一种脉冲压缩雷达回波信号的优化处理方法与流程
本发明属于数字信号处理
技术领域:
,特别涉及一种脉冲压缩雷达回波信号的优化处理方法,适用于目标跟踪、遥感、道路交通等领域。
背景技术:
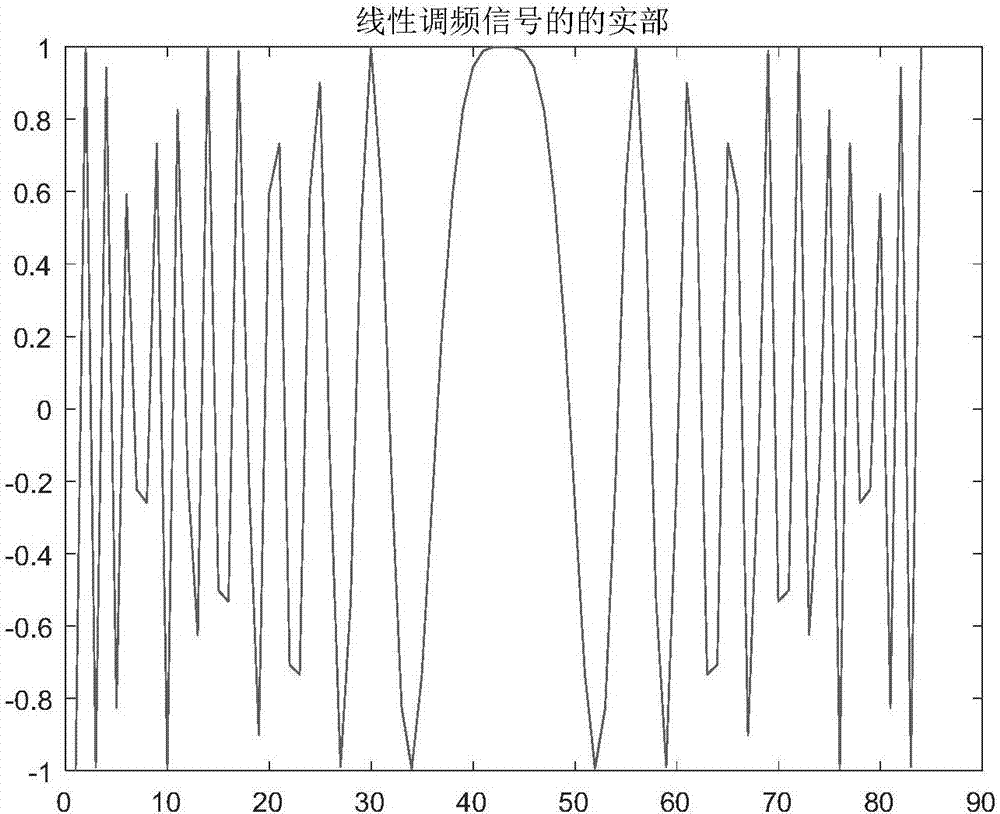
:传统脉冲压缩雷达脉冲多普勒雷达采用大时宽带宽积信号,以满足对提高探测距离和距离分辨率的双重要求;脉冲压缩处理将发射的宽脉冲信号压缩成窄脉冲信号,在发射脉冲时,脉冲越窄,信号频带越宽,但发射很窄的脉冲,要有很高的峰值功率,实际实现时困难很大,通常都采用大时宽的宽频带信号。现有的技术,大部分使用数字信号处理器(dsp)进行脉冲压缩雷达的脉冲压缩、动目标显示(mtd)、动目标检测(mti)等处理步骤,系统复杂,功耗大,开发周期长;使用现场可编程门阵列芯片(fpga)实现雷达成像,实现复杂,资源利用率不高,而且开发成本高,耗费时间和人力。技术实现要素:针对现有技术存在的不足,本发明的目的在于提出一种脉冲压缩雷达回波信号的优化处理方法,该种脉冲压缩雷达回波信号的优化处理方法利用nvidiajetsontx1板卡进行脉冲压缩雷达回波信号的模拟和处理,能够简化信号处理系统结构,缩短开发周期,进而实现更高的可移植性。为达到上述技术目的,本发明采用如下技术方案予以实现。一种脉冲压缩雷达回波信号的优化处理方法,其特征在于,基于nvidiajetsontx1板卡,所述nvidiajetsontx1板卡上包括host端和device端,host端为中央处理器cpu,device端为图形处理器gpu,且gpu和cpu集成进同一片系统芯片中,所述方法包括以下步骤:步骤1,在host端输入脉冲压缩雷达的参数,并计算host端的目标回波信号串,进而计算得到置零处理后的模拟回波信号;步骤2,device端获取置零处理后的模拟回波信号echo,然后对置零处理后的模拟回波信号echo依次进行脉冲压缩、动目标检测、动目标显示,分别得到脉冲压缩后的最终结果、动目标检测后的结果和动目标显示后的结果;步骤3,根据脉冲压缩后的最终结果、动目标检测后的结果和动目标显示后的结果,分别得到脉冲压缩后的最终结果图、动目标检测后的结果图和动目标显示后的结果图,所述脉冲压缩后的最终结果图、动目标检测后的结果图和动目标显示后的结果图为一种脉冲压缩雷达回波信号的优化处理结果。本发明与现有技术相比具有以下优点:第一,本发明采用了nvidia公司推出的tegrax1板卡,这款板卡将桌面级性能的256coremaxwellgpu和armcortexa57*4+a53*4@64bit八核cpu集成进soc中,在一张信用卡大小的pcb上,以最高10w的功耗实现了最高1tflops(每秒可执行浮点操作数)@16bit、500gflops@32bit的性能;tegrax1拥有更加丰富的内部资源和外部接口,芯片内集成了更多的乘法加法器和函数运算器;本发明采用的nvidiajetsontx1板卡,使用armcortexcpu作为主控芯片,内置基于linux的ubuntu系统,可以接受多种编程语言,如c/c++、java、python、fortan等,软件拓展性高,语言灵活性好,能够部署多种多用途程序,处理性能高,硬件拓展性好,功耗低。第二,本发明利用nvidia公司提供的nsighteclipseedition集成编译软件来进行程序开发,该软件主要基于eclipse软件定制,支持c++、java、python和fortan语言,提供了图形化的代码编写、编译及调试界面,在linux系统下为cuda语言编程提供了有力的支持。该软件还支持pc与nvidiajetsontx1板卡交叉编译、远程联调,极大地降低了脉冲压缩雷达信号处理程序的开发难度;本发明采用nvidia公司推出的cuda语言进行嵌入式gpu编程,该语言基于c/c++语言进行拓展,强调并行化计算;与以往的dsp开发使用的汇编语言相比,gpu使用的cuda语言计算可读性好、可移植性高,天然地适合于图形计算,而且还适合于大规模通用计算,并且具有学习成本低、调试方便等的特点。第三,本发明使用嵌入式gpu进行信号数据处理,对普通脉冲压缩雷达的一维时域信号进行了线程级的并行计算,能够在优于titms320c6678dsp的运行能耗下得到两倍于、甚至三倍于titms320c6678dsp的浮点运算性能,尤其在进行生成随机数序列、元素点乘和fft变换等操作时,运算效率比titms320c6678dsp快了两到三倍。第四,本发明采用了cufft、cublas、curand等cuda专用计算库,对用户隐藏了繁杂的硬件操作信息,可以在明显降低软件开发难度的同时极大地提高运算效率。另外,因为开发平台是soc系统,cpu与gpu共用一片专用高速运行内存,不存在主机端与设备端的拷贝延时,再加上对编写的雷达数据处理软件进行了存储器访存优化,更好地发挥了嵌入式gpu的性能,与普通arm、cpu或dsp相比,得到了4~5倍的计算加速比,而且因为该程序通用性更高,可以方便地移植到nvidia公司已经发售的tx2或更新的平台及普通pc平台。第五,本发明采用的nvidiajetsontx1板卡,内置操作系统和蓝牙、wlan等无线通讯方式,能够方便地与pc进行联机或者单机调试,易于配置,不需要专用下载器,有效地降低了开发的硬件成本并显著提高了开发的效率。附图说明下面结合附图和具体实施方式对本发明作进一步详细说明。图1为本发明的一种脉冲压缩雷达回波信号的优化处理方法流程图;图2为传统方法中待调制的线性调频脉冲chirp的实部幅值图;图3为传统方法中置零处理后的模拟回波信号echo幅值图;图4为传统方法中时域脉压结果pc_time1的示意图;图5为传统方法中频域脉压结果pc_freq1的示意图;图6为传统方法中脉冲压缩后的最终结果diff取绝对值后的示意图;图7为传统方法中动目标检测后的结果mtd的示意图;图8为传统方法中动目标显示后的结果mti的示意图;图9为本发明方法中待调制的线性调频脉冲chirp的实部幅值图;图10为本发明方法中置零处理后的模拟回波信号echo幅值图;图11为本发明方法中时域脉压结果pc_time1的示意图;图12为本发明方法中频域脉压结果pc_freq1的示意图;图13为本发明方法中脉冲压缩后的最终结果diff取绝对值后的示意图;图14为本发明方法中动目标检测后的结果mtd的示意图;图15为本发明方法中动目标显示后的结果mti的示意图。具体实施方法:步骤1,在nvidiajetsontx1板卡上设定脉冲压缩雷达的脉冲发射信号参数,并计算得到置零处理后的模拟回波信号echo。1a)在nvidiajetsontx1板卡上按住“ctrl+alt+t”,打开nvidiajetsontx1板卡终端,输入脉冲压缩雷达的参数,所述脉冲压缩雷达的参数包括脉冲压缩雷达的发射频率rf、脉冲压缩雷达的工作波长lamda、脉冲压缩雷达的发射信号带宽bw、脉冲压缩雷达的发射信号时宽tw、脉冲压缩雷达的发射脉冲重复周期prt、脉冲压缩雷达的发射脉冲重复频率prf、脉冲压缩雷达的采样频率fs、脉冲压缩雷达的噪声功率noisepower(单位为db)、脉冲压缩雷达检测范围内存在的目标总个数n、每个目标的距离、每个目标的速度和每个目标的反射系数和每个目标的回波脉冲数pulsenumber,时域脉压与频域脉压的绝对值差。所述nvidiajetsontx1板卡上包括host端和device端,host端为中央处理器cpu,device端为图形处理器gpu;本方法中采用cuda编程语言同时使用了cpu和gpu参与计算,其中cpu被称为host端,主要执行初始参数计算、读写文件系统和循环判断等顺序执行的任务,只对内存地址进行读写;gpu被称为device端,主要执行可以并行化的计算任务,可以同时对内存和显存地址进行读写;一般地,在cuda语言中需要区分内存和显存地址,约定前缀没有“dev_”的地址是内存地址,由cpu即host端进行操作,而前缀有“dev_”的地址是显存地址,由gpu即device端进行操作。由于nvidiajetsontx1板卡将gpu和cpu集成进了同一片系统芯片soc中,并且两者共用一片lpddr44gb的内存,所有的内存地址和显存地址是一起分配管理的,所以在nvidiajetsontx1板卡上进行cuda语言开发时,可以使用特殊的显存分配指令,使得gpu可以免除显存和内存之间数据传输的时间开销,而直接对内存进行操作。由nvidiajetsontx1板卡的cpu部分,即host端获取待调制的线性调频脉冲chirp,以及分别计算一个脉冲周期内的采样点数samplenumber、每个目标对应的距离门、每个目标对应的频移和每个目标对应的总采样点数totalnumber,其参数表达式分别为:lamda=c/rfsamplenumber=fix[fs×prt]prf=1/prttotalnumber=samplenumber×pulsenumberdealy[m]=fix[2fs×d[m]/c]targetfd[m]=2v[m]/lamda其中,c表示光速,fix表示向0取整操作,dealy[m]表示第m个目标对应的距离门,d[m]表示第m个目标的距离,targetfd[m]表示第m个目标对应的频移,v[m]表示第m个目标的速度,m=1,2,…,n,n为大于0的正整数;其中待调制的线性调频脉冲chirp如图2和图9所示。1b)由host端计算待调制的线性调频脉冲chirp的长度number,也就是每个回波脉冲的长度,其表达式为:number=fix[fs×tw]其中host端长度为i的待调制的线性调频脉冲值为chirp[i],其表达式为:其中,i=1,2,…,number,j表示虚数单位,exp表示指数函数。1c)由host端操作,将待调制的线性调频脉冲chirp中number个长度处的值重新倒序排列并取共轭,进而计算得到host端待调制的线性调频脉冲的脉冲压缩系数coeff,其中长度为i的待调制的线性调频脉冲值的脉冲压缩系数coeff[i]:coeff[i]=(chirp[number-i])*其中,上标*表示取共轭操作。host端产生脉冲压缩雷达回波模拟信号,且脉冲压缩雷达的接收机会周期性地接收回波信号并采样,进而得到每一个目标的脉冲回波信号;host端产生第m个目标的脉冲回波信号signal[m],m=1,2,…,n;第m个目标的脉冲回波信号signal[m]的长度为totalnumber,每个目标包括pulsenumber个回波脉冲数,每个回波脉冲分别被采样为长度为samplenumber的采样串,samplenumber表示每个采样串包含的采样点个数;进而第m个目标的脉冲回波信号signal[m]由pulsenumber个采样串依次排列、且首位相接组成第m个目标的脉冲回波信号采样串sample[m];第m个目标的脉冲回波模拟信号串为single_signal[m],第m个目标的脉冲回波模拟信号串single_signal[m]包含pulsenumber个信号串,由于脉冲压缩雷达的接收机的开启期持续时间比目标回波脉冲信号串的持续时间长,因此第m个目标的脉冲回波模拟信号串single_signal[m]中的每一个信号串分别被包含于第m个目标的脉冲回波模拟信号采样串sample[m]中,每一个信号串的长度都为number,且每一个信号串所在位置都由第m个目标对应的距离门delay[m]确定,其关系式为:single_signal[m,i]=r[m]2×chirp[i]sample(delay[m],delay[m+number])=single_signal[m]其中,sample(delay[m],delay[m+number])表示在samplenumber个采样点中除了编号为第m个目标对应的距离门dealy[m]的位置至编号为第m+number个目标对应的距离门dealy[m+number]的位置采样点处的数之外,其他位置采样点处的数均为0,并定义为第m个目标中每一个回波脉冲对应的信号串single_signal[m],single_signal[m,i]表示第m个目标中每一个回波脉冲对应的信号串single_signal[m]中长度为i处的值,r[m]表示第m个目标的反射系数。1c.1)根据第m个目标对应的频移targetfd[m],计算第m个目标的第i'个采样点对应的多普勒频移为freqmove[m,i'],其计算公式为:其中,i'=0,1,2,…,totalnumber-1,targetfd[m]表示第m个目标对应的频移。1c.2)令i'分别取0至totalnumber-1,重复执行1c.1),分别得到第m个目标的第0个采样点对应的多普勒频移为freqmove[m,0]至第m个目标的第totalnumber-1个采样点对应的多普勒频移为freqmove[m,totalnumber-1],并记为第m个目标的多普勒频移freqmove[m]。host端将第m个目标的脉冲回波信号signal[m]与第m个目标的多普勒频移freqmove[m]分别传输给相应的device端,分别记为显存中第m个目标的脉冲回波信号dev_signal[m]和显存中第m个目标的多普勒频移dev_freqmove[m],device端使用kernel1函数对显存中第m个目标的脉冲回波信号dev_signal[m]和显存中第m个目标的多普勒频移dev_freqmove[m]做复数点乘,得到复数点乘后的结果,记为第m个目标的回波信号dev_signal_freqmove[m],m=1,2,…,n,进而得到第1个目标的回波信号dev_signal_freqmove[1]至第n个目标的回波信号dev_signal_freqmove[n]后进行累加,得到host端的目标回波信号串dev_signalall,其表达式为:device端将host端的目标回波信号串dev_signalall传输给host端,记为host端的目标回波信号串signalall。1d)为了模拟雷达接收机从杂波环境中获得高斯白噪声信号,在device端使用curandgeneratenormal()函数产生符合高斯分布的随机序列,并设置随机序列长度为totalnumber,随机序列均值为0,随机序列标准差为stddev,所述随机序列标准差stddev与脉冲压缩雷达的噪声功率noisepower有关,分别产生杂波环境中高斯白噪声信号的实部dev_noise_r和杂波环境中高斯白噪声信号的虚部dev_noise_i,dev_noise_r的长度和dev_noise_i的长度分别为totalnumber,将杂波环境中高斯白噪声信号的实部dev_noise_r和杂波环境中高斯白噪声信号的虚部dev_noise_i相加得到高斯白噪声信号dev_noise,并将高斯白噪声信号dev_noise传输给host端,记为host端高斯白噪声信号noise。将host端的目标回波信号串signalall与host端高斯白噪声信号noise相加,相加后的结果记为模拟回波信号echo_real。所述模拟回波信号echo_real是由pulsenumber个回波脉冲组成的回波信号,每一个回波脉冲由samplnumber个复数组成。考虑到在雷达的发射期间,接收机闭锁不接受信号,即每一个回波脉冲的前number个数是不需要的,所以需要在模拟回波信号echo_real的对应位置做置零处理,即将模拟回波信号echo_real的每一个脉冲的前number个复数都写为零,然后记为置零处理后的模拟回波信号echo;其中置零处理后的模拟回波信号echo如图3和图10所示。步骤2,gpu从显存中读取置零处理后的模拟回波信号echo,然后对置零处理后的模拟回波信号echo依次进行脉冲压缩、mtd、mti,得到mti后的模拟回波信号。2a)第一步:脉冲压缩的时域脉压和频域脉压。时域脉压:host端将置零处理后的模拟回波信号echo和host端待调制的线性调频脉冲的脉冲压缩系数coeff做卷积乘,得到卷积乘后的模拟回波信号pc_time0,该卷积乘后的模拟回波信号pc_time0中前number个数为0的暂态点,剔除前number个暂态点,得到暂态点剔除后的模拟回波信号,记为时域脉压结果pc_time1;其中,时域脉压结果pc_time1如图4和图11所示。频域脉压:host端将置零处理后的模拟回波信号echo和host端待调制的线性调频脉冲的脉冲压缩系数coeff分别传输给device端显存中,分别记为device端显存中置零处理后的模拟回波信号dev_echo和device端显存中的脉冲压缩系数dev_coeff,device端使用cufft函数对device端显存中置零处理后的模拟回波信号dev_echo和device端显存中的脉冲压缩系数dev_coeff进行p点fft运算,分别得到fft处理后device端显存中置零处理后的模拟回波信号dev_echo_fft和fft处理后device端显存中的脉冲压缩系数dev_coeff_fft。其中,p表示设定的fft的运算点数,p为大于0的正整数;为了提高gpu的运算速度和方便数据对齐,fft的运算点数p取不小于totalnumber的2的幂,totalnumber表示dev_noise_r的长度或dev_noise_i的长度。使用kernel1函数将fft处理后device端显存中置零处理后的模拟回波信号dev_echo_fft和fft处理后device端显存中的脉冲压缩系数dev_coeff_fft做复数点乘,再使用cufft函数对复数点乘后的结果进行p点逆fft计算,得到逆fft处理后的结果,记为逆fft处理后device端显存中的模拟回波信号dev_pc_freq0,该逆fft处理后device端显存中的模拟回波信号dev_pc_freq0存在前number个值为0的暂态点,剔除前number个暂态点后,记为剔除暂态点后逆fft处理后device端显存中的模拟回波信号dev_pc_freq1,将该剔除暂态点后逆fft处理后device端显存中的模拟回波信号dev_pc_freq1传输给host端内存中,得到host端内存中剔除暂态点后逆fft处理后的模拟回波信号,记为频域脉压结果pc_freq1;其中,频域脉压结果pc_freq1如图5和图12所示。将时域脉压结果pc_time1和频域脉压结果pc_freq1做差,取作差后的结果绝对值,记为脉冲压缩后的最终结果diff;其中,脉冲压缩后的最终结果diff如图6和图13所示。由于gpu提供的双精度计算能力有限,所以本实施例使用的所有数据都尽量以单精度表示,这样导致脉冲压缩后的最终结果diff会相对增大。2b)第二步:数据重排。在host端将频域脉压结果pc_freq1重新整形为pulsenumber行、samplenumber列维矩阵,记为频域脉压矩阵pd。将频域脉压矩阵pd表示为由samplenumber个列向量组成,记为(x1,x2,x3,…,xh,…,xsamplenumber-1,xsamplenumber)组成,xh表示第h个列向量,所述第h个列向量为pulsenumber×1维列向量;也可表示为由pulsenumber个行向量组,记为(y1,y2,y3,…,yg,…,ypulsenumber-1,ypulsenumber)t,yg表示第g个行向量,所述第g个行向量为是samplenumber×1维行向量。2c)第三步:动目标检测(mtd);目标回波信号中含有运动目标的多普勒频移信息,可以依此推算出动目标的运动速度;本方法利用pulsenumber-点fft滤波器组,对频域脉压矩阵pd进行fft处理,实现动目标检测mtd功能。对频域脉压矩阵pd的每一个列向量分别进行pulsenumber-点fft处理,进而得到pulsenumber-点fft处理结果,然后将pulsenumber-点fft处理结果中的正、负频率以零频为中心,按大小顺序重新进行排列,进而完成samplenumber个列向量的处理,最终得到动目标检测后的结果mtd。2c.1)host端读取频域脉压矩阵pd中第h个列向量xh存入内存,记为第h个列向量的内存buff_h,将第h个列向量的内存buff_h传输至显存中,得到第h个列向量的显存数据dev_buff_h,device端开启cufft函数对第h个列向量的显存数据dev_buff_h进行pulsenumber点fft处理,得到第h个列向量的pulsenumber点fft处理结果dev_buff_fft_h。由于fft计算的结果没有将正频率和负频率按正负大小排序,所以需要对第h个列向量的pulsenumber点fft处理结果dev_buff_fft_h进行频谱搬移;device端开启kernel2函数,将第h个列向量的pulsenumber点fft处理结果dev_buff_fft_h中正、负频率以零频为中心,按大小顺序进行重新排列,进而得到频谱搬移后第h个列向量的处理结果dev_buff_kernel_h。然后将频谱搬移后第h个列向量的处理结果dev_buff_kernel_h传输给内存指针buff_fft,记为第h'个列向量数据h'的初始值为1,并令h'的值加1。2c.2)令h的值分别取1至samplenumber,重复执行2c.1),直到得到第1个列向量数据至第samplenumber个列向量数据记为动目标检测后的结果mtd,其表达式为:将动目标检测后的结果mtd回传给pc,pc使用matlab读取动目标检测后的结果mtd即可输出动目标检测后的结果mtd内包含的信息。一般的,如果脉冲压缩雷达检测范围内具有n个速度不同的目标,在动目标检测后的结果mtd中就在一片较低幅值的杂波背景下出现n个具有较大幅值的尖峰;其中,动目标检测后的结果mtd如图7和图14所示。2d)第四步:动目标显示(mti);为了使脉冲压缩雷达检测范围内的运动目标能够都被探测出来,需要有效地抑制动目标检测后的结果mtd中的杂波,本发明实施例采用双延迟线对消器作为动目标显示滤波器,所述双延迟线对消器在直流和脉冲重复频率prf的整数倍处具有较深的阻带。本发明方法中使用双延迟线对消器的脉冲响应为h(t):h(t)=δ(t)-2δ(t+tr)+δ(t+2tr),tr=samplenumber其中,t表示时间变量,tr表示脉冲重复周期;将频域脉压矩阵pd发送至device端,记为device端的频域脉压矩阵device_pd,然后开启kernel3函数对device端的频域脉压矩阵device_pd做双延迟对消操作:kernel3函数开辟一个规模为1×tm的线程块block,tm表示线程块block包含的线程个数,记为{thread(0),thread(1),…,thread(r),…,thread(tm-1)},thread(r)表示线程块block中的第r个线程,r∈{0,1,…,tm-1},线程块block包含的线程个数tm取值小于或等于nvidiajetsontx1板卡拥有的计算核心数corenumber;由于本实施例中使用的nvidiajetsontx1板卡拥有256个计算核心,所以corenumber取值是256,但线程块block包含的线程个数tm取值大于nvidiajetsontx1板卡拥有的计算核心数也是可行的,这时第一次循环会进行corenumber个线程,剩下的(tm-corenumber)个线程会在第二次循环进行。2d.1)初始化:令blockc表示第c个线程块,每个线程块的规模都为1×1×tm,c=1,2,…,samplenumber-2,c的初始值为1;tm表示线程块包含的线程个数,tm取值小于或等于gpu拥有的计算核心数;2d.2)读取device端的频域脉压矩阵device_pd中三个相邻行向量yc、yc+1和yc+2,使用双延迟线对消器的脉冲响应分别将第c个线程块blockc中的每一个线程分别对应与device端的频域脉压矩阵device_pd中第c行元素行向量进行滤波处理,将第c个线程块blockc中的每一个线程分别对应与device端的频域脉压矩阵device_pd中第c+1行元素行向量进行滤波处理,将第c个线程块blockc中的每一个线程分别对应与device端的频域脉压矩阵device_pd中第c+2行元素行向量进行滤波处理,分别得到滤波处理后第c个行向量滤波处理后第c+1个行向量和滤波处理后第c+2个行向量进而得到第l'行行向量l'的初始值为1,l'的最大值为samplenumber-2,并令l'的值加1。其中,滤波处理后第c个行向量滤波处理后第c+1个行向量和滤波处理后第c+2个行向量的得到过程是同时进行的。2d.3)令c的值加1,返回2d.2),直到得到第samplenumber-2行行向量并将此时得到的第1行行向量至第samplenumber-2行行向量记为device端动目标显示后的结果device_mti。然后将device端动目标显示后的结果device_mti传输至host端的内存中,记为动目标显示后的结果mti,并将动目标显示后的结果mti回传至pc,pc使用matlab读取动目标显示后的结果mti即可输出动目标显示后的结果mti内包含的信息。经过双延迟对消器后,动目标检测后的结果mtd中大部分的杂波信息被滤除,甚至一些低速运动目标的回波也会被抑制;如果n个目标中包含有若干个具有较大速度的目标,那么动目标显示后的结果图中就会出现对应数量的波峰;其中,动目标显示后的结果mti如图8和图15所示。经过双延迟对消器后,动目标检测后的结果mtd中大部分的杂波信息被滤除,进而得到动目标显示后的结果mti,其表达式为:其中,*表示卷积操作。2d.4)增大线程块维度:将kernel3函数的线程块规模分别从1×1×tm更改为2×1×tm、3×1×tm,…,甚至计算动目标显示后的结果时可以同时计算多个行向量,并能够使线程块被分配到更多的gpu计算核心,每个线程块拥有更多的线程,提高gpu核心的占用率,同一时间处理的矩阵元素更多,相应的处理速度也更快;其中,表示设定的规模最大值,为大于1的正整数;如表1所示。表1更改kernel3线程块大小的执行时间比较kernel3线程块大小执行时间(us)gpu执行占用率1*4802973.598.7%14*480883.698.7%nvidiajetsontx1板卡的gpu拥有256个计算核心,表1说明在更改线程块大小后,动目标显示后的结果mti的处理步骤得到了明显的加速。nvidiajetsontx1板卡的内存和显存是共用的,host端的内存地址可以由device端直接操作,可以明显减少内存指针操作,提高程序鲁棒性。如,通常用于分配显存的cudamalloc()函数可以更改为cudamallochost()函数,可以使gpu直接操作内存地址,减少内存和显存之间的传输开销。步骤3,将pc和nvidiajetsontx1板卡开发板连接至同一路由器,使两者的ip地址处于同一网段下,在nsighteclipseedition软件中编写雷达信号处理软件并进行远程编译,在nvidiajetsontx1板卡上进行远程调试,并对比双端已处理数据的差异。3a)将nvidiajetsontx1板卡和pc通过网线连接至同一个连接速度达1000mbps的路由器,并在路由器设置界面将两个设备设定为静态ip,使两者的ip地址处于同一网段下,使其可以相互ping通,测试方法是在pc端的ubuntu系统下按住“ctrl+t”打开终端窗口,输入“ping192.168.xx.xx(即nvidiajetsontx1板卡的ip地址)”,界面显示目标响应延迟正常即为ping通,否则检查并重设路由器。3b)在pc端打开nsighteclipseedition软件,建立工程并编写雷达信号处理软件的代码。3c)在pc端的nsighteclipseedition软件下,更改编译目标架构为aarchx64,添加aarchx64库路径至编译库路径中,选定需要使用的运行库cufft、curand和cublas,并设置编译目标为远程目标,检索至nvidiajetsontx1板卡的ip,即192.168.xx.xx,输入用户名和密码登录,然后进行远程编译。3d)开启nvidiajetsontx1板卡上的远程调试,在pc端的nsighteclipseedition界面的console窗口中查看脉冲压缩后的最终结果diff、动目标检测后的结果mtd和动目标显示后的结果mti。3e)使用pc端的matlab软件中的fread函数读取由nvidiajetsontx1板卡端返回的脉冲压缩后的最终结果diff、动目标检测后的结果mtd和动目标显示后的结果mti,如果使用plot、mesh函数得到脉冲压缩后的最终结果图、动目标检测后的结果图和动目标显示后的结果图,所述脉冲压缩后的最终结果图、动目标检测后的结果图和动目标显示后的结果图为一种脉冲压缩雷达回波信号的优化处理结果。通过实验对本发明效果作进一步验证说明。(一)pc上用matlab仿真结果:脉冲压缩雷达发射频率:1.65ghz,回波脉冲数:16发射信号带宽:2mhz,发射信号时宽:42μm雷达脉冲重复周期:240μm,采样频率:2mhz噪声功率:-12db,目标个数:4目标反射系数:[1,1,0.25,1],目标距离:[2800m,8025m,8025m,9200m]目标径向速度:[50m/s,-100m/s,0m/s,230m/s]从图7中可以看出,存在3个有速度的目标。从图8中可以判明有4个具有不同速度的目标,一个目标的速度为0。(二)nvidiajetsontx1板卡计算结果:从图14中可以看出,存在3个有速度的目标。从图15中可以判明有4个具有不同速度的目标,一个目标的速度为0。从图14和图15中可以看出,虽然在精度上有所损失,但nvidiajetsontx1板卡完全可以完成产生脉冲压缩雷达模拟回波并处理数据的工作。(三)nvidiajetsontx1板卡与titms320c6678dsp的fft计算速度对比下表是不同点数fft在两个处理器上的运算时间,titms320c6678dsp上调用官方提供的函数库(dsplib/dspf_sp_fftspxsp)并开启8个核心完成计算,gpu上调用cufft函数库完成运算。表2gpu与dsp完成不同点数fft时间对比fft点数gpu/usdsp/us加速比64k198.1388.51.96128k358.7701.51.95256k823.71354.21.64512k1595.03402.12.131024k3109.16612.42.13表2表明jetsontx1综合考虑了性能和功耗的平衡,其峰值功耗只有10w,比tms320c6678dsp的功耗更低,但它进行fft计算的执行效率能够达到c6678的2倍左右。综上所述,仿真实验验证了本发明的正确性,有效性和可靠性。显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围;这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1