检查数据处理装置以及检查数据处理方法与流程
本发明涉及检查数据处理装置以及检查数据处理方法,特别涉及用于根据从被检对象测量出的检查数据来辨别该被检对象是正常还是异常的检查数据处理方法以及检查数据处理装置。
背景技术:
在机械或者电器设备的产品检查中实施音响检查,以辨别正常产品与异常产品。音响检查要求高的辨别精度。
对于由机械或者电气设备产生的噪音,以往,主要通过人(检查者)的耳朵来检查噪音,从而辨别正常/异常。特别是,在根据是不是用检查者的耳朵感到不适的声音来辨别正常/异常的情况下,必须通过检查者的耳朵进行感官检查。
但是,在利用检查者的耳朵进行的辨别中,每个检查者的辨别基准存在偏差。另外,即使是同一个检查者,根据检查时的身体状况,辨别基准也发生变化。
因此,需要一种不依赖于测量条件以及检查者的自动辨别技术。这样的辨别技术主要在声音辨别领域中的辨别特定的音源或者语言的领域发展起来。
例如,在专利文献1(日本特开2000-172291号公报)中,制作通过麦克风收集到的声音数据的音响模型,依照音响模型来辨别声音的各单词。另外,在专利文献2(日本特开2002-189493号公报)中,通过使用学习到的按特征区分的图案(pattern)校正说话者声音的频谱,从而提高声音辨别性能。
另外,作为辨别正常与异常的方法提出有如下辨别方法:作为以正常产品的数据组为基准定量地辨别异常的方法,将作为图案辨别技术之一的马氏距离用作指标。例如,在专利文献3(日本特开2003-310564号公报)中,在代替医生来实施脑波的辨别的情况下,从脑波的时间序列数据提取多个特征量。然后,将马氏距离用作分离指标,该马氏距离是根据基准数据空间以及该提取出的作为辨别对象的特征量计算出的,该基准数据空间是使用基准学习数据计算出的。
在与音响相关的领域中,也提出有将马氏距离用作辨别指标的方法。例如,在专利文献4(日本特开2004-198383号公报)中,针对每个产生原因将碰撞声的组所具有的声音的特征量定义为基准空间,使用马氏距离评价各组辨别对象的分离度。由此,推测声音的产生原因。
在这里,通过逆矩阵计算算出上述基准空间。但是,在音响数据或者图像数据等中,由于数据彼此的相关系数大,所以产生多重共线性的问题,其结果是,难以实施通常的逆矩阵计算。为了应对这一情况,例如在专利文献5(日本特开2012-093423号公报)中,通过将特征量集合为平均值、敏感度、标准sn比来避免逆矩阵计算,根据这些特征量计算马氏距离,基于计算出的马氏距离来实施图案识别所涉及的辨别。
现有技术文献
专利文献1:日本特开2000-172291号公报
专利文献2:日本特开2002-189493号公报
专利文献3:日本特开2003-310564号公报
专利文献4:日本特开2004-198383号公报
专利文献5:日本特开2012-093423号公报
技术实现要素:
在上述专利文献3中,为了根据马氏距离辨别脑波的正常/异常,基于正常脑波数据生成用于辨别的基准数据空间。根据该方法,在以正常的数据组为基准时,数据的偏差比以异常的数据组为基准时小,能够提高正常/异常的分离度。然而,专利文献4并未提出用于使基于正常声波数据的基准空间数据更加均匀的方法,所以难以基于基准空间数据提高上述分离度。
本发明是为了解决上述课题而完成的,本发明的目的在于提供能够高精度地辨别检查对象是正常产品还是异常产品的检查数据处理装置以及检查数据处理方法。
本发明的检查数据处理装置重复实施预定数量的从包括表示正常产品的特征量的上述预定数量的数据的数据组随机提取多个数据并计算代表特征量的处理,根据包括表示通过重复实施该预定数量的处理而计算出的代表特征量的预定数量的数据的数据组生成基准空间,该代表特征量代表所提取出的多个数据所表示的特征量。然后,根据所生成的基准空间与表示检查对象的特征量的数据之间的距离的大小辨别检查对象是正常产品还是异常产品。
在一个方案中,如上所述,通过根据包括表示正常产品的代表特征量的预定数量的数据的数据组生成基准空间,由基准空间的数据表示均匀的特征量。由此,能够基于与该基准空间的距离来准确地辨别正常产品或者异常产品。
附图说明
图1是示出本发明的实施方式的检查数据处理装置50的硬件结构的图。
图2是示出本发明的实施方式的检查数据处理装置50的功能结构的图。
图3是示出图2的信息储存部10中储存的数据的一个例子的图。
图4是示出在检查对象的设备的测量中得到的时间序列数据的一个例子的图。
图5是示出从图4切出的1秒钟的时间序列数据的一个例子的图。
图6是示出根据图5的时间序列数据使用自回归模型推测出的时间序列数据的一个例子的图。
图7是示出对时间序列数据进行fft处理后的结果的图。
图8是示出针对时间序列数据使用自回归模型推测谱密度后的结果的图。
图9是示出实施方式3的用于对比的实验结果的图。
图10是示出实施方式4的层次构造的一个例子的图。
图11是示出实施方式4的实验结果的一个例子的图。
图12是示出本实施方式5的针对各特征量的sn比(signal-to-noiseratio,信噪比)的一个例子的图。
图13是实施方式7的整体处理的流程图。
(符号说明)
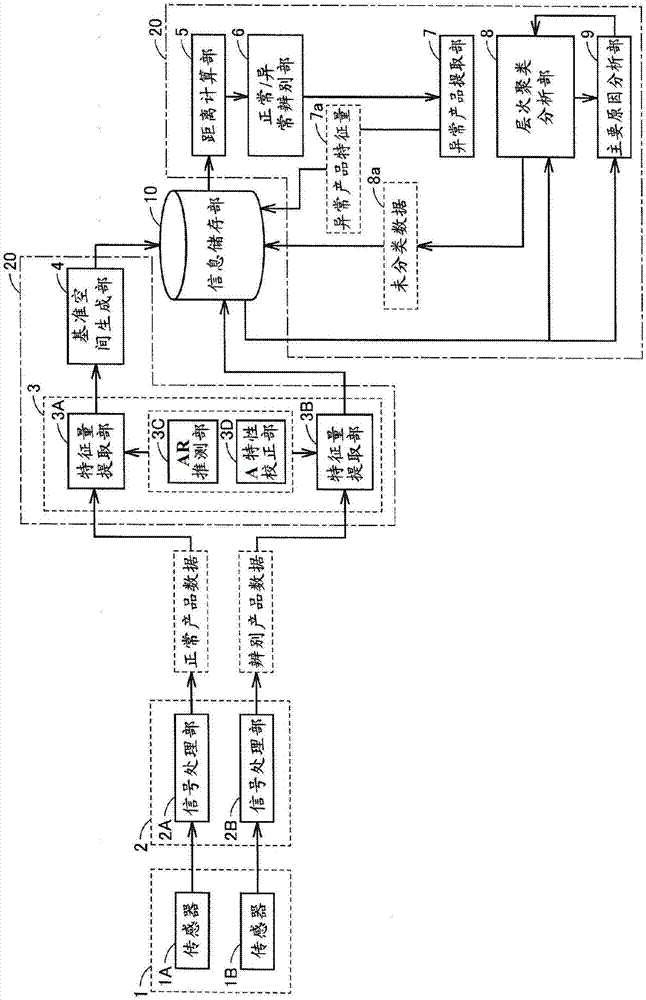
1:测量部;1a、1b:传感器;2、2a、2b:信号处理部;3、3a、3b:特征量提取部;3c:ar推测部;3d:a特性校正部;4:基准空间生成部;5:距离计算部;6:异常辨别部;7:异常产品提取部;8:层次聚类分析部;9:主要原因分析部;10:信息储存部;20:辨别处理部;50:检查数据处理装置。
具体实施方式
以下,参照附图,说明本发明的实施方式。此外,图中相同的符号表示相同或者相当的部分。
在本实施方式中,作为检查对象例示出机械或者电气设备等产品,但检查对象不限于此。另外,作为检查对象的产品相当于正常产品或者异常产品的辨别对象即辨别产品。在本实施方式中,使用时间序列数据来实施辨别,该事件序列数据是通过以预定时间间隔对来自检查对象的声音信号进行采样而生成的。时间序列数据被例示为表示声波波形的强度(level)(振幅等)的时间变化以及频率变化的数据,但不限于该数据,也可以是表示从检查对象产生的振动波形的强度的时间变化以及频率变化的数据。
另外,在本实施方式中,正常产品是指在利用人的听觉检查从产品产生的声音时能够判定为正常的产品。另外,异常产品是指在利用人的听觉检查从产品产生的声音时能够判定为异常的产品。具体而言,在产生的声音包括例如由机械部件的接触所引起的异常音、由旋转体的轴偏移引起的接触音的情况下,辨别为产品是异常产品即不合格产品。
(实施方式的概要)
本实施方式的检查数据处理装置重复实施预定数量(例如,1000个)的如下的处理:从包括表示正常产品的特征量的上述预定数量的数据的数据组随机提取多个数据,计算代表特征量,该代表特征量代表提取出的多个数据所表示的特征量。检查数据处理装置根据数据组生成基准空间,该数据组包括表示通过该预定数量的重复实施而计算出的代表特征量的预定数量的数据。然后,检查数据处理装置根据所生成的基准空间与表示检查对象的特征量的数据之间的马氏距离的大小,辨别检查对象是正常产品还是异常产品。
这样,通过由代表特征量组构成基准空间,能够使构成基准空间的特征量的偏差降低并均匀化。因此,能够基于离基准空间的马氏距离的大小来辨别正常/异常,该基准空间是特征量的偏差少的均匀的基准空间。由此,能够提高辨别精度。
[实施方式1]
(装置的结构)
图1是示出本发明的实施方式的检查数据处理装置50的硬件结构的图。检查数据处理装置50具有相当于计算机的结构。具体而言,检查数据处理装置50具备相当于信息处理部的cpu(centralprocessingunit,中央处理单元)51、包括rom(readonlymemory,只读存储器)以及ram(randomaccessmemory,随机存取存储器)等的主存储装置52、hdd(harddiskdrive,硬盘驱动器)等辅助存储装置53、键盘或者鼠标等输入装置54、显示器或者打印机等输出装置55、用于与外部设备(未图示)通信的通信装置56、存储器驱动器57以及外部i/f(接口(interface)的简记)部58。
外部i/f部58受理来自传感器1a、1b的信号的输入。传感器1a、1b测量来自作为检查对象的机械或者电气设备(未图示)的声音,将测量出的信号(声波信号)输出到外部i/f部58。作为存储介质的存储卡59以装卸自如的方式安装于存储器驱动器57。在cpu51的控制之下,存储器驱动器57将数据写入到所安装的存储卡59或者从存储卡59读出数据。
(功能结构)
图2是示出本发明的实施方式的检查数据处理装置50的功能结构的图。参照图2,检查数据处理装置50具备:测量部1,测量从检查对象的机械或者电气设备(未图示)产生的声音;信号处理部2,对来自测量部1的测量信号进行处理并输出时间序列数据;以及辨别处理部20和信息储存部10。辨别处理部20包括特征量提取部3、距离计算部5、正常/异常辨别部6、异常产品提取部7、层次聚类分析部8以及主要原因分析部9。这些各部的详情将在后面叙述。
信号处理部2以及辨别处理部20分别通过由cpu51执行的程序或者程序与电路的组合来实现。
信息储存部10相当于图2的辅助存储装置53或者存储卡59的存储区域。图3是示出图2的信息储存部10所储存的数据的一个例子的图。参照图3,信息储存部10包括区域e1~e8。区域e1储存辨别产品特征量组11,该辨别产品特征量组11包括后述的多个辨别产品数据的特征量。区域e2储存正常产品特征量组12,该正常产品特征量组12包括后述的多个正常产品数据的特征量。区域e3储存表示基准空间的基准空间数据13。
区域e4储存异常产品特征量组14,该异常产品特征量组14包括根据距离辨别出的异常产品数据的特征量。区域e5储存按模式区分的特征量组15,该按模式区分的特征量组15包括后述的每个异常模式的异常产品数据的特征量。区域e6储存用于识别每个异常模式的有效特征量的特征量识别数据16。区域e7储存未分类数据组17,该未分类数据组17包括未被分类为任何异常模式的未分类数据8a。区域e8储存异常主要原因数据18。各区域的数据的详情将在后面叙述。
返回到图2,测量部1包括:传感器1a,测量来自被预先分类为正常产品的机械或者电气设备的声音;以及传感器1b,测量来自作为检查对象的机械或者电气设备(即辨别产品)的声音。传感器1a和传感器1b包括例如加速度传感元件,具有相同的测量功能。
信号处理部2包括:信号处理部2a,对来自传感器1a的测量信号进行处理,输出基于处理结果的时间序列数据(以下称为正常产品数据);以及信号处理部2b,对来自传感器1b的测量信号进行处理,输出基于处理结果的时间序列数据(以下称为辨别产品数据)。信号处理部2a、信号处理部2b分别包括滤波器电路、模拟/数字(analog/digital)转换电路以及采样电路等,实施相同的信号处理。
特征量提取部3包括:特征量提取部3a,从来自信号处理部2a的表示正常产品的正常产品数据提取特征量;以及特征量提取部3b,从来自信号处理部2b的辨别产品数据提取特征量。特征量提取部3a和特征量提取部3b实施相同的特征提取处理。
另外,为了更适当地提取特征量,特征量提取部3包括ar(autoregressive,自回归)推测部3c以及a特性校正部3d。特征量提取部3a将从各正常产品数据提取出的特征量储存到区域e2,特征量提取部3b将从各辨别产品数据提取出的特征量储存到区域e1。
检查数据处理装置50还包括基准空间生成部4。基准空间生成部4根据储存于区域e2的正常产品特征量组12生成表示基准空间的基准空间数据13,并将基准空间数据13储存到区域e3。
距离计算部5计算辨别产品数据的特征量与基准空间数据13所表示的基准空间之间的距离(后述的马氏距离)。正常/异常辨别部6根据计算出的距离辨别该辨别产品数据的辨别产品是正常产品还是异常产品。异常产品提取部7将异常产品特征量7a储存到区域e4,该异常产品特征量7a表示由正常/异常辨别部6辨别了的辨别产品数据中的、被辨别为异常产品的辨别产品数据的特征量。
为了将储存于区域e4的异常产品特征量组14所包括的各异常产品特征量7a分类为多个异常模式,层次聚类分析部8实施层次聚类分析。主要原因分析部9针对每个异常模式分析异常的主要原因(原因)。层次聚类分析部8将异常产品特征量组14中的未被分类为任何异常模式的异常产品特征量作为未分类数据8a储存到区域e8。主要原因分析部9将主要原因的分析结果反馈给层次聚类分析部8或者输出。
此外,在图2中,针对正常产品与辨别产品独立地设置有传感器、信号处理部以及特征量提取部,但传感器、信号处理部以及特征量提取部也可以是正常产品与辨别产品共用的结构。
(马氏距离的计算)
在本实施方式中,检查数据处理装置50根据依照mts(马氏田口系统)法得到的马氏距离d(以下还简记为距离d)对辨别产品辨别正常/异常。mts法作为图案辨别的一种方法,由田口玄一博士提出的这一方法与其它图案辨别方法(例如神经网络等)相比,能够处理的特征量的数量多、能够实现高的辨别精度。
mts法包括mt(马氏田口)法、rt(recognitiontaguchi:识别田口)法等几个计算方法,本实施方式使用mt(马氏田口)法。距离d是使用广义逆矩阵a计算出的,该广义逆矩阵a基于根据构成基准空间的正常产品数据的特征量计算出的相关系数矩阵r。广义逆矩阵也被称为一般逆矩阵、穆尔-彭罗斯逆矩阵、伪逆矩阵,但在此统一称为“广义逆矩阵”。
<基准空间的生成>
基准空间是根据正常产品的声音的时间序列数据生成的,正常产品是通过人的听觉检查预先分类出的。
传感器1a通过加速度传感元件从正常产品测量来自正常产品的声音并输出声波信号。信号处理部2a对来自传感器1a的声波信号进行滤波处理,将滤波处理后的声波信号转换成作为数字数据的正常产品数据(表示波形的时间序列数据)。所得到的正常产品数据的数量例如为1000个,将该正常产品数据储存到区域e2。
在特征量提取部3a中,通过利用ar推测部3c实施的ar推测(后述)将来自信号处理部2a的正常产品数据转换成谱密度的数据。谱密度数据表示每个频率分量的谱密度。特征量提取部3a针对谱密度数据每10hz进行谱密度的平均化处理,从而计算出1000个谱密度数据(特征量)。由此,对1000个正常产品数据的各个正常产品数据提取1000个特征量。此外,在提取特征量时,也可以实施由后述的a特性校正部3d进行的处理。
基准空间生成部4将关于从特征量提取部3a输出的1000个正常产品数据的特征量储存到信息储存部10的区域e3。由此,将基准空间数据13储存到区域e3。
参照通过发明人的实验得到的图4~图8的时间序列数据说明由上述测量部1实施的测量信号的处理以及特征量的计算。
在这里,由于传感器1a、传感器1b实施相同的测量动作,所以以测量部1的动作来说明这些动作。另外,由于信号处理部2a、信号处理部2b实施相同的处理,所以以信号处理部2的处理来说明这些处理。另外,特征量提取部3a、特征量提取部3b也实施相同的处理,所以以特征量提取部3的处理来说明这些处理。
图4是示出在检查对象设备的测量中得到的时间序列数据的一个例子的图。图4示出连续5秒钟的以100khz的采样速度测量出的时间序列数据。
特征量提取部3将图4的时间序列数据中的1秒钟的数据作为连续部分切出。也就是说,从5秒钟的时间序列数据得到包括5个时间序列数据的数据集。图5是示出从图4切出的1秒钟的时间序列数据的一个例子的图。
为了从上述时间序列数据提取特征量,特征量提取部3执行用于利用ar推测部3c实施频谱推测的计算处理。自回归模型(ar模型)是与用于根据过去的序列值预测未来的值的时间序列预测相关的方法。具体而言,ar推测部3c通过以下步骤计算预测波形(时间序列数据)。
在假设使用偏离平均值的偏移xi、自回归系数aj、阶m以及噪声ξi而以(式1-1)表示的情况下,通过推测模型参数(m、aj、σ2,而对离散的时间序列数据进行模型化。另外,通过使用自解析模型的参数,解析地得到(式1-2)。
[式1]
ar推测部3c推测参数ai、σ以及平均值m,根据自回归模型推测时间序列数据。图6是示出使用自回归模型从图5的时间序列数据推测出的时间序列数据的一个例子的图。
在从表示声音、振动等波形的时间序列数据提取特征量的情况下,通常通过傅里叶变换进行提取,傅里叶变换假设离散数据为无限连续的信号的1个周期。但是,在fft(fastfouriertransform,快速傅里叶变换)处理中,由于时间波形的偏移而产生大量的噪声分量,有效的特征量可能被噪声分量掩盖。
因此,在本实施方式的特征量提取部3中,对时间序列数据应用自回归模型来推测谱密度。在正常/异常的辨别时使用通过推测得到的针对频率分量的特征量(谱密度)的数据集。在该情况下,与通过fft处理获得频谱的情况相比,时间序列数据的曲线图形状更加平滑(参照图6),能够不被噪声分量掩盖而得到有效的特征量。
进一步地说明上述效果。图7是示出对时间序列数据进行fft处理得到的结果的图。图7横轴表示频率,纵轴表示电压信号的强度(单位:v2)。图8是示出对时间序列数据使用自回归模型推测谱密度而得到的结果的图。图8的横轴与图7同样地表示频率,纵轴表示通过电压示出的谱密度(单位:v/hz)。
在本实施方式中,通过使用自回归模型计算谱密度,从而能够使图6的时间序列数据与图5的原来的时间序列数据充分一致。因此,在比较图7的数据与图8的时间序列数据的情况下,可知在图8的时间序列数据中排除了每个频率的细微的时间变化,其中,图7的数据是针对时间序列数据简单地对频谱强度进行fft处理而得到的数据,图8的数据表示针对相同的时间序列数据通过自回归模型推测出的谱密度。
发明人们得到如下的见解:在如上所示地使用自回归模型推测谱密度得到的时间序列数据(参照图8)的情况下,与通过fft处理取得的时间序列数据(参照图7)相比,不被噪声分量掩盖而能够提取有效的特征量。
<广义逆矩阵a的计算>
cpu51从基准空间数据13导出用于计算距离d的广义逆矩阵a。具体而言,首先,cpu51根据信息储存部10的基准空间数据13计算以下的(式2)所示的相关系数矩阵r。
[式2]
如(式3)所示,相关系数矩阵r的要素rij是表示正常产品数据的特征量的数据(以下称为单位数据)的第i个项目与第j个项目的相关系数。也就是说,是表示单位数据所包括的1000个特征量(谱密度)中的第i个特征量与第j个特征量的相关性的系数。
[式3]
在i=j时,rij=1
rij=rji
接下来,为了计算奇异值矩阵λ、特征向量矩阵w以及矩阵v,首先,计算相关系数矩阵r的特征值(characteristicvalue)。具体而言,cpu51通过以下的(式4)计算特征值λ,按计算值从大到小的顺序排列为λ1、λ2、λ3、…λk≥0。根据该排列,通过(式5)计算奇异值矩阵λ。
[式4]
[式5]
接下来,cpu51计算针对λ1的特征向量((式6)的λ1不是取平方根的奇异值)。也就是说,根据(式6)计算(式7)的向量。
[式6]
[式7]
另外,cpu51对λi(i=1~k)与上面叙述的λ1同样地计算特征向量。cpu51根据计算出的这些特征向量计算(式8)所示的特征向量矩阵w。
[式8]
然后,cpu51根据下面的(式9)计算矩阵v。
[式9]
cpu51根据(式10)计算广义逆矩阵a,(式10)使用了计算出的特征向量矩阵w、奇异值矩阵λ以及矩阵v。将计算出的广义逆矩阵a储存到信息储存部10。
[式10]
<距离d的计算>
说明本实施方式的距离d的计算方法。cpu51使用广义逆矩阵a计算各单位数据的距离d。例如,依照(式11)计算单位数据的样品no.1的距离d。另外,关于信号数据、未知数据也同样依照(式12)和(式13)计算距离d(a与求单位数据的距离d时所使用的矩阵是共同的)。
[式11]
[式12]
[式13]
在对构成基准空间数据13的全部的正常产品数据(单位数据)分别计算出距离d时,cpu51根据它们的平均值,依照预定运算来计算用于辨别正常/异常的阈值(以下,辨别阈值)。将计算出的辨别阈值储存到信息储存部10的预定区域。
如上所述,根据正常产品数据的特征量(单位数据)的集合即基准空间数据13生成广义逆矩阵,使用所生成的广义逆矩阵计算各单位数据的距离d,根据计算出的距离d计算辨别阈值。
(正常/异常的辨别处理)
接下来,说明正常/异常的辨别处理。根据发明人们的实验得到如下见解:在正常/异常辨别部6利用使用上述(式13)计算出的距离d来实施辨别处理的情况下,能够降低将正常产品误辨别为异常产品的概率。
实验时,例如在信息储存部10的区域e4中关于异常产品对由上述测量部1以及信号处理部2取得的时间序列数据(例如1000个时间序列数据)储存有异常产品特征量组14。特征量提取部3对区域e2的正常产品特征量组12应用自回归模型(ar模型)来提取特征量,对区域e4的异常产品特征量组14同样地应用自回归模型来提取特征量。距离计算部5对正常产品特征量组12的各正常产品数据使用提取出的特征量,根据上述(式13)计算距离d,对异常产品特征量组14的各异常产品数据同样地使用提取出的特征量,根据上述(式13)计算距离d。
正常/异常辨别部6对关于正常产品数据以及异常产品数据计算出的距离d与上述辨别阈值进行比较,根据比较结果,在(距离d≥辨别阈值)的关系成立的情况下辨别为是“异常产品”,在(距离d<辨别阈值)的关系成立的情况下辨别为是“正常产品”。在该情况下,能够将把正常产品误辨别为异常产品的概率(也就是说“错检率(overlookingratio)”)做到约10%。
(实施方式1的效果)
根据实施方式1,通过在辨别中使用距基准空间的距离d,能够提高正常产品与异常产品的分离度,该基准空间是利用正常产品特征量组12生成的基准空间数据13所示出的基准空间。具体而言,从正常产品测量出的声音波形具有偏差小且特征也类似的性质,与此相对,从异常产品测量的声音波形具有偏差大的性质。也就是说,正常产品的特征量具有较均匀的分布,而异常产品的特征量的分布存在大的倾向性。
因此,通过将根据正常产品特征量组12生成的基准空间数据13用作辨别基准,能够高精度地辨别正常产品与异常产品,该正常产品特征量组包括比异常产品数据的特征量组更加均匀的特征量。
另外,为了计算距离d而实施使用广义逆矩阵a的逆矩阵计算。在使用声音等时间序列数据时有时产生多重共线性的问题,从而难以进行逆矩阵计算,但在广义逆矩阵的情况下,即使在未正则的情况下也能够计算逆矩阵。因此,通过应用广义逆矩阵a,不管有没有多重共线性都能够计算距离d。
另外,马氏距离d通过使用广义逆矩阵来计算,能够得到高的辨别精度。也就是说,在如专利文献4(日本特开2004-198383号公报)所述地将特征量集合为平均值、敏感度、标准sn比来计算马氏距离的情况下,难以提取对辨别有效的特征而使用,从而无法得到高的辨别精度。相反,在实施方式1中,应用广义逆矩阵计算出的距离d由于不集合特征量而能够包括与大量的特征量相关的信息,所以能够得到高的辨别精度。
[实施方式2]
实施方式2示出实施方式1的变形例。在实施方式2中,基准空间生成部4在生成基准空间数据13时使单位数据的分布均匀化。
具体而言,基准空间生成部4为了使基准空间数据13中的单位数据的分布均匀化而实施包括以下的步骤sa和步骤sb的平均化处理。
(步骤sa):基准空间生成部4从基准空间数据13的1000个单位数据随机提取400个单位数据,对提取出的单位数据的特征量进行平均化处理,将表示平均化处理得到的特征量的数据定义为新的单位数据。
(步骤sb):基准空间生成部4使在上述步骤sa中提取出的400个单位数据返回到原来的基准空间数据13。之后,基准空间生成部4实施上述步骤sa。
基准空间生成部4重复实施1000次上述步骤sa和步骤sb的处理,生成包括计算(定义)出的1000个单位数据的新的基准空间数据13,并储存到区域e3。由此,将区域e3的基准空间数据13的单位数据改写成表示均匀的特征量的单位数据。此外,在上述步骤sa中对400个单位数据所表示的特征量计算了平均值,但计算值不限于此。也就是说,所计算的值是关于400个单位数据的特征量的代表值即可,也可以计算例如400个单位数据表示的特征量的中值、众数等。
发明人们在实验中,在使用实施上述平均化处理得到的基准空间数据13的情况下实施了由正常/异常辨别部6进行的辨别处理,在使用未实施平均化处理得到的基准空间数据13的情况下也实施了由正常/异常辨别部6进行的辨别处理。其结果,得到如下见解:实施平均化处理的情况与未实施平均化处理的情况相比,正常产品与异常产品的辨别精度提高。也就是说,在未实施平均化处理的实施方式1中错检率约10%,与此相对,根据实施平均化处理的实施方式2,能够使该错检率降低到1%。
另外,发明人们通过实验得到如下见解:在步骤sa中从基准空间数据13提取的单位数据的数量与错检率具有相关性。也就是说,在从基准空间数据13提取出40%~50%的数量的单位数据的情况下,能够使错检率最低。另外,发明人们还得到不管构成基准空间数据13的单位数据的数量如何都能够得到该效果的见解。
(实施方式2的效果)
这样,在实施方式2中,通过使用包括均匀分布的单位数据的基准空间数据13能够使“错检率”降低即提高辨别精度,“错检率”表示将正常产品误辨别为异常产品的概率。
[实施方式3]
实施方式3示出实施方式1或者2的变形例。在实施方式3中,为了使辨别精度接近人的敏感度的精度,特征量提取部3对上述时间序列数据进行基于频率的加权。
具体而言,实施方式3基于以下背景进行:人的听觉在频带中不具有同样的敏感度。另一方面,在特征量提取部3对全部频率区域以相等的权重从时间序列数据提取特征量的情况下,得到与人的听觉不同的辨别结果,成为辨别精度降低的主要原因。因此,在实施方式3中,为了接近人的敏感度的辨别精度,特征量提取部3对时间序列数据进行基于频率的加权处理。
特征量提取部3的a特性校正部3d是“加权部”的一个实施例,对时间序列数据实施基于a特性的校正处理。在基于a特性的校正处理中考虑人类听觉而对频率进行加权。也就是说,该校正处理相当于鉴于如下特性的滤波处理,该特性为:人类的听觉在低频侧在1000hz以下的频带中敏感度降低,在20hz以下不具有敏感度(听不到),并且在高频侧也是频率越高则敏感度越降低,在20khz时不具有敏感度。在该滤波处理中应用a特性校正部3d所具有的a特性滤波器。
a特性滤波器具有不影响1000hz附近的分量而使低频以及高频的分量(振幅等)衰减的特性。a特性滤波器通过以下的(式14)表示。最好以人的耳朵敏感的频率区域中的异常声音作为对象来实施加权处理。因此,在(式14)中,将在人的听觉中示出高的敏感度的频率f1~f4用作参数。
[式14]
在发明人们的实验中,特征量提取部3对时间序列数据实施在实施方式2中说明的由ar推测部3c进行的基于自回归模型的谱密度计算,进而实施由a特性校正部3d进行的加权处理。由此,提取出表示所得到的谱密度数据的特征量。然后,基准空间生成部4基于实施方式2的处理生成包括均匀的单位数据的基准空间数据13。正常/异常辨别部6根据如上所述地被均匀化了的基准空间数据13实施辨别处理。通过这样的实验,能够将错检率做到0.1%以下。
(其它实验例)
发明人们进行了使用本实施方式3所示的、示出错检率为0.1%以下的基准空间数据13的其它实验。在该实验中,特征量提取部3将通过人的听觉检查预先判明为异常的异常产品的150个时间序列数据以及正常产品的200个时间序列数据作为对象,从各时间序列数据提取出特征量。正常/异常辨别部6利用使用提取出的特征量计算出的距离d实施了辨别处理。在该实验中,正常/异常辨别部6能够完全无误地辨别正常产品与异常产品。
另外,发明人们为了进行对比还实施了其它实验。图9是示出实施方式3的用于对比的实验结果的图。在实验中,在上述异常产品的150个时间序列数据中,表示3种异常主要原因的异常模式ma、mb、mc各包括30个通过人的听觉检查而判明异常的主要原因、且其特征明确的样品。关于3种异常模式的各异常模式构成基准空间数据。对各异常模式的基准空间数据,关于未实施a特性校正的各异常产品数据计算距离d,并将计算出的距离d作为辨别阈值的指标。发明人们针对每个异常模式,对各异常产品数据进行了基于该距离d和辨别阈值的辨别。在图9中,关于异常模式ma、mb以及mc的各异常模式,以对比的方式示出通过该实验得到的正解个数(16个、18个、17个)以及通过人的听音检查得到的正解个数(30个、30个、30个)。如图9所示,可知在不实施a特性校正的情况下,正解率降低为50~60%。
(实施方式3的效果)
这样,在实施方式3中,通过在对人的耳朵敏感的频率区域的特征量(谱密度)进行加权之后实施特征量提取,能够降低将正常产品误辨别为异常产品的“错检率”。因此,辨别精度提高。
[实施方式4]
(层次聚类)
在本实施方式4中,层次聚类分析部8是“异常模式分类部”的一个实施例。层次聚类分析部8实施层次聚类分析,该层次聚类分析用于将被实施了实施方式3的ar推测或者a特性校正的辨别产品数据中的、被辨别为异常产品的各辨别产品数据分类为多种异常模式(相当于集群)。以下说明层次聚类分析。
首先,层次聚类分析部8对信息储存部10的区域e4的异常产品特征量组14的各异常产品数据的特征量实施层次聚类分析。
在这里,如上所述,因为异常产品特征量组14的各异常产品数据的特征量相当于来自异常产品提取部7的异常产品特征量7a,所以使用异常产品特征量7a说明层次聚类分析。分析包括以下的处理步骤(1)~(4)。
步骤(1):层次聚类分析部8将异常产品特征量组14的各个异常产品特征量7a定量化为特征向量。定量化而得到的特征向量作为要素(相当于后述的项目i、j)具有上述的对10hz的量的谱密度进行平均化处理而计算出的1000个特征量。
步骤(2):层次聚类分析部8根据“非类似度”计算距离矩阵,该“非类似度”是异常产品特征量7a彼此的非类似性的尺度。
步骤(3):层次聚类分析部8选择聚类算法(后述)。
步骤(4):层次聚类分析部8依照选择出的聚类算法重复进行处理,直至将全部异常产品特征量7a整合为一个集群为止。
在这里,在执行层次聚类分析之前,层次聚类分析部8使用上述“非类似度”制作将特征向量的项目i与项目j之间的距离dij作为要素的距离矩阵,该“非类似度”为表示异常产品数据彼此的不相似程度的量。虽然提出有多个表示“非类似度”的式子,但在本实施方式中,“非类似度”使用相关系数rij通过以下的(式15)定义。
[式15]
dij=1-rij…(式15)
另外,还能够应用将向量xi与向量xj之间的“非类似度”设为cosθ、通过以下的(式16)定义的方法,但在这里,“非类似度”是使用相关系数rij通过(式15)计算的。
[式16]
在上述步骤(3)中,作为聚类算法,能够应用最近距离法、最远距离法、组平均法、重心法、中值法、离差平方和(ward)法等算法。以下,说明各算法的概要。
最近距离法是如下方法:分别从2个集群的各个集群中各选择1个个体并计算所选择出的2个个体之间的距离,将在计算出的各距离中最近的个体间的距离确定为该2个集群之间的距离。
最远距离法是如下方法:分别从2个集群的各个集群中各选择1个个体并计算所选择出的2个个体之间的距离,将在计算出的各距离中最远的个体间的距离确定为该2个集群之间的距离。
组平均法是如下方法:将最近距离法与最远距离法折衷的方法。具体而言,组平均法是指从2个集群的各个集群中各选择1个个体,并计算所选择出的2个个体之间的距离,将计算出的各距离的平均值确定为该2个集群之间的距离。
重心法是如下方法:计算集群各自的重心(例如,平均向量)并将计算出的重心之间的距离确定为集群之间的距离。
中值法是对重心法变形得到的方法。具体而言,虽然计算2个集群的重心之间的加权的距离,但将使权重相等而计算出的距离的值确定为2个集群之间的距离。
ward法是如下方法:在融合2个集群时,依照用于使各集群的组内的方差与集群彼此之间的组间的方差之比最大化的基准形成集群。ward法是能够得到最高的分离度的方法,也被称为最小方差法。
<数据的整合和异常模式的分类>
接下来,参照图10,使用层次构造来说明上述步骤(4)中的、将异常产品特征量组14的全部异常产品特征量7a整合为1个的过程,并且说明在该层次构造中将异常产品特征量7a分类为各异常模式的过程。图10是示出实施方式4的层次构造的一个例子的图。在这里,设想为异常产品特征量组14具有9个异常产品数据d1~d9的异常产品特征量。
作为使用上述特征量的距离尺度,应用使用特征量彼此的相关系数rij的“非类似度”,使用相关系数rij依照上述(式15)定义非类似度dij。另外,在步骤(3)中,选择上述的组平均法来作为聚类算法。
在组平均法中,根据作为对象的异常产品数据的特征量的相关系数计算“非类似度”,将该计算值的平均值作为异常产品数据彼此的距离。
层次聚类分析部8对异常产品特征量组14的9个异常产品数据d1~d9,用分支连接距离近的异常产品数据彼此。由此,制作图10所示的系统树图(树形图)。在图10的系统树图中示出对9个异常产品数据d1~d9进行聚类分析得到的结果。图10的系统树图的纵轴表示聚类间的距离的值(0.2、0.4、…1.0),图10的从下向上将异常产品数据d1~d9结合起来。
在这里,集群数量(即异常模式的数量)根据操作者的指示来确定。具体而言,当操作者经由输入装置54将集群数量输入到检查数据处理装置50时,为了计算阈值(图),层次聚类分析部8根据所输入的集群数量执行预先确定的运算。层次聚类分析部8通过将上述阈值应用到所生成的系统树图,从而在系统树图上将全部异常产品数据分类为所指示的数量的集群(异常模式)。
在图10中,将异常产品数据d1~d6分类为异常模式ma的集群,将异常产品数据d7和d8分类为异常模式mb的集群,并且将异常产品数据d9分类为异常模式mc的集群。这样,将异常产品特征量组14的全部异常产品数据整合为1个系统树图,并且分类为各异常模式。
图11是示出实施方式4的实验结果的一个例子的图。在图11中,示出每个异常模式的相对于人的听音检查的正解的比例(正解率)。在实验中,将异常产品特征量组14的异常产品数据的150个异常产品数据的特征量分割成异常模式ma、异常模式mb、异常模式mc以及其它模式这共计4种集群。
通过图11的表示出通过人的听音检查得到的向各异常模式的分类结果,并示出其正解率是约70~80%。另外,发明人们根据实验得到如下见解:通过层次聚类分析部8进行的基于正常产品的基准空间的异常模式的分类处理与使用异常产品的基准空间的异常模式的分类处理相比,提高了分类的精度。
(实施方式4的效果)
根据实施方式4,在使用包括正常产品数据的基准空间数据13来辨别正常/异常的情况下,也实施ar推测以及a特性校正,从而异常产品特征量7a中能够包括不被噪声掩盖而被进行了基于人的听觉敏感度的加权的状态的特征量。因此,通过层次聚类分析,能够将异常产品特征量7a适当地分类为每个异常模式。
[实施方式5]
在实施方式5中,检查数据处理装置50对实施方式4的通过层次聚类分析部8分类了的各异常模式分析异常的主要原因。
(异常主要原因的分析处理)
主要原因分析部9依照使用包括正常产品数据的基准空间的mts(马氏田口系统)法对由层次聚类分析部8分类为异常模式的异常产品数据分析主要原因。
图12是示出本实施方式5的各特征量的sn比(signal-to-noiseratio,信噪比)的一个例子的图。在图12中,对横轴分配特征量编号n1、n2、…、n999、n1000,这些特征量编号被分配给作为上述特征向量的要素的1000个特征量(对应于频率分量的谱密度),对纵轴分配sn比。在作为特征向量的要素的1000个特征量中包括sn比大的特征量(以下称为特定特征量)。这样,sn比大的特定特征量在使用正常产品的基准空间来辨别异常产品时以使马氏距离d变大的方式发挥作用,所以作为正常/异常的辨别时使用的指标是有效的。
预先通过实验等对1000个特征量分析并确定sn比变大的物理性原因,从而能够对各异常模式推测异常主要原因。例如,通过实验等取得对应于特征量编号的特征量的异常主要原因。然后,生成将各特征量编号与对应的异常主要原因关联起来登记的异常主要原因数据18,并预先储存到信息储存部10的区域e8。因此,能够根据sn比大的特定特征量的编号从异常主要原因数据18读出对应的异常主要原因。
另外,通过选择性地使用这些特定特征量,能够降低马氏距离的计算负荷,高速并且得到高的辨别精度。以下说明确定每个异常模式所特有的特征量的处理。
主要原因分析部9是“异常主要原因确定部”的一个实施例。主要原因分析部9对各异常模式使用被分类为该异常模式的异常产品特征量7a,实施上述逆矩阵计算,对各异常产品特征量7a计算马氏距离(步骤t1)。
主要原因分析部9对每个异常模式计算标准差σ,该标准差σ表示异常产品数据组的马氏距离d的偏差程度。具体而言,主要原因分析部9对各异常模式,分别计算仅使用特定特征量以及使用全部特征量这两种情况下的马氏距离d的偏差程度的标准差σ(步骤t2)。
当在步骤t2中判断为仅使用特定特征量时的马氏距离的标准差σ小于使用全部特征量时的距离d的标准差σ的情况下,主要原因分析部9将该特定特征量确定为使该异常模式的异常产品数据组的分布减小(更加均匀化)的有效的特征量(以下还称为有效特征量)。
主要原因分析部9根据所确定的有效特征量的编号,从信息储存部10的区域e9读出对应的异常主要原因数据。将所读出的异常主要原因数据经由输出装置55输出。由此,能够通知被辨别为异常的检查对象产品的异常主要原因。
(实施方式5的效果)
这样,主要原因分析部9无需学习异常产品的数据库,就能够对各异常模式确定用于确定异常主要原因的有效特征量。也就是说,随着判定产品数据的增加,作为层次聚类分析对象的异常产品数据增加,其结果是,异常模式数量增加。经过这样的过程而学习到异常产品的数据库。另外,通过使用特定特征量构成各异常模式的基准空间,就各异常模式的基准空间来说,能够生成包括更加均匀化的特征量的基准空间。因此,容易使用马氏距离来辨别辨别产品数据符合哪种异常模式。
[实施方式6]
在本实施方式6中,检查数据处理装置50使用实施方式5中的主要原因分析结果(对每个异常模式确定的有效特征量)来生成基准空间数据13。
<使用主要原因分析结果的基准空间的生成>
主要原因分析部9将识别上述有效特征量的特征量编号作为特征量识别数据16储存到信息储存部10的区域e6。基准空间生成部4将表示单位数据的特征向量的1000个特征量中的由特征量识别数据16表示的第i个项目与第j个项目的相关系数用作用于计算广义逆矩阵的相关系数矩阵r的要素rij(参照上述(式3))。另外,根据单位数据生成基准空间数据13,该单位数据是由以特征量识别数据16示出的有效特征量表示的单位数据。
(实施方式6的效果)
根据实施方式6,能够使利用第1距离d得到的正常产品/异常产品的辨别精度比利用第2距离d得到的辨别精度提高,其中上述第1距离d是根据仅使用有效特征量生成的基准空间计算出的距离,上述第2距离d是与使用全部特征量生成的基准空间的距离。
另外,在根据仅使用有效特征量生成的基准空间通过层次聚类分析部8分类为各异常模式时,与使用异常产品所具有的全部特征量来辨别正常/异常的情况相比,也能够提高分类精度。
[实施方式7]
在实施方式7中,说明通过程序来实施上述各实施方式所示的一系列的处理的情况。图13是实施方式7的整体处理的流程图。该流程图所示的处理作为程序而预先储存于存储部(主存储装置52、辅助存储装置53以及存储卡59等)。cpu51通过从存储部读出程序并执行所读出的程序来实现处理。
参照图13的流程图,说明预先生成基准空间数据13的处理(步骤s1)。具体而言,基准空间生成部4经由信号处理部2a以及特征量提取部3a输入表示由传感器1a检测到的从正常产品产生的声音的特征量数据,并将特征量数据储存到信息储存部10的区域e2。此时,在特征量提取部3a中实施利用ar推测部3c进行的ar推测处理以及利用a特性校正部3d进行的a特性校正处理(步骤s1a、s1b)。由此,将各正常产品的特征量数据(单位数据)储存到区域e2。
基准空间生成部4根据正常产品特征量组12生成平均化处理了的基准空间数据13,将所生成的基准空间数据13储存到区域e3(步骤s1c)。
由此,在信息储存部10的区域e3储存包括均匀的单位数据的基准空间数据13,基准空间数据13的生成结束。
接下来,说明基于基准空间数据13所表示的基准空间进行的正常/异常的辨别处理。
首先,生成包括多个辨别产品数据的辨别产品特征量组11(步骤s2)。具体而言,通过传感器1b测量来自辨别产品的声音。通过信号处理部2b以及特征量提取部3b对由传感器1b得到的测量信号进行处理(步骤s3)。此时,在特征量提取部3b中,实施利用ar推测部3c以及a特性校正部3d进行的处理(步骤s4、s5)。
由此,将从辨别产品数据提取出的特征量数据作为辨别产品特征量储存到信息储存部10的区域e1。通过对多个辨别产品实施步骤s2~s5的处理,从而将辨别产品特征量组11储存到区域e1。
对辨别产品特征量组11的各辨别产品特征量实施正常/异常的辨别(步骤s7)。具体而言,距离计算部5对从辨别产品特征量组11读出的辨别产品特征量计算马氏距离d。正常/异常辨别部6对计算出的距离d与判定阈值进行比较,根据比较结果进行辨别。另外,根据该辨别结果,将辨别产品数据中的被辨别为异常产品的异常产品特征量作为异常产品特征量7a储存到信息储存部10的区域e4。通过对辨别产品特征量组11的各辨别产品特征量实施步骤s5和s6的处理,从而将异常产品特征量组14储存到区域e4。
层次聚类分析部8通过上述步骤(1)~(4)的层次聚类分析,对区域e4的异常产品特征量组14进行分类(步骤s9)。层次聚类分析部8将按异常模式区分的异常产品特征量作为按模式区分的特征量组15储存到信息储存部10的区域e5。另外,将未被分类为任何异常模式的异常产品特征量作为未分类数据8a储存到信息储存部10的区域e8。
在cpu51判断为未分类数据组17的未分类数据8a达到预定个数时,主要原因分析部9通过主要原因分析确定每个异常模式的有效特征量,并将其特征量编号作为特征量识别数据16储存到区域e6(步骤s11)。另外,将根据各异常模式的有效特征量从信息储存部10的区域e8的异常主要原因数据18读出的原因数据经由输出装置55输出。
将该原因分析的结果反馈给层次聚类分析部8(步骤s13)。具体而言,对由区域e6的特征量识别数据16表示的有效特征量进行加权,实施上述层次聚类分析。由此,关于异常模式的分类,仅对敏感度高的特征量(有效特征量)进行加权。因此,在层次聚类分析中,能够得到异常模式的分类的高分类精度。
另外,cpu51将主要原因分析结果反映到基准空间(步骤s15)。具体而言,cpu51将单位数据的1000个特征量中的、由特征量识别数据16表示的第i个项目与第j个项目的相关系数用作用于计算广义逆矩阵的相关系数矩阵r的要素rij(参照上述(式3)),即用作单位数据的第i个项目与第j个项目的相关系数。另外,将区域e3的基准空间数据13变更为新的基准空间数据13。基准空间数据13包括表示通过特征量识别数据16识别的有效特征量的单位数据。
之后,cpu51判断是否结束处理(步骤s16)。例如,cpu51根据从输入装置54输入的操作者的指示判断是否结束该处理。cpu51在判断为不结束处理的情况下(步骤s16中“否”),使控制返回到步骤s2。cpu51在判断为结束处理的情况下,(步骤s16中“是”),结束一系列的辨别处理。
[实施方式8]
将用于实现各实施方式中说明的检查数据处理装置50的处理的程序储存在存储部(主存储装置52、辅助存储装置53以及存储卡59)中。cpu51通过从存储部读出该程序并执行所读出的程序,从而与其它电路部协作而实现处理。
上述各实施方式的处理还以上述程序来提供。将这样的程序记录到附属于图1的检查数据处理装置50的计算机的存储卡59等计算机可读的记录介质中来提供。或者,还能够记录到内置于计算机的主存储装置52、辅助存储装置53以及存储卡59等记录介质来提供程序。另外,还能够通过经由未图示的通信网络以及通信装置56下载到检查数据处理装置50的存储部来提供程序。
将所提供的程序例如安装于辅助存储装置53的硬盘等程序储存部,由cpu51读出并执行所安装的程序。此外,程序产品包括程序本身以及非临时性地存储程序的存储介质。
应该认为本次公开的实施方式在所有方面都是示例性的,而并非限制性的。本发明的范围不通过上述说明表示,而是通过权利要求书来表示,意图包括与权利要求书等同的含意以及范围内的全部变更。
- 还没有人留言评论。精彩留言会获得点赞!