一种基于经验池迁移的燃料电池汽车深度强化学习能量管理方法
本发明属于燃料电池混合动力能量管理领域,尤其涉及一种基于经验池迁移的燃料电池汽车深度强化学习能量管理方法。
背景技术:
1、由于全球石油储量不断减少,以及全球各地日益严格的排放规定,迫切需要生产更多的节能汽车。质子交换膜燃料电池(pemfc)是商用车最有前途的选择之一。燃料电池汽车将燃料中的自由能量直接转化为电能,具有行驶里程长、充电周期短的优点。但是单独的pemfc往往无法满足汽车行驶的需要,需要和电池/超级电容混合使用,这使得燃料电池混合动力汽车具有多种输入能量来源和工作模式。为了发挥燃料电池和动力电池的各自优势,实现燃料电池混合动力汽车高效的能量管理至关重要。
2、目前,混合动力车辆能量管理算法主要可以分为三个大类:基于规则的策略、基于优化的策略和基于学习的策略。基于规则的策略计算量小,在工程实践中应用广泛,但其过于依赖于工程师经验,且对不同驾驶工况和车型的可移植性差。基于优化的策略可分为全局优化和实时优化,前者不适合应用在实时控制的场景,后者仍依赖于未来工况信息等先验知识和参数的调节,且易于陷入局部最优。
3、目前深度强化学习在燃料电池能量管理方面是一种较有潜力的机器学习方法,然而现有技术中的方法存在一些缺点,这类能量管理策略研究基本集中于对某一特定车型的特定目标的案例研究,难以适应其它车型,同时所需训练时间较长。所以为了加速混合动力汽车能量管理策略的开发,提高训练效率,减少成本,能量管理策略的可移植性对新能源汽车的发展具有重要意义。
技术实现思路
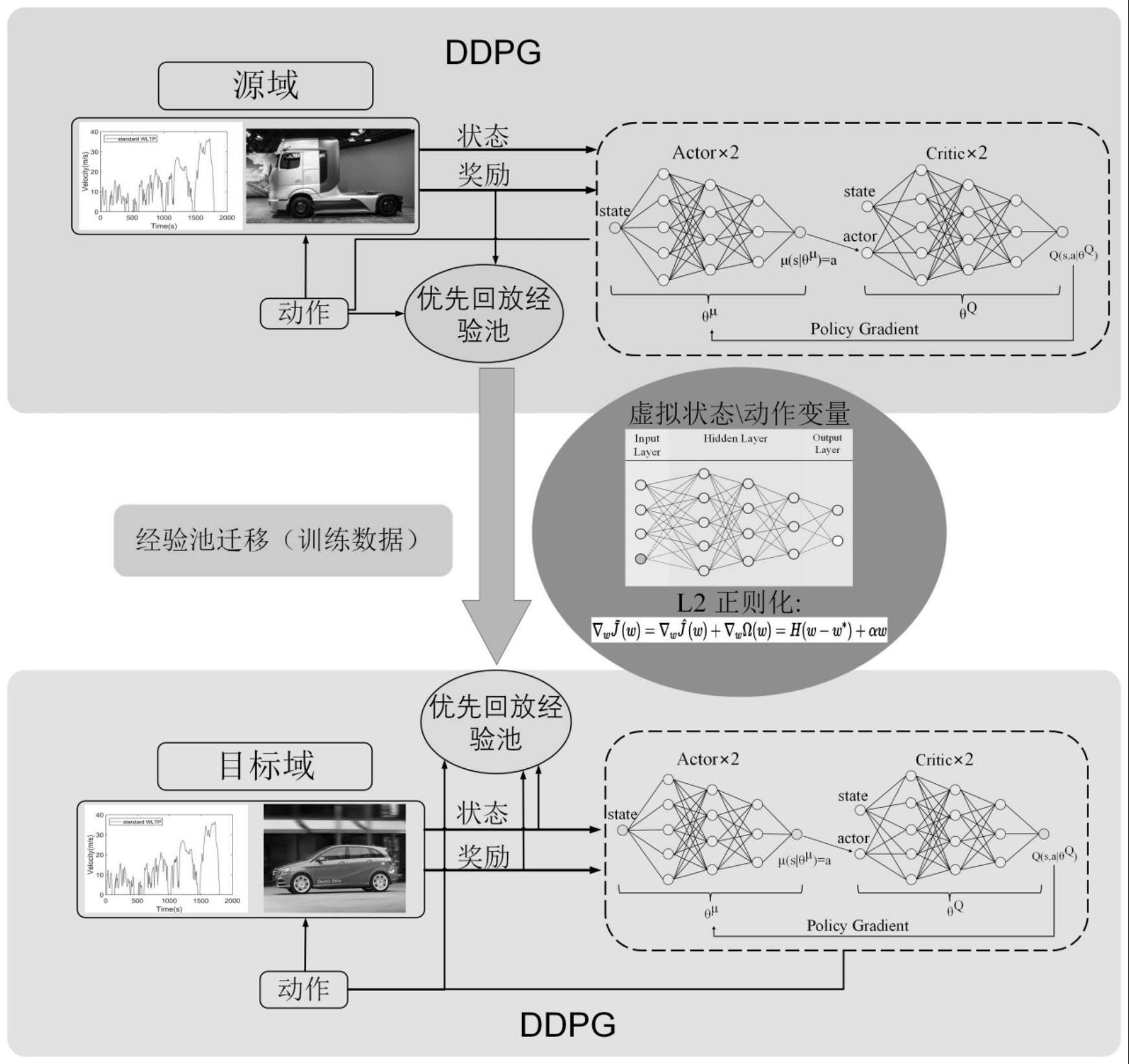
1、本发明提供了一种基于经验池迁移的燃料电池汽车深度强化学习能量管理方法,能够通过经验池迁移方法有效利用其他车型车辆的能量管理的训练数据集,加速车辆能量管理经验池的开发速度,而且可以提升汽车燃油经济性和在不同工况下的泛化性能。
2、为了实现以上目的,本发明采用以下技术方案:
3、一种基于经验池迁移的燃料电池汽车深度强化学习能量管理方法,包括以下步骤:
4、步骤1:模拟实际开发情况,建立两种显著不同的燃料电池汽车模型分别作为源域和目标域;
5、步骤2:建立基于经验池迁移的ddpg代理模型,设置ddpg代理模型的状态、动作和奖励,得到设置后的ddpg代理模型;
6、步骤3:针对目标域车型,训练ddpg代理模型,获取训练后ddpg代理模型的经验池;
7、步骤4:迁移源域车型经验池至目标域车型上,继续训练ddpg代理模型,获取基于经验池迁移的ddpg代理模型;
8、步骤5:利用最终训练完成的ddpg代理进行新车型的能量管理。
9、以上所述步骤中,步骤1中所述两种显著不同的燃料电池汽车模型分别为以燃料电池/电池/超级电容的物流卡车与以燃料电池/电池的b级轿车,前者作为源域,后者作为目标域,两个模型均包括汽车动力学模型、燃料电池以及电机和电池,不同的是物流卡车模型还包含了超级电容;
10、所述汽车动力学模型如下公式所示:
11、
12、其中,v为车辆的速度;f为滚动电阻系数;cd为气动阻力系数;a为车辆前部区域;ρ为空气密度;a为物流车辆的加速度;α是道路的坡度;m是车辆质量;
13、所述燃料电池模型采用amphlett静态模型进行描述,过电位损耗由激活过电位vact、欧姆过电位vohm和浓度过电位vcon三部分组成,其计算公式为:
14、
15、其中ξ1,ξ2,ξ3,ξ4和b是由制造商提供的预校准系数;t是温度;ist是当前堆栈值;是阴极催化剂层的氧浓度;rst为堆叠的等效电阻;j和jmax分别表示电流密度的实际极限和最大极限;
16、所述电机模型如下公式所示:
17、
18、ηm=lut(tmot,ωmot)
19、其中,preq是牵引功率;pmot是燃料电池和锂离子电池提供的电机功率;tmot和ωmot分别为电机的转矩和转速;lut代表采用查表法,利用tmot和ωmot的实验数据确定效率ηm;
20、所述电池模型如下公式所示:
21、
22、式中,rbat、uref、voc、ibat、rint分别表示电池的开路电阻、额定电压、开路电压、电流、内阻;pbat为要求电池功率,放电功率为正值,充电功率为负值;ploss为损失功率;
23、所述超级电容模型如下公式所示:
24、
25、其中,n为单元的个数;qcell为每个单元的电量;socsc(tk)、socsc(tk-1)分别为超级电容瞬时soc变化、当前soc和上一时刻soc;isc为超级电容电流;
26、步骤2中所述基于经验池迁移的ddpg代理模型的状态量为:汽车车速v、汽车加速度acc、动力电池soc和超级电容soc;动作变量为燃料电池功率pfc和动力电池功率pbat,状态变量和动作变量设置如下所示:
27、
28、奖励函数被用于评价在当前状态下执行动作的表现性能,本发明中越小越好,为行驶成本c和soc惩罚项之和,奖励函数如下公式所示:
29、
30、其中,c为车辆行驶成本;β和γ为权重因子;socbat和socsc分别为动力电池soc和超级电容soc;socbat_ref和分别为动力电池soc和超级电容soc的参考值;
31、上述步骤中采用了一种虚拟变量的方法,以满足在迁移经验池时,两种车型车辆的ddpg代理模型的状态量、动作量必须相同的条件,此方法为b级轿车的状态量、动作量增加了一个虚拟维度,并用一个定值来替代原本的超级电容soc和动力电池功率pbat;
32、步骤3针对一种车型,训练ddpg代理模型,获取训练后ddpg代理模型的经验池,具体包括以下步骤:
33、步骤a:初始化所述设定后的ddpg代理模型;
34、步骤b:将初始化后的ddpg代理模型与驾驶循环和燃料电池汽车进行交互,得到训练数据集;
35、步骤c:使用训练数据集对ddpg代理模型进行训练,得到训练后的ddpg代理模型。
36、上述步骤a具体包括:用权重θq和θμ分别初始化ddpg代理模型中的当前actor网络参数与critic网络参数;用权重θq′和θμ′初始化目标actor网络参数与critic网络参数;累计梯度θqi′←θqi,θμ′←θμ,最终得到初始化后的ddpg代理模型;
37、上述步骤b将初始化后的ddpg代理模型与驾驶循环和燃料电池汽车进行交互,得到训练数据集,具体包括:当前神经网络与环境进行交互,将当前状态集合st={v,acc,socsc,socbat}t输入当前神经网络,根据当前策略π(st|θμ)得到动作at;为了更好的进行探索,控制信号at在拉普拉斯分布中随机采样获得,将当前动作at作用于燃料电池汽车得到当前回报rt以及下一时刻的状态集合st+1;最后,根据上述的相关数据st,at,rt和st+1,得到训练数据集(st,at,rt,st+1),用于神经网络的训练过程;
38、上述步骤c使用训练数据集对ddpg代理模型进行训练,得到训练后的ddpg代理模型,具体包括以下几个步骤:
39、步骤①:从优先经验回放集合d中采样m个样本,并计算当前目标q值,采用的公式为:
40、
41、其中,yi为当前目标q值,ri为当前奖励;si为当前状态;γ为衰减因子;qj′(s′,a′)为目标q值;
42、步骤②:通过均方差损失函数和l2正则更新critic网络,采用的公式为:
43、
44、其中,lk为总损失函数;m为采样的经验池大小;q(sj,aj)为当前q值;l2为l2正则损失函数;
45、步骤③:使用梯度策略更新actor策略,采用的公式为:
46、
47、其中,j是目标函数;θμ是当前actor网络参数;π表示策略;
48、步骤④:为所有采样的经验重新计算td-errorδi=yi-q(si,ai|θq),更新策略中各经验优先级;
49、步骤⑤:采用平滑的方式更新目标网络参数:
50、
51、其中,τ是软更新权重;θq、θqi′、θμ、θμ′分别代表当前critic网络、目标critic网络、当前actor网络、目标actor网络的参数;
52、步骤⑥:如此重复步骤①至步骤⑤,直至达到训练要求,最后得到训练后的物流轻型卡车ddpg代理模型。
53、上述步骤4迁移源域车型经验池至目标域车型上,继续训练ddpg代理模型,获取基于经验池迁移的ddpg代理模型,所述迁移源域车型经验池,其具体方法为,以一部分或者全部的源域训练完成的ddpg代理模型的经验池参数,替代目标域初始化后的经验池参数,具体迁移的网络层数可自由调整,在此基础上进行后续部分,步骤4的后续部分与步骤3相同;
54、上述步骤5利用最终训练完成的ddpg代理进行新车型的能量管理,具体包括以下步骤:
55、第一步:通过相关传感器获取目标域汽车当前状态量集合st={v,acc,socsc,socbat}t,其中socsc为设置好的虚拟变量;
56、第二步:将获取的汽车当前状态量集合st={v,acc,socsc,socbat}t输入训练后的基于迁移经验池的ddpg代理模型,进而输出控制量燃料电池功率pfc;
57、第三步:将所获得的控制量燃料电池功率pfc作用于汽车,驱动汽车行驶,进而得到下一时刻汽车状态量集合st+1={v,acc,socsc,socbat}t;
58、第四步:如此重复第一步至第三步,直至汽车完成行驶任务。
59、以上所述的基于经验池迁移的燃料电池车辆能量管理方法理论上是数据驱动和无模型的,对燃料电池混合动力系统的任何特定拓扑不敏感,可应用于各种复合电源燃料电池系统。
60、有益效果:本发明提供了一种基于经验池迁移的燃料电池汽车深度强化学习能量管理方法,为了模拟实际开发情况,建立两种显著不同的燃料电池汽车模型作为源域车型和目标域车型;通过在不同类型的燃料电池汽车之间迁移训练数据的方法,加速车辆能量管理策略的开发速度,同时可以提升汽车燃油经济性;本发明的方法可以有效解决能量管理策略只能针对某一特定车型的特定目标,难以适应其它车型,且所需训练时间长的问题,可以有效利用其他车型的车辆能量管理经验池,提高迁移后代理模型的训练收敛速度、汽车燃油经济性和算法鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!