城市低速环境下的大型营运车辆安全驾驶决策方法
1.本发明涉及一种营运车辆驾驶决策方法,尤其是涉及一种城市低速环境下的大型营运车辆安全驾驶决策方法,属于汽车安全技术领域。
背景技术:
2.在城市交通环境下,因驾驶员视线盲区引发的道路交通事故占比最高,这些事故的肇事主体多为重型货车、大型客车、汽车列车等大型营运车辆。不同于乘用车辆,大型营运车辆具有体积大、车身长、轴距大、驾驶位置高等特点,其车身周围存在较多的静态和动态视觉盲区,如车头前方、右前轮附近和右后视镜下方等。当营运车辆转向特别是右转时,极易碰撞甚至碾压视野盲区内行人和非机动车,是产生恶性安全事故的主要区域。此外,相比于较为封闭的高速公路场景,在机非混行的城市交通环境下,交通参与者的类型和数量相对较多,营运车辆突遇障碍物的情况时有发生,具有更高的危险性。因此,在开放、多交通目标干扰的城市交通环境下,如何提高营运车辆的行车安全性,是目前亟需解决的关键问题,也是保障城市道路交通安全的重点。
3.目前,积极发展自动驾驶技术已成为国内外广泛认可的保障车辆运行安全的重要手段。作为实现高品质自动驾驶的关键一环,驾驶决策决定了营运车辆自动驾驶的合理性和安全性。如果能在交通事故发生前的1.5秒对驾驶员进行危险预警,并提供可靠、有效的安全驾驶策略,可以大幅度降低因视觉盲区、突遇障碍物等因素造成的交通事故发生频率。因此,研究大型营运车辆的安全驾驶决策方法,对于保障营运车辆的行车安全具有重要作用。
4.已有较多专利和文献对防碰撞驾驶决策进行了研究,但主要面向乘用车辆。相比于乘用车辆,营运车辆具有较大的视觉盲区,且具有更长的制动距离和制动时间。面向乘用车辆的防撞决策方法,无法直接应用于营运车辆。另一方面,已有部分专利对营运车辆的安全驾驶决策进行了研究,如一种高度类人的自动驾驶营运车辆安全驾驶决策方法(申请号:202210158758.2)、一种基于深度学习的大型营运车辆车道变换决策方法(公开号:cn113954837a)等,但这些决策方法均面向高速公路场景。
5.不同于交通参与者类型较少的高速公路场景,城市交通环境具有开放、多交通目标干扰、机非混行等特点。特别是车辆视觉盲区、突遇障碍物等因素的存在,对城市交通环境下的营运车辆安全驾驶提出了更高的挑战。因此,面向高速公路场景的营运车辆安全驾驶决策方法,无法直接应用于开放干扰的城市交通环境。
6.总体而言,针对开放、多交通目标干扰的城市交通环境,现有的方法难以满足营运车辆对于安全驾驶决策的要求,尚缺乏能够提供驾驶动作、行车路径等具体驾驶建议的安全驾驶决策方法,特别是缺乏考虑视觉盲区和突遇障碍物影响的大型营运车辆安全驾驶决策研究。
技术实现要素:
7.发明目的:为了实现城市低速环境下的大型营运车辆安全驾驶决策,保障车辆行车安全,本发明针对重型货车、重型卡车等自动驾驶营运车辆,提出了一种城市低速环境下的大型营运车辆安全驾驶决策方法。该方法综合考虑了视觉盲区、突遇障碍物、不同行驶工况等因素对行车安全的影响,且能够模拟人类驾驶员的安全驾驶行为,为自动驾驶营运车辆提供更加合理、安全的驾驶策略,可以有效保障自动驾驶营运车辆的行车安全。同时,该方法无需考虑复杂的车辆动力学方程和车身参数,计算方法简单清晰,可以实时输出自动驾驶营运车辆的安全驾驶策略,且使用的传感器成本较低,便于大规模推广。
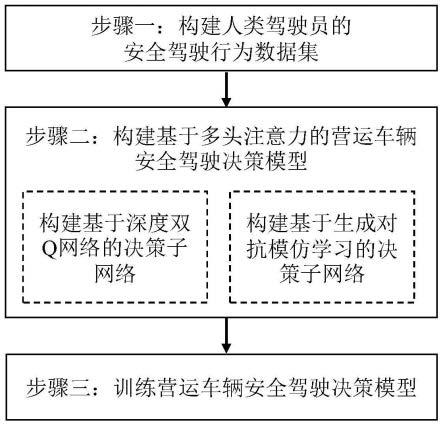
8.技术方案:为实现本发明的目的,本发明所采用的技术方案是:城市低速环境下的大型营运车辆安全驾驶决策方法。首先,采集城市交通环境下人类驾驶员的安全驾驶行为,构建形成安全驾驶行为数据集。其次,构建基于多头注意力的营运车辆安全驾驶决策模型。该模型包含深度双q网络和生成对抗模仿学习两个子网络。其中,深度双q网络通过无监督学习的方式,学习危险场景、冲突场景等边缘场景下的安全驾驶策略;生成对抗模仿学习子网络模仿不同驾驶条件和行驶工况下的安全驾驶行为。最后,训练安全驾驶决策模型,得到不同驾驶条件和行驶工况下的驾驶策略,实现对营运车辆安全驾驶行为的高级决策输出。具体包括以下步骤:
9.步骤一:采集城市交通环境下人类驾驶员的安全驾驶行为
10.为了实现与人类驾驶员相媲美的驾驶决策,本发明通过实际道路测试和驾驶模拟仿真的方式,采集不同驾驶条件和行驶工况下的安全驾驶行为,进而构建表征人类驾驶员安全驾驶行为的数据集。具体包括以下4个子步骤:
11.子步骤1:利用毫米波雷达、128线激光雷达、视觉传感器、北斗传感器和惯性传感器搭建多维目标信息同步采集系统。
12.子步骤2:在真实城市环境下,多名驾驶员依次驾驶搭载多维目标信息同步采集系统的营运车辆,对驾驶员的车道变换、车道保持、车辆跟驰、加减速等各种驾驶行为的相关数据进行采集和处理,获取各驾驶行为的多源异质描述数据,如雷达或视觉传感器测得多个不同方位的障碍物距离,北斗传感器及惯性传感器测得的位置、速度、加速度及横摆角速度等,以及车载传感器测得的方向盘转角等。
13.子步骤3:为了模仿危险场景、冲突场景等边缘场景下的安全驾驶行为,搭建基于硬件在环仿真的虚拟城市场景,所构建的城市交通场景包括以下三类:
14.(1)在车辆行驶过程中,车辆前方会出现横向接近的交通参与者(即突遇障碍物);
15.(2)在车辆转向过程中,车辆的视觉盲区内存在静止的交通参与者;
16.(3)在车辆转向过程中,车辆的视觉盲区内存在运动的交通参与者。
17.在上述交通场景中,存在多种路网结构(直道、弯道和十字路口)和多类交通参与者(营运车辆、乘用车、非机动车和行人)。
18.多名驾驶员通过真实控制器(方向盘、油门和制动踏板)驾驶虚拟场景中的营运车辆,采集自车的横纵向位置、横纵向速度、横纵向加速度、与周围交通参与者的相对距离和相对速度等信息。
19.子步骤4:基于真实城市环境和驾驶模拟仿真环境采集的数据,构建形成用于安全驾驶决策学习的驾驶行为数据集,具体可表示为:
[0020][0021]
式中,x表示涵盖状态、动作的二元组,即构建的表征人类驾驶员安全驾驶行为的数据集,(sj,aj)表示j时刻的“状态-动作”对,其中,sj表示j时刻的状态,aj表示j时刻的动作,即人类驾驶员基于状态sj做出的动作,n表示数据库中“状态-动作”对的数量。
[0022]
步骤二:构建基于多头注意力的营运车辆安全驾驶决策模型
[0023]
为了实现城市低速环境下的大型营运车辆安全驾驶决策,本发明综合考虑视觉盲区、突遇障碍物、行驶工况等因素对行车安全的影响,建立营运车辆安全驾驶决策模型。考虑到深度强化学习将深度学习的感知能力和强化学习的决策能力相结合,通过无监督学习的方式对交通环境进行探索,本发明利用深度强化学习对危险场景、冲突场景等边缘场景下的安全驾驶策略进行学习。此外,考虑到模仿学习具有仿效榜样的能力,本发明利用模仿学习模拟人类驾驶员在不同驾驶条件和行驶工况下的安全驾驶行为。因此,构建的安全驾驶决策模型由两部分组成,具体描述如下:
[0024]
子步骤1:定义安全驾驶决策模型的基本参数
[0025]
首先,将城市低速环境下的安全驾驶决策问题转化为有限马尔科夫决策过程。其次,定义安全驾驶决策模型的基本参数。
[0026]
(1)定义状态空间
[0027]
为了描述自车和附近交通参与者的运动状态,本发明利用时间序列数据和占据栅格图构建状态空间。具体描述如下:
[0028]st
=[s1(t),s2(t),s3(t)]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0029]
式中,s
t
表示t时刻的状态空间,s1(t)和s2(t)表示t时刻与时间序列数据相关的状态空间,s3(t)表示t时刻与占据栅格图相关的状态空间。
[0030]
首先,利用连续位置、速度、加速度和航向角信息描述自车的运动状态:
[0031]
s1(t)=[p
x
,py,v
x
,vy,a
x
,ay,θs]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0032]
式中,p
x
,py分别表示自车的横向位置和纵向位置,单位为米,v
x
,vy分别表示自车的横向速度和纵向速度,单位为米每秒,a
x
,ay分别表示自车的横向加速度和纵向加速度,单位为米每二次方秒,θs表示自车的航向角,单位为度。
[0033]
其次,利用自车与周围交通参与者的相对运动状态信息描述周围交通参与者的运动状态:
[0034][0035]
式中,分别表示自车与第i个交通参与者的相对距离、相对速度和加速度,单位分别为米、米每秒和米每二次方秒。
[0036]
现有的状态空间定义方法中,常使用固定的编码方法,即考虑的周围交通参与者的数量是固定的。然而,在实际的城市交通场景中,营运车辆周围的交通参与者数量和位置是时刻变化的,且需要特别考虑突遇障碍物和视觉盲区导致的侧向碰撞。虽然固定编码的方法可以实现有效的状态表征,但考虑的交通参与者数量有限(使用了表示场景所需的最少信息量),无法准确、全面地描述周围所有交通参与者对营运车辆行车安全的影响。
[0037]
最后,为了更加形象地描述自车与周围交通参与者的相对位置关系,提高决策的可靠性和有效性,本发明将道路区域栅格化,划分成若干个a
×
b的网格区域,将道路区域及
车辆目标抽象成栅格图,即用于描述相对位置关系的“存在”栅格图s3(t)。其中,a表示网格区域的长度,b表示网格区域的宽度。
[0038]“存在”栅格图包含四种属性,包括栅格坐标、是否存在车辆、对应车辆的类别、与左右车道线的距离。其中,不存在交通参与者的网格置为“0”,存在交通参与者的网格置为“1”,该网格与自车所在网格的位置分布,用于描述两车的相对间距。
[0039]
(2)定义动作空间
[0040]
利用横向和纵向驾驶动作定义动作空间:
[0041]at
=[a
left
,a
straight
,a
right
,a
accel
,a
cons
,a
decel
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0042]
式中,a
t
表示t时刻的动作空间,a
left
,a
straight
,a
right
分别表示左转、直行和右转,a
accel
,a
cons
,a
decel
分别表示加速、匀速和减速。
[0043]
(3)定义奖励函数
[0044]rt
=r1+r2+r3ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0045]
式中,r
t
表示t时刻的奖励函数,r1,r2,r3分别表示前向防撞奖励函数、后向防撞奖励函数和侧向防撞奖励函数,可通过式(7)、式(8)和式(9)获得。
[0046][0047][0048][0049]
式中,ttc表示自车与前方障碍物发生碰撞的时间,可通过自车与前方障碍物之间的距离除以相对速度获得,ttc
thr
表示距离碰撞时间阈值,rttc表示后向碰撞时间,rttc
thr
表示后向碰撞时间阈值,单位均为秒,x
lat
表示自车与两侧交通参与者的距离,x
min
表示最小侧向安全距离,单位均为米,β1,β2,β3分别表示前向防撞奖励函数、后向防撞奖励函数和侧向防撞奖励函数的权重系数。
[0050]
子步骤2:构建基于深度双q网络的决策子网络
[0051]
考虑到深度双q网络(double deep q network,ddqn)通过使用经验复用池的方式,提高了数据的利用效率,且能够避免参数振荡或发散,可以降低q学习网络中因过估计导致负面的学习效果。因此,本发明利用深度双q网络学习边缘场景下的安全驾驶策略。
[0052]
不同于处理固定维度的状态空间,处理涵盖周围所有交通参与者的特征信息,需具有更强的特征提取能力。考虑到注意力机制可以捕捉到更加丰富的特征信息(自车与周围各交通参与者之间的依赖关系),本发明设计了基于多头注意力机制的策略网络。此外,考虑到驾驶决策只与自车、周围交通参与者的运动状态有关,不应受状态空间中各交通参与者的顺序影响,本发明利用位置编码方法(文献:vaswani,ashish,et al.“attention is all you need.”advances in neural information processing systems.2017.),将排列不变性构建到决策子网络中。
[0053]
注意力层可表示为:
[0054]
multihead(q,k,v)=concat(head1,...,headh)woꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0055]
式中,multihead(q,k,v)表示多头注意力值,q表示查询向量,k表示键向量,维度均为dk,v表示值向量,维度为dv,wo表示需要学习的参数矩阵,headh表示多头注意力中的第h个头,在本发明中,h=2,可通过下式计算:
相连,得到特征f6。然后,将特征f4、f5和f6依次与合并层、全连接层fc
10
、sigmoid激活函数相连,得到输出
[0071]
其中,全连接层fc6、fc7、fc8、fc9和fc
10
的神经元数量均为64,卷积层c3的卷积核为3
×
3,步长为2,卷积层c4的卷积核为3
×
3,步长为1。
[0072]
步骤三:训练营运车辆安全驾驶决策模型
[0073]
首先,训练基于生成对抗模仿学习的决策子网络。生成对抗模仿学习子网络的目标是学习一个生成器网络,使得判别器无法区分生成器生成的驾驶动作与驾驶行为数据集中的动作。具体包括以下几个子步骤:
[0074]
子步骤1:在驾驶行为数据集中,初始化生成器网络参数θ0和判别器网络参数ω0;
[0075]
子步骤2:进行l次迭代求解,每一次迭代包括子步骤2.1至2.2,具体地:
[0076]
子步骤2.1:利用式(13)描述的梯度公式更新判别器参数ωi→
ω
i+1
:
[0077][0078]
式中,表示参数为ω的神经网络损失函数的梯度函数;
[0079]
子步骤2.2:设置奖励函数利用信赖域策略优化算法更新生成器参数θi→
θ
i+1
。
[0080]
首先,在上述网络训练结果的基础上,继续训练构建基于ddqn的决策子网络,具体包括以下几个子步骤:
[0081]
子步骤3:初始化经验复用池d的容量为n;
[0082]
子步骤4:初始化动作对应的q值为随机值;
[0083]
子步骤5:进行m次迭代求解,每一次迭代包括子步骤5.1至5.2,具体地:
[0084]
子步骤5.1:初始化状态s0,初始化策略参数φ0;
[0085]
子步骤5.2:进行t次迭代求解,每一次迭代包括子步骤5.21至5.27,具体地:
[0086]
子步骤5.21:随机选择一个驾驶动作;
[0087]
子步骤5.22:否则选择a
t
=maxaq
*
(φ(s
t
),a;θ);
[0088]
式中,q
*
(
·
)表示最优的动作价值函数,a
t
表示t时刻的动作;
[0089]
子步骤5.23:执行动作a
t
,获得t时刻的奖励值r
t
和t+1时刻的状态s
t+1
;
[0090]
子步骤5.24:在经验复用池d中存储样本(φ
t
,a
t
,r
t
,φ
t+1
);
[0091]
子步骤5.25:从经验复用池d中随机抽取小批量的样本(φj,aj,rj,φ
j+1
);
[0092]
子步骤5.26:利用下式计算迭代目标:
[0093][0094]
式中,表示t时刻目标网络的权重;γ表示折扣因子;argmax(
·
)表示使目标函数具有最大值的变量,yi表示i时刻的迭代目标,p(s,a)表示动作分布;
[0095]
子步骤5.27:利用下式在(y
i-q(φj,aj;θ))2上进行梯度下降:
[0096][0097]
式中,表示参数为θi的神经网络损失函数的梯度函数,ε表示在ε-greedy探索策略下,随机选择一个行为的概率;θi表示i时刻迭代的参数,li(θi)表示i时刻的损失函数,q(s,a;θi)表示目标网络的动作价值函数,a
′
表示状态s
′
所有可能存在的动作。
[0098]
当营运车辆安全驾驶决策模型训练完成后,将传感器采集的状态空间信息输入到安全驾驶决策模型中,可以实时地输出转向、直行、加减速等高级驾驶决策,能够有效保障城市低速环境下的营运车辆运行安全。
[0099]
有益效果:相比于一般的驾驶决策方法,本发明提出的方法具有更为有效、可靠的特点,具体体现在:
[0100]
(1)本发明提出的方法能够模拟人类驾驶员的安全驾驶行为,为城市低速环境下的营运车辆提供更加合理、安全的驾驶策略,实现了具有高度类人水平的大型营运车辆安全驾驶决策,可以有效保障车辆的行车安全。
[0101]
(2)本发明提出的方法综合考虑了视觉盲区、突遇障碍物、不同行驶工况等因素对行车安全的影响,并正常驾驶场景和边缘场景下进行策略学习和训练,进一步提高了驾驶决策的有效性和可靠性。
[0102]
(3)本发明提出的方法引入了多头注意力机制,考虑了自车与周围各交通参与者之间的动态交互,且能够处理输入可变(周围交通参与者数量动态变化)的安全驾驶决策.
[0103]
(4)本发明提出的方法无需考虑复杂的车辆动力学方程和车身参数,计算方法简单清晰,可以实时输出大型营运车辆的安全驾驶决策策略,且使用的传感器成本较低,便于大规模推广。
附图说明
[0104]
图1是本发明的技术路线图;
[0105]
图2是本发明设计的基于多头注意力机制的策略网络结构示意图;
[0106]
图3是本发明设计的生成器网络结构示意图;
[0107]
图4是本发明设计的判别器网络结构示意图。
具体实施方式
[0108]
下面结合附图和实施例对本发明的技术方案作进一步的说明。
[0109]
本发明针对开放、多交通目标干扰的城市交通环境,提出了一种具有高度类人水平的大型营运车辆安全驾驶决策方法。首先,采集城市交通环境下人类驾驶员的安全驾驶行为,构建形成安全驾驶行为数据集。其次,构建基于多头注意力的营运车辆安全驾驶决策模型。该模型包含深度双q网络和生成对抗模仿学习两个子网络。其中,深度双q网络通过无监督学习的方式,学习危险场景、冲突场景等边缘场景下的安全驾驶策略;生成对抗模仿学习子网络模仿不同驾驶条件和行驶工况下的安全驾驶行为。最后,训练安全驾驶决策模型,得到不同驾驶条件和行驶工况下的驾驶策略,实现对营运车辆安全驾驶行为的高级决策输出。本发明提出的方法,能够模拟人类驾驶员的安全驾驶行为,且考虑了视觉盲区、突遇障碍物等因素对行车安全的影响,为大型营运车辆提供更加合理、安全的驾驶策略,实现了城
市交通环境下的营运车辆安全驾驶决策。本发明的技术路线如图1所示,具体步骤如下:
[0110]
步骤一:采集城市交通环境下人类驾驶员的安全驾驶行为
[0111]
为了实现与人类驾驶员相媲美的驾驶决策,本发明通过实际道路测试和驾驶模拟仿真的方式,采集不同驾驶条件和行驶工况下的安全驾驶行为,进而构建表征人类驾驶员安全驾驶行为的数据集。具体包括以下5个子步骤:
[0112]
子步骤1:利用毫米波雷达、128线激光雷达、视觉传感器、北斗传感器和惯性传感器搭建多维目标信息同步采集系统。
[0113]
子步骤2:在真实城市环境下,多名驾驶员依次驾驶搭载多维目标信息同步采集系统的营运车辆。
[0114]
子步骤3:对驾驶员的车道变换、车道保持、车辆跟驰、加减速等各种驾驶行为的相关数据进行采集和处理,获取各驾驶行为的多源异质描述数据,如雷达或视觉传感器测得多个不同方位的障碍物距离,北斗传感器及惯性传感器测得的位置、速度、加速度及横摆角速度等,以及车载传感器测得的方向盘转角等。
[0115]
子步骤4:为了模仿危险场景、冲突场景等边缘场景下的安全驾驶行为,搭建基于硬件在环仿真的虚拟城市场景,所构建的城市交通场景包括以下三类:
[0116]
(1)在车辆行驶过程中,车辆前方会出现横向接近的交通参与者(即突遇障碍物);
[0117]
(2)在车辆转向过程中,车辆的视觉盲区内存在静止的交通参与者;
[0118]
(3)在车辆转向过程中,车辆的视觉盲区内存在运动的交通参与者。
[0119]
在上述交通场景中,存在多种路网结构(直道、弯道和十字路口)和多类交通参与者(营运车辆、乘用车、非机动车和行人)。
[0120]
多名驾驶员通过真实控制器(方向盘、油门和制动踏板)驾驶虚拟场景中的营运车辆,采集自车的横纵向位置、横纵向速度、横纵向加速度、与周围交通参与者的相对距离和相对速度等信息。
[0121]
子步骤5:基于真实城市环境和驾驶模拟仿真环境采集的数据,构建形成用于安全驾驶决策学习的驾驶行为数据集,具体可表示为:
[0122][0123]
式中,x表示涵盖状态、动作的二元组,即构建的表征人类驾驶员安全驾驶行为的数据集,(sj,aj)表示j时刻的“状态-动作”对,其中,sj表示j时刻的状态,aj表示j时刻的动作,即人类驾驶员基于状态sj做出的动作,n表示数据库中“状态-动作”对的数量。
[0124]
步骤二:构建基于多头注意力的营运车辆安全驾驶决策模型
[0125]
为了实现城市低速环境下的大型营运车辆安全驾驶决策,本发明综合考虑视觉盲区、突遇障碍物、行驶工况等因素对行车安全的影响,建立营运车辆安全驾驶决策模型。考虑到深度强化学习将深度学习的感知能力和强化学习的决策能力相结合,通过无监督学习的方式对交通环境进行探索,本发明利用深度强化学习对危险场景、冲突场景等边缘场景下的安全驾驶策略进行学习。此外,考虑到模仿学习具有仿效榜样的能力,本发明利用模仿学习模拟人类驾驶员在不同驾驶条件和行驶工况下的安全驾驶行为。因此,构建的安全驾驶决策模型由两部分组成,具体描述如下:
[0126]
子步骤1:定义安全驾驶决策模型的基本参数
[0127]
首先,将城市低速环境下的安全驾驶决策问题转化为有限马尔科夫决策过程。其次,定义安全驾驶决策模型的基本参数。
[0128]
(1)定义状态空间
[0129]
为了描述自车和附近交通参与者的运动状态,本发明利用时间序列数据和占据栅格图构建状态空间。具体描述如下:
[0130]st
=[s1(t),s2(t),s3(t)]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0131]
式中,s
t
表示t时刻的状态空间,s1(t)和s2(t)表示t时刻与时间序列数据相关的状态空间,s3(t)表示t时刻与占据栅格图相关的状态空间。
[0132]
首先,利用连续位置、速度、加速度和航向角信息描述自车的运动状态:
[0133]
s1(t)=[p
x
,py,v
x
,vy,a
x
,ay,θs]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0134]
式中,p
x
,py分别表示自车的横向位置和纵向位置,单位为米,v
x
,vy分别表示自车的横向速度和纵向速度,单位为米每秒,a
x
,ay分别表示自车的横向加速度和纵向加速度,单位为米每二次方秒,θs表示自车的航向角,单位为度。
[0135]
其次,利用自车与周围交通参与者的相对运动状态信息描述周围交通参与者的运动状态:
[0136][0137]
式中,分别表示自车与第i个交通参与者的相对距离、相对速度和加速度,单位分别为米、米每秒和米每二次方秒。
[0138]
现有的状态空间定义方法中,常使用固定的编码方法,即考虑的周围交通参与者的数量是固定的。然而,在实际的城市交通场景中,营运车辆周围的交通参与者数量和位置是时刻变化的,且需要特别考虑突遇障碍物和视觉盲区导致的侧向碰撞。虽然固定编码的方法可以实现有效的状态表征,但考虑的交通参与者数量有限(使用了表示场景所需的最少信息量),无法准确、全面地描述周围所有交通参与者对营运车辆行车安全的影响。
[0139]
最后,为了更加形象地描述自车与周围交通参与者的相对位置关系,提高决策的可靠性和有效性,本发明将道路区域栅格化,划分成若干个a
×
b的网格区域,将道路区域及车辆目标抽象成栅格图,即用于描述相对位置关系的“存在”栅格图s3(t)。其中,a表示网格区域的长度,b表示网格区域的宽度。
[0140]“存在”栅格图包含四种属性,包括栅格坐标、是否存在车辆、对应车辆的类别、与左右车道线的距离。其中,不存在交通参与者的网格置为“0”,存在交通参与者的网格置为“1”,该网格与自车所在网格的位置分布,用于描述两车的相对间距。
[0141]
(2)定义动作空间
[0142]
利用横向和纵向驾驶动作定义动作空间:
[0143]at
=[a
left
,a
straight
,a
right
,a
accel
,a
cons
,a
decel
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0144]
式中,a
t
表示t时刻的动作空间,a
left
,a
straight
,a
right
分别表示左转、直行和右转,a
accel
,a
cons
,a
decel
分别表示加速、匀速和减速。
[0145]
(3)定义奖励函数
[0146]rt
=r1+r2+r3ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0147]
式中,r
t
表示t时刻的奖励函数,r1,r2,r3分别表示前向防撞奖励函数、后向防撞奖
励函数和侧向防撞奖励函数,可通过式(7)、式(8)和式(9)获得。
[0148][0149][0150][0151]
式中,ttc表示自车与前方障碍物发生碰撞的时间,可通过自车与前方障碍物之间的距离除以相对速度获得,ttc
thr
表示距离碰撞时间阈值,rttc表示后向碰撞时间,rttc
thr
表示后向碰撞时间阈值,单位均为秒,x
lat
表示自车与两侧交通参与者的距离,x
min
表示最小侧向安全距离,单位均为米,β1,β2,β3分别表示前向防撞奖励函数、后向防撞奖励函数和侧向防撞奖励函数的权重系数。
[0152]
子步骤2:构建基于ddqn的决策子网络
[0153]
考虑到深度双q网络(double deep q network,ddqn)通过使用经验复用池的方式,提高了数据的利用效率,且能够避免参数振荡或发散,可以降低q学习网络中因过估计导致负面的学习效果。因此,本发明利用深度双q网络学习边缘场景下的安全驾驶策略。
[0154]
不同于处理固定维度的状态空间,处理涵盖周围所有交通参与者的特征信息,需具有更强的特征提取能力。考虑到注意力机制可以捕捉到更加丰富的特征信息(自车与周围各交通参与者之间的依赖关系),本发明设计了基于多头注意力机制的策略网络。此外,考虑到驾驶决策只与自车、周围交通参与者的运动状态有关,不应受状态空间中各交通参与者的顺序影响,本发明利用位置编码方法(文献:vaswani,ashish,et al.“attention is all you need.”advances in neural information processing systems.2017.),将排列不变性构建到决策子网络中。
[0155]
注意力层可表示为:
[0156]
multihead(q,k,v)=concat(head1,...,headh)woꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0157]
式中,multihead(q,k,v)表示多头注意力值,q表示查询向量,k表示键向量,维度均为dk,v表示值向量,维度为dv,wo表示需要学习的参数矩阵,headh表示多头注意力中的第h个头,在本发明中,h=2,可通过下式计算:
[0158][0159][0160]
式中,attention(q,k,v)表示输出的注意力矩阵,表示需要学习的参数矩阵。
[0161]
构建基于深度双q网络的决策子网络,如图2所示,具体描述如下。
[0162]
首先,状态空间s
t
分别与编码器1、编码器2和编码器3相连。编码器1由两个全连接层组成,输出自车运动状态编码。编码器2的结构与编码器1相同,输出相对运动状态编码。编码器3由两个卷积层组成,输出占据栅格图编码。
[0163]
其中,全连接层的神经元数量均为64,激活函数均为tanh函数。卷积层的卷积核均为3
×
3,步长均为2。
[0164]
其次,利用多头注意力机制分析自车与周围交通参与者的依赖关系,使得决策子
网络能够注意到突然靠近自车或与自车行驶路径冲突的交通参与者,并将不同的输入大小和排列不变性构建到决策子网络中。编码器1、编码器2和编码器3的输出均与多头注意力模块连接,输出注意力矩阵。再次,将输出的注意力矩阵与解码器1相连。编码器1由一个全连接层组成。
[0165]
其中,全连接层的神经元数量为64,激活函数为sigmoid函数。
[0166]
子步骤3:构建基于生成对抗模仿学习的决策子网络
[0167]
在开放、多交通目标干扰的复杂城市交通环境下,很难构建一个准确、全面的奖励函数,特别是难以定量描述多种不确定性(如突遇障碍物、视觉盲区内的交通参与者等)对行车安全的影响。为了减小安全驾驶决策受交通环境和行驶工况不确定性的影响,提高驾驶决策的有效性和可靠性,本发明利用生成对抗模仿学习子网络,学习驾驶行为数据集及其泛化的样本数据中的驾驶策略,进而模仿不同驾驶条件和行驶工况下的安全驾驶行为。生成对抗模仿学习子网络由生成器和判别器两部分组成,分别利用深度神经网络构建生成器网络和判别器网络。具体描述如下:
[0168]
(1)构建生成器
[0169]
构建如图3所示的生成器网络。生成器的输入是状态空间,输出是动作空间中各个动作的概率值f=π(
·
|s;θ),其中,θ表示生成器网络的参数。首先,状态空间依次与全连接层fc1和fc2相连,得到特征f1。状态空间依次与全连接层fc3和fc4,得到特征f2。同时,状态空间依次与卷积层c1和卷积层c2相连,得到特征f3。然后,将特征f1、f2和f3依次与合并层、全连接层fc5、softmax激活函数相连,得到输出f=π(
·
|s;θ)。
[0170]
其中,全连接层fc1、fc2、fc3、fc4和fc5的神经元数量均为64,卷积层c1的卷积核为3
×
3,步长为2,卷积层c2的卷积核为3
×
3,步长为1。
[0171]
(2)构建判别器
[0172]
构建如图4所示的判别器网络。判别器的输入是状态空间,输出是向量维度为6,其中,φ表示判别器网络的参数。首先,状态空间依次与全连接层fc6和fc7相连,得到特征f4。状态空间依次与全连接层fc8和fc9,得到特征f5。同时,状态空间依次与卷积层c3和卷积层c4相连,得到特征f6。然后,将特征f4、f5和f6依次与合并层、全连接层fc
10
、sigmoid激活函数相连,得到输出
[0173]
其中,全连接层fc6、fc7、fc8、fc9和fc
10
的神经元数量均为64,卷积层c3的卷积核为3
×
3,步长为2,卷积层c4的卷积核为3
×
3,步长为1。
[0174]
步骤三:训练营运车辆安全驾驶决策模型
[0175]
首先,训练基于生成对抗模仿学习的决策子网络。生成对抗模仿学习子网络的目标是学习一个生成器网络,使得判别器无法区分生成器生成的驾驶动作与驾驶行为数据集中的动作。具体包括以下几个子步骤:
[0176]
子步骤1:在驾驶行为数据集中,初始化生成器网络参数θ0和判别器网络参数ω0;
[0177]
子步骤2:进行l次迭代求解,每一次迭代包括子步骤2.1至2.2,具体地:
[0178]
子步骤2.1:利用式(13)描述的梯度公式更新判别器参数ωi→
ω
i+1
:
[0179][0180]
式中,表示参数为ω的神经网络损失函数的梯度函数;
[0181]
子步骤2.2:设置奖励函数利用信赖域策略优化算法更新生成器参数θi→
θ
i+1
。
[0182]
首先,在上述网络训练结果的基础上,继续训练构建基于ddqn的决策子网络,具体包括以下几个子步骤:
[0183]
子步骤3:初始化经验复用池d的容量为n;
[0184]
子步骤4:初始化动作对应的q值为随机值;
[0185]
子步骤5:进行m次迭代求解,每一次迭代包括子步骤5.1至5.2,具体地:
[0186]
子步骤5.1:初始化状态s0,初始化策略参数φ0;
[0187]
子步骤5.2:进行t次迭代求解,每一次迭代包括子步骤5.21至5.27,具体地:
[0188]
子步骤5.21:随机选择一个驾驶动作;
[0189]
子步骤5.22:否则选择a
t
=maxaq
*
(φ(s
t
),a;θ);
[0190]
式中,q
*
(
·
)表示最优的动作价值函数,a
t
表示t时刻的动作;
[0191]
子步骤5.23:执行动作a
t
,获得t时刻的奖励值r
t
和t+1时刻的状态s
t+1
;
[0192]
子步骤5.24:在经验复用池d中存储样本(φ
t
,a
t
,r
t
,φ
t+1
);
[0193]
子步骤5.25:从经验复用池d中随机抽取小批量的样本(φj,aj,rj,φ
j+1
);
[0194]
子步骤5.26:利用下式计算迭代目标:
[0195][0196]
式中,表示t时刻目标网络的权重;γ表示折扣因子;argmax(
·
)表示使目标函数具有最大值的变量,yi表示i时刻的迭代目标,p(s,a)表示动作分布;
[0197]
子步骤5.27:利用下式在(y
i-q(φj,aj;θ))2上进行梯度下降:
[0198][0199]
式中,表示参数为θi的神经网络损失函数的梯度函数,ε表示在ε-greedy探索策略下,随机选择一个行为的概率;θi表示i时刻迭代的参数,li(θi)表示i时刻的损失函数,q(s,a;θi)表示目标网络的动作价值函数,a
′
表示状态s
′
所有可能存在的动作。
[0200]
当营运车辆安全驾驶决策模型训练完成后,将传感器采集的状态空间信息输入到安全驾驶决策模型中,可以实时地输出转向、直行、加减速等高级驾驶决策,能够有效保障城市低速环境下的营运车辆运行安全。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1