用于在技术装置处的操纵识别的方法和设备与流程
1.本发明涉及机动车,以及尤其是用于对机动车的装置进行操纵识别的方法。本发明还涉及废气后处理装置和用于识别操纵并且用于对废气后处理装置进行诊断的方法。
背景技术:
2.在具有柴油燃烧发动机的重型载重车辆中安装有所谓的选择性催化还原(selective catalyst reduction,scr)废气后处理系统,该废气后处理系统的任务在于借助于化学反应来分解有毒的氮氧化物(nox)。为此,必须将水和尿素的混合物添加给废气(通常以注册商标名称ad-blue为人所知)。这通过热解分解成氨。然后在催化净化器中发生反应,该反应将氮氧化物转化成水和氮。
3.需要废气后处理系统满足相应的法定的废气排放规定。这样,欧6标准例如针对载货车(lkw)中的氮氧化物以0.4g/kw h来规定whsc的极限值。对于货运公司来说,scr废气后处理系统的正常运行是一个不小的成本因素。
4.机动车中的技术装置可能以不允许的方式被操纵,以便实现对于驾驶员来说有利的运行。这样,可以操纵废气后处理装置,用于发动机系统的功率提高或者用于材料消耗、尤其是尿素(ad-blue)的减少。
5.通常,用于识别操纵的方法基于规则。基于规则的操纵监控方法具有如下缺点:只有已知的操纵策略可以被识别或只有已知的操纵可以被拦截。因此,这种防御策略对于新型操纵来说没有辨别力。此外,将复杂的技术系统及其依赖关系在控制系统中考虑进去并且创建用于识别操纵的相对应的规则花费高。
6.例如,对于废气后处理装置来说,由于其动态特性,运行状态是各式各样的并且尤其是在很少出现的系统状态的情况下并不能明确地与操纵的存在关联起来。例如,如今的用于脱氧(通过将尿素注入废气中来还原氮)的scr废气后处理系统(scr:selective catalytic reduction(选择性催化还原))拥有法律规定的对对于无错误的运行来说重要的系统参数的监控。这些系统参数在车载诊断的框架内被监控是否遵循物理上合理的极限值并且由此来予以合理性检查。对于其值根据scr控制的不同调定量的组合所得到的系统固有参数来说,还可以检查在系统干预之后是否出现所预期的系统反应。这样,例如在关闭阀时,能预期到在液压系统中的压力的下降。
7.然而,越来越多地使用所谓的scr仿真器,这些scr仿真器能够改变在监控系统的程序代码中的数据或者该监控系统所使用的传感器值的数据,使得即使scr系统只是受限地活跃或者完全不再活跃,误识别也通过该监控系统来被排除。由此,在车辆运行时,可以降低维护花费,并且在容忍氮氧化物排放增加的情况下可以节省加注尿素的成本。传统的诊断功能被经模拟的传感器信号所欺骗,这使得对操纵的识别变得困难。
技术实现要素:
8.按照本发明,规定了一种按照权利要求1所述的用于在技术装置、尤其是机动车中
的技术装置、尤其是废气后处理装置中的操纵识别的方法以及一种按照并列权利要求所述的设备和一种按照并列权利要求所述的技术系统。
9.其它的设计方案在从属权利要求中说明。
10.按照第一方面,规定了一种用于技术装置、尤其是机动车中的技术装置、尤其是废气后处理装置的操纵识别的方法,该方法具有如下步骤:
‑ꢀ
在连续的时间步长提供输入向量,该输入向量具有一个或多个系统参量并且具有用于干预该技术装置的至少一个调定量;
‑ꢀ
使用基于数据的操纵识别模型,以便在每个时间步长内针对各一个输入向量生成相对应的输出向量作为分类向量,其中该基于数据的操纵识别模型被设计用于针对输入向量来输出说明监控参量在值范围方面的分类的输出向量;
‑ꢀ
在这些连续的时间步长内基于至少一个测量值来提供实际的监控参量;
‑ꢀ
针对每个时间步长,根据实际的监控参量来创建测量分类向量;
‑ꢀ
根据该测量分类向量以及针对时间窗的一个或多个时间步长的第一和第二比较向量来识别操纵,其中该第一和第二比较向量通过基于作为舍入限制的第一操纵阈值和与第一操纵阈值不同的第二操纵阈值对输出向量的元素值的舍入来被确定。
11.可以规定:该技术装置包括废气后处理装置,其中输入向量包括针对尿素注射系统的调定量,作为该调定量。
12.按照上述方法,提出:使用机器学习方法,以便实行对机动车中的技术装置的操纵识别。借助于基于数据的操纵识别模型,所基于的技术装置的正常行为被教导并且与其正常行为的偏差被视为操纵的结果。
13.借助于深度学习方法,可以独立识别该技术装置对于所基于的操纵识别来说重要的依赖性和特性。由于该技术装置的正常行为在操纵识别模型中被训练,所以可以识别该技术装置的与其有偏差的行为。这具有如下优点:新的和到目前为止未知的操纵尝试也可以通过这种操纵识别模型来被识别。
14.上述方法使用操纵识别模型,该操纵识别模型被设计成分类模型。操纵识别模型被训练为:基于在连续的时间步长内所提供的输入向量来生成分类向量作为输出向量。输入向量的元素分别对应于在一个时间步长内的系统参量和至少一个调定量的值,并且反映系统的当前状态。分类向量根据时间步长的输入向量来说明监控参量的值所在的值范围。
15.通过将操纵识别模型设计成至少部分循环的网络,操纵识别模型也可以考虑该技术装置的动态影响。
16.此外,输出向量可具有标称编码,该标称编码针对监控参量说明了该监控参量所在的值范围,其中这些值范围通过多个类别来被分类,其中该监控参量的值范围随着输出向量的索引值k的升高分别通过相对应地递增/递减的(经排序的)分类阈值s1, s2, s3, ..., s
k-1
来被说明,其中输出向量的元素值以它们的值来说明该监控参量是预期小于还是大于与输出向量的元素的索引值相对应的分类阈值。
17.因此,对用于说明大致的监控参量的分类参量的评估基于编码方案,如其例如从j. cheng等人的出版文献“a neural network approach to ordinary regression”,ieee international joint conference on neural networks,1279至1284页,2008年中所公开的那样。在这种情况下,每个类别都使用k维向量来被表示,其中具有升高的索引值k的k个
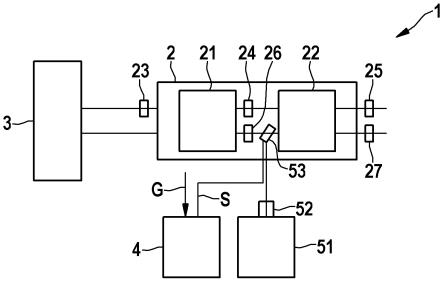
类别针对分别相对应地递增/递减的分类阈值s1, s2, s3, ..., s
k-1
来说明:监控参量y是预期小于还是大于或者是大于还是小于相对应的分类阈值s1, s2, s3, ..., sk,也就是说针对y《s1为(1, 0, ...0),针对y 《 s2为(1, 1, 0,...0),针对y《s3为(1, 1, 1, 0, ...0),以此类推,直至针对y 》= s
k-1
为(1, ..., 1)为止。据此得到具有编码(1, 1, ..., 1, 0, ..., 0)的分类向量。尤其是,第一类别通过k维向量(1, 0, ..., 0)来被表示,并且第k个类别相对应地通过k维1向量(1, ..., 1)来被表示。该编码也称为针对标称类别的标称编码。
18.操纵识别模型可对应于用于输出具有k个元素的输出向量的神经网络,也就是说例如借助于具有k个神经元的全连接层,其中输出层具有单调递增的激活函数,诸如sigmoid激活函数,该激活函数具有从0到1的值范围。
19.为了评估操纵识别模型,针对每个时间步长,将当前的输入参量、也就是说系统参量和至少一个调定量以相对应的输入向量的形式输送给操纵识别模型,并且获得相对应的输出向量作为分类向量。由于输出向量的元素可以取0与1之间的值,所以这些元素说明了监控参量处在该监控参量的通过索引值k所限定的值范围内或也许更大的建模概率。例如,输出(0.99, 0.9, 0.8, 0, ..., 0)可以被解释为使得真实值有99%的概率至少处在类别1的值范围内,真实值有90%的概率至少处在类别2的值范围内,以此类推。可以识别真实值是否有一定的概率甚至更大,其方式是考虑针对接下来的类别3、4
……
的概率。操纵识别模型的分类可以使用随后描述的方法在分别具有一个或多个时间步长的连续的时间窗内被评估。
20.现在,针对每个时间窗,根据针对操纵识别模型所提供的类别划分来对相关的连续的时间步长的一个或多个输入向量进行分类,并且针对每个时间步长获得相对应的输出向量。
21.此外,针对每个时间步长,在该技术装置中测量或者根据测量值来确定实际的监控参量。
22.可以规定:在标称编码的情况下使用实际的监控参量的值来创建测量分类向量。
23.实际的监控参量根据针对操纵识别模型的训练所提供的类别划分来被转换成测量分类向量。这利用上述标称编码来实现,其中具有升高的索引值k的k个类别针对分别相对应地递增/递减的分类阈值s1, s2, s3, ..., s
k-1
来说明:实际的监控参量y
real
是小于还是大于或者是大于还是小于相对应的分类阈值s1, s2, s3, ..., sk。
24.可以规定:如果实际的监控参量预期小于或大于与输出向量的元素的索引值相对应的分类阈值,则测量分类向量的元素具有第一值,并且如果实际的监控参量预期大于或小于与输出向量的元素的索引值相对应的分类阈值,则测量分类向量的元素具有第二值。
25.此外,为了确定第一比较向量,输出向量的元素可以基于超过作为舍入限制的第一操纵阈值被舍入到第一值并且基于低于作为舍入限制的第一操纵阈值被舍入到第二值,其中为了确定第二比较向量,输出向量的元素基于超过作为舍入限制的第二操纵阈值被舍入到该第一值并且基于低于作为舍入限制的第二操纵阈值被舍入到该第二值,其中根据第一比较向量的具有该第一值的元素值的数目与测量分类向量的具有该第一值的元素值的数目之间的差异并且根据测量分类向量的具有该第一值的元素值的数目与第二比较向量的具有该第一值的元素值的数目之间的差异来识别操纵。
26.例如,现在根据相应的输出向量来确定第一比较向量,其中给在该输出向量中高于指定的例如为0.75的第一操纵阈值的所有元素都分派1,并且给具有低于第一操纵阈值的值的所有元素都分派为0的元素值。现在,可以将第一比较向量与测量值分类向量进行比较。根据测量分类向量的具有为“1”(示例性的第一值)的元素值的元素的数目与第一比较向量的具有为“1”(示例性的第一值)的元素值的元素的数目的差异/差来得到第一操纵值。针对多个时间步长,差异/差可以被加和或者以其它方式被汇总,以便获得第一操纵值。
27.例如,现在根据相应的输出向量来确定第二比较向量,其中给在该输出向量中高于指定的例如为0.05的第二阈值的所有元素都分派1,并且给具有低于第一操纵阈值的值的所有元素都分派为“0”(示例性的第二值)的元素值。在此,第二操纵阈值被选择得明显小于第一阈值。现在,可以将第二比较向量与测量值分类向量进行比较。根据第二比较向量的具有为“1”(示例性的第一值)的元素值的元素的数目与测量分类向量的具有为“1”的元素值的元素的数目的差异/差来得到第二操纵值。针对多个时间步长,差异/差可以被加和或者以其它方式被汇总,以便获得第二操纵值。
28.现在,根据第一和第二操纵值,可以确定操纵识别值。该方法可以针对每个时间窗被单独执行,或者也可以针对评估时间窗的多个时间窗来被执行。
29.针对每个时间窗都可以生成操纵信号,其中根据评估期的多个时间窗的表明操纵的操纵信号的比例来识别操纵。
30.可以规定:该技术装置包括废气后处理装置,其中输入向量包括针对尿素注射系统的调定量,作为该调定量。尤其可以报告所识别出的操纵,或者可以根据所识别出的操纵来运行该技术装置。
31.按照另一方面,规定了一种用于技术装置、尤其是机动车中的技术装置、尤其是废气后处理装置的操纵识别的设备,其中该设备构造用于:
‑ꢀ
在连续的时间步长提供输入向量,该输入向量具有一个或多个系统参量并且具有用于干预该技术装置的至少一个调定量;
‑ꢀ
使用基于数据的操纵识别模型,以便在每个时间步长内针对各一个输入向量生成相对应的输出向量作为分类向量,其中该基于数据的操纵识别模型被设计用于针对输入向量来输出说明监控参量在值范围方面的分类的输出向量;
‑ꢀ
在这些连续的时间步长内基于至少一个测量值来提供实际的监控参量;
‑ꢀ
针对每个时间步长,根据实际的监控参量来创建测量分类向量;
‑ꢀ
根据该测量分类向量以及针对时间窗的一个或多个时间步长的第一和第二比较向量来识别操纵,其中该第一和第二比较向量通过基于作为舍入限制的第一操纵阈值和与第一操纵阈值不同的第二操纵阈值对输出向量的元素值的舍入来被确定。
附图说明
32.随后,依据随附的附图更详细地阐述实施方式。其中:图1示出了作为技术系统的示例的废气后处理装置的示意图;图2示出了阐明用于图1的废气后处理装置的操纵识别的方法的流程图。
具体实施方式
33.图1示出了用于具有燃烧发动机3的发动机系统1的废气后处理系统2的示意图。废气后处理装置2被设计用于对燃烧发动机3的燃烧废气的废气后处理。燃烧发动机3可以构造成柴油发动机。
34.废气后处理装置2具有微粒过滤器21和scr催化净化器22。在微粒过滤器21的上游、微粒过滤器21的下游和scr催化净化器22的下游利用相应的温度传感器23、24、25来测量废气温度,并且在scr催化净化器22的上游和下游利用相应的nox传感器26、27来测量no
x
含量,并且将所述废气温度和所述含量在控制单元4中进行处理。传感器信号作为系统参量g被提供给控制单元。
35.设置尿素储存器51、尿素泵52和针对尿素的可控注射系统53。注射系统53能够通过控制单元4借助于调定量s来被控制地将预定量的尿素输送到scr催化净化器22上游的燃烧废气中。
36.控制单元4根据公知方法通过规定针对注射系统53的调定量来控制尿素到scr催化净化器22上游的输送,以便实现对燃烧废气的尽可能好的催化净化,使得氮氧化物含量尽可能被减少。
37.传统的操纵设备对传感器信号和/或调节信号进行操纵,以便减少或者完全停止尿素的消耗。
38.虽然可以通过基于规则地监控废气后处理装置的运行状态来识别这样的操纵,但是并不是所有相对应的不被允许的运行状态都可以用这种方式来被检查。因而,提出了一种基于操纵识别模型的操纵识别方法。这可以在控制单元4中被实施,如依据图2的流程图示例性示出的那样。该方法可以在控制单元4中作为软件和/或硬件来被实现。
39.在步骤s1中,针对一个或多个时间步长记录由系统参量g和至少一个调定量s、尤其是针对尿素的喷射系统53的调定量构成的输入向量。
40.系统参量s可包括如下参量中的一个或多个参量:上述废气温度;上述nox浓度;当前发动机力矩;燃烧发动机3的当前充气量;燃烧发动机3的转速;燃烧发动机3的被注入的燃料量;废气系统内的压力;nh3浓度;在燃烧废气中的氧气浓度;denox效率(denox效率依据在scr催化净化器前后的nox浓度来被确定);发动机温度;驾驶员所需的力矩,例如通过加速踏板位置来预先给定;车速;环境压力;环境温度;换挡的所选挡位;车辆重量;废气再循环阀的位置;和燃烧废气中的炭烟量。
41.在步骤s2中,借助于预先训练的基于数据的操纵识别模型来评估输入向量,以便获得针对每个时间步长的输出向量。
42.操纵识别模型被设计用于根据在每个时间步长内的输入向量来输出分类向量,作为输出向量。为了对该技术装置的动态行为进行建模,基于数据的操纵识别模型具有适合的结构,该结构容许对动态行为的建模。例如,基于数据的操纵识别模型可具有带循环组分的神经网络,例如由“全连接(fully connected)”层和循环层的组合,如其例如在lstm或gru模型中公知的那样。替代地,也可以提供如narx高斯过程模型那样的基于数据的模型,以便映射该技术装置的动态行为。
43.操纵识别模型被设计用于以针对标称类别的标称编码的格式来输出该输出向量。该格式规定:使用k维向量来说明每个类别,其中具有升高的索引值k的k个类别针对分别相
对应地递增/递减的分类阈值s1, s2, s3, ..., s
k-1
来限定:监控参量y是预期小于还是大于或者是大于还是小于相对应的分类阈值s1, s2, s3, ..., sk,也就是说针对y《s1为(1, 0, ...0),针对y 《 s2为(1, 1, 0,...0),针对y《s3为(1, 1, 1, 0, ...0),以此类推,直至针对y 》= s
k-1
为(1, ..., 1)为止。据此得到具有编码(1, 1, ..., 1, 0, ..., 0)的分类向量。尤其是,第一类别通过k维向量(1, 0, ..., 0)来被表示,并且第k个类别相对应地通过k维1向量(1, ..., 1)来被表示。
44.可以在多个时期内以本身公知的方式来对操纵识别模型进行训练。在此,在每个时期内都对所有训练数据进行处理。训练数据对应于系统参量和至少一个调定量的输入向量,所述系统参量和所述至少一个调定量是在废气后处理装置2的防操纵的运行环境中被记录的。输入向量分配有监控参量、也就是说废气侧的氮氧化物浓度的相对应的测量值。在训练之前,根据通过分类阈值s1, s2, s3, ..., sk所限定的类别划分来对该测量值进行分类。因此,在递增或递减的分类阈值s1, s2, s3, ..., sk的情况下,得到这些测量值中的每个测量值到分类向量的分配。现在,该分类向量被用作用于训练操纵识别模型的标签。
45.此外,训练数据被划分成批次,这些批次的批次大小可自由指定,但是通常选择2的幂,以便实现最佳的可并行性。还将指定评估期的长度。优选地,500至3000条训练数据是适合的,这些训练数据分别对应于所测量的时间步长。
46.为了训练,在需要时可以对输入值进行预处理。这样,例如常见的是对这些输入值进行归一化、进行鲁棒归一化或者进行标准化。可以使用均方误差(mean squared error)或均方根误差(root mean squared error)或二元交叉熵作为用于训练操纵识别模型的误差函数。所计算出的误差以常规的方式被使用,以便借助于反向传播和常见的优化策略、诸如sgd、adam、adagrad等等来使神经网络的权重适配。
47.对操纵识别模型的评估引起对输出向量的输出,该输出向量的元素可以取在0与1之间的值范围内的值,对应于在分类向量中在训练过程期间的测量值的归一化。同样能够以类似的方式实现针对值范围的其它编码。在所描述的实施例中,输出向量针对每个元素都具有在0与1之间的值,这说明了监控参量、也就是说下游的氮氧化物浓度处在通过该元素的索引值所说明的值范围内的概率。这样,例如为0的元素值说明了监控参量的值处在通过索引值所指定的值范围内的概率为零。另一方面,为1的元素值说明了操纵识别模型的绝对可靠性:监控参量的值处在通过索引值所指定的值范围内。通常,在上文所使用的编码的情况下,输出如下输出向量,该输出向量的元素值随着索引值的升高而减小。
48.针对每个或当前的时间步长,存储输出向量。
49.同时,在随后的步骤s3中,针对相应的时间步长记录和存储监控参量的实际值、诸如废气侧的氮氧化物浓度的测量值。
50.如果在步骤s4中查明:达到所要考虑的时间窗的指定时间步长数目(二选一:是),则该方法以步骤s5来继续,否则(二选一:否)跳回到步骤s1。时间窗的指定的时间步长数目可以为1或者大于1。尤其是,时间步长数目可以在50与500之间。
51.在随后的步骤中,针对该时间窗的一个或多个时间步长来评估所存储的输出向量和实际的监控参量的相对应的测量值。为此,在步骤s5中,首先将测量值根据类别划分转换成测量值分类向量,该类别划分也用于操纵识别模型的训练。这按照上述方案根据指定的分类范围阈值来实现,这些分类范围阈值分别说明了范围,以便获得与标称编码相对应的
测量值分类向量。
52.随后,在步骤s6中,针对每个时间步长,根据第一操纵阈值来相对应地确定第一比较向量。第一操纵阈值针对输出向量说明了舍入方案,在该舍入方案中,高于第一操纵阈值的所有值都被舍入到1(第一值),并且低于第一操纵阈值的所有值都被舍入到0(第二值)。现在,针对在评估期中的每个时间步长,获得第一比较向量。与测量值分类向量一样,该第一比较向量只具有元素值为0和1的元素。
53.现在,在步骤s7中,针对每个时间步长,第一操纵值被确定为测量值分类向量的元素和与第一比较向量的元素和的差异或差并且必要时在这些时间步长期间被加和或者汇总。也可以将针对时间窗的多个时间步长的测量值分类向量的元素和之和与针对该时间窗的多个时间步长的第一比较向量的元素和之和的商确定为第一操纵值。
54.尤其是,在该第一比较中,检查这些值的其中操纵识别模型非常可靠的怎样的比例与实际测量结果相符。在正常运行时应预期:第一比较向量的“1”值(第一值)的仅仅非常微小的比例处在测量比较向量之外。
55.如果出于技术原因该监控参量的当前值例如在一定的时间段内高于正常情况,则模型最多表明这一点,存在与测量值的相符。然而,在尝试操纵的情况下,事先并不知道在该范围内的监控参量的值高于正常情况——被操纵的传感器值相对应地并不升高,存在与监控参量的值的偏差。
56.随后,在步骤s8中,根据输出参量借助于第二操纵阈值来确定第二比较向量。如上所述,第二操纵阈值指定了舍入方案,也就是说大于第二操纵阈值的所有值都被舍入到1(第一值),小于第二操纵阈值的所有值都被舍入到值0(第二值)。第二操纵阈值优选地明显小于第一操纵阈值,并且例如可以以在0.05与0.2之间的值来被指定。
57.在步骤s8中,在某种程度上可以说反过来,检查所测量到的值是否处在其中操纵识别模型有指定的概率可靠的值范围内。如果例如只会执行第一比较,则操纵尝试可能会容易通过相对应的干预来指定监控参量的恒定地高的值,而通过该第一比较并不会识别出操纵。
58.现在,在步骤s9中可以将第二比较向量与测量值分类向量进行比较。根据第二比较向量的具有为“1”的元素值的元素的数目或元素和与测量分类向量的具有为“1”的元素值的元素的数目或该测量分类向量的元素和的差异/差来得到第二操纵值。针对该时间窗的时间步长,差异/差可以被加和或者以其它方式被汇总,以便获得第二操纵值。也可以将针对时间窗的多个时间步长的第二比较向量的元素和之和与针对该时间窗的多个时间步长的测量值分类向量的元素和之和的商确定为第二操纵值。
59.在随后的步骤s10中,对第一和第二操纵值进行评估,以便查明当前时间窗的操纵。可以将第一和第二操纵值分别与指定的阈值进行比较,以便产生针对当前时间窗的操纵信号,该操纵信号说明了是否可能存在操纵。例如,当第一和第二操纵值中的一个操纵值已经超过预定的阈值并且借此被识别为异常时,可以产生针对当前时间窗的说明是否存在操纵的操纵信号。当第一和第二操纵值的尤其是经加权的平均值超过预定的阈值并且借此识别出异常时,也可以产生针对当前时间窗的说明是否存在操纵的操纵信号。
60.因此,可以针对时间窗中的每个时间窗确定操纵信号,其中如果多个时间窗的操纵信号中的至少指定的比例表明存在操纵,则识别出操纵。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1