基于室内声学信道扰动分析的物体识别方法与流程
本发明涉及声学技术领域,具体为一种基于室内声学信道扰动分析的物体识别方法。该方法利用极少的硬件设备,通过室内声学信道扰动分析对不同物体进行识别,可应用于智能家居、室内安保等对识别要求较高又存在较多障碍物的场景中。
背景技术:
物体识别(objectrecognition)是一项含义及应用都非常广泛的技术,它既包括了对人们日常生活中不同物体的分类识别,也包括军事领域中针对各种航行器的目标识别,甚至更广泛的人物识别也属于一种广义的物体识别,因此其在很多学科领域中都得到了持续的研究。
室内环境是人们在生活中接触最多的物体识别应用场景。在此类环境中,一个准确而快速的物体识别方法可为很多先进技术研究及工业应用的展开提供关键基础,例如,涉及公共安全保障的室内不明物体识别、智能家居个性化应用中对不同人物的识别、各种功能机器人对工作任务及行进路线上的物体识别等。
目前,室内环境中的物体识别研究绝大多数集中于计算机视觉领域,即通过各种图像处理算法对不同物体的特征进行归纳及提取,并由此分辨出不同类型的物体。经过多年的高速发展,图像类的物体识别技术已经非常成熟,结合流行的机器学习算法,几乎可以实现对任意物体的准确识别,因此也在很多场合获得了应用。但是,基于计算机视觉处理的物体识别技术也存在一个明显的短板,就是必须依靠图像的捕捉。当应用场景为室内环境时,会存在有较多障碍物的情况,当摄像设备无法直接获取物体的图像时,物体识别就无法完成;而且,在很多场合中,由于隐私、安全、造价等各种因素的制约,甚至不存在摄像设备,此时物体识别也就无从谈起。
鉴于计算机视觉物体识别技术所存在的问题,非可视类物体识别技术逐渐发展起来,以无线通信技术为基础的方法相继被提出,其中近年来出现的基于wifi信号的物体识别方法就是一种具有代表性的技术。由于现代生活中wifi的使用趋向普及,而且wifi信号具有穿透障碍物的能力,因此wifi信号具有明显的载体优势。目前,国外已成功利用wifi技术实现对多种物体模式的识别,国内也已有研究机构利用wifi实现了对家庭中不同人物的识别。但是,基于wifi信号的物体识别也在技术及应用层面存在明显问题。首先,从技术层面来说,基于wifi的物体识别分析手段较为单一,均普遍利用信道状态信息(channelstation0information,csi)的时域波形差异性实现识别。因此,为了得到丰富的波形变化信息,通常要求被识别物体具有一定的运动特征,例如人物识别实际上是通过步态特征实现的,这样,就会导致对于完全静止物体或运动特征不规律物体的识别精度较差。另外,从应用层面,由于日常生活中wifi信号源过多,常常会造成接收干扰导致噪声过大,从而影响识别精度,而且wifi信号的安全性也是实际应用中需要慎重考虑的因素。
声学技术是实现非可视物体识别的一个重要手段。首先,声波具有明显的衍射、干涉等波动性质,因此在传播过程中可越过障碍物,实现传统图像识别方法所无法完成的非可视功能,这也避免了夜间光线较弱所带来的问题,可真正实现全天候工作;而且,声波频率成分丰富,可使声波波长具有较大的跨度,从而适用于各种尺寸的物体识别;另外,与其他设备相比,声学设备通常造价更低,无论是大型空间中的规模铺设或者是小型空间中的定点测量都具有更高的经济优势。综合以上因素,本发明提出以声学技术为手段实现室内环境中的物体识别。
在室内环境中,声波发出之后,会经过一定的传播过程到达接收点,由于边界条件复杂,声波的传播路径也会非常复杂,这为实现精确的物体识别提供了基础:声波在室内环境中由固定的声源向接收点传播过程中会有一定的传播模式,从而形成特定形式的声场,当室内环境中存在物体时,便会导致声波传播路径发生改变,对声场产生扰动作用,由于物体形状、尺寸、吸声、散射性质各不相同,对声场产生的扰动也会存在差异,对差异进行分析即可实现对室内环境中物体的识别。此研究通过声学技术可实现对室内环境中物体的非可视识别,从而拓宽应用场景,并为物体识别技术提供新思路,具有重要的理论意义及工程应用价值。
技术实现要素:
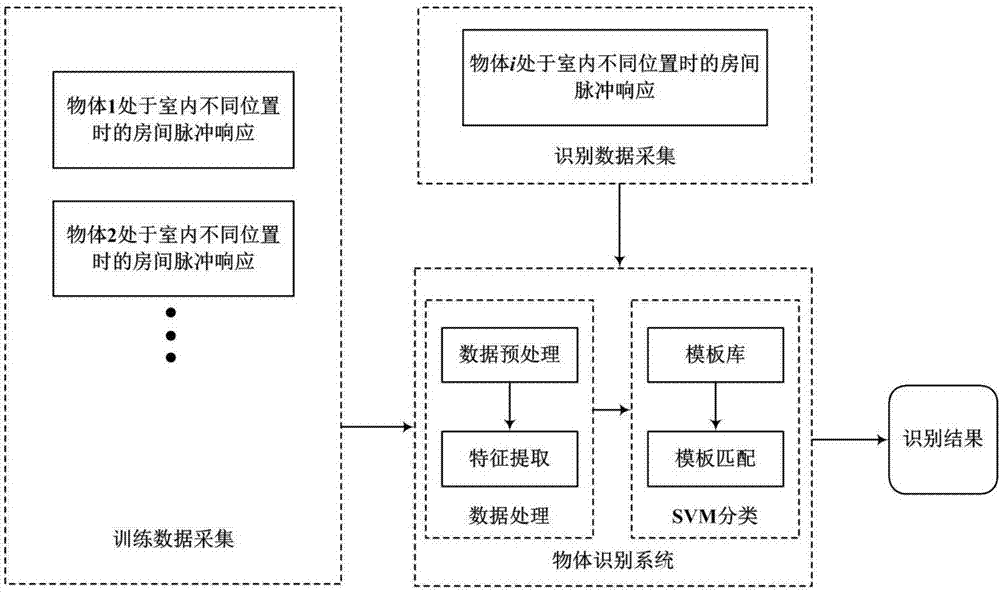
为了避免现有技术的不足之处,本发明提出一种以声学信道分析为技术手段的室内物体识别方法。在封闭空间中,声学信道具有多途传播性的特点,基于此,当空间内部存在物体时,会使原始的声学信道受到扰动发生变化,而由于物体的尺寸、形状等特点均不相同,所以对声学信道的影响也不同,根据此特点即可实现对不同物体的识别。本发明所提出的识别方法需分两阶段完成,第一个阶段为样本库的建立,第二个阶段为实际识别阶段。首先,在室内应用环境场景中,选取未来要进行识别的不同类别的物体,对这些物体处于室内不同位置时的声学信道分别进行测量,对测量信号进行特征的提取,归纳出不同物体所具有的特征,结果作为样本特征库;在实际识别过程中,对存在某一物体时的声学信道再次进行测量,将测量结果按照前述的特征提取方法进行特征的提取,并与样本库中的数据进行协同处理,即可最终识别此时室内的物体。
本发明的技术方案为:
所述一种基于室内声学信道扰动分析的物体识别方法,其特征在于:包括以下步骤:
步骤1:建立特征样本库:
步骤1.1:选取样本:当后续识别过程中的物体能够确定时,则直接选取确定的物体作为样本;当后续识别过程中的物体不能够确定时,则根据应用场景环境,预测后续识别过程中所涉及的物体种类,并选取与预测物体具有相同尺寸、形状特征的物体作为样本;
步骤1.2:在应用场景环境内设置一个声源s及一个麦克风m,在初始的应用场景环境内,声源s的位置ps与麦克风m的位置pm之间没有障碍物影响声源s到麦克风m的声信道;
步骤1.3:在应用场景环境内均匀布置若干个物体放置点l1,l2,…,ln,其中n为放置点的数量;
步骤1.4:选择一个样本物体o1,放置在应用场景环境的某个物体放置点上,声源发出一段声信号s(t),麦克风接收到声信号r(t),得到此过程中房间声学脉冲响应h(t)为:
其中fft表示对时域信号进行傅里叶变换,ifft表示对频域信号进行反傅里叶变换;
步骤1.5:将样本物体o1放置在应用场景环境的其他物体放置点上,重复步骤4,得到样本物体o1在所有物体放置点上对应的房间声学脉冲响应;
步骤1.6:选择其他样本物体,重复步骤4和步骤5,最终得到k个样本物体在n个放置点上的房间脉冲响应hij(t),其中i=1,2,…,k,j=1,2,…,n;
步骤1.7:对所有房间脉冲响应hij(t)进行特征提取建立特征样本库;
步骤2:利用步骤1建立的特征样本库,采用机器学习算法进行识别学习;
步骤3:根据步骤2的学习结果,对应用场景环境内的物体进行识别:
步骤3.1:在应用场景环境内设置声源及麦克风,声源及麦克风的位置与步骤1.2中设置的声源及麦克风的位置对应一致;
步骤3.2:获取房间声学脉冲响应,并对获取的房间声学脉冲响应提取与步骤1.7中相同类型的特征;
步骤3.3:利用步骤2的学习结果,对步骤3.2得到的特征进行识别,完成对应用场景环境内物体的识别。
进一步的优选方案,所述一种基于室内声学信道扰动分析的物体识别方法,其特征在于:步骤1.7中提取的特征为梅尔频率倒谱系数。
进一步的优选方案,所述一种基于室内声学信道扰动分析的物体识别方法,其特征在于:步骤2中采用的机器学习算法为支持向量机算法。
有益效果
本发明以声学手段为基础实现室内物体的识别。该方法较目前广泛使用的视频识别及wifi识别具有非可视识别、利用极少的硬件设备等优点。本发明充分利用了房间通道的声学信息,计算简便,定位效率较高。在封闭,半封闭,以及环境变化不大的空间中,可以取得很好的识别效果。通过室内声学信道扰动分析对不同物体进行识别,可应用于智能家居、室内安保等对识别要求较高又存在较多障碍物的场景中。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1:某封闭空间中声场划分及传声器分布示意图
图2:本发明物体识别方法的流程图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
本发明在实现识别的过程中总体上分两个阶段,特征样本库建立阶段及识别阶段,下面详细介绍技术方案的步骤。
步骤1:建立特征样本库:
步骤1.1:选取样本;
此处样本的选取应注意两点:第一,当后续识别过程中的物体能够确定时,则直接选取确定的物体作为样本,例如智能家居中对家庭人员的识别,样本库的采集即应以所有家庭成员为基础完成;第二,当后续识别过程中的物体不能够确定时,则根据应用场景环境,预测后续识别过程中所涉及的物体种类,并选取与预测物体具有相同尺寸、形状特征的物体作为样本;例如当应用场景为室内障碍物识别时,可对一定数量的具有不同大小、形状的室内常见静态物体,如桌椅、箱子等作为样本进行声信道采集。
步骤1.2:在应用场景环境内设置一个声源s及一个麦克风m,声源起到发出声信号的作用,麦克风起到接收声信号的作用,通过二者可得到代表声信道的参数——房间声学脉冲响应。在初始的应用场景环境内,声源s的位置ps与麦克风m的位置pm之间没有障碍物影响声源s到麦克风m的声信道,通常设置在室内较高的地方,以避免障碍物带来的影响。在测量和识别过程中,声源及麦克风的位置应始终保持不变。
步骤1.3:在应用场景环境内均匀布置若干个物体放置点l1,l2,…,ln,其中n为放置点的数量,以便测量物体处于这些位置时的不同声信道。
步骤1.4:选择一个样本物体o1,放置在应用场景环境的某个物体放置点上,声源发出一段声信号s(t),麦克风接收到声信号r(t),根据室内声学理论,声源所发出的声信号经过多途传播之后,到达麦克风,此过程中声信号传播的信道即为房间声学脉冲响应h(t):
其中fft表示对时域信号进行傅里叶变换,ifft表示对频域信号进行反傅里叶变换。
步骤1.5:将样本物体o1放置在应用场景环境的其他物体放置点上,重复步骤4,得到样本物体o1在所有物体放置点上对应的房间声学脉冲响应。
步骤1.6:选择其他样本物体,重复步骤4和步骤5,最终得到k个样本物体在n个放置点上的房间脉冲响应hij(t),其中i=1,2,…,k,j=1,2,…,n。
步骤1.7:对所有房间脉冲响应hij(t)进行特征提取建立特征样本库,本实施例中采用梅尔频率倒谱系数(melfrequencycepstralcoefficients,mfcc)作为声学信道的特征。mfcc是语音识别领域常用且具有优良效果的一种特征,mfcc特征的获得可采用现有的开源工具包完成。
步骤2:利用步骤1建立的特征样本库,采用机器学习算法进行识别学习;本实施例中采用支持向量机算法(supportvectormachine,svm)完成识别。首先对特征样本库进行学习,然后用于对后续识别过程中得到的特征进行识别,以最终完成物体的识别。svm算法可利用开源工具包获得。
步骤3:根据步骤2的学习结果,对应用场景环境内的物体进行识别:
步骤3.1:在应用场景环境内设置声源及麦克风,声源及麦克风的位置与步骤1.2中设置的声源及麦克风的位置对应一致;
步骤3.2:获取房间声学脉冲响应,并对获取的房间声学脉冲响应提取与步骤1.7中相同类型的特征;
步骤3.3:利用步骤2的学习结果,对步骤3.2得到的特征进行识别,完成对应用场景环境内物体的识别。
本实施例中,物体识别的应用场景为智能家居中的人物识别,假设家庭共有四位成员,要求任意成员在待识别空间中的任意位置均能保持较高的识别率。
步骤1:建立特征样本库:
步骤1.1:选取样本;
此实施例中的室内环境为一真实家庭的客厅环境,需要识别的人物为4位家庭成员,分别记为o1,o2,o3,o4,室内环境的平面图如附图1所示。
步骤1.2:在室内环境内设置一个麦克风及声源。麦克风及声源的位置可任意选择,但为了减少障碍物对麦克风及声源的遮挡,此实施例中将麦克风及声源置于屋顶。声源为家用普通音箱,麦克风为家用普通麦克风。
步骤1.3:在室内环境中设置14个放置点以测量脉冲响应,放置点近似均匀分布在空间范围内,用l1,l2,…,l14表示。
步骤1.4:选择一个样本o1,放置在应用场景环境的某个物体放置点上,声源发出一段声信号s(t),麦克风接收到声信号r(t),根据室内声学理论,声源所发出的声信号经过多途传播之后,到达麦克风,此过程中声信号传播的信道即为房间声学脉冲响应h(t):
其中fft表示对时域信号进行傅里叶变换,ifft表示对频域信号进行反傅里叶变换。
步骤1.5:将样本o1放置在应用场景环境的其他放置点上,重复步骤4,得到样本o1在所有放置点上对应的房间声学脉冲响应。
步骤1.6:选择其他样本,重复步骤4和步骤5,最终得到4个样本在14个放置点上的房间脉冲响应hij(t),其中i=1,2,…,4,j=1,2,…,14。
步骤1.7:对所有房间脉冲响应hij(t)进行特征提取建立特征样本库,本实施例中采用梅尔频率倒谱系数(melfrequencycepstralcoefficients,mfcc)作为声学信道的特征。mfcc是语音识别领域常用且具有优良效果的一种特征,mfcc特征的获得可采用现有的开源工具包完成,本实施例中利用matlab编程的开源程序对数据进行整理。在对数据进行梅尔频率倒谱系数特征提取的过程中,需要输入的参数包括采样频率,通常采样频率与麦克风及电脑采集声卡相关,此例中采样频率为22050hz。
步骤2:利用步骤1建立的特征样本库,采用机器学习算法进行识别学习;本实施例中采用支持向量机算法(supportvectormachine,svm)完成识别。首先对特征样本库进行学习,然后用于对后续识别过程中得到的特征进行识别,以最终完成物体的识别。svm算法可利用开源工具包获得。
步骤3:根据步骤2的学习结果,对应用场景环境内的物体进行识别:
步骤3.1:在应用场景环境内设置声源及麦克风,声源及麦克风的位置与步骤1.2中设置的声源及麦克风的位置对应一致;
步骤3.2:获取房间声学脉冲响应,并对获取的房间声学脉冲响应提取与步骤1.7中相同类型的特征;
步骤3.3:利用步骤2的学习结果,对步骤3.2得到的特征进行识别,完成对应用场景环境内物体的识别。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在不脱离本发明的原理和宗旨的情况下在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!