基于卫星遥感的地面PM2.5反演方法及系统与流程
本发明涉及气溶胶监测技术领域,更为具体地,涉及一种基于卫星遥感的地面PM2.5反演方法及系统。
背景技术:
PM2.5指空气中空气动力学粒径小于2.5微米的颗粒物。与大粒径颗粒物相比,PM2.5粒径小,富含大量的有毒有害物质且在大气中的停留时间长、输送距离远,因而对人体和大气环境质量的影响很大。国外大量的流行病学研究证明PM2.5与负面的健康效应有关,如会导致心血管和呼吸系统疾病的发病率及死亡率升高。
其中,对PM2.5的健康效应的研究需要长时间、大范围的PM2.5暴露数据的支撑。而利用卫星遥感AOD(Aerosol Optical Depth,气溶胶光学厚度)反演地面PM2.5是近年来快速发展的一项新技术。与地面监测相比,卫星监测不受地面监测站点选址的限制,具有地面监测站点无可比拟的时间和空间覆盖度。
现有的利用卫星遥感AOD反演地面PM2.5浓度的方法主要有比例因子方法、基于物理机理的半经验公式法和统计模型法三种。
其中,比例因子方法是利用大气化学传输模型模拟出PM2.5与AOD的比例关系因子,然后将这个比例因子乘上卫星遥感得到的AOD,从而估算地面PM2.5浓度。该方法不需要地面PM2.5监测数据就可以进行模型模拟和计算,但模型准确性差,且涉及到大气污染化学传输模型的模拟,对数据要求高,需要准确的地面污染物排放清单,不利于推广应用。
基于物理机理的半经验公式法是基于PM2.5、AOD、湿度、以及AOD垂直廓线特征等参数之间关系的物理机理,构建出PM2.5的估算公式。由于PM2.5和AOD关系的物理机理比较复杂,现有的半经验公式尚不能完全准确描述他们之间的关系,因而使得PM2.5反演的效果总体不理想。
与前两种方法相比,统计模型法的准确性相对较高,特别是高级统计模型可适用于高PM2.5浓度区域,但其需要大量的地面监测数据来进行模型的拟合和验证。虽然我国目前已经构建了一些利用卫星遥感AOD反演PM2.5的高级统计模型方法(如广义线性模型、地理加权回归模型等),但其精度并不高,因此需要开发一种精度更高的统计模型,从而为环境及健康效应的研究提供精度更高的PM2.5暴露数据。
技术实现要素:
鉴于上述问题,本发明的目的是提供一种基于卫星遥感的地面PM2.5反演方法及系统,以解决现有的高级统计模型在反演地面PM2.5时存在精度不高的问题。
根据本发明的一个方面,提供一种基于卫星遥感的地面PM2.5反演方法,包括:
将待反演地区的AOD数据、地面PM2.5数据、气象数据以及土地利用数据分别重采样到创建的与AOD数据分辨率相同的网格后进行数据匹配;
根据网格中所匹配的地面PM2.5数据、AOD数据和气象数据,构建反映时间变异的线性混合效应模型,根据线性混合效应模型估算待反演地区的地面PM2.5的初步浓度值;
根据待反演地区的地理坐标和土地利用数据,构建反映空间变异的广义加和模型,根据广义加和模型获取线性混合效应模型的PM2.5残差;
将PM2.5残差与初步浓度值加和,估算待反演地区的地面PM2.5的最终浓度值。
此外,还包括:采用十折交叉验证方法对线性混合效应模型和广义加和模型进行交叉验证,并相应调整线性混合效应模型和广义加和模型,以确定最终的线性混合效应模型和广义加和模型;根据确定的最终的线性混合效应模型和广义加和模型估算待反演地区的地面PM2.5的最终浓度值。
另一方面,本发明还提供一种基于卫星遥感的地面PM2.5反演系统,包括:
数据匹配单元,用于将待反演地区的AOD数据、地面PM2.5数据、气象 数据以及土地利用数据分别重采样到创建的与AOD数据分辨率相同的网格后进行数据匹配;
线性混合效应模型构建单元,用于根据网格中所匹配的地面PM2.5数据、AOD数据和气象数据,构建反映时间变异的线性混合效应模型,根据线性混合效应模型估算待反演地区的地面PM2.5的初步浓度值;
广义加和模型构建单元,用于根据待反演地区的地理坐标和土地利用数据,构建反映空间变异的广义加和模型,根据广义加和模型获取线性混合效应模型的PM2.5残差;
PM2.5浓度值估算单元,用于将PM2.5残差与初步浓度值加和,估算待反演地区的地面PM2.5的最终浓度值。
利用上述根据本发明的基于卫星遥感的地面PM2.5反演方法及系统,通过采用两级(即线性混合效应模型+广义加和模型)高级统计模型来反映PM2.5随时间和空间的变异,从而有效提高对地面PM2.5浓度的估算精度;同时,还可以根据数据的可获得性,加入不同的气象数据、土地利用数据来进一步提高模型的精度,从而使PM2.5的反演更加灵活。
为了实现上述以及相关目的,本发明的一个或多个方面包括后面将详细说明并在权利要求中特别指出的特征。下面的说明以及附图详细说明了本发明的某些示例性方面。然而,这些方面指示的仅仅是可使用本发明的原理的各种方式中的一些方式。此外,本发明旨在包括所有这些方面以及它们的等同物。
附图说明
通过参考以下结合附图的说明及权利要求书的内容,并且随着对本发明的更全面理解,本发明的其它目的及结果将更加明白及易于理解。在附图中:
图1为根据本发明实施例的基于卫星遥感的地面PM2.5反演方法流程示意图;
图2为根据本发明实施例的基于卫星遥感的地面PM2.5反演系统的逻辑结构框图。
在所有附图中相同的标号指示相似或相应的特征或功能。
具体实施方式
以下将结合附图对本发明的具体实施例进行详细描述。
针对前述现有的高级统计模型在估算地面PM2.5浓度时存在精度不高的问题,本发明通过采用线性混合效应模型+广义加和模型两级高级统计模型,从而能够有效提高对地面PM2.5的估算精度。
在对本发明进行说明前,先对本发明中涉及的概念和术语进行说明。
在本发明中采用美国宇航局Aqua卫星上的中分辨率成像光谱仪(MODerate-resolution Imaging Spectroradiometer,简称MODIS)第六版(C6)卫星遥感AOD产品。对该产品中的数据采用暗目标算法(DT)和深蓝算法(DB)提取卫星AOD数据并进行逆方差加权融合,以构建并反演我国全国尺度的PM2.5浓度分布。其中,在本发明中,采用基于逆方差加权平均的卫星AOD数据融合方法对AOD数据进行融合,至于是如何采用上述方法对AOD数据进行融合的,则不在本发明描述的范围之内,在此不再赘述。
此外,需要说明的是,在本发明中PM2.5亦可写为PM2.5。
为了详细说明本发明提供的基于卫星遥感的地面PM2.5反演方法,图1示出了根据本发明实施例的基于卫星遥感的地面PM2.5反演方法流程。
如图1所示,本发明提供的基于卫星遥感的地面PM2.5反演方法包括:
S110:将待反演地区的AOD数据、地面PM2.5数据、气象数据以及土地利用数据分别重采样到创建的网格中,然后进行数据匹配。
需要说明的是,上述待反演地区的AOD数据为融合后的AOD数据,待反演地区的地面PM2.5数据、气象数据以及土地利用数据分别从相应的数据产品中收集所得。
其中,首先创建一个与AOD数据分辨率相当的网格,然后将融合后的待反演地区的AOD数据、收集到的待反演地区的地面PM2.5数据、待反演地区的气象数据和待反演地区的土地利用数据进行重采样到网格中并匹配。
具体地,对于AOD数据采用如下方式:首先构建AOD数据像元点的泰森多边形,并与创建的网格进行空间叠置分析,从而将AOD数据分配到网格中的每个网格单元中。
对于收集到的地面PM2.5数据采用如下方式:将网格中的某个网格单元内所有PM2.5站点同一天采集到的地面PM2.5数据进行平均后赋值给对应的网格单元。
对于气象数据采用如下方式:将网格中的某个网格单元的分辨率与该网格单元对应的气象数据的分辨率进行比较,将高于对应网格单元的分辨率的气象数据进行平均后赋值给对应的网格单元,将不高于对应网格单元的分辨率的气象数据采用空间插值方法赋值给对应的网格单元。
土地利用数据与气象数据类似,采用如下方式:将网格中的某个网格单元的分辨率与该网格单元对应的土地利用数据的分辨率进行比较,将高于对应网格单元的分辨率的土地利用数据进行平均后赋值给对应的网格单元,将不高于对应网格单元的分辨率的土地利用数据采用空间插值方法赋值给对应的网格单元。
为了提高模型的精度,除了上述的AOD数据、气象数据和土地利用数据外,还可以增加火点数据。具体地,为网格的每个网格单元创建一个缓冲区,计算该缓冲区内每天的火点数量,然后将计算的火点数量赋值给对应的网格单元。
当将上述数据都重采样到网格后,将同一网格单元内同一天不同类型的数据进行匹配。
S120:根据网格中所匹配的地面PM2.5数据、AOD数据和气象数据,构建反映时间变异的线性混合效应模型以估算待反演地区的地面PM2.5的初步浓度值。
其中,在构建线性混合效应模型时,只使用随时间变化的数据(如AOD数据、气象数据等),如此才能够反映出PM2.5随时间的变异。其中,气象数据包括地表风速、边界层高度、地表气压、边界层内平均相对湿度、降水量等。数据可以随年积日、月或者季节变化。
具体地,在构建线性混合效应模型的过程中,根据固定效应和随机效应截距、AOD数据、气象数据和火点数量的固定效应斜率、AOD数据随年积日变化的随机效应斜率、以及气象数据和火点数量的随机效应斜率构建线性混合效应模型,以估算地面PM2.5的初步浓度值。然而对于气象数据和火点数量的随机效应斜率,可根据实际情况设定随年积日或随月份或随季节变化, 或者也可不设定气象数据和火点数量的随机效应斜率。
其中,当用到火点数据时,还可以根据在每个网格单元中创建的缓冲区内的火点数量来加入到线性混合效应模型中,以提高模型的估算精度。
S130:根据待反演地区的地理坐标和土地利用数据,构建反映空间变异的广义加和模型以获取线性混合效应模型的PM2.5残差。
其中,在构建线广义加和模型时,只使用随空间变化的数据(即不随时间变化或随时间变化缓慢的数据,如地理坐标、土地利用数据等),如此才能够反映出PM2.5随空间的变异。其中,土地利用数据包括森林覆盖率和城市区域覆盖率等。
具体地,在构建上述广义加和模型的过程中,根据线性混合效应模型的PM2.5残差与待反演地区的地理坐标、土地利用数据之间的平滑函数关系,构建广义加和模型,以获取线性混合效应模型的PM2.5残差。
S140:将PM2.5残差与初步浓度值加和,估算待反演地区的地面PM2.5的最终浓度值。
进一步地,为了确保模型稳定性和PM2.5浓度值的估算精度,采用十折交叉验证方法对线性混合效应模型和广义加和模型进行交叉验证,并相应调整线性混合效应模型和广义加和模型,以确定最终的线性混合效应模型和广义加和模型,然后根据确定的最终的线性混合效应模型和广义加和模型估算待反演地区的地面PM2.5的最终浓度值。
具体地,在进行交叉验证的过程中,当交叉验证结果显示模型存在过度拟合时,通过调整AOD数据、气象数据、土地利用数据对线性混合效应模型和广义加和模型进行调整,然后对调整后的线性混合效应模型和广义加和模型再次进行交叉验证,直到交叉验证结果显示调整后的线性混合效应模型和广义加和模型的过度拟合在可接受(即预设)范围内时,根据调整后的线性混合效应模型和广义加和模型估算地面PM2.5的浓度值;当估算的地面PM2.5的浓度值在空间分布上存在异常时,可以重复上述S120~S140步骤,直到调整到满意的模型效果,进而确定最终模型。
需要说明的是,上述的最终模型指经过调整后形成的最终的线性混合效应模型和最终的广义加和模型。
下面以一个示例对本发明提供的基于卫星遥感的地面PM2.5反演方法进 行更为详细的说明。
S1:创建一个覆盖全中国(包括台湾)的网格,网格尺寸为0.1°×0.1°(大约为10km×10km,共100,699个网格单元),将融合的待反演地区的AOD数据分配到网格单元中。
其中,S1进一步包括:对MODIS AOD数据产品的所有原始像元中心点(包括缺失AOD数据的像元点)创建泰森多边形,然后将此泰森多边形与0.1°×0.1°网格进行空间叠置分析,从而将MODIS AOD原始像元重采样到0.1°×0.1°的网格,然后将采用DT和DB逆方差平均融合的AOD数据分配到网格单元中。
S2:收集待反演地区的地面PM2.5数据、气象数据、土地利用数据以及火点数据,将收集到的上述数据重采样到创建的网格中并匹配。
具体地,地面PM2.5数据来源于环境监测部门、气象数据采用GEOS-5FP(Goddard Earth Observing System Model,Version 5,戈达德地球观测系统模型第5版)气象数据产品、土地利用数据来源于GlobCover 2009(指拍摄时间为2009年的全球陆地覆盖数据)数据产品、火点数据来源于MODIS的火点观测数据,对各数据进行重采样到0.1°×0.1°的网格并进行分配。分配的过程如下:
S2.1:将某一网格单元内所有PM2.5站点同一天的数据进行平均后赋值给该网格单元;
S2.2:对于GEOS-5FP气象数据,由于其分辨率低于网格单元分辨率的,利用反距离加权插值方法进行赋值;
S2.3:对于GlobCover土地利用数据,由于分辨率高于网格单元分辨率的,对其进行平均处理分配到网格单元;
S2.4:对于MODIS火点数据,对每个网格单元创建75km的缓冲区,计算缓冲区内每天的MODIS的火点数,然后赋值给对应的网格单元。
S2.5:数据分配到网格后,将同一网格单元、同一天的不同类别数据进行匹配。
S3:线性混合效应模型设定了模型截距和AOD的斜率随年积日的变化、以及气象数据斜率随季节变化作为随机项,以此来解释模型关系的时间变异;对于降雨和火点数据,交叉验证结果显示其不适合设定随机项,因此只设定了固定效应项。
其中,在S3中,线性混合效应模型的基本结构如下式所示:
PM2.5,st=(μ+μ')+(β1+β1')AODst+(β2+β2')WSst+(β3+β3')PBLHst+(β4+β4')PSst
+(β5+β5')RH_PBLHst+β6Precip_Lag1st+β7Fire_spotsst (1)
+ε1,st(μ'β1')~N[(0,0),Ψ1]+ε2,sj(β2'β3'β4'β5')~N[(0,0,0,0),Ψ2]
式中:PM2.5,st:网格单元s在第t天的地面PM2.5浓度值;
AODst:网格单元s在第t天的逆方差加权平均融合的AOD;
WSst,PBLHst,PSst,RH_PBLHst,Precip_Lag1st:分别为网格单元s在第t天的地表风速、边界层高度、地表气压、边界层内平均相对湿度、前一天降水量;
Fire_spotsst:网格单元s在第t天的75km缓冲区范围内的MODIS火点数量;
μ和μ′:分别为固定效应截距和随年积日变化的随机效应截距;
β1-β7:各自变量的固定效应斜率;
β1′:AOD对年积日变化的随机效应斜率;
β2′-β5′:相应气象数据随季节变化的随机效应斜率;
ε1,st:网格单元s在第t天的误差项;
ε2,sj:网格单元s在季节j的误差项;
Ψ1和Ψ2:分别是随天和随季节变化随机效应的方差-协方差矩阵。
由于一些省份的PM2.5观测站点较少,特别是在西部一些省份(如西藏、新疆、青海等),没有足够多的匹配数据来构建一个稳健的模型,因此进行分省建模。对每个省创建一个缓冲区,用缓冲区内所有匹配数据进行建模。对于缓冲区的选择,需满足以下条件:1)至少50km;2)至少有3000个匹配数据;3)至少有300天的匹配数据。
在满足上述条件情况下,尝试不同的缓冲区大小,选择了模型表现最佳的缓冲区范围。对于不同省份缓冲区之间的重叠区域,本发明对其重复的预测估算值进行了平均处理。同时尝试了气象数据斜率随年积日或月份的变化作为随机效应,但结果发现这会造成模型的过度拟合。
S4:采用广义加和模型,对待反演地区的地理坐标、土地利用数据采用了薄板回归样条平滑函数进行拟合。
其中,在S4中,广义加和模型的基本结构如下式所示:
PM2.5_residst=
μ0+s(X_Lon,Y_Lat)s+s(ForestCover)s+s(UrbanCover)s+εst
(2)
式中:PM2.5_residst:线性混合效应模型得到的网格单元s在第t天的
PM2.5残差;
μ0:截距项;
s(X_Lon,Y_Lat)s:对网格单元s地理坐标的平滑函数;
s(ForestCover)s:对网格单元s森林覆盖率的平滑函数;
s(UrbanCover)s:对网格单元s城市区域覆盖率的平滑函数;
εst:网格单元s在第t天的误差项。
S5:采用了十折交叉验证进行验证,并对模型进行了数次调整;
其中,采用十折交叉验证对线性混合效应模型和广义加和模型的过度拟合进行评价,模型结构式(1)和(2)是经过多次验证和调整后的最终模型结构(即经过多次验证和调整而形成的最终的线性混合效应模型和广义加和模型)。
S6:将调整好的最终模型,应用于S2中不含地面PM2.5的匹配数据,以估算地面PM2.5浓度。
其中,对最终模型所估算出的PM2.5估算值空间分布进行分析,如无发现明显异常值,最终输出文件格式为逗号分隔值文件(即CSV文件)。
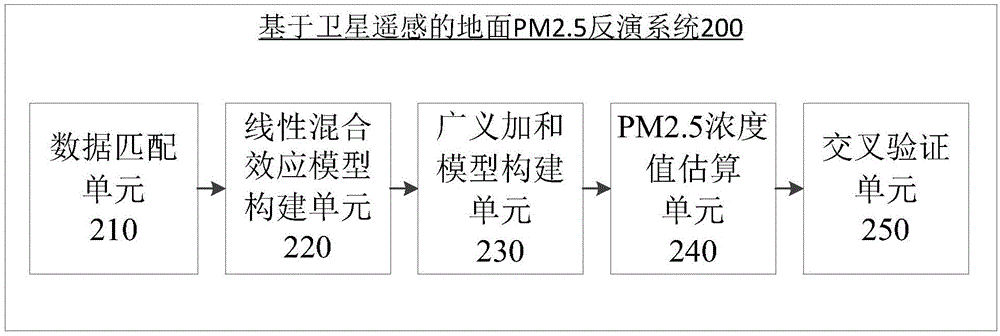
与上述方法相对应,本发明提供一种基于卫星遥感的地面PM2.5反演系统。其中,图2示出了根据本发明实施例的基于卫星遥感的地面PM2.5反演系统的逻辑结构。
如图2所示,本发明提供的基于卫星遥感的地面PM2.5反演系统200包括数据匹配单元210、线性混合效应模型构建单元220、广义加和模型构建单元230、PM2.5浓度值估算单元240和交叉验证单元250。
需要说明的是,上述待反演地区的AOD数据为融合后的AOD数据,待反演地区的地面PM2.5数据、气象数据以及土地利用数据分别从相应的数据产品中收集所得。
其中,数据匹配单元210用于将待反演地区的AOD数据、地面PM2.5数据、气象数据以及土地利用数据分别重采样到创建的与AOD数据分辨率相 同的网格中,然后进行数据匹配。
具体地,首先创建一个与AOD数据分辨率相当的网格,然后将融合后的待反演地区的AOD数据、收集到的待反演地区的地面PM2.5数据、气象数据和土地利用数据进行重采样到网格中并匹配。
对于AOD数据采用如下方式:首先构建AOD数据像元点的泰森多边形,并与创建的网格进行空间叠置分析,从而将融合后的AOD数据分配到网格中的每个网格单元中。
对于收集到的地面PM2.5数据采用如下方式:将网格中的某个网格单元内所有PM2.5站点同一天采集到的地面PM2.5数据进行平均后赋值给对应的网格单元。
对于气象数据采用如下方式:将网格中的某个网格单元的分辨率与该网格单元对应的气象数据的分辨率进行比较,将高于对应网格单元的分辨率的气象数据进行平均后赋值给对应的网格单元,将不高于对应网格单元的分辨率的气象数据采用空间插值方法赋值给对应的网格单元。
土地利用数据与气象数据类似,采用如下方式:将网格中的某个网格单元的分辨率与该网格单元对应的土地利用数据的分辨率进行比较,将高于对应网格单元的分辨率的土地利用数据进行平均后赋值给对应的网格单元,将不高于对应网格单元的分辨率的土地利用数据采用空间插值方法赋值给对应的网格单元。
为了提高模型的精度,除了上述的AOD数据、气象数据和土地利用数据外,还可以增加火点数据。具体地,为网格的每个网格单元创建一个缓冲区,计算该缓冲区内每天的火点数,然后将计算的火点数赋值给对应的网格单元。
当将上述数据都分配到网格后,即可将同一网格单元内同一天的不同类别数据进行匹配。
线性混合效应模型构建单元220用于根据网格中所匹配的地面PM2.5数据、AOD数据和气象数据,构建反映时间变异的线性混合效应模型以估算待反演地区的地面PM2.5的初步浓度值。
具体地,在构建线性混合效应模型的过程中,根据固定效应截距、随机效应截距、AOD数据、气象数据和火点数量的固定效应斜率、AOD数据随年积日变化的随机效应斜率、以及气象数据和火点量的随机效应斜率构建线性 混合效应模型,以估算待反演地区的地面PM2.5的初步浓度值。其中,对于气象数据和火点数量的随机效应斜率,可根据实际情况设定随年积日、月份或季节变化的随机效应斜率,或者不设定气象数据和火点数量的随机效应斜率。
进一步地,当用到火点数据时,还可以根据在每个网格单元中创建的缓冲区内的火点数量来加入到线性混合效应模型,以提高模型的估算精度。
广义加和模型构建单元230用于根据待反演地区的地理坐标和土地利用数据,构建反映空间变异的广义加和模型以获取线性混合效应模型的PM2.5残差。
具体地,在构建上述广义加和模型的过程中,根据线性混合效应模型的PM2.5残差与待反演地区的地理坐标、土地利用数据之间的平滑函数关系,构建广义加和模型,以获取线性混合效应模型的PM2.5残差。
PM2.5浓度值估算单元240用于将PM2.5残差与初步浓度值加和,估算待反演地区的地面PM2.5的最终浓度值。
进一步地,还可以包括交叉验证单元250,用于采用十折交叉验证方法对线性混合效应模型和广义加和模型进行交叉验证,并相应调整线性混合效应模型和广义加和模型,以确定最终的线性混合效应模型和广义加和模型,并根据确定的最终的线性混合效应模型和广义加和模型估算待反演地区的地面PM2.5的最终浓度值。
通过上述可知,本发明提供的基于卫星遥感的地面PM2.5反演方法及系统,采用两级(即线性混合效应模型+广义加和模型)高级统计模型来反映PM2.5随时间和空间的变异,从而有效提高对地面PM2.5浓度的估算精度;同时,加入不同的气象数据、土地利用数据来进一步提高模型的精度,从而使得对PM2.5的浓度估算更加灵活。
如上参照附图以示例的方式描述了根据本发明的。但是,本领域技术人员应当理解,对于上述本发明所提出的,还可以在不脱离本发明内容的基础上做出各种改进。因此,本发明的保护范围应当由所附的权利要求书的内容确定。
- 还没有人留言评论。精彩留言会获得点赞!