数据机理深度融合的自动驾驶安全高效进化方法及装置
本技术涉及自动驾驶,具体而言,涉及数据机理深度融合的自动驾驶安全高效进化方法及装置。
背景技术:
1、面对复杂多变的外界环境,高级别自动驾驶汽车被要求具备极高的智能化程度,具有安全高效的自我进化能力对于推动高级别自动驾驶技术的发展至关重要,这种能力能够促使系统不断提升性能水平,使其能够应对各种挑战,以满足不同场景下的自动驾驶需求。
2、当前的自动驾驶决策控制算法大多主要依赖于优化和规则,尽管这些算法充分利用了专家经验与领域知识,但人为定义的规则难以灵活应对各种高度复杂的外界环境,这阻碍了真正高级别自动驾驶的实现,与此同时,基于生成式深度学习大模型的方法展现了实现通用人工智能的潜力。
3、但是,这些方法仍然需要大量专家数据的支撑,并且存在着安全性难以保证的隐忧,这限制了其在自动驾驶领域的应用,当前技术发展的趋势表明,结合专家经验知识与生成式深度学习模型的方法,会为实现高级别自动驾驶技术的突破提供新的可能性,这种融合的方式有望结合传统方法与深度学习大模型方法的优势,为自动驾驶技术的进一步发展开辟了新的思路和方向。
技术实现思路
1、为了解决现有技术仍然需要大量专家数据的支撑,并且存在着安全性难以保证的隐忧,限制了其在自动驾驶领域的应用的问题,本技术提供了一种数据机理深度融合的自动驾驶安全高效进化方法及装置。
2、本技术的实施例是这样实现的:
3、第一方面,本技术提供一种数据机理深度融合的自动驾驶安全高效进化方法及装置,包括:
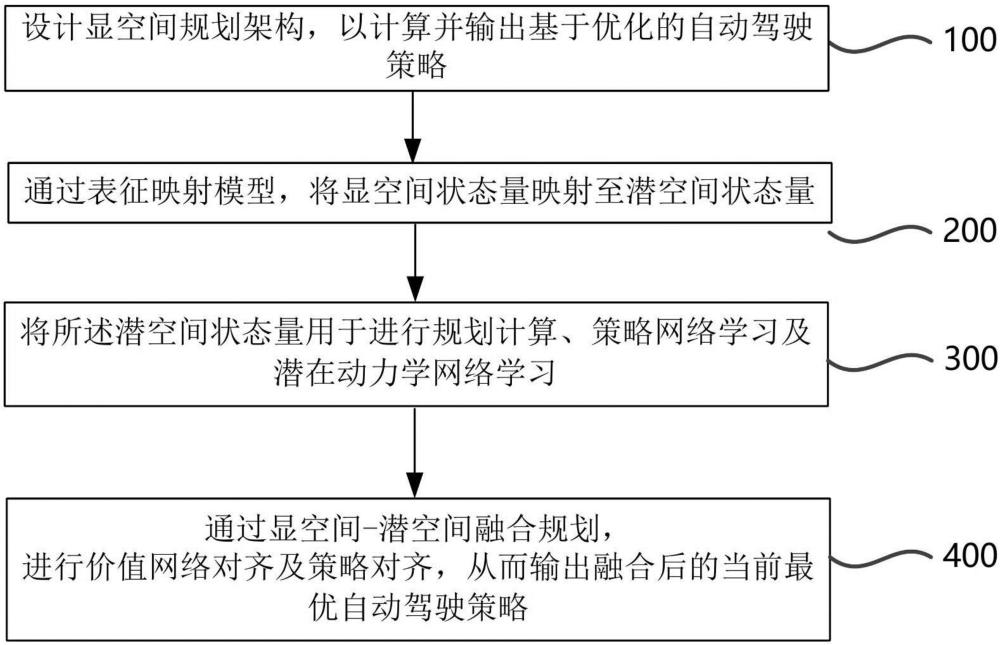
4、设计显空间规划架构,以计算并输出基于优化的自动驾驶策略;
5、通过表征映射模型,将显空间状态量映射至潜空间状态量;
6、将所述潜空间状态量用于进行规划计算、策略网络学习及潜在动力学网络学习;
7、通过显空间-潜空间融合规划,进行价值网络对齐及策略对齐,从而输出融合后的当前最优自动驾驶策略。
8、在一种可能的实现方式中,在所述通过显空间-潜空间融合规划模块,进行价值网络对齐及策略对齐,从而输出融合后的当前最优自动驾驶策略步骤之后,还包括记录经验更新神经网络,进一步进行策略学习。
9、在一种可能的实现方式中,显空间状态量为自动驾驶算法在实际运行过程中所输入的,具有实际物理意义的状态空间,其与算法细节相关。
10、在一种可能的实现方式中,设计显空间规划架构,以计算并输出基于优化的自动驾驶策略,进一步包括:
11、构造非线性规划问题,并设计代价函数;
12、约束用于表示显空间规划中不应出现的状态违背情况,所述约束包括车辆运动学约束、控制增量约束、碰撞约束及安全跟车约束;
13、将非线性优化问题构建在优化组件中,求解得到基于优化的自动驾驶策略并输出。
14、在一种可能的实现方式中,所述表征映射模型用于表征从显空间状态量到潜空间状态量之间的映射关系。
15、在一种可能的实现方式中,所述显空间-潜空间融合规划,包括价值估计融合及输出策略对齐:
16、通过所述价值估计融合,可以使较为准确但性能有限的基于机理的代价函数,和最终性能很好但一开始并不准确的基于深度神经网络的价值函数相结合,从而发挥数据方法和机理方法的优势;
17、通过所述输出策略对齐,可以保证输出策略的安全性,防止数据驱动方法输出不合理的策略。
18、在一种可能的实现方式中,在进行潜空间下的规划时,会根据潜在动力学模型,价值模型和奖励模型进行策略参数的更新;
19、潜在动力学模型定义为:
20、;
21、奖励模型定义为:
22、;
23、价值模型定义为:
24、;
25、策略网络定义为:
26、;
27、其中,为i+1时刻的潜在状态量;
28、通过潜在动力学模型,价值模型和奖励模型,计算得到潜空间规划过程中的采样轨迹总回报为:
29、;
30、其中,h为浅空间预测时域,为对齐策略,为价值折扣因子。
31、在一种可能的实现方式中,在所述通过潜在动力学模型,价值模型和奖励模型,计算得到潜空间规划过程中的采样轨迹总回报步骤之后,还包括:
32、将显空间规划中的代价函数与相融合,并通过参数调节权重:
33、;
34、其中,参数随着训练过程线性调整;
35、设为潜空间规划得到的策略输出,该策略服从于正态分布;
36、其中,i为单位矩阵;
37、将采样轨迹得到的回报排序,选择前k个回报并进行迭代,迭代结束后得到新的参数及:
38、;
39、;
40、其中,控制权重的锐度,在固定次数的迭代之后,规划过程终止,并从动作序列的最终回报归一化分布中采样轨迹,表示连续的a动作下的采样轨迹;
41、将、与策略网络的输出相对齐,得对齐策略:
42、;
43、其中,参数为权重系数,该系数随着碰撞风险情况动态调整,碰撞风险由自动汽车与周围交通车之间的相对欧拉距离计算;
44、规划过程会在显空间预测时域np内进行,并重复上述过程直到np步对齐策略被选择为规划的一串动作中的第一个动作。
45、在一种可能的实现方式中,所述映射模型、显性动力学网络、潜在动力学模型及奖励模型均由探索得到的经验数据,通过监督学习的方式进行训练;
46、所述的价值网络由下式训练:
47、;
48、其中为策略网络,为价值折扣因子,为了缓解价值网络过高估计问题,定义目标价值网络,其中的参数不随着训练过程实时更新,而是每间隔固定周期,再由更新至;
49、策略网络通过最大化价值进行参数更新,其公式为:
50、;
51、其中,sg()为停止梯度回传算子,表示i时刻的潜在状态量的输入不会带来整个loss的梯度更新,为策略折扣因子,表示轨迹。
52、第二方面,本技术提供一种数据机理深度融合的自动驾驶安全高效进化装置,包括:
53、设计模块,用于设计显空间规划架构,以计算并输出基于优化的自动驾驶策略;
54、映射模块,用于通过表征映射模型,将显空间状态量映射至潜空间状态量;
55、学习模块,用于将所述潜空间状态量用于进行规划计算、策略网络学习及潜在动力学网络学习;
56、输出模块,用于通过显空间-潜空间融合规划,进行价值网络对齐及策略对齐,从而输出融合后的当前最优自动驾驶策略。
57、本技术提供的技术方案至少可以达到以下有益效果:
58、本技术提供的数据机理深度融合的自动驾驶安全高效进化方法,通过结合专家经验知识与生成式深度学习大模型的方法,将显性空间规划结果与潜在空间规划结果相融合,使自动驾驶算法得以安全且高效的自我进化并提升智能。
- 还没有人留言评论。精彩留言会获得点赞!