生物标志物的制作方法
本发明涉及使用生物标志物对非酒精性脂肪肝病(nafld)的进展进行诊断、预测或监测或分阶段的方法。本发明还涉及确定nafld严重性的评分方法,以及治疗nafld的方法。
背景技术:
nafld是西方世界最常见的肝脏疾病。它包括进行性肝病的疾病谱,范围从非酒精性脂肪肝(nafl)到非酒精性脂肪性肝炎(nash),其可发展为肝纤维化和肝硬化。该疾病与肥胖有关,美国和英国约有3分之1的人患有一定程度的nafld,全世界平均约有5分之1的人患有一定程度的nafld。nafld是诊断不出来的,因为患者通常是无症状的,即使在晚期肝病(esld)发展之前。
nafld的主要阶段包括非酒精性脂肪肝(nafl),非酒精性脂肪性肝炎(nash),肝纤维化(肝脏纤维化)和肝硬化。
“非酒精性脂肪肝”或“nafl”也称为单纯性脂肪变性。它是肝脏的肝细胞中脂肪(甘油三酯)和其他脂质积累的地方。失调的脂肪酸代谢导致脂肪变性,并且可由多种因素引起,例如糖尿病中的胰岛素耐受性、缺乏运动和过量的食物摄入,其中热量摄入和燃烧之间存在不平衡。
“非酒精性脂肪性肝炎”或“nash”是nafld的更具侵袭性的阶段,其中存在伴有脂肪变性的肝脏炎症。在英国和欧洲,多达20分之一1的人患有nash。接受肝脏移植的患者中约有20%是nash患者。在包括儿童和青少年在内的一般人群中,nash病例正在增加。
“肝纤维化(hepaticfibrosis)”可与“肝脏纤维化(liverfibrosis)”互换使用。肝纤维化是伤口愈合反应,其特征在于肝脏中瘢痕组织(即细胞外基质)的过度积累。在nash中可能会或可能不会看到肝纤维化,并且肝纤维化是组织的正常结构元素被过量的非功能性瘢痕组织所取代。肝纤维化可由多种因素引起,包括脂肪肝、酒精和病毒。肝脏纤维化通常使用各种分阶段方法,例如ishak,metavir,knodell以及用于nafld的kleiner-brunt方法按严重性进行分阶段。
“肝硬化”或“肝硬变”是肝脏瘢痕的最严重形式,并且与肝纤维化不同,它是结节状的并且对肝脏造成不可逆的结构损伤。肝硬化是英国每年6000多人和美国约27,000人死亡的原因,使其成为第九大致死原因。肝硬化是肝细胞癌(hcc)的主要危险因素,并且在肝癌的这个阶段,唯一的治疗方法是肝移植。在可逆性肝脏瘢痕形成的早期阶段诊断纤维化是必要的,以便肝硬化中的不可逆的肝损伤可以被预防。
评估肝纤维化和nafld的参考标准是肝脏活组织检查,这种侵入性手术有许多众所周知的缺点:患者不适(疼痛和出血);由于整个肝脏纤维化不均匀,肝脏活组织检查可能是不可靠的;假阴性率可高达20%;相关死亡率为1/10,000;观察者间的变化和高成本。超声可用于诊断nafld,尽管这种方法对最有可能患有nafld的患者的临床肥胖患者的敏感性较差。超声也无法区分nafld内的nash和纤维化,并且对脂肪变性的敏感性较低(poynardetal.,2005,comparativehepatology,4,10;yaoetal.,2001,jultrasoundmed,20,465;schwenzeretal.,2009,jhepatol,51,433)。在与活组织检查类似的方式中,nafld的超声评估是依赖于操作者的,具有观察者间的变化(straussetal.,2007,amjroentgenol;189,w320)。磁共振成像(mri)是诊断肝纤维化的一种有前途的方法(banerjeeetal.,2014,jhepatol,60,69),其适用于大多数患者,尽管它不能用于患有幽闭恐惧症的、无法保持静止状态、无法适应mri扫描仪的极少数患者,和不能用于具有内体医疗设备(如心脏起搏器)的患者。瞬时弹性成像(fibroscan)评估肝硬度,尽管所述方法对于肝纤维化是有希望的,但是在组成大多数nafld患者的肥胖患者中难以进行(pettaetal.,2011,alimentpharmacolther,33,1350)。
因此,需要改进的微创的方法来确定患者的nafld阶段。
技术实现要素:
发明人已经鉴定了处于nafld的不同阶段(例如nafl、具有/不具有纤维化的nash、肝硬化)的患者中上调或下调的蛋白质生物标志物。
本发明提供了一种对个体非酒精性脂肪肝病(nafld)的进展进行诊断、预测或监测或分阶段的方法,所述方法包括检测和定量从所述个体获得的生物样品中的一个或多个生物标志物,其中所述一个或多个生物标志物选自载脂蛋白f、脂多糖结合蛋白、纤维胶凝蛋白-2、载脂蛋白d、激肽原-1、载脂蛋白m、血小板反应蛋白-1、iggfc结合蛋白、胱抑素-c、α-1-酸糖蛋白2和富含亮氨酸的α-2-糖蛋白,从而对nafld的进展进行诊断、预测或监测或分阶段。
本发明还提供了一种用于确定nafld严重性的评分方法,所述方法包括检测和定量从所述个体获得的生物样品中的一个或多个生物标志物,其中所述一个或多个生物标志物选自载脂蛋白f、脂多糖结合蛋白、纤维胶凝蛋白-2、载脂蛋白d、激肽原-1、载脂蛋白m、血小板反应蛋白-1、iggfc结合蛋白、胱抑素-c、α-1-酸糖蛋白2和富含亮氨酸的α-2-糖蛋白,其中将生物标志物的水平与对照样品或参照样品/水平进行比较以得出分数。
本发明另外提供了一种治疗nafld的方法,所述方法包括通过上述方法诊断个体的nafld,和对所述个体施用药剂或实施对治疗nafld有效的治疗方案。
现在将通过示例而非限制的方式并参考附图更详细地描述本发明。对于本领域技术人员而言,当获得本公开时,许多等同的修改和变化将是显而易见的。因此,所阐述的本发明的示例性实施方式被认为是说明性的而非限制性的。在不脱离权利要求所限定的本发明的范围的情况下,可以对所描述的实施方式进行各种改变。本文引用的所有文献,无论是上文还是下文,均通过整体引用明确地并入本文。
本发明包括所述方面和优选特征的组合,除非这种组合是显然不允许的,或者说是必须明确避免的。如在本说明书和所附权利要求中所使用的,单数形式“一”、“一个”和“所述”包括复数指示,除非内容另有明确说明。因此,例如,提及“生物标志物”包括两个或多个此类生物标志物。
附图说明
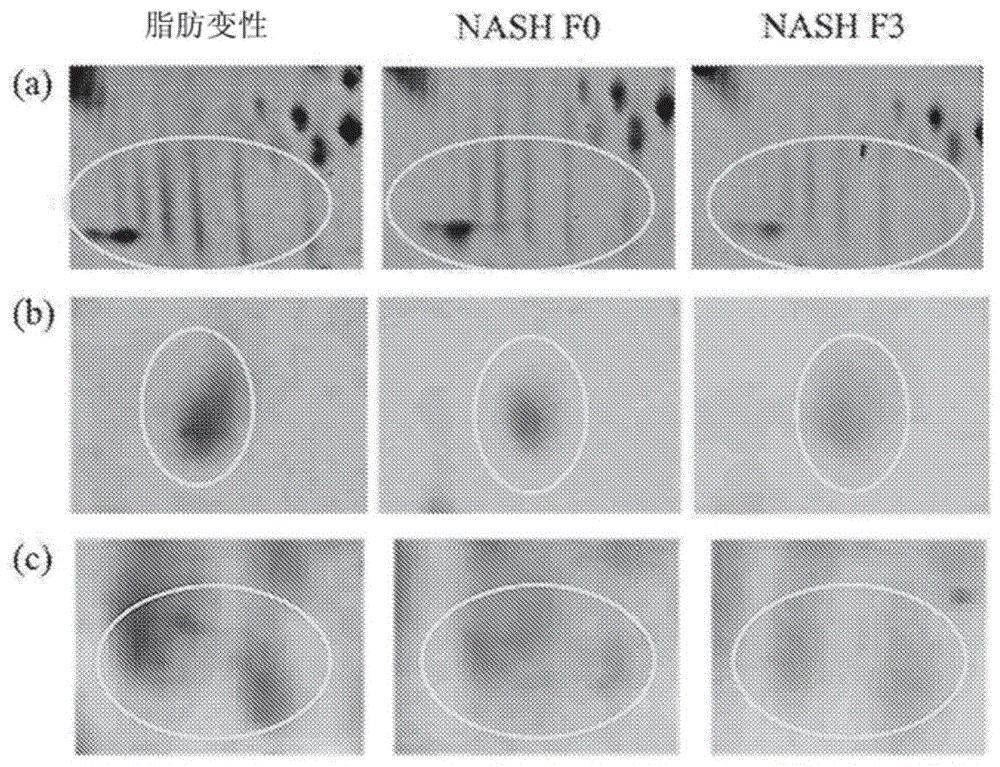
图1-显示跨nafld阶段的生物标志物表达降低的代表性2d-page凝胶的放大区域。显示了三种新型的生物标志物作为实施例,并且圈出了所鉴定的蛋白质的相对位置。从左到右的nafld阶段是脂肪变性(nafl)、没有纤维化的nash(f0)和具有晚期纤维化的nash(f3)。(a)载脂蛋白d、(b)载脂蛋白m、(c)激肽原-1。
图2-使用具有nafld严重性增加的患者血清样品的新型生物标志物的蛋白质免疫印迹光密度测定数据。(a)载脂蛋白d;这种生物标志物在健康对照中很高,并且在nafld的所有阶段始终较低,表明它可用作早期nafld生物标志物。(b)载脂蛋白m;所述生物标志物显示从脂肪变性(nafl)到nashf0的轻微降低,但在nashf3中的表达显著降低,表明它在确定肝纤维化方面最有用。(c)激肽原-1;所有nafld阶段均持续降低。(d)载脂蛋白f;所有nafld阶段均持续降低。
图3-使用来自健康个体(对照)和患有脂肪变性(nafl)和nash(具有f0、f1和f3的kleiner-brunt分数)的患者的血清样品的新型nafld生物标志物的使用串联质量标签(tmt;10-plex)的质谱相对定量数据。(3a)载脂蛋白f(apo-f)显示随着nafld严重性的增加其浓度降低。(3b)脂连蛋白从对照到脂肪变性(nafl)到nash,其浓度降低,但在nash的所有纤维化阶段都是恒定的,表明它是一种良好的nafld生物标志物。(3c)纤维胶凝蛋白-2显示nafld的一些降低,并在纤维化阶段f3中具有最低水平。(3d)血小板反应蛋白-1从对照到脂肪变性(nafl)和跨nafld的所有阶段增加。
图4-用于选定的潜在生物标志物的基于质谱定量数据的平行反应监测(prm)。(4a)使用apo-f序列中三种不同的胰蛋白酶肽的apo-f的绝对浓度。使用ignislc-ms方法将血清样品的消化物(100ng)用于定量apo-f。(4b-i)使用prm的生物标志物的相对定量,用于(4b)纤维胶凝蛋白-2、(4c)血小板反应蛋白-1、(4d)脂连蛋白、(4e)iggfc结合蛋白、(4f)胱抑素-c、(4g)脂多糖结合蛋白,(4h)α-1-酸糖蛋白2,(4i)富含亮氨酸的α-2-糖蛋白和(4j)载脂蛋白d。所有样品经两次技术重复进行分析。
具体实施方式
本发明人已经鉴定了特定生物标志物,其可以单独或组合用于对非酒精性脂肪肝病(nafld)的进展进行诊断、预测或监测或分阶段。这些生物标志物尤其可用于nafld分阶段,以评估个体患有与nafld相关的非酒精性脂肪肝(nafl)、非酒精性脂肪性肝炎(nash)、肝纤维化和/或肝硬化。可以使用鉴定的生物标志物来评估nafld的严重性。这些标志物也在包括nafld的诊断、监测或分阶段以及随后治疗个体的方法中有用,以治疗nafld。
本发明涉及取自个体的样品中的一个或多个生物标志物的分析。通常,样品是血液样品、血清样品或血浆样品,但它可包括细胞、细胞裂解物、尿液、羊水和其他生物液体。血液样品可以是毛细血管的、静脉或动脉血液或血浆或血清样品。样品可以是纯样品或从干血斑或其他固体培养基中提取。可以使用试管(包括真空采血管)进行样品的收集,或者可以将样品印迹到固体培养基上,例如在滤纸、纤维素膜等上的干血斑(使用毛细血管血液)。在干血斑(dbs)的情况下,这可以通过用刺血针刺破他们的手指并将一滴或多滴毛细血管血液转移到滤纸、纤维素膜或等同样品支持介质上来获取,与静脉穿刺相比,这使得样品处理和样品运输更容易,同时更受患者喜欢。毛细管血液也可以收集在专用管中,例如microtainer、microvette、monovette、minivette或multivette。
个体通常是人类。个体可以显示nafld的一种或多种症状和/或可能先前已被诊断患有nafld,其中本方法用于对nafld进行监测或分阶段。可以预先使用其他参数,或者使其与本发明的方法组合使用以辅助nafld的评估。这些参数包括患者年龄、患者性别、患者体重、患者身高、体重指数(bmi)、快速体重减轻/体重增加的证据、饮食习惯、酒精摄入量、药物记录、患者运动/活动史、种族和疾病病史(包括2型糖尿病的糖尿病史、心血管疾病、肥胖症、胃分流术、多囊卵巢综合征、睡眠呼吸暂停、甲状腺机能减退、垂体机能减退和代谢综合征,所述代谢综合征通常包括以下三个因素:腰围增加、高甘油三酯血症、高血压、高空腹血糖和低密度脂蛋白(hdl)水平)。
根据本发明,一个或多个生物标志物被检测和定量,至少一个生物标志物通常选自载脂蛋白f、脂多糖结合蛋白、纤维胶凝蛋白-2、载脂蛋白d、激肽原-1、载脂蛋白m、血小板反应蛋白-1、iggfc结合蛋白、胱抑素-c、α-1-酸糖蛋白2和富含亮氨酸的α-2-糖蛋白。
下面列出了uniprot数据库中的生物标志物及其数据库登录号。本文公开的蛋白质序列参考截至2016年7月31日的uniprot序列。因此,下面是我们的生物标志物的列表,及其登录号(括号内)和替代名称(斜体字):
载脂蛋白-f(q13790)apo-f,脂质转移抑制蛋白,ltip;
载脂蛋白-m(o95445)apo-m,apom,蛋白g3a;
载脂蛋白-d(p05090)apo-d,apod;
激肽原-1(p01042)α-2-硫醇蛋白酶抑制剂、菲兹杰拉尔德因子、高分子量激肽原、hmwk,威廉姆斯-菲兹杰拉尔德-flaujeac因子
将激肽原-1裂解成以下6个链:1)激肽原-1重链,2)t-激肽;替代名称:ile-ser-bradykinin,3)缓激肽;替代名称:胰激肽i,4)赖氨酰-缓激肽,替代名称:胰激肽ii,5)激肽原-1轻链,6)低分子量生长促进因子;
纤维胶凝蛋白-2(q15485)37kda弹性蛋白结合蛋白、含胶原蛋白/纤维蛋白原结构域的蛋白2、ebp-37、纤维胶凝蛋白-b、纤维胶凝蛋白-β、hucolin、l-纤维胶凝蛋白、血清凝集素p35;
血小板反应蛋白-1(p07996);
iggfc结合蛋白(q9y6r7)fcγ结合蛋白抗原、fcγbp
胱抑素-c(p01034)胱抑素-3,γ-痕量,神经内分泌基本多肽,后γ-球蛋白;
脂多糖结合蛋白(p18428)lbp;
α-1-酸糖蛋白2(p19652)agp2,血清类黏蛋白-2,omd2;和
富含亮氨酸的α-2-糖蛋白(p02750)lrg。
根据本发明,发明人已经确定这些蛋白质的某些水平随着nafld严重性的增加而降低。特别地,载脂蛋白f、α-1-酸糖蛋白2、纤维胶凝蛋白-2和富含亮氨酸的α-2-糖蛋白均证明随着nafld严重性增加而蛋白质水平降低。相反,胱抑素c、脂多糖结合蛋白、iggfc结合蛋白和血小板反应蛋白-1显示随着nafld严重性增加而水平增加。
在本发明的一个优选方面,所述一个或多个标志物选自载脂蛋白f、载脂蛋白d、激肽原-1、纤维胶凝蛋白-2,载脂蛋白m和血小板反应蛋白-1。特别优选的生物标志物是载脂蛋白f。
载脂蛋白f随着nafld严重性的增加而显示出浓度降低。因此,监测个体该蛋白质水平的变化提供了nafld在各阶段的进展的指示。
载脂蛋白d在健康对照中表现出高水平,并且在nafld的所有阶段中始终较低。因此,该标志物可用作早期nafld生物标志物。与对照样品或参照样品/水平相比,载脂蛋白d水平降低表明nafld的严重性增加。载脂蛋白m显示出从脂肪变性(nafl)到nashf0的轻微降低,但在nashf3中的表达降低。因此,载脂蛋白m可用于确定肝纤维化的进展。激肽原-1在所有nafld阶段均显示出持续降低。
纤维胶凝蛋白-2显示在nafld阶段的降低,在纤维化阶段f3中显示其最低水平。
血小板反应蛋白-1从对照水平到脂肪变性(nafl)和nafld的所有阶段增加。
在本发明的一个优选方面,至少一个生物标志物包括载脂蛋白f、脂多糖结合蛋白和/或纤维胶凝蛋白-2。在本发明的另一个优选方面,至少一个生物标志物包括载脂蛋白f、脂多糖结合蛋白、纤维胶凝蛋白-2和/或载脂蛋白d。
在本发明的另一个优选方面,本发明提供了对至少两个,至少三个,至少四个或至少五个或更多个生物标志物的分析,从而对nafld的进展进行诊断、预测或监测或分阶段。因此,上述鉴定的生物标志物优选与一个或多个附加生物标志物组合使用。
例如,标志物的组合可用于提供对nafld更精确的分阶段。这种生物标志物可选自载脂蛋白f、脂多糖结合蛋白、纤维胶凝蛋白-2、载脂蛋白d、激肽原-1、载脂蛋白m、血小板反应蛋白-1、iggfc结合蛋白、胱抑素-c、α-1-酸糖蛋白2和富含亮氨酸的α-2-糖蛋白。根据本发明使用的标志物的组合优选包含生物标志物载脂蛋白f和一个或多个附加生物标志物,所述附加生物标志物选自脂多糖结合蛋白、纤维胶凝蛋白-2、载脂蛋白d、激肽原-1、载脂蛋白m、血小板反应蛋白-1、iggfc-结合蛋白、胱抑素-c、α-1-酸糖蛋白2和富含亮氨酸的α-2-糖蛋白。优选的组合包含载脂蛋白f和一个或多个,例如两个,三个或四个附加生物标志物,所述附加生物标志物选自脂多糖结合蛋白、纤维胶凝蛋白-2、载脂蛋白d、α-1-酸糖蛋白2和血小板反应蛋白-1。
可根据本发明使用的标志物的其他组合包括(i)选自载脂蛋白f、脂多糖结合蛋白和纤维胶凝蛋白-2的一个或多个生物标志物和选自载脂蛋白d、α-1-酸性糖蛋白2和血小板反应蛋白-1的一个或多个生物标志物组合;(ii)选自载脂蛋白f、脂多糖结合蛋白和纤维胶凝蛋白-2的一个或多个生物标志物和选自载脂蛋白d、α-1-酸糖蛋白2和血小板反应蛋白-1的一个或多个生物标志物组合。或者,可以将附加生物标志物与本发明的一个或多个生物标志物组合。
在本发明的一个优选方面,所述方法包括至少分析载脂蛋白f和脂多糖结合蛋白;载脂蛋白f和纤维胶凝蛋白-2;载脂蛋白f和载脂蛋白d;脂多糖结合蛋白和纤维胶凝蛋白-2;脂多糖结合蛋白和载脂蛋白d;载脂蛋白d和纤维胶凝蛋白-2;载脂蛋白f、脂多糖结合蛋白和纤维胶凝蛋白-2;或载脂蛋白f、载脂蛋白d、脂多糖结合蛋白和纤维胶凝蛋白-2。
本方法可用于nafld的诊断,或用于nafld的预测,例如,以确定疾病的严重性。在本发明的一个优选方面,所述方法可用于nafld的分阶段,特别是用于患有非酒精性脂肪肝(nafl),也称为脂肪变性的个体的分阶段。用于nafld早期分阶段和分阶段为nafl的优选生物标志物是载脂蛋白d。所述方法也可用于将nafld分阶段为非酒精性脂肪性肝炎(nash)。用于对nafld严重性分阶段和分阶段为nash的优选生物标志物是载脂蛋白m。所述方法还可用于对患有肝纤维化的个体进行分阶段,包括纤维化的严重性。
在本发明的另一方面,除了如上公开的一个或多个生物标志物的分析之外,本发明还提供了一个或多个其他生物标志物的分析。一个或多个其他生物标志物可以选自如下所述的根据本发明鉴定的其他生物标志物。
一个或多个其他生物标志物可包含角蛋白i型细胞骨架18,括号中为登录号;斜体为替代名称:(p05783)细胞增殖诱导基因46蛋白、细胞角蛋白-18、ck-18、角蛋白-18、k18和/或脂连蛋白(q15848)30kda脂肪细胞补体相关蛋白、脂肪细胞补体相关30kda蛋白、acrp30、脂肪细胞、c1q和含有胶原结构域的蛋白、脂肪最丰富的基因转录物1蛋白、apm-1、明胶结合蛋白。
脂连蛋白是特别优选的其他生物标志物。本文所述的结果显示脂连蛋白从对照到脂肪变性(nafl)到nash浓度降低,但在nash的纤维化阶段是恒定的。因此,其是对于nafl和进展到nash的有用的早期标志物。与对照样品或参照样品/水平相比,脂连蛋白水平降低,因此表明nafld随着其进展至非酒精性脂肪性肝炎阶段而严重性增加。
因此,本发明的方法可以包括至少分析载脂蛋白f和脂连蛋白;脂多糖结合蛋白和脂连蛋白;纤维胶凝蛋白-2和脂连蛋白;载脂蛋白d和脂连蛋白;载脂蛋白f、载脂蛋白d和脂连蛋白;载脂蛋白f、脂多糖结合蛋白和脂连蛋白;载脂蛋白f、纤维胶凝蛋白-2和脂连蛋白;脂多糖结合蛋白、纤维胶凝蛋白-2和脂连蛋白;载脂蛋白d、脂多糖结合蛋白和脂连蛋白;载脂蛋白d、纤维胶凝蛋白-2和脂连蛋白;或载脂蛋白f、脂多糖结合蛋白、纤维胶凝蛋白-2和脂连蛋白。
本发明还提供了对一个或多个蛋白质的裂解产物的评估。用于分析裂解产物的合适蛋白质包括激肽原-1、角蛋白i型细胞骨架18和血管紧张素原。通常,这些肽的裂解产物的量随着nafld的严重性而增加,使得所述裂解产物水平的监测可以用作本发明方法的一部分。
本方法还可用于监测nafld的进展,例如,在诊断患有nafld的患者中。所述方法可以以适当的间隔重复,例如每月一次、每两个月一次、每三个月一次、每六个月一次、每一年一次、每两年一次或每三年一次,以监测nafld的进展,并且特别是监测与进展到nafld不同阶段相关的生物标志物的变化。这种监测也可用于评估对于这种患者的治疗效果。
可以通过任何合适的技术(包括例如免疫测定法)评估本发明的一个或多个生物标志物。在本发明特别优选的方面,所述方法使用质谱法来评估一个或多个生物标志物。
在具体的实施方案中,使用无抗体的方法定量一个或多个生物标志物,所述无抗体的方法例如但不限于,使用质谱法的平行反应监测(prm)、选择反应监测(srm)、多反应监测(mrm)或mrm-立方(mrm3)中的多阶段片段化。
生物样品(毛细血管的/静脉/动脉血液、血清或血浆)用蛋白酶消化,所述蛋白酶例如但不限于胰蛋白酶、胰凝乳蛋白酶、arg-c、asp-n、梭菌蛋白酶、弹性蛋白酶、glu-c、lys-c、lys-n、胃蛋白酶、蛋白质肽链内切酶和葡萄球菌蛋白酶,但在特定实施方案中,酶是胰蛋白酶。在胰蛋白酶的情况下,这还包括用于更高产量消化的固定化胰蛋白酶,例如来自perfinitybiosciences的闪消(flashdigest)(也称为来自thermoscientific的智能消化(smartdigest))。这些酶的裂解特性是已知的(例如,胰蛋白酶在赖氨酸k或精氨酸r之后裂解),因此手动地或使用软件(例如skyline,pinpoint等),以在硅芯片计算机(in-silico)中消化蛋白质所得肽是确定的。通常排除短于7个氨基酸的肽,因为它们不太可能是独特的。通常排除长于25个氨基酸的肽,因为作为标准的合成肽可能是昂贵的。尽管通常选择7至25个氨基酸的肽用于分析,但不应完全排除短于7个氨基酸且长于25个氨基酸的肽。当使用胰蛋白酶时,通常选择没有错过裂解的肽,但对于错过一个或多个裂解的肽,可以被任何酶考虑。通常选择未经修饰的(例如糖基化、磷酸化等)和避免甲硫氨酸m的肽,因为该氨基酸可以被氧化或不被氧化,并且这些修饰会改变肽的质量。如果已知修饰的质量(例如糖基化、磷酸化、氧化、氨甲酰甲基化等),则不应完全排除修饰的肽。
在线数据库,例如但不限于peptideatlas和全球蛋白质组学机器数据库(gpmdb),帮助确定感兴趣的蛋白质的通常观察的肽。mrmaid可用于帮助设计基于质谱法的靶向定量分析,这通过基于来自pride数据库的实验光谱,建议监测肽和ms2离子进行。蛋白质blast用于检查所选肽的独特性。如果肽不是唯一的,则将选择生物标志物序列内的另一个肽。
在质谱分析之前,可以使用磷酸肽富集、糖肽富集,高ph反相分馏等对消化的肽进行分馏。肽可以通过反相液相色谱法、亲水相互作用液相色谱法(hilic)、离子交换色谱法、等电点聚焦等分离,但在特定实施方案中,通过使用碳-18(c-18)柱的反相液相色谱法进行分离。在非常低丰度的生物标志物的情况下,可以使用基于ph的反相分馏对样品分馏,可以使用免疫沉淀法富集生物标志物或者可以耗尽高丰度的蛋白质(使用免疫沉淀法或染料亲和力法,例如活性蓝用于消耗血清和/或血浆样品中的白蛋白)。
使用三重四极杆质谱仪进行srm/mrm。第一个四极杆过滤感兴趣的蛋白质的预选肽(ms1离子),第二个四极杆将该肽片段化,第三个四极杆过滤该肽的一个或多个片段(ms2离子)用于检测。使用混合四极杆-轨道阱质谱仪例如thermoqexactive及其变体或thermofusion及其变体进行prm。在prm中,四极杆过滤感兴趣的蛋白的预选肽(ms1离子),高能量碰撞解离(hcd)细胞片段化这种肽和轨道阱由于其高分辨率能够检测该肽的所有片段(ms2离子)。使用qtrap质谱仪进行mrm3。在mrm3中,第一个四极杆过滤感兴趣的蛋白质的预选肽(ms1离子),第二个四极杆将该肽片段化,然后碎片离子(ms2离子)在线性离子阱中分离后被捕获,然后激发以执行使用ms3离子的第二次破碎步骤,以提供更高水平的灵敏度。在具体的实施方案中,该技术包括能够使用电喷雾电离(esi)进行样品电离的ms/ms的任何串联质谱仪,但也可以使用其他电离方法进行样品电离。
碎片离子的曲线下面积(auc)可用于相对量化蛋白质水平。已知量的具有与预选肽相同序列的合成纯重标记肽可用于建立校准曲线以帮助确定蛋白质的绝对浓度。更详细地,可以使用srm、mrm、mrm3、prm等进行这些肽的检测,其中质谱仪过滤预选肽(ms1离子),使肽片段化和检测该肽片段(ms2离子)。这些ms2离子的auc用于量化生物标志物。对于绝对定量,使用已知量的合成肽,其可以是同位素标记的。通常从肽的c末端到n末端进行合成。合成循环包括:a)将c-末端氨基酸加载到固体支持物相(聚苯乙烯树脂)中。该氨基酸在n-末端受到保护,以避免不必要的反应;b)去除该氨基酸的n-末端保护基团(pg);c)活化下一个氨基酸的c-末端(n-末端带有保护基团);d)使两种氨基酸进行偶联反应;e)在b)重新开始循环或从树脂上裂解全长肽。肽可以是粗制的或具有至少70%、至少75%、至少80%、至少85%、至少90%、至少95%或至少98%的纯度。肽可以是合成肽、ignis肽、pepotec肽、aqua肽、spiketide肽、蛋白质表位标记标签(qprest)肽、微波辅助固相合成肽、由qconcat基因编码的串联标记肽等。生物样品中内源肽的检测和/或富集均可使用抗肽抗体、具有抗肽抗体的稳定同位素标准捕获(siscapa)等来实现,其中抗肽抗体针对预先确定的肽产生。除了同位素标记肽之外,生物标志物的定量还可以通过基于无标记质谱的定量(使用progenesislc-ms软件,skyline软件等)进行,或通过使用同位素标签标记生物样品中的蛋白质来实现,所述同位素标签为例如串联质谱标签(tmt)、用于相对和绝对定量的同量异位标签(itraq)、同位素编码的亲和标签(icat)等。
绝对定量可以使用来自lifetechnologies的heavypeptideignisprime自定义肽定量试剂盒进行,使用胰蛋白酶或固定化胰蛋白酶,例如来自perfinitybiosciences的闪消(也称为来自thermoscientific的智能消化),消化ignisprime肽。
使用载脂蛋白f(apo-f)作为例子描述肽选择的工作流程,并且可以对所列出的任何生物标志物进行该流程。未加工的apo-f前体具有326个氨基酸。氨基酸1-35用于信号肽,氨基酸36-164用于前肽,氨基酸用于功能性apo-f。功能性apo-f序列的硅芯片计算机消化显示在7至25个氨基酸的标准之间的4种肽:slptedcenek(m/z661.2825,2+或m/z441.1907,3+),sgvqqliqyyqdqk(m/z849.4283,2+或m/z566.6213,3+),danisqpettk(m/z602.2962,2+,m/z401.8666,3+),sydldpgagslei(m/z668.8170,2+,m/z446.2138,3+)。所有这些肽可以通过使用srm、mrm、prm、mrm3的质谱来靶向,通过靶向上述括号中所示的ms1离子进行。在danisqpettk的情况下,在其序列中的第二个苏氨酸t是o-糖基化的,因此通常不会被选为合适的肽。然而,如果蛋白质去糖基化的,则不应排除danisqpettk。
除了检测生物标志物本身之外,在一些实施方案中,本发明的方法涉及检测特定生物标志物的片段。例如,裂解一些蛋白质如角蛋白i型骨架18和激肽原-1,其中裂解水平在nafld中增加。因此,对于这些蛋白质,监测裂解产物提供了对于nafld和/或疾病的阶段的标志物。在优选的实施方案中,通过质谱法检测裂解产物。当检测裂解产物时,可以不进行初始蛋白酶消化步骤。
在角蛋白i型细胞骨架18的情况下,该蛋白质通过半胱天冬酶在完全未加工序列的氨基酸397/398之间进行裂解(即,在除去引发剂甲硫氨酸后,功能性角蛋白i型细胞骨架18的氨基酸396/397之间),并且这种裂解随着nafld而增加。胰蛋白酶肽lledgedfnlgdaldssnsmqtiqk覆盖该裂解区域,并且可以通过使用srm、mrm、prm、mrm3等的质谱法进行靶向。已知该序列中的三个丝氨酸(s)氨基酸被磷酸化并且甲硫氨酸(m)可被氧化,因此如果这四个氨基酸都经修饰和未经修饰,则应计算该肽的m/z。该肽的水平随着nafld严重性的增加而降低。此外,裂解的胰蛋白酶肽lledgedfnlgdald可以通过使用srm、mrm、prm、mrm3等的质谱法进行靶向(通过靶向m/z818.3729,2+或m/z545.9177,3+的肽进行)。该肽的水平随着nafld严重性的增加而增加。裂解的胰蛋白酶肽ssnsmqtiqk也可以通过使用srm、mrm、prm、mrm3等的质谱法进行靶向,并且还随着nafld严重性的增加而增加,尽管如前所述,如果丝氨酸(s)和甲硫氨酸(m)都经修饰和未经修饰,则应计算该肽的m/z。
发现激肽原-1是nafld的新型生物标志物。激肽原-1裂解成以下6个链,所有这些链可以是nafld的潜在生物标志物:激肽原-1重链、t-激肽、缓激肽、赖氨酰-缓激肽、激肽原-1轻链和低分子量生长促进因子。t-激肽(序列islmkrppgfspfr;m/z816.9558,2+;m/z544.9729,3+)、缓激肽(序列rppgfspfr;m/z530.7880,2+;m/z354.1944,3+)和赖氨酰-缓激肽(序列krppgfspfr;m/z594.8355,2+;m/z396.8927,3+)是短肽,其可以通过使用srm、mrm、prm、mrm3等的质谱法进行靶向。靶向这些序列而不用胰蛋白酶或其他酶预先消化样品。缓激肽通过血浆激肽释放酶从激肽原释放。上述序列中第二个脯氨酸(p)的羟基化(rpp[+16]gfspfr;m/z538.7854,2+;m/z359.5236,3+)发生在缓激肽释放之前,该缓激肽另外需要考虑ms1离子选择。
以与角蛋白i型细胞骨架18和激肽原-1类似的方式,可以选择用于裂解脂肪肝和/或纤维化的其他蛋白质的肽,其覆盖裂解区域并位于裂解区域的任一侧。例如,α2巨球蛋白和裂解/完整补体c3是具有纤维化依赖性硫酯裂解区域的蛋白质。
血红蛋白a1c(hba1c,糖化血红蛋白)是结合葡萄糖的血红蛋白的组分,并且其升高的水平表明糖尿病患者在6-8周内血糖控制不良。ii型糖尿病是nafld的风险因素,因此除了本文公开的生物标志物之外还可以测量hba1c水平。在hba1c中,葡萄糖与血红蛋白β链的n末端缬氨酸(v)连接。未加工的血红蛋白β链长度为147个氨基酸,第一个氨基酸是去除的引发剂甲硫氨酸。来自2-147的剩余氨基酸构成功能性血红蛋白β链。位置2的缬氨酸(v)氨基酸是hba1c的糖化位点。hba1c通常通过hplc在临床中测量,但也可以通过使用srm、mrm、prm、mrm3等的质谱法靶向进行分析。如果来自nafld或糖尿病患者的生物样品中的蛋白质被胰蛋白酶消化,则来自血红蛋白β链的n末端肽具有序列vhltpeek(m/z476.7585,2+;m/z318.1748,3+),其可以通过质谱法进行靶向。在m/z476.7585(2+)或m/z318.1748(3+)处该肽的存在将表明n末端缬氨酸(v)处未糖基化的血红蛋白β链,而该肽的缺失将表明血红蛋白β链在n末端缬氨酸(v)处的糖基化。糖基化肽将具有附加质量的葡萄糖(具有一个水分子的损失),其序列为v[+162.1]hltpeek(m/z557.7850,2+;m/z372.1924,3+)。这可用于评估患者的血糖控制,并用于监测ii型糖尿病,ii型糖尿病是nafld的主要危险因素。所述方法还可用于检查血红蛋白α和β链以及其他蛋白质中的其他糖基化位点。
血管紧张素原也是纤维化的生物标志物。以下肽激素源自血管紧张素原:血管紧张素-1(drvyihpfhl;m/z648.8460,2+;m/z432.8998,3+)、血管紧张素1-9(drvyihpfh;m/z592.3040,2+;m/z395.2051,3+)、血管紧张素-2(drvyihpf;m/z523.7745,2+;m/z349.5188,3+)、血管紧张素1-7(drvyihp;m/z450.2403,2+;m/z300.4960,3+)、血管紧张素1-5(drvyi;m/z333.1845,2+;m/z222.4588,3+;非独特且太短)、血管紧张素1-4(drvy;m/z276.6425,2+;m/z184.7641,3+;非独特且太短)、血管紧张素-3(rvyihpf;m/z466.2611,2+;m/z311.1765,3+)和血管紧张素-4(vyihpf;m/z388.2105,2+;m/z259.1428,3+)。血管紧张素-2是肝纤维化中已知的肝星状细胞激活剂。可以通过使用srm、mrm、prm、mrm3等的质谱法靶向这些肽。必须靶向这些序列而不用胰蛋白酶或其他酶预先消化样品。
由于来自激肽原-1和血管紧张素原的肽从对它们的处理中自然地释放,因此可以在不需要用酶(例如胰蛋白酶、胰凝乳蛋白酶等)进行裂解的情况下检测它们。通过使用色谱法、分子量截止滤光片、尺寸排阻等去除具有更高分子量的蛋白质,然后通过质谱法靶向肽,可以从生物样品中检测肽。
本发明的检测方法还可包括使用试剂,其中试剂特异性地检测感兴趣的蛋白质或肽。所述试剂可以是结合要分析的蛋白质或肽的抗体或其功能等同物(即抗肽抗体)。这些抗体可用于进行免疫测定,例如但不限于酶联免疫吸附测定(elisa)、放射免疫测定、蛋白质点印迹、蛋白质免疫印迹、比浊法、浊度测定法等。试剂盒可以进一步包含至少一种靶,其特异性用于检测可用作预测指标的基因或基因产物。
还可以使用特异性结合感兴趣的标志物的试剂通过合适的免疫测定法检测生物标志物。此类结合试剂包括免疫球蛋白和免疫球蛋白的功能等同物,其特异性结合感兴趣的生物标志物。术语“免疫球蛋白”和“抗体”在本文中可互换使用并且在其最广泛的意义上使用。因此,它们包括完整的单克隆抗体、多克隆抗体、抗体噬菌体展示(apd)、由至少两个完整抗体形成的多特异性抗体(例如双特异性抗体)和抗体片段,只要它们表现出所需的生物活性即可。apd涉及噬菌体基因工程和多轮噬菌体繁殖和抗原引导选择。
除了使用抗体来检测生物标志物之外,还可以使用抗体来富集生物样品中的生物标志物以帮助其他检测/定量方法。这包括诸如使用用于生物素化抗体的蛋白a、蛋白g、蛋白a/g或链霉亲和素/抗生物素蛋白珠的免疫沉淀技术。使用针对靶生物标志物的免疫沉淀抗体可选地使用交联剂(例如辛二酸二琥珀酰基酯(dss))交联到珠子上,以避免在洗脱中存在抗体。或者,质谱免疫测定(msia)可用于使用srm、mrm、mrm3、prm等的nafld相关的生物标志物的下游质谱分析。msia提示可具有蛋白a、蛋白g或蛋白a/g,用于捕获对于靶生物标志物的抗体。msia提示可具有链霉亲和素或抗生物素蛋白,用于捕获对于靶生物标志物的生物素化抗体。msia特别适用于非常低丰度的生物标志物,其通常在没有富集的情况下检测不到(例如角蛋白i型细胞骨架18)。
本发明进一步提供了使用对感兴趣的生物标志物特异的抗体检测生物样品中一个或多个感兴趣的生物标志物的存在和/或测量其水平的方法。具体地,用于检测生物样品中感兴趣的生物标志物的存在的方法可以包括使样品与单克隆抗体接触并检测抗体与样品中的生物标志物的结合的步骤。更具体地,可以使用包括但不限于放射性标记、酶、发色团和荧光团的化合物标记抗体以产生可检测的信号。
当与合适的对照比较时,检测对于感兴趣的蛋白质或其功能等同物的特异性抗体的特异性结合,表明生物标志物存在于样品中。合适的对照包括已知不含有感兴趣的蛋白质的样品和与对于编码的蛋白质不特异的抗体(例如抗独特型抗体)接触的样品。检测特异性抗体-抗原相互作用的多种方法是本领域已知的,并且可以用于所述方法,包括但不限于标准免疫组织学方法、免疫沉淀法、酶免疫测定和放射免疫测定法。通常,特异性抗体将被直接或间接地可检测地标记。直接标记包括放射性同位素;产物可检测的酶(例如荧光素酶、3-半乳糖苷酶等);荧光标记(例如,异硫氰酸荧光素、罗丹明,藻红蛋白等);荧光发射金属(例如112eu,或其他镧系元素,其通过金属螯合基团如edta与抗体连接);化学发光化合物(例如鲁米诺、异鲁米诺、吖啶盐等);生物发光化合物(例如萤光素、水母素(绿色荧光蛋白)等)。抗体可以连接(偶联)到不溶性载体上,例如聚苯乙烯板或珠子。间接标记包括第二抗体,其对编码的蛋白特异的抗体(“第一特异性抗体”)特异,其中第二抗体如上所述进行标记;和特异性结合对的成员,例如生物素-亲和素等。生物样品可以与固体支持物或载体(例如滤纸、硝酸纤维素膜或纤维素膜)接触并被固定,所述固体支持物或载体能够固定细胞、细胞颗粒或可溶性蛋白质。然后可以用合适的缓冲液或溶剂(例如丙酮,其溶解纤维素膜并将蛋白质沉淀在生物样品中)洗涤支持物,然后使用酶将样品中的蛋白质消化成肽,然后通过质谱法或与可检测标记的第一特异性抗体接触来检测和定量生物标志物。检测方法是本领域已知的,并且将根据可检测标记发出的信号进行选择。通常与合适的对照和与适当的标准相比较完成检测。
本发明的检测方法还可以包括使用试剂来检测nafld和跨nafld阶段中的生物标志物的翻译后的修饰的变化。这些翻译后的修饰可包括n-糖基化、o-糖基化和磷酸化。
在另一个实施方案中,本发明提供了一种确定nafld/纤维化预测的方法,包括:(a)确定从患者获得的生物样品中的蛋白质水平,所述蛋白质选自载脂蛋白f、脂多糖结合蛋白、纤维胶凝蛋白-2、载脂蛋白d、激肽原-1、载脂蛋白m、血小板反应蛋白-1、iggfc结合蛋白、胱抑素-c、α-1-酸糖蛋白2和富含亮氨酸的α-2-糖蛋白;(b)将所述(a)的水平与所述蛋白质的对照水平进行比较,以确定所述脂肪肝或纤维化的阳性或阴性诊断。
治疗方法
在根据本发明的一些情况下,描述了治疗nafld的方法。所述方法包括诊断个体的nafld,检测和定量从个体获得的生物样品中的一个或多个生物标志物,其中所述一个或多个生物标志物选自载脂蛋白f、脂多糖结合蛋白、纤维胶凝蛋白-2、载脂蛋白d、激肽原-1、载脂蛋白m、血小板反应蛋白-1、iggfc结合蛋白、胱抑素-c、α-1-酸糖蛋白2和富含亮氨酸的α-2-糖蛋白,对个体施用药剂或对其进行治疗方案,并从而治疗nafld。
该个体通常患有nafld,即已被诊断为患有nafld,或怀疑患有nafld,即表现出nafld的症状。如本文所用,术语“治疗”包括以下任何一种:预防疾病或与疾病相关的一种或多种症状;减少或预防疾病或症状的发展或进展;以及减少或消除现有疾病或症状。nafld/nash的治疗旨在减少肝脏相关和全因(特别是心血管)的发病率和死亡率。选择治疗方法需要评估肝脏疾病的严重性。可根据本发明使用的治疗策略包括(i)生活方式干预或其他体重减轻方案,目标是体重减轻>7;(ii)优化心血管危险因素的治疗,包括糖尿病患者的血糖控制,血压控制或降脂治疗。
可以用于治疗的药剂包括血管紧张素转换酶抑制剂(ace-i)/血管紧张素受体阻滞剂(arbs),其具有潜在的抗纤维化作用,和二甲双胍,其可降低肝癌风险。利拉鲁肽是可用于治疗的另一种药物,其似乎改善nash超过其对体重减轻的影响(leanstudy,armstrongetal.lancet2015)。也可以使用针对那些患有nash和更晚期纤维化(f2-3)的患者的肝特异性治疗剂(例如在3期临床试验中的那些)。实例包括奥贝胆酸、合成胆汁酸衍生物(拦截药品)、elafibranor、ppara/d激动剂(genfit)。目前有许多处于不同发展阶段的候选药物可以使用。可以在被诊断患有nafld的个体使用的进一步治疗策略是外科手术。例如,在病态肥胖患者中进行减肥手术(袖状胃切除术或roux-en-y胃旁路术)。
本文所述治疗剂的具体给药途径、给药剂量和给药方法可由医师常规确定。这些将在下面更详细地讨论。
试剂
用于本文所述治疗方法的试剂可以配制成药物组合物。除治疗活性成分外,这些组合物还可包含药学上可接受的赋形剂、载体、稀释剂、缓冲剂、稳定剂或本领域技术人员熟知的其他材料。这些材料应无毒,不应干扰活性成分的功效。药物载体或稀释剂可以是例如等渗溶液。
试剂盒
本发明进一步提供了试剂盒,其包含用于检测和定量来自个体的生物样品中的本文所述的一个或多个生物标志物的装置(例如试剂)和根据本发明的方法使用所述试剂盒的说明书。该试剂盒还可以包括关于所述方法可以在哪些个体上施用的细节。所述试剂盒通常含有与相关生物标志物特异性结合的一个或多个试剂(例如抗体)。所述试剂盒可另外包含用于测量其他实验室或临床参数的装置。使用这些试剂盒的程序可由临床实验室、实验实验室、医疗从业者或个人执行。
所述试剂盒可另外包含能够使所述方法实施的一个或多个其他试剂或仪器。此类试剂或仪器可包括以下的一个或多个:合适的缓冲液(水溶液)、同位素标记的或未标记的肽、肽校准曲线标准物、显影剂、酶、标记物、反应表面、检测手段、对照样品、标准物、说明书、解释性信息、从样品中分离相关生物标志物的方法、从个体获得样品的装置(例如容器或包含针头的仪器)或包含孔的支持物,在其上定量反应可以完成。
根据本发明鉴定的其他生物标志物
如实施例中所述,除了上述优选的生物标志物外,其中所述生物标志物通过2d-page和质谱法进行初步鉴定,然后通过在nafld中的表达更详细地表征(载脂蛋白f、激肽原-1、载脂蛋白d、载脂蛋白m、纤维胶凝蛋白-2、α-1-酸糖蛋白2、富含亮氨酸的α-2-糖蛋白、脂多糖结合蛋白、血小板反应蛋白-1、iggfc结合蛋白和胱抑素-c),本发明还提供了用于nafld其他生物标志物,其通过2d-page和质谱法初步鉴定。这些其他生物标志物列于下面。
因此,本发明还提供了一种对个体非酒精性脂肪肝病(nafld)的进展进行诊断、预测或监测或分阶段的方法,其基于检测和定量从个体获得的生物样品中的一个或多个下述其他生物标志物,从而对nafld的进展进行诊断、预测或监测或分阶段。本发明另外提供了一种对个体非酒精性脂肪肝病(nafld)的进展进行诊断、预测或监测或分阶段的方法,所述方法包括检测和定量从个体获得的生物样品中的一个或多个生物标志物,其中一个或多个生物标志物选自载脂蛋白f、脂多糖结合蛋白、纤维胶凝蛋白-2、载脂蛋白d、激肽原-1、载脂蛋白m、血小板反应蛋白-1、iggfc结合蛋白、胱抑素-c、α-1-酸糖蛋白2和富含亮氨酸的α-2-糖蛋白,并另外地检测和定量一个或多个下述其他标志物,从而对nafld的进展进行诊断、预测或监测或分阶段。
使用2d-page,除了优选的生物标志物载脂蛋白f、激肽原-1、载脂蛋白d和载脂蛋白m之外,还鉴定了以下用于nafld的其他生物标志物:鉴定为特征随nafld严重性增加的蛋白质包括抗凝血酶-iii、α-1-抗胰蛋白酶、igγ-1链c区、补体因子b、α-2-巨球蛋白、补体因子h、补体c1r亚组分、补体c4-a、间α-胰蛋白酶抑制剂重链h4、载脂蛋白a-iv和血清白蛋白。鉴定为特征随nafld严重性降低的蛋白质包括载脂蛋白c2、载脂蛋白c4、载脂蛋白m、载脂蛋白c-iii、载脂蛋白a-iv、凝聚素、蛋白质apoc4-apoc2、触珠蛋白、血清白蛋白、锌-α-2-糖蛋白、凝血酶链、转甲状腺素蛋白、谷胱甘肽过氧化物酶3、α-1-抗胰蛋白酶、α-1-抗胰凝乳蛋白酶、lmw激肽原-1、补体c3、补体c4-a、c4b结合蛋白α链、补体因子i轻链、补体c1r亚组分、igα-1链c区、igκ链c区,igγ-1链c区、igγ-2链c区、间α-胰蛋白酶抑制剂重链h3、凝血酶原、推定的延伸因子1-α样3、维生素d结合蛋白、β-2-糖蛋白1和α-2-hs-糖蛋白。
发现三种蛋白质特征从nafl到nashf0/f1强度增加,然后在nashf3中强度降低,并且在这些特征中鉴定的蛋白质包括补体c1s亚组分、补体c3、触珠蛋白、载脂蛋白a-iv、血清白蛋白、igκ链c区和载脂蛋白ai。一些蛋白质在nafld中鉴定为特征都增加和减少可能是由于蛋白质的不同片段的翻译后修饰或差异性表达,这些蛋白质包括α-1-抗胰蛋白酶、igγ-1链c区、补体c1r亚组分、补体c4-a、载脂蛋白a-iv和血清白蛋白。
使用质谱和tmt,除了优选的生物标志物纤维胶凝蛋白-2、α-1-酸糖蛋白2,富含亮氨酸的α-2-糖蛋白、脂多糖结合蛋白、血小板反应蛋白-1、iggfc结合蛋白和胱抑素-c之外,还鉴定了以下用于nafld的其他生物标志物:鉴定为随nafld严重性增加的蛋白质包括胱抑素-c(p01034)、磷脂酰肌醇-聚糖特异性磷脂酶d(p80108)、gtp酶激活rap/ran-gap结构域样蛋白3(q5vvw2)、igκ链v-i区dee(p01597)、纤维胶凝蛋白-3(o75636)、α-2-hs-糖蛋白(p02765)、肝细胞生长因子样蛋白(p26927)、碳酸酐酶1(p00915)、ig重链v-ii区wah(p01824)、igκ链v-i区mev(p01612)、血清灭菌蛋白(p27918)、igκ链v-iii区hah(p18135)、血红蛋白亚基β(p68871)、血管性血友病因子(p04275)、血红蛋白亚基α(p69905)、igκ链v-i区ni(p01613)、igκ链v-i区eu(p01598)、igα-1链c区(p01876)、sparc(p09486)、纤连蛋白(p02751)、血小板碱性蛋白(p02775)和血小板因子4(p02776)。鉴定为随nafld严重性降低的蛋白质包括妊娠区蛋白(p20742)、载脂蛋白(a)(p08519)、凝血因子xiiia链(p00488)、半乳糖凝集素-3结合蛋白(q08380)、脂连蛋白(q15848)、肌动蛋白细胞质1(p60709)、载脂蛋白a-ii(p02652)、α-2-抗纤溶酶(p08697)、肽酶抑制剂16(q6uxb8)、锌-α-2-糖蛋白(p25311)、α-1-酸糖蛋白2(p19652)、凝血因子xi(p03951)、血清淀粉样蛋白p成分(p02743)、蛋白z依赖性蛋白酶抑制剂(q9uk55)、单核细胞分化抗原cd14(p08571)、胰岛素样生长因子结合蛋白复合酸不稳定亚基(p35858)和载脂蛋白l1(o14791)。
除了本文提供的方法中的本发明的生物标志物/生物标志物组合之外,还可以分析一个或多个以下生物标志物:白和生育酚结合蛋白、丙氨酸氨基转移酶(alt)、α-1b-糖蛋白、α-1-微球蛋白、甲胎蛋白(afp)、血管紧张素2,血管紧张素原、载脂蛋白a-1、载脂蛋白c1、载脂蛋白c2、载脂蛋白e、脱唾液酸糖蛋白受体1、脱唾液酸糖蛋白受体2、天冬氨酸转氨酶(ast)、β2微球蛋白、胆红素、生物素、血液胆固醇、血糖(禁食和/或餐后)、血甘油三酯、血尿素氮(bun)、缓激肽、c反应蛋白(crp)、羧肽酶n2、c4b结合蛋白β链、cd5抗原样蛋白(cd5l)、铜蓝蛋白、几丁质酶-3样蛋白1、胶原肽酶、补体c3(包括c3dg及其在氨基酸1010-1013之间硫酯位点的裂解物)、补体因子h相关蛋白1、结缔组织生长因子、胶原蛋白iv、胶原蛋白vi、胶原蛋白xiv、72kdaiv型胶原酶、皮质类固醇结合球蛋白、肌酐、抑制因子-1、上皮细胞粘附分子、纤维蛋白原γ链、纤维连接蛋白iii型结构域蛋白5、纤维胶凝蛋白-1、全血计数、半乳糖基羟基甲基葡糖基转移酶、γ-谷氨酰转肽酶、明胶酶b、凝溶胶蛋白、磷脂酰肌醇蛋白聚糖-3,高尔基体膜蛋白1、触珠蛋白(包括ph值为5.46-5.49的β链,聚糖主要为双触角的、单的或二唾液酸化的,几乎没有任何三或四触角/唾液酸化结构,和比其他低ph的触珠蛋白亚型具有更少唾液酸和更多的单唾液酸化结构)、触珠蛋白相关蛋白、血红蛋白a1c、血红素结合蛋白、高密度脂蛋白(hdl)、透明质酸、免疫球蛋白j链、间α胰蛋白酶抑制剂(h1、h2、h5、h6)、细胞内粘附分子1、鸢尾素、层粘连蛋白亚基α/β/γ(包括层粘连蛋白p1片段),卵磷脂胆固醇酰基-转移酶、肝功能检查、低密度脂蛋白(ldl)、赖氨酰羟化酶、赖氨酸氧化酶、基质金属蛋白酶(mmp-1至mmp-28)、金属蛋白酶抑制剂(timp1、timp2、timp3、timp4)、微纤维相关蛋白4、单胺-氧化酶、n-乙酰-β-d-氨基葡萄糖苷酶、骨桥蛋白、过氧化物酶-2、磷脂酰胆碱-甾醇酰基转移酶、色素上皮衍生因子、血小板计数、血小板衍生生长因子、i型前胶原(包括n-末端前肽和c-末端前肽)、iii型前胶原(包括完整原胶原、n-末端前肽、c-末端前肽、完整前肽col1-3)、前肽col-1的球状结构域、脯氨酰羟化酶、14-3-3蛋白质ζ/δ、蛋白质ambp、凝血酶原(指数/凝血酶原时间/inr比率)、抵抗素、视黄醇结合蛋白4、sal样蛋白4、血清对氧磷酶/芳酰酯酶1、性激素结合球蛋白、snc73、人踝蛋白-1、肌腱蛋白、血小板反应蛋白-2、血小板反应蛋白-3、血小板反应蛋白-4、血小板反应蛋白-5、转铁蛋白、转化生长因子α(tgfα)、转化生长因子β-1(tgfβ-1)、原肌球蛋白(1-4)、肿瘤坏死因子(tnfα)、iv型胶原蛋白(包括nc1-片段c-末端交联结构域pivp和7s结构域/7s胶原蛋白)、vi型胶原蛋白、粗纤维调节素、血管细胞粘附分子和/或玻连蛋白。
实施例
在比较不同阶段nafld患者的血浆时建立的差异性表达的蛋白质
发明人已发现各种蛋白质在nafld患者的人血清样品中差异性表达。比较以下组:nafl、没有纤维化f0的nash,具有轻度纤维化f1的nash和具有晚期纤维化f3的nash。这一发现是通过使用两种蛋白质组学方法(二维聚丙烯酰胺凝胶电泳(2d-page)和基于tmt的质谱法)比较这些血清样品来实现的。
实施例1-二维聚丙烯酰胺凝胶电泳(2d-page)
为了鉴定用于nafld的生物标志物,使用两种基于2d-page的蛋白质组学方法分析血清样品。分析以下nafld阶段:nafl、没有纤维化f0的nash、具有轻度纤维化f1的nash和具有晚期纤维化f3的nash。
在第一种方法中,根据制造商协议,使用top12丰富蛋白质消耗旋转柱(thermoscientific,loughborough,uk)通过免疫沉淀从所有nafld样品中耗尽12种高丰度血清蛋白。耗尽的12种蛋白质是α1-酸性糖蛋白、α1-抗胰蛋白酶、α2-巨球蛋白、白蛋白、载脂蛋白a-i、载脂蛋白a-ii、纤维蛋白原、触珠蛋白、iga、igg、igm和转铁蛋白。50微克耗尽的血清蛋白在凝胶的第一维中使用7cmph3-11非线性梯度通过电荷进行分离并且然后使用4-12%(w/v)sds-page梯度在第二维中通过分子量(大小)进行分离。gangadharan等,(2007),clinchem,53,1792,描述了执行凝胶的电泳、荧光染色和扫描。
在第二种方法中,2毫克未耗尽的血清蛋白在第一维中使用ph为3-5.6非线性梯度通过电荷进行分离,然后使用9-16%(w/v)sds-page梯度在第二维中通过分子量进行分离。gangadharan等,(2012),plosone,7,e39603;gangadharan等,(2011),natureprotocolexchange,doi:10.1038/protex.2011.261andgangadharan等,(2011),jproteomeres,10,2643描述了执行凝胶的电泳、荧光染色和扫描。
实施例2-特异性图像分析和蛋白质鉴定
通过计算机辅助图像分析比较不同nafld阶段产生的二维点阵。使用progenesissamespots软件(nonlineardynamicslimited,newcastle,uk)通过计算机辅助图像分析对所有2d-page凝胶的扫描图像进行分析。图像在自动线性工作流程中处理,包括凝胶对准、斑点检测、斑点分裂和统计分析。斑点检测产生完整的数据集,因为所有凝胶含有相同数量的斑点,每个斑点与所有凝胶上的相应斑点匹配。没有遗漏值,允许应用有效的统计分析。只有差异性表达变化为1.5倍或更多不同,并且对于95%置信度具有anovap值≤0.05被认为是统计学上显著的。列表中显示的所有变化都在所有凝胶中可视化和确认。使用具有耗尽血清的ph3-11凝胶观察到总共15个差异性表达的特征。使用具有未耗尽血清的ph3-5.6凝胶观察到总共38个差异性表达的特征。总共11种蛋白质鉴定为特征随nafld严重性增加,并且35种蛋白质鉴定为特征随nafld严重性降低(即总共46种蛋白质)。差异性表达特征的实例显示在图1中。从凝胶中切除这些差异性表达的特征,用胰蛋白酶消化凝胶片中的蛋白质,并且通过质谱法分析肽以基本上鉴定生物标志物,如gangadharan等,(2007),clin.chem.,53,1792和gangadharan等,(2012),plosone,7,e39603所述。
使用针对新型生物标志物的抗体,通过sds-page和之后的蛋白质免疫印迹(westernblotting)分离nafld血清样品中的蛋白质。载脂蛋白f和激肽原-1在所有nafld阶段均显示降低。与nafld的所有阶段相比,健康对照中的载脂蛋白d更高,表明它有可能成为早期nafld标志物并且能够区分健康对照与nafl患者。载脂蛋白m水平在健康对照和nafld所有阶段(除了nashf3)似乎是恒定的,表明它是一种晚期纤维化生物标志物。这四种nafld生物标志物的蛋白质免疫印迹显示在图2中,并且这四种生物标志物被认为是通过2d-page初步鉴定的46种蛋白质的原始列表中的特别优选的生物标志物。
实施例3-基于tmt的质谱分析
分析来自以下五个阶段中的每一个的两个血清样品:1)健康个体,2)nafl,3)没有纤维化f0的nash,4)具有轻度纤维化f1的nash和5)具有晚期纤维化f3的nash。用胰蛋白酶消化这10个样品中的蛋白质,并根据制造商协议(lifetechnologies)用等压同位素标记的串联质量标签(tmt)标记胰蛋白酶肽。将具有tmt标记的肽的所有10个样品混合并使用dionexultimate3000超高效液相色谱仪和热q活化混合式四极轨道阱质谱仪通过lc-ms/ms进行分析。使用所述方法,观察到总共54种差异性表达的血清蛋白。基于相对定量tmt数据的差异性表达蛋白质的实例显示在图3中。
使用血清样品的胰蛋白酶消化物,通过prm靶向所有54种差异性表达的蛋白质,尽可能使用每种蛋白质的三种肽。该验证检查有助于确定54种潜在nafld生物标志物中哪些最有希望。在54种蛋白质中,发现实施例2中先前未鉴定的8种蛋白质是特别有希望的生物标志物(因此总共提供12种特别有希望的生物标志物,包括实施例2中列出的4种)。从8种蛋白质的列表中,纤维胶凝蛋白-2、脂连蛋白、α-1-酸糖蛋白2和富含亮氨酸的α-2-糖蛋白在跨nafld阶段均显示降低,而脂多糖结合蛋白、血小板反应蛋白-1、iggfc结合蛋白和胱抑素-c在跨nafld阶段显示增加。这8种nafld生物标志物与载脂蛋白d的prm数据如图4所示。
实施例4-nafld和/或纤维化评分量表
可以配制每种新型生物标志物的nafld和/或纤维化评分量表。确定这些生物标志物在nafld和/或肝纤维化的各个阶段的毛细血管血液、静脉血液、动脉血液、血清、血浆或其他体液中的平均浓度。在nafld中,kleiner-brunt量表0至4目前用于评估临床中的肝纤维化,其中0代表无纤维化,1-3代表纤维化的中间阶段,其严重性从轻度到中度/重度增加,4代表肝硬化(kleiner,(2005),hepatology,41,1313)。纤维化也可以根据从0到4(例如metavir,knodell)或0到6的其他类似量表进行分阶段,其中0表示无纤维化,1-5表示纤维化的中间阶段,严重性从轻度到中度/重度逐渐增加,6是肝硬化(ishak,(1995),jhepatol,22,696)。通过确定跨这些阶段的新型生物标志物的浓度范围,可以指定与kleiner-brunt或类似方法的数学评分算法,以帮助提供关于分阶段和预测的信息。来自多于一种的新型生物标志物的得分的相加结果可以提供更可靠的纤维化程度指示,而不是测量单个生物标志物。评分方法可能不一定遵循现有的评分,例如kleiner-brunt、ishak、metavir、knodell等,并且可以是新的评分量表以帮助确定nafld和/或纤维化阶段并确定是否需要治疗。
实施例5-通过质谱法定量
使用质谱法的无抗体方法可用于确定nafld和/或纤维化阶段,这通过检测和/或定量一个或多个感兴趣的生物标志物进行。生物样品(毛细血管血液、静脉血液、动脉血液、血清、血浆或其他体液)中的蛋白质通常用尿素等进行变性。可以可选的还原蛋白质(使用二硫苏糖醇,三(2-羧乙基)膦,β-巯基乙醇等)并烷基化(使用碘乙酰胺等),这些步骤通常在消化之前进行,尽管它们可以在消化后进行。用酶如胰蛋白酶、胰凝乳蛋白酶等消化蛋白质。在胰蛋白酶的情况下,这还包括用于更高产量消化的固定化胰蛋白酶,例如来自perfinitybiosciences的闪消(也称为来自thermoscientific的智能消化)。蛋白质消化可以使用溶液内消化、过滤辅助样品制备(fasp)、凝胶内消化(其中样品在进行消化前进入sds-page凝胶,所述样品可选地染色并切离用于消化,或浇注在聚丙烯酰胺凝胶块中),固定化酶消化(例如来自perfinitybiosciences的闪消或来自thermofisherscientific的智能消化)等。同位素标记的肽标准物可以在消化之前或之后掺入生物样品中,这些包括合成肽、ignis肽、pepotec肽、aqua肽、spiketide肽、蛋白质表位标记标签(qprest)肽,微波辅助固相合成肽,由qconcat基因编码的串联标记肽等。
对于不同酶(例如胰蛋白酶)的蛋白质裂解位点是已知的,因此生物标志物可以手动地或使用软件(例如skyline、pinpoint等)在硅芯片计算机消化,以帮助确定用于靶向定量的合适的肽。通常选择的肽长于7个氨基酸,短于25个氨基酸,未经修饰(例如糖基化、磷酸化等)并且不含甲硫氨酸,尽管不应完全排除该标准之外的肽。在线数据库,例如但不限于peptideatlas和全球蛋白质组学机器数据库(gpmdb),帮助确定感兴趣的蛋白质的通常观察的肽。mrmaid可用于帮助设计基于质谱法的靶向定量分析,这通过基于来自pride数据库的实验光谱,建议监测肽和ms2离子进行。蛋白质blast用于检查所选肽的独特性。如果发现肽不是唯一的,则将选择生物标志物序列内的另一个肽。
在质谱分析之前,可以使用磷酸肽富集、糖肽富集,高ph反相分馏等对消化的肽进行分馏。肽可以通过反相液相色谱法、亲水相互作用液相色谱法(hilic),离子交换色谱法,等电点聚焦等分离。
使用三重四极杆质谱仪进行srm/mrm,所述三重四极杆质谱仪具有三个四极杆,其包括诸如thermotsqquantiva,watersxevotq-s,agilent6495,brukerevoq,absciex3500,shimadzu8050等仪器。使用混合四极杆-轨道阱质谱仪例如thermoqexactive及其变体或thermofusion及其变体进行prm。使用qtrap质谱仪如absciexqtrap6500进行mrm3。碎片离子的曲线下面积(auc)可用于相对量化目标蛋白质水平。已知量的与预选肽具有相同序列的合成纯重标记肽可用于建立校准曲线以帮助确定蛋白质的绝对浓度。或者,可以使用lifetechnologies的heavypeptideignisprime自定义肽定量试剂盒进行绝对定量。
发明人还提出,任何裂解的或具有感兴趣区域的生物标志物可以通过质谱法进行靶向,这使用覆盖在质谱分析中使用的这些裂解区域或感兴趣区域的肽标准物进行。
实施例6-免疫测定
可以进行免疫测定以评估生物标志物的水平,例如酶联免疫吸附测定(elisa)、放射免疫测定、蛋白质点印迹、蛋白质免疫印迹、比浊法,浊度法等。
在elisa的情况下,可以在96孔板中进行分析。一种选择是使用非竞争性单位点结合elisa。在该分析中,在缓冲液(例如碳酸氢盐缓冲液)中制备毛细血管血液、静脉血液、动脉血液、血清、血浆或其他体液和已知浓度的抗原,将其加入到96孔板并在4℃规定时间内(例如过夜)培养。然后用溶液,例如磷酸盐缓冲盐水(pbs)和吐温(pbs-t)等洗涤所述孔,然后用含有牛血清白蛋白等的pbs溶液封闭。在培养期(例如37℃培养1小时)后,加入针对抗原(在该实施例中,感兴趣的生物标志物)的第一抗体,将板培养一段时间(例如37℃培养1小时)然后用pbs-t等洗涤。然后加入针对第一抗体动物来源的缀合第二抗体(例如辣根过氧化物酶),并将板培养一段时间(例如37℃培养1小时),然后用pbs-t等洗涤。最后,向每个孔中加入底物(例如过氧化物酶底物如2,2'-连氮基-双(3-乙基苯并噻唑啉-6-磺酸,abts),并在读板器上读取吸光度(例如对于abts在30分钟后405nm处)。
或者,可以使用夹心elisa。在这种类型的分析中,一种抗体与板孔的底部结合。加入抗原(在这种情况下是生物标志物蛋白),并且通过洗涤去除未结合的产物。然后加入第二种标记的抗体,其与抗原结合。通常用比色法定量结合的第二抗体的量。除了新型生物标志物外,本发明人提出任何裂解或具有感兴趣区域的生物标志物,然后可以应用抗体,所述抗体靶向在免疫测定中使用的这些裂解区域或感兴趣区域。
序列表
<110>牛津大学创新有限公司
<120>生物标志物
<130>n408344wo
<150>gb1614455.2
<151>2016-08-24
<160>44
<170>patentinversion3.5
<210>1
<211>11
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>apo-f肽-1
<400>1
serleuprothrgluaspcysgluasnglulys
1510
<210>2
<211>14
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>apo-f肽-2
<400>2
serglyvalglnglnleuileglntyrtyrglnaspglnlys
1510
<210>3
<211>11
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>apo-f肽-4
<220>
<221>mod_res
<222>(10)..(10)
<223>可以是o-糖基化苏氨酸
<400>3
aspalaasnileserglnprogluthrthrlys
1510
<210>4
<211>13
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>apo-f肽-3
<400>4
sertyraspleuaspproglyalaglyserleugluile
1510
<210>5
<211>25
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>胰蛋白酶的肽
<400>5
leuleugluaspglygluasppheasnleuglyaspalaleuaspser
151015
serasnsermetglnthrileglnlys
2025
<210>6
<211>15
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>裂解的胰蛋白酶的肽
<400>6
leuleugluaspglygluasppheasnleuglyaspalaleuasp
151015
<210>7
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>裂解的胰蛋白酶的肽
<400>7
serserasnsermetglnthrileglnlys
1510
<210>8
<211>14
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>t-激肽
<400>8
ileserleumetlysargproproglypheserprophearg
1510
<210>9
<211>9
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>缓激肽
<220>
<221>mod_res
<222>(3)..(3)
<223>可以是羟化脯氨酸
<400>9
argproproglypheserprophearg
15
<210>10
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>赖氨酰缓激肽
<400>10
lysargproproglypheserprophearg
1510
<210>11
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>来自血红蛋白β链的糖基化n末端肽
<220>
<221>mod_res
<222>(1)..(1)
<223>可以是糖基化的缬氨酸
<400>11
valhisleuthrprogluglulys
15
<210>12
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>血管紧张素-1
<400>12
aspargvaltyrilehisprophehisleu
1510
<210>13
<211>9
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>血管紧张素1-9
<400>13
aspargvaltyrilehisprophehis
15
<210>14
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>血管紧张素-2
<400>14
aspargvaltyrilehisprophe
15
<210>15
<211>7
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>血管紧张素1-7
<400>15
aspargvaltyrilehispro
15
<210>16
<211>5
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>血管紧张素1-5
<400>16
aspargvaltyrile
15
<210>17
<211>4
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>血管紧张素1-4
<400>17
aspargvaltyr
1
<210>18
<211>7
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>血管紧张素-3
<400>18
argvaltyrilehisprophe
15
<210>19
<211>6
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>血管紧张素-4
<400>19
valtyrilehisprophe
15
<210>20
<211>9
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4b序列1
<400>20
valaspglyservalaspphetyrarg
15
<210>21
<211>23
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4b序列2
<400>21
leuglygluphetrpleuglyasnaspasnilehisalaleuthrala
151015
glnglythrsergluleuarg
20
<210>22
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4b序列3
<400>22
asncyshisvalserasnleuasnglyarg
1510
<210>23
<211>14
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4c序列1
<400>23
ilegluaspalaasnleuileproprovalproaspasplys
1510
<210>24
<211>9
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4c序列2
<400>24
glypheleuleuleualaserleuarg
15
<210>25
<211>13
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4c序列3
<400>25
alaglythrleuaspleuserleuthrvalglnglylys
1510
<210>26
<211>15
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4d序列1
<400>26
glyaspileglygluthrglyvalproglyalagluglyproarg
151015
<210>27
<211>15
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4d序列2
<400>27
ilephetyrasnglnglnasnhistyraspglyserthrglylys
151015
<210>28
<211>23
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4d序列3
<400>28
asnglyleutyralaaspasnaspasnaspserthrphethrglyphe
151015
leuleutyrhisaspthrasn
20
<210>29
<211>13
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4e序列1
<400>29
tyraspleualaphevalvalalaserglnalathrlys
1510
<210>30
<211>12
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4e序列2
<400>30
leuaspserleuvalalaglnglnleuglnserlys
1510
<210>31
<211>14
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4e序列3
<400>31
glyalathrthrserproglyvaltyrgluleuserserarg
1510
<210>32
<211>11
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4f序列
<400>32
alaleuaspphealavalglyglutyrasnlys
1510
<210>33
<211>8
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4g序列1
<400>33
serpheargprophevalproarg
15
<210>34
<211>9
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4g序列2
<400>34
ilethrglypheleulysproglylys
15
<210>35
<211>12
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4g序列3
<400>35
valglnleutyraspleuglyleuglnilehislys
1510
<210>36
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4h序列1
<400>36
gluhisvalalahisleuleupheleuarg
1510
<210>37
<211>15
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4h序列2
<400>37
asntrpglyleuserphetyralaasplysprogluthrthrlys
151015
<210>38
<211>17
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4h序列3
<400>38
gluglnleuglygluphetyrglualaleuaspcysleucysilepro
151015
arg
<210>39
<211>11
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4i序列1
<400>39
alaleuglyhisleuaspleuserglyasnarg
1510
<210>40
<211>10
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4i序列2
<400>40
valalaalaglyalapheglnglyleuarg
1510
<210>41
<211>9
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4i序列3
<400>41
glyglnthrleuleualavalalalys
15
<210>42
<211>7
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4j序列1
<400>42
valleuasnglngluleuarg
15
<210>43
<211>13
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4j序列2
<400>43
asnproasnleuproprogluthrvalaspserleulys
1510
<210>44
<211>11
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>图4j序列3
<400>44
asnileleuthrserasnasnileaspvallys
1510
- 还没有人留言评论。精彩留言会获得点赞!