用户交互方法、系统及车辆与流程
1.本公开涉及人机交互领域,具体地,涉及一种用户交互方法、系统及车辆。
背景技术:
2.目前,车载交互系统主要包括三种交互方式:按键控制、触摸控制和语音控制。按键控制和触摸控制这两种交互方式需要用户对设备进行手动操作,如果用户在驾驶车辆的过程中对车载交互设备进行操作,便不能专心驾驶,由此会带来安全隐患。而现有的语音控制交互方式仅仅是执行用户的语音指令,同样需要由用户进行主动控制才能提供服务。
技术实现要素:
3.本公开的目的是提供一种用户交互方法、系统及车辆,以便车载交互系统更加智能地对用户进行服务。
4.为了实现上述目的,本公开提供一种用户交互方法,包括:采集用户的人脸图像,以获得人脸图像信息;至少根据所述人脸图像信息,获得所述用户的状态识别结果,所述状态识别结果包括情绪状态识别结果和/或精神状态识别结果;根据所述状态识别结果,控制车载语音设备输出相应的语音信息。
5.可选地,所述方法还包括:采集所述用户的语音信息;所述至少根据所述人脸图像信息,获得所述用户的状态识别结果,包括:根据所述用户的语音信息和所述人脸图像信息,获得所述用户的状态识别结果。
6.可选地,所述根据所述状态识别结果,控制车载语音设备输出相应的语音信息,包括:确定待输出的语音内容;根据所述状态识别结果,确定与所述用户的状态相匹配的语音特征信息;将所述语音特征信息和所述语音内容传输至所述车载语音设备,以使所述车载语音设备根据所述语音特征信息和所述语音内容进行语音合成,并输出合成后得到的语音信息可选地,所述语音特征信息包括以下中的一种或多种:韵律、声调、音高。
7.可选地,所述语音信息包括以下中的一种或多种:语音导航信息、对话信息、语音提示信息、音频。
8.本公开还提供一种用户交互系统,包括:图像采集装置、控制装置和车载语音设备,其中:所述图像采集装置用于采集用户的人脸图像,以获得人脸图像信息;所述控制装置用于至少根据所述人脸图像信息,获得所述用户的状态识别结果,所述状态识别结果包括情绪状态识别结果和/或精神状态识别结果;根据所述状态识别结果,控制所述车载语音设备输出相应的语音信息。
9.可选地,所述系统还包括:语音采集装置,用于采集所述用户的语音信息;所述控制装置进一步用于:根据所述用户的语音信息和所述人脸图像信息,获得所述用户的状态识别结果。
10.可选地,所述控制装置进一步用于:确定待输出的语音内容;根据所述状态识别结果,确定与所述用户的状态相匹配的语音特征信息;将所述语音特征信息和所述语音内容传输至所述车载语音设备,以使所述车载语音设备根据所述语音特征信息和所述语音内容进行语音合成,并输出合成后得到的语音信息可选地,所述语音特征信息包括以下中的一种或多种:韵律、声调、音高。
11.本公开还提供一种车辆,该车辆包括本公开提供的上述用户交互系统。
12.通过上述技术方案,能够自动识别出用户在驾驶车辆的过程中实时的情绪状态和/或精神状态,并针对不同的识别结果向用户输出相应的语音提示,为用户提供人性化服务,提升用户的驾驶体验。同时,由于上述技术方案能够针对用户的情绪状态和/或精神状态主动提供语音服务,能够使用户更专注于驾驶,保证行车安全。
13.本公开的其他特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
14.附图是用来提供对本公开的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本公开,但并不构成对本公开的限制。在附图中:图1是根据本公开一示例性实施例的一种用户交互方法的流程图。
15.图2是根据本公开又一示例性实施例的一种用户交互方法的流程图。
16.图3是根据本公开一示例性实施例的一种用户交互系统的框图。
17.图4是根据本公开又一示例性实施例的一种用户交互系统的框图。
具体实施方式
18.以下结合附图对本公开的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本公开,并不用于限制本公开。
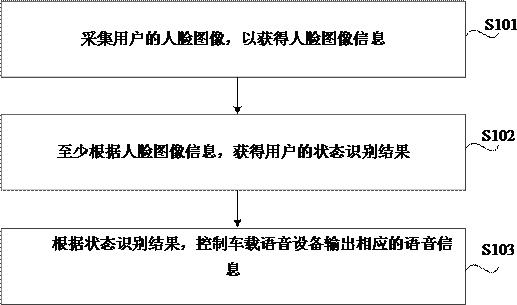
19.图1是根据本公开一示例性实施例的一种用户交互方法的流程图,该方法可以应用于车辆。如图1所示,该方法可以包括步骤s101至步骤s103。
20.在步骤s101中,采集用户的人脸图像,以获得人脸图像信息。
21.示例地,用户可以为驾驶员,也可以为车辆上任一其他乘员。可以在驾驶室内安装摄像头,对用户的面部进行拍摄,获得用户实时的面部图像。摄像头的安装位置可依照要采集的用户的位置进行设置,确保能够采集到较为清晰的该用户的人脸图像。
22.在步骤s102中,至少根据人脸图像信息,获得用户的状态识别结果,该状态识别结果包括情绪状态识别结果和/或精神状态识别结果。
23.利用人脸识别技术对步骤s101获得的人脸图像信息进行分析,获得用户当前的状态识别结果。用户的状态识别结果可以包括情绪状态识别结果,例如,“愤怒”、“高兴”、“平静”等;也可以包括精神状态识别结果,例如,“疲惫”、“困倦”等;也可以包括情绪状态识别
结果和精神状态识别结果两者。
24.在步骤s103中,根据状态识别结果,控制车载语音设备输出相应的语音信息。
25.用户情绪状态、精神状态极有可能影响用户的驾驶行为。可以预先设定每种情绪状态、精神状态相对应的语音信息。用户在驾驶车辆的过程中,根据步骤s102获得的用户的状态识别结果,控制车载语音设备输出相应的语音信息。例如,当识别到用户的情绪状态为“愤怒”时,可以语音提醒用户保持冷静,专注开车。又例如,当识别到用户的精神状态为“疲惫”时,可以语音提醒用户进行适当休息。
26.通过上述技术方案,能够自动识别出用户在驾驶车辆的过程中实时的情绪状态和/或精神状态,并针对不同的识别结果向用户输出相应的语音提示,为用户提供人性化服务,提升用户的驾驶体验。同时,由于上述技术方案能够针对用户的情绪状态和/或精神状态主动提供语音服务,能够使用户更专注于驾驶,保证行车安全。
27.图2是根据本公开又一示例性实施例的一种用户交互方法的流程图。如图2所示,该方法可以包括步骤s201至步骤s204。
28.在步骤s201中,采集用户的人脸图像,以获得人脸图像信息。该步骤s201的实施与上文所述的步骤s101相同,此处不再赘述。
29.在步骤s202中,采集用户的语音信息。示例地,通过车载麦克风采集用户的语音信息。
30.在步骤s203中,根据用户的语音信息和人脸图像信息,获得用户的状态识别结果。
31.在步骤s204中,根据状态识别结果,控制车载语音设备输出相应的语音信息。该步骤s204的实施与上文所述的步骤s103相同,此处不再赘述。
32.在本实施例中,在步骤s203中,结合用户的语音信息和人脸图像信息,综合判断用户当前的状态,以得到用户的情绪状态识别结果和/或精神状态识别结果。其中,通过用户的语音信息,可以识别出用户的语气,而用户的语气也能在一定程度上反映出用户的情绪状态和精神状态。
33.例如,在驾驶过程中,用户在听到导航信息后,面部表情较为平静,而麦克风采集到了用户带有疑问语气的语音信息“嗯”,此时,通过用户的语音信息可以判定用户的情绪状态为“困惑”。此时,可以推断出用户对导航信息可能存在疑惑,因此,可以控制车载语音设备再次语音播报该导航信息。
34.通过上述技术方案,能够根据用户的语音信息和人脸图像信息综合判断出用户实时的情绪状态和/或精神状态,在用户面部表情较为平静的时候也能分析出用户的需求,并主动提供语音服务,提升了用户的使用体验。同时,由于上述技术方案根据用户实时的情绪状态和/或精神状态主动为用户提供语音服务,使得用户更加专注于驾驶,保证了行车安全。
35.可选地,步骤s103、步骤s204可以包括:确定待输出的语音内容;根据状态识别结果,确定与用户的状态相匹配的语音特征信息;将该语音特征信息和该语音内容传输至车载语音设备,以使该车载语音设备根据该语音特征信息和该语音内容进行语音合成,并输出合成后得到的语音信息。
36.待输出的语音内容是指待输出的文本信息。在一种实施方式中,可以根据用户输入的语音信息来确定待输出的语音内容,以作为对用户的语音信息的响应。例如,用户输入
的语音信息为车载语音设备的唤醒词,则待输出的语音内容可以为“您好,请问有什么可以帮助到您”。在另一种实施方式中,可以根据状态识别结果,确定待输出的语音内容。例如,状态识别结果表征用户当前的精神状态为疲惫,则待输出的语音内容可以为“请停车休息,避免疲劳驾驶”。
37.接下来,根据状态识别结果,确定与用户的状态相匹配的语音特征信息。其中,语音特征信息能够体现车载语音设备在输出语音信息时的语气特征。示例地,语音特征信息可以包括以下中的一种或多种:韵律、声调、音高。
38.声调特征是指声音的高低升降的变化。示例地,中文中有四个声调:阴平、阳平、上声和去声,英文包括重读、次重读和轻读,日文包括重读和轻读。韵律特征用于指示在阅读文本时应该在哪些地方进行停顿。音高特征是指各种音调高低不同的声音。
39.可以预先设定各状态对应的语音特征信息,这样,在获得状态识别结果后,可以通过该预先设定的对应关系,确定出与该状态识别结果相匹配的语音特征信息。之后,将该语音特征信息和该语音内容传输至车载语音设备,以使该车载语音设备根据该语音特征信息和该语音内容进行语音合成,并输出合成后得到的语音信息。如此,可以使得车载语音设备输出的语音信息带有与用户的状态相匹配的语气特征,使得对话氛围更贴合用户需求,提升用户交互时的用户体验。
40.例如,当用户的状态识别结果为“喜悦”时,车载语音设备可以输出具有能够体现较为欢快的语气的语音特征信息的语音信息,而当用户的状态识别结果为“疲惫”时,车载语音设备可以输出具有能够体现警示语气的语音特征信息的语音信息。
41.可选地,语音信息可以包括以下中的一种或多种:语音导航信息、对话信息、语音提示信息、音频。
42.针对用户的不同状态识别结果,向用户输出的语音信息可以包括语音导航信息、对话信息、语音提示信息、音频中的一种或多种。其中,语音导航信息是指引导用户驾驶车辆的信息,对话信息是指车载语音系统与用户之间的互动对话,语音提示信息是指针对用户当前状态所作出的语音提示,音频是指音乐、有声书、广播等以声音为载体的媒体内容。例如,在用户的状态识别结果为“困惑”时,可以向用户重复播报导航信息和前方路况的提示。又例如,当用户处于“疲惫”状态时可以向用户播放使用户不至于困倦的有声书、音乐等。
43.基于同一发明构思,本公开还提供一种用户交互系统。图3是根据本公开一示例性实施例的一种用户交互系统的框图。如图3所示,该系统300可以包括:图像采集装置301、控制装置302和车载语音设备303,其中:图像采集装置301用于采集用户的人脸图像,以获得人脸图像信息;控制装置302用于至少根据人脸图像信息,获得用户的状态识别结果,状态识别结果包括情绪状态识别结果和/或精神状态识别结果;根据状态识别结果,控制车载语音设备303输出相应的语音信息。
44.示例地,图像采集装置301可以为摄像头,控制装置302可以为ecu(电子控制单元,electronic control unit)、t-box(telematics box,远程信息处理器)等等。
45.可选地,本公开还提供又一种用户交互系统。图4是根据本公开又一示例性实施例的一种用户交互系统的框图。该系统300还包括:语音采集装置401,用于采集用户的语音信
息;控制装置302进一步用于:根据用户的语音信息和人脸图像信息,获得用户的状态识别结果。
46.可选地,控制装置302进一步用于:确定待输出的语音内容;根据状态识别结果,确定与用户的状态相匹配的语音特征信息;将语音特征信息和语音内容传输至车载语音设备303,以使车载语音设备303根据语音特征信息和语音内容进行语音合成,并输出合成后得到的语音信息。
47.关于上述实施例中的系统,其中各个装置执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
48.本公开还提供一种车辆,包括以上任一实施例所述的用户交互系统300。
49.以上结合附图详细描述了本公开的优选实施方式,但是,本公开并不限于上述实施方式中的具体细节,在本公开的技术构思范围内,可以对本公开的技术方案进行多种简单变型,这些简单变型均属于本公开的保护范围。
50.另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合。为了避免不必要的重复,本公开对各种可能的组合方式不再另行说明。
51.此外,本公开的各种不同的实施方式之间也可以进行任意组合,只要其不违背本公开的思想,其同样应当视为本公开所公开的内容。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1