异常音检测装置、异常度计算装置、异常音生成装置、异常音检测学习装置、异常信号检测装置、异常信号检测学习装置、及它们的方法以及程序与流程
本发明涉及用于由音响信号等信号进行异常音等的异常波检测的学习技术。
背景技术:
设置在工厂等中的大型制造设备、成型设备等商业用设备,仅由于故障而运转停止,对商业带来很大麻烦。因此,需要日常性地监视其动作状况,在异常发生后马上进行应对。作为解决方案,有商业用设备的管理业者定期向现场派遣维修员,确认部件的磨损等的方法。但是,因为花费大量人工费和移动费、劳力,所以难以在全部商业用设备或工厂中实施该方法。
作为其解决手段,有在机械内部设置麦克风,日常性地监视其动作音的方法。分析其动作音,在发生了被认为是异常的声音(即,异常音)后对其探测,通过发出警报来解决它。但是,在对每个机械的种类或每个个体,设定异常音的种类或其检测方法中,比人工监视更花费成本。因此,需要自动设计以自动方式探测异常音的规则。
作为解决该问题的方法,已知基于统计的方法的异常音探测(例如,参照非专利文献1。)。基于统计的方法的异常音探测大致分为有教师异常音探测和无教师异常音探测。在有教师异常音探测中,由正常音和异常音的学习数据学习识别器,相对于此,在无教师异常音探测中,仅由正常音的学习数据学习识别器。在产业的应用中,因为收集异常音的学习数据很困难,所以在多数情况下,采用无教师异常音探测。
无教师异常音探测的学习/探测流程如图7所示。在学习中,提取由正常动作时的音数据(学习数据)得到的音响特征量。之后,由该音响特征量学习正常音模型(概率密度函数)。然后,在判定中,对于新得到的观测,提取音响特征量,以学习完的正常音模型评价负的对数似然(即,异常度)。若该值小于阈值,则判断为正常,若大于阈值则判断为异常。这即为评价观测音的正常音模型的符合的良好度。这基于以下的考虑方法,即,若观测为正常音,则应为发出与正常音的学习数据“相似的”音,若为异常,则应为发出与正常音的学习数据“不相似的”音。
为了使图7更具体化,用算式进行说明。异常音探测的问题是判定观测信号xω,τ∈cω×t正常还是异常的问题。其中,ω∈{1,...,ω}和τ∈{1,...,t}分别是频率和时间的索引。
首先,最初从观测信号提取音响特征量fτ∈rd。
fτ=f(xτ)(1)
其中,f是特征量提取函数。并且xτ是将音响特征量的提取所需要的xω,τ排列后的向量,例如以下那样设定。
xτ=(x1,τ,x2,τ,...,xω,τ)(3)
其中,t表示转置,pb,pf分别表示xτ中包含的过去和未来的帧数。例如,被设定为pb=pf=5左右。
接着,如以下那样计算异常度l(fτ)。
l(fτ)=-lnp(fτ|z=0)(4)
其中,p(fτ|z=0)是正常音模型。而且,z是若xω,τ为正常音则z=0,若为异常音则z≠0的指示符。最后,若l(fτ)的值大于阈值
其中,
现有技术文献
非专利文献
非专利文献1:井出剛,杉山将,“異常検知と変化検知,”講談社,pp.6-7,2015.
技术实现要素:
发明要解决的课题
在无教师异常探测中成为问题的是特征量提取函数f(·)的设计。在有教师异常音探测中,由人工设计可良好地识别判别对象的音响特征量。例如若得知正常音为1000hz的正弦波,异常音为2000hz的正弦波,则由于音色不同,所以对每帧提取梅尔滤波器组(melfilterbank)的对数功率(log-mfbo)。若正常音是不变的发动机音,异常音是设备之间“咯噔”碰撞那样的音,则由于异常音为突发的音,使用提取梅尔滤波器组的功率的时间差分(δmfbo)。而且,在作为有教师学习之一的“深层学习”中,也可以说可根据学习数据自动设计音响特征量。
但是,在无教师异常探测中,不知道发生具有哪样的音的特性的异常音。所以难以通过人工设计特征量提取函数,而且也难以使用深层学习。例如,由于正常音为1000hz的正弦波,所以若异常音假定为2000hz的正弦波,并将log-mfbo设为音响特征量,则不能检测设备之间“咯噔”碰撞那样的异常音。而且,反之亦然。因此,只能使用作为通用的音响特征量的梅尔滤波器组倒谱系数(mfcc)等,与有教师学习相比检测精度较差。
本发明的目的是提供与有无异常信号的学习数据无关,可生成用于异常信号检测的特征量提取函数的异常音检测学习装置、使用了该特征量提取函数的异常音检测装置、异常度计算装置、异常音生成装置、异常音检测学习装置、异常信号检测装置、异常信号检测学习装置、这些装置的方法以及程序。
用于解决课题的手段
本发明的一个方式的异常音检测装置是检测输入的输入音是否为异常音的异常音检测装置,包括:使用特征量提取函数提取输入音的音响特征量的音响特征量提取单元;使用提取的音响特征量计算输入音的异常度的异常度计算单元;根据得到的异常度和阈值判定输入音是否为异常音的判定单元,特征量提取函数基于将可包含正常音以及异常音的声音模型化后的概率分布、将正常音模型化后的概率分布、以及将输入的异常音模型化后的概率分布,使用由正常音得到的异常度设定阈值。
本发明的一个方式的异常度计算装置是为了检测输入的输入音是否为异常音,计算输入音的异常度的异常度计算装置,包括:使用特征量提取函数提取输入音的音响特征量的音响特征量提取单元;使用提取的音响特征量计算输入音的异常度的异常度计算单元,特征量提取函数基于将可包含正常音以及异常音的声音模型化后的概率分布、将正常音模型化后的概率分布、以及将输入的异常音模型化后的概率分布,使用从正常音得到的异常度设定阈值。
本发明的一个方式的异常音生成装置是根据可包含正常音以及异常音的声音,生成异常音的异常音生成装置,包括:使用将可包含正常音以及异常音的声音模型化后的概率分布、作为特征量提取函数的逆函数的特征量逆变换函数、以及阈值来生成异常音的异常音生成单元;特征量逆变换函数是基于将可包含正常音以及异常音的声音模型化后的概率分布、将正常音模型化后的概率分布、将输入的异常音模型化后的概率分布的特征量变换函数的逆变换函数,使用从正常音得到的异常度设定阈值。
本发明的一个方式的异常音检测学习装置包括:根据变分自动编码器的最佳化指标,更新输入的特征量提取函数以及特征量逆变换函数的第一函数更新单元;使用输入的特征量提取函数,根据正常音的学习数据提取正常音的音响特征量的音响特征量提取单元;使用提取的音响特征量更新正常音模型的正常音模型更新单元;使用正常音的学习数据以及输入的特征量提取函数,求与作为规定的值的伪阳性率ρ对应的阈值
本发明的一个方式的异常信号检测装置是检测输入的输入信号是否为异常信号的异常信号检测装置,包括:使用特征量提取函数提取输入信号的特征量的特征量提取单元;使用提取的特征量计算输入信号的异常度的异常度计算单元;以及根据得到的异常度和阈值,判定输入信号是否为异常信号的判定单元,特征量提取函数基于将可包含正常信号以及异常信号的信号模型化后的概率分布、将正常信号模型化后的概率分布、将输入的异常信号模型化后的概率分布,使用从正常信号得到的异常度设定阈值。
本发明的一个方式的异常信号检测学习装置包括:根据变分自动编码器的最佳化指标,更新输入的特征量提取函数以及特征量逆变换函数第一函数更新单元;使用输入的特征量提取函数,根据正常信号的学习数据提取正常信号的特征量的特征量提取单元;使用提取的特征量更新正常信号模型的正常信号模型更新单元;使用正常信号的学习数据以及输入的特征量提取函数,求与作为规定的值的伪阳性率ρ对应的阈值
发明效果
与有无异常信号的学习数据无关,可生成用于异常信号检测的特征量提取函数。而且,使用该特征量提取函数,可进行异常音检测、异常度计算、异常音生成、异常音检测学习、异常信号检测、异常信号检测学习。
附图说明
图1是用于说明异常音检测学习装置的例子的方框图。
图2是用于说明异常音检测学习方法的例子的流程图。
图3是用于说明异常音检测装置的例子的方框图。
图4是用于说明异常音检测方法的例子的流程图。
图5是用于说明特征量的提取及其分布的图形的图。
图6是用于说明学习步骤的直观的图形的图。
图7是用于说明以往技术的图。
具体实施方式
[技术背景]
(内曼皮尔森型最佳化指标)
无教师异常音探测可以将零假设(nullhypothesis)和对立假设设为以下的假设检验的一种。
零假设:xτ是由p(x|z=0)生成的样本。
对立假设:xτ不是由p(x|z=0)生成的样本。
因此,可考虑通过按照假设检验的理论将特征量提取函数最佳化,可以将异常音探测率最大化。
已知若按照内曼皮尔森的定理(例如,参照参考文献1),最强的假设检验函数是,在将伪阳性率(fpr:falsepositiverate)设为ρ的基础上,将真阳性率(tpr:truepositiverate)最大化的函数。而且,fpr和tpr可以通过以下的式子计算。伪阳性率是将正常音误检测为异常音的概率。另一方面,真阳性率是将异常音检测作为异常音的概率。也将伪阳性率或者真阳性率称为误检测率。
fpr(f,φ)=∫h(l(f(x)),φ)p(f(x),x|z=0)dx(6)
tpr(f,φ)=∫h(l(f(x)),φ)p(f(x),x|z10)dx(7)
〔参考文献1〕j.neyman,etal.,“ontheproblemofthemostefficienttestsofstatisticalhypotheses”,phi.trans.oftheroyalsociety,1933.
其中,在将fpr=ρ的阈值设为
j=tpr(f,φρ)+{ρ-fpr(f,φρ)}(8)
在考虑将该目标函数考虑对于f最大化的变分问题时,若注意ρ为与f无关的常数的事实,则最佳的特征量提取函数f可以通过以下的算式求出。
换言之,设定特征量提取函数f,使得
以下,将算式(9)的最佳化指标成为“内曼皮尔森型最佳化指标”。在以下的说明中,使用该指标说明将f最佳化的实施例。
(内曼皮尔森变分自动编码器)
使用学习数据将算式(9)变形至最佳化的形式。首先,将fpr和tpr的期待值运算置换至学习数据的算术平均。其中,t是学习数据的数。
其中,xτ和xk分别是正常音和异常音的学习数据。但是,异常音的学习数据难以收集(无教师学习)。因此,在无教师学习的情况下从p(f(x),x|z≠0)进行采样。
为了采样异常音,必须已知异常音遵从的概率分布p(f(x),x|z≠0)。但是,不知什么样的异常音鸣响的信息的情况居多,难以直接估计p(f(x),x|z≠0)。因此,考虑相比估计p(f(x),x|z≠0),估计所有音遵从的概率分布p(f(x),x)比较容易,并估计p(f(x),x)。
例如若为工厂的机械音的异常探测,则所有音是指各种工厂中收录的所有机械音。换言之,所有音是可包含正常音以及异常音的声音。更详细地,所有音是,使用异常音检测装置的环境的声音,即可包含正常音以及异常音的声音。按照贝叶斯定理,p(f(x),x)可如以下那样分解。而且,「∝」意味着比例。
这里,通过假定等级先验分布p(z)为固定,从式(12)变形至式(13)。即,通过估计p(f(x),x)和p(f(x),x|z=0),正常音以外的声音遵从的概率分布,换言之,异常音遵从的概率分布p(f(x),x|z≠0)可以通过以下的式子进行估计。
p(f(x),x|z10)∝p(f(x),x)-p(f(x),x|z=0)(14)
而且,也将异常音遵从的概率分布记述为p(f(x)|z≠0),将所有音遵从的概率分布记述为p(f(x)),将正常音遵从的概率分布记述为p(f(x)|z=0)。而且,也将“声音遵从的概率分布”表现为“将声音模型化后的概率分布”。
这样,将异常音模型化后的概率分布p(f(x)|z≠0)称为从将所有音(可包含正常音以及异常音的声音)模型化后的概率分布p(f(x))去除了将正常音模型化后的概率分布p(f(x)|z=0)的概率分布。
而且,如以下说明的那样,将该式子(14)作为前提求特征量提取函数,所以称特征量提取函数基于将所有音(可包含正常音以及异常音的声音)模型化后的概率分布p(f(x))、将正常音模型化后的概率分布p(f(x)|z=0)、将异常音模型化后的概率分布p(f(x)|z≠0)。
在图5中直观地表示了以上的理论。如图5的左边那样考虑特征量的空间时,所有音应该广泛地分布在特征量的空间中,正常音应该分布在一部分空间中。由此,异常音相当于作为在所有音的分布中概率高(例如是在真实世界中能够产生的机械音)、在正常音的分布中概率低(例如与监视对象的设备的声音不相似的机械音)的声音而生成。
在高精度地估计p(f(x),x)的方法中,有变分自动编码器(例如,参照参考文献2。)。
〔参考文献2〕d.p.kingma,andm.welling,“auto-encodingvariationalbayes”,proceedingsoftheinternationalconferenceonlearningrepresentations(iclr),2014.
在参考文献中给出详细的说明,但变分自动编码器是,准备由潜在变量(音响特征量)f=f(x)生成观测信号的函数(以下,称为“特征量逆变换函数”)
x=g(f(x))(15)
,将f和g最佳化以便将以下的目标函数最小化的方法。
其中,kl[a|b]是概率分布a和b的kl散度(divergence)。本发明中为了简单,设置为
p(f(x))=n(0,id)(17)
q(f(x)|x)=n(f(x),id)(18)
。其中,n(μ,σ)是具有平均向量μ和协方差矩阵σ的多维正态分布,id是d维单位矩阵。而且,fs是由式(18)采样的值,式(16)的第二项的概率分布通过
p(x|g(fs))=n(x|g(fs),ih)(19)
表现。由式(17)(19),为
p(f(x),x)=p(x|f(x)p(f(x)))(20)
=p(x|g(f(x))p(f(x)))(21)
。而且,若由式(1)(15),设f和g是确定性的信息变换的假定,则因p(x|g(f(x))始终为三角函数,所以成为
。因此,为了生成异常音数据,首先,通过
生成k个异常音的音响特征量fks。式(23)的“~”,意味着fks遵从概率分布p(f(x))-p(f(x)|z=0)。然后,通过
生成异常音数据xk即可。这样,至少使用将可包含正常音以及异常音的声音模型化后的概率分布p(f(x))、将正常音模型化后的概率分布p(f(x)|z=0)、以及特征量逆变换函数g生成异常音数据xk。
而且,在考虑式(14)、(23)、(24)时,也可以说对遵从将异常音模型化后的概率分布p(f(x))-p(f(x)|z=0)的音响特征量进行采样,使用采样的音响特征量fk和特征量逆变换函数g生成异常音。
由以上,可以通过交替使用式(16)的变分自动编码器的最佳化指标和式(10)的内曼皮尔森型最佳化指标,将特征量提取函数和特征量逆变换函数最佳化来实现特征量提取函数的最佳化。其中,式(10)的最佳化中使用的异常音数据通过式(23)、(24)生成。
(具体的执行例子)
在图6中表示本实施方式的执行步骤的直观的图形。本实施方式通过重复4阶段的学习步骤来实现。
首先,按照变分自动编码器的最佳化指标,学习f和g。这里,f和g例如可以用全耦合的多层感知器或多层卷积神经网络来实现。而且,在所有音中,若是机械音的异常音探测,则可以用各种工厂中收录的声音数据,也可以使用人的声音数据等。
接着,从正常音的学习数据xτ(τ∈{1,...,t})中提取音响特征量。
fτ=f(xτ)(25)
然后,由该数据学习正常音模型。在此例如可以使用混合高斯分布
等。其中,c是混合数,wc、μc、σc分别是第c个分布的混合比、平均向量、协方差矩阵。该学习例如可以使用em算法(例如,参照参考文献3)等实现。
〔参考文献3〕小西貞則,“多変量解析入門,付録cemアルゴリズム”pp.294-298,岩波書店,2010..
最后,使用事先设定的fpr即ρ,决定阈值
接着,通过式(23)(24)生成异常音数据。为了更简单地生成fks,也可以使用以下的步骤1.至3.。通过这些步骤1.至3.,可以生成按照式(23)fks。这样,可以通过将与由这些步骤1.至3.生成的按照式(23)的fks相近似的值~fks设为fks,生成按照式(23)的fks。
1.生成p(f(x))至~fks。
2.计算异常度l(~fks)。
3.异常度l(~fks)若大于
这样,异常音也可以使用将可包含正常音以及异常音的声音模型化后的概率分布p(f(x))、作为特征量提取函数的逆函数的特征量逆变换函数g、以及阈值
最后,使用式(10)的内曼皮尔森型最佳化指标,更新f。在将f实际安装在多层感知器等中的情况下,使用误差反向传播法即可。
[异常音检测学习装置以及方法]
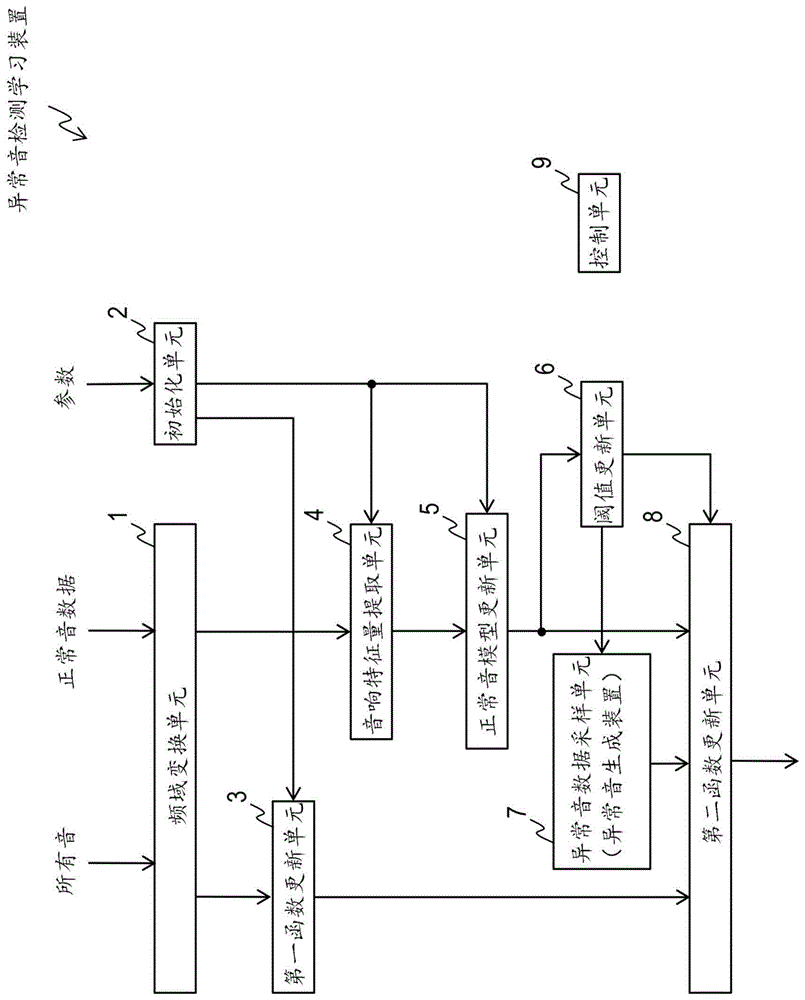
如图1中例示的那样,异常音检测学习装置包括:频域变换单元1、初始化单元2、第一函数更新单元3、音响特征量提取单元4、正常音模型更新单元5、阈值更新单元6、异常音数据采样单元7、以及第二函数更新单元8。异常音检测学习方法通过异常音检测学习装置的各单元执行图2以及以下说明的步骤s1至s9的处理来实现。
异常音数据采样单元7也是异常音生成装置。
在异常音检测学习装置中输入正常音数据和所有音数据。这些抽样频率根据要分析的声音的性质而被适当设定。例如,将抽样频率设为16khz左右。
而且,假设被设定了特征量提取函数、特征量逆变换函数以及正常音模型的参数。例如,若为多层感知器,则输入中间层的层数和隐藏单元数。正常音模型若为混合高斯分布则输入混合数。而且,例如设定为特征量的维数d=16,ρ=0.05左右即可。
<频域变换单元1>
频域变换单元1将输入的正常音的学习数据以及所有音数据分别变换为频域(步骤s1)。在变换中,可以利用短时傅里叶变换等。这时,傅里叶变换长度例如设定为512点,移位长度例如设定为256点左右即可。
变换为频域的正常音的学习数据被输入到音响特征量提取单元4。变换为频域的正常音的学习数据被输入到第一函数更新单元3。
<初始化单元2>
初始化单元2按照输入参数,将特征量提取函数、特征量逆变换函数以及正常音模型初始化(步骤s2)。
初始化后的特征量提取函数被输入到音响特征量提取单元4。初始化后的特征量提取函数以及特征量逆变换函数被输入到第一函数更新单元3。初始化后的正常音模型被输入到正常音模型更新单元5。
<第一函数更新单元3>
第一函数更新单元3例如根据式(16)的变分自动编码器的最佳化指标,更新被输入的特征量提取函数以及特征量逆变换函数(步骤s3)。换言之,在第一函数更新单元3中,特征量提取函数根据变分自动编码器的最佳化指标进行第1更新。
在该更新中,例如可以使用概率的梯度法。这时的批量大小(一次更新中使用的数据量)例如设为512左右即可。
更新后的特征量提取函数以及特征量逆变换函数被输入到第二函数更新单元8。
<音响特征量提取单元4>
音响特征量提取单元4使用输入的特征量提取函数,根据输入的正常音的学习数据提取正常音的音响特征量(步骤s4)。
提取的正常音的音响特征量被输入到正常音模型更新单元5以及第二函数更新单元8。
使用由初始化单元2初始化的特征量提取函数进行音响特征量提取单元4的第1次的处理。使用由第二函数更新单元8更新后的特征量提取函数进行音响特征量提取单元4的第2次以后的处理。
<正常音模型更新单元5>
正常音模型更新单元5使用在音响特征量提取单元4中提取的音响特征量来更新正常音模型(步骤s5)。更新后的正常音模型被输入到第二函数更新单元8。
<阈值更新单元6>
阈值更新单元6使用输入的正常音的学习数据以及输入的特征量提取函数,求与作为规定的值的伪阳性率ρ对应的阈值
求出的阈值
例如,阈值更新单元6使用正常音的全学习数据计算异常度l(f(x)),使用将其降序分类时的从上起第n个异常度作为阈值
例如,以这样的方式,使用由正常音得到的异常度设定阈值
阈值更新单元6的第1次的处理使用由初始化单元2初始化的特征量提取函数来进行。阈值更新单元6的第2次以后的处理使用由第二函数更新单元8更新后的特征量提取函数来进行。
<异常音数据采样单元7>
异常音数据采样单元7模拟生成异常音数据并进行采样(步骤s7)。采样后的异常音数据被输入到第二函数更新单元8。
例如,异常音数据采样单元7通过上述说明的步骤1.至3.,使用特征量逆变换函数和阈值
具体地说,异常音数据采样单元7通过步骤1.,生成近似了音响特征量fks的值~fks,该音响特征量fks遵从将能够包含正常音以及异常音的声音模型化后的概率分布p(f(x))。
然后,异常音数据采样单元7通过步骤2.,计算基于~fks的异常度l(~fks)。
然后,异常音数据采样单元7通过步骤3.,通过比较计算出的异常度l(~fks)和阈值
然后,异常音数据采样单元7根据式(24),计算将作为音响特征量fks接受的~fks输入到特征量逆变换函数g时的输出值。
异常音数据采样单元7例如以这样的方式,生成异常音数据。
异常音数据采样单元7也可以通过用式(23)、(24)生成异常音数据,进行异常音的采样。
而且,在异常音的学习数据存在的情况下,换言之,在有教师学习的情况下,不进行采样。即,只要将异常音的学习数据作为采样结果进行以后的处理即可。当然,也可以与采样并用。
而且,在第二函数更新单元8中,输入异常音的音响特征量作为异常音数据。因此,异常音数据采样单元7也可以进行用于提取采样的异常音的音响特征量的音响特征量提取处理。该音响特征量提取处理的第1次处理,使用通过初始化单元2初始化的特征量提取函数来进行。该音响特征量提取处理的第2次以后的处理,使用由第二函数更新单元8更新后的特征量提取函数来进行。
<第二函数更新单元8>
第二函数更新单元8使用音响特征量提取单元4中提取的正常音的音响特征量以及输入的异常音的音响特征量,根据由阈值更新单元6中求出的阈值
更新后的特征量提取函数被输入到第一函数更新单元3、音响特征量提取单元4、阈值更新单元6以及异常音数据采样单元7。在特征量逆变换函数已被更新的情况下,该更新后的特征量逆变换函数被输入到第一函数更新单元3、音响特征量提取单元4、阈值更新单元6以及异常音数据采样单元7。
而且,在控制单元9的反复控制之后,最后被更新的特征量提取函数以及正常音模型,作为异常音检测学习装置以及方法的最终的学习结果被输出。
<控制单元9>
控制单元9反复进行以由第二函数更新单元8更新的特征量提取函数作为输入的、第一函数更新单元3、音响特征量提取单元4、正常音模型更新单元5以及第二函数更新单元8、阈值更新单元6以及异常音数据采样单元7的处理。在通过第二函数更新单元8进一步更新特征量逆变换函数的情况下,控制单元9反复进行以由第二函数更新单元8更新的特征量提取函数以及特征量逆变换函数作为输入的、第一函数更新单元3、音响特征量提取单元4、正常音模型更新单元5以及第二函数更新单元8、阈值更新单元6以及异常音数据采样单元7的处理。进行这些反复处理,直至特征量提取函数以及正常音模型收敛(步骤s9)。
例如,将反复进行了处理的次数达到一定次数(例如1000次)设为第1收敛条件,控制单元9进行控制,以进行上述的反复处理,直至满足第1收敛条件。作为第1收敛判定条件,也可以使用其它条件。
[异常音检测装置以及方法]
如图3中例示的那样,异常音检测装置包括:频谱计算单元11、音响特征量提取单元12、异常度计算单元13以及判定单元14。异常音检测方法通过异常音检测装置的各单元执行图4以及以下说明的步骤s11至s14的处理来实现。
异常度计算单元13也可以是异常度计算装置。
<频谱计算单元11>
用麦克风拾音成为异常音的检测对象的机械的动作音。这时的采样率使用与学习时同样的采样率。拾音的音响信号被输入到频谱计算单元11。
与频域变换单元1同样,频谱计算单元11根据拾音的音响信号获得音响特征量(步骤s11)。得到的音响特征量被输出到音响特征量提取单元12。
<音响特征量提取单元12>
音响特征量提取单元12使用得到的音响特征量,根据通过异常音检测学习装置以及方法作为最终的学习结果而输出的特征量提取函数,提取拾音到的音响信号的音响特征量(步骤s12)。换言之,音响特征量提取单元12使用特征量提取函数提取输入音的音响特征量。
提取的音响特征量被输出到异常度计算单元13。
<异常度计算单元13>
异常度计算单元13使用提取的音响特征量、通过异常音检测学习装置以及方法作为最终的学习结果而输出的正常音模型,计算作为负的对数似然的异常度l(f(x))(步骤s13)。换言之,异常度计算单元13使用提取的音响特征量计算输入音的异常度。
计算出的异常度被输出到判定单元14。
<判定单元14>
若当前帧的异常度为阈值
阈值应与机械和环境匹配地调整,但是例如可以设定为1500左右。
而且,与声音区间判别同样,可以还使用以启发式的规则抑制判别错误的“切断(hangover)”。适用的切断处理考虑各种处理,但是应该根据异常音的误探测的种类设定切断处理。
作为其一例,有时将抑制噪音时发生的音乐噪音判定为突发的异常音。突发的撞击音等因为在频谱形状上发生100ms以上的变化的情况较多,所以┌(100/stft的帧偏移宽度)┐帧连续,异常度为阈值以上。但是,因为音乐噪音仅在该帧中产生异常的振幅频谱值,所以连续异常度为阈值以上的最多是几帧。因此,可以将异常判定的规则设定为“若连续f1帧以上异常度为阈值以上,则输出“异常”。”等。
作为其它的例子,还考虑因为异常音的音量小,所以异常度以稍微低于阈值的程度长时间持续的情况。在这样的情况下,作为用于持续的异常音的判定规则,可以追加“若最近f2帧的异常度的总和为
通过使用这样的异常音检测装置以及方法,从工厂等中设置的大型制造设备、成型设备探测异常音,能够迅速应对故障,预测故障。由此,例如对产业、特别是制造业的高效化产生贡献。
[程序以及记录介质]
在通过计算机实现异常音检测学习装置、异常音检测装置、异常度计算装置或者异常音生成装置中的各处理的情况下,异常音检测学习装置或者异常音检测装置应有的功能的处理内容通过程序记述。然后,通过在计算机中执行该程序,在计算机上实现该各处理。
记述了该处理内容的程序,可以记录在计算机可读取的记录介质中。作为计算机可读取的记录介质,例如可以是磁记录装置、光盘、光磁记录介质半导体存储器等任意介质。
而且,各处理手段既可以通过在计算机上执行规定的程序来构成,也可以硬件性地实现这些处理内容的至少一部分。
[变形例]
在异常音检测学习装置、异常音检测装置、异常度计算装置或者异常音生成装置中说明的处理,不仅按照记载的顺序时间序列地执行,也可以根据执行处理的装置的处理能力或者需要并行地或者单独地执行。
在上述中,限于声音进行了说明,但是即使对于温度传感器或加速度传感器得到的信号等其它时间序列数据,本发明也能够适用。此时,将输入的音数据变更为传感器数据即可。
即,至此说明的异常音检测学习装置、异常音检测装置以及异常音生成装置也可以分别是异常信号检测学习装置、异常信号检测装置以及异常信号生成装置。异常信号检测学习装置、异常信号检测装置以及异常信号生成装置的说明,与将此前说明的异常音检测学习装置、异常音检测装置以及异常音生成装置的说明中的“音”改读为“信号”,将“音响特征量”改读为“特征量”后的说明相同,所以这里省略重复说明。
另外,不言而喻,在不脱离本发明的宗旨的范围内能够进行适当变更。
- 还没有人留言评论。精彩留言会获得点赞!