一种权重自进化的智能汽车个性化换道决策系统
本发明涉及一种自动驾驶汽车换道行为决策系统,特别涉及一种权重自进化的智能汽车个性化换道决策系统。
背景技术:
1、随着汽车智能化水平不断提高,配备高等级自动驾驶系统的智能汽车的产销量不断增加。高等级的自动驾驶系统应当具备感知复杂交通态势的能力,并在与周围车的交互中做出正确的行为决策,在降低碰撞风险的同时,提高交通通行效率。换道行为是微观交通流的核心组成部分,是典型的车间交互行为。在换道交互过程中,自车能否正确理解周围车的意图,并做出正确决策,是当前智能汽车技术领域的重大技术挑战。
2、为了表征不同驾驶人驾驶行为的个性化差异,结合基于驾驶行为的驾驶风格分类算法的智能汽车个性化换道决策系统被建立。目前,智能汽车个性化换道决策系统通常包括数据驱动的换道决策与基于机理规则的换道决策两大类。数据驱动的换道决策通常利用学习类方法,将自车及周围车的运动学参数等特征作为学习算法的传入,利用神经网络等方法拟合出传入特征与自车行为意图间的内在映射关系;基于机理规则的换道决策通常利用人工设置的规则及常识的认知建立驾驶人的驾驶行为与驾驶人意图的映射关系。然而,数据驱动的和基于机理规则的智能汽车换道行为决策系统尚存在以下技术问题:
3、1.当前基于驾驶行为的驾驶风格分类算法仅可作定性分析,难以作定量分析。目前所构建的驾驶风格分类算法仅将驾驶人的驾驶风格分为谨慎型、一般型、激进型三类。事实上,驾驶人的驾驶风格存在个体差异,且易受所处交通环境的影响。准确评估驾驶风格对于正确判断驾驶人的行驶意图从而做出正确决策尤为重要,但是,现有的驾驶风格分类算法难以提供驾驶风格的量化指标。
4、2.数据驱动的换道决策系统建立车辆行驶过程中周围车及自车的运动学变量与自车换道决策间的多维映射关系,其本质是通过在海量数据中学习隐含的交互逻辑,从而建立传入参数与输出结果的内生关系。由于数据驱动的方法属于黑盒类算法,算法的可解释性差,因而难以对各系统参数与换道决策期间交通车间的交互关系做出显式表达,这导致对系统的调参存在现实困难,进一步导致系统输出不稳定甚至存在安全隐患。
5、3.基于机理规则的换道决策系统利用对驾驶人驾驶行为的观察,建立车辆运动学信息与车辆行驶意图间具备实际含义的函数映射关系,综合考虑自车运动学约束及行车安全性,依据人工设定的决策规则进行换道决策。然而,现实交通环境复杂多变,人工规则难以覆盖各类行驶工况,这造成了基于机理规则的换道决策系统泛用性差的问题。与此同时,基于机理规则的换道决策系统中的参数通常保持固定,这使得系统难以具备自主学习的能力,进一步限制了基于机理规则的换道决策系统的性能。
技术实现思路
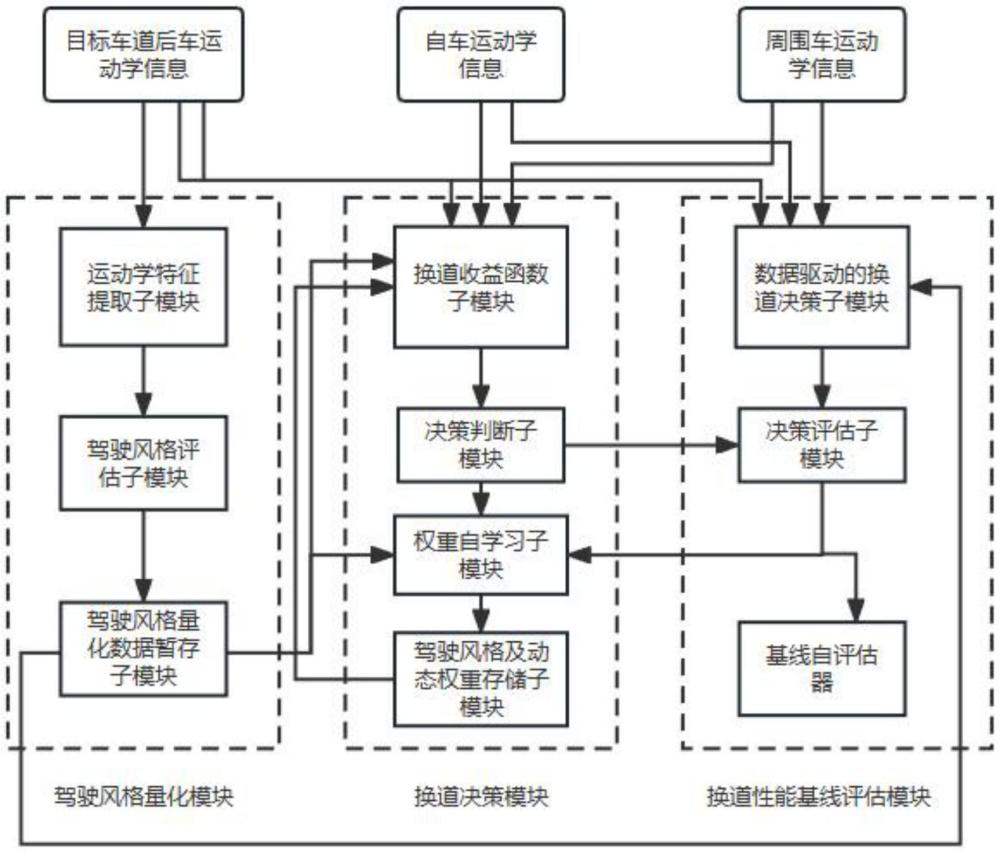
1、为了解决上述技术问题,本发明提供一种权重自进化的智能汽车个性化换道决策系统,包括:驾驶风格量化模块、换道决策模块、换道性能基线评估模块;所述的驾驶风格量化模块包括运动学特征提取子模块、驾驶风格评估子模块和驾驶风格量化数据暂存子模块;所述的换道决策模块包括:换道收益函数子模块、决策判断子模块、权重自学习子模块和驾驶风格及动态权重存储子模块;所述的换道性能基线评估模块包括数据驱动的换道决策子模块、决策评估子模块和基线自评估器。
2、进一步的,所述的驾驶风格量化模块的工作过程如下:首先,将目标车道后车运动学信息传入运动学特征提取子模块,运动学特征提取子模块对传入的运动学信息进行数据预处理及数据特征提取,随后将处理后的信息传入驾驶风格评估子模块,驾驶风格评估子模块中训练完成的高斯混合模型(简称为gmm)接收上述信息,并依据所获得的信息给出目标车道后车的各驾驶风格量化概率包括:谨慎型的概率xd1、一般型的概率xd2、激进型的概率xd3,并将概率xd1、xd2、xd3输出至驾驶风格量化数据暂存子模块,驾驶风格量化数据暂存子模块将数据整理为一个一行三列的向量xd=[xd1,xd2,xd3],即驾驶风格量化数据,并存储在数据暂存器中;当有新的驾驶风格量化数据传输至驾驶风格量化数据暂存子模块后,数据暂存器中储存的先前数据将会被新的量化数据覆盖。
3、具体的,所述的运动学特征提取子模块的数据特征提取功能为:获取t时间内目标车道后车相对自车的相对速度、相对加速度及急动度信息,计算平均相对速度、平均相对加速度及平均急动度,将算得的平均相对速度、平均相对加速度及平均急动度信息传入驾驶风格评估子模块。
4、具体地,所述的高斯混合模型的训练过程如下:
5、步骤1、预处理与特征提取:从数据集中获取n条有换道行为发生的目标车道后车在自车发生换道前的t时间内相对自车的相对速度、相对加速度及急动度信息,计算第i条训练数据的目标车道后车的平均相对速度平均相对加速度及平均急动度记为所有n条符合条件的训练数据表示为:p=[p1,p2,......,pn];
6、步骤2、高斯混合模型的参数训练:将所有n条符合条件的训练数据传入高斯混合模型,高斯混合模型中子高斯模型的数量k设置为3,利用最大期望算法求解高斯混合模型的参数,主要分为两步:
7、第一步,e-step,按照如下公式计算q函数,它代表第i个数据属于第k个子高斯分布的概率:
8、
9、其中,φk表示第k个子高斯分布的概率,x(i)表示第i个数据,μk表示第k个子高斯分布的均值,σk表示第k个子高斯分布的标准差,首轮迭代时随机给定φk、μk、σk的值;
10、第二步,m-step,按照如下公式更新模型的参数:
11、
12、重复迭代e-step及m-step数次,直至模型收敛。
13、训练完成后,高斯混合模型通过传入后车在自车发生换道前的t时间内的平均相对速度、平均相对加速度及平均急动度信息,评估出后车驾驶风格属于谨慎型的概率xd1、一般型的概率xd2、激进型的概率xd3,并将上述概率作为驾驶风格评估子模块的输出量输出。
14、进一步的,所述的换道决策模块的工作过程如下:将目标车道后车运动学信息、自车运动学信息、周围车运动学信息,以及驾驶风格量化模块的驾驶风格量化数据xd=[xd1,xd2,xd3]传入换道收益函数子模块,换道收益函数子模块依据建立的自车sv的收益函数及目标车道后车pv的收益函数;先查询驾驶风格及动态权重存储子模块中是否存有相同驾驶风格量化数据的动态权重记录,如存在记录,则调用该动态权重记录作为pv收益函数的各项权重ω1、ω2;如不存在记录,则依据驾驶风格量化数据xd=[xd1,xd2,xd3]初步调整pv收益函数的各项权重:随后依据建立的自车sv的收益函数算得sv的收益函数结果,依据建立的目标车道后车pv的收益函数算得pv的收益函数结果;将算得的sv收益函数结果、pv收益函数结果及pv收益函数的各项权重传入决策判断子模块,决策判断子模块先判断此时sv的换道收益rlane是否大于保持在原车道行驶的车道保持收益rstay,若此时sv的换道收益rlane不大于保持在原车道行驶的车道保持收益rstay,则给出自车sv应当车道保持的决策;若此时sv的换道收益rlane大于保持在原车道行驶的车道保持收益rstay,则决策判断子模块依据pv期望获得最大收益的博弈思想,默认pv将依据最大化自身收益的原则采取避让减速或是采取不避让继续行驶的动作,据此给出自车sv是否应当换道或车道保持的决策,随后将决策传入换道性能基线评估模块的决策评估子模块,将pv收益函数的各项权重传入权重自学习子模块,决策评估子模块确定当前pv收益函数的各项权重是否具备优化空间,并将评估结果输出至权重自学习子模块,权重自学习子模块接收来自决策判断子模块的pv收益函数的各项权重、来自决策评估子模块的评估结果及来自驾驶风格量化数据暂存子模块的驾驶风格量化数据,若来自决策评估子模块的评估结果显示pv收益函数的各项权重存在优化空间,则权重自学习子模块随后引导动态调整pv收益函数的各项权重,并将新权重及对应的驾驶风格量化数据存入驾驶风格及动态权重存储子模块,否则权重自学习子模块不对pv收益函数的各项权重做出调整,直接将对应权重及对应的驾驶风格量化数据传入驾驶风格及动态权重存储子模块。
15、具体的,在当前时间步t,换道收益函数子模块依据从数据集中获取的当前时间步t的目标车道后车运动学信息、自车运动学信息、周围车运动学信息及从驾驶风格量化模块获取的当前驾驶风格量化数据,利用所建立的自车sv收益函数及pv收益函数计算当前时间步t的sv收益函数结果及pv收益函数结果,所建立的自车sv收益函数及pv收益函数如下:
16、sv收益函数spricesv为:
17、
18、上式中,ksv1、ksv2、ksv3、均为正比例系数,rlane为决策换道时sv的换道收益;
19、vs(vsv,vfv1)函数表征自车sv期望通过换道以确保自身行驶速度的意愿收益,表示为:其中,vsv是自车sv在当前时间步t的速度,vfv1是fv1在当前时间步t的速度;
20、vfv(vfv1,vfv2)函数表征自车通过换道动作可以提升自身后续跟驰速度的收益,表示为:其中,vfv1是fv1在当前时间步t的速度,vfv2是fv2在当前时间步t的速度;
21、spv(ssv,spv)函数表征依据自车sv及后车pv纵向间距的安全收益,表示为:
22、
23、其中,ssv是sv在当前时间步t的纵向位置(以车辆行驶方向为坐标系正向),spv是pv在当前时间步t的纵向位置;spv(ssv,spv)是一个分段函数,当sv与pv的纵向间距ssv-spv超过安全阈值ss时,提供一个恒定的正值收益rsp;当sv与pv的纵向间距ssv-spv处于安全阈值ss与危险阈值sd之间时,提供一个随间距减少而逐渐下降的正值收益直至到达危险阈值时收益降为0;当sv与pv的纵向间距ssv-spv低于危险阈值sd时,提供一个较大的负值恒定收益rspd;
24、函数表征依据sv与fv1纵向距离及纵向速度的sv行为决策约束函数,表示为:其中,sfv1是fv1在当前时间步t的纵向位置,当sv与fv1的纵向到达时间小于3.5秒时,
25、提供一个较大的负值收益rspn1;当sv与fv1的纵向到达时间大于等于3.5秒时,提供一个较小的正值收益rsp1;
26、函数表征依据sv与fv2纵向距离及纵向速度的sv行为决策约束函数,表示为:其中,sfv2是fv2在当前时间步t的纵向位置,当sv与fv2的纵向到达时间小于最小换道安全跟驰时差tsp2=3.5+tlanec时,提供一个较大的负值收益rspn2;当sv与fv2的纵向到达时间大于等于最小换道安全跟驰时差tsp2时,
27、提供一个较小的正值收益rsp2,其中,tlanec为驾驶人平均换道时间,tlanec通过公开数据集统计驾驶人平均换道时间获得;
28、当sv不进行换道即保持在原车道行驶时,其获得一个恒定的较小负值收益rstay。
29、pv收益函数spricepv为:
30、spricepv=ω1·vpv(apv,vpv)+ω2·sspace(spv,ssv)
31、上式中,ω1、ω2表征pv收益函数的各项权重,是动态可变的正权重系数,vpv(apv,vpv)函数表征pv的速度要求收益,表示为:其中,vpv为pv在当前时间步t的速度,apv为pv在当前时间步t的加速度数值,当pv的动作为避让减速时,apv为一个负值常数,当pv的动作为不避让时,apv=0,τ0为一个正值常数;sspace(spv,ssv)函数表征pv的距离要求收益,表示为:其中,h0为一个正值常数,ssv是sv在当前时间步t的纵向位置,spv是pv在当前时间步t的纵向位置。
32、具体的,决策判断子模块的决策过程如下:决策判断子模块从换道收益函数子模块获得当前时间步t的sv收益函数结果及pv收益函数结果,首先判断此时sv的换道收益rlane是否大于保持在原车道行驶的车道保持收益rstay,若此时sv的换道收益rlane不大于保持在原车道行驶的车道保持收益rstay,则决策判断子模块判断此时不具备换道前提,输出自车sv应当车道保持的决策;若此时sv的换道收益rlane大于保持在原车道行驶的车道保持收益rstay,则决策判断子模块判断此时具备换道前提;随后计算pv避让减速收益及pv不避让收益,比较两者的收益数值,认为pv将采取具备更大收益数值的动作:如果pv避让减速收益大于等于不避让收益,则判断pv采取避让减速动作,如果pv避让减速收益小于不避让收益,则判断pv采取不避让动作,据此给出此时自车sv是否应当换道或继续车道保持的决策:如果判断pv的动作为避让减速,则此时决策判断子模块的输出决策为换道;如果判断pv的动作为不避让,则此时决策判断子模块的输出决策为车道保持,随后决策判断子模块将决策传入换道性能基线评估模块的决策评估子模块,将pv收益函数的各项权重传入权重自学习子模块。
33、进一步的,所述的换道性能基线评估模块的工作过程如下:首先,将从数据集中提取的目标车道后车运动学信息、自车运动学信息、周围车运动学信息,以及驾驶风格量化模块的驾驶风格量化数据作为当前状态,经过数据预处理后传入已训练完成的数据驱动的换道决策子模块,已训练完成的数据驱动的换道决策子模块依据传入的当前状态,输出当前sv的动作,即换道或是车道保持,随后将动作传入决策评估子模块,决策评估子模块依据换道决策模块的决策判断子模块传入的sv当前应当换道或是车道保持的决策,与数据驱动的换道决策子模块的输出进行对比,评估当前数据驱动的换道决策子模块的输出决策结果与换道决策模块的决策判断子模块的输出决策结果哪一个更优,随后将评估结果输出至基线自评估器及换道决策模块的权重自学习子模块,权重自学习子模块根据决策评估子模块的评估结果,动态调整pv收益函数的各项权重,基线自评估器根据决策评估子模块的评估结果,决定当前权重自进化过程是否可以终结。
34、具体的,传入已训练完成的数据驱动的换道决策子模块前的数据预处理的过程如下:
35、将从数据集中获取的目标车道后车运动学信息、自车运动学信息、周围车运动学信息,以及驾驶风格量化模块的驾驶风格量化数据xd组成状态数据集sd:
36、
37、其中,i代表该状态是从数据集中提取的第i个时序序列,0≤i≤ne;对于第i个时序状态序列sd(i),表示为:
38、
39、其中,t代表当前状态数据为第t个采样点的状态数据,0≤t≤te,第i个时序序列sd(i,t)在第t个采样点的状态数据表示为:
40、sd(i,t)=[epv(i,t),esv(i,t),efv1(i,t),efv2(i,t),xd(i)]
41、其中,epv(i,t)表示目标车道后车pv在第t个采样点的运动学信息,esv(i,t)表示自车sv在第t个采样点的运动学信息,efv1(i,t)表示自车换道前所在车道前车fv1在第t个采样点的运动学信息,efv2(i,t)表示目标车道前车fv2在第t个采样点的运动学信息,xd(i)表示对第i个时序序列的pv的驾驶风格量化数据。
42、具体的,所述的数据驱动的换道决策子模块的训练过程如下:
43、首先从状态数据集sd中任意取出一个时序状态序列sd(i),随后将时序状态序列的每一个采样点的状态数据按时序顺序依次传入数据驱动的换道决策子模块;在第t个时间步,sd(i,t)被传入,数据驱动的换道决策子模块中的深度q网络计算出当前动作状态价值并做出动作at,其中动作at为车道保持或换道的两个离散动作之一,为深度q网络的模型参数,随后来到第t+1个时间步,sd(i,t+1)被传入,数据驱动的换道决策子模块中的深度q网络获得由自身回报函数rs(t)定义的真实奖励rt,基于最大化此时的动作状态价值的原则,预估动作at+1=argmaxq(st+1,a,ω),计算时序目标其中0<γ<1,为最小化损失loss:进行梯度下降更新模型参数:其中η为一个正值常数;
44、重复上述步骤直至模型参数收敛,数据驱动的换道决策子模块即训练完成。训练完成后,通过在时间步t时将sd(i,t)传入数据驱动的换道决策子模块,数据驱动的换道决策子模块输出在时间步t时的决策。
45、进一步的,数据驱动的换道决策子模块的深度q网络的回报函数rs(t)定义如下:
46、
47、其中,μ1、μ2、μ3为常值系数,vsv(t)表示从esv(i,t)获取的sv纵向速度信息,vfv1(t)表示从efv1(i,t)获取的fv1的纵向速度信息,vfv2(t)表示从efv2(i,t)获取的fv2的纵向速度信息,ssv(t)表示从esv(i,t)获取的sv的纵向位置信息,spv(t)表示从epv(i,t)获取的pv的纵向位置信息,sd为危险阈值。
48、具体的,所述的决策评估子模块的评估过程如下:
49、决策评估子模块接收来自换道决策模块的决策判断子模块的决策动作a1及数据驱动的换道决策子模块的决策动作a2,依据这两个动作的输出值,根据如下判断规则决定动作的优劣并动作:
50、(1)若a1=a2=车道保持,则此刻由于换道行为未发生,决策评估子模块仅向基线自评估器输出决策一致的信息。
51、(2)若a1=车道保持,a2=换道,则此刻决策评估子模块利用三次多项式方法,保持换道开始时刻及换道完成时刻的速度一致,换道时长为tlanec规划换道路线并尝试换道;在尝试换道过程中,周围车及pv的行驶轨迹依靠已从数据集中获得的运动学信息进行更新,sv的行驶轨迹依据所规划的换道路线进行更新:如果尝试换道过程中出现sv与pv的纵向间距低于安全阈值sd的情形,则认为此刻进行换道是劣于车道保持的,因此决策评估子模块仅向基线自评估器输出换道决策模块更优的信息;如果尝试换道过程中sv与pv的纵向间距始终高于安全阈值sd,则认为此刻进行换道是优于车道保持的,因此决策评估子模块向换道决策模块的权重自学习子模块输出当前可以换道的信息,并向基线自评估器输出决策不一致的信息。
52、(3)若a1=换道,a2=换道,则此刻由于动作一致,故决策评估子模块仅向基线自评估器输出决策一致的信息。
53、(4)若a1=换道,a2=车道保持,则此刻决策评估子模块利用三次多项式规划换道路线并尝试换道;在尝试换道过程中,周围车及pv的行驶轨迹依靠已从数据集中获得的运动学信息进行更新,sv的行驶轨迹依据所规划的换道路线进行更新:如果尝试换道过程中出现sv与pv的纵向间距低于安全阈值sd的情形,则认为此刻进行换道是劣于车道保持的,因此决策评估子模块向换道决策模块的权重自学习子模块输出当前换道存在风险的信息,并向基线自评估器输出决策不一致的信息;如果尝试换道过程中sv与pv的纵向间距始终高于安全阈值sd,则认为此刻进行换道是优于车道保持的,因此决策评估子模块仅向基线自评估器输出换道决策模块更优的信息。
54、具体的,所述的基线自评估器的运作过程如下:
55、基线自评估器接收决策评估子模块输出的信息,并每隔m(m为正值常数)个数据统计其中换道决策模块更优的信息的个数h1,决策不一致的信息h2,决策一致信息h3,如果且则认为此时决策判断子模块的决策已经显著优于数据驱动的换道决策子模块的决策,权重自进化过程终止,否则权重自进化过程继续进行;其中β0、β1为大于零的正值常数。
56、具体的,所述的权重自学习子模块的运作过程如下:
57、权重自学习子模块接收决策判断子模块的pv收益函数的各项权重及决策评估子模块输出的信息:
58、(1)当接收到来自决策评估子模块的当前换道存在风险的信息时,即认为此时对于pv的收益函数中的速度收益项的权重存在低估,因此权重自学习子模块按如下公式调整pv收益函数spricepv的权重ω1、ω2为新权重ω1'、ω'2:
59、1-ω1'→ω'2,其中α为一个正的常值系数。
60、(2)当接收到来自决策评估子模块的当前可以换道的信息时,即认为此时对于pv的收益函数中的距离收益项的权重存在低估,因此权重自学习子模块按如下公式调整pv收益函数spricepv的权重ω1、ω2为新权重ω1'、ω'2:
61、1-ω'2→ω1',其中α为一个正的常值系数。
62、(3)当未接收到来自决策评估子模块的信息时,权重自学习子模块不对pv收益函数的各项权重做出调整。
63、随后,权重自学习子模块将最新的pv收益函数的各项权重及其对应的驾驶风格量化数据传入驾驶风格及动态权重存储子模块中储存。
64、具体的,驾驶风格及动态权重存储子模块的运作过程如下:
65、首先,驾驶风格及动态权重存储子模块接收来自权重自学习子模块新传入的pv收益函数的各项权重及其对应的驾驶风格量化数据;然后,驾驶风格及动态权重存储子模块查询当前存储中是否有与新传入的驾驶风格量化数据一致的驾驶风格量化数据记录,做出如下操作:
66、(1)存在与新传入的驾驶风格量化数据一致的驶风格量化数据记录,则驾驶风格及动态权重存储子模块更新原记录,用新传入的pv收益函数的各项权重覆盖原pv收益函数的各项权重记录。
67、(2)不存在与新传入的驾驶风格量化数据一致的驶风格量化数据记录,则驾驶风格及动态权重存储子模块将新传入的pv收益函数的各项权重及其对应的驾驶风格量化数据作为一个记录保存在存储中。
68、本发明提供的一种权重自进化的智能汽车个性化换道决策系统的权重自进化学习总体流程如下:
69、步骤一,提取数据集中目标车道后车运动学信息、自车运动学信息及周围车运动学信息,随后将上述信息送入驾驶风格量化模块、换道决策模块及换道性能基线评估模块;首先从数据集中随机抽取一条行驶信息,一条行驶信息包括一个换道过程各个时间步的目标车道后车运动学信息、自车运动学信息及周围车运动学信息;在时间步t时,传入驾驶风格量化模块的信息为该条行驶信息的目标车道后车从时间步t-t+1至时间步t期间共t时间内的运动学信息;在时间步t时,传入换道决策模块及换道性能基线评估模块的信息为该条行驶信息在时间步t时的目标车道后车运动学信息、自车运动学信息及周围车运动学信息。
70、步骤二,驾驶风格量化模块首先将目标车道后车运动学信息传入运动学特征提取子模块,运动学特征提取子模块对传入的运动学信息进行数据预处理及数据特征提取,随后将处理后的信息传入驾驶风格评估子模块,驾驶风格评估子模块中训练完成的高斯混合模型接收上述信息,并依据所获得的信息给出目标车道后车的各驾驶风格量化概率包括:谨慎型的概率xd1、一般型的概率xd2、激进型的概率xd3,并将概率xd1、xd2、xd3输出至驾驶风格量化数据暂存子模块,驾驶风格量化数据暂存子模块将数据整理为一个一行三列的向量xd=[xd1,xd2,xd3],即驾驶风格量化数据,并存储在数据暂存器中;当有新的驾驶风格量化数据传输至驾驶风格量化数据暂存子模块后,数据暂存器中储存的先前数据将会被新的量化数据覆盖。
71、步骤三,换道决策模块依据目标车道后车运动学信息、自车运动学信息及周围车运动学信息及驾驶风格量化模块的驾驶风格量化数据,通过换道收益函数子模块计算sv和pv的收益函数,将计算结果及pv收益函数的各项权重输出至决策判断子模块;决策判断子模块将决策判断结果输出至换道性能基线评估模块的决策评估子模块,将pv收益函数的各项权重输出至权重自学习子模块。
72、步骤四,换道性能基线评估模块的数据驱动的换道决策子模块依据目标车道后车运动学信息、自车运动学信息、周围车运动学信息及驾驶风格量化模块的驾驶风格量化数据,输出决策结果至决策评估子模块。
73、步骤五,决策评估子模块评估当前数据驱动的换道决策子模块的输出决策结果与换道决策模块的决策判断子模块的输出决策结果哪一个是更优的,随后将评估结果输出至换道决策模块的权重自学习子模块及基线自评估器。
74、步骤六,权重自学习子模块根据决策评估子模块的评估结果,动态调整pv收益函数的各项权重,并将最新的pv收益函数的各项权重及从驾驶风格量化数据暂存子模块获得的对应驾驶风格量化数据传入换道决策模块的驾驶风格及动态权重存储子模块中,驾驶风格及动态权重存储子模块储存传入的信息。
75、步骤七,基线自评估器根据决策评估子模块的评估结果,决定当前权重自进化过程是否可以终结,若权重尚未调整到最优状态,则重复步骤一至步骤七;若权重已经调整到最优状态,则权重自进化过程终结。
76、本发明的有益效果:
77、1.本发明所述一种权重自进化的智能汽车个性化换道决策系统通过分析邻近车道后车在自车产生换道意图时的运动学显式特征,实现了后车运动学参数与后车驾驶人驾驶风格之间关系的抽象表征,并进一步建立驾驶风格量化指标,通过概率模型量化描述后车驾驶人的驾驶风格及不同驾驶风格间的差异;
78、2.本发明所述一种权重自进化的智能汽车个性化换道决策系统深入考虑实际换道过程中车间的行为交互,建立了基于博弈思想的换道决策模块,使所述系统可以显式表达换道期间动态时变的车辆间交互现象,进而使得换道决策逻辑清晰透明,增强了算法的可解释性。通过综合考虑多方面的行车收益,建立了具备实际含义的多权重博弈收益函数,依据该收益函数进行换道决策,提高了系统决策输出的稳定性;
79、3.本发明所述一种权重自进化的智能汽车个性化换道决策系统通过动态调节博弈收益函数权重,大幅提高了换道决策系统的工况适应性与灵活性,引入基于深度强化学习的换道性能基线评估模块,并与驾驶风格量化模块形成耦合联系,从而建立了驾驶风格与换道决策结果间的量化映射关系,并使得所建立的换道决策系统具备了自主学习能力,能够在各类复杂多变的行驶工况中取得良好的性能表现,使得通过数据驱动方法引导换道决策系统稳定提升成为可能。
- 还没有人留言评论。精彩留言会获得点赞!