不同近红外光谱变量优选结果融合方法及应用与流程
本发明涉及近红外光谱学、化学计量学领域,尤其涉及一种光谱变量选择融合方法。
背景技术:
近红外光谱是指780~2526nm的电磁波,其信息源于分子非谐振性振动使分子从基态向高能级跃迁时产生的倍频和合频吸收。分子振动倍频与合频跃迁的能量间距离散,导致近红外光谱谱峰宽。相同分子振动倍频与合频形式多样,致使近红外光谱谱峰多。当检测对象为多组分复杂样本时,近红外谱带大量重叠,变量共线性严重,致使近红外光谱解析困难。具体来说,复杂样本近红外光谱通常包括几百甚至上千波长或波数变量,并不是所有变量均有益于待测目标,其中大部分变量高度相关,为冗余变量。基于化学计量学方法进行变量优选,在压缩数据量及模型运算量的同时,可减少噪声信号影响,利于模型性能提高。然而,现有技术中近红外光谱变量优选方法较多,而不同变量优选算法结果不同,甚至矛盾,为应用带来了困扰。
二维相关分析是一种通过对体系施加外部扰动,获取一系列变化的动态光谱,进而把一维线性光谱数据向二维平面扩展的化学计量学方法。经二维相关扩展的谱图有两个:同步谱和异步谱。同步谱表征特定变量处动态谱强度同步和协同变化,同步谱中位于对角线位置的峰称为自动峰,表示特定变量处扰动期间光谱强度变化的总体程度,反映该处光谱强度随外界扰动变化的灵敏度。非对角线处的峰称之为交叉峰,同步交叉峰表示两频率间光谱强度变化的相似性。异步谱表征特定变量处动态谱强度变化差异性。应用二维相关方法提高光谱分辨率,进而分离复杂多组分样本的高度重叠近红外谱峰。通过相关分析,得到分子间及分子内部相互作用信息,进而解析近红外变量共线性机理。综合重叠峰分辨和共线性变量解析,为不同近红外光谱变量优选结果融合提供可能。
技术实现要素:
本发明的目的是提供一种基于二维相关分析的不同近红外光谱变量优选结果融合方法,以解决现有技术中当用多种算法优选近红外光谱变量时结果不一致/矛盾所带来的问题。
为实现上述目的,本发明提出一种基于二维相关分析的不同近红外光谱变量优选结果融合方法,包括步骤:
步骤1:测定样本近红外光谱数据与目标待测物浓度参考值;
步骤2:构建浓度扰动动态光谱,进行二维相关分析;
步骤3:基于二维相关分析,综合考虑邻近光谱变量共线性,识别高频优选敏感变量;
步骤4:基于二维相关分析,识别独立谱区低频优选敏感变量;
步骤5:得出全谱区域综合变量优选结果。
其中,所述步骤1中,获取样本近红外光谱x及目标待测物浓度参考值c,基于近红外光谱x及目标待测物浓度参考值c,利用m种变量优选方法优选光谱敏感变量,每种变量优选方法优选出的敏感光谱变量子集vm包含k个敏感变量γm1,γm2,...,γmk,叠加不同变量优选结果,构建总优选变量集v。
其中,所述步骤1中,所述目标待测物浓度参考值为要检测的物料待测目标的测量值。
其中,所述步骤2中,设定等间距目标待测浓度yes,构建目标待测物浓度分布区间内n个目标待测物浓度间距为yes的样本子集,其相应光谱子集为xj(γ)=x(γ,cj),j=1,2,...,n,γ表示光谱变量,cj表示所属光谱的目标待测物浓度,j表示样本/光谱编号。其中选定动态光谱子集的平均谱为参考谱
其中,所述步骤3中,定义共线性临近距离d和重复选择频次f,假设光谱变量间隔在共线性临近距离之内的变量高度相关,在总优选变量集v中,变量在[i-d,i+d]范围内的变量优选频次定义为变量γi的优选频次fi,优选频次fi≥f的变量及其距离d之内的变量为共线性临近变量组vg,每组内优选的唯一变量为高频优选敏感变量。
其中,所述步骤3中,优选步骤为:
①如共线性临近变量组vg中优选频次最高的变量唯一,则该变量定义为高频优选敏感变量;
②如共线性临近变量组vg中优选频次最高的变量不唯一,计算优选频次最高变量的均值,如距该均值最近的变量唯一,则该变量定义为高频优选敏感变量;以及
③如距该均值最近的变量不唯一,则优选频次最高变量处二维相关同步相关系数大的变量为高频优选敏感变量。
其中,所述步骤4中,基于二维相关同步自动峰切线谱独立峰,划分光谱子区间,剔除包含高频优选敏感变量的区间和与总优选变量集无交集的区间,余下每个区间中优选唯一变量为低频优选敏感变量。
其中,所述步骤4中,优选步骤为:计算区间内优选变量均值,如距该均值最近变量唯一,则该变量为低频优选敏感变量;如距该均值最近变量不唯一,选择优选变量处二维同步相关系数大的变量为低频优选敏感变量。
其中,所述步骤5中,结合高频优选敏感变量与低频优选敏感变量为全谱区域综合变量优选结果。
而且,为实现上述目的,本发明还提出了基于二维相关分析的不同近红外光谱变量优选结果融合方法在农产品品质快速检测中的应用。
本发明所提出的基于二维相关分析的不同近红外光谱变量优选结果融合方法,综合考虑了近红外光谱谱峰重叠特性和变量间共线性,避免了单一变量优选算法的局限性,在减少光谱冗余信息基础上强化关键敏感变量信息,解决多种优选变量算法下不同结果的融合问题。
附图说明
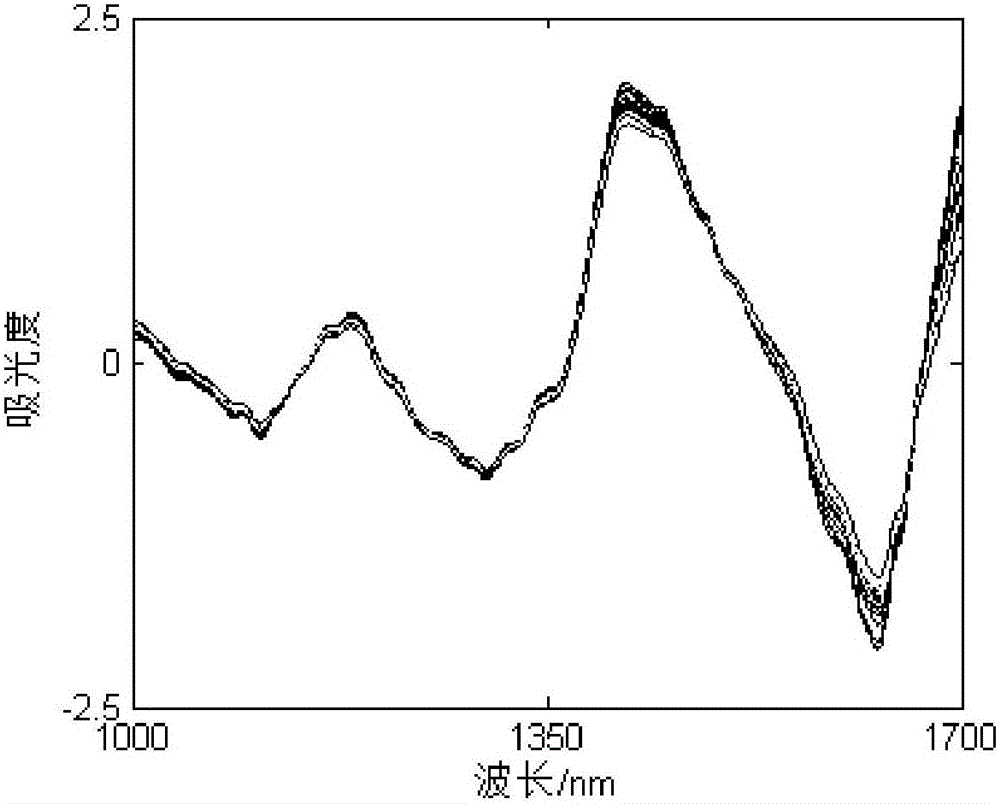
图1为小麦籽粒原始近红外光谱。
图2为小麦籽粒预处理的近红外光谱。
图3为两种方法优选小麦籽粒近红外光谱敏感变量结果。
图4为小麦籽粒近红外二维相关自动峰切线谱。
图5为共线性临近变量。
图6为高频优选敏感变量。
图7为子区间划分。
图8为无高频优选敏感变量区间中的待选变量图。
图9为低频优选敏感变量。
图10为全谱区域综合变量优选结果。
具体实施方式
本发明提出一种基于二维相关分析的不同近红外光谱变量优选结果融合方法,其方案为:
步骤1:测定样本近红外光谱数据与目标待测物浓度参考值
获取样本近红外光谱x及目标待测物浓度参考值c,基于近红外光谱x及目标待测物浓度参考值c,利用m种变量优选方法优选光谱敏感变量,每种变量优选方法优选出的敏感光谱变量子集vm包含k个敏感变量γm1,γm2,...,γmk,叠加不同变量优选结果,构建总优选变量集v。
其中,目标待测物浓度参考值指要检测的物料(如实施例中小麦籽粒)待测目标(如实施例中蛋白含量)的测量值(如实施例中42个成熟小麦籽粒样本的蛋白含量)。
步骤2:构建浓度扰动动态光谱,进行二维相关分析。
设定等间距目标待测浓度yes,构建目标待测物浓度分布区间内n个目标待测物浓度间距为yes的样本子集,其相应光谱子集为xj(γ)=x(γ,cj),j=1,2,...,n,γ表示光谱变量,cj表示所属光谱的目标待测物浓度,j表示样本/光谱编号。其中选定动态光谱子集的平均谱为参考谱
步骤3:基于二维相关分析,综合考虑邻近光谱变量共线性,识别高频优选敏感变量。
定义共线性临近距离d和重复选择频次f,假设光谱变量间隔在共线性临近距离之内的变量高度相关,在总优选变量集v中,变量在[i-d,i+d]范围内的变量优选频次定义为变量γi的优选频次fi,优选频次fi≥f的变量及其距离d之内的变量为共线性临近变量组vg,每组内优选的唯一变量为高频优选敏感变量。优选准则为:①如共线性临近变量组vg中优选频次最高的变量唯一,则该变量定义为高频优选敏感变量;②如共线性临近变量组vg中优选频次最高的变量不唯一,计算优选频次最高变量的均值,如距该均值最近的变量唯一,则该变量定义为高频优选敏感变量;③如距该均值最近的变量不唯一,则优选频次最高变量处二维相关同步相关系数大的变量为高频优选敏感变量。
步骤4:基于二维相关分析,识别独立谱区低频优选敏感变量
基于二维相关同步自动峰切线谱独立峰,划分光谱子区间,剔除包含高频优选敏感变量的区间和与总优选变量集无交集的区间,余下每个区间中优选唯一变量为低频优选敏感变量。优选步骤为:计算区间内优选变量均值,如距该均值最近变量唯一,则该变量为低频优选敏感变量;如距该均值最近变量不唯一,选择优选变量处二维同步相关系数大的变量为低频优选敏感变量。
步骤5:得出全谱区域综合变量优选结果
结合高频优选敏感变量与低频优选敏感变量为全谱区域综合变量优选结果。
本发明的基于二维相关分析的不同近红外光谱变量优选结果融合方法可应用于小麦籽粒等农产品的蛋白含量、水分含量等品质的快速光谱评价领域,针对不同的样本,待测目标,该方法中参数可进行相应的调整。
实施例:
一、测定样本近红外光谱数据与目标待测物浓度参考值;
选取42个成熟小麦籽粒样本,采集1000-1700nm范围内分辨率为1.6nm的近红外光谱(见图1),根据gb/t24899-2010测定其蛋白质含量在10.51~16.94%,均值为14.09%,标准偏差1.45%。光谱经9点平滑、变量标准化、归一化预处理(见图2)。选用两种变量优选算法:弹性网(elasticnet)和遗传算法(geneticalgorithm),分别优选22和23个敏感变量(见图3)。
二、构建浓度扰动动态光谱,进行二维相关分析
选择蛋白质含量为10.51、11.07、11.66、12.26、12.85、13.43、14.12、14.64、15.21、15.74、16.37、16.94%的12个样本光谱,进行二维相关计算并提取其自动峰切线谱(见图4)。
三、基于二维相关分析,综合考虑邻近光谱变量共线性,识别高频优选敏感变量
定义共线性临近距离d=8nm和重复选择频次f=2。合并弹性网和遗传算法优选变量结果,构建总优选变量集v。其中变量及其共线性临近距离范围γi-8~γi+8内,优选择频次≥f=2的变量有28个(见图5),依据共线性临近距离分组原则,分为10组。其中1273.4nm和1298.4nm变量均被弹性网和遗传算法选中,作为高频优选敏感变量;1026.6nm、1257.8nm、1364.1nm、1403.1nm和1476.6nm距组内均值近,为高频优选敏感变量;1010.9nm、1242.2nm和1326.6nm的二维相关自动峰同步相关系数高,优选为高频优选敏感变量。高频优选敏感变量结果如图6所示。
四、基于二维相关分析,识别独立谱区低频优选敏感变量
基于二维相关自动峰切线谱划分子区间(见图7),提取无高频优选敏感变量区间。无高频优选敏感变量区间存在14个变量(见图8)。其中1023.4nm、1126.6nm、1146.9nm、1187.5nm、1259.4nm、1354.7nm、1584.4nm和1693.8nm距组内均值近,优选为低频优选敏感变量;1167.2nm的二维相关同步相关系数高,优选为低频优选敏感变量。低频优选敏感变量结果如图9所示。
五、得出全谱区域综合变量优选结果
结合高频优选敏感变量与低频优选敏感变量结果,得出综合不同算法优选敏感变量结果(见图10)。
本发明的效果:
本发明所提出的基于二维相关分析的不同近红外光谱变量优选结果融合方法,综合考虑了近红外光谱谱峰重叠特性和变量间共线性,避免了单一变量优选算法的局限性,在减少冗余基础上增加关键敏感变量信息,解决多种优选变量算法下不同结果的融合问题。
当然,本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,熟悉本领域的技术人员可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!