电梯异响检测方法及系统与流程
本发明涉及一种电梯异响检测方法及系统。
背景技术:
电梯在现代生活的各个领域中得到了广泛的使用,其工作特点是高效率垂直运行。电梯在给人们带来极大便利的同时,也伴随着一定的风险,如电梯的撞击,坠落以及设备因保养不当带来的安全隐患。电梯在运行过程中发出异常声响,如抖动、碰撞等声音,这是存在安全隐患的信号,实现准确的识别电梯运行过程中的异常声响对确保电梯的安全运行十分重要,能为电梯机械部件潜在安全隐患识别和故障诊断提供技术支持。
目前已有的技术中,主要是采用在指定零部件上安装检测设备的方式来检测具体零部件是否发生故障。依据现有的技术,虽然能够在一定程度上对电梯运行过程中的发出的异响进行检测,但是现有的技术严重依赖了硬件设备,并且大多数是针对某一零部件进行检测。在使用成本,和实际效果上都有待商榷。例如专利208907833u公开的一种电梯反绳轮异响检测装置,采用安装异响检测装置的方式来实现,对电梯某个零部件实现异响检测。该技术使用了声音传感器,a/d电路,数据分析电路,控制器以及加油电路,对电梯运行状态进行实时监测,成本高昂,并且只能对单一零部件实现异响监测,存在一定的局限性。
当然,也存在一些采用音频特征识别异响的技术,例如专利cn111634777a公开的电梯异常运行状态的监测方法及装置。该专利中,通过采集电梯轿厢声谱,并将实时声谱和预设的异常声谱对比,从而确定电梯是否发生异响。这种手段虽然能初步检测出异响的发生,但是,在不同电梯上应用时,其异常声谱一定会有所不同。因此其中包含的异常声响数据并不适用于对应电梯,所以导致检测精度不高,很容易出现漏检从而发生危险。
技术实现要素:
本发明的目的在于提供一种适应性更广的电梯异响检测方法和系统。
为实现上述目的,本发明提供一种电梯异响检测方法,包括以下步骤:
a、采集电梯轿厢的视频录像,并从中提取音频数据;
b、对所述音频数据进行预处理,并从中提取音频特征;
c、将音频数据输入检测模型,识别电梯在当前时刻是否发生异响;
d、若判断电梯在当前时刻发生异响,则进而根据异响的幅值大小决定是否发出告警信号。
根据本发明的一个方面,在所述步骤(b)中,所述预处理包括滤波、降噪和/或去除奇异值;
所述音频特征包括过零率、频域能量、频谱质心和/或梅尔到普系数。
根据本发明的一个方面,在所述步骤(c)中,所述检测模型在线下训练,并上传至线上,其训练步骤包括特征选择、模型训练、模型测试、模型评估与验证;
所述特征选择的算法为穷举法、方差选择法或相关系数法;
所述模型评估与验证的指标包括精确率或召回率之一或二者加权的f1分数。
根据本发明的一个方面,在所述步骤(c)中,将所述音频数据与预设的数据库对比,识别其中的正常样本和异响样本,若所述音频数据的异响样本少于2000条,则训练无监督异常检测模型作为所述检测模型;反之,则训练有监督学习分类模型作为所述检测模型。
根据本发明的一个方面,所述无监督异常检测模型为无监督聚类、isolationfroest、oneclasssvm、autoencoder或ganormaly;
所述有监督学习分类模型为randomforesets、lightgbm、xgboost之一或多个的集成;或者为lstm、cnn、gcn或gru。
根据本发明的一个方面,在所述步骤(c)中,若所述检测模型输出的异响概率大于概率阈值,则判断为发生异响,所述概率阈值为0.8。
根据本发明的一个方面,所述检测模型为lstm,则所述异响概率的计算流程为:
更新遗忘门的输出:
ft=σ(wf·[ht-1,xt]+bf);
式中,xt为当前时刻网络的输入,ht-1为上一时刻lstm的输出值,wf是遗忘门的权重矩阵,[ht-1,xt]表示把两个向量连接成一个更长的向量,bf是遗忘门的偏置项,σ是sigmoid函数;
更新输入门的两部分输出:
it=σ(wi·[ht-1,xt]+bi);
以及
式中,ct为单元状态,其由上一时刻的单元状态ct-1按元素乘以遗忘门ft,再用当前输入的单元状态
更新细胞状态:
式中,
更新输出门状态:
ot=σ(wo·[ht-1,xt]+bo);
以及
更新当前序列输出:
式中,v为权重矩阵,by是偏置。
全连接层计算:
y=x·w+b
式中,x为输入,w为权重矩阵,b是偏置。
softmax概率值输出:
式中,i∈[1,k],zi是神经网络模型第i个节点输出值,c为输出节点个数。
根据本发明的一个方面,在所述步骤(d)中,若异响的声音幅值大于幅值阈值,则发出告警信号;
在发出告警信号时,同时发出包含电梯在当前时刻所处楼层的楼层信息;
利用数字识别模型在所述视频录像中识别电梯轿厢内的楼层显示数据得到所述楼层信息;
所述幅值阈值为0.9。
电梯异响检测系统,包括:
采集模块,用于采集视频录像,并从中提取音频数据;
预处理模块,用于对音频数据进行预处理;
特征构造模块,用于提取经过预处理的音频数据中的音频特征,并识别其中的正常样本与异响样本;
模型拟合模块,用于根据异响样本的数量训练无监督异常检测模型或有监督学习分类模型作为检测模型;
异响识别模块,用于判断电梯在当前时刻是否发生异响并根据异响的严重程度决定是否发出告警信号;
楼层定位模块,用于识别电梯所处楼层并将楼层信息作为辅助信息与告警信号一并发出。
根据本发明的构思,利用实时采集的音频数据来训练检测模型,从而使得所训练的模型是对因关于当前电梯的模型,相比于简单地将音频数据与数据库对比的方式,其适应性更广,且检测精度更高。
根据本发明的一个方案,直接从电梯监控视频中提取音频数据,由此不需要使用大量传感器设备即可获得检测所用的数据,极大的降低了使用成本。另外,这种方式使得本发明不针对某一具体零部件进行故障诊断,可以对电梯大多数异响的音频特征进行分析,从而实现准确地对各类异响进行检测,并及时发出告警。并且,还利用数字识别模型根据视频和音频信号推断出发生异响的楼层,方便维保人员准确的定位故障楼层。如此,本发明极大的降低了对硬件设备的要求,并且能够识别大多数电梯在运行过程中产生的异响。
根据本发明的一个方案,根据异响样本的数量自适应的选择有、无监督的模型作为训练目标,这样可以保证最优的检测效果。
根据本发明的一个方案,在线下训练模型然后再上传至线上。这种方式不会占用太多资源,也不会影响其他线上任务。并且,线下训练的方式更方便调整。
附图说明
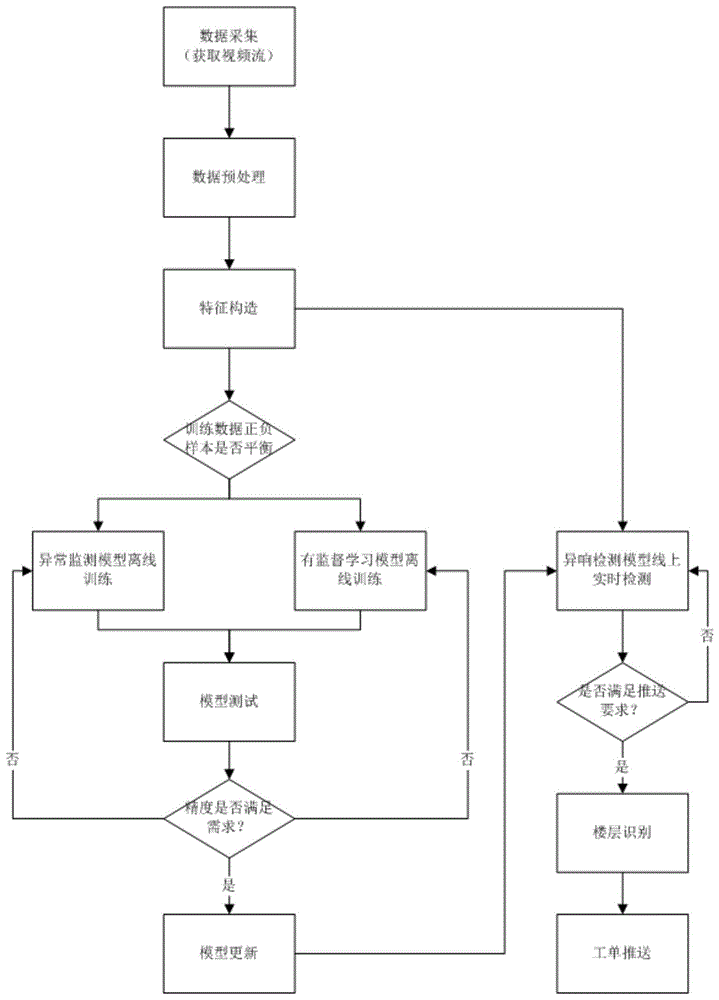
图1是示意性表示根据本发明的一种实施方式的电梯异响检测方法的流程图;
图2是异响样本的音频特征图;
图3是正常样本的音频特征图。
具体实施方式
为了更清楚地说明本发明实施方式或现有技术中的技术方案,下面将对实施方式中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是本发明的一些实施方式,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
下面结合附图和具体实施方式对本发明作详细地描述,实施方式不能在此一一赘述,但本发明的实施方式并不因此限定于以下实施方式。
参见图1,本发明的电梯异响检测方法中,首先采集电梯轿厢的视频录像,并从中提取音频数据。实际上,采集视频录像即为调用电梯内视频监控录像。由此,可以从视频录像中提取音频数据,以将这些实时的音频数据输入至在线的检测模型中进行检测。
根据本发明的构思,不仅利用这些音频数据进行实时检测,还利用之作为检测所用的模型的学习目标,即线下训练检测模型。如此,利用实时数据离线地训练模型,再将训练好的模型上传至线上,从而实现了检测模型适应于相应的电梯,从而能够使检测更加全面,使得本发明适用性更广。
为了获取更高质量的数据,以保证检测模型的检测精度,本发明还对音频数据进行预处理。预处理包括滤波、降噪和/或去除奇异值等,从而可以保证检测模型的效果。音频数据经过预处理以后,需要提取其中的音频特征,作为后续检测和训练模型的基础。具体的,音频特征包括过零率、频域能量、频谱质心和/或梅尔到普系数等重要特征。部分特征的频谱如图2和图3所示,从这两图中可以看出,正常样本和异响样本的频谱存在明显区别,因此可以提前设立一个异响样本数据库,这些样本均具有标签。这样,在提取完音频特征后,可以自动的识别出实时音频数据中的异响(负)样本数量,后续的模型训练步骤即可根据正负样本的比例选择性地训练模型。
具体的,经过特征提取后即可将音频数据输入至检测模型中进行检测。本发明中,检测模型分为两种,分别为无监督异常检测模型和有监督学习分类模型,可根据异常样本的数量决定训练哪一种模型。但每种模型的训练步骤均包括特征选择、模型训练、模型测试、模型评估与验证。在特征选择过程中可以根据特征维度的高低自适应的匹配特征选择算法,其包括穷举法、方差选择法或相关系数法等。模型评估与验证的步骤目的在于评估模型的检测效果,其评估指标包括精确率或召回率之一或二者加权的f1分数(即f1-score)。当异常样本数量严重不足时,即音频数据的正负样本严重失衡,则训练无监督异常检测模型作为检测模型;反之,若异常样本数量充足时,则训练有监督学习分类模型作为检测模型。在本发明中,异常样本量少于2000条即视为严重不足。无监督异常检测模型可自适应的选择异常检测方法或者深度学习方法,例如无监督聚类、isolationfroest、oneclasssvm、autoencoder或ganormaly等。有监督学习分类模型可以选用机器学习模型,如randomforesets、lightgbm、xgboost之一或多个模型集成的方法。当然,有监督学习分类模型也可以自适应的选择深度学习模型,如lstm、cnn、gcn或gru,也可提高检测效果。如上述步骤即可根据样本量来自适应的训练得到检测模型,将其上传至线上后即可用来实时检测。在实时检测过程中,将音频数据输入在线的检测模型,检测模型会对音频数据进行处理。在本实施方式中,检测模型为lstm,即长短期记忆(longshorttermmemory,lstm)网络模型。lstm的输入有三个,分别为当前时刻网络的输入xt(即音频数据)、上一时刻lstm的输出值ht-1以及上一时刻的单元状态ct-1。lstm的输出有两个,分别为当前时刻lstm输出值ht和当前时刻的单元状态ct。在本发明中,x、h、c均为向量。同时,lstm中引入了三个门:遗忘门(forgetgate)、输入门(inputgate)和输出门(outputgate)。遗忘门决定了上一时刻的单元状态ct-1有多少保留到当前时刻ct。输入门决定了当前时刻网络的输入xt有多少保留到单元状态ct。输出门来控制单元状态ct有多少输出到lstm的当前输出值ht。其中,lstm各门的计算逻辑如下:
遗忘门计算:
ft=σ(wf·[ht-1,xt]+bf)
其中,wf是遗忘门的权重矩阵,[ht-1,xt]是表示把两个向量连接成一个更长的向量,bf是遗忘门的偏置项,σ是sigmoid函数。
输出门计算:
it=σ(wi·[ht-1,xt]+bi)
单元状态计算:
以及
式中,ct单元状态,其由上一时刻的单元状态ct-1按元素乘以遗忘门ft,再用当前输入的单元状态
输出门:
ot=σ(wo·[ht-1,xt]+bo);
lstm最终的输出,是由输出门和单元状态共同确定的,即:
综合上述,本实施方式利用lstm的计算流程为:
更新遗忘门的输出:
ft=σ(wf·[ht-1,xt]+bf);
更新输入门的两部分输出:
it=σ(wi·[ht-1,xt]+bi);
以及
更新细胞状态:
更新输出门状态:
ot=σ(wo·[ht-1,xt]+bo);
以及
更新当前序列输出:
式中,v为权重矩阵,by是偏置。
全连接层计算:
y=x·w+b
式中,x为输入,w为权重矩阵,b是偏置。
softmax概率值输出:
式中,i∈[1,k],zi是神经网络模型第i个节点输出值,c为输出节点个数,即分类的类别个数。
当模型输出当前数据发生异响的概率大于模型的概率阈值时,则判断为出现异响。本发明中,概率阈值为0.8,这一数值选取能够保证正确的判断是否真实发生异响。当判断出现异响后,需要进而判断异响的严重程度,若异响较为严重,即声音幅值大于幅值阈值,则发出告警信号。本发明中,幅值阈值为0.9,这一设定可以准确地判断出异响的严重程度。本发明在告警的同时还告知维保人员电梯发生异响的楼层,以便人员清楚的知道异响发生位置。具体的,利用数字识别模型识别视频录像中的电梯轿厢内的楼层显示信息的数字,从而确定电梯当前所处楼层。而此楼层信息作为辅助信息随告警信息一并发出。
本发明的电梯异响检测系统,包括采集模块、预处理模块、特征构造模块、模型拟合模块、异响识别模块和楼层定位模块。采集模块用于采集视频录像,并从中提取音频数据。本发明中,采集模块即为电梯轿厢内的监控设备,其需同时具有视频和音频采集功能。预处理模块和特征构造模块则分别用于对音频数据进行预处理和提取经过预处理的音频数据中的音频特征,并识别音频数据中的正常样本和异响样本。对于这两个模块,其只要集成有上述方法中的算法即可但是,特征构造模块还应具备异响数据库。模型拟合模块则用于根据异响数据的数量训练无监督异常检测模型或有监督学习分类模型作为检测模型。异响识别模块用于判断电梯是否发生异响并根据异响的严重程度决定是否发出告警信号。楼层定位模块用于识别电梯所处楼层并将楼层位置作为辅助信息与告警信号一并发出。
以上所述仅为本发明的一个实施方式而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!