结合时空图神经网络和强化学习调控曝气量实现石化废水高效低耗微氧水解酸化的方法
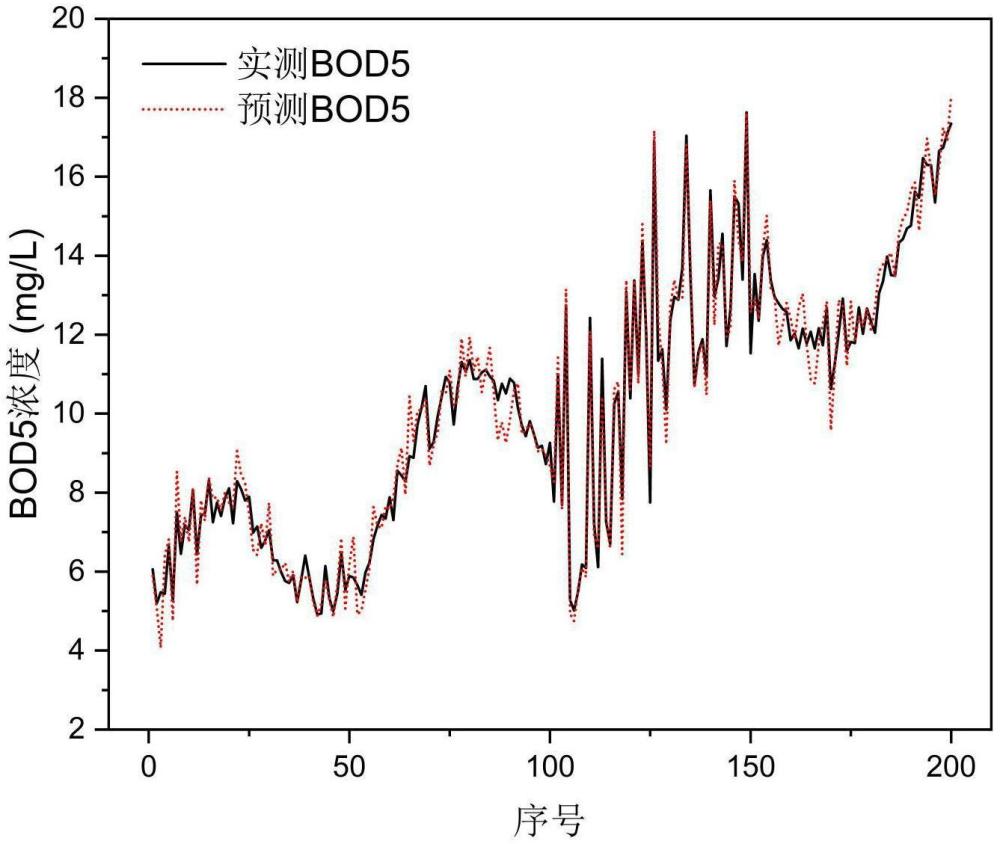
本发明涉及调控曝气量实现石化废水高效低耗微氧水解酸化的方法,属于废水处理工艺。
背景技术:
1、在众多的石化废水处理技术中,生物废水处理技术具有处理成本低、处理效率高等特点,是石化废水处理中最有前景的处理工艺。但由于石化废水高毒性、低生物降解性的特点,因此通常在生物处理法前需要对其采取水解酸化等技术进行预处理,以提高废水的生物降解性。水解酸化的作用是将难降解的复杂大分子,如芳香烃或杂环物质,转变为小分子有机酸和醇类等易生物降解有机物。但由于石化废水的成分非常复杂,传统的水解酸化工艺对石化废水的处理效果有限,无法实现废水可生化性的有效提高,进而限制了石化废水的后续进一步处理。
2、微氧水解酸化是指在水解酸化过程中引入微量氧气,以提高相关功能微生物的代谢活性,从而促进有机物的水解酸化效率。然而,该过程的调控极为复杂,对氧气浓度和流量的精确控制至关重要。一方面需要提供足够的氧气以促进微生物活性,另一方面又必须避免氧气过量导致厌氧微生物功能受抑。此外,溶解氧在反应器内的均匀分布也直接影响微氧状态的维持,增加了过程的复杂性。传统的调控方法主要依赖于经验设置或固定的操作参数,缺乏对工艺参数和实时数据变化的灵活响应能力,难以适应废水组成和环境条件的动态变化。这种刚性的控制策略不仅可能导致溶解氧分布不均、微生物群落失衡,还增加了操作成本,进而导致处理效率的不稳定,影响水解酸化的最终效果。
技术实现思路
1、本发明要解决的现有的微氧水解酸化中氧气浓度和流量调控的精确度差,处理效率不稳定的技术问题,而提供一种结合时空图神经网络和强化学习调控曝气量实现石化废水高效低耗微氧水解酸化的方法,通过结合st-gnn和强化学习相结合的方法,优化微氧水解酸化过程中的物理和化学参数调控。通过st-gnn对反应器内关键参数(溶解氧、ph、vfa浓度等)进行动态建模与预测,为强化学习提供准确的环境状态信息,进而实现对曝气量、搅拌速率等操作的实时优化,最终目标是提高微氧水解酸化效率、稳定工艺产物,并在保障处理效果的前提下,降低能耗,实现微氧水解酸化工艺的智能化和高效化管理。
2、本发明的结合时空图神经网络和强化学习调控曝气量实现石化废水高效低耗微氧水解酸化的方法,其中的处理系统包括数据收集模块、机器学习模块和曝气控制模块。通过整合上述模块,是采用机器学习技术来动态调节污水处理过程中的曝气量,以优化处理效率和能源消耗,实现了一种智能化、自动化的污水处理曝气控制系统,该系统不仅可以提高污水处理效率,降低能源消耗,而且能够根据实际情况灵活调整,具有很高的实用价值和推广前景。此外,该系统的设计还考虑了易用性和维护性,确保各种工况下都能稳定运行,为现代污水处理厂提供了一种高效、经济的技术解决方案。
3、本发明的结合时空图神经网络和强化学习调控曝气量实现石化废水高效低耗微氧水解酸化的方法,按以下步骤进行:
4、一、数据收集和清洗
5、(1)在水解酸化池中设置监测点和监测收集数据的传感器,监测并收集水解酸化池中进水口、出水口、中间反应区的工艺参数,其中工艺参数为溶解氧浓度、污水的流速和流量、进水bod5浓度、出水bod5浓度、进水cod浓度、出水cod浓度、氨氮浓度、温度、ph值、vfa浓度、曝气量、搅拌速率;数据监测采集的时间节点为:正常工作条件下每隔10~15min采集一次,曝气和搅拌设备开启或关闭时每隔1~2分钟采集一次;温度、ph或溶解氧参数出现显著波动时每隔1~2分钟采集一次;其中显著波动是指参数值变化超过20%;以确保精细地捕捉系统的动态特征;
6、(2)数据收集后,通过回归分析对各工艺参数的数据进行清洗,清洗后的数据通过z-score标准化或最小-最大标准化进行尺度规范化,以确保不同量纲的数据在同一尺度上操作;对具有正态分布特征的数据,采用z-score标准化将数据规范到均值为0、标准差为1的分布中;对具有偏态分布的数据,采用最小-最大标准化将数据缩放到[0,1]范围内;这样规范后的数据既提高了模型训练的效率,又增强了预测的准确性;
7、(3)引入基于时间序列的lstm-autoencoder模型识别多维数据中的异常值,异常的标准是各参数值偏离正常波动范围的2倍标准差以上;本步骤结合多传感器数据融合,增强异常值的识别和剔除;
8、(4)结合基于密度的空间聚类应用带噪声算法对溶解氧浓度、污水的流速和流量、进水bod5浓度、出水bod5浓度、进水cod浓度、出水cod浓度、氨氮浓度、温度、ph值、vfa浓度、曝气量、搅拌速率进行聚类分析,以异常的标准是偏离群体密度的3倍标准差作为异常的标准进行识别并剔除异常值,筛选出了与曝气量最直接的工艺参数数据;
9、(5)将处理后的多维工艺参数数据构建时空图的节点,每个节点代表特定位置和时间下的一个参数值,并使用边来表示这些工艺参数之间的相互作用关系,边的权重计算基于各工艺参数之间的相关性和因果关系,以量化反映工艺参数间的影响强度;
10、二、构建图数据集
11、(1)将经过清洗后的工艺参数作为节点输入图模型,每个节点代表一个特定的工艺参数,这些节点具有时间序列特性;通过相关性分析计算各节点间的皮尔逊相关系数,识别参数之间的基本线性关系,对于相关性系数大于0.7的节点对,初步判断其存在直接关联;应用核主成分分析(核pca)来提取参数间的非线性特征,将多维数据降维并保留主要特征,从而识别出工艺参数的潜在非线性交互关系,这有助于简化模型结构,同时突出关键特征采用核岭回归来构建非线性关系较复杂的节点对的边特征值,进一步量化这些节点对的非线性交互关系;通过这些步骤,形成具有边特征值的静态图结构,其中每条边的特征值反映节点对之间相互作用的强度;
12、(2)通过结合历史运行数据,将各时间步的数据快照按时间顺序排列,生成每个时间步的图结构,形成根据时间序列构建的动态图数据集,以此捕捉系统的动态变化特征;
13、(3)最终得到的动态图数据集按时间序列输入到st-gnn模型中进行训练,st-gnn的图卷积层将每个节点的特征与其邻居节点的特征进行聚合,从而提取节点的全局空间信息,通过多层卷积捕捉节点间的复杂交互和长距离依赖关系;之后,时间卷积层对聚合后的节点特征进行时间序列处理,以捕捉各工艺参数在时间上的动态变化趋势;经过图卷积和时间卷积处理后,st-gnn模型输出每个节点的综合表示,将节点的时空信息融合在一起,反映节点在不同工况下的动态状态;
14、三、st-gnn模型的训练
15、(1)将构建好的图数据集输入到st-gnn模型中进行训练;st-gnn模型包含3-5层图卷积网络结构,通过每一层卷积操作,提取工艺参数之间的空间关系和全局信息;通过多层图卷积,模型可以捕捉不同工艺参数之间的长距离依赖关系。
16、(2)同时采用、剪枝、量化模型压缩技术对st-gcn模型进行轻量化处理,轻量化处理的步骤是:首先,设定权重阈值为0.01,保留权重高于0.01的权重连接,去除去除权重小于0.01的连接,从而减少冗余参数的数量;同时结合结构化剪枝方法对整个卷积层进行评估,移除低贡献的通道或节点,剪枝比例设为20%-40%;通过剪枝策略去除卷积层中冗余或重要性低的参数,达到减少模型运算量和存储需求、确保模型精度尽量不受影响的目的;接着,采用量化技术将32位浮点数转换为8位整数表示,从而大幅降低模型的存储需求,加速推理过程;最后,在图卷积层中引入注意力机制,使模型能够动态识别并重点关注与目标参数关联性最强的节点和边,优先计算对目标输出影响最大的关系,进一步提升计算效率;通过以上模型压缩技术可以对st-gcn模型进行优化,以减少计算复杂度并提高计算效率;
17、(3)采用五折交叉验证方法评估模型的泛化性能,具体操作是:将图数据集分为五个子集,每次从中选取一个子集作为验证集,其余子集作为训练集,反复迭代训练模型,以确保模型在不同工况下的预测精度,预测精度为平均绝对误差(mae)控制在5%以内,均方误差(mse)控制在10%以内,均方根误差(rmse)控制在6%以内,此操作避免了过拟合,增强了模型对未知工况的适应性;同时在模型训练过程中,结合注意力机制或通过对重要特征进行可视化,识别对预测结果最具影响力的工艺参数及其交互关系,以增强模型的可解释性;
18、(4)在训练过程中,采用以cod去除率、vfa产量为主要目标的多目标损失函数来优化st-gnn模型的预测精度,其中损失函数包括对微氧水解酸化效果(cod去除率、vfa产量)的预测精度、对曝气量调控的准确性;通过均方误差(mse)衡量模型对微氧水解酸化效果的预测精度,将mse控制在5%以内;并评估模型预测的曝气量与实际最优曝气量之间的差异,差异应控制在±3%以内,以确保曝气量调控的准确性;在训练过程中,若误差指标均在设定范围内,则继续执行后续步骤,完成训练;若误差超出范围,则调整模型参数或增加训练迭代次数,直至误差回到合适范围内;通过优化这些误差,实现对曝气系统的精准控制和稳定的微氧水解酸化效果;
19、(5)再引入自适应权重调整机制,通过在损失函数中设定两个初始权重参数,分别对应vfa产量和曝气能耗,并根据系统的实时状态动态调整这两个权重,从而在不同工况下实现优化目标;当检测到系统能耗较高时,自适应机制会自动增加曝气能耗项的权重,使模型优先关注能耗的降低;当vfa产量不足时,系统则会提高vfa产量项的权重,以确保产量达到需求;通过这种机制,模型能够在不同工况下动态平衡vfa产量和能耗,实现优化效果,确保系统运行的稳定性和高效性;
20、四、构建深度q强化学习模型:
21、(1)基于st-gnn模型的输出,构建深度q学习模型,即,将st-gnn模型预测的各个物理和化学参数溶解氧浓度、ph值、温度、vfa浓度、进水流量,以及当前的操作参数曝气量和搅拌速率作为状态输入,导入到深度q学习模型中;
22、(2)利用主成分分析(pca)、t-sne或自编码器对高维状态空间进行降维处理,提取最具代表性的工艺参数特征,达到降低状态空间的复杂性,加速模型的训练收敛的目的;
23、(3)根据优化目标,设置多组奖励函数,分别针对最大化vfa产量和最小化曝气能耗的不同目标进行训练;
24、(4)深度q学习模型通过多次迭代在不同工况下试探并优化其策略,以满足优化目标;达到优化完成的标准是当奖励值在连续若干轮迭代中保持收敛,且vfa产量和能耗指标稳定在预设阈值内时,表示策略已优化完成;通过这种训练,,最终实现在提高产酸效率的同时,降低曝气过程中的能耗,实现更经济的运行;
25、五、曝气量的实时调控
26、(1)将训练好的st-gnn模型嵌入污水处理厂的自动控制系统中,通过传感器网络实时获取工艺参数数据,并输入到st-gnn模型中,模型利用当前工况和历史数据的交互,输出当前时间步的最优曝气量以及对微氧水解酸化效果的预测;
27、(2)根据st-gnn模型的输出,调整曝气设备的运行参数鼓风机功率和曝气时间,以实现实时控制;
28、(3)系统同时记录每次调整后的水解酸化效果指标cod去除率和vfa产量,将这些新的工艺参数数据再次输入到模型中,实现闭环控制,动态优化曝气量;同时集成应急控制策略,当检测到异常状况,自动启用预设的应急控制策略,以稳定工艺,直至强化学习模型重新收敛,实现石化废水高效低耗微氧水解酸化。
29、更进一步地,步骤一(1)中定期对传感器进行校准和维护,并设置冗余监测点,即在关键位置部署3~5个传感器,用于数据交叉验证和异常检测,以提高数据的准确性和减少传感器故障的影响。
30、更进一步地,步骤一(2)中所述的数据清洗的具体方法如下:首先,应用回归模型对采集到的数据进行异常值检测,以识别并去除超出正常波动范围的无效或错误数据点;清洗标准是使用3倍标准差作为阈值,剔除偏离均值超过此范围的数据点,从而减少数据中的噪声和异常;对于缺失的数据点,采用插值或前后数据均值填充的方法进行补全,以避免数据的间断性影响模型的稳定性和连续性。
31、更进一步地,步骤一(4)中所述的筛选与曝气量最直接的参数的方法是:首先,通过皮尔逊相关系数和互信息方法评估各工艺参数与曝气量的相关性,保留与曝气量相关性系数大于0.7的参数,以确保其对曝气量的预测具有较强影响力;然后,结合granger因果分析模型判断参数对曝气量的因果影响,排除噪声数据,噪声数据的标准:granger因果检验的p值大于0.05,此时因果关系不显著;或者参数的残差分布偏离正态分布,且残差方差高于数据集平均方差的两倍;最终保留对曝气量具有直接因果影响的参数;接着,通过分析不同参数的波动范围,采用变异系数cv(coefficient ofvariation)定量表示波动性,其计算公式为:cv=μ/σ,其中,σ为参数的标准差,μ为参数的均值;选择变异系数大于0.15的参数,表明其对系统动态变化较为敏感;同时,通过分析参数的功率谱密度(psd),选择在>0.1hz的高频段的能量占比超过30%的参数,确保模型在动态调控时具有较强的响应能力;最后,优先保留可通过传感器实时监测的参数,保证模型在实时控制过程中的可操作性和反馈速度;本步骤基于相关性分析、因果关系分析、参数波动性和实时可监测性的筛选原则找到与曝气量最直接的参数。
32、更进一步地,步骤一(5)中所述的边的权重的具体计算方法如下:
33、①相关性分析:首先计算各工艺参数对的皮尔逊相关系数,识别参数间的线性关系强度;对于相关系数大于0.7的参数对,赋予较高的边权重,以反映其在正常操作条件下的直接关联性;该方法有助于初步筛选出可能对曝气量调控有较大影响的参数;
34、②因果关系分析:使用granger因果检验对参数对进行因果关系分析,识别哪些参数的变化在时间上对其他参数有直接的因果影响;对于检验结果显著的因果关系对,增加其边权重,以确保时空图在建模时能够捕捉到关键的控制变量与结果变量间的因果联系;该方法适用于确定对曝气量和溶解氧浓度这两项关键参数具有直接影响的工艺变量;
35、③动态时间规整(dtw)距离:在时间序列上采用dtw方法衡量参数间的模式相似度,尤其适用于捕捉参数在复杂、动态反应环境中的同步性;dtw距离较小的参数对(即时间序列模式相似性高的参数对)将获得较高的边权重,以反映其在系统动态调控中的重要性;
36、④最终,边的权重将通过以上三种方法的结果加权融合计算得到,权重计算公式为:边权重=α·相关性权重+β·因果关系权重+γ·dtw距离权重;其中α、β、γ分别为各方法的权重系数;这样得到的边权重既能反映各参数间的线性关系和因果作用,也能捕捉其在时间上的同步性,从而实现对曝气量的精确动态调控;
37、更进一步地,步骤三(5)中所述的自适应调整通过梯度变化或特定阈值控制实现,即,监测每轮训练中损失函数的梯度变化,若vfa产量的梯度低于预设阈值,自动提升其权重;若能耗项的梯度变化超过阈值,则增加能耗项的权重。
38、更进一步地,步骤四中,主成分分析(pca)用于线性降维,保留主要特征成分;t-sne用于非线性数据的可视化与降维,将高维数据映射到低维空间;自编码器通过神经网络自动学习紧凑的低维表示,保留关键特征;降维后,状态空间的复杂度降低,从而加速深度q学习模型的训练收敛;
39、更进一步地,步骤四中所述的异常状况是进水水质突变、设备故障或污泥中毒。
40、本发明的结合时空图神经网络和强化学习调控曝气量实现石化废水高效低耗微氧水解酸化的方法,还可以对模型准确性与稳定性评估,具体的方法是:通过对比st-gnn调控前后的工艺参数数据,包括曝气量、能耗、水解酸化效果,监测曝气量在不同调控策略下的使用效率,评估调控前后曝气系统的电能消耗,确定能耗的优化幅度;通过cod去除率、vfa产量等指标评估st-gnn调控策略对污水处理效果的影响;增加不同进水cod、温度变化、流量变化的工况变化的情景模拟和突发事件测试,确保模型在多种实际场景中的适应性和鲁棒性;引入传统曝气量调控策略作为对照组,采用交叉验证方法,定期与st-gnn+rl模型进行对比测试,明确模型在不同工况下的优势与不足,量化节能效率和产酸效果的提升幅度。
41、本发明的结合时空图神经网络和强化学习调控曝气量实现石化废水高效低耗微氧水解酸化的方法,还可以对模型进行更新与参数调节,具体的方法是:在运行过程中,持续收集新的工艺参数数据,并将其纳入图数据集,定期对st-gnn模型进行再训练,以提高其在不同工况下的预测和调控性能;模型更新的周期根据工况变化的频率和水质要求来设定,每月或每季度进行一次更新;在模型更新过程中,采用网格搜索、贝叶斯优化方法,通过调整损失函数中的权重参数,自动寻找损失函数的最优参数组合,从而实现微氧水解酸化效果和曝气能耗之间的最佳平衡点;同时,利用运行结果中的反馈信息,分析模型输出与实际效果之间的偏差,进而优化st-gnn模型的结构和训练策略,以进一步提高调控的精度和稳定性。
42、本发明所提出的技术方法可以充分利用图神经网络的建模能力,捕捉工艺参数之间的复杂关联,实现污水处理厂曝气量的实时自适应调控。通过多目标优化,该方法能够在保持微氧水解酸化效果的同时,降低曝气能耗,实现更经济、环保的污水处理。此外,该方案具有灵活性和可扩展性,能够在多种污水处理工况下实现自适应调控,为污水处理厂提供一种智能化、自动化的调控手段。本发明的方法的流程图如图1所示,有益效果主要在于:
43、(1)动态构建图数据集,捕捉复杂关系
44、与传统特征提取方法不同,本方法利用核pca、核岭回归等非线性特征提取方法,建立更精确的参数关联关系。同时引入动态图结构,使得模型可以根据新的数据动态调整图的结构和权重,反映实时工况。此外,动态图结构能够更好地适应微氧水解酸化过程中的复杂性和变化性,捕捉参数之间的非线性交互关系,为st-gnn模型提供更丰富的时空特征信息,提高模型的预测性能和对工艺变化的适应能力,实现更精准的曝气量调控,以优化微氧水解酸化效果。
45、(2)模型轻量化与实时性增强
46、通过模型压缩技术(知识蒸馏、剪枝、量化等)对st-gnn进行轻量化处理,减少模型的计算负担,从而使系统能够在工况变化时快速做出调控决策,确保曝气量等关键参数能够被及时调整,避免调控滞后,提高污水处理的效率和稳定性。
47、(3)实时在线学习动态调控曝气量
48、通过状态空间降维、自适应奖励函数和在线学习策略,强化st-gnn模型的学习能力,使其能够灵活应对多目标优化(提高vfa产量、降低能耗)和工况变化,并在高维状态空间中加速收敛。从而能够根据实际工况的变化实时更新,并动态调整调控策略,使微氧水解酸化过程在满足目标要求的同时,实现更高的产酸效率和更低的能耗。模型的自适应优化使得系统更加智能化,提升整体工艺的运行效率。
49、(4)集成应急控制策略提高系统稳定性
50、本方法引入了应急控制策略,当检测到异常状况(进水水质突变、设备故障)时,机器学习系统可以自动启用预设的应急策略,使其在突发事件中仍能维持稳定的工艺效果,减少了对水质和系统性能的负面影响,确保工艺的稳定运行。
51、(5)多维度评估改进系统性能
52、通过情景模拟、基准对比测试和自动化超参数优化技术(贝叶斯优化、遗传算法),多维度评估和优化模型的性能,使st-gnn和强化学习模型能够持续学习和适应不同工况,从而使得模型在更新周期内不断进行微调,确保在工况变化的背景下,保持高效的预测和调控性能。自动化优化提高了系统的运行效率和可靠性,为实现污水处理的智能化和精细化管理提供了有力保障。
53、(6)闭环控制实现动态优化
54、闭环控制通过传感器实时获取工艺参数,将其输入st-gnn模型进行预测,并根据预测结果实时调整曝气设备的运行参数。每次调整后的工艺参数会再次输入模型,保证了系统的动态适应性,使曝气量的调控更加精准。这种动态优化不仅能够提高水解酸化的产酸效率,还能有效降低能耗,实现经济与环境效益的双赢。
55、(7)多传感器动态监测集成提升数据质量
56、通过加强传感器的维护与冗余布置,结合定期校准和多传感器数据交叉验证,确保数据的准确性和稳定性。同时,动态调整数据采样频率,适应系统状态的变化,从而能够有效降低传感器误差和数据漂移的影响,提高了模型对污水处理过程的实时监测能力,确保调控策略的及时性和准确性。
57、(8)多层次数据清洗提升模型准确度
58、通过引入基于回归分析、基于密度的空间聚类应用带噪声和时间序列异常检测模型的多层次数据清洗方法,提高了对复杂多维数据中异常值的识别和剔除能力,确保了数据的完整性和准确性,为后续建模提供了高质量的数据基础,减少了模型输入中的噪声,从而提升了模型的训练效率和预测准确性。
59、(9)智能化预测调控减少人工干预误差
60、通过st-gnn的智能化预测与调控,污水处理厂的曝气量调控可以实现自动化,减少对人工经验和干预的依赖。这不仅提高了调控效率,还降低了人为操作误差的风险,有助于实现污水处理厂的数字化和智能化管理。
- 还没有人留言评论。精彩留言会获得点赞!