锅炉节煤控制方法与流程
本发明涉及电子
技术领域:
,特别是一种锅炉节煤控制方法。
背景技术:
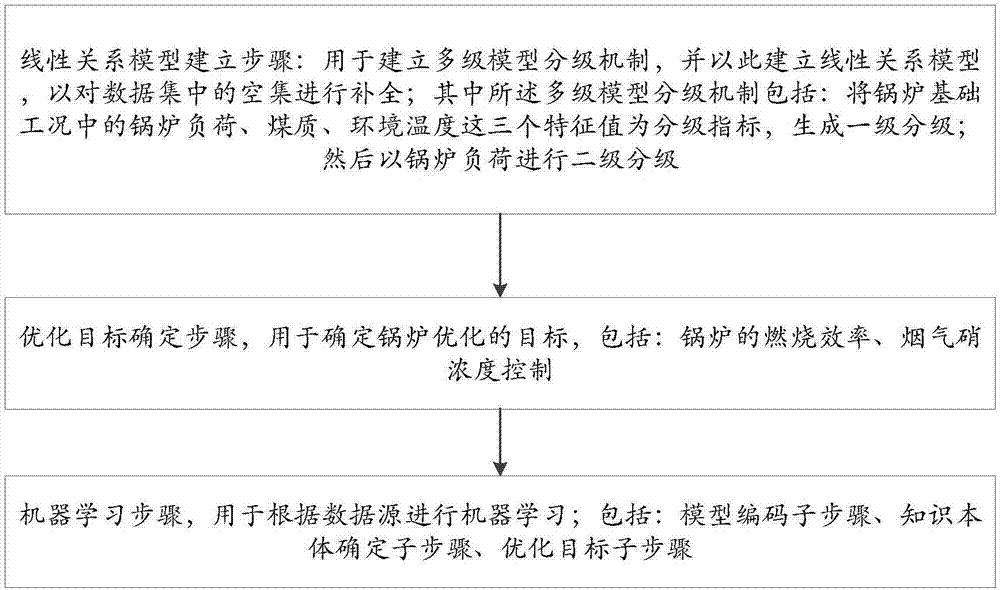
锅炉节煤是火电厂关注的重要课题,而节煤控制的最重要的一个环节就是要实时获取锅炉的炉膛内的环境参数,这样才可能实现锅炉的节煤控制。但是由于炉膛内的环境非常恶劣,因此要求炉膛内的检测节点具有极强的防护能力,且同时还要能获得准确的检测参数;否则就无法准确获取锅炉燃烧状态,无法有效的进行节煤控制。现有技术中提出了一种炉膛燃烧状态虚拟还原技术,其是利用激光光谱分析测量探头网来还原炉膛燃烧状态。这种技术具有非常好的检测效果,能够解决指导燃烧优化问题;但是其组网时需要上百个激光测量探头,而每一个激光测量探头的成本都在30万人民币以上;这样导致整个系统的成本极高,无法大范围推广。技术实现要素:针对现有技术中存在的问题,本发明实施例的目的是提供一种锅炉节煤控制方法,能够利用机器学习技术来对锅炉炉膛环境参数进行预测,以在降低成本的情况下获取锅炉炉膛的环境参数。为了达到上述目的,本发明实施例提出了一种锅炉节煤控制方法,包括:线性关系模型建立步骤、优化目标确定步骤、机器学习步骤;其中,线性关系模型建立步骤:用于建立多级模型分级机制,并以此建立线性关系模型,以对数据集中的空集进行补全;其中所述多级模型分级机制包括:将锅炉基础工况中的锅炉负荷、煤质、环境温度这三个特征值为分级指标,生成一级分级;然后以锅炉负荷进行二级分级;其中锅炉负荷是以每50mw为跨度对锅炉负荷进行分级;其中煤质是以吨煤功率进行分级,其中吨煤功率=有用功率/给煤量;其中环境温度是以季节指标或循环水温度进行分级;其中锅炉负荷的二级分级是将一次分级的锅炉负荷这一特征值进行进一步的二级分级,将锅炉负荷以1mw的跨度进一步进行细分,以确定以下锅炉参数之间的建立线性关系模型:锅炉负载、每一磨煤机的瞬时给煤率、每一磨煤机的冷一次风开度、每一磨煤机的热一次风、综合风门开度、各一次风机变频指令与挡板开度、4个上层燃尽风摆角及其开度、4个下层燃尽风摆角及其开度;然后利用该线性关系模型结合偏微分理论,对数据中的空集进行补全;其中,优化目标确定步骤,用于确定锅炉优化的目标,包括:锅炉的燃烧效率、烟气硝浓度控制;具体包括:判断锅炉的燃烧效率,数据源中是否包括燃烧效率字段,如果否,则计算燃烧效率因数作为锅炉的燃烧效率;确定锅炉的nox浓度控制值;其中,机器学习步骤,用于根据数据源进行机器学习;包括:模型编码子步骤、知识本体确定子步骤、优化目标子步骤;其中:模型编码子步骤用于生成基础工况与模型之间的映射关系,以根据基础工况确定对应的模型;其中,模型编码=环境温度编码+锅炉负荷等级编码×环境温度编码权+吨煤功率比编码×锅炉负荷等级编码权×环境温度编码权;环境温度编码:本发明实施例中可以使用季节为指标,也可以使用循环水温度为指标;当使用季节为指标,则编码=0(冬季)或1(夏季);当使用循环水温度为指标,则将循环水温度分为10个等级,且对应的编码为0~9;环境温度编码权=16;锅炉负荷等级编码:每50mw为1个分级,并为每一级别设定一个编码数值;锅炉负荷等级编码权=16;吨煤功率比编码=取整函数((吨煤功率–吨煤功率最低值)/吨煤功率分级跨度);吨煤功率分级跨度=(吨煤功率最高值-吨煤功率最低值)/10;吨煤功率=有用功率/给煤量;基础工况的二次分级对应模型内的一个等级队列,保存了该模型接受到的细分实例;在保存实例时,利用差分法计算锅炉负荷的单位变化量对应的各因素的平均变化量,这些变化量就是各因素方向的偏微分值;生成优化方案时,如果存在当前基础工况对应的实例时,直接使用;如果不存在,取第一个实例做基准,根据锅炉负荷的差值和各因素方向的偏微分值,计算各因素的理论值;知识本体确定子步骤,用于确定与锅炉燃烧效益相关的所有可操作的设备的状态;其中各状态包括:各磨煤机的瞬时给煤率;各磨煤机的冷一次风开度;各磨煤机的热一次风开度;综合风门开度;各一次风机变频指令与挡板开度;4个上层燃尽风摆角及其开度;4个下层燃尽风摆角及其开度;4层二次风摆角及其开度;二次风总风量;优化目标子步骤,用于生成知识本体的排序规则;具体包括:当数据源包括锅炉燃烧效率时,排序规则如下:如果2个知识本体所对应的燃烧效率均小于等于97%,燃烧效率越高的排前;如果2个知识本体所对应的燃烧效率均大于97%,nox浓度低的排前;如果2个知识本体所对应的燃烧效率,一个小于等于97%,一个大于97%,小于等于97%的排前;数据源不包括锅炉燃烧效率时,使用锅炉燃烧效率因数代替锅炉燃烧效率,排序规则如下:如果2个知识本体所对应的燃烧效率因数均小于等于30,燃烧效率因数越高的排前;如果2个知识本体所对应的燃烧效率因数均大于30,nox浓度低的排前;如果2个知识本体所对应的燃烧效率因数,一个小于等于30,一个大于30,小于等于30的排前;其中,燃烧效率因数=100/|(排烟温度-排烟温度最低标准)*(排烟含氧量-负荷含氧因子)|;排烟温度最低标准=110。进一步的,所述机器学习步骤还包括:限制条件子步骤,用于生成禁止学习的规则和不推荐的规则,并将禁止学习的规则和不推荐的规则直接删除;本发明实施例中限制条件的知识本体包括:烟道温度低于标准,例如110°;或锅炉负荷小于20%;主汽温度与设定值的偏差的绝对值、一/二次再热温度与设定值的偏差的绝对值,大于配置的最大偏差。进一步的,所述机器学习步骤还包括:稳态筛选子步骤,当动态工况下的数据剧烈变化,导致无法稳定反应机组能效和排放与可操作因子之间的关系,则将该数据筛除;其中稳态筛选子步骤覆盖的测点范围包括:锅炉负荷、再热汽温、再热汽压;且还可以包括以下的一种:主汽温度、主汽压力、循环水温度。进一步的,所述机器学习步骤还包括:优化建议子步骤,用于在确定当前基础工况条件下有更优操作方案时,将操作方案按优化规则进行排序后进行显示;其中优化规则包括以下的至少一项:磨煤机的瞬时给煤率、冷一次风开度、热一次风开度、综合风门开度、各一次风机变频指令与挡板开度、4个上层燃尽风摆角及其开度、4个下层燃尽风摆角及其开度、4层二次风摆角及其开度、二次风总风量。本发明的上述技术方案的有益效果如下:上述技术方案提出了一种锅炉节煤控制方法,以提升燃烧效率为目标,以无害化为前提,采用大数据和人工智能技术对影响锅炉燃烧效率的主要因素(煤侧因素、风侧因素)进行分析以得到提升燃烧效率的优化建议,达到节煤的智能辅助决策的目的。上述技术方案不需要改变锅炉燃烧结构和原理、不需要增加额外测点,在不影响正常生产的前提下,通过机器学习的方法,提供安全、便捷、合理的操作建议,达到提升锅炉的燃烧效率、节煤增效的目标。附图说明图1为本发明实施例的流程图。具体实施方式为了说明本发明下面结合附图和具体实施方式对本发明作进一步详细的说明。本发明实施例提出了一种锅炉节煤控制方法,以提升燃烧效率为目标,以无害化为前提,采用大数据和人工智能技术对影响锅炉燃烧效率的主要因素(煤侧因素、风侧因素)进行分析以得到提升燃烧效率的优化建议,达到节煤的智能辅助决策的目的。其中,无害化的前提是指:1、对汽机侧:方案不能影响主汽机温度、一次再热温度、二次再热温度。2、对环保侧:烟气的nox浓度不能过高。3、结焦不能变严重。上述技术方案不需要改变锅炉燃烧结构和原理、不需要增加额外测点,在不影响正常生产的前提下,通过机器学习的方法,提供安全、便捷、合理的操作建议,达到提升锅炉的燃烧效率、节煤增效的目标。要提升锅炉的燃烧效率则需要明确燃烧效率由哪些因素决定。经过详细研究,影响锅炉的燃烧效率的主要因素包括:1、锅炉构造及燃烧原理,该元素为不变因素;2、煤质;3、煤侧相关因素,具体包括:磨机运行方式、磨机瞬时给煤率、一次风风量;4、风侧相关因素,具体包括:二次风总风量、燃尽风摆角与开度、二次风摆角与开度。由于不变因素是无法通过监测锅炉炉膛环境参数以进行锅炉节煤控制,因此本发明实施例中在进行锅炉节煤控制时只考虑可优化的可变因素,以提升锅炉的燃烧效益。同时为了满足无害化要求,需要在无害的前提下优化锅炉的燃烧效率以达到节煤效果。其中无害化的前提包括:1、对汽机侧:方案不能影响主汽机温度、一次再热温度、二次再热温度;2、对环保侧:烟气的nox浓度不能高于控制值;3、结焦不能变严重。在该前提下,本发明实施例提出了一种锅炉节煤控制方法,其包括:线性关系模型建立步骤:用于建立多级模型分级机制,并以此建立线性关系模型,以对数据集中的空集进行补全。在本发明实施例中,对于不同的基础工况要建立不同的优化模型以使优化建议更具有针对性;且建立了模型二次分级机制。基础工况选择的因素和划分颗粒的细度对优化方案的效果影响很大,划分颗粒的细度越细则结果越精确,但如果划分颗粒的细度过细就会导致空集趋向增多、可用性降低。本发明实施例采用了二级分级机制,具体包括:一次分级:以锅炉负荷、煤质、环境温度这三个特征值为分级指标,是基础工况的基本分级,颗粒度较大,解决了样板数不足的问题,包括:1)煤质分级:煤质是个重要因素,但煤质没有在线数据;本发明实施例中采用吨煤功率代表煤质;吨煤功率=有用功率/给煤量;2)锅炉负荷:以每50mw为跨度,对锅炉负荷进行分级;3)环境温度:环境温度会对燃烧效益产生影响;在本发明实施例中可以利用季节指标或循环水温度代表环境温度;在实际试验中发现使用循环水温度较季节指标更精确一些;其中二次分级是在一级分组的一个组内进一步进行分组,在本发明实施例中是将一次分级的锅炉负荷这一特征值进行进一步的二级分级,将锅炉负荷以1mw的跨度进一步进行细分,以确定以下锅炉参数之间的建立线性关系模型:锅炉负载、每一磨煤机的瞬时给煤率、每一磨煤机的冷一次风开度、每一磨煤机的热一次风、综合风门开度、各一次风机变频指令与挡板开度、4个上层燃尽风摆角及其开度、4个下层燃尽风摆角及其开度。然后利用该线性关系模型结合偏微分理论,可以对数据中的空集进行补全,这样既提升了模型计算精度又提升了可用性,解决了一次分级普遍存在的难题。优化目标确定步骤:用于确定锅炉优化的目标,包括:锅炉的燃烧效率、烟气硝浓度控制;具体包括:判断锅炉的燃烧效率,数据源中是否包括燃烧效率字段,如果否,则计算燃烧效率因数作为锅炉的燃烧效率;确定锅炉的nox浓度控制值。机器学习步骤:用于根据数据源进行机器学习;包括:模型编码子步骤、知识本体子步骤、优化目标子步骤、限制条件子步骤;其中:模型编码子步骤用于生成基础工况与模型之间的映射关系,以根据基础工况确定对应的模型;其中,模型编码=环境温度编码+锅炉负荷等级编码×环境温度编码权+吨煤功率比编码×锅炉负荷等级编码权×环境温度编码权;环境温度编码:本发明实施例中可以使用季节为指标,也可以使用循环水温度为指标;当使用季节为指标,则编码=0(冬季)或1(夏季);当使用循环水温度为指标,则将循环水温度分为10个等级,且对应的编码为0~9;环境温度编码权=16;锅炉负荷等级编码:每50mw为1个分级,并为每一级别设定一个编码数值;锅炉负荷等级编码权=16;吨煤功率比编码=取整函数((吨煤功率–吨煤功率最低值)/吨煤功率分级跨度);吨煤功率分级跨度=(吨煤功率最高值-吨煤功率最低值)/10;吨煤功率=有用功率/给煤量;基础工况的二次分级对应模型内的一个等级队列,保存了该模型接受到的细分实例。在保存实例时,利用差分法计算锅炉负荷的单位变化量对应的各因素的平均变化量,这些变化量就是各因素方向的偏微分值。生成优化方案时,如果存在当前基础工况对应的实例时,直接使用;如果不存在,取第一个实例做基准,根据锅炉负荷的差值和各因素方向的偏微分值,计算各因素的理论值。知识本体确定子步骤,用于确定与锅炉燃烧效益相关的所有可操作的设备的状态;其中该状态包括:各磨煤机的瞬时给煤率;各磨煤机的冷一次风开度;各磨煤机的热一次风开度;综合风门开度;各一次风机变频指令与挡板开度;4个上层燃尽风摆角及其开度;4个下层燃尽风摆角及其开度;4层二次风摆角及其开度;二次风总风量。优化目标子步骤,用于生成知识本体的排序规则;具体包括:当数据源包括锅炉燃烧效率时,排序规则如下:如果2个知识本体所对应的燃烧效率均小于等于97%,燃烧效率越高的排前;如果2个知识本体所对应的燃烧效率均大于97%,nox浓度低的排前;如果2个知识本体所对应的燃烧效率,一个小于等于97%,一个大于97%,小于等于97%的排前;数据源不包括锅炉燃烧效率时,使用锅炉燃烧效率因数代替锅炉燃烧效率,排序规则如下:如果2个知识本体所对应的燃烧效率因数均小于等于30,燃烧效率因数越高的排前;如果2个知识本体所对应的燃烧效率因数均大于30,nox浓度低的排前;如果2个知识本体所对应的燃烧效率因数,一个小于等于30,一个大于30,小于等于30的排前;其中,燃烧效率因数=100/|(排烟温度-排烟温度最低标准)*(排烟含氧量-负荷含氧因子)|;排烟温度最低标准=110,负荷含氧因子由下表确定:0-200千千瓦(含)1.15200-300千千瓦(含)1.64300-450千千瓦(含)1.55450-700千千瓦(含)1.37700-900千千瓦(含)1.22900以上千千瓦(含)1.15限制条件子步骤,用于生成禁止学习的规则和不推荐的规则,并将禁止学习的规则和不推荐的规则直接删除;本发明实施例中限制条件的知识本体包括:烟道温度低于标准,例如110°;或锅炉负荷小于20%;主汽温度与设定值的偏差的绝对值、一/二次再热温度与设定值的偏差的绝对值,大于配置的最大偏差。稳态筛选子步骤,当动态工况下的数据剧烈变化,导致无法稳定反应机组能效和排放与可操作因子之间的关系,则将该数据筛除;其中稳态筛选子步骤覆盖的测点范围包括:锅炉负荷、再热汽温、再热汽压;且还可以包括以下的一种:主汽温度、主汽压力、循环水温度。优化建议子步骤,用于在确定当前基础工况条件下有更优操作方案时,将操作方案按优化规则进行排序后进行显示;其中优化规则包括以下的至少一项:磨煤机的瞬时给煤率、冷一次风开度、热一次风开度、综合风门开度、各一次风机变频指令与挡板开度、4个上层燃尽风摆角及其开度、4个下层燃尽风摆角及其开度、4层(共16个)二次风摆角及其开度、二次风总风量。其中,该优化建议子步骤因为有了主汽机温度、一次再热温度、二次再热温度波动范围的限制,不会影响汽机的效能。同时,如果把燃烧效率因数目标设立在平衡点附近或更低些,则不会产生过多的nox。全部建议均来自历史操作的再现,因此对结焦的影响不会比以往更坏。同时由于系统中包括一个限制条件子步骤生成的不良操作规则库,因此在使用中如果发现新的违规操作建议,则可以加入不良操作规则库以避免推荐这类操作。上述技术方案的技术特点为:1、建立神经网络状态的在线知识网:在线知识网是机器学习之后,知识点的存储方式。在线知识网的优点是知识检索速度快,可支持较高的访问量,弱点是内存需求大,且对存储结构的高效性和节约性要求较高。2、强大的寻优能力:神经网络的所有子网络具备最优化能力,即子网络的根节点永远是子网络中的最优方案,所以历史寻优只需找到符合条件的第1个节点,就是全局最优点(高效、便捷)。3、建立负面规则库:根据负面规则库,自主发现违规操作,做到了违规的经验不学、违规的建议不出。4、不需要人为的给学习资料加标签,可以根据后续工况和规则,自主评价知识、归档知识。有监督机器学习必须给学习资料加标签(所有教科书都是这样要求的),但给学习资料加标签并不一定是要人工加标签,也可以是机器本身给学习资料加标签,本方案就是自动给学习资料加标签的(如是否更优、是否违规等)。5、建立一数一溯源:建立数据溯源机制,神经网络知识点具备联想溯源机制,每条建议都可以追溯到知识的源头,用户可查询该建议的依据(电厂、机组、时间、煤质、基础工况、操作状态、燃烧效率和nox排放等信息),使建议更具有合理性和安全可信性。以上所述是本发明的优选实施方式,应当指出,对于本
技术领域:
的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1