一种丁羟推进剂药浆组分近红外检测方法与流程
本发明涉及推进剂组分装药检测方法,具体是一种丁羟推进剂药浆组分近红外快速检测方法,用于对固体推进剂中的粘结剂htpb、增塑剂dos和氧化剂ap含量进行快速检测,为发动机装药质量提供重要保障。
背景技术:
:推进剂药浆组分含量是固体发动机装药工艺过程重要控制的环节,它直接影响推进剂的各项性能指标。粘结剂含量波动大小对推进剂力学性能具有决定性的影响。增塑剂不但可以降低未固化推进剂药浆的粘度,降低推进剂玻璃化温度,而且其含量波动大小对改善低温力学性能有重要作用。氧化剂对体系燃烧性能至关重要。因此将混合药浆中粘结剂(htpb)、增塑剂(kz)、氧化剂(ap)组分含量控制在要求的技术指标范围内是发动机装药质量的重要保证条件。对推进剂药浆组分实施快速检测是各国推进剂制造行业共同追求的目标。复合固体推进剂药浆是含有粘合剂基体,氧化剂颗粒,金属粒子以及其它一些功能组分的复杂浆状混合物体系,药浆不透光,而且含有大量的固体颗粒。由于体系复杂,其混合过程的分析检测难度非常大。目前,国内在推进剂制造行业仅仅强调对所用原材料进行指标控制和分析,通过配方调试来确定装药参数。虽然这样做对控制发动机装药质量起到有效保障作用,但由于装药过程质量控制缺乏有效检测手段,因此当受环境等诸多因素影响时,有时的性能预示实验往往并不尽人意,浪费了大量时间、人力、物力。目前,对于复合固体推进剂药浆组分含量的快速检测还处于简单的探索研究阶段。传统分析方法测定一个样品的多种性质或浓度数据需要多种分析仪器,成本高工作效率低,远不能适应推进剂组分快速检测的需要。因此,多年来国内外对固体推进剂装药过程质量控制快速分析虽有迫切生产需求,但在固体推进剂装药分析检测
技术领域:
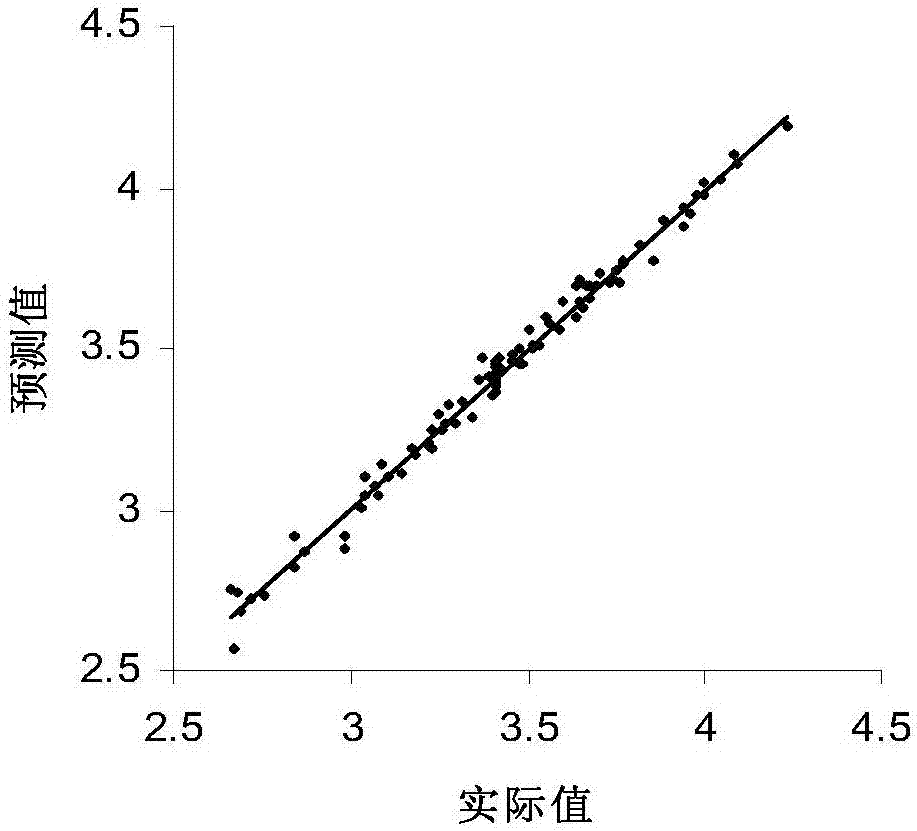
,一直均未实现对复合固体推进剂稀药浆组分含量的快速检测。近红外分析技术具有分析快速、无损、无污、可进行多组分同时测试、易于实现在线的特点,它在农业、医药、化工等行业质量控制快速分析方面得到广泛应用,虽然从信号干扰严重、信号微弱的光谱中提取有效信息是近红外在推进剂应用的难点,但各国仍在推进剂领域积极开展近红外技术探索研究。talanta报道,2004年,加拿大布里斯托尔宇航有限rockwood推进剂厂michaeld.judge利用近红外技术对固体推进剂中的四种组分均匀预混所组成的体系进行了组分含量测定。这种测定的研究体系相对简单,体系内仅有四种组分组成,与由十多种组分组成的真正固体推进剂相差甚远,且液体组分占~99%,可用透射方式进行样品光谱采集,因此其获得的光谱强度比采真正固体推进剂的光谱强度强很多。而本申请研究的却是由十多种组分组成的实际应用的固体推进剂,固体组分高达约90%的真正稀药浆。由于近红外技术属无损测试,故固体组分比例高达~90%导致的微观非均匀性、样品颜色较深使光谱强度很弱、多达十余个组分所组成体系形成了固体推进剂丁羟药浆样品特性的复杂性,形成了对模型预测精度的严重不利影响,使得固体推进剂丁羟药浆的近红外检测成为检测难点。技术实现要素:为克服现有技术中存在的模型预测精度影响大的不足,本发明提出了一种丁羟推进剂药浆组分近红外检测方法。本发明的具体过程是:步骤1.建立样品库。所述建立的样品库是丁羟推进剂药浆样品库,具体过程是采用实验室配制和生产现场取样两种方式获得,并将获得的样品分别用于建立校正集和建立验证集。步骤2.采集各样品的近红外漫反射光谱。用傅立叶变换红外光谱仪,通过旋转杯分别采集各样品的近红外漫反射光谱。采集样品的近红外漫反射光谱时,将第一个样品分为三份,分别放入旋转杯内并平铺为1cm的厚度;用称量瓶轻压药浆以使样品紧贴杯底。分别旋转各装有样品的旋转杯,通过漫反射积分球装置对所述样品进行光谱采集,得到第一个样品的三张近红外漫反射光谱数据,取平均光谱用于数据处理。采集时,扫描次数为60~120次,分辨率为4cm-1,增益为2,近红外漫反射光谱采集范围为4000~10000cm-1。重复所述获得第一个样品平均近红外漫反射光谱的过程,分别对其余各样品进行光谱测试;分别得到其余各样品的平均近红外漫反射光谱。步骤3.滤波平滑预处理。以得到的各样品的平均近红外漫反射光谱分别作为原始光谱。具体是,通过滤波对原始光谱进行平滑预处理,以消除各种干扰因素引起的光谱偏差,并对光谱图进行波长选择。波长选择时选择相关性最好的两个光谱区域。分别得到经过预处理后的各样品的平均近红外漫反射光谱。所述滤波平滑预处理时,相关性最好的两个光谱区域分别为6800cm-1~5550cm-1光谱区域和5180cm-1~4000cm-1光谱区域。步骤4.建立校正模型。所述的校正模型是丁羟推进剂药浆吸光度分别与粘结剂htpb含量、增塑剂dos含量、氧化剂ap含量之间的关系。在建立校正模型前需确定最佳变量的数量。具有最小预测残差平方和的变量数就是模型的最佳变量数。通过公式(1)确定最佳变量数:式中:press是预测残差平方和,n是样品数;是交互验证预测值;yi是实际值。将经过预处理后的各样品的平均近红外漫反射光谱分别与粘结剂htpb含量、增塑剂dos含量、氧化剂ap含量进行关联,用偏最小二乘法建立其中93个样品与粘结剂htpb含量、增塑剂dos含量、氧化剂ap含量的校正模型,形成校正集。步骤5.校正模型的性能评价。所述的校正模型性能包括:光谱的吸光度分别与粘结剂htpb、增塑剂dos和氧化剂ap之间含量的相关系数rk,其中r为相关系数,k=1、2、3,分别表示粘结剂htpb的相关系数、增塑剂dos的相关系数和氧化剂ap相关系数;粘结剂htpb的校正误差均方根与验证误差均方根;增塑剂dos的校正误差均方根与验证误差均方根;氧化剂ap的校正误差均方根与验证误差均方根。在对校正模型进行性能评价时:通过相关系数r分别评价粘结剂htpb的预测值与实际值关系的线性程度、增塑剂dos的预测值与实际值关系的线性程度、氧化剂ap的预测值与实际值关系的线性程度;分别得到粘结剂htpb相关系数r1、增塑剂dos的相关系数r2和氧化剂ap的相关系数r3。分别计算粘结剂htpb的校正误差均方根和验证误差均方根;分别计算增塑剂dos的校正误差均方根与验证误差均方根;分别计算氧化剂ap的校正误差均方根与验证误差均方根。当粘结剂htpb的相关系数r1大于0.9、校正误差均方根小于0.2、验证误差均方根小于0.2时,该粘结剂htpb校正模型满足要求;当增塑剂dos的相关系数r2大于0.9、校正误差均方根小于0.1、验证误差均方根小于0.1时,该增塑剂dos校正模型满足要求;当氧化剂ap的相关系数r3大于0.9、校正误差均方根小于0.3、验证误差均方根小于0.3时,该氧化剂ap校正模型满足要求;在评价校正模型的性能时,通过公式(2)分别确定粘结剂htpb1、增塑剂dos和氧化剂ap的相关系数rk:该rk值表示预测值与实际值关系的线性程度;rk越接近1,则校正模型的预测值与实际值相关性越强。通过公式(3)确定校正误差均方根rmsec:通过公式(4)确定验证误差均方根rmsep:上述各式中:-nir数学模型预测值;ci-组分含量实际值;-实际值的平均值;n-建立模型所用的校正集样本数;m-用于检验模型的验证集样本数。步骤6.模型预测。所述模型预测的具体过程是另采集一张样品,并得到该样品的近红外光谱。将得到的近红外光谱带入至所建立的丁羟推进剂药浆吸光度分别与粘结剂htpb含量、增塑剂dos含量、氧化剂ap含量之间关系的模型中,同时得到粘结剂htpb含量、增塑剂dos含量、氧化剂ap含量。本发明是建立一种对丁羟固体推进剂药浆粘结剂htpb、增塑剂dos、氧化剂ap组分的快速检测方法,为发动机装药质量提供重要保障。本发明利用近红外测试方法,通过选择可旋转的漫反射采样技术和多点采集技术等手段解决因丁羟药浆样品特性对测试精度的不利影响,通过化学计量法、分析波段选择、最佳变量数等最佳建模参数确定,建立吸光度与组分含量之间关系,通过建立准确的校正模型,形成定量组分含量方法,根据所建立的吸光度与含量之间的相关关系,通过一张被测的样品的近红外光谱即可同时给出待测样品的多组分含量定量结果,实现丁羟推进剂药浆组分快速检测。本发明建立了一种丁羟推进剂药浆组分近红外快速检测方法,实现了丁羟复合固体推进剂稀药浆中粘结剂htpb、增塑剂dos、氧化剂ap三组分含量检测,具有以下特点:(1)测定速度极快,从得到样品到给出数据不到十分钟;(2)分析效率高,通过被测样品的一张光谱即可进行多组分同时定量;(3)待测样品无需预处理,不破坏样品,属无损测试,利于实现在线监测。本发明为装药过程中丁羟推进剂药浆组分中的粘结剂、增塑剂、氧化剂组分含量提供了一种快速、高效、无损检测手段,可及时发现装药生产过程中药浆组分浓度变化,实现对工艺质量稳定性和均匀性的控制,避免不必要浪费。附图说明图1为实施例1中丁羟推进剂药浆htpb含量实际值与nir预测值之间的关系图,图2为实施例1中丁羟推进剂药浆kz含量实际值与nir预测值之间的关系图。图3为实施例1中丁羟推进剂药浆ap含量实际值与nir预测值之间的关系图。图4为实施例2中丁羟推进剂药浆htpb含量实际值与nir预测值之间的关系图。图5为实施例2中丁羟推进剂药浆kz含量实际值与nir预测值之间的关系图。图6为实施例2中丁羟推进剂药浆ap含量实际值与nir预测值之间的关系图。图7为本发明的流程图。图中的1均为该实施例中校正样品在关系图中的分布示意。具体实施方式本发明采用近红外光谱测试技术对某配方的丁羟推进剂药浆组分粘结剂htpb、增塑剂dos、氧化剂ap含量快速检测。所述的粘结剂htpb为端羟基聚丁二烯,所述的增塑剂dos为癸二酸二异辛酯,所述的氧化剂ap为高氯酸铵。通过提取混合物光谱中与需要分析的组分含量相关的光谱信息进行关联,建立相关模型,利用该模型对未知混合物的光谱进行预测,即可得到混合物中需要分析的组分含量。实施例1步骤1.建立样品库。通过收集丁羟推进剂药浆样品,建立样品库。所述样品是按常规方法采用实验室配制和生产现场取样两种方式获得,并将获得的样品分别用于建立校正集和建立验证集。本实施例中,样品集有101个样品,其中93个样品用来建立校正集,8个用来建立验证集。步骤2.采集各样品的近红外漫反射光谱。用傅立叶变换红外光谱仪采集样品近红外漫反射光谱。所用仪器为美国thermonicolet公司的nexus670傅立叶变换近红外光谱仪、漫反射积分球装置、omnic信号采集软件及tqanalyst数据处理软件。采集样品的近红外漫反射光谱时,将第一个样品分为三份,分别放入旋转杯内并平铺为1cm的厚度;用称量瓶轻压药浆以使样品紧贴杯底。分别旋转各装有样品的旋转杯,通过漫反射积分球装置对所述样品进行光谱采集,得到第一个样品的三张近红外漫反射光谱数据,取平均光谱用于数据处理。采集时,扫描次数为120次,分辨率为4cm-1,增益为2,近红外漫反射光谱采集范围为4000~10000cm-1。重复所述获得第一个样品平均近红外漫反射光谱的过程,分别对其余各样品进行光谱测试;分别得到其余各样品的平均近红外漫反射光谱。共计得到101个样品的平均近红外漫反射光谱。步骤3.滤波平滑预处理。以得到的101个样品的平均近红外漫反射光谱分别作为原始光谱。通过savitzky-golay滤波对原始光谱进行平滑预处理,以消除各种干扰因素引起的光谱偏差,并对光谱图进行波长选择。波长选择时选择相关性最好的两个光谱区域,分别为6800cm-1~5550cm-1光谱区域和5180cm-1~4000cm-1光谱区域。分别得到经过预处理后的各样品的平均近红外漫反射光谱。所选择的光谱区域中,样品光谱在7000cm-1以上时噪声较大并存在一定偏移,没有明显的吸收峰,且7400cm-1~6800cm-1和5550cm-1~5180cm-1段因受水汽吸收影响比较明显,这些波段在分析时均不予使用。通过波长选择确定的两个光谱区域,对减少噪音信号的影响、提高运算速度和模型的稳定性是有益的。因为当采用全谱区计算时,不仅计算量大,而且在某些光谱区域,样品的光谱信息很弱,或与样品的组成、性质间缺乏相关关系,引入这些波长会造成模型精度降低甚至错误,所以在光谱分析中,需对波长点进行选择,删除一些对建模无用的干扰波长。步骤4.建立校正模型。所述的校正模型是丁羟推进剂药浆吸光度分别与粘结剂htpb含量、增塑剂dos含量、氧化剂ap含量之间的关系。定量分析的模型质量还取决于正确选取最佳变量的数量。选择因子数太小会出现拟合不足,丢掉了样品光谱信息,但是选择最佳变量太多会导致过拟合,引入噪音,降低模型质量。因此,建立定量校正模型时,需对最佳变量数进行合理选择。所述对最佳变量数进行合理选择的方法采用陆婉珍等在《现代近红外光谱分析技术》中提出的采用交互验证法所得的预测残差平方和的方法确定。所述交互验证的方法是每次剔除一个或多个样品,然后用剩下的样品建立模型,用该模型预测被剔除样品,重复上述过程直到每个样品都被剔除过一次。具有最小预测残差平方和的变量数就是模型的最佳变量数。最佳变量数选择为12。通过公式(1)计算press值:式中n——样品数;——交互验证预测值;yi——实际值。本实施例中,通过交互验证的方法最终确定建模所需的最佳变量数为12。将经过预处理后的各样品的平均近红外漫反射光谱分别与粘结剂htpb含量、增塑剂dos含量、氧化剂ap含量进行关联,用偏最小二乘法建立其中93个样品与粘结剂htpb含量、增塑剂dos含量、氧化剂ap含量的校正模型,形成校正集。所述93个样品标记为i,i=1~n;本实施例中,n=93。剩余的8个样品作为验证集,标记为j,j=1~m;本实施例中,m=8。步骤5.校正模型的性能评价。所述的校正模型性能包括:光谱的吸光度分别与粘结剂htpb、增塑剂dos和氧化剂ap之间含量的相关系数rk,其中r为相关系数,k=1、2、3,分别表示粘结剂htpb的相关系数、增塑剂dos的相关系数和氧化剂ap相关系数。粘结剂htpb的校正误差均方根与验证误差均方根;增塑剂dos的校正误差均方根与验证误差均方根;氧化剂ap的校正误差均方根与验证误差均方根。在对校正模型进行性能评价时:通过相关系数r分别评价粘结剂htpb的预测值与实际值关系的线性程度、增塑剂dos的预测值与实际值关系的线性程度、氧化剂ap的预测值与实际值关系的线性程度。分别得到粘结剂htpb相关系数r1、增塑剂dos的相关系数r2和氧化剂ap的相关系数r3。分别计算粘结剂htpb的校正误差均方根和验证误差均方根;分别计算增塑剂dos的校正误差均方根与验证误差均方根;分别计算氧化剂ap的校正误差均方根与验证误差均方根。当粘结剂htpb的相关系数r1大于0.9、校正误差均方根小于0.2、验证误差均方根小于0.2时,该粘结剂htpb校正模型满足要求。当增塑剂dos的相关系数r2大于0.9、校正误差均方根小于0.1、验证误差均方根小于0.1时,该增塑剂dos校正模型满足要求。当氧化剂ap的相关系数r3大于0.9、校正误差均方根小于0.3、验证误差均方根小于0.3时,该氧化剂ap校正模型满足要求。在评价校正模型的性能时,通过公式(2)分别确定粘结剂htpb1、增塑剂dos和氧化剂ap的相关系数rk:该rk值表示预测值与实际值关系的线性程度。rk越接近1,则校正模型的预测值与实际值相关性越强。通过公式(3)确定校正误差均方根rmsec:通过公式(4)确定验证误差均方根rmsep:上述各式中:-nir数学模型预测值;ci-组分含量实际值;-实际值的平均值;n-建立模型所用的校正集样本数;m-用于检验模型的验证集样本数:rmsec和rmsep分别代表校正集和验证集的预测值与实际值的偏差。值愈小,则模型的预测精度愈高。如果指标不好,一般需通过不断优化建模参数,以提高校正模型拟合质量。本实施例中,校正模型性能评价结果见表1。表1三种组分的模型参数组分相关系数(rk)校正误差均方根(rmsec)验证误差均方根(rmsep)htpb0.980850.09060.0742kz0.993990.03880.0370ap0.957650.20100.1650从表中可以看出,粘结剂htpb和增塑剂dos的rmsec、rmsep均非常小,氧化剂ap稍大;三种组分的相关系数均大于0.95,kz组分达到0.99399。步骤6.模型预测。另采集一张样品,并得到该样品的近红外光谱,通过所建立的校正模型,可同时得到粘结剂htpb含量、增塑剂dos含量、氧化剂ap含量。丁羟推进剂药浆中粘结剂htpb含量、增塑剂dos含量和氧化剂ap含量实际值与近红外光谱预测结果分别见附图1、附图2、附图3。图中横坐标为组分含量的真实值,纵坐标为近红外光谱预测值。线性关系好,说明预测值与真实值较接近。可以看出,所建模型线性关系显著,模型校正误差和验证误差均较小,此模型预测精度较高。实施例2步骤1.建立样品库。通过收集丁羟推进剂药浆样品,建立样品库。所述样品是采用实验室配制和生产现场取样两种方式获得。样品集有99个样品,其中91个样品用来建立校正集,8个用来建立验证集。步骤2.采集各样品的近红外漫反射光谱。用傅立叶变换红外光谱仪采集样品近红外漫反射光谱。所用仪器为美国thermonicolet公司的nexus670傅立叶变换近红外光谱仪、漫反射积分球装置、omnic信号采集软件及tqanalyst数据处理软件。采集样品的近红外漫反射光谱时,将第一个样品分为三份,分别放入旋转杯内并平铺为1cm的厚度;用称量瓶轻压药浆以使样品紧贴杯底。分别旋转各装有样品的旋转杯,通过漫反射积分球装置对所述样品进行光谱采集,得到第一个样品的三张近红外漫反射光谱数据,取平均光谱用于数据处理。采集时,扫描次数为64次,分辨率为4cm-1,增益为2,近红外漫反射光谱采集范围为4000~10000cm-1。重复所述获得第一个样品平均近红外漫反射光谱的过程,分别对其余各样品进行光谱测试;分别得到其余各样品的平均近红外漫反射光谱。共计得到99个样品的平均近红外漫反射光谱。步骤3.滤波平滑预处理。以得到的99个样品的平均近红外漫反射光谱分别作为原始光谱。通过savitzky-golay滤波对原始光谱进行平滑预处理,以消除各种干扰因素引起的光谱偏差,并对光谱图进行波长选择。波长选择时选择相关性最好的两个光谱区域,分别为6800cm-1~5550cm-1光谱区域和5180cm-1~4000cm-1光谱区域。分别得到经过预处理后的各样品的平均近红外漫反射光谱。步骤4.建立校正模型。通过交互验证的方法确定建模所需的最佳变量数为12。将经过预处理后的各样品的平均近红外漫反射光谱分别与粘结剂htpb含量、增塑剂dos含量、氧化剂ap含量进行关联,用偏最小二乘法建立其中91个样品与粘结剂htpb含量、增塑剂dos含量、氧化剂ap含量的校正模型,形成校正集。所述91个样品标记为i,i=1~n;本实施例中,n=91。剩余的8个样品作为验证集,标记为j,j=1~m;本实施例中,m=8。步骤5.校正模型的性能评价。与实施例1相同方法进行校正模型性能评价,校正模型性能评价结果见表2。表2三种组分的模型参数组分相关系数(rk)校正误差均方根(rmsec)验证误差均方根(rmsep)htpb0.984230.08050.0632kz0.993700.03850.0301ap0.964250.18100.1900步骤6.模型预测。另采集一张待测样品的nir光谱,调用所建立的nir模型,经计算机处理即可同时得到htpb、kz、ap三组分含量。丁羟推进剂药浆中htpb、kz和ap含量实际值与nir光谱预测结果分别见附图4、附图5、附图6。图中横坐标为组分含量的真实值,纵坐标为nir光谱预测值。可以看出,所建模型线性关系显著,模型校正误差和验证误差均较小,此模型预测精度较高。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1