率,或者基于传感器20的预定的采样输出速率。在各种实施例中,在传感器(在下面也可以表示为第一传感器)的传感器数据的多个采样之间的时间间距可以与如结合图1b介绍的第二传感器30的传感器数据的多个采样之间的时间间距相同。
37.存在可以应用所提出的方案的各种类型的传感器数据。例如,传感器数据可以是交通工具传感器(即,交通工具中采用的传感器)的传感器数据。例如,交通工具可以是电动交通工具(ev),传感器数据可以是与所述电动交通工具的电的动力传动系相关的传感器的传感器数据。例如,(第一)传感器的传感器数据可以与电动交通工具100的动力传动系的电流相关,例如,与电动交通工具的电池系统输出的电流相关,或者与电动交通工具100的一个或多个电机使用的电流相关。备选地,传感器可以是其它类型的分布式系统(例如,机械、如工业设施、机器人或飞机)的传感器。一般来说,分布式系统(例如,交通工具、机械、工业设施、机器人、飞机等)可以包括所述系统和传感器(以及可选地包括第二传感器)。
38.处理电路配置为用于,获取关于在传感器的传感器数据与参考时间之间的时间偏移的信息。一般来说,关于在传感器的传感器数据与参考时间之间的时间偏移的信息可以指示传感器数据的采样落后于参考时间多远。例如,如果当前时间是参考时间,则(第一传感器的)传感器数据的多个采样中的一个采样可以在时间t(例如,参考时间)(由处理电路)
时获取,但是与在时间t-to时发生的测量相关,其中to是时间偏移。如果参考时间不是当前时间,但是所述参考时间例如由第二传感器的采样限定,则可以采用类似的逻辑。在这种情况下,参考时间t可以由在第二传感器处发生的测量限定,或者所述参考时间可以限定成第二传感器的采样被处理电路接收到的时间。在任何情况下,关于在传感器的传感器数据与参考时间之间的时间偏移的信息可以限定在参考时间与(第一)传感器的传感器数据的采样被处理电路获取的时间之间的滞后或延迟,所述采样相对于参考时间在预定的时间(例如,在参考时间)时被测量。一般来说,关于在传感器的传感器数据与参考时间之间的时间偏移的信息可以从(已经确定时间偏移的)另一个系统接收,从所述系统的存储器读出(如果时间偏移至少暂时是恒定的话),或者由处理电路确定、如将参照第二传感器介绍的那样。
39.处理电路配置为用于,基于传感器数据的多个采样来执行时间序列投影(也被称为时间序列预测)。一般来说,时间序列投影基于一个或多个数值的历史数据来预测所述一个或多个数值在时间间隔(包括多个时间点)上的发展。换句话说,所述一个或多个数值的趋势可以基于所述数值的历史数据来预测,并且可以预测所述数值的发展的发展的时间序列。在实施例中,(第一)传感器的传感器数据的采样可以被看作时间序列,所述采样中的每个采样都以一个或多个数值表示。时间序列投影可以应用于将时间序列(相对于时间序列)扩展到未来,即,使时间序列朝向参考时间扩展。换句话说,时间序列投影可以用于将传感器数据的发展朝向参考时间投影,从而闭合(或者至少缩小)在传感器数据的最新的采样与参考时间之间的缺口。
40.可以使用自回归统计模型来执行时间序列投影。一般来说,存在用于执行时间序列投影的各种方法。一些方法、如指数平滑,将接收的数值输入到预定的公式中以获取估计的传感器数据。备选地,更进布的手段,诸如机器学习和/或自回归马尔可夫(markov)模型,可以用于执行时间序列投影。在实施例中,可以使用折中——比指数平滑更复杂、但不如训练机器学习模型复杂的自回归统计模型。换句话说,指数平滑可能不被看作是统计模型,而基于机器学习的方法(例如自回归马尔可夫模型)可能也不被看作是统计模型。在实施例中,自回归统计模型可以是如下统计模型,在所述统计模型上执行对于该统计模型的内部参数的估计处理以便执行时间序列投影。在下面,这样的内部估计处理结合arma和arima模型示出。
41.如前面已经阐述的,自回归统计模型可以是基于arma或arima的模型。arma和arima(arima是arma的基于整合的变型)是提供时间序列的数值的时间序列投影的自回归统计模型。拆开首字母缩略词——ar代表自回归(auto regressive),ma代表移动平均(moving average)。一般来说,用于时间序列投影的自回归统计模型是(仅)使用时间序列的先前的数值来执行基于回归的时间序列投影的统计模型,即,投影可以仅基于时间序列的先前的数值。在移动平均模型中,输出值线性地取决于随机项的当前的值和一个或多个过去值。具体地说,回归误差可以是当前的误差项和先前的误差项的线性组合。因此,自回归统计模型可以是自回归移动平均模型。arma和arima模型的更多细节在本公开的后面的部分中示出。
42.如以上已经指出的,arima模型是arma模型的变型,其中,字母“i”指示模型是整合的(integrated)模型,即,包括整合分量的模型。更具体地说,在arima中,时间序列投影应
用于数值的经微分的版本上。换句话说,自回归模型可以应用于传感器数据的多个采样的微分。在arima中(经常)使用数值的一次求导的版本。换句话说,自回归模型可以应用于传感器数据的多个采样的一次求导的版本上。一般来说,可以通过计算所述多个采样的后续的采样之间的差来计算微分。换句话说,可以通过对于所述多个采样中的每个采样(除了第一个采样之外)从该采样减去所述多个采样的前一个采样来计算所述多个采样的经微分的版本(例如,一次求导的版本)。
43.一般来说,在基于arma或arima的模型中,可以应用各种过程来执行时间序列投影。一般来说,可以在统计模型内应用处理“估计”、“验证”和“应用”。一般来说,“估计”涉及对代表时间序列的内部多项式值进行估计。换句话说,处理电路可以配置为用于估计表示时间序列的内部多项式值,例如使用最大似然性估计或者使用最小平方估计来进行估计。“验证”是指基于所识别的内部多项式值来验证正在执行的时间序列投影(例如,就通过时间序列值产生的误差残差是否不相关和/或误差残差是否表现得像白噪声而言)的处理。换句话说,处理电路可以配置为用于验证表示时间序列的所估计的内部多项式值。“应用”是指执行并且输出时间序列投影的处理。换句话说,处理电路可以配置为用于使用表示时间序列的所估计的内部多项式值来执行时间序列投影。
44.在一些实施例中,可以应用处理“识别”来识别arma或arima模型的通用参数。备选地,arma或arima模型的通用参数可以是预定的。换句话说,处理电路可以配置为用于从所述系统的存储器获取arma或arima模型的通用参数、或者用于确定通用参数(例如,通过使用有界穷尽网格搜索)。例如,如在本公开的后面的部分中将介绍的,赤池信息准则(akaike information criterion,aic)可以用于确定arma或arima模型的通用参数。
45.一般来说,arma和arima模型都具有至少两个通用参数,这两个通用参数一般被指定为p(其是趋势自回归阶数)和q(其是趋势移动平均阶数)。另外,基于arima的模型具有通用参数d,其限定趋势差分阶数。在实验中,发现参数值p=1、d=1和q=4是合适的参数。换句话说,arma模型能以参数p=1和q=4使用,而arima模型能以p=1、d=1和q=4使用。另外,发现40个先前的采样提供适合的历史数据组。换句话说,可以使用传感器的传感器数据的至少20个采样(或者至少30个采样)和/或至多60个采样(或者至多50个采样)(例如,使用40个采样)来执行时间序列投影。
46.一些自回归统计模型使用所谓的季节性来对时间序列中的季节性改变进行建模。这在具有季节性变化(例如周末和工作日之间的变化、或者日间小时和夜间小时之间的变化)的时间序列中是有用的。然而,在实施例中,这样的季节性变化可能是不适用的,例如,因为所包含的时间范围可能太小以致于不能表现出季节性。因此,与季节性相关的通用参数可以被忽略或者被设置为零。例如,在arima中,可以限定与时间序列投影的季节性相关的通用参数、例如p(季节性自回归阶数)、d(季节性差分阶数)、q(季节性移动平均阶数)和m(用于单个季节性时间段的时间步的数量)。这些通用参数可以忽略或者设置为零,即,(p,d,q,m)=(0,0,0,0)。
47.一般来说,无论使用哪种自回归统计模型,所使用的投影范围可以限定为,使得所述投影范围填补通过时间偏移限定的缺口。换句话说,处理电路可以配置为用于以与在传感器数据与参考时间之间的时间偏移相匹配的投影范围来执行时间序列投影。例如,时间序列投影可以扩展传感器的传感器数据,使得在传感器数据与参考时间之间的缺口被填
补。换句话说,处理电路可以配置为用于执行时间序列投影,使得在传感器数据与参考时间之间的时间偏移被时间序列投影填补。
48.处理电路配置为用于,基于时间序列投影并且基于在传感器数据与参考时间之间的时间偏移来确定针对参考时间的对传感器数据的估计。例如,如前面已经阐述的,时间序列投影可以扩展传感器的传感器数据,使得在传感器数据与参考时间之间的缺口被填补。处理电路可以配置为用于使用时间序列投影的输出来确定针对参考时间的对传感器数据的估计,所述输出与针对参考时间的对传感器数据的估计相对应。在各种实施例中,在任何给定的时间点,处理电路可以配置为用于(相对于当前的传感器数据)确定针对参考时间的(即,在参考时间时的、参照参考时间的)对传感器数据的单个估计,并且忽略在最新的采样与针对参考时间估计的采样之间的时间。最后,处理电路可以配置为用于输出对传感器数据的估计。
49.如前面已经指出的,分布式系统(例如,交通工具)可以包括第二传感器。在一些实施例中,第二传感器可以是如下传感器,所述传感器提供相对于参考时间具有较小缺口或者相对于参考时间具有零缺口的传感器数据,因此所述传感器可以被用作参考。因此,参考时间可以基于第二传感器30的传感器数据。例如,参考时间可以由第二传感器的传感器数据的最新的采样限定,或者参考时间可以与传感器的传感器数据成预定的关系。时间序列投影可以用于使第一传感器的传感器数据和传感器数据同步。用更正式的说法,第二传感器的传感器数据可以包括多个第二采样,处理电路可以配置为用于确定对传感器数据的估计,使得对传感器数据的估计与第二传感器的传感器数据的最新的采样在时间上同步。换句话说,对传感器数据的估计可以针对如下时间点来确定,所述时间点与第二传感器的所述多个第二采样中最新的采样的时间点匹配。再次,所述多个第二采样中最新的采样可以要么限定参考时间,要么与参考时间成预定的时间关系。
50.备选地或附加地,分布式系统(例如,交通工具)可以包括耦联到系统10(所述系统也可以是电子控制单元)的另一个电子控制单元(ecu)40。本公开的实施例可以用于补偿由从一个电子控制单元到另一个电子控制单元的传输引入的延迟,所述传输是在分布式系统/交通工具的总线系统上执行的。因此,参考时间可以基于在系统10与电子控制单元40之间的通信延迟。例如,时间偏移可以对应于在系统10与电子控制单元40之间的通信延迟(或通信延迟的负值)。
51.在各种实施例中,处理电路进一步配置为用于获取第二传感器的传感器数据、例如经由接口12获取。第二传感器的传感器数据可以用于以下两件事中的至少一件:确定参考时间、以及提供第一传感器和第二传感器的传感器数据的时间同步的版本。
52.例如,处理电路可以配置为用于,基于第二传感器的传感器数据并且基于传感器的传感器数据来获取在传感器的传感器数据与参考时间之间的时间偏移(因为第二传感器的传感器数据的最新的采样可以与参考时间成预定的时间关系或限定参考时间)。一般来说,第一传感器数据和第二传感器数据可以是相关联的。作为示例,在电动交通工具的动力传动系中,电池的输出一般与一个或多个电机的电流消耗和/或与动力传动系的一个或多个组件的温度相关(因为电流不仅被用于产生机械功率,而且还被用于产生在各种组件中的相应热量)。因此,第一传感器的传感器数据中的变化可以看出第二传感器的传感器数据中的对应的(即,相关联的)变化,以在时间序列投影中使用的相同的时间偏移可感知所述
变化。处理电路可以配置为用于,计算在第一传感器的传感器信号与第二传感器的传感器数据的多个经时移的版本之间的相关性(或者反过来)。产生最高相关度的经时移的版本可以是基于(正确的)时间偏移的。因此,处理电路可以配置为用于将相关性分析应用于第一传感器和第二传感器的传感器数据的经时移的版本上以确定时间偏移。
53.附加地或备选地,可以以时间同步的方式输出第一传感器和第二传感器的传感器数据。换句话说,处理电路可以配置为用于输出传感器的估计的传感器数据和第二传感器的传感器数据的时间同步的版本。
54.接口12可以对应于用于在模块内、在模块之间、或者在不同实体的模块之间接收和/或发送信息的一个或多个输入和/或输出,所述信息可以是根据指定代码的数字(位)值。例如,接口12可以包括配置为用于接收和/或发送信息的接口电路。
55.在实施例中,处理电路14可以使用一个或多个处理单元、一个或多个处理装置、用于处理的任何手段(例如能以相应地适配的软件操作的处理器、计算机或可编程硬件组件)来实现。换句话说,处理电路14的所描述的功能也可以以软件来实现,所述软件然后在一个或多个可编程硬件组件上被执行。这样的硬件组件可以包括通用处理器、数字信号处理器(dsp)、微控制器等。
56.结合所提出的构思或上述或下述的一个或多个示例(例如,图2a至图4b)提到了所述系统和方法的更多细节和方面。所述系统和方法可以包括与所提出的构思或上述或下述一个或多个示例的一个或多个方面相对应的一个或多个附加的可选特征。
57.本公开的实施例涉及提高电子交通工具中的测量质量。交通工具可以比作是分布式系统,所述分布式系统包括经由总线系统彼此连接和通信的多个控制单元(ecu)。遗憾的是,在总线通信中可能发生时间延迟。它们导致延迟并因此导致效率损失。延迟对于每个(作为信号的源头的)ecu而言可以是独特的并且可以被确定。在确定延迟之后,在最后接收的信号与当前的时间步长之间的值仍可以是已知的。在一些其他的系统中,自回归马尔可夫模型(armm)和神经网络可以用于预测在最后接收的信号与当前的时间步长之间的值。
58.举个例子:信号1比信号2晚3个时间步长到达。在实施例中,时间延迟可以被确定以发现信号1相对于信号2延迟3个时间步长,并且信号可以被相应地修正。本公开的实施例关注于针对当前的时间步长和两个先前的时间步长对信号1的值的预测。
59.在下面示出对不同的时间序列投影算法的评估。对使用来自已经接收到的值的时间序列预测来产生丢失的信号值的不同的五个改进的和两个普通的算法进行了评估。所考虑的算法是:(两个不同版本的)指数平滑;arima;box-cox变换、arma(自回归移动平均)残差、趋势和季节性(bats);和三角季节性、box-cox变换、arma残差、趋势和季节性(tbats);以及普通的方法“预测的值=最后接收到的值”和随机游走。附加地,对不同算法的经由装袋法(bagging)或引导聚合(bootstrap aggregation)的组合进行了评估。
60.与电机的实际的信号相比,高压存储器(hvs)的电流测量信号由控制单元(ecu)延迟大约6个时间步长接收到。因此,虽然信号可以被修正,并且信号值可以与其“实际的”时间相关联,但是实施例可以用于预测尚未接收到的6个值。在上述各算法的帮助下,可以从例如20个最后接收到的测量值逼近/估计这6个值。例如,实施例可以用于交通工具和机械、飞机等中。
61.本公开的各种实施例涉及用于电的动力传动系的测量的时间序列预测。实时的系
统需要最新的信息。然而,由于动力传动系的分布式架构,电动交通工具(ev)的动力传动系中的测量信号通常以独特的时间延迟被接收到。本公开的实施例提供一种试图通过从最后接收到的值预测直至目前的时间步长的每个信号来补偿时间延迟的方法。在下面针对时间序列预测对5种时间序列预测算法和2种普通的方法进行评估。将所述算法应用于ev的真实的动力传动系数据上,并且评估结果。所述评估集中于运行时间、精度和准确度。如下面将示出的,所评估的方法实现了小于5%的预测误差率。如所预期的,基准普通方法是最快速的。令人惊讶的是,基准普通方法获得与指数平滑相当的结果。box-cox变换、arma(自回归移动平均)残差、趋势和季节性(bats)和三角季节性、box-cox变换、arma残差、趋势和季节性(tbats)是最慢的算法。尽管如此,它们实现最佳的准确度但存在异常值的问题。arima(自回归整合移动平均)具有最高的精度并且因此在所有算法中具有在异常值与准确度之间的最佳折中。附加地,为了进一步提高准确度,对不同算法的预测的组合的益处进行了评估。
62.现代的交通工具包括多个分布式和嵌入式系统。例如,气候控制单元和马达单元是分开的嵌入式系统。这些系统中的每个系统都包括一个或多个传感器和电子控制单元(ecu)。各ecu经由总线系统连接并且交换信息。总线通信需要时间,因此,许多测量一到达ecu(参见图2a)就是延迟的。相反,这意味着从ecu的角度来说,来自其他ecu的实际时间步长的测量仍是不可用的(参见图2b)。
63.图2a和2b示出关于传感器数据的可用性的曲线图。在图2a中示出了曲线图,该曲线图中示出了在“真实的”信号210(以十字标记)和延迟的接收的信号220(虚线,以虚线圆圈标记)之间的区别。由于在ev的动力传动系中的分布式系统之间的时间延迟,ecu接收原始的测量信号210的延迟版本220。在图2b中示出了以下场景:延迟的信号被修正230(使得接收的采样被归于其正确的时间),因此变得明显的是,最新的采样240丢失。换句话说,如果通过执行自动时间延迟估计来修正延迟的信号,则变得明显的是,最后的时间步长240的测量尚未被接收到。尽管如此,这些实际的测量可能是控制ev所必需的。本公开的实施例可以尝试预测直至目前的丢失的值(通过执行时间序列投影来预测)。测量的可用性的丢失或延迟是有问题的,因为许多交通工具实时控制功能取决于这些数据和它们的及时性。尤其是,电动交通工具(ev)由于时间延迟而损失效率和性能(参见j.pfeiffer和x.wu(2019),“automated time delay estimation for distributed sensor systems of electric vehicles”)。本公开的实施例可以对尚未接收到的信号构造可信的虚拟测量值。从过去的时间步长已经接收到的测量可以用于预测直至目前的值。
64.在下面给出四组算法。
65.第一组算法涉及指数平滑:指数平滑是60多年前首次提出的一族时间序列预测算法(参见r.g.brown和a.d.little(1956),“exponential smoothing for predicting demand”)。在下面使用简单的和完全加性的霍尔特-温特斯(holt-winters)模型(r.j.hyndman和y.khandakar(2008):“automatic time series forecasting:the forecast package for r”)。
66.指数平滑的基本构思是将未来值的预测构造为过去的观察y
t
和先前的预测的加权平均。由此,将更重的权重分配给更近的值。来自更遥远的过去值的权重更小。形式上,简单的指数平滑预测方程可以被写为:
[0067][0068]
其中,0<α<1是平滑因子。
[0069]
对这个基本模型的扩展是完全加性的霍尔特-温特斯模型。它通过考虑加性的趋势和季节性来预测针对下一个时间步长的值。通过用3个隐藏的状态变量扩展来自等式(1)的预测来将季节性方面包入。
[0070]
l
t
=α
·
(y
t-s
t-m
)+(1-α)
·
(l
t-1
+b
t-1
),
[0071]bt
=β
·
(l
t-l
t-1
)+(1-β)
·bt-1
,
[0072]st
=γ
·
(y
t-l
t-1-b
t-1
)+(1-γ)
·st-m
,
ꢀꢀꢀꢀ
(2)
[0073]
其中,l
t
是序列水平,b
t
是趋势,s
t
是在时间步长t时的季节性分量。α、β和γ是对应的平滑系数。它们通过最佳化算法拟合,并且具有在0和1之间的值。m表示季节性因子。它反映在季节性时间段内的时间步长的数量并且确保季节性被正确地建模。可以借助于结合简单的、部分的自相关函数的频谱密度分析来获得m。新的预测由以下等式给出:
[0074][0075]
第二组算法涉及arima。arima是用于分析和预测时间序列数据的一类统计模型(v.kotu和b.deshpande(2019),data science:concepts and practice. cambridge, ma, united states: elsevier,2019)。它是以整合扩展的对更简单的arma的一般化。首字母缩略词arima是描述性的,并且表达模型本身的关键方面。它们可以概括在下面3个组成部分中:
[0076]
1)自回归(ar):使用在观察与多个滞后的观察之间的依赖关系的模型。
[0077]
2)整合(i):对原始观察的微分,以使时间序列稳定。这可以通过从前一个时间步长时的观察减去在实际的时间步长时的观察来实现。
[0078]
3)移动平均(ma):使用在观察与来自应用于滞后的观察的移动平均模型的残留误差之间的依赖关系的模型。
[0079]
这些组成部分中的每个组成部分都在标准表示法arima(p,d,q)中的模型参数中明确地指定。它们被替换为整数值以表明所使用的特定模型,并且被如下限定。p是模型中所包括的滞后观察的数量,也被称为滞后阶数。d是原始观察被求导的次数,也称为微分的程度。q是移动平均窗口的大小,也称为移动平均的阶数。
[0080]
未来的步长t+1的预测值因此是常数和y的一个或多个近期值的加权和或预测误差e的一个或多个近期值的恒定的加权和。在示例中,设p=1,d=1,q=2。在这种情况下获得的arima模型是阻尼趋势线性指数平滑。它推断在时间序列结束时的局部趋势。同时,它将趋势在更长的预报范围内拉平以引入少量的保守性。为了预测,首先计算未来值y
t+1
的d阶差分所述差分是原始的时间序列的过去值和预测误差的过去值的线性组合。可以根据以下方程来计算:
[0081][0082]
其中,l
t
是局部水平,e
t
是时间步长t时的预测误差。αj是相对于y
t-j
的d阶差分的斜率,j∈{0,1,2,
…
,p}。θk是相对于预测误差e
t-k
的移动平均参数,k∈{0,1,2,
…
,q}。在此,e
t+1
被假定为白噪声。arima的整合部分被反映在的d阶差分中。对于一阶微分,
可以例如通过以下方程来获得:
[0083][0084]
其中,y
t
和y
t-1
分别是在运行步长t和t-1时的真实的值。最后,可以获得预测方程:
[0085][0086]
第三组算法涉及box-cox变换、arma残差、趋势和季节性(bats)和三角季节性、box-cox变换、arma残差、趋势和季节性(tbats),这些是在a.m.de livera,r.j.hyndman和r.d.snyder(2011):“forecasting tume series with complex seasonal patterns using exponential smoothing”中示出的状态空间建模框架的扩展。它们介绍了综合方法以用于预测复杂的季节性时间序列(例如具有多个季节性时间段、高频率季节性和非整数季节性的时间序列)。这通过利用box-cox变换、具有时变系数的傅里叶表示和arma误差修正的优点来实现。box-cox变换解决了数据中的非线性的问题。arma模型解决时间序列数据中的残差的去相关。de livera等人证明与简单的状态空间模型相比,bats模型可以改进预测性能。这两个框架的关键特征是它们依赖于强烈地降低最大似然性估计的计算复杂度的优化的方法。
[0087]
bats模型的根源是指数平滑。它将等式(3)重新表达为:
[0088][0089]
并且将来自(2)的隐藏状态变量重新表达为:
[0090]
l
t
=l
t-1
+φ
·bt-1
+α
·dt
,
[0091]bt
=(1-φ)
·
b+φ
·bt-1
+β
·dt
,
[0092][0093]
其中
[0094][0095]
这里,是用参数ω进行box-cox变换的在时间步长t时的观察。类似于上面,表示第i季节性分量,l
t
是局部水平,b
t
是阻尼趋势。记号d
t
代表用于残差的arma(p,q)处理。因为我们不能直接计算预测误差e
t
,所以它被建模为高斯白噪声处理。e
t-1
代表第i box-cox变换的预测误差。box-cox变换参数ω、平滑参数α和β、趋势阻尼因子arma系数φi和θi、以及季节性平滑因子γi都可以通过高斯似然性处理来估计。
[0096]
tbats通过包入用于分解复杂的季节性时间序列并且识别潜在的季节性分量的三角公式来扩展bats模型。基于如下的傅里叶级数来对季节性分量进行建模:
[0097][0098][0099]
decomposition and box-cox transformation”)。
[0111]
在下面,介绍实验设置和用于评价结果的手段。参考数据由ev的动力传动系中的电流测量的广泛的记录集合组成。测量数据在公共道路上记录,并且反映ev的动力传动系在一般的驾驶条件下的行为。数据集合涵盖以100hz的频率测量的总共4小时的驾驶数据。对于实验,焦点在于hv电池、电机、电加热器、空调压缩机和dc/dc转换器的5hv电流。现有的数据集合被划分为训练段和测试段以应用嵌套交叉验证。为此,数据被划分为尺寸恒定的组块。每个组块由20个数据点组成。总共考虑10480个组块。
[0112]
为了更好地估计每种算法的预测误差,常见的方法是对所有的训练/测试划分部分上的误差求平均。所用的技术是基于被称为正向推理的方法。其在文献中被称为滚动-原点评价(l.j.tashman(2000):“out-of-sample tests of forecasting accuracy:an analysis and review”)或滚动-原点-重新校准评价(c.bergmeir和j.bentez(2012):“on the use of cross-validation for time series predictor evaluation”)。基于该方法,每个数据组块都被认为是测试集合(参见图3)。先前的数据被分配给训练集合。假定数据集合可以被划分为如图3所示的5个组块,则确定四个不同的训练划分部分和测试划分部分。流程用于将数据集合划分为——在该示例性情况下——五个训练组块和测试组块。
[0113]
图3示出嵌套交叉验证流程的按时间顺序的表示。划分为五个组块的历史hv电流测量在左边示出。在第一次运行中,将一个组块用作训练(training)数据,并且将一个组块用作测试(test)数据。在第二次运行中,将两个组块用作训练数据,并且将一个组块用作测试数据,在第三次运行中,将三个组块用作训练数据,并且将一个组块用作测试数据,在第四次运行中,将四个组块用作训练数据,并且将一个组块用作测试数据。训练用于选择模型的超参数(在第一次运行中一个数据组块,在第二次运行中两个组块,等等),测试数据用于评价模型。每次运行产生误差error1至error4,模型性能通过对error1至error4进行求和来确定。
[0114]
通过生成多个不同的训练/测试划分部分,实现对每种算法的预测准确度的更好的评定。对每个划分部分上的误差再次求平均以便计算对每种算法的误差的鲁棒的估计。总体预测误差∈被相应地建模为:
[0115][0116]
其中,n代表划分部分的数量,m代表每个划分部分的数据点的数量,代表现有的误差性能度量。
[0117]
为了测量每种算法关于其准确度和计算效率的性能,引入了以下度量:均方根误差(rmse)和平均绝对百分比误差(mape)。
[0118]
均方根误差(rmse)是测量误差的平均幅值的二次评分规则。其是在预测与实际观察y
t
之间的平方差的平均值的平方根。其由以下方程给出:
[0119][0120]
其中,h是预测范围。
[0121]
平均绝对百分比误差(mape)是预测模型的准确度的统计测度。在除以实际的值的一组预测中,mape是平均误差幅值。平均误差幅值反映预测和实际的观察之间的绝对差分的测试采样上的平均值,其中,所有单独的差分都具有相等的权重。它由以下式子给出:
[0122][0123]
分析每种预测算法的运行时间性能对于调查其对于实时系统的适合性是重要的。如果预测花费太多时间,则它可能变得过时。因此,所有的算法都在相同的情况下、在相同的执行平台上被执行多次,并且测量它们的运行时间。在随后的测量中,使用具有2.4ghz cpu和8gb的ram的计算机。
[0124]
测试设置用于在7个候选算法的池中识别算法的最佳组合。其本质是将关于不同算法的预测误差的知识与历史数据相联系。因此,在下面,关注用于将历史电流测量映射到预测方法性能的实验。在第一步中,关注获得每种算法的最佳的超参数并且评定单独的性能。在第二步中,评定组合来自不同方法的预报在降低不确定性和提高预报准确度中的增加价值。
[0125]
在下面,评定算法在预测未来的hv电流中的单独的性能。在特定的约束下执行分析。主要约束是对未来的电流值的推断和预测仅基于历史测量。使用前面描述的嵌套交叉验证过程来评定每种算法的性能。在第一阶段中,执行遍历在训练划分部分上的超参数空间的手动指定的子集的穷尽网格搜索。这有助于识别用于每种算法的超参数的最佳组合。作为选择度量,采用赤池信息准则(aic)。aic奖励在每种算法的估计参数的数量k给定的情况下、通过似然性函数评定的拟合优度。同时,aic对k和所述算法的复杂度进行惩罚以防止过度拟合。设为用于预测算法的似然性函数的最大值。所述算法的aic值于是为:
[0126][0127]
其中,对数似然性是模型拟合的代表性测度。在统计上,数量越多,拟合越好。优选的模型——分别为超参数的最佳组合——因此是具有最小aic值的模型。在第二阶段中,评估每种算法在测试数据划分部分上的预测性能。总共,以上讨论的三个度量被用作比较值。从而可以对每个单独的算法就预测准确度和运行时间效率这二者而言的性能如何进行调查。在hv电流测量的给定上下文下,实现在运行时间与准确度之间的权衡是最关键的。这个分析阶段从而关注识别确保最佳权衡的算法。为了这个目的,每种算法必要的历史数据点的最佳数量也被考虑在内。下面提供每种算法对于20个时间步长的预测范围的结果。
[0128]
另一方面在分析引导聚合法的潜在增加价值。假定将来自基本上不同的方法的预测进行组合有助于提高总体准确度。考虑到关于哪种方法最准确和动力传动系正在哪些条件下操作的不确定性高,引导聚合法在目前的情况下可以是适宜的。在组合算法的预测中采用规范过程。在理想的情况下,预测误差是负相关的,以使得它们可能彼此抵消。因此,我们遵循如以下等式中所描述的等权重方法:
[0129]
[0130]
其中,是算法i∈[1..m]在时间步长t+1时的预测值,m=7是池中的算法的数量。
[0131]
在下面呈现了结果。分别讨论每个实验。首先,评定单独的性能。在该部分中,目的是评定每种预测算法的孤立的性能。为此,使用以上讨论的性能度量。图4a中总结了对于rmse和mape度量获得的值。为了比较获得的预测性能,将普通的方法用作基准。就mape而言,只有arima算法强于它。通过arima实现的mape改进为8%。这些优越的结果是由arima的整合部分而导致的。因此,所述算法可以对于非静止数据更好地自行调整。还需要提及的是,所有考虑的算法(除了bats和tbats之外)都实现了小于5%的平均预测误差率。然而,关于rmse的比较获得更好的结果。arima、bats和tbats强于基准。尤其是bats和tbats实现了好得多的结果。它们的良好的rmse结果是有吸引力的,因为它们二者都获得了相对较高的mape值,分别为7.47%和7.48%。其他的普通的方法、随机游走和指数平滑算法实现了与基准类似的相当的结果。就rmse和mape这二者而言获得的差异提示了,将多个算法的预报结合可能引起总体性能的改进。图4a示出通过所述算法在测试集合上获得的预测性能得分的概览。
[0132]
图4b中示出的表格将图4a中描述的结果扩展以涵盖计算方面。如以上所讨论的,计算复杂度和运行时间要求可以被视为对于预测hv电流测量的目标而言关键的。考虑低于20个时间步长的预测范围,季节性arima、bats和tbats的方法可以被视为是过时的。它们各自的运行时间可能超过我们最大200ms的限制。在实际的使用条件下,所获得的预报在它们被计算出来的时候可能是不重要的。arima仅短暂地错失运行时限制。进一步的优化可以使该算法对于目的是可行的。没有进一步的优化,焦点可以设置在其余的最简单的方法上以用于部署。图4b示出每种算法的就准确度和效率而言的比较。
[0133]
在本节中,结果是在引导聚合期间获得的。对于该实验,将具有最低的mape的五种算法组合。因此,被考虑用于组合的算法是arima、简单的霍尔特-温特斯指数平滑、以及随机游走和普通的方法,如图4a所示。如上所述,遵循等权重方法。每种算法的预测值因此在每次预测运行时被求平均。在这里讨论的结果是针对与以上使用的数据集合相同的数据集合获得的。这使得能够客观地比较对于相同数据的单独的性能和组合的性能。对于相同的测试集合,引导聚合法引起1.74的rmse值和4.19%的mape值。这再次意味着预测误差率低于5%。与单独的性能相比,就mape而言,除了arima之外,引导聚合法强于所有的单个的方法。因此,引导聚合法未能改进总体预测。尽管如此,可以用自适应权重方法来改进结果。代替本公开的上下文下使用的等权重方法,自适应权重方法可能能够受益于arima的高准确度。
[0134]
如所预期的,引导聚合法具有在所有考虑的方法中最差的运行时间。因为构思将多个算法组合,所以它也将所有这些算法的所需运行时间相加。特别是在以上描述的应用领域中(在ecu上执行),长运行时可能被认为是缺点。令人遗憾地,这种缺点可能无法通过所实现的结果来平衡。
[0135]
在分布式系统之间的时间延迟导致过时的测量信号。但是最新的输入数据是控制功能所必需的,特别是在实时系统、如ev的动力传动系中。对于该问题的解决方案是预测直至目前的延迟的信号。本文章的目标是评估哪些算法适合于对ev的动力传动系的延迟的测量信号进行时间序列预测。为了这个目的,我们对5种现有技术的时间序列预测算法和2种
普通的方法进行了评估。因为对于实时系统而言重要的是在所需的时间帧内获取信息,所以我们的评价不仅集中于我们以rmse和mape度量的准确度,而且还集中于执行预测所需的运行时间。bats和tbats是最准确的算法。然而,由于它们的高异常值,故它们不适合于我们的目标。arima提供在高准确度与小异常值之间的最佳折中。如所预期的,普通的方法是最快速的方法。令人惊讶地,尽管它是所有方法中最简单的方法,但是其准确度并非远低于其他方法。其相对良好的结果表明准确地预测电的动力传动系的hv测量的难度。因此,需要做进一步的工作来使得能够进行快速的、准确的预测。对于未来的工作的可能性是优化arima并且试图使它更快速。另一种可行方案是将多种算法的预测与引导聚合法结合。尽管这里实现的等权重方法强于几乎所有的算法,但是其不能实现arima的低mape值。必须进行进一步的工作以调查自适应权重方法是否强于arima。目前,引导聚合法需要最多的运行时间。
[0136]
结合之前详述的示例和附图中的一个或多个提到和描述的方面和特征也可以与一个或多个其他示例组合,以便替换其他示例的类似特征或者以便将该特征附加地引入到其他示例。
[0137]
示例进一步可以是或涉及具有程序代码的计算机程序,所述程序代码用于当在计算机或处理器上执行计算机程序时实现一个或多个以上方法。通过编程的计算机或处理器,可以实施上述各种方法的步骤、操作或过程。示例还可以覆盖诸如数字数据存储介质的程序存储设备,这些设备是机器、处理器或计算机可读取的并且编码机器可执行的、处理器可执行的或计算机可执行的指令程序。指令实施或引起实施上述方法的一些或全部动作。程序存储设备可以包括或者可以是例如数字存储器、诸如磁盘和磁带等的磁存储介质、硬盘驱动或光学可读取的数字数据存储介质。另外的示例还可以覆盖被编程以实现上述方法的动作的计算机、处理器或控制单元或者被编程以实现上述方法的动作的(现场)可编程逻辑阵列((f)pla)或(现场)可编程门阵列((f)pga)。
[0138]
说明书和附图仅说明了本公开的原理。此外,本文所记载的所有示例主要明确地旨在仅用于说明的目的,以帮助读者理解本公开的原理以及发明人为改进技术而贡献的构思。本文中记载本公开的原理、方面和示例以及本公开的具体示例的所有说明旨在涵盖其等同方案。
[0139]
表示为用于执行某个功能的“用于
…
装置”的功能块可以指被配置用于执行某个功能的电路。因此,“用于某事的装置”可以实现为“配置用于或适用于某事的装置”,例如配置用于或适用于相应任务的设备或电路。
[0140]
附图中所示的各种元件的功能,包括标记为“装置”、“用于提供信号的装置”和“用于产生信号的装置”等的任何功能块,可以以诸如“信号提供器”、“信号处理单元”、“处理器”和“控制器”等专用硬件以及能结合适当的软件执行软件的硬件的形式实现。当由处理器提供时,功能可以由单个专用处理器、单个共享处理器或由多个单独处理器(其中一些或全部处理器可以共享)提供。然而,术语“处理器”或“控制器”尤其不限于专门能够执行软件的硬件,而是可以包括数字信号处理器(dsp)硬件、网络处理器、专用集成电路(asic)、现场可编程门阵列(fpga)、用于存储软件的只读存储器(rom)、随机存取存储器(ram)和非易失性存储器。还可以包括其他传统的和/或定制的硬件。
[0141]
框图例如可以示出实现本公开原理的高级电路图。类似地,流程图、流程框图、状态转换图和伪代码等可以表示各种处理、操作或步骤,这些处理、操作或步骤例如可以基本
上计算机可读介质中表示,并且由计算机或处理器执行,无论该计算机或处理器是否明确示出。说明书或权利要求中公开的方法可以由具有用于执行这些方法的各个动作中的每个动作的装置的设备来实现。
[0142]
应当理解,除非另外明确地或隐含地说明(例如出于技术原因),否则在说明书或权利要求中公开的多种动作、过程、操作、步骤或功能的公开不可以解释为在特定顺序内。因此,多种动作或功能的公开不会将其限制为特定顺序,除非这些动作或功能出于技术原因不可互换。此外,在一些示例中,单个动作、功能、过程、操作或步骤可以分别包括或者分解为多个子动作、子功能、子过程、子操作或子步骤。除非明确排除,否则这些子动作可以包括在该单个动作的公开中并且是该单个动作的公开的一部分。
[0143]
此外,以下权利要求在此并入具体实施方式中,其中每个权利要求自身可以作为单独的示例存在。虽然每个权利要求自身可以作为单独的示例存在,但是要注意到,尽管一个从属权利要求在权利要求书中可以指一个或多个其他权利要求的特定组合,其他示例也可以包括该从属权利要求与每个其他从属或独立权利要求的主题的组合。除非表明并不旨在进行特定组合,否则本文明确地提出了这些组合。此外,一个权利要求的特征也包括在其他任何独立权利要求中,即使该权利要求没有直接从属于该独立权利要求。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1