一种基于行为风险强化学习的智能汽车环岛驾驶决策方法
本发明属于汽车,具体的说是一种基于行为风险强化学习的智能汽车环岛驾驶决策方法。
背景技术:
1、环岛场景作为复杂城市交通的重要组成部分,在汽车分流、减少汽车行驶冲突、提高汽车行驶效率等方面发挥着重要作用。相较于纵向巡航跟驰、侧向高速换道等简单驾驶工况,智能汽车在环岛场景中执行汇入、绕岛行驶和驶出等动态多样驾驶任务时面临高复杂性和强交互性问题,这对智能汽车驾驶决策安全性能提出了重大挑战。
2、深度强化学习融合深度神经网络特征提取能力和强化学习环境交互优势,被认为是智能汽车驾驶决策策略设计的有效解决方案,已在车道保持、变道和自适应巡航等简单城市交通工况中得到了广泛地应用。但是将深度强化学习应用于汽车驾驶决策前,需要对环境进行合理建模以提升策略训练品质。然而,上述简单城市交通工况研究缺乏综合考虑汽车横纵向耦合动作空间、动态多样驾驶任务、复杂行驶工况约束、车辆强交互等问题,导致它们直接应用于环岛等复杂城市交通场景下智能汽车驾驶决策时存在一定安全风险。
3、此外,奖励函数对基于深度强化学习的汽车驾驶决策策略训练寻优、收敛过程至关重要。基于专家经验人为设计的复杂城市交通场景奖励函数可能存在一定经验盲区,导致基于深度强化学习的汽车驾驶决策策略无法收敛或陷入局部最优。因此,近年来模仿学习、逆强化学习等方法来在复杂城市交通场景汽车驾驶决策策略设计中得到了应用。然而,模仿学习高度依赖有效的专家示范数据,且对于数据未覆盖场景的泛化能力较弱;逆强化学习同样依赖专家示范数据,且不同专家的异质性驾驶特征也会导致拟合的奖励函数出现偏差或难以收敛。最近,基于人类偏好的强化学习方法,如人类反馈强化学习,广泛应用于大语言模型领域,其核心思路是基于优、劣势策略的对比学习,使其尽可能输出优势策略而非劣势策略。因此,理解人类偏好的强化学习方法也可应用于驾驶决策中,帮助智能汽车在复杂交通场景中输出安全性更高的驾驶动作。其中,人类偏好通过建立客观的奖励函数进行表征。然而,这种奖励函数的训练需要大量驾驶决策数据,这一定程度上阻碍了基于人类偏好的强化学习算法在复杂城市交通场景中的应用。
技术实现思路
1、为解决上述问题,本发明提供了一种基于行为风险强化学习的智能汽车环岛驾驶决策方法,可实现对环岛复杂交互场景的适应,并保证深度强化学习算法训练过程中的安全决策,同时可实现强化学习算法的快速落地。
2、本发明技术方案结合附图说明如下:
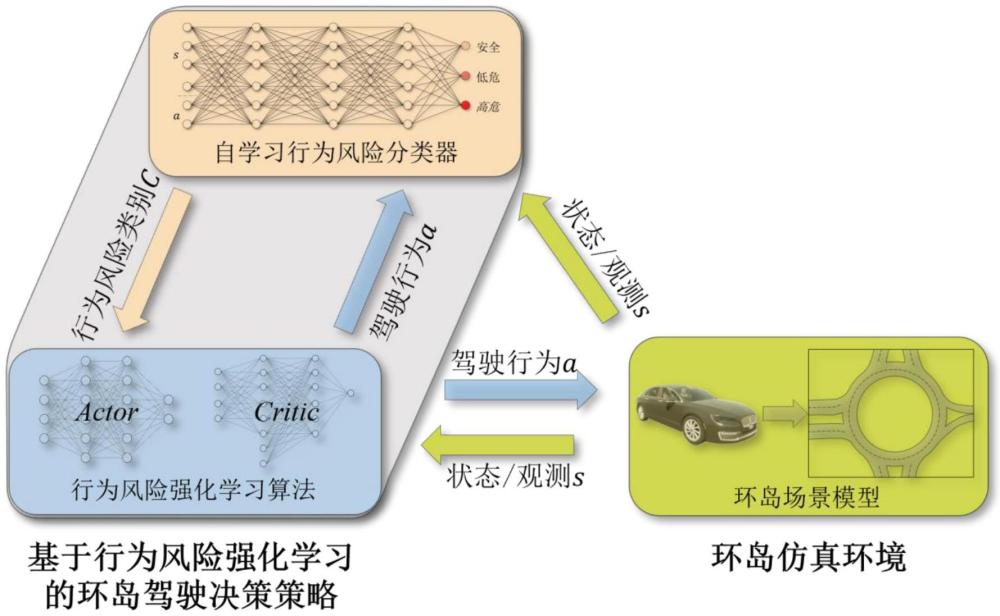
3、一种基于强化学习的智能汽车环岛驾驶决策方法,包括以下步骤:
4、步骤一、搭建环岛场景模型;
5、步骤二、构建自学习行为风险分类器。
6、步骤三、对行为风险强化学习驾驶决策算法进行建模,从而实现智能汽车在环岛驾驶的决策。
7、进一步的,所述步骤一的具体方法如下:
8、11)设计动作空间;
9、12)设计状态空间;
10、13)设计智能汽车多目标奖励函数。
11、进一步的,所述步骤11)的具体方法如下:
12、将智能和驱动合并为仿真车辆纵向加减速控制所需的归一化信号px∈[-1,1],并与前轮主动转向信号δe∈[-1,1]结合,构建智能汽车横纵向耦合动作空间ae:
13、ae=[pex,δe] (1)。
14、进一步的,所述步骤12)的具体方法如下:
15、设计由重点任务和驾驶任务组成的驾驶任务向量vt,如下:
16、
17、式中,δpend为自车当前位置相对终点的坐标;和分别为自车相对前方路径点pi的距离和朝向偏差,pi随着车辆向前行驶而递进;
18、设计由周围车辆信息构成的周围环境状态向量ve;通过区域切割编码方法,将自车周围环境划分为p0~p6的7个检测区间;将p0、p1、p4、p5高交互检测区间进行膨胀处理;当外置感知模块检测到与自车行驶方向相同,且中心点投影位于检测区间内的其他车辆时,将其标记为被感知车辆,对应的车辆信息vi表示为:
19、vi=[f,δl,d-1,δv,δθ,i],i={0,...,6}, (3)
20、式中,f∈{0,1}为是否存在车辆的标志位;δl、d、δv=[δvx,δvy]和δθ分别为他车和自车间的相对车道偏移、距离,速度和相对朝向;i∈[-1,1]为他车换道可能性;
21、当检测区间内没有他车时,相应设定最终,得到周围环境向量ve为:
22、ve=[v0,v1,v2,v3,v4,v5,v6]. (4)
23、设计包含自车速度信息ve=[vex,vey]、加速度信息ae=[aex,aey]、行驶方向信息he=[cosθe,sinθe]和横摆角速度信息ωe自车状态向量,加入未来目标点预瞄信息来综合建立状态向量ve:
24、ve=[ve,ae,he,ωe,δθe,ae], (5)
25、式中,θe为自车航向角;为未来三个目标点方向与自车航向角之间的角度差;
26、综上,形成状态空间:
27、s=[vt,ve,ve]t. (6)。
28、进一步的,所述步骤13)的具体方法如下:
29、设计碰撞奖励函数rc为:
30、
31、式中,min{di}为检测区间内所有车辆与自车的最近距离;dc为危险碰撞车距阈值;
32、通过纵横向安全奖励rf和rl进行引导,如下所示:
33、rf=-0.5|min(0,δvfx)|(df-df), (8)
34、rl=-2.5|min(0,δvky)|(dl-dk)2, (9)
35、式中,δvfx和df∈(dc,df)为前车与自车的相对纵向速度和距离;δvky和dk∈(dc,dl)为自车旁边最近车辆与自车的相对横向速度和距离;df和dl为纵、横向安全车距;
36、设计环岛入口安全奖励rre,如下所示:
37、rre=-0.25||δvi||(dre-di), (10)
38、式中,di∈(dc,dre)和δvi分别为自车与高风险车辆的距离和相对速度向量;dre为高风险交互安全车距;
39、得到安全奖励函数,如下所示:
40、rs=rc+rf+rl+rre, (11)
41、建立抵达终点奖励rsucc,如下所示:
42、rsucc=100,||δpend||≤dp, (12)
43、式中,dp为自车与路径点p的距离阈值;
44、引入路径跟踪奖励rtag,如下所示:
45、
46、式中,为两目标点间自车的行驶距离;
47、建立速度奖励rsp,如下所示:
48、
49、设计航向奖励rδθ引导车辆按照规定的道路方向运动,如下所示:
50、
51、式中,vlim为道路限速;δθe为自车航向与道路方向偏差;θδθ1,θδθ2为车辆行驶方向偏差阈值;
52、设计驾驶任务奖励函数,如下所示:
53、rt=rsucc+rtag+rδθ+rsp (16)
54、设计转向奖励rst,如下所示:
55、rst=-2|δe|vx (17)
56、设计车道保持奖励rlk,如下所示:
57、
58、式中,δd为主车当前位置相对于道路中线的横向偏移;l为道路宽度;当车辆越过道路边界时,即|δd|≥l时,rlk=-20结束当前回合重置环境;
59、定义控制指令奖励rcontrol,如下所示:
60、rcontrol=-4||acur-aper||2 (19)
61、式中,aper,acur分别为前后时刻的动作向量;
62、建立横摆舒适性奖励rω,引导汽车横摆角速度平稳变化,如下所示:
63、rω=-((ω-ωω)/5)2,ωω<ω (20)
64、式中,ωω为横摆角速度阈值;
65、设计驾驶行为奖励函数rc,如下所示:
66、rc=rlk+rω+rst+rcontrol (21)
67、最终,得到了智能汽车多目标奖励函数,如下所示:
68、r=rs+rt+rc (22)。
69、进一步的,所述步骤二的具体方法如下:
70、21)构建多层感知机,输入为状态空间s和动作空间a,输出为三种行为风险类别即安全、低危、高危的概率;
71、22)对分类器进行训练。
72、进一步的,所述步骤22)的具体方法如下:
73、1)数据收集和标注:基于现有的环岛决策策略,收集环岛驾驶仿真数据;从收集的数据中随机采样状态-动作对{s,a},并进行行为风险类别标注,评估其驾驶决策行为的风险;三种行为风险的判断依据为:高危行为指在将发生碰撞、驶出车道或高速转向的危险工况下,执行后将继续恶化驾驶安全的行为;安全行为指在安全工况下执行跟随、换道行为或者在危险工况下执行避免工况进一步恶化的行为;低危行为指在安全工况中,执行后将恶化驾驶安全的行为;
74、2)预训练:使用标注数据对分类器进行基于监督学习的预训练,使初步具备区分不同风险类别的能力;
75、3)自学习训练:预测阶段,分类器首先对无标签的环岛数据进行预测;高置信度筛选,对于那些风险类别预测置信度超过90%的状态-动作对,将其标注为对应的预测类别,并将这些数据加入下一轮训练集,循环训练,重复上述自学习过程,不断更新分类器;
76、4)终止训练:当分类器在测试集上的分类准确率不再提高时,结束训练;
77、采用焦点损失和标签分布感知边距损失组成的联合损失来处理预训练以及自学习训练过程中存在的类别不平衡及困难样本挖掘的问题,构建联合损失函数如下所示:
78、
79、式中,γ为调节权重因子的超参;py∈[0,1]为预测值;αy=3∑jnj/ny为平衡样本数量的权重参数,其中nj为各类别的样本数;
80、设计损失函数中与类别占比相关的参数αy,ny随着训练动态变化,而实现损失函数的自适应调整。
81、进一步的,所述步骤三的具体方法如下:
82、31)通过引入策略熵来激励策略产生更多样化的探索行为,如下所示:
83、
84、式中,πφ为策略函数;
85、32)强化学习算法通过贝尔曼回归算子和时序差分对考虑策略熵的q值函数进行迭代求解,如下所示:
86、
87、算法价值网络的代价函数定义为
88、
89、式中,s,a,r,s′分别为采样的当前状态、动作、奖励及下一状态;α为熵权重系数;分别为价值网络和目标网络;φ为策略网络;
90、在约束条件下,自动调节熵权重系数α以平衡策略熵与期望回报之间的比重,设计超参数α的代价函数,如下所示:
91、
92、式中,为熵约束阈值;
93、33)将迭代目标设计为最小化策略函数π与q值函数之间的信息散度,即同时最大化期望奖励和策略熵如下所示:
94、
95、式中,πφ(s)=fφ(s,ξ)为重参数化技巧下策略分布的采样值;为服从标准正太分布的噪声;k(s)为配分函数,不参与策略优化;
96、34)采用状态动作数据集,通过最大化同一输入下优、劣势行为所能获得奖励差的期望来迭代优化,从而使奖励网络具备准确评估优、劣势策略的能力,代价函数,如下所示:
97、
98、式中,rψ为奖励网络;a+,a-为同一状态s下对应的优、劣势行为;σ为sigmoid函数;
99、35)加入信息散度来限制新策略与原始策略的偏差,其代价函数定义为:
100、
101、式中,πφ为训练的策略模型;πref为初始模型;β为控制两策略偏离程度的参数;z=∑aπref(a|s)exp(r(s,a)/β)为配分函数,只与状态s和πref有关,而与优化的策略πφ无关;
102、策略πφ的优化目标等价于最小化分子与分母之间分布的差异,将最优策略π*定义为:
103、
104、进一步将公式(31)代入公式(30)中,即得策略πφ的优化目标为最小化训练策略πφ与最优策略π*之间分布的偏差,如下所示:
105、
106、由公式(30)得奖励网络rψ和最优策略π*之间的关系为:
107、
108、36)利用奖励网络与最优策略的关系消除公式(28)中奖励网络rψ,并基于最大似然优化思想和公式(32)的策略πφ优化目标,通过将最优策略替换为策略πφ,实现使用人为标注数据直接优化策略πφ的目的,即最大化同一状态下策略输出优、劣势行为的概率差,如下所示:
109、
110、通过对采样驾驶行为的风险评估,改善策略迭代方向,减小奖励函数设计不足对策略优化的影响,如下所示:
111、
112、式中,πφ′为πφ的目标函数;a+,a-分别为基于行为风险分类的优、劣势行为,由目标策略函数πφ′进行两次随机采样生成,并通过行为风险分类器进行风险分类,驾驶风险越低则行为越优;β′=β+(c--c+)/4为行为风险类别差异系数;c∈{0,1,2}分别对应于安全、低危和高危三种风险行为标签。
113、本发明的有益效果为:
114、1)本发明设计了环岛场景模型,包含汽车横纵向耦合动作空间、由驾驶任务-周围环境-自车信息构成的多尺度信息状态空间以及考虑安全-任务-驾驶行为的多目标奖励函数,能充分表征环岛驾驶的特点,使强化学习能充分理解和处理复杂的环岛交互场景
115、2)本发明基于人类偏好强化学习理论设计了能应用于驾驶决策领域的行为风险强化学习,通过引入行为风险分类优化目标来弥补强化学习训练过程中的奖励函数设计不足问题;
116、3)本发明基于奖励训练和策略训练推导了行为风险优化目标函数,实现了由双阶段训练过程到单阶段训练的简化,直接使用行为风险数据优化策略迭代方向;
117、4)为了实现在策略优化过程中,对采样行为的相对优、劣势进行并行且准确的评估,本发明采用了以安全、低危、高危三种行为风险类别为基础的行为风险分类器;
118、5)为了实现行为风险分类器并减小标注驾驶风险数据的强度和难度,设计了基于自学习的分类器训练策略,仅通过少量的标签数据即可完成基于多层感知机的分类器训练任务。
- 还没有人留言评论。精彩留言会获得点赞!