一种基于驾驶员个性化的拟人变道轨迹优化方法
本发明涉及自动驾驶汽车行为决策,尤其是涉及一种基于驾驶员个性化的拟人变道轨迹优化方法。
背景技术:
1、自动驾驶是近年来学术界和业界广泛研究的热门话题。随着技术的发展,可以预见在未来,将有越来越多的自动驾驶汽车出现在道路上。但现阶段,人们对自动驾驶汽车的接受程度并不高。其中很大的原因是自动驾驶汽车与人类驾驶员所作出的驾驶行为较为不一致,不能实现拟人驾驶。研究表明,自动驾驶汽车的行为越像人类驾驶员的行为,人们对自动驾驶汽车的信任度越高。因而自动驾驶汽车的驾驶行为应尽可能像人类驾驶员的驾驶行为,从而使得自动驾驶汽车能被更多人接纳。
2、对于类人驾驶行为模拟,随着人工智能的发展,目前主要有两种方法:模仿学习和逆强化学习。模仿学习,直接学习人类的驾驶行为。而逆强化学习通过学习人类驾驶行为背后的奖励函数,进而通过奖励函数学习最优行为策略。由于奖励函数相比直接学习具体的行为,本质上更具可转移性,因而逆强化学习的泛化性通常较强。通常逆强化学习与强化学习结合,通过逆强化学习得到奖励函数,再通过强化学习根据这一奖励函数寻找最优策略。但是这种方法,使得模型较为复杂,计算量较大,对自动驾驶汽车的应用提出了挑战。
3、同时,随着社会科技的发展,人们越来越偏向于产品实现个性化,能够根据自己的需求定制产品。放在自动驾驶汽车上,便是人们希望自动驾驶汽车能够按照他们期望的驾驶风格进行驾驶。驾驶风格是人类驾驶员驾驶行为的概况,反应了人类驾驶员的驾驶行为。不同驾驶员拥有不同的驾驶风格,不同人期望的驾驶风格是不同的,因而自动驾驶汽车应能根据人们期望的驾驶风格进行驾驶,以此来实现个性化自动驾驶。
4、汽车的驾驶行为可以分成两大类,跟车行为和变道行为。跟车行为的交互对象仅限于同一车道的前后车,而变道行为的交互对象则涉及到目标车道的车辆,更加复杂、危险。因而安全、高效地实现个性化、拟人化变道行为,对自动驾驶汽车而言十分具有挑战。
技术实现思路
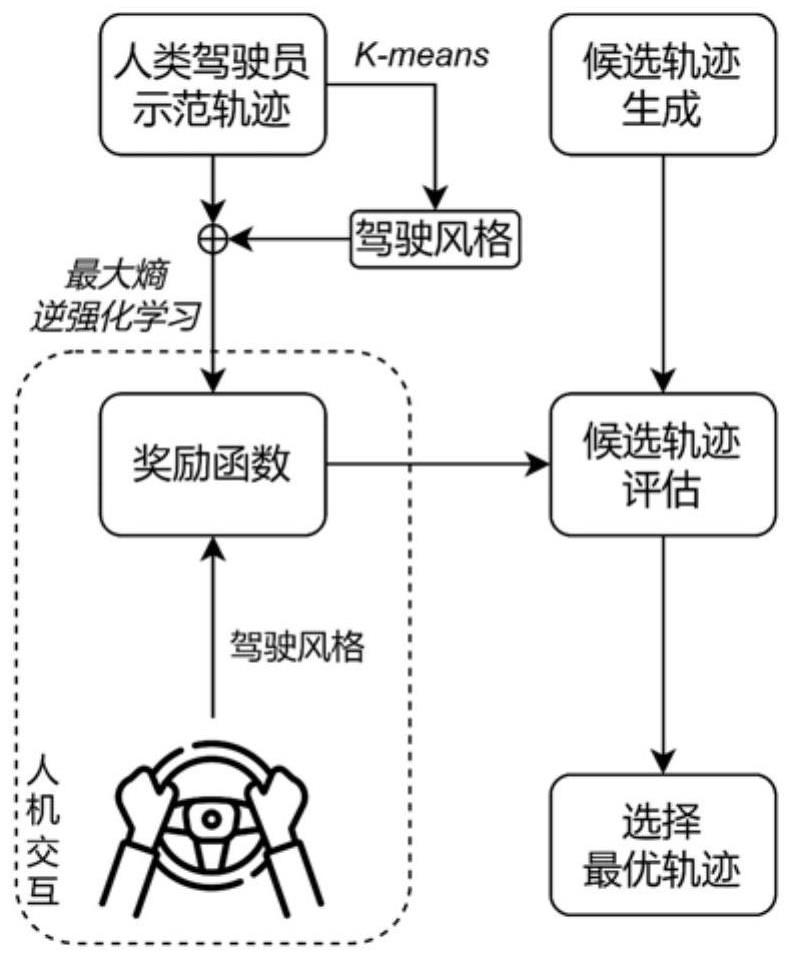
1、本发明的目的是为了提供一种基于驾驶员个性化的拟人变道轨迹优化方法,通过将基函数与驾驶风格识别结合,在拟人化基础上实现个性化决策,同时通过候选变道轨迹的生成减小模型复杂度和计算量。
2、本发明的目的可以通过以下技术方案来实现:
3、一种基于驾驶员个性化的拟人变道轨迹优化方法,包括以下步骤:
4、s1、根据车辆变道行为决策的起点的车辆状态,构建变道轨迹的约束,通过遍历所有可能的变道行为决策的终点的车辆状态,生成候选变道轨迹;
5、s2、构建最大熵逆强化学习模型,所述最大熵逆强化学习模型的奖励函数由一组基函数组成,基函数从驾驶安全、个性化驾驶风格两个方面进行设计,保证车辆变道的安全性和驾驶风格个性化,同时基函数的系数通过逆强化学习进行确定;
6、s3、基于人类驾驶员示范轨迹对最大熵逆强化学习模型进行拟人化训练;
7、s4、基于训练完成的最大熵逆强化学习模型的奖励函数对候选变道轨迹进行评估,选择最优变道轨迹。
8、进一步的,所述步骤s1中,在直线道路行驶时,变道行为决策后,车辆将进入稳定行驶的状态,近似于匀速直线运动,故目标状态空间为:
9、
10、其中,ve、ye分别为变道过程结束时刻车辆的纵向速度以及横向位置。
11、进一步的,所述变道轨迹的约束为:
12、
13、
14、其中,纵向运动存在5个约束,即初始纵向状态约束和纵向目标状态约束,对于横向运动存在6个约束,即初始横向状态约束和横向目标状态约束;xs、vs、as、ys、vys、ays分别为决策过程开始时刻车辆的纵向位置、纵向速度、纵向加速度、横向位置、横向速度以及横向加速度,即初始状态约束;t为变道过程的结束时刻;ve、ye分别为变道过程结束时刻车辆的纵向速度以及横向位置,为待定的目标状态约束。
15、进一步的,所述候选变道轨迹根据变道轨迹的约束方程,表示为一个纵向的4次多项式和一个横向的5次多项式,即:
16、
17、其中,x(t)为t时刻车辆的纵向位置,y(t)为t时刻车辆的横向位置。
18、进一步的,所述最大熵逆强化学习模型中,衡量驾驶安全的基函数基于跟车安全、交互安全和碰撞惩罚三方面的考虑构建得到:
19、fs(t)=(ffollow(t),finteraction(t),fcollision(t))
20、其中,fs(t)为衡量驾驶安全的基函数,ffollow(t)为保证跟车安全的基函数,finteraction(t)为保证交互安全的基函数,fcollision(t)表示发生碰撞的惩罚的基函数。
21、进一步的,所述保证跟车安全的基函数基于改进的碰撞时间mttc构建:
22、
23、
24、δv=vf-vr
25、δa=af-ar
26、
27、
28、其中,tth表示碰撞时间阈值,d表示前后车的相对距离,vf、vr分别表示前、后车的速度,af、ar分别表示前、后车的加速度;
29、所述保证交互安全的基函数基于目标车道及本车道后车的纵向减速度之和构建:
30、finteraction(t)=-min(arx(t),0)-min(atrx(t),0)
31、其中,arx(t)、atrx(t)分别为本车道和目标车道的后车的加速度;
32、所述发生碰撞的惩罚的基函数为:
33、
34、进一步的,所述最大熵逆强化学习模型中,衡量个性化驾驶风格的基函数的构建过程为:设计一组函数组,基于人类驾驶员的示范轨迹计算函数组中各函数的函数值作为特征,并进行归一化处理,利用特征选取的分布式k-means聚类算法,对驾驶员驾驶风格进行分类,从函数组中选取对驾驶风格分类影响最大的特征对应的多个函数,组成衡量个性化驾驶风格的基函数。
35、进一步的,所述函数组中的函数包括纵向运动急动度、横向运动急动度、纵向速度、纵向运动加速度、纵向运动减速度、横向运动加速度、横向运动减速度、变道开始时刻目标车道与本车距离最近的前车距离、变道开始时刻目标车道与本车距离最近的后车距离。
36、进一步的,所述最大熵逆强化学习模型采用梯度下降法训练奖励函数中基函数的系数,目标函数为:
37、
38、
39、其中,τ为同一驾驶风格的人类驾驶员的示范轨迹;为候选轨迹;n为候选轨迹的总数;r(τ)表示变道轨迹的奖励函数,fs为衡量驾驶安全的一组基函数,ωs为相应学习得到的系数,fp为表征个性化驾驶的一组基函数,ωp为相应学习得到的系数。
40、进一步的,所述步骤s4中,对于候选变道轨迹的选择,利用最大熵逆强化学习学得的不同驾驶风格下的奖励函数,代入计算得到各候选轨迹在不同驾驶风格下的奖励,不同驾驶风格下候选变道轨迹被选择的概率与该轨迹所获得的奖励的指数成正比,即:
41、
42、其中,pj(τ)代表候选变道轨迹在驾驶风格j下被选择的概率,rj(τ)代表该轨迹在驾驶风格j下获得的奖励,n为候选轨迹的总数;
43、驾驶风格j下概率pj(τ)最大的候选轨迹,即为最终确定的驾驶风格j下的最优变道轨迹。
44、与现有技术相比,本发明具有以下有益效果:
45、(1)本发明通过将基函数与驾驶风格识别结合,在拟人化基础上实现了个性化决策。
46、(2)本发明通过候选变道轨迹的生成,实现了最优策略的寻找,相比于强化学习等方法寻找最优轨迹,大大减少了模型复杂度和计算量。
- 还没有人留言评论。精彩留言会获得点赞!