基于加权自动编码器的马尾松苗木根部水分快速测量方法与流程
本发明涉及苗木化学物质含量测量方法技术领域,特别是涉及基于加权自动编码器的马尾松苗木根部水分快速测量方法。
背景技术
生态文明建设、现代林业建设需要数量充足、质量优良的苗木。苗木质量评价是苗木质量调控的核心问题之一,因此,精准评价苗木质量、调控苗木质量成为林业行业的关键技术问题。目前苗木质量的评价主要是依据苗高、苗冠、苗干和根系状况等形态指标,但是形态指标无法较好地反应苗木质量。生理指标能够反映苗木内在生命力的强弱,然而由于需要多种专用测试仪器,且测试过程复杂、耗时长,在实践中往往可操作性不强。苗木水分在很大程度上决定了苗木的生命活动,根系生理缺水可能损伤细胞壁,进而影响造林成活率,根系含水量低的苗木造林成活率也低,因此应用先进的技术手段实现马尾松苗木根部水分预测对生态文明建设、现代林业建设具有非常重要的意义。
目前大多较为流行的回归方法通常被看作是浅层学习模型,例如偏最小二乘回归(plsr),多元线性回归(mlr),人工神经网络(ann)和支持向量回归(svr)等,然而这些回归方法不能有效地提取光谱数据的高阶特征。
技术实现要素:
本发明所要解决的技术问题是:弥补上述现有技术的不足,提出基于加权自动编码器的马尾松苗木根部水分快速测量方法,克服传统方法无法有效提取光谱数据的高阶特征的问题,提高效率与精度,实现苗木根部水分的精准快速测量。
本发明的技术问题通过以下的技术方案予以解决:
基于加权自动编码器的马尾松苗木根部水分快速测量方法,包括以下步骤:
1)使用savitzky-golay方法对苗木近红外谱图进行平滑滤波,一阶导数消除基线漂移;
2)使用改进的可变加权堆叠自动编码器进行高阶特征提取;
3)使用两层全连接神经网络进行有监督微调并利用支持向量机回归进行水分含量的预测。
步骤2)中,改进的可变加权堆叠自动编码器被用来捕获输入数据的高级特征表示,具体包括:
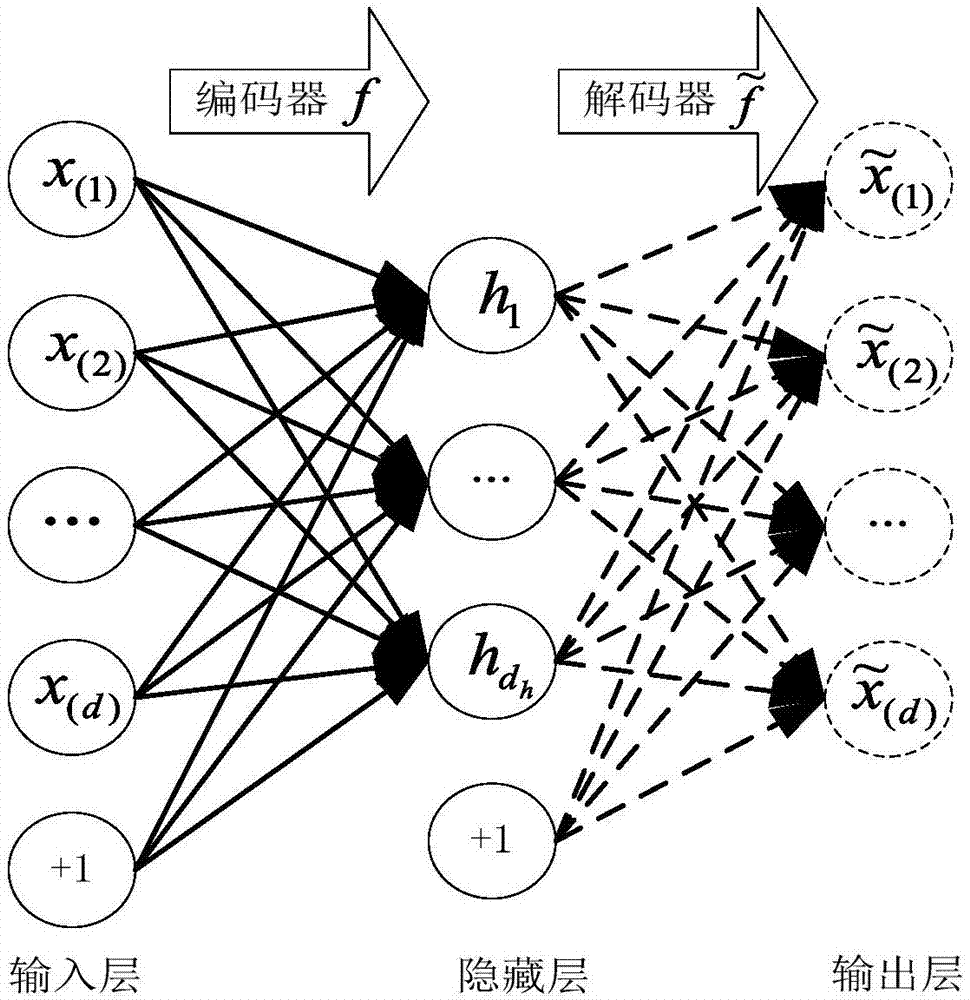
自动编码器尝试提取隐藏特征以至解码层的重构矢量近似于输入层的输入数据,假定输入数据为x=[x(1),x(2),…x(d)]′,d为输入数据的维度;编码器通过函数h=f(x)=sf(wx+b)将输入x映射到隐藏层
其中
|cc|min=min{|cc(j)|}j=1,2…d
|cc|max=max{|cc(j)|}j=1,2…d
其中
步骤3)中,所述使用全连接神经网络进行有监督微调,即在堆叠编码器最顶层之后添加神经网络,然后利用反向传播算法来更新权重以获得改进的高级功能。
步骤3)中,所述利用支持向量机回归进行水分含量的预测,支持向量机回归被用来估计基于可变加权堆叠自动编码器获得的特征表示的输出,采用优化算法寻找最佳参数构建回归模型,以获得最好的性能估计。
有益效果:与现有技术对比,本发明具有以下优势:
本发明的基于加权自动编码器的马尾松苗木根部水分快速测量方法,利用改进的堆叠自动编码器逐层提取光谱数据的高阶特征表示,并利用支持向量回归方法对苗木根部水分进行预测,克服传统方法无法有效提取光谱数据的高阶特征的问题,提高效率与精度,实现苗木根部水分的精准快速测量。另外,通过与输出变量的相关性分析,可以从每个自动编码器的输入层中的其他变量中识别出重要的变量,并给这些变量相应地分配有不同的权重,使得输出相关变量的重建更加准确。
附图说明
图1是自动编码器典型结构图;
图2是加权自动编码器结构图;
图3是苗木根部水分快速测量网络结构图;
图4是实验结果比较图。
具体实施方式
下面结合具体实施方式并对照附图对本发明做进一步详细说明。
实施例1
如图1所示,为典型的自动编码器结构图,它由编码器和解码器两部分组成,本质上都是对输入信号做某种变换。该结构把输入层数据x转换到中间层(隐层)h,再转换到输出层。图中的每个节点代表数据的一个维度,每两层之间的变换都是“线性变换”+“非线性激活函数”。假定输入数据为x=[x(1),x(2),…x(d)]′,d为输入数据的维度。编码器通过函数h=f(x)=sf(wx+b)将输入x映射到隐藏层
如图2所示,为加权自动编码器结构图,为确保整体损失函数很小,每个变量都应该非常精确,然而,并不是所有的波长变量对于近红外光谱中的输出都是同样重要的,甚至一些波长变量可能对结果具有不利影响,所以本发明采用可变权重堆叠自动编码器来克服这类问题。
假设训练数据为
如图3所示,为苗木根部水分快速测量网络结构图,测量步骤如下:
步骤1:几个可变加权自动编码器逐层叠加形成深度神经网络。这种深度神经网络可以将复杂的输入数据转换为一系列简单的高级特征,并降低输入数据的维数。首先,第一个可变加权自动编码器以无监督的方式接受训练,训练结束后,其解码器被废弃,隐藏层的输出作为第二个可变加权自动编码器的输入,剩下的编码器以相同的方式逐层训练。将训练得到的编码器的权重用来初始化深度神经网络,最顶端的隐藏层输出输入数据的基本高级特征。
步骤2:为了更好地表达输入数据,使用有监督方法来微调权重。在可变加权自动编码器最顶层之后添加神经网络,然后利用反向传播算法来更新权重。
步骤3:将改进的高阶特征作为输入数据输入到支持向量机回归中,并采用优化算法选择适当的参数以构建回归模型。
实施例2
为了进一步突出本发明的优势,对一批马尾松苗木进行了实验,方法同实施例1,将118个样本分成88个校准数据集和30个预测数据集进行,同时将实验结果与偏最小二乘回归,支持向量回归,堆叠自编码器结合人工神经网络,堆叠自编码器结合支持向量回归,以及加权堆叠自编码器结合人工神经网络方法进行了比较,结果显示如图4,图中,a偏最小二乘回归,b支持向量回归,c堆叠自编码器结合人工神经网络,d堆叠自编码器结合支持向量回归,e加权堆叠自编码器结合人工神经网络,f加权堆叠自编码器结合支持向量回归。
从图4结果可以看出,偏最小二乘回归产生的预测结果最差,是因为它的线性本质不能处理非线性相关数据。支持向量回归虽然可以处理非线性问题,但由于其不能很好地描述非线性数据,因此仅仅优于偏最小二乘回归方法。堆叠自编码器结合人工神经网络和堆叠自编码器结合支持向量回归两种方法都采用相同的网络结构,通过采用堆叠自编码器,可以在堆叠自编码器中逐层提取高级抽象特征。此外,通过在完全连接的网络中使用预先训练的权重和偏差项,这些方法可以避免较差的局部最优并加快学习过程,因此这两种方法可以比简单的偏最小二乘回归和支持向量回归更准确地描述复杂的数据结构。加权堆叠自编码器结合人工神经网络和加权堆叠自编码器结合支持向量回归这两种方法在前两种方法的基础上,通过对不同的变量赋予不同的权重,使得输出更加精确。此外,本发明中使用的小规模训练样本也可能限制了人工神经网络模型的预测能力,然而采用优化算法的支持向量回归结合加权堆叠自动编码器,在小规模训练样本中可以获得较好的性能。总体而言,本发明所提出的马尾松苗木根部水分快速测量方法优于目前研究所能及的其他方法。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下做出若干替代或明显变型,而且性能或用途相同,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!