一种基于ELM‑LRF的自适应视觉导航方法与流程
本发明提供一种基于elm-lrf(基于局部接收野的极限学习机)的自适应视觉导航方法,具体而言就是输入像素数据、输出决策(选择行走动作),直到找到想要的物体,停下。属于机器学习、神经网络算法、强化学习技术领域。
背景技术:
视觉导航是在机器人上安装单目或双目照相机,获取环境中局部图像,实现自我位姿确定和路径识别,从而做出导航决策,与人类视觉反馈导航很类似。从输入图像到输出动作,机器学习是核心。随着计算机计算性能的不断提高和越来越多数据的产生,挖掘数据的价值为人们生活服务成为必然。在此趋势下,“大数据”和“人工智能”成为火热的名词,而机器学习又是其中的核心技术。机器学习主要包括监督学习、无监督学习和强化学习。
监督学习最火热的当属深度学习,深度学习简单说就是多层的神经网络,给定数据和相应标签,给定一个优化目标,采用bp(误差反向传播errorbackpropagation)训练算法来训练神经网络。深度学习算法中最著名是卷积神经网络(cnn),cnn受启发于人类的视觉皮层,输入至隐藏层采用局部连接。
极限学习机(elm),可用于特征学习,聚类,回归和分类。传统观点认为神经网络的隐藏层神经元需要在训练阶段迭代调整,比如bp算法,涉及大量的梯度下降,容易陷入局部最优。elm理论打破了这种信条,认为隐层神经元虽然很重要,但不需要迭代调整,解决了传统方法的缺陷[1.g.-b.huang,q.-y.zhu,andc.-k.siew.extremelearningmachine:anewlearningschemeoffeedforwardneuralnetworks,inproc.int.jointconf.neuralnetworks,july2004,vol.2,pp.985–990.][2.g.-b.huang,q.-y.zhu,andc.-k.siew,.extremelearningmachine:theoryandapplications,neurocomputing,vol.70,pp.489–501,dec.2006.]。隐藏层节点的所有参数(权重w和偏置b)都独立于训练样例,可以随机的(任意连续概率分布)生成,这样的elm依然具有普适的逼近和分类能力。elm理论表明,只要隐层神经元的激活函数是非线性分段连续的,神经网络就不需要通过迭代调整网络来获得学习能力。
elm-lrf[3.g.-bhuang,zbai,llckasun,cmvong.localreceptivefieldsbasedextremelearningmachine.[j].ieeecomputationalintelligencemagazine,2015,10(2):18-29]是基于局部感受野的极限学习机,输入与隐藏层间的连接是稀疏的,且由相应的局部感受野(对连续概率分布采样得到)包围。elm理论证明,隐藏层节点可以按照任意概率分布生成,这里的随机是指:输入与隐藏层节点间的连接密度是根据不同类型的概率分布随机采样得到的,输入与隐藏层节点间的连接权重也是随机生成的。
强化学习是一种重要的机器学习方法,在智能控制、机器人及分析预测等领域有许多应用。在人工智能领域,一般用智能体来表示一个具备行为能力的物体,比如机器人,无人车,人等等。那么强化学习考虑的问题就是智能体和环境之间交互的任务。比如一个机械臂要拿起一个手机,那么机械臂周围的物体包括手机就是环境,机械臂通过外部的比如摄像头来观察环境,然后机械臂需要输出动作来实现拿起手机这个任务。再举玩游戏的例子,比如玩赛车游戏,人们只看到屏幕,这就是环境,然后通过操作键盘来控制车的运动。不管是什么样的任务,都包含了一系列的动作,观察还有反馈值。所谓的反馈值就是智能体执行了动作与环境进行交互后,环境会发生变化,变化的好与坏就用反馈值来表示。如上面的例子,如果机械臂离手机变近了,那么回报值就应该是正的,如果玩赛车游戏赛车越来越偏离跑道,那么回报值就是负的。用了观察一词而不是环境那是因为智能体不一定能得到环境的所有信息,比如机械臂上的摄像头就只能得到某个特定角度的画面。因此,只能用观察来表示智能体获取的感知信息。人与环境的交互就是一个典型的强化学习过程。
深度强化学习(deepreinforcementlearning)将深度学习和强化学习结合,这个想法在几年前就有人尝试,但真正成功的开端就是deepmind在nips2013上发表的[4.volodymyrmnih,koraykavukcuoglu,davidsilver,alexgraves,ioannisantonoglou,daanwierstra,martinriedmiller.playingatariwithdeepreinforcementlearning[a].nips,2013.]一文,在该文中第一次提出深度强化学习这个名称,并且提出dqn(deepq-network)算法,实现从纯图像输入完全通过学习来玩atari游戏的成果。之后deepmind在nature上发表了改进版的dqn文章[5.volodymyrmnih,koraykavukcuoglu,davidsilver,andreia.rusu,joelveness,marcg.bellemare,alexgraves,martinriedmiller,andreask.fidjeland,georgostrovski,stigpetersen,charlesbeattie,amirsadik,ioannisantonoglou,helenking,dharshankumaran,daanwierstra,shanelegg&demishassabis,human-levelcontrolthroughdeepreinforcementlearning.[j]nature.2015.518:529-541.],引起了广泛的关注,深度强化学习从此成为深度学习领域的前沿研究方向。2016年9月,lifeifei组的最新文章[6.yukezhu,roozbehmottaghi,erickolve,josephj.lim,abhinavgupta,lifei-fei,andalifarhadi.target-drivenvisualnavigationinindoorscenesusingdeepreinforcementlearning.corr,abs/1609.05143,2016.]使用深度增强学习实现目标驱动的视觉导航。这篇文章中,作者构建了一个虚拟仿真环境,并且通过在高度仿真的环境中训练,然后迁移到真实场景中。这种方法被证明是有效的。深度强化学习可以用来做视觉导航,但有个缺陷就是训练速度非常慢。
技术实现要素:
本发明技术解决问题:克服现有技术的不足,提供一种基于elm-lrf的自适应视觉导航方法,大大提高了导航速度。
本发明技术解决方案:一种基于elm-lrf的自适应视觉导航方法,。该方法分配(st,at,rt,st+1,qt)结构体数据存储空间;令机器人在选定环境中重复运动,获得所需结构体数据,将状态相同的数据通过删除q值较小的数据进行预处理。然后以st作为输入,at作为输出完成对elm-lrf的训练,建立起当前状态和最优动作的映射关系。最后以机器人能否找到目标来测试机器人的导航能力。本发明在该数据空间下利用elf-lrf模型提出的方法大大提高了机器人的导航速度。其中,st是当前状态,在这里为拍摄到的照片,at是在st下机器人的动作(前后左右运动),rt是at的即时回报,st+1是机器人在at后的状态,q为长远回报,qt值为在状态st下执行at后得到的总的长远回报
具体包含如下:
(1)分配存储(st,at,rt,st+1,qt)的空间;(st,at,rt,st+1,qt)是结构体存储,st是当前状态,在这里为拍摄到的照片,at是在st下的动作,rt是at的即时回报,st+1是at后的状态,qt值为在状态st下执行at后得到的总的长远回报;
(2)机器人在环境中运动,得到一组从初始位置到发现目标物的(st,at,rt,st+1,qt)数据;
(3)机器人重置到初始位置,当在某状态st′下得到的qt′比之前同状态st得到的qt大时,删除在st状态下得到的(st,at,rt,st+1,qw)数据,否则删除在st′下得到的(st′,at′,rt′,st+1′,qt′);重复多次,从而得到较好的当前状态和最优动作的数据,即得到为训练所提供的更好的样本数据;
(4)在步骤(3)的基础上,完成对基于局部接收野的极限学习机神经网络的训练,即elm-lrf的训练,建立起当前状态和最优动作的映射关系;
(5)根据步骤(4)的建立起当前状态和最优动作的映射关系,测试机器人导航能力,观察机器人是否能找到目标。
所述步骤(4)的具体实现过程如下:
(4.1)计算隐层输出矩阵h
给定的训练集(xi,ti),=1…l,xi为步骤(3)得到的st,ti为步骤(3)得到的at,
其中,g(ai,bi,x)是一个非线性分段连续函数,实际上是将d维的输入空间映射到l维的隐层随机空间,是一个随机特征映射;ai,bi是第i个隐藏节点的参数,非线性分段连续函数的参数,非线性分段连续函数有很多种,比如sin(ax+b),r代表实数;
(4.2)根据步骤(4.1)中的h,求隐藏层至输出的权重β
elm-lrf的输出函数
通过求解
其中σ1>0,σ2>0,p,q>0,c用于控制两项的重要性,t是训练样例的目标矩阵:
当σ1=σ2=p=q=2时,常用的闭式解为:
p,q是范数下标,n是矩阵t的行数,l是矩阵β的行数。
本发明与现有技术相比的优点在于:为了探索输入图像数据输出动作的端到端学习,其中在当前状态和最优动作建立联系时选择了elm-lrf,而不是cnn。与dqn采用的cnn架构不同的是,cnn采用bp训练,这使得dqn面临bp中的琐碎问题,如:局部最优,慢的收敛速度。而elm-lrf随机生成输入权重并解析地计算输出权重,也就是计算主要是输出权重的计算,从而elm-lrf更为高效。
因此,传统方法需要设计特征提取器,而借助elm-lrf神经网络能实现输入图像到输出动作的映射,并且相比于其他类型神经网络,比如卷积神经网络,elm-lrf训练速度快,所需计算资源也少,本发明通过仿真试验测试大大提高了导航速度,从而很好的提高导航能力。
附图说明
图1为本发明方法的elm-lrf神经网络架构;
图2为本发明方法的实现流程图。
具体实施方式
下面结合附图和实施例,对本发明的技术方案做进一步的说明。
如图1所示,elm-lrf神经网络架构如图1所示,elm-lrf分为elm特征学习和elm特征映射两个阶段,首先随机分配输入向量,局部接收野中的像素是随机选取,输入到隐藏层的权重也是随机给出,接下来进行下采样,最后输出。
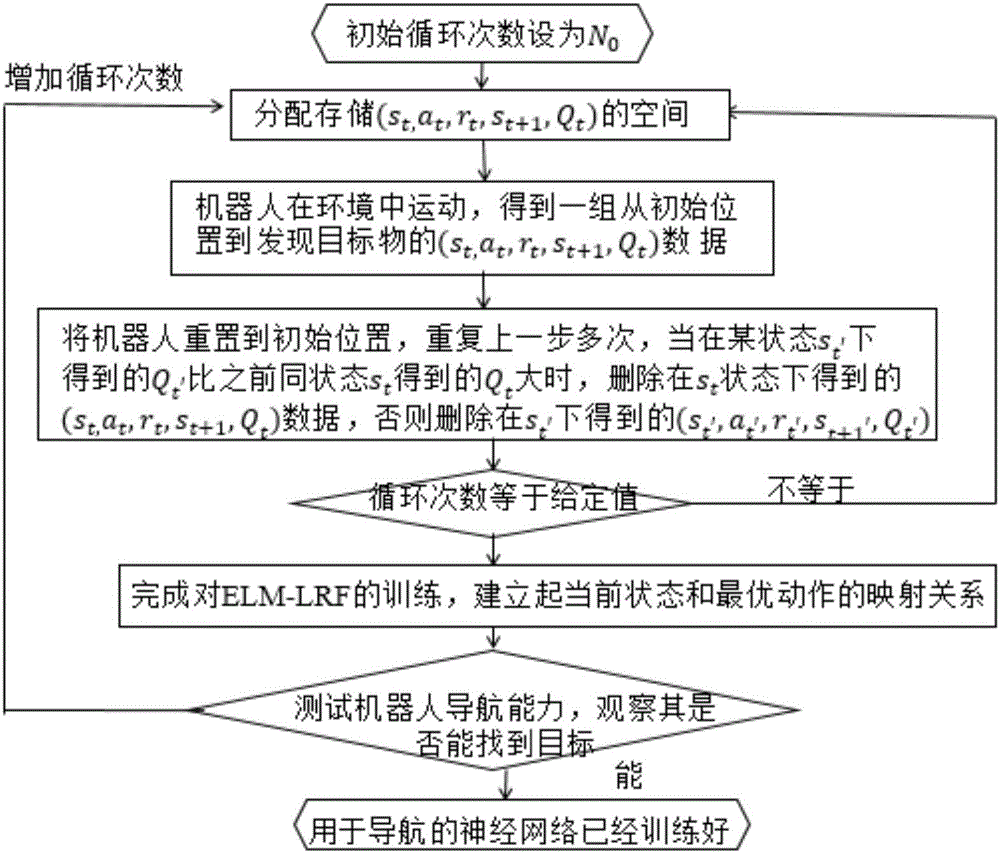
如图2所示,本发明一种基于elm-lrf的自适应视觉导航方法,具体实施例的流程如下:
步骤一:分配能存储(st,at,rt,st+1,qt)结构体的空间。qt初始化为0,根据当前所处状态st,随机选取运动at(机器人可以向前后左右四个方向运动),机器人在运动at下向相应方向走0.5m,得到新状态st+1与即时回报rt。找到目标物回报为1,其他为0。存储(st,at,rt,st+1,qt),状态图像信息按64×64灰白图存储。
步骤二:重复步骤一,机器人在环境中不断运动,直到机器人找到目标物停止,这时将得到一组从初始位置到发现目标物的(st,at,rt,st+1,qt)数据。每组最后的at的即时回报rt是1,qt值也为1,其他状态下通过式(1)更新qt的值。
qt(st,at)=rt+γmaxq(st+1,at+1)(1)
其中,rt是st即时回报,记找到目标物为1,未找到为0。st+1,at+1为下一个状态与动作,0<γ<1为折扣因子,影响决策时的远视程度。当前的动作会影响后续动作。
步骤三:机器人重置到初始位置,回到步骤一继续循环,当在某状态st′下得到的qt′比之前同状态st得到的qt大时,删除在st状态下得到的(st,at,rt,st+1,qt)数据,否则删除在st′下得到的(st′,at′,rt',st+1′,qt′),循环n0次来获得大量样本数据。
步骤四:将系统所处状态st做输入,对应qt的动作at做输出构造样本,at四个方向1,2,3,4用[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]取代。计算隐层输出矩阵h,根据式(2):计算输出权重β,完成对elm-lrf的训练,建立起当前状态和最优动作的映射关系。
步骤五:将机器人放到新的出发点,测试其导航能力,观察其是否能找到目标。找不到目标可以增加训练次数,增加步骤三中的n0,获得更多样本数据,接着重新训练elm-lrf神经网络。训练之后继续测试,直到测试结果显示能发现目标,则表示用于导航的elm-lrf神经网络训练好了。
- 还没有人留言评论。精彩留言会获得点赞!