一种基于机器学习的盾构施工过程地质特征确定方法
1.本发明涉及盾构隧道技术领域,尤其涉及一种基于机器学习的盾构施工过程地质特征确定方法。
背景技术:
2.随着城市化的快速发展,城市交通压力日益增加,越来越多的城际铁路和地铁等公共交通设施得到了快速发展。盾构法由于安全、环保的特点,在城市地下公共交通的施工中得到了广泛地应用。土压平衡盾构机由千斤顶推进,驱动电机驱动刀盘转动,使得到盘上的刀具贯入并切削土壤和岩石,通过土仓和螺旋输送机将岩石和土体运输到外部。地质特征是影响盾构参数设置和刀具磨损的关键因素之一,盾构机在不同特征的地质条件施工时,需设置不同的掘进参数。盾构掘进前需要进行地质勘察了解地质特征,而地质勘察孔往往不连续且间隔一定距离,无法为盾构掘进提供实时准确的地质特征信息。为了保证盾构机安全、高效地掘进,确定盾构掘进过程中的地质特征至关重要。
3.根据不同的地质特征,选择合适的盾构机类型、设置良好的盾构参数能够极大地提升盾构施工效率。刘允刚等于2013年在《施工技术》上发表的《复杂地质条件盾构设备选型及关键参数选择》中强调了不同地质特征对盾构机选型、刀具配置和盾构参数设置有着极其重大的影响。目前,施工区间地质特征往往由两勘察孔的地质特征采用线性连接推测获得,而无法实时获得盾构机前方地质特征类型。因此,为了实时获取盾构机前方地质特征,并利用地层特征指导盾构参数的设置和盾构刀具的更换,有必要提出一种基于机器学习的盾构施工过程地质特征确定方法。
4.经过对现有技术文献检索发现,申请号为201810649269.0,专利名称为:基于xgboost的盾构施工不良地质类型预测方法,该方法利用随机森林提取地质特征,并采用xgboost算法对施工过程中的不良地质类型进行预测,可用于盾构施工过程中实时监测和分析开挖面围岩的地质情况。但是,该方法仅针对不良地质情况进行预测,无法对正常掘进状态下的地质特征进行预测。此外,该方法仅通过一种算法进行不良地质预测,容错率较低。本发明专利提出了一种基于机器学习的盾构施工过程地质特征确定方法,根据盾构机实时掘进参数动态确定盾构施工过程的地质特征并进行标签化,通过机器学习中的堆叠算法对盾构机前方地质特征进行精准确定,从而更好地指导盾构机参数设置和刀具的更换。
技术实现要素:
5.本发明实施例所要解决的技术问题在于,提供一种基于机器学习的盾构施工过程地质特征确定方法,该方法能够有效地对盾构机穿越的地质特征进行分类并确定,从而更好地指导盾构机掘进参数的设置和盾构刀具的更换。
6.为了解决上述技术问题,本发明提供了一种基于机器学习的盾构施工过程地质特征确定方法,包括以下步骤:
7.s1:收集地质勘察报告资料和盾构掘进参数,并进行地质特征预分类;
8.s2:对所述盾构掘进参数进行预处理,所述预处理包括对收集的盾构机参数数据进行剔除处理、数据光滑性处理、数据二次变换和数据标准化处理,得到标准化的fpi与tpi指数;
9.s3:将所述标准化的fpi与tpi指数输入k-means++算法,将地质特征类别从2~9开始划分,在所有划分类别中采用肘部算法和轮廓系数确定地质特征最终的类别数;
10.s4:构建地质特征确定方法的数据集,将所述标准化的fpi与tpi指数作为输入数据集,标签化后地质特征作为输出集;
11.s5:将所述数据集输入到堆叠分类算法中,采用网格搜索算法和k折交叉验证进行优化,得到地质特征确定方法;
12.将新收集的盾构掘进参数进行处理并输入到地质特征确定方法中,输出确定地质特征类型。
13.其中,所述盾构掘进参数包括盾构机推力f、推进速度v、刀盘扭矩t和刀盘转速n。
14.其中,所述地质特征预分类为根据地质勘察报告,将盾构法隧道设计穿越的地质特征人工分为k0类。
15.其中,所述剔除处理包括删除盾构机实时参数中的空白值和异常值d,所述异常值d定义为其中,x为采集的盾构数据;为数据的平均值;σ为采集数据的标准差。
16.其中,所述数据二次变换包括fpi与tpi处理,将光滑性处理过的数据进行二次计算得到fpi与tpi指数,所述fpi为单位切深下所需要的盾构推力;所述的tpi为土体抵抗刀盘形成隧洞的能力,所述fpi与tpi指数由以下公式确定:
17.fpi=f/p
18.tpi=t/p
19.p=v/n
20.式中,f为盾构机推力(kn);t为刀盘扭矩(kn
·
m);p为贯入度(mm/r);v是推进速度(mm/min);n为刀盘转速(rpm)。
21.其中,所述数据标准化处理包括采用标准化公式将所述fpi与tpi指数落入0-1之间,所述数据标准化由以下公式确定:
22.式中,x
′
为变换后的数据;x为原始数据;x
min
为数据中的最小值;x
max
为数据中的最大值。
23.其中,所述k-means++算法包括以下步骤:
24.a:随机选取一个样本点作为初始聚类中心;
25.b:计算每个样本点到聚类中心的距离d(x)和每个样本点被选为下一个聚类中心的概率p,d(x)和p由以下公式确定:
[0026][0027]
[0028]
式中,(x
c
,y
c
)为聚类中心点坐标;(x
i
,y
i
)为任意样本点坐标;x为样本点;x为数据集;
[0029]
c:将每个样本点的概率累加,得到每个样本点的概率区间;采用轮盘法选取下一个聚类中心点,然后重复步骤b,直至选出k个聚类中心;
[0030]
d:计算每个样本点分别至k个聚类中心的距离,并将每个样本点分配给距离最小的聚类中心所属类别;
[0031]
e:对每个类别的所有样本点重新计算聚类中心,聚类中心由以下公式确定:
[0032][0033]
式中,μ
i
为聚类中心(质心);c
i
为第i类;x为c
i
中的样本点;
[0034]
f:重复步骤d和步骤e直至聚类中心不发生改变。
[0035]
其中,所述轮盘法包括在0~1之间随机产生一个随机数,判断所述随机数所属的区间,选择区间对应的样本点为下一个聚类中心。
[0036]
其中,所述肘部算法包括根据每个类别内所有样本点的平方误差和sse与类别数k在二维平面图上绘制折线图,将每个点两侧的连线所成的夹角从小到大排列,前两个角度顶点处的平方误差和对应的类别数为候选类别数k
c
;
[0037]
所述轮廓系数s为根据划分类别内样本点的最小组内距离和最大组间距离,由以下公式确定:
[0038][0039]
b
i
=min{b
i1
,b
i2
,b
i3
,
…
,b
ik
}
[0040]
式中,s
i
为单个样本点的轮廓系数;a
i
为同一类别内第i个样本点到其他样本点的平均距离;b
ik
为第i个样本点到其他类别内所有样本点的平均距离。
[0041]
其中,所述堆叠分类算法包括m层初级学习器和1层次级学习器,第i层初级学习器包含n
i
个初级学习器,数据集依次经过m层初级学习器和1个次级学习器处理后,输出最终的地质特征类型;所述初级学习器和次级学习器为具有分类功能的机器学习算法;
[0042]
所述网格搜索算法包括将堆叠算法中的初级学习器和次级学习器中的j个超参数进行逐一配对,经过训练和验证后得到最优的超参数组合;
[0043]
所述k折交叉验证包括将训练集等分为k组,每一组轮流作为验证集,对每个分类算法进行评估,最后得到每个算法的平均误差;
[0044]
所述地质特征确定方法指的是经过所述网格搜索和k折交叉验证后,选取最高准确率的分类算法及超参数组合得到的地质特征确定方法。
[0045]
实施本发明实施例,具有如下有益效果:本发明利用k-means++算法、肘部算法和轮廓系数确定地质特征类别,最后利用优化的堆叠算法实现地质特征的确定,同时,本发明明确了地质特征类别数量的确定方法,综合使用多种机器学习算法提升了该方法的容错率,此外,采用网格搜索和k折交叉验证提升了地质特征确定方法的准确度。本发明操作简单易行,成本低,能够显著地提高盾构的施工效率,保证了盾构掘进的安全性。
附图说明
[0046]
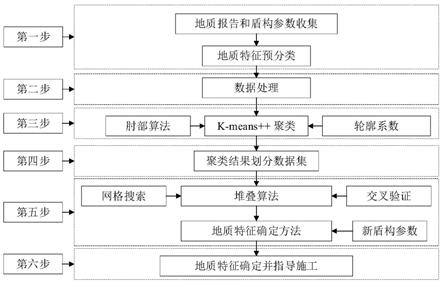
图1为本发明一实施例中地质类型确定方法流程示意图;
[0047]
图2为本发明一实施例中地质特征类别数确定方法示意图;
[0048]
图3为本发明一实施例中标签化的地质特征类型示意图;
[0049]
图4为本发明一实施例中堆叠算法具体实施路线示意图;
[0050]
图5为本发明一实施例中确定的地质类型随环号变化示例。
具体实施方式
[0051]
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述。
[0052]
本发明实施例以位于广州市某双线盾构隧道示例说明,隧道全长3110m,盾构管片设计内径8.0m、外径8.8m、环宽1.8m。采用刀盘直径9.15m的土压平衡盾构进行施工。影响隧道施工的地质条件主要为全风化花岗岩、中风化花岗岩和微风化花岗岩。盾构隧道修建位于市区,地质勘察孔间隔较大,两勘察孔之间的地质特征不明确,本工程采用机器学习的盾构施工过程地质特征确定方法进行施工。
[0053]
本实施例技术路线图如图1所示,具体的实施步骤如下:
[0054]
第一步:收集地质勘察报告资料和盾构掘进参数,进行地质特征预分类。
[0055]
(1)收集地质勘察单位在盾构施工前对施工区间进行地质勘察后出具的总结报告及其图纸,主要包括工程地质条件、水文地质条件和经过地质钻孔取土后,获取的施工区间地质剖面图和土层柱状图。
[0056]
(2)收集由盾构机传感器按照时间收集反馈的盾构机参数。包括:盾构机推力(f)、推进速度(v)、刀盘扭矩(t)和刀盘转速(n)。
[0057]
(3)根据地质勘察报告,洞身影响范围内的土层包括全风化花岗岩、中风化花岗岩和微风化花岗岩,将盾构法隧道设计穿越的地质特征人工分为全断面软土地层、软硬不均地层和全断面硬岩地层3类。
[0058]
第二步:盾构机参数预处理。
[0059]
(1)对收集的盾构机参数数据进行剔除处理、数据光滑性处理、数据二次变换和数据标准化处理。具体地:
[0060]
数据剔除处理是指删除盾构机实时参数中的空白值和异常值。异常值d由以下公式确定:
[0061][0062]
式中,x为采集的盾构数据;为数据的平均值;σ为采集数据的标准差。
[0063]
将删除空白值与异常值后的盾构机参数进行降噪处理,选取3个连续数据进行算数平均值处理,减少数据中的峰值,使得整体数据更具有光滑性。
[0064]
将光滑性处理过的数据进行二次变换得到fpi与tpi指数,fpi与tpi指数由以下公式确定:
[0065]
fpi=f/p
[0066]
tpi=t/p
[0067]
p=v/n
[0068]
式中,f为盾构机推力(kn);t为刀盘扭矩(kn
·
m);p为贯入度(mm/r);v是推进速度(mm/min);n为刀盘转速(rpm)。
[0069]
采用标准化公式将fpi与tpi指数落入0-1之间,标准化公式如下:
[0070][0071]
式中,x
′
为变换后的数据;x为原始数据;x
min
为数据中的最小值;x
max
为数据中的最大值。
[0072]
第三步:将标准化后的fpi与tpi指数输入k-means++算法,采用肘部算法、轮廓系数(s)确定地质特征最终的类别数(k)。
[0073]
(1)将标准化后的fpi与tpi指数输入k-means++算法,将地质特征类别数从2~9开始划分类别,分别获取对应类别的平方误差和(sse)和轮廓系数。k-means++算法具体步骤如下:
[0074]
a:随机选取一个样本点作为初始聚类中心。
[0075]
b:计算每个样本点到聚类中心的距离(d(x))和每个样本点被选为下一个聚类中心的概率p。d(x)和p由以下公式确定:
[0076][0077][0078]
式中,(x
c
,y
c
)为聚类中心点坐标;(x
i
,y
i
)为任意样本点坐标;x为样本点;x为数据集。
[0079]
c:将每个样本点的概率累加,得到每个样本点的概率区间;采用轮盘法选取下一个聚类中心点,然后重复步骤b,直至选出k个聚类中心。
[0080]
优选地,所述的轮盘法是指在0~1之间随机产生一个随机数,判断这个随机数所属的区间,选择区间对应的样本点为下一个聚类中心。
[0081]
d:计算每个样本点分别至k个聚类中心的距离,并将每个样本点分配给距离最小的聚类中心所属类别。
[0082]
e:对每个类别的所有样本点重新计算聚类中心(质心),聚类中心由以下公式确定:
[0083][0084]
式中,μ
i
为聚类中心(质心);c
i
为第i类;x为c
i
中的样本点。
[0085]
f:重复步骤d和步骤e直至聚类中心不发生改变。
[0086]
(2)如图2所示,作出误差平方和(sse)与类别数(k)所形成的肘部图形,将每个点两侧的连线所成的夹角从小到大排列,前两个角度顶点处的平方误差和对应的类别数3和4作为候选类别数k
c
。平方误差和(sse)的由以下公式确定:
[0087][0088]
(3)如图2,将轮廓系数绘制在二维平面图上,并将横轴与肘部算法的二维平面图对齐,将两张二维平面图合并再比较候选类别数k
c
。具体的,轮廓系数(s)由以下公式确定:
[0089][0090]
b
i
=min{b
i1
,b
i2
,b
i3
,
…
,b
ik
}
[0091]
式中,s
i
为单个样本点的轮廓系数;a
i
为同一类别内第i个样本点到其他样本点的平均距离;b
ik
为第i个样本点到其他类别内所有样本点的平均距离。轮廓系数(s)为所有样本点轮廓系数的平均值。
[0092]
(4)根据肘部算法和轮廓系数确定地质特征最终的类别数。肘部图中,根据角度从小到大排列,前两个角度顶点对应的候选类别数3和4;再根据轮廓系数,在k=3时,轮廓系数最大。因此,选取地质特征最终的类别数k=3。
[0093]
第四步:根据最终确定的k=3和k-means++算法将地质特征进行标签化分别赋值为1、2和3。图3给出了标签化的地质类型示例。将fpi与tpi指数作为输入集,将标签化的地质特征作为输出集,按照4:1的比例划分训练集和预测集。
[0094]
第五步:如图4所示,将划分好的数据集输入到堆叠分类算法中,并采用网格搜索算法和5折交叉验证对堆叠分类算法进行优化,得到地质特征确定方法。
[0095]
(1)堆叠分类算法包括1层3个初级学习器和1层1个次级学习器。3个初级学习器分别为支持向量机(svm)、随机森林(rf)和梯度提升决策树(gbdt);1个次级学习器为逻辑回归(lr)。输入的数据集经过初级学习器分类后,得到具有3个特征的新数据集;然后将初级学习器产生的新数据集输入次级学习器进行学习并分类,得到最终的地质特征类型。
[0096]
(2)选取堆叠算法中的初级学习器的超参数进行网格算法配对。具体的,
[0097]
支持向量机中选取超参数为核函数(kernel),惩罚因子(c)和径向基函数参数(γ)。核函数选取有“rbf”、“linear”和“poly”;惩罚因子取值范围为[1,5],取值步长为0.5;参数γ取值范围为[0.1,1],取值步长为0.1。
[0098]
随机森林选取超参数为决策树的最大深度(max_depth)、子树的数量(n_estimators)和最小样本叶片(min_samples_leaf)。决策树的最大深度取值范围为[10,100],取值步长为10;子树的数量取值范围为[10,1000],取值步长为10;最小样本叶片取值范围为[1,10],取值步长为1。
[0099]
梯度提升树选取超参数为分类器的数量(n_estimators)和学习率(learning_rate)。分类器的数量取值范围为[1,1000],取值步长为10;学习率的取值范围为(0,1],取值步长为0.1。
[0100]
(3)将配对完成后的超参数输入到分类算法中,结合5折交叉验证将训练集等分为5组,每一组轮流作为验证集,对每个分类算法进行评估,最后得到每个算法的平均误差和准确率。
[0101]
(4)经过网格搜索和5折交叉验证后,选取最高准确率分类算法的超参数组合得到地质特征确定算法。具体的,
[0102]
支持向量机中选取最佳超参数组合为kernel=“rbf”、c=2和γ=0.8;随机森林中选取的最佳超参数组合为n_estimators=80、max_depth=30和min_samples_leaf=2;梯度提升树中选取的最佳超参数组合为n_estimators=270和learning_rate=0.8。
[0103]
支持向量机最佳准确率为0.992;随机森林最佳准确率为0.987和梯度提升树最佳准确率为0.974。
[0104]
将最佳超参数组合输入到堆叠算法中,采用逻辑回归算法作为次级学习器得到地质特征确定方法,该方法的准确率为0.996。
[0105]
第六步:如图5所示,将新收集的盾构掘进参数进行处理并输入到地质确定方法中,得到输出的确定地质特征类型。
[0106]
以上所揭露的仅为本发明一种较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1