车辆用控制数据的生成方法、车辆用控制装置、车辆用控制系统以及车辆用学习装置与流程
本公开涉及车辆用控制数据的生成方法、车辆用控制装置、车辆用控制系统以及车辆用学习装置。
背景技术:
例如日本特开2016-6327号公报记载了一种控制装置,其基于通过用滤波器对加速踏板的操作量进行处理而得到的值来对节气门进行操作。节气门是搭载于车辆的内燃机的操作部的一个例子。
技术实现要素:
发明要解决的技术问题
上述滤波器需要构成为根据加速踏板的操作量来将搭载于车辆的内燃机的节气门的操作量设定为适当的操作量。因此,滤波器的设定需要熟练人员花费大量工时。这样,以往对于与车辆的状态相应的车辆内的电子设备的操作量等的设定,熟练人员花费了大量工时。
用于解决问题的技术方案
以下,对本公开的例子进行记载。
例1.一种车辆用控制数据的生成方法,在存储装置存储有对具备旋转电机和内燃机的车辆的状态与行动变量的关系进行规定的关系规定数据,所述行动变量是与所述车辆内的电子设备的操作有关的变量,所述生成方法包括使执行装置执行:取得处理,取得确定变量和基于传感器的检测值得到的所述车辆的状态,所述确定变量是对在所述内燃机的工作状态下所述内燃机产生的转矩是否被利用于所述车辆的推力的生成进行确定的变量;操作处理,对所述电子设备进行操作;奖励算出处理,基于通过所述取得处理取得的所述车辆的状态,在所述车辆的特性满足基准的情况下给与比所述车辆的特性不满足基准的情况下大的奖励;更新处理,将通过所述取得处理取得的所述车辆的状态、在所述电子设备的操作中所使用的所述行动变量的值以及与该操作对应的所述奖励作为向预先确定的更新映射的输入,对所述关系规定数据进行更新,所述更新映射输出以使按照所述关系规定数据操作所述电子设备的情况下的关于所述奖励的期待收益增加的方式进行了更新的所述关系规定数据,所述奖励算出处理包括变更处理,所述变更处理在所述内燃机的工作状态下所述内燃机产生的转矩不被利用于所述车辆的推力的生成的情况下,使所述车辆的特性为预定特性时所给与的所述奖励相对于在所述内燃机的工作状态下所述内燃机产生的转矩被利用于所述车辆的推力的生成的情况下的该奖励进行变更。
在上述方法中,通过算出伴随着电子设备操作的奖励,能够掌握通过该操作能得到什么样的奖励。并且,基于奖励来通过依照了强化学习的更新映射对关系规定数据进行更新,由此能够设定车辆的状态与行动变量的适当的关系。因此,在设定车辆的状态与行动变量的适当的关系时,能够削减对熟练人员要求的工时。
在内燃机的转矩被利用于车辆的推力的生成的情况下和内燃机的转矩不被利用于推力的生成而仅被利用于发电的情况下,例如在内燃机的操作部所设置的电子设备的适当操作可能不同。于是,在上述方法中,在根据确定变量来变更奖励的给与方式的同时,通过强化学习对关系规定数据进行学习,由此,能够对能执行对于内燃机产生的转矩的用途来说适当的控制的关系规定数据进行学习。
例2.在上述例1所记载的车辆用控制数据的生成方法中,所述奖励算出处理包括在能量利用效率高的情况下给与比能量利用效率低的情况下大的奖励的处理,所述变更处理包括如下处理:在所述内燃机的工作状态下所述内燃机产生的转矩不被利用于所述车辆的推力的生成的情况下,与在所述内燃机的工作状态下所述内燃机产生的转矩被利用于所述车辆的推力的生成的情况相比,对所述奖励进行变更以使得提高所述能量利用效率在得到更大奖励这一方面有利。
根据上述变更处理,在内燃机产生的转矩不被利用于车辆的推力的生成的情况下,不存在与车辆的加速器响应有关的要求要素等。因此,与内燃机产生的转矩被利用于车辆的推力的生成的情况相比,提高能量利用效率会给与有利的奖励。由此,能够在内燃机产生的转矩不被利用于车辆的推力的生成的情况下,将燃料高效地变换为电能。
例3.在上述例1或者例2所记载的车辆用控制数据的生成方法中,还包括使所述执行装置执行如下处理:基于通过所述更新处理更新后的所述关系规定数据,对所述车辆的状态和使所述期待收益最大化的所述行动变量的值进行关联,由此生成将所述车辆的状态作为输入、输出使所述期待收益最大化的所述行动变量的值的控制用映射数据。
在上述方法中,基于通过强化学习进行了学习的关系规定数据,生成控制用映射数据。因此,通过将该控制用映射数据安装于控制装置,能够基于车辆的状态和行动变量,简单地设定使期待收益最大化的行动变量的值。
例4.一种具备旋转电机和内燃机的车辆用的控制装置,具备:存储装置,其构成为存储关系规定数据,所述关系规定数据对所述车辆的状态与行动变量的关系进行规定,所述行动变量是与所述车辆内的电子设备的操作有关的变量;和执行装置,所述执行装置构成为执行:取得处理,取得确定变量和基于传感器的检测值得到的所述车辆的状态,所述确定变量是对在所述内燃机的工作状态下所述内燃机产生的转矩是否被利用于所述车辆的推力的生成进行确定的变量;操作处理,基于所述关系规定数据,按照与所述车辆的状态相应的行动变量的值,对所述电子设备进行操作;奖励算出处理,基于通过所述取得处理取得的所述车辆的状态,在所述车辆的特性满足基准的情况下给与比所述车辆的特性不满足基准的情况下大的奖励;以及更新处理,将通过所述取得处理取得的所述车辆的状态、在所述电子设备的操作中所使用的所述行动变量的值以及与该操作对应的所述奖励作为向预先确定的更新映射的输入,对所述关系规定数据进行更新,所述更新映射输出以使按照所述关系规定数据操作所述电子设备的情况下的关于所述奖励的期待收益增加的方式进行了更新的所述关系规定数据,所述奖励算出处理包括变更处理,所述变更处理在所述内燃机的工作状态下所述内燃机产生的转矩不被利用于所述车辆的推力的生成的情况下,使所述车辆的特性为预定特性时所给与的所述奖励相对于在所述内燃机的工作状态下所述内燃机产生的转矩被利用于所述车辆的推力的生成的情况下的该奖励进行变更。
在上述构成中,基于通过强化学习进行了学习的关系规定数据来设定行动变量的值,基于该值来操作电子设备,由此,能够对电子设备进行操作以使得增大期待收益。
例5.一种具备旋转电机和内燃机的车辆用的控制系统,具备:存储装置,其构成为存储关系规定数据,所述关系规定数据对所述车辆的状态与行动变量的关系进行规定,所述行动变量是与所述车辆内的电子设备的操作有关的变量;和执行装置,所述执行装置构成为执行:取得处理,取得确定变量和基于传感器的检测值得到的所述车辆的状态,所述确定变量是对在所述内燃机的工作状态下所述内燃机产生的转矩是否被利用于所述车辆的推力的生成进行确定的变量;操作处理,基于所述关系规定数据,按照与所述车辆的状态相应的行动变量的值,对所述电子设备进行操作;奖励算出处理,基于通过所述取得处理取得的所述车辆的状态,在所述车辆的特性满足基准的情况下给与比所述车辆的特性不满足基准的情况下大的奖励;以及更新处理,将通过所述取得处理取得的所述车辆的状态、在所述电子设备的操作中所使用的所述行动变量的值以及与该操作对应的所述奖励作为向预先确定的更新映射的输入,对所述关系规定数据进行更新,所述更新映射输出以使按照所述关系规定数据操作所述电子设备的情况下的关于所述奖励的期待收益增加的方式进行了更新的所述关系规定数据,所述奖励算出处理包括变更处理,所述变更处理在所述内燃机的工作状态下所述内燃机产生的转矩不被利用于所述车辆的推力的生成的情况下,使所述车辆的特性为预定特性时所给与的所述奖励相对于在所述内燃机的工作状态下所述内燃机产生的转矩被利用于所述车辆的推力的生成的情况下的该奖励进行变更,所述执行装置包括搭载于所述车辆的第1执行装置和有别于车载装置的第2执行装置,所述第1执行装置具备构成为至少执行所述取得处理和所述操作处理的第1处理电路,所述第2执行装置具备构成为至少执行所述更新处理的第2处理电路。
在上述构成中,通过第2执行装置执行更新处理,与第1执行装置执行更新处理的情况相比,能够减轻第1执行装置的运算负荷。
此外,第2执行装置为有别于车载装置的装置意味着第2执行装置不是车载装置。
例6.一种车辆用控制装置,具备上述例5记载的车辆用控制系统的第1执行装置。
例7.一种车辆用学习装置,具备上述例5记载的车辆用控制系统的第2执行装置。
附图说明
图1是表示第1实施方式涉及的控制装置和驱动系统的图。
图2是表示图1的控制装置执行的处理的步骤的流程图。
图3是表示第1实施方式涉及的生成映射数据的系统的图。
图4是表示第1实施方式涉及的系统执行的处理的步骤的流程图。
图5是表示第1实施方式涉及的学习处理的详细的流程图。
图6是表示第1实施方式涉及的映射数据的生成处理的步骤的流程图。
图7是表示第2实施方式涉及的控制装置和驱动系统的图。
图8是表示图7的控制装置执行的处理的步骤的流程图。
图9是表示第3实施方式涉及的系统的构成的图。
图10a是表示第3实施方式涉及的系统执行的处理的步骤的流程图。
图10b是表示第3实施方式涉及的系统执行的处理的步骤的流程图。
具体实施方式
以下,参照附图对车辆用控制数据的生成方法、车辆用控制装置、车辆用控制系统以及车辆用学习装置涉及的实施方式进行说明。
<第1实施方式>
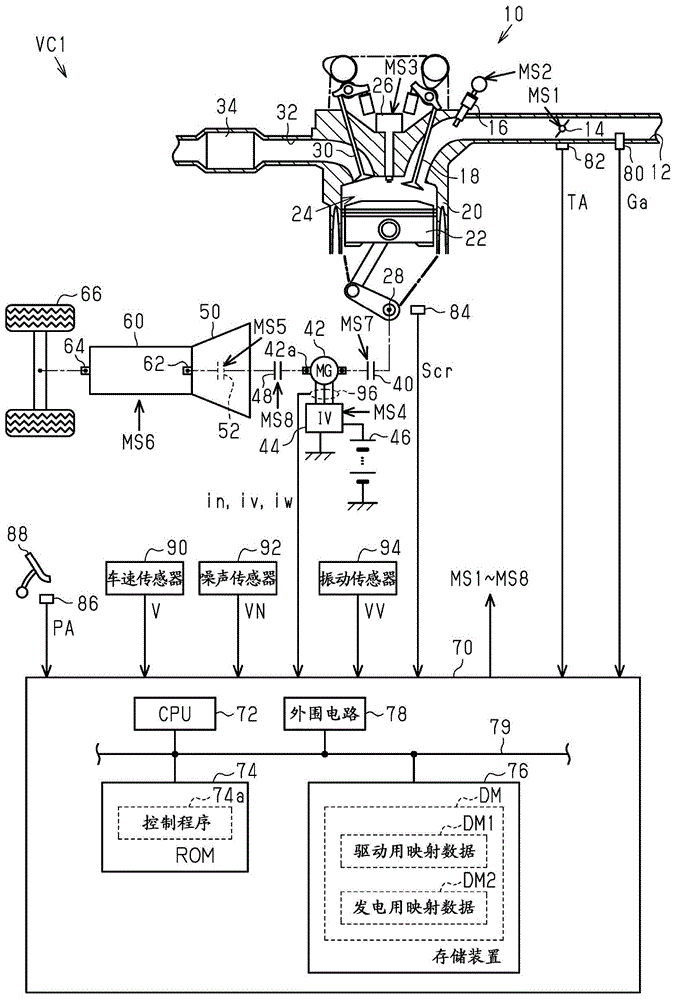
在图1中表示本实施方式涉及的车辆vc1的驱动系统和控制装置的结构。
如图1所示,在内燃机10的进气通路12中从上游侧开始依次配置有节气门14和燃料喷射阀16。被吸入到进气通路12的空气和从燃料喷射阀16喷射的燃料伴随着进气门18的开阀而流入到由气缸20和活塞22区划的燃烧室24。在燃烧室24内,燃料和空气的混合气伴随着点火装置26的火花放电而被供于燃烧。通过燃烧产生的能量经由活塞22被变换为曲轴28的旋转能量。被供于燃烧的混合气伴随着排气门30的开阀而被作为排气排出到排气通路32。在排气通路32配置有催化剂34,催化剂34是对排气进行净化的后处理装置。
电动发电机42的旋转轴42a能够经由离合器40以机械的方式连结于曲轴28。电动发电机42具有多个端子。作为直流电压源的电池46的端子电压经由变换器44被变换为交流电压,被施加于各端子。
变速装置60的输入轴62能够经由具备离合器48和锁止离合器52的转矩转换器50以机械的方式连结于旋转轴42a。变速装置60是使变速比为可变的装置,该变速比是输入轴62的转速与输出轴64的转速之比。在输出轴64以机械的方式连结有驱动轮66。
控制装置70对内燃机10进行控制。详细而言,控制装置70为了对内燃机10的控制量、例如转矩和排气成分比率进行控制,对内燃机10的操作部进行操作。操作部例如是节气门14、燃料喷射阀16以及点火装置26。控制装置70对电动发电机42进行控制。详细而言,控制装置70例如为了对电动发电机42的转矩和转速进行控制,对变换器44进行操作。控制装置70对转矩转换器50进行控制。详细而言,控制装置70为了对锁止离合器52的接合状态进行控制,对锁止离合器52进行操作。另外,控制装置70对变速装置60进行控制。详细而言,控制装置70为了对变速装置60的控制量、例如变速比进行控制,对变速装置60进行操作。在图1中记载了节气门14、燃料喷射阀16、点火装置26、变换器44、锁止离合器52、变速装置60、离合器40、离合器48各自的操作信号ms1~ms8。
控制装置70为了控制量的控制,例如对由空气流量计80检测的吸入空气量ga、由节气门传感器82检测的节气门14的开口度(节气门开口度ta)以及曲轴角传感器84的输出信号scr进行参照。另外,控制装置70对由加速器传感器86检测的加速踏板88的踏下量(加速器操作量pa)和由车速传感器90检测的车速vs进行参照。另外,控制装置70对由噪声传感器92检测的车室内的噪声强度vn、由振动传感器94检测的车室内的振动强度vv以及由电流传感器96检测的在电动发电机42中流动的电流iu、iv、iw进行参照。
控制装置70执行驱动模式和发电模式。在驱动模式中,使离合器40、48为缔结状态,将内燃机10的动力传递至驱动轮66,将内燃机10的转矩利用于车辆vc1的推力的生成。在发电模式中,使离合器48为断开状态,通过电动发电机42将内燃机10的动力变换为电能来对电池46进行充电。控制装置70在驱动模式中以根据对于车辆vc1的要求动力而预先确定的分配比,将内燃机10的动力和电动发电机42的动力传递至驱动轮66。
控制装置70具备cpu72、rom74、能够电重写的非易失性存储器(存储装置76)以及外围电路78,那些部件能够经由局域网络79相互进行通信。在此,外围电路78包括生成对内部动作进行规定的时钟信号的电路、电源电路以及复位电路。
在rom74中存储有控制程序74a。控制程序74a是对内燃机10工作时的控制的执行进行指示的程序。另一方面,在存储装置76中存储有映射数据dm。映射数据dm包括作为驱动模式用的映射数据的驱动用映射数据dm1、和作为发电模式用的映射数据的发电用映射数据dm2。在此,驱动用映射数据dm1是将驱动模式下的当前的变速比gr、车速vs以及加速器操作量pa的时间序列数据作为输入变量、将作为节气门开口度ta的指令值的节气门开口度指令值ta*和作为变速比gr的指令值的变速比指令值gr*作为输出变量的映射数据。另一方面,发电用映射数据dm2是将对于内燃机10的输出指令值p*和内燃机10的转速ne作为输入变量、将节气门开口度指令值ta*作为输出变量的映射数据。此外,映射数据是指输入变量的离散的值和与输入变量的值分别对应的输出变量的值的数据组。
在图2中表示本实施方式涉及的控制装置70执行的处理的步骤。图2所示的处理通过cpu72例如以内燃机10处于工作状态为条件来按预定周期反复执行存储于rom74的控制程序74a来实现。此外,以下通过在开头赋予了“s”的数字表现各处理的步骤编号。
在图2所示的一系列处理中,cpu72首先取得对是为驱动模式还是为发电模式进行确定的确定变量vu(s10)。并且,cpu72在判定为确定变量vu表示驱动模式的情况下(s12:是),取得包括加速器操作量pa的6个采样值“pa(1)、pa(2)、……、pa(6)”的时间序列数据、当前的变速比gr以及车速vs(s14)。时间序列数据所包含的各采样值在互不相同的时间点进行采样。6个采样值例如是以一定的采样周期采样到的在时间序列上相互相邻的值。
并且,cpu72使用驱动用映射数据dm1,通过映射运算累来求出节气门开口度指令值ta*和变速比指令值gr*(s16)。在映射运算中,例如在输入变量的值与映射数据的输入变量的值的某一个一致的情况下,将映射数据中的所对应的输出变量的值作为运算结果,与此相对,在不一致的情况下,将通过映射数据所包含的多个输出变量的值的内插得到的值作为运算结果即可。
并且,cpu72向节气门14输出操作信号ms1来对节气门开口度ta进行操作,并且,向变速装置60输出操作信号ms6来对变速比进行操作(s18)。在本事例中,通过反馈控制,将节气门开口度ta调整为节气门开口度指令值ta*。在该情况下,即使节气门开口度指令值ta*为相同的值,操作信号ms1也可能成为互不相同的信号。
与此相对,cpu72在判定为是发电模式的情况下(s12:否),取得作为对于内燃机10的输出的指令值的输出指令值p*和内燃机10的转速ne(s20)。此外,转速ne通过cpu72基于输出信号scr来算出。接着,cpu72使用发电用映射数据dm2,将输出指令值p*和转速ne作为输入变量,通过映射运算来求出节气门开口度指令值ta*(s22)。并且,cpu72为了将节气门开口度ta控制为节气门开口度指令值ta*,向节气门14输出操作信号ms1来对节气门开口度ta进行操作(s24)。
此外,cpu72在s18、s24的处理完成的情况下,暂时结束图2所示的一系列处理。
在图3中表示生成上述映射数据dm的系统。
如图3所示,在内燃机10的曲轴28能够经由离合器40以机械的方式连结电动发电机42。在电动发电机42能够经由离合器48、转矩转换器50以及变速装置60以机械的方式连结测力计100。使内燃机10进行了工作时所产生的各种各样的状态变量由传感器组102进行检测,那些检测结果被输入到作为生成映射数据dm的计算机的生成装置110。此外,传感器组102包括搭载于图1所示的车辆vc1的1个以上传感器。
生成装置110具备cpu112、rom114、能够电重写的非易失性存储器(存储装置116)以及外围电路118,那些部件能够通过局域网络119相互进行通信。在存储装置116中存储有包括驱动用规定数据dr1和发电用规定数据dr2的关系规定数据dr。驱动用规定数据dr1是对状况变量与行动变量的关系进行规定的数据。状态变量是加速器操作量pa的时间序列数据、车速vs以及变速比gr。行动变量是节气门开口度指令值ta*和变速比指令值gr*。发电用规定数据dr2是对状况变量与行动变量的关系进行规定的数据。状态变量是内燃机10的输出指令值p*和转速ne。行动变量是节气门开口度指令值ta*。在rom114中存储有通过强化学习对关系规定数据dr进行学习的学习程序114a。
在图4中表示生成装置110执行的处理的步骤。图4所示的处理通过cpu112执行存储于rom114的学习程序114a来实现。
在图4所示的一系列处理中,cpu112首先设定确定变量vu的值(s30)。接着,cpu112判定在s30中所设定的确定变量vu的值是否为与驱动模式对应的值(s32)。并且,cpu112在判定为是驱动模式的情况下(s32:是),在使内燃机10进行了工作的状态下,取得加速器操作量pa的时间序列数据、当前的变速比gr以及车速vs来作为状态“s”(s34)。在此的时间序列数据是与在s14中取得的数据同样的形态。但是,在图3所示的系统中,不存在加速踏板88。因此,加速器操作量pa通过生成装置110对车辆vc1的状态进行模拟来以虚拟的方式生成。以虚拟的方式所生成的加速器操作量pa被视为基于传感器的检测值的车辆的状态。另外,车速vs被作为假定为实际存在车辆的情况下所得到的车辆的行驶速度来通过cpu112进行算出。在本实施方式中,该车速被视为基于传感器的检测值的车辆的状态。详细而言,cpu112基于曲轴角传感器84的输出信号scr来算出曲轴28的转速ne,基于转速ne和变速比gr来算出车速vs。
并且,cpu112按照驱动用规定数据dr1所确定的策略π,设定由与通过s34的处理取得的状态“s”相应的节气门开口度指令值ta*和变速比指令值gr*规定的行动“a”(s36)。
关系规定数据dr是确定行动价值函数q和策略π的数据。行动价值函数q是表形式的数据。特别是,驱动用规定数据dr1规定的行动价值函数q表示与状态s和行动a的10维的自变量相应的期待收益的值。另外,策略π确定如下规则:在被提供了状态s时,在自变量成为所提供的状态s的行动价值函数q中,虽然优先选择使行动价值函数q的值为最大的行动a(贪婪(greedy)行动),但以预定的概率来选择贪婪行动以外的行动a。
详细而言,本实施方式涉及的行动价值函数q的自变量可取的值的数量为例如通过人的见解削减了状态s和行动a可取的值的全部组合的一部分后的数量。即,例如对于如加速器操作量pa的时间序列数据中的相邻的两个采样值中的一个为加速器操作量pa的最小值、另一个为最大值这样的状况,认为是不可能由人对加速踏板86的操作而产生的,不定义行动价值函数q。另外,为了避免变速比gr从2档急剧变化为4档,例如在当前的变速比gr为2档的情况下,将作为可取的行动a的变速比指令值gr*限制为1档、2档以及3档。即,在作为状态s的变速比gr为2档的情况下,不定义4档以上的行动a。通过这样的基于人的见解的维度削减,将定义行动价值函数q的自变量可取的值例如限制为10的5次方个以下,更优选限制为10的4次方个以下。
接着,cpu112基于所设定的节气门开口度指令值ta*和变速比指令值gr*,与s18的处理同样地输出操作信号ms1、ms6(s38)。接着,cpu112取得转速ne、变速比gr、被输入到转矩转换器50的转矩trq、转矩指令值trq*、振动强度vv以及噪声强度vn(s40)。转矩指令值trq*是向转矩转换器50的输入转矩的指令值。cpu112基于测力计100生成的负荷转矩和变速装置60的变速比来算出转矩trq。另外,转矩指令值trq*根据加速器操作量pa和变速比gr来设定。此外,在此,变速比指令值gr*为强化学习的行动变量。因此,不限于变速比指令值gr*使转矩指令值trq*在每个运转状态下为能够通过内燃机10和电动发电机42中的至少一方实现的最大转矩以下。因此,转矩指令值trq*不限于能够在每个状态下通过内燃机10和电动发电机42中的至少一方实现的最大转矩以下的值。
另一方面,cpu112在判定为是发电模式的情况下(s32:否),设定输出指令值p*和转速ne来作为状态s(s50)。在此,输出指令值p*通过cpu112设定为对由车辆生成的指令值进行了模拟的值。输出指令值p*通常例如基于电池46的充电率来设定。电池46的充电率例如基于电池46的端子电压或者充放电电流来算出,因此,基于电池46的充电率来设定的输出指令值p*被视为基于传感器的检测值的车辆的状态。
并且,cpu112按照由发电用规定数据dr2规定的策略π,设定行动a(s52)。行动a是与通过s50的处理取得的状态s相应的节气门开口度指令值ta*。接着,cpu112基于所设定的节气门开口度指令值ta*,与s24的处理同样地输出操作信号ms1(s54)。接着,cpu72取得转矩trq、转矩指令值trq*、振动强度vv以及噪声强度vn(s56)。转矩指令值trq*是对输出指令值p*除以转速ne后的值。转矩trq是电动发电机42的负荷转矩。负荷转矩根据在电动发电机42中流动的电流iu、iv、iw来算出。
接着,cpu112判定从执行了s30的处理的时间点和进行了后述的s44的处理的时间点中的某个晚的一方起是否经过了预定期间(s42)。并且,cpu112在判定为经过了预定期间的情况下(s42:是),通过强化学习对行动价值函数q进行更新(s44)。在此,预定期间设为如下的(a)或者(b)的期间即可。
(a)从转矩指令值trq*的变化量的绝对值成为第1预定值以上到成为比第1预定值小的第2预定值以下而经过具有预定长度的时间为止的期间。
(b)到转矩指令值trq*的变化量的绝对值成为第1预定值以上为止的期间。
但是,即使是在由上述(a)和(b)确定的期间的途中,若从驱动模式和发电模式中的某一方切换为另一方,则将该时间点作为预定期间的起点或者终点。
在图5中表示s44的处理的详细。
在图5所示的一系列处理中,cpu112取得包括预定期间内的转速ne、转矩指令值trq*以及转矩trq的3个采样值的组的时间序列数据、状态s的时间序列数据以及行动a的时间序列数据(s60)。在图5中,括号中记载的不同的多个数字表示分别在不同的采样时间点得到的变量的值。例如,转矩指令值trq*(1)和转矩指令值trq*(2)是在互不相同的采样时间点得到的。另外,将预定期间内的行动a的时间序列数据定义为行动集合aj,将预定期间内的状态s的时间序列数据定义为状态集合sj。
接着,cpu112基于转矩trq和转速ne的时间序列数据,算出内燃机10以及电动发电机42的效率ηe的时间序列数据和基准效率ηer的时间序列数据(s62)。
详细而言,在驱动模式中电动发电机42的转矩为零的情况下或者在发电模式的情况下,cpu112基于由转矩trq(k)和转速ne(k)确定的工作点,算出内燃机10的效率ηe(k)和基准效率ηer的。k(=1、2、3、……)表示采样定时。效率ηe按内燃机10的各工作点来定义。效率ηe是使内燃机10的燃烧室24内的混合气的空燃比为预定值、使点火正时为预定正时的情况下所产生的燃烧能量中的能作为动力取出的比例。另外,基准效率ηer按内燃机10的各输出来定义。基准效率ηer是对使内燃机10的燃烧室24内的混合气的空燃比为预定值、使点火正时为预定正时的情况下所产生的燃烧能量中的能作为动力取出的比例的最大值乘以比“1”小的预定系数而得到的值。即,基准效率ηer是对能作为动力取出的比例成为最大的工作点的该比例乘以预定系数而得到的值。具体而言,例如在将转矩trq和转速ne作为输入变量、将效率ηe作为输出变量的映射数据存储于rom114的情况下,cpu112通过映射运算求出效率ηe。另外,例如在将作为转矩trq和转速ne之积的输出设为输入变量、将基准效率ηer设为输出变量的映射数据存储于rom114的情况下,cpu112通过映射运算求出基准效率ηer。
此外,在驱动模式中电动发电机42的转矩比零大的情况下,cpu112基于在电动发电机42中流动的电流,算出电动发电机42的转矩。cpu112进一步通过从转矩trq减去所算出的电动发电机42的转矩来算出内燃机10的转矩。并且,cpu112基于对电动发电机42的工作点进行确定的电动发电机42的转矩和转速,算出作为电动发电机42的输出相对于向变换器44的输入电力的比例的效率,并且,基于内燃机10的转矩和转速,算出内燃机10的效率,作为所算出的那些效率的平均值来算出效率ηe。另外,基准效率ηer按被输入到转矩转换器50的动力来定义。基准效率ηer是对作为效率ηe可取的最大值乘以预定系数而得到的值。
接着,cpu112将对累计值乘以系数k而得到的值代入到奖励r(s64),该累计值是从对效率ηe(k)除以基准效率ηer(k)后的值减去“1”而得到的值的累计值。根据该处理,在效率ηe大于基准效率ηer的情况下,奖励r成为比效率ηe小于基准效率ηer的情况下的该奖励r大的值。
在此,cpu112使系数k为根据确定变量vu而可变。详细而言,在确定变量vu表示发电模式的情况下,将系数k设定为比确定变量vu表示驱动模式的情况下的该系数k大的值。该设定是在发电模式中使给与预定奖励时的效率的基准降低的设定。即,得到相同奖励时的效率ηe在发电模式中变低。由此,在发电模式中,当选择效率ηe高的工作点时,奖励r成为比驱动模式下的该奖励r大的值。
接着,cpu112判定预定期间内的任意的转矩trq与转矩指令值trq*之差的绝对值为规定量δtrq以下这一条件(a)是否成立(s66)。
在此,cpu112根据预定期间开始时的转矩指令值trq*的每单位时间的变化量δtrq*和确定变量vu的值以可变的方式设定规定量δtrq。即,cpu112在变化量δtrq*的绝对值大的情况下作为是与过渡时有关的情节,将规定量δtrq设定为比稳态时的情况下的该规定量δtrq大的值。另外,cpu112在发电模式的情况下,将规定量δtrq设定为比驱动模式的情况下的该规定量δtrq大的值。
cpu72在判定为是规定量δtrq以下的情况下(s66:是),对奖励r加上“k1·n”(s68),另一方面,在判定为是假的情况下(s66:否),从奖励r减去“k1·n”(s70)。在此,“n”表示预定期间中的效率ηe的采样数。s66~s70的处理在满足与转矩的响应有关的基准的情况下给与比不满足与转矩的响应有关的基准的情况下大的奖励。
在此,cpu112根据确定变量vu以可变的方式设定系数k1。详细而言,cpu112在驱动模式的情况下,将系数k1设定为比发电模式的情况下的该系数k1大的值。
cpu112在s68、s70的处理完成的情况下,判定噪声强度vn为阈值vnth以下这一条件(b)与振动强度vv为阈值vvth以下这一条件(c)的逻辑积是否为真(s72)。在此,cpu112在发电模式的情况下将阈值vnth、vvth设定为比驱动模式的情况下的该阈值vnth、vvth小的值。这是由于:在驱动模式中,车辆vc1正在行驶,因此,与停车时相比,作为噪声和振动,将更大的强度作为容许范围。cpu112在判定为逻辑积为真的情况下(s72:是),对奖励r加上“k2·n”(s74)。另一方面,在判定为逻辑积为假的情况下(s72:否),从奖励r减去“k2·n”(s76)。此外,s72~s76的处理在车室内的状态满足基准的情况下给与比车室内的状态不满足基准的情况下大的奖励。
在此,cpu112根据确定变量vu以可变的方式设定系数k2。详细而言,cpu112在发电模式的情况下将系数k2设定为比驱动模式的情况下的系数k2大的值。
cpu112在s74、s76的处理完成的情况下,对存储于图3所示的存储装置76的驱动用规定数据dr1和发电用规定数据dr2中的通过s30的处理指定的一方的数据进行更新。在本实施方式中,使用ε软同策略型蒙特卡罗方法(ε-softon-policymontecarlomethod)。
即,cpu112对由通过上述s60的处理读出的各状态和与其对应的行动的组确定的收益r(sj,aj)加上奖励r(s78)。在此,“r(sj,aj)”是对将状态集合sj的要素之一作为状态、将行动集合aj的要素之一作为行动的收益r进行了总括的记载。接着,对由通过上述s60的处理读出的各状态和与其对应的行动的组确定的收益r(sj,aj)进行平均化,将平均化后的收益r(sj,aj)代入到所对应的行动价值函数q(sj,aj)(s80)。在此,平均化设为对通过s78的处理算出的收益r除以进行了s78的处理的次数的处理即可。此外,收益r的初始值设为零即可。
接着,cpu112关于通过上述s60的处理读出的状态,分别将如下的行动代入到行动aj*(s82),该行动是所对应的行动价值函数q(sj,a)中的使行动价值函数q的值最大的行动。在此,“a”表示可取的任意的行动。此外,行动aj*是根据通过上述s60的处理读出的状态的种类而成为不同的值的行动,但在此将记载简化而通过同一标号进行记载。
接着,cpu112关于通过上述s60的处理读出的各个状态,对所对应的策略π(aj|sj)进行更新(s84)。即,当将行动的总数设为“|a|”时,将通过s82选择的行动aj*的选择概率设为“(1-ε)+ε/|a|”。另外,将行动aj*以外的“|a|-1”个行动的选择概率分别设为“ε/|a|”。s84的处理基于通过s82的处理进行了更新的行动价值函数q。因此,对状态s与行动a的关系进行规定的关系规定数据dr被进行更新以使收益r增加。
此外,cpu112在s84的处理完成的情况下,暂时结束图5所示的一系列处理。
返回图4,cpu112当s44的处理完成时,判定行动价值函数q是否已收敛(s46)。在此,在基于s44的处理的行动价值函数q的更新量成为预定值以下的连续次数达到预定次数的情况下判定为已收敛即可。cpu112在判定为未收敛的情况下(s46:否)、或者在s42的处理中作出否定判定的情况下,返回s32的处理。与此相对,cpu112在判定为已收敛的情况下(s46:是),判定是否通过s30的处理设定了驱动模式和发电模式这两方(s48)。
cpu112在关于驱动模式和发电模式中的某一方判定为尚未通过s30的处理进行设定的情况下(s48:否),返回s30的处理,将确定变量vu设定为尚未设定的值。cpu112在s48的处理中作出肯定判定的情况下,暂时结束图4所示的一系列处理。
在图6中表示生成装置110执行的处理中的、特别是基于通过图4的处理进行了学习的行动价值函数q来生成映射数据dm的处理的步骤。图6所示的处理通过cpu112执行存储于rom114的学习程序114a来实现。
在图6所示的一系列处理中,cpu112首先设定确定变量vu的值(s90)。并且,cpu112对成为驱动用映射数据dm1和发电用映射数据dm2中的与通过s90的处理设定的确定变量vu的值对应的一方的数据的输入变量的值的多个状态s中的一个进行选择(s92)。接着,cpu112对由驱动用规定数据dr1和发电用规定数据dr2中的与确定变量vu的值对应的数据规定且与状态s对应的行动价值函数q(s,a)中的、使行动价值函数q的值最大的行动a进行选择(s94)。即,在此通过贪婪策略选择行动a。接着,cpu112使状态s和行动a的组存储于存储装置116(s96)。
接着,cpu112判定驱动用映射数据dm1和发电用映射数据dm2中的与确定变量vu的值对应的一方的、数据的输入变量的值的全部是否通过s92的处理进行了选择(s98)。并且,cpu112在判定为存在未被选择的值的情况下(s98:否),返回s92的处理。与此相对,cpu112在判定为全部值已被选择的情况下(s98:是),判定是否通过s90的处理设定了作为确定变量vu的值可取的全部值(s100)。cpu112在判定为存在尚未设定的值的情况下(s100:否),返回s90的处理来设定该值。
与此相对,cpu112在判定为已设定全部值的情况下(s100:是),生成驱动用映射数据dm1和发电用映射数据dm2(s102)。在此,在映射数据dm中,将与作为状态s的输入变量的值对应的输出变量的值作为所对应的行动a。
此外,cpu112在s102的处理完成的情况下,暂时结束图6所示的一系列处理。
在此,对本实施方式的作用和效果进行说明。
在图3所示的系统中,cpu112通过强化学习对行动价值函数q进行学习。并且,行动价值函数q的值收敛意味着在满足关于能量利用效率要求的基准、关于转矩的响应要求的基准以及与车室内的状态有关的基准上学习了适当的行动。并且,cpu112关于成为映射数据dm的输入变量的各个状态,选择使行动价值函数q最大化的行动,使状态和行动的组存储于存储装置116。接着,cpu112基于存储于存储装置116的状态和行动的组,生成映射数据dm。由此,能够关于驱动模式和发电模式这两方,不使熟练人员的工时过度增大地根据对状态进行确定的变量来设定适当的行动。
特别是,在本实施方式中,根据是驱动模式、还是发电模式,改变奖励的给与方式来执行了强化学习。详细而言,在发电模式中,与驱动模式相比,使对于转矩的响应的基准宽松,另一方面,使与车室内状态有关的基准变得严格。由此,在发电用规定数据dr2的学习时,即使使转矩的响应比较低,也能够满足上述条件(a)而得到基于s68的处理的奖励。因此,降低响应等而尽量减小振动和噪声在增大总计的奖励上是有利的。因此,发电用映射数据dm2成为能够实现对车室内的噪声和振动进行抑制的控制的数据。
另外,在发电模式下,与驱动模式相比,增大了在能量利用效率高的情况下所给与的奖励。由此,在发电模式下,与驱动模式相比,提高能量利用效率在增大总计的奖励上是有利的。因此,发电用映射数据dm2成为能够实现能量利用效率变高的控制的数据。
另一方面,在驱动用规定数据dr1的学习时,虽然提高了效率ηe,但通过s64的处理得到的奖励变小。因此,在增大总计的奖励上,提高转矩的响应而满足上述条件(a)来获得基于s68的处理的奖励是有利的。因此,驱动用映射数据dm1成为能够实现对于用户的加速器操作的响应性良好的控制。
根据以上说明的本实施方式,能进一步得到以下记载的效果。
(1)在控制装置70具备的存储装置76存储有映射数据dm,而不是行动价值函数q。由此,cpu72基于使用了映射数据dm的映射运算,例如设定节气门开口度指令值ta*,由此,与执行选择行动价值函数q的值成为最大的自变量的值的处理的情况相比,能够减轻运算负荷。
<第2实施方式>
以下,以与第1实施方式的不同点为中心,参照附图对第2实施方式进行说明。
在图7中表示本实施方式涉及的车辆vc1的驱动系统和控制装置。此外,在图7中,为了便于说明,关于与图1所示的部件对应的部件标记了同一标号。
如图7所示,在本实施方式中,除了控制程序74a之外,在rom74中还存储有学习程序74b。另外,在存储装置76中未存储有映射数据dm,取而代之,存储有关系规定数据dr,另外,存储有转矩输出映射数据dt。在此,关系规定数据dr是通过图4的处理进行了学习的已学习的数据,包括驱动用规定数据dr1和发电用规定数据dr2。转矩输出映射由转矩输出映射数据dt进行规定。转矩输出映射是将转速ne、充填效率η以及点火正时作为输入、并输出内燃机10的转矩的例如与神经网络的已学习模型有关的数据。此外,上述转矩输出映射数据dt例如也可以是执行图4的处理时将通过s56的处理取得的转矩trq作为教师数据进行了学习的数据。此外,充填效率η也可以通过cpu72基于转速ne和吸入空气量ga来算出。
在图8中表示本实施方式涉及的控制装置70执行的处理的步骤。图8所示的处理通过cpu72例如以预定周期反复执行存储于rom74的控制程序74a和学习程序74b来实现。此外,在图8中,关于与图4所示的处理对应的处理,为了便于说明,赋予同一步骤编号。
在图8所示的一系列处理中,cpu72首先执行图2的s10、s12的处理,在判定为是驱动模式的情况下(s12:是),取得加速器操作量pa的时间序列数据、当前的变速比gr以及车速vs来作为状态s(s34a)。与此相对,cpu72在判定为是发电模式的情况下(s12:否),取得输出指令值p*和转速ne来作为状态s(s50a)。cpu72在s34a的处理完成的情况下,执行图4的s36~s44的处理。在此,在s40的处理中,cpu72基于由转矩输出映射数据dt规定的转矩输出映射来算出内燃机10的转矩,基于电流iu、iv、iw来算出电动发电机42的转矩,将那些之和作为转矩trq。
与此相对,cpu72在完成s50a的处理的情况下,执行s52~56、s42、s44的处理。此外,cpu72在s42的处理中作出否定判定的情况下、或者在完成s44的处理的情况下,暂时结束图8所示的一系列处理。此外,图8所示的处理中的s44的处理以外的处理通过cpu72执行控制程序74a来实现,s44的处理通过cpu72执行学习程序74b来实现。
这样,通过在控制装置70安装关系规定数据dr和学习程序74b,与第1实施方式的情况相比,能够使学习频度提高。
<第3实施方式>
以下,以与第2实施方式的不同点为中心,参照附图对第3实施方式进行说明。
在本实施方式中,在车辆vc1外执行关系规定数据dr的更新。
在图9中表示在本实施方式中执行强化学习的控制系统的结构。此外,在图9中,为了便于说明,对与图1所示的部件对应的部件赋予同一标号。
图9所示的车辆vc1内的控制装置70中的rom74存储控制程序74a,但不存储学习程序74b。另外,控制装置70具备通信机77。通信机77是用于经由车辆vc1外部的网络120与数据解析中心130进行通信的设备。
数据解析中心130对从多个车辆vc1、vc2、……发送的数据进行解析。数据解析中心130具有cpu132、rom134、能够电重写的非易失性存储器(存储装置136)、外围电路138以及通信机137,那些部件能够通过局域网络139相互进行通信。在rom134中存储有学习程序134a,在存储装置136存储有关系规定数据dr。
在图10a和图10b中表示本实施方式涉及的强化学习的处理步骤。图10a所示的处理通过cpu72执行存储于图9所示的rom74的控制程序74a来实现。另外,图10b所示的处理通过cpu132执行存储于rom134的学习程序134a来实现。此外,在图10a和图10b中,为了便于说明,对与图8所示的处理对应的处理赋予同一步骤编号。以下,沿着强化学习的时间顺序,对图10a和图10b所示的处理进行说明。
在图10a所示的一系列处理中,cpu72执行s10、s12、s34a、s36~s40的处理或者s10、s12、s50a、s52~s56的处理。并且,cpu72通过在判定为经过了预定期间的情况下(s42:是)对通信机77进行操作,发送关系规定数据dr的更新处理所需要的数据(s110)。在此,被作为发送对象的数据在预定期间内的确定变量vu的值之外还包括转速ne、转矩指令值trq*以及转矩trq的时间序列数据、状态集合sj及行动集合aj。
与此相对,如图10b所示,cpu132接收被发送来的数据(s120),基于所接收到的数据,对关系规定数据dr进行更新(s44)。并且,cpu132判定关系规定数据dr的更新次数是否为预定次数以上(s122)。cpu132在判定为是预定次数以上的情况下(s122:是),对通信机137进行操作,向发送了通过s120的处理接收到的数据的车辆vc1发送关系规定数据dr(s124)。此外,cpu132在完成s124的处理的情况下、或者在s122的处理中作出否定判定的情况下,暂时结束图10b所示的一系列处理。
与此相对,如图10a所示,cpu72对是否存在更新数据进行判定(s112),在判定为存在更新数据的情况下(s112:是),接收被进行了更新的关系规定数据dr(s114)。并且,cpu72将在s36、s52的处理中利用的关系规定数据dr重写为所接收到的关系规定数据dr(s116)。此外,cpu72在完成s116的处理的情况下、或者在s42、s112的处理中作出否定判定的情况下,暂时结束图10a所示的一系列处理。
这样,在车辆vc1的外部进行关系规定数据dr的更新处理,因此能够减轻控制装置70的运算负荷。进一步,例如在s120的处理中,若是接收来自多个车辆vc1、vc2、……的数据而进行s44的处理,则能够容易地增大用于学习的数据数量。
<对应关系>
上述实施方式中的事项与上述“发明内容”一栏所记载的事项的对应关系为如下所述那样。以下,按“发明内容”一栏所记载的例子的各编号来表示对应关系。
[1]在例1中,“执行装置”在图7中对应于cpu72和rom74,在图3中对应于cpu112和rom114,在图9中对应于cpu72、132以及rom74、134。“存储装置”在图7中对应于存储装置76,在图3中对应于存储装置116,在图9中对应于存储装置76、136。“取得处理”对应于图4的s30、s34、s40、s50、s56的处理、以及图8和图10a的s10、s34a、s40、s50a、s56的处理。“操作处理”对应于s38、s54的处理,“奖励算出处理”对应于s62~s76的处理,“更新处理”对应于s78~s84的处理。“更新映射”对应于通过学习程序74b中的执行s78~s84的处理的指令规定的映射。“变更处理”对应于使s64的处理中的系数k、s66的处理中的条件(a)、s68、s70的处理中的系数k1、s72的处理中的条件(b)、(c)、s74、s76的处理中的系数k2为根据确定变量vu而可变的处理。
[2]例2中的“对奖励进行变更的处理”对应于在s64、s68、s70、s74、s76的处理中在发电模式的情况下与驱动模式相比而系数k、k2被设为大的值、系数k1被设为小的值。
[3]例3中的“控制用映射数据”对应于映射数据dm。
[4]在例4中,“执行装置”对应于图7中的cpu72和rom74,“存储装置”对应于图7中的存储装置76。
[5]~[7]在例5~例7中,第1执行装置对应于cpu72和rom74,第2执行装置对应于cpu132和rom134。
<其他实施方式>
此外,本实施方式可以如以下那样进行变更来实施。本实施方式以及以下的变更例能够在技术上不矛盾的范围内相互组合来实施。
“关于变更处理”
·不限于执行如s66的处理那样对与响应有关的基准进行变更的处理和如s68、s70的处理那样对与是否满足关于响应的基准相应的奖励进行变更的处理这两双方,也可以仅执行这些处理中的任一方。
·例如,也可以作为变更为在发电模式下不能满足条件(a)的条件、并且在s70的处理中从奖励r减去零的处理,在驱动模式中,将s64的处理中的基准效率ηer设为不可取的高效率,并且,将累计值和零中的大的一方代入到奖励r。这与在发电模式中不执行在响应满足基准的情况下给与比响应不满足基准的情况下大的奖励的处理、在驱动模式中不执行在能量利用效率满足基准的情况下给与比能量利用效率不满足基准的情况下大的奖励的处理是等效的。因此,也可以设为如下处理:在发电模式中,不执行在响应满足基准的情况下给与比响应不满足基准的情况下大的奖励的处理,在驱动模式中,不执行在能量利用效率满足基准的情况下给与比能量利用效率不满足基准的情况下大的奖励的处理。对此,也可视为如下处理:对在响应满足基准的情况下给与比响应不满足基准的情况下大的奖励的处理、和在能量利用效率满足基准的情况下给与比能量利用效率不满足基准的情况下大的奖励的处理中的至少一个处理进行变更。
·例如系数k1、k2也可以设为固定值。即使是在该情况下,若是在发电模式的情况下使系数k比驱动模式的情况下的系数k大,则在发电模式中提高能量利用效率也在提高总计的奖励上成为更加有利。
·例如,也可以使系数k为固定值。即使是在该情况下,若是在发电模式中使系数k1比驱动模式中的系数k1小,则在发电模式中提高能量利用效率也在提高总计的奖励上成为更加有利。
·如下述“关于奖励算出处理”一栏所记载的那样也可以设为:对于根据节气门开口度指令值ta*的变化速度的绝对值是否为预定值以下来给与奖励的处理,在发电模式中执行该处理,在驱动模式中不执行该处理。另外,也可以在驱动模式中,将预定值设定为比作为节气门开口度指令值ta*的变化速度的绝对值所设想的最大值大的值,并且,执行上述处理。在该情况下,与在驱动模式中不执行在节气门开口度指令值ta*的变化速度的绝对值为预定值以下的情况下给与比节气门开口度指令值ta*的变化速度的绝对值比预定值大的情况下大的奖励的处理是同等的。因此,在驱动模式中不执行该处理可视为在驱动模式的情况下使预定值相对于发电模式下的该预定值进行变更的处理。
“能量利用效率”
·在上述实施方式中,仅基于工作点来对能量利用效率进行了定量化,但不限于此。例如如下述“关于行动变量”一栏所记载的那样,在行动变量包含点火正时的情况下,当所采用的点火正时从mbt偏离时,根据该偏离量来对能量利用效率进行减少修正即可。另外,在行动变量包含与空燃比控制有关的变量的情况下,当所采用的空燃比从预定的空燃比偏离时,根据该偏离量来对能量利用效率进行修正即可。
·在上述实施方式中,将驱动电动发电机42时的效率ηe设为了电动发电机42的效率和内燃机10的效率的简单平均,但不限于此。例如,也可以使用与电动发电机42的输出和内燃机10的输出的比率相应的权重系数,算出电动发电机42的效率和内燃机10的效率的加权移动平均处理值。
“关于表形式的数据的维度削减”
·作为表形式的数据的维度削减方法,不限于在上述实施方式中例示的方法。例如加速器操作量pa很少会成为最大值,因此,关于驱动用规定数据dr1中的加速器操作量pa成为规定量以上的状态,也可以不定义行动价值函数q,对加速器操作量pa成为规定量以上的情况下的节气门开口度指令值ta*等另外进行设定。另外,例如也可以通过从行动可取的值去掉节气门开口度指令值ta*成为规定值以上的值来进行维度削减。
“关于关系规定数据”
·在上述实施方式中将行动价值函数q设为了表形式的函数,但不限于此,例如,也可以使用函数近似器。
·例如,也可以代替使用行动价值函数q,用将状态s和行动a作为自变量、将采取行动a的概率作为因变量的函数近似器表现策略π,根据奖励r来对确定函数近似器的参数进行更新。
“关于操作处理”
·例如如“关于关系规定数据”一栏所记载的那样,在将行动价值函数作为函数近似器的情况下,将关于上述实施方式中的表型式的函数的成为自变量的行动的离散的值的全部组与状态s一起输入到行动价值函数q,由此,确定使行动价值函数q最大化的行动a即可。在该情况下,例如在主要将所确定的行动a采用于操作的同时,以预定概率选择除此之外的行动即可。
·例如如“关于关系规定数据”一栏所记载的那样,在使策略π为将状态s和行动a作为自变量、将采取行动a的概率作为因变量的函数近似器的情况下,基于由策略π表示的概率来选择行动a即可。
“关于更新映射”
·在s78~s84的处理中,例示了基于ε软同策略型蒙特卡罗方法的处理,但不限于此。例如,也可以是基于离策略型蒙特卡罗法(off-policymontecarlomethod)的处理。当然,不限于蒙特卡罗法,例如也可以使用离策略td法,另外,例如也可以如sarsa法那样使用同策略型td法,另外,例如也可以使用资格迹法(eligibilitytracemethod)来作为同策略型的学习。
·例如如“关于关系规定数据”一栏所记载的那样,在使用函数近似器来表现策略π、基于奖励r直接对其进行更新的情况下,使用策略梯度法等来构成更新映射即可。
·不限于仅将行动价值函数q和策略π中的某一方作为基于奖励r的直接的更新对象。例如,也可以如actor-critic法那样分别对行动价值函数q和策略π进行更新。另外,在actor-critic法中,不限于此,例如也可以代替行动价值函数q而将价值函数v作为更新对象。
“关于行动变量”
·在上述实施方式中,作为与作为驱动模式中的行动变量的节气门的开口度有关的变量,例示了节气门开口度指令值ta*,但不限于此。例如,也可以用无用时间和二阶滞后滤波器表现节气门开口度指令值ta*对于加速器操作量pa的响应性,将无用时间、规定二阶滞后滤波器的两个变量的合计三个变量作为与节气门的开口度有关的变量。但是,在该情况下,对于状态变量,优选代替加速器操作量pa的时间序列数据而设为加速器操作量pa的每单位时间的变化量。
·在上述实施方式中,作为与内燃机的操作部的操作有关的行动变量,例示了与节气门的开口度有关的变量,但不限于此。例如,也可以在与节气门的开口度有关的变量之外,还使用与点火正时有关的变量、与空燃比控制有关的变量。
·如“关于内燃机”一栏所记载的那样,在为压缩着火式的内燃机的情况下,使用与喷射量有关的变量来代替与节气门的开口度有关的变量即可。另外,也可以在此基础上,例如使用与喷射正时有关的变量、与一个燃烧周期中的喷射次数有关的变量或者与用于一个燃烧周期中的一个气缸的在时间序列上相邻的2个燃料喷射中的一方的结束定时与另一方的开始定时之间的时间间隔有关的变量。
·如下述“关于电子设备”一栏所记载的那样,在成为与行动变量相应的操作的对象的电子设备包括内燃机驱动式的空调装置的压缩机的情况下,行动变量也可以包括压缩机的负荷转矩,在同样地成为操作的对象的电子设备包括电动式的空调装置的情况下,行动变量也可以包括电动式的空调装置的消耗电力。
“关于状态”
·在上述实施方式中,加速器操作量pa的时间序列数据为等间隔地采样到的6个值,但不限于此,加速器操作量pa的时间序列数据是互不相同的采样时间点的2个以上的采样值即可,例如也可以是3个以上的采样值。这些值的采样间隔可以为等间隔。
·作为与加速器操作量有关的状态变量,不限于加速器操作量pa的时间序列数据,例如也可以如“关于行动变量”一栏所记载的那样为加速器操作量pa的每单位时间的变化量。
·与内燃机10有关的状态变量不限于在上述实施方式中例示的变量,例如也可以是催化剂34的温度。由此,通过强化学习对能够使从排气通路32排出到外部的排气的特性更加良好的行动进行学习也成为可能。
·例如也可以在状态变量包括电池46的充放电电流量、电池46的充电率或者对于电池46的要求输出。由此,能够通过强化学习对在提高能量利用效率上更适当的行动进行学习。
·另外,例如如“关于行动变量”一栏所记载的那样,在行动包括压缩机的负荷转矩、空调装置的消耗电力的情况下,在状态包括车室内的温度即可。
“关于奖励算出处理”
·作为在能量利用效率高的情况下给与比能量利用效率低的情况下大的奖励的处理,不限于取成为基准的效率与实际的工作点的效率之比和“1”的差的处理,例如也可以是取成为基准的效率与实际的工作点的效率之差的处理。
·例如也可以代替在满足条件(a)的情况下一律给与相同的奖励而设为如下处理:在转矩trq与转矩指令值trq*之差的绝对值小的情况下给与比该绝对值的大的情况下更大的奖励。另外,例如也可以代替在不满足条件(a)的情况下一律给与相同的奖励而设为如下处理:在转矩trq与转矩指令值trq*之差的绝对值大的情况下给与比该绝对值小的情况下更小的奖励。
·作为在满足与响应有关的基准的情况下给与比不满足与响应有关的基准的情况下大的奖励的处理,不限于在上述实施方式中例示的处理,例如也可以设为如下处理:限于变化量δtrq*的绝对值为预定值以上的情况下,当满足条件(a)时给与比不满足条件(a)时大的奖励。在该情况下也可以另外设置如下处理:在变化量δtrq*的绝对值小于预定值的情况下,当满足对转矩指令值trq*的跟随性时给与不满足对转矩指令值trq*的跟随性时大的奖励。在该情况下,另外设置的处理中的跟随性的基准或者奖励也可以在驱动模式和发电模式中相同。
·作为在驱动模式中在满足与响应有关的基准的情况下给与比不满足与响应有关的基准的情况下大的奖励的处理,不限于根据是否满足上述条件(a)来给与奖励的处理。例如,也可以是如下处理:限于变化量δtrq*的绝对值为预定值以上的情况,根据是否满足车辆的前后加速度处于例如基于加速器操作量pa设定的范围内这一条件来给与奖励。
·作为在车室内的状态满足基准的情况下给与比车室内的状态不满足基准的情况下大的奖励的处理,不限于根据上述条件(b)和条件(c)的逻辑积是否为真来给与奖励的处理。例如,也可以设为根据是否满足条件(b)来给与奖励的处理、和根据是否满足条件(c)来给与奖励的处理这两个处理,另外,关于两个处理,也可以仅执行这些处理中的某一个处理。
·作为在因内燃机10的工作而引起的振动强度大的情况下给与比该振动强度小的情况下大的奖励的处理,不限于在满足条件(c)的情况下给与比不满足条件(c)的情况下大的奖励的处理。例如,也可以是在瞬时转速的变动量小的情况下给与比瞬时转速的变动量大的情况下大的奖励的处理。瞬时转速是与曲轴28的微小的旋转角度区域的旋转有关的速度。在此,在设为当变动量小于阈值时给与比变动量大于阈值时大的奖励的处理的情况下,使阈值为发电模式时比驱动模式时小的值即可。但是,并不必须使阈值为发电模式时比驱动模式时小的值。例如,在驱动模式中,曲轴28连结于驱动系统,因此,容易牵涉到车辆的振动,与此相对,在发电模式中曲轴28不连结于驱动系统的情况下,不容易牵涉到车辆的振动,因此,也可以使阈值为发电模式时比驱动模式时大的值。
·奖励算出处理也可以在当满足与响应有关的基准时给与比不满足与响应有关的基准时大的奖励的处理、当能量利用效率满足基准时给与比能量利用效率不满足基准时大的奖励的处理以及当车室内的状态满足基准时给与比车室内的状态不满足基准时大的奖励的处理之外、或者代替这些处理中的某一处理而例如包括当排气特性满足基准时给与比排气特性不满足基准时大的奖励的处理。在该情况下,在发电模式中可以不考虑与加速器响应有关的要求要素,因此,也可以使与排气特性有关的基准更加严格。
·也可以包括如下处理:在发电模式中,在节气门开口度指令值ta*的变化速度的绝对值为预定值以下的情况下给与比该绝对值大于预定值的情况下大的奖励。由此,能够抑制内燃机10的运转状态急剧地变化。其结果,高精度地控制空燃比变得容易。因此,发电模式下的排气特性满足更严格的基准也成为可能。换言之,也能够不执行在排气特性满足基准的情况下给与比排气特性不满足基准的情况下大的奖励的处理、和在发电模式中使排气特性的基准比驱动模式中的该基准严格的处理,就获得与执行了那些处理同等的效果。
·也可以执行如下处理:在内燃机10的转矩的变化速度的绝对值处于预定范围内的情况下给与比该绝对值不处于预定范围内的情况下大的奖励。在此,若是设定预定范围以使得在发电模式中变化速度的绝对值为比驱动模式中的该绝对值小的值,则在发电模式中高精度地控制空燃比变得容易。或者也可以设为:若是即使使内燃机10的转矩急剧地变化、车辆的加速度的绝对值也不过度地变大,则设定上述预定范围以使得在发电模式中变化速度的绝对值为比驱动模式中的该绝对值大的值。
“关于车辆用控制数据的生成方法”
·在图4的s34、s50的处理中,基于行动价值函数q来决定了行动,但不限于此,也可以等概率地选择可取的全部行动。
“关于控制用映射数据”
·通过将车辆的状态与使期待收益最大化的行动变量的值一对一地关联来将车辆的状态作为输入、并输出使期待收益最大化的行动变量的值的控制用映射数据不限于映射数据,例如也可以是函数近似器。如上述“关于更新映射”一栏所记载的那样,例如在使用策略坡度法的情况下,用对可能采取行动变量的值的概率进行表示的高斯分布来表现策略π,用函数近似器表现其平均值,设为对表现平均值的函数近似器的参数进行更新,能够通过将学习后的平均值作为控制用映射数据来加以实现。即,在此,将函数近似器输出的平均值视为使期待收益最大化的行动变量的值。
“关于电子设备”
·成为与行动变量相应的操作的对象的内燃机的操作部不限于节气门14,例如也可以是点火装置26或者燃料喷射阀16。
·成为与行动变量相应的操作的对象的电子设备中的与车辆的推力生成装置有关的电子设备不限于内燃机的操作部,例如也可以是如变换器44那样的连接于旋转电机的电力变换电路。
·成为与行动变量相应的操作的对象的电子设备不限于车载驱动系统的电子设备,例如既可以是内燃机驱动式的空调装置的压缩机,也可以是电动式的空调装置。
·在驱动模式与发电模式这两方中,与行动变量相应的操作的对象并不必须包括内燃机的操作部。例如,在上述实施方式中,也可以从驱动模式的情况下的行动变量中删除节气门开口度指令值ta*。
“关于车辆用控制系统”
·在图10a和图10b所示的例子中,在数据解析中心130中执行了s44的全部处理,但不限于此。例如也可以设为:在数据解析中心130中执行s78~s84的处理,但不执行算出奖励的s62~s76的处理,在s110的处理中,发送奖励的算出结果。
·在图10a和图10b所示的例子中,在车辆侧执行了决定基于策略π的行动的s36、s52的处理,但不限于此。例如也可以从车辆vc1发送通过s34a、s50a的处理取得的数据,在数据解析中心130使用被发送来的数据来决定行动a,向车辆vc1发送所决定的行动。
·车辆用控制系统例如也可以代替数据解析中心130而使用用户的便携终端。或者,车辆用控制系统也可以在控制装置70和数据解析中心130之外还具备便携终端。这例如能够通过便携终端执行s36、s52的处理来实现。
“关于模式”
·在上述实施方式中,在驱动模式中,内燃机的工作状态下的内燃机的转矩被利用于车辆的推力的生成,但不限于此。例如,也可以使仅用内燃机10的转矩来生成车辆的推力的模式和通过内燃机10的转矩与电动发电机42的转矩的协作来生成车辆的推力的模式为分别的模式。
·例如若是下述“关于混合动力车辆”一栏所记载的混联式混合动力车辆(series/parallelhybridvehicle),则在被进行牵引控制的电动发电机的输出为对车辆的推力有贡献的输出以上的情况下,定义为内燃机的工作状态下的内燃机的转矩不被利用于车辆的推力的生成的模式即可。在此,例如在对行星齿轮机构的行星架以机械的方式连结内燃机的曲轴、对太阳轮以机械的方式连结第1电动发电机、对齿圈以机械的方式连结第2电动发电机和驱动轮的情况下,在内燃机的工作状态下,对第1电动发电机进行发电控制,对第2电动发电机进行牵引控制即可。在该情况下,当第2电动发电机的输出为对车辆的推力的生成有贡献的输出以上时,设为内燃机的工作状态下的内燃机的转矩不被利用于车辆的推力的生成的第1模式即可。另一方面,在第2电动发电机的输出低于对车辆的推力的生成有贡献的输出的情况下,成为内燃机的工作状态下的内燃机的转矩被利用于车辆的推力的生成的第2模式。在第2模式的情况下,内燃机的驱动状态有助于加速器响应。因此,例如增大对赋予驱动轮66的转矩的指令值的跟随性满足基准的情况下的奖励是有效的。与此相对,在第1模式的情况下,加速器响应能够仅由第2电动发电机来确定。因此,例如增大能量利用效率满足基准的情况下的奖励是有效的。
“关于执行装置”
·作为执行装置,不限于具备cpu72(112、132)和rom74(114、134)来执行软件处理的装置。例如,也可以具备对在上述实施方式中执行的软件处理的至少一部分进行处理的专用的硬件电路、例如asic。即,执行装置是以下的(a)~(c)中的任一结构即可。(a)具备按照程序执行全部的上述处理的处理装置和存储程序的rom等的程序保存装置。(b)具备按照程序来执行上述处理的一部分的处理装置以及程序保存装置、和执行其余处理的专用的硬件电路。(c)具备执行全部的上述处理的专用的硬件电路。在此,具备处理装置和程序保存装置的软件执行装置、专用的硬件电路也可以是多个。即,上述处理由具备一个或者多个软件处理电路和一个或者多个专用的硬件电路中的至少一方的处理电路(processingcircuitry)来执行即可。
“关于存储装置”
·在上述实施方式中,使存储关系规定数据dr的存储装置和存储学习用程序74b、114a、控制程序74a的存储装置(rom74、114、134)为不同的存储装置,但不限于此。
“关于内燃机”
·内燃机具备的燃料喷射阀不限于向进气通路12喷射燃料的端口喷射阀,也可以是向燃烧室24直接喷射燃料的缸内喷射阀。或者,内燃机也可以具备端口喷射阀和缸内喷射阀这两方。
·作为内燃机,不限于火花点火式内燃机,例如也可以是使用轻油等来作为燃料的压缩着火式内燃机。
“关于混合动力车辆”
·作为混合动力车辆,不限于并联式混合动力车,例如也可以是混联式混合动力车。
- 还没有人留言评论。精彩留言会获得点赞!