识别方法、分类分析方法、识别装置、分类分析装置及记录介质与流程
本发明是关于对从计测系统得到的计测数据中包含的不合适数据进行识别的识别方法、对除去了该不合适数据的数据进行分类分析的分类分析方法、识别装置、分类分析装置及记录介质。
背景技术:
例如,如非专利文献1记载的那样,在纳米传感、微量计测、量子计测等先进传感设备开发领域中,用于计测微细-微量的对象的元件相继被开发。
现有技术文献
专利文献
[专利文献1]wo2013-137209号公报
【非专利文献】
【非专利文献1】「rosenstein,j.k.,wanunua,m.,merchant,c.a.,drndic,m.,andshepard,k.l.:integratednanoporesensingplatformwithsub-microsecondtemporalresolution,naturemethods,pp.487-492(2012)」
【非专利文献2】「weka3:dataminingsoftwareinjava」,machinelearninggroupattheuniversityofwaikato,internet<url:http://www.cs.waikato.ac.nz/ml/weka/>
【非专利文献3】「elkan,c.andnoto,k.:learningclassifiersfromonlypositiveandunlabeleddata,inkdd'08proceedingsofthe14thacmsigkddinternationalconferenceonknowledgediscoveryanddataminig,pp.213-220.lasvegas,nevada,usa(2008),acmnewyork,ny,usa」
【非专利文献4】「tsutsui,m.,taniguchi,m.,yokota,k.,andkawai,t.:identifyingsinglenuleotidesbytunnelingcurrent,naturenanotechnology,vol.5,pp.286-290(2010)」
技术实现要素:
发明要解决的课题
但是,上述的先进传感设备的大多,由于计测系统或计测对象为微小,所以仅输出该对象的部分的信息,输出受热噪声或量子噪声等的影响多。因此,噪声信号水平比对象信号更大的情况,即,sn比非常差这样的情况多,在一次的计测阶段中产生计测精度过低而不适合实用化这样的问题。还有,在如此的计测状况下,假设小的信号为噪声,大的信号为对象进行表示时,没有办法采用以信号强度除去噪声成分这样一般的噪声除去手法。再有,关于适用使用了对象的知识或问题固有的性质的各种噪声过滤的情况也是涉及的知识或性质为不明的情况多而难适用。特别是使用了1分子计测技术的下下世代dna测序仪中,在对象分子或计测系统的性质,由于未知的部分多且噪声信号大,因此噪声的影响成为深刻的课题。
本发明的目的是提供:从计测数据集合适当地识别不合适数据,例如,由先进传感设备的计测结果的可靠性提高有贡献的识别方法、对于计测数据能够进行高精度的分类分析的分类分析方法、识别装置、分类分析装置、识别用记录介质及分类分析用记录介质。
用于解决课题的手段
在鉴于所述课题,本发明是基于如下的见识而进行的发明,着眼于从正例集合和未知集合学习分类器的机械学习手法,例如,通过使用由适于正例/负例的2值分类的pu分类手法(classificationofpositiveandunlabeledexamples)构成了的分类器,从计测模式能够高精度识别不合适数据。pu分类手法的详细在非专利文献3中有记载。
本发明涉及的第1形态为一种识别方法,其是从在计测空间导入含有分析物的试样并检出了脉冲状信号的数据,通过电脑控制程序的执行来进行起因于分析物以外的要素并被检出了不合适数据的识别,其特征在于,
所述电脑控制程序具有使用了学习分类器的机械学习的识别处理程序,所述分类器是从正例集合的正例数据、和正例负例的任一者为不明的未知集合的未知数据进行分类正负例的分类器,
具有记录第1种数据和第2种数据的记录设备,所述第1种数据是在计测空间导入不含分析物的试样进行计测的第1计测条件之下得到的脉冲状信号的数据,所述第2种数据是在计测空间导入含有分析物的试样进行计测的第2计测条件之下得到的脉冲状信号的数据,
将所述第1种数据作为所述正例数据,将所述第2种数据作为所述未知数据,通过执行所述识别分析程序,对所述第2种数据中包含的所述不合适数据进行识别。
本发明涉及的第2形态为一种分类分析方法,其特征在于,
具有将通过第1形态涉及的识别方法识别了的不合适数据进行记录的不合适数据记录设备,
通过电脑控制程序的执行来进行分类分析,所述分类分析是从在计测空间导入含有分析物的试样并检出了脉冲状信号的数据,除去起因于分析物以外的要素并被检出了不合适数据的被分析数据的分类分析,
所述电脑控制程序具有进行使用了机械学习的分类分析的分类分析程序,
预先求出表示所述脉冲状信号的波形形态的特征的特征量,
将预先求出了的特征量作为用于所述机械学习的学习数据,将从除去了所述不合适数据的被分析数据的脉冲状信号得到的特征量作为变数,通过执行所述分类分析程序来进行关于所述分析物的分类分析。
本发明涉及的第3形态为分类分析方法,其中,
所述特征量为如下的任一者或者两者以上:
在规定的时间幅内波形的波高值;
脉冲波长ta;
从脉冲开始至脉冲峰的时间tb和ta的比tb/ta表示的峰位置比;
表示该波形的锐度的尖度;
表示从脉冲开始至脉冲峰的倾斜的俯角;
表示将波形按照每规定的时间进行了分割的时间划分面积的总和的面积;
表示从脉冲开始至脉冲峰的时间划分面积之和相对于全部波形面积的面积比;
以脉冲开始时点作为中心,将所述时间划分面积作为质量,并且将从该中心至所述时间划分面积的时间作为旋转半径进行了拟制时所确定的时间惯性力矩;
相对于所述时间惯性力矩以波高成为基准值的方式而规格化时的被规格化的时间惯性力矩;
将波形按波高方向同等分割,脉冲峰前后分别计算出在各个分割単位中的时刻值的平均值,将以同一波高位置的平均值作为矢量的成分的平均值矢量;
相对于所述平均值矢量以波长成为基准值的方式而规格化时的被规格化的平均值矢量;
将波形在波高方向同等分割,脉冲峰前后分别计算出在各个分割单位的时刻值的平均值,将以同一波高位置的平均值之差作为矢量的成分的平均值的差矢量拟制为质量分布并以波形底部的时间轴作为旋转中心时所确定的波幅平均值惯性力矩;
相对于所述波幅平均值惯性力矩以波长成为基准值的方式而规格化时的被规格化的波幅平均值惯性力矩;
将波形在波高方向同等分割,从每个分割单位的时刻值求出分散,将以该分散作为矢量的成分的分散矢量拟制为质量分布并以波形底部的时间轴作为旋转中心时所确定的波幅分散惯性力矩;以及
相对于所述波幅分散惯性力矩以波长成为基准值的方式而规格化时的被规格化的波幅分散惯性力矩。
本发明涉及的第4形态为一种识别装置,其是从在计测空间导入含有分析物的试样并检出了脉冲状信号的数据,通过电脑控制程序的执行来进行起因于分析物以外的要素并被检出了不合适数据的识别,其特征在于,
所述电脑控制程序具有使用了学习分类器的机械学习的识别处理程序,所述分类器是从正例集合的正例数据、和正例负例的任一者为不明的未知集合的未知数据进行分类正负例的分类器,
具有记录第1种数据和第2种数据的记录设备,所述第1种数据是在计测空间导入不含分析物的试样进行计测的第1计测条件之下得到的脉冲状信号的数据,所述第2种数据是在计测空间导入含有分析物的试样进行计测的第2计测条件之下得到的脉冲状信号的数据,
将所述第1种数据作为所述正例数据,将所述第2种数据作为所述未知数据,通过执行所述识别分析程序,对所述第2种数据中包含的所述不合适数据进行识别。
本发明涉及的第5形态为一种分类分析装置,其特征在于,
具有将通过第4形态涉及的识别装置识别了的不合适数据进行记录的不合适数据记录设备,
通过电脑控制程序的执行来进行分类分析,所述分类分析是从在计测空间导入含有分析物的试样并检出了脉冲状信号的数据,除去起因于分析物以外的要素并被检出了不合适数据的被分析数据的分类分析,
所述电脑控制程序具有进行使用了机械学习的分类分析的分类分析程序,
预先求出表示所述脉冲状信号的波形形态的特征的特征量,
将预先求出了的特征量作为用于所述机械学习的学习数据,将从除去了所述不合适数据的被分析数据的脉冲状信号得到的特征量作为变数,通过执行所述分类分析程序来进行关于所述分析物的分类分析。
本发明涉及的第6形态为所述特征量为如下的任一者或者两者以上:
在规定的时间幅内波形的波高值;
脉冲波长ta;
从脉冲开始至脉冲峰的时间tb和ta的比tb/ta表示的峰位置比;
表示该波形的锐度的尖度;
表示从脉冲开始至脉冲峰的倾斜的俯角;
表示将波形按照每规定的时间进行了分割的时间划分面积的总和的面积;
表示从脉冲开始至脉冲峰的时间划分面积之和相对于全部波形面积的面积比;
以脉冲开始时点作为中心,将所述时间划分面积作为质量,并且将从该中心至所述时间划分面积的时间作为旋转半径进行了拟制时所确定的时间惯性力矩;
相对于所述时间惯性力矩以波高成为基准值的方式而规格化时的被规格化的时间惯性力矩;
将波形按波高方向同等分割,脉冲峰前后分别计算出在各个分割単位中的时刻值的平均值,将以同一波高位置的平均值作为矢量的成分的平均值矢量;
相对于所述平均值矢量以波长成为基准值的方式而规格化时的被规格化的平均值矢量;
将波形在波高方向同等分割,脉冲峰前后分别计算出在各个分割单位的时刻值的平均值,将以同一波高位置的平均值之差作为矢量的成分的平均值的差矢量拟制为质量分布并以波形底部的时间轴作为旋转中心时所确定的波幅平均值惯性力矩;
相对于所述波幅平均值惯性力矩以波长成为基准值的方式而规格化时的被规格化的波幅平均值惯性力矩;
将波形在波高方向同等分割,从每个分割单位的时刻值求出分散,将以该分散作为矢量的成分的分散矢量拟制为质量分布并以波形底部的时间轴作为旋转中心时所确定的波幅分散惯性力矩;以及
相对于所述波幅分散惯性力矩以波长成为基准值的方式而规格化时的被规格化的波幅分散惯性力矩。
本发明涉及的第7形态为一种识别用记录介质,其特征在于:记录了第1形态涉及的电脑控制程序。
本发明涉及的第8形态为一种分类分析用记录介质,其特征在于:记录了第2形态涉及的电脑控制程序。
根据第1形态,其是从在计测空间导入含有分析物的试样并检出了脉冲状信号的数据,通过电脑控制程序的执行来进行起因于分析物以外的要素并被检出了不合适数据的识别的识别方法,所述电脑控制程序具有使用了学习从正例集合的正例数据、和正例负例的任一者为不明的未知集合的未知数据进行分类正负例的分类器的机械学习的识别处理程序,具有记录第1种数据和第2种数据的记录设备,所述第1种数据是在计测空间导入不含分析物的试样进行计测的第1计测条件之下得到的脉冲状信号的数据,所述第2种数据是在计测空间导入含有分析物的试样进行计测的第2计测条件之下得到的脉冲状信号的数据,将所述第1种数据作为所述正例数据,将所述第2种数据作为所述未知数据,通过执行所述识别分析程序,能够对所述第2种数据中包含的所述不合适数据进行识别。因此,本形态中,构成基于pu分类手法的分类器,能够将计测的结果得到的脉冲状信号中所含的不合适数据以高精度地识别,例如,能够对由先进传感设备的计测结果的可靠性提高有贡献。
特别是本形态中的分类器,并非使用关于对象的知识或问题固有的性质,而是能够以在过去被収集的不合适数据集合、和正负不明的实测数据集合的各数据来构成,因此具备以单纯的信号强度识别的现有手法无法实现的、优异的不合适数据的除去性能,具有对各种计测数据的解析的广泛适用可能性。
根据第2形态,其具有将通过第1形态涉及的识别方法识别了的不合适数据进行记录的不合适数据记录设备,是通过电脑控制程序的执行来进行分类分析的分类分析方法,所述分类分析是从在计测空间导入含有分析物的试样并检出了脉冲状信号的数据,除去起因于分析物以外的要素并被检出了不合适数据的被分析数据的分类分析,所述电脑控制程序具有进行使用了机械学习的分类分析的分类分析程序,预先求出表示所述脉冲状信号的波形形态的特征的特征量,将预先求出了的特征量作为用于所述机械学习的学习数据,将从除去了所述不合适数据的被分析数据的脉冲状信号得到的特征量作为变数,通过执行所述分类分析程序能够进行关于所述分析物的分类分析。因此,本形态中,通过将由基于第1形态涉及的pu分类手法的分类器来高精度地识别了的不合适数据除去了的被分析数据,能够高精度地进行关于上述分析物的分类分析。
根据第3形态,上述的各特征量是脉冲状信号的波形形态由来的特征量,通过使用这些特征量组的任一者或者2个以上的特征量,能够更高精度地进行由机械学习的分类分析。
本形态中,并不限于使用上述特征量组中的至少1个以上的特征量来进行分类分析的情况,能够使用上述特征量组中的2个以上的组合来进行分类分析。
根据第4形态,其是从在计测空间导入含有分析物的试样并检出了脉冲状信号的数据,通过电脑控制程序的执行来进行起因于分析物以外的要素并被检出了不合适数据的识别的识别装置,所述电脑控制程序具有使用了学习从正例集合的正例数据、和正例负例的任一者为不明的未知集合的未知数据进行分类正负例的分类器的机械学习的识别处理程序,具有记录第1种数据和第2种数据的记录设备,所述第1种数据是在计测空间导入不含分析物的试样进行计测的第1计测条件之下得到的脉冲状信号的数据,所述第2种数据是在计测空间导入含有分析物的试样进行计测的第2计测条件之下得到的脉冲状信号的数据,将所述第1种数据作为所述正例数据,将所述第2种数据作为所述未知数据,通过执行所述识别分析程序,能够对所述第2种数据中包含的所述不合适数据进行识别。因此,本形态中,构成基于pu分类手法的分类器,能够将计测的结果得到的脉冲状信号中所含的不合适数据高精度地识别,例如,能够提供对由先进传感设备的计测结果的可靠性提高有贡献的识别装置。
特别是本形态涉及的分类器,并非使用关于对象的知识或问题固有的性质,而是能够以在过去被収集的不合适数据集合、和正负不明的实测数据集合的各数据来构成,因此本形态具备以单纯的信号强度识别的现有手法无法实现的、优异的不合适数据的除去性能,能够实现具有对各种计测数据的解析的广泛适用可能性的识别装置。
根据第5形态,其具有将通过第4形态涉及的识别装置识别了的不合适数据进行记录的不合适数据记录设备,是通过电脑控制程序的执行来进行分类分析的分类分析装置,所述分类分析是从在计测空间导入含有分析物的试样并检出了脉冲状信号的数据,将起因于分析物以外的要素并被检出了不合适数据的被分析数据除去了的分类分析,所述电脑控制程序具有进行使用了机械学习的分类分析的分类分析程序,预先求出表示所述脉冲状信号的波形形态的特征的特征量,将预先求出了的特征量作为用于所述机械学习的学习数据,将从除去了所述不合适数据的被分析数据的脉冲状信号得到的特征量作为变数,通过执行所述分类分析程序能够进行关于所述分析物的分类分析。因此,本形态中,通过将由基于第4形态涉及的pu分类手法的分类器来高精度地识别了的不合适数据除去了的被分析数据,能够提供高精度地进行关于上述分析物的分类分析的分类分析装置。
根据第6形态,上述的各特征量是脉冲状信号的波形形态由来的特征量,通过使用这些特征量组的任一者或者2个以上的特征量,能够提供更高精度地进行由机械学习的分类分析的分类分析装置。
本形态中,并不限于使用上述特征量组中的至少1个以上的特征量来进行分类分析的情况,能够实现使用上述特征量组中的2个以上的组合来进行分类分析的分类分析装置。
根据第7形态,能够提供记录了第1形态涉及的电脑控制程序的识别用记录介质。因此,本形态涉及的记录介质具有在第1形态说明了的由所述电脑控制程序的效果,所以将在识别用记录介质中记录了的电脑控制程序装入电脑,通过使该电脑进行识别分析动作,能够进行高精度的识别分析。
根据第8形态,能够提供记录了第2形态涉及的所述电脑控制程序的分类分析用记录介质。因此,本形态涉及的记录介质具有在第2形态说明了的由所述电脑控制程序的效果,所以将在分类分析用记录介质中记录了的电脑控制程序装入电脑,通过使该电脑进行分类分析动作,能够进行高精度的分类分析。
作为第7及第8形态涉及的记录介质,能够选择软盘、磁盘、光盘、cd、mo、dvd、硬盘、移动终端等,通过电脑可读取的记录介质的任一者。
发明的效果
根据本发明,利用电脑终端,能够高精度地进行如下领域中的数据分析,使用了dna记录介质的信息压缩技术或人工碱基对的医药品创药,或者,计测试样中混入的微细的尘埃,或者体液等中所含的分析物质作为计测对象的情况,红细胞、白细胞、血小板等的微小物质等起因的不合适数据的识别-除去技术等的领域。
附图说明
【图1】模拟表示本发明涉及的实施形态中用于测定成为分析对象的计测数据的计测系统的概要图,表示通过该计测系统计测了的脉冲状信号的波形例的图。
【图2】表示通过上述计测系统对dna构成分子计测了的脉冲状信号的波形例的图。
【图3】表示作为本发明的一实施形态的分类分析装置的概略构成的概略方框图。
【图4】表示通过在上述实施形态中使用的pc1的识别-分类分析程序可执行的处理内容的概要的图。
【图5】表示由pc1的识别处理的流程图。
【图6】表示通过本发明的识别精度的验证中使用了的22种的分类器用软件的罗列的表。
【图7】表示在上述实施形态中使用的波高矢量的图。
【图8】表示在上述实施形态中使用的波长方向时间矢量的图。
【图9】用于说明pu法的学习算法的处理顺序的概要的图。
【图10】表示pu法中的主要的解析内容的图。
【图11】整理了通过pu法的分类器的处理内容的概要说明图。
【图12】表示通过上述识别处理中的pu法的2值分类器的识别处理的流程图。
【图13】表示用于验证本发明涉及的识别方法的识别精度从识别实验得到的脉冲峰波高的柱状图的图。
【图14】表示从上述识别实验得到的f-尺度(f-measure)的柱状图的图。
【图15】表示微-纳米孔设备的概略构成的概略侧断面图。
【图16】表示由pc1的分析处理的说明所必要的处理程序构成的图。
【图17】表示对实施例的大肠杆菌和枯草杆菌实测了因粒子通过所致脉冲波形例的图。
【图18】用于说明本发明涉及的各种特征量的脉冲波形图。
【图19】用于说明卡尔曼滤波器的图。
【图20】用于将卡尔曼滤波器的各因子以实际的检测电流数据进行说明的图。
【图21】表示卡尔曼滤波器的预测(8a)和更新(8b)的重复详细的图。
【图22】表示基于bl推定处理程序的bl推定处理的流程图
【图23】用于卡尔曼滤波器的因子调整的珠子模型的波形图。
【图24】将大肠杆菌22和枯草杆菌23混入在电解质溶液24中的样子以模拟表示的贯通孔12周边的扩大图。
【图25】表示相应于调整因子m、k、α的组合的从珠子模型的波形来拾取脉冲的数的表。
【图26】表示特征量提取程序的执行处理内容的概要的流程图。
【图27】表示粒子种类推定处理的流程图。
【图28】表示关于一个波形数据的各特征量(15a),和在大肠杆菌和枯草杆菌的粒子种类中概率密度函数的方案图(15b)的图。
【图29】由大肠杆菌和枯草杆菌的粒子种类的各个获得的概率密度分布的重合的方案图。
【图30】表示k个的粒子类别的粒子总数、粒子类别的出现概率、和数据整体的出现频度的期待值的关系的方案图。
【图31】用于说明通过拉格朗日未定乘数法(lagrangeundeterminedmultipliermethod)进行最佳化带有约束的对数似然(logarithmiclikelihood)最大化式的导出过程的图。
【图32】表示数据文件制作处理的流程图。
【图33】表示概率密度函数的推定处理的流程图。
【图34】表示粒子数的推定处理的流程图。
【图35】表示由哈苏迭代法(hasselbladiterativemethod)的粒子数推定处理的流程图。
【图36】表示由em算法的处理顺序的流程图。
【图37】表示通过本实施形态涉及的个数分析机能分析了的结果的一例的图。
【图38】表示作为特征量使用脉冲波长、波高的验证例,和作为特征量使用脉冲波长、峰位置比的验证例的各推定结果数据的表。
【图39】表示作为特征量使用峰付近波形的扩大、脉冲波长的验证例,和作为特征量使用峰付近波形的扩大、波高的验证例的各推定结果数据的表。
【图40】表示在作为特征量使用尖度、和脉冲波高的情况中的个数推定结果的图。
【图41】表示基于bl推定处理程的bl推定处理的流程图。
【图42】表示在大肠杆菌和枯草杆菌各自以混合比1:10、2:10、3:10、35:100的情况中各个数推定结果的柱状图。
【图43】表示在大肠杆菌和枯草杆菌各自以混合比4:10、45:100、1:2的情况中各个数推定结果的柱状图。
【图44】将在作为特征量使用了脉冲波长、脉冲波高的情况中各粒子的散布状态合成了的图。
【图45】将在作为特征量使用了峰付近波形的扩大、脉冲波长的情况,作为特征量使用了峰付近波形的扩大、峰位置比的情况,使用了峰付近波形的扩大、脉冲波高的情况中各粒子的散布状态合成了的图。
【图46】表示使用微-纳米孔设备8,3种粒子33a、33b、33c通过贯通孔12所获得的检出信号的波形例,和基于特征量所获得的概率密度函数的导出例的图。
【图47】用于说明俯角以及面积的特征量的脉冲波形图。
【图48】用于说明波高矢量的取得方法的图。
【图49】用于说明d次元的波高矢量和数据抽样的关系的图。
【图50】用于说明关于时间(波长)以及波幅的第2类型的特征量的脉冲波形图。
【图51】用于说明dw次元的波幅矢量和数据抽样的关系的图。
【图52】用于说明关于波幅的惯性力矩通过波幅矢量取得的取得过程的图。
【图53】用于说明在多个方向分割了的情况的特征量制作用波形矢量的一例的图。
【图54】表示特征量提取的处理内容的流程图。
【图55】以1mhz、500khz抽样时的关于各特征量组合的推定评价表。
【图56】以250khz、125khz抽样时的关于各特征量组合的推定评价表。
【图57】以63khz、32khz抽样时的关于各特征量组合的推定评价表。
【图58】以16khz、8khz抽样时的关于各特征量组合的推定评价表。
【图59】以4khz抽样时的关于各特征量组合的推定评价表。
【图60】与相对于全部抽样数据的关于各特征量组合的推定评价表。
【图61】以1mhz~125khz高密度抽样时的关于各特征量组合的推定评价表。
【图62】以63khz~4khz低密度抽样时的关于各特征量组合的推定评价表。
【图63】在使用全部抽样数据时(50a)以及以高密度抽样时(50b)高的个数推定精度所获得的关于上位5种特征量的组合的抽样频率数-加重平均相对误差(平均值)的图。
【图64】以低密度抽样时高的个数推定精度所获得的关于上位5种的特征量的组合的抽样频率数-加重平均相对误差(平均值)的图(51a),和使用全部抽样数据时的关于4种类特征量的组合的抽样频率数-加重平均相对误差(平均值)的图(51b)。
【图65】表示相对于4种类的各特征量的组合,特征量制作所需的计算时间和由hasselblad法的迭代计算所需的计算时间的总计计算时间的抽样频率数(khz)-所需计算时间(秒)的图(52a),和表示对于各特征量组合的特征量制作所需的计算时间抽样频率数(khz)-所需计算时间(秒)的图(52b)。
【图66】表示相对于4种类的各特征量的组合,由hasselblad法的迭代计算所需的计算时间的抽样频率数-所需计算时间(秒)的图。
【图67】用于说明本发明涉及的分类分析方法的概要的概要图。
【图68】表示本实施形态中的主要控制处理的图。
【图69】表示本实施形态中的分类分析处理的流程图。
【图70】表示通过分类分析处理的验证的评价结果、和该验证中的分析试样的详细的表。
【图71】f-尺度(f-measure)的说明图。
具体实施方式
本发明的一实施形态涉及的分类分析装置参照附图说明如下。在本实施形态中,作为分析物的一例以分类分析dna构成分子的碱基种类分析形态予以说明。
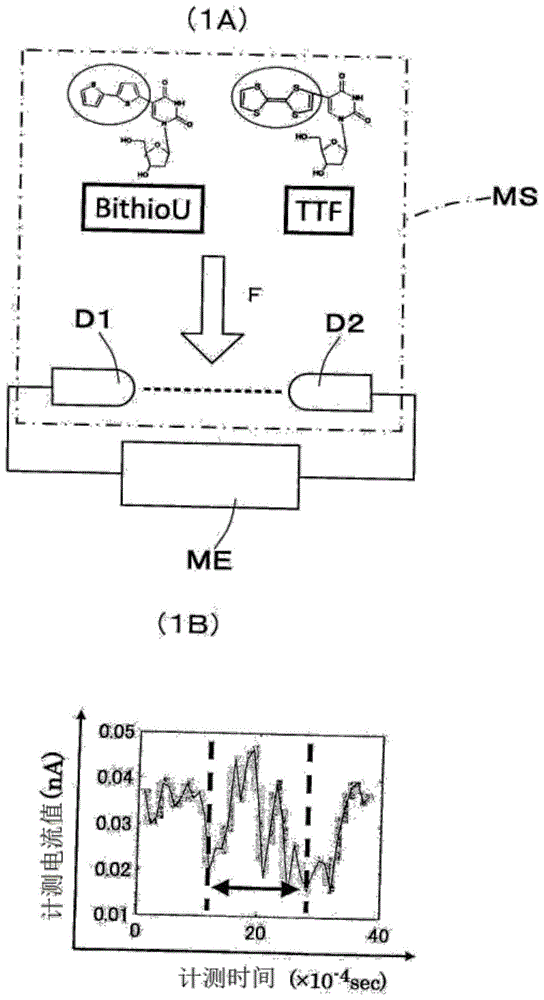
图1的(1a)是模拟表示本实施形态中用于测定成为分析对象的计测数据的计测系统的概要图
计测系统具有以収容包含碱基分子的溶液的収容容器构成的计测空间ms、和在计测空间ms内相向而配置的1对的微细形状的电极d1、d2。电极d1、d2是以金(au)元素来形成的纳米间隙电极,相互间隔微细距离而配设。微细距离是以约1nm来形成的。在计测空间ms,测定试样是包含溶媒(纯水)、和在溶媒混入了dna构成分子的溶液样本。
如非专利文献4记载的那样,纳米间隙电极是作为下下世代dna测序仪而被期待的元件。此电极是使用被称为机械的破断接合的手法来制作的具有极微细隙间的电极间隙。对此电极间隙施加一定的电压时,物质通过间隙付近之际由量子力学的隧道效果的电流(隧道电流:参照图1的虚线)流动。此隧道电流作为物质通过瞬间的脉冲电流由电流计测器me来计测。通过计测由此纳米间隙电极的隧道电流脉冲,使dna碱基分子的种类以1分子单位进行识别成为可能,使在已存技术中变成困难的肽的氨基酸配列或疾病标识的修饰氨基分子的识别等成为可能。图1的测定系统中,使用具有约1nm的电极间隙的纳米间隙电极(d1、d2),计测通过了电极付近的1分子流动的隧道电流脉冲而检出了脉冲状信号的数据作为分析对象。
在被计测分子中,使用了人工核酸碱基的二噻吩尿嘧啶衍生物(以下,简称bithiou)和ttf尿嘧啶衍生物(以下,简称ttf)的2种类。这些分子是为了容易识别而进行了化学修饰的后天部位(dna甲基化等发生的后天修饰部位)的分子。如箭头f所示,使dna分子通过间隙付近的驱动力源,在分子自体的布朗运动之外,能够使用由电泳动、电浸透流、介电泳动导致的运动。
图1的(1b)及图2,表示通过图1的计测系统计测了的脉冲状信号的波形例。这些图中,横轴表示计测时间(×10-4sec),纵轴表示计测电流值(na)。
如(1b)所示,脉冲状信号的脉冲判定部分是计测波形中央的1/3的部分,此脉冲波形数据在被分析数据中使用。
(2a)的2a1、2a2,表示检出了碱基分子bithiou时的波形例。(2b)的2b1、2b2,表示检出了碱基分子ttf时的波形例。(2a)的2a3、2a4及(2b)的2b3、2b4,表示检出了碱基分子时混在的噪声波形例。
图1的计测系统中,dna的1碱基分子作为电流脉冲进行计测并检出。被计测的脉冲中,不仅包含碱基分子由来的脉冲,还包含由电极表面的金属原子的摇动或者杂质导致的电流脉冲(图2的(2a)的2a3、2a4及(2b)的2b3、2b4参照)。由于这些噪声脉冲,看漏本来是碱基由来的脉冲,或者相反噪声脉冲的碱基分子脉冲被计测而致误判的可能性会发生,作为计测结果,dna碱基分子的识别变得困难。本发明是从被计测的脉冲的波形数据集合适当地识别、除去噪声脉冲的不适合数据,使高精度地进行碱基种类的分类分析变成可能。
图3表示本实施形态的分类分析装置的概略构成。此分类分析装置是通过个人电脑(以下,以pc称之)1所构成,pc1中具有cpu2、rom3、ram4以及数据文件记录部5。rom3中收纳有本发明涉及的电脑控制程序。在电脑控制程序中,包括用于进行使用了机械学习的不合适数据的识别处理及分类分析的识别-分类分析程序及识别-分类分析所必要的特征量的制作用程序等的各种处理程序。分类分析程序等的各种处理程序是将记录了各程序的记录介质(cd、dvd等)进行装入并存储可能。pc1中接通有可输入输出的键盘等的输入设备6以及液晶表示器等的显示设备7。数据文件记录部5中可收纳分析用数据。
pc1具备不合适数据的识别处理机能及分类分析处理机能,而在本发明中,识别处理机能及分类分析处理机能能够分别各自以具备的专用末端来构成。
图4表示通过pc1的识别-分类分析程序(电脑控制程序)可执行的处理内容的概要。图5是pc1的识别处理的流程图。
pc1的识别处理是基于以下的识别方法通过处理顺序来进行。识别-分类分析程序中,有基于使用了学习分类器的机械学习的pu手法的识别处理程序被收纳,所述分类器是从正例集合的正例数据、和正例负例的任一者为不明的未知集合的未知数据进行分类正负例的分类器。
(处理1-1)将在计测空间ms导入不含分析物(dna构成分子)的试样(仅溶媒)进行计测的第1计测条件之下得到的脉冲状信号的第1种数据读入记录设备的ram4而被记录。
(处理1-2)将在计测空间ms导入含有分析物(dna构成分子)的试样(溶媒+dna构成分子)进行计测的第2计测条件之下得到的脉冲状信号的第2种数据读入记录设备的ram4而被记录。
(处理1-3)为了与识别处理程序的输入形式吻合,制作第1种数据及第2种数据的属性矢量。
(处理1-4)将第1种数据作为正例数据,将第2种数据作为未知数据,执行识别处理程序。
(处理1-5)通过识别处理程序的执行,提取概率p(s=1|x)而求出。该概率数据是在ram4的规定区域中被记录、保存。另外,由以下的pu法的解析中被使用的属性矢量是由多次元数据来的,以矢量表述的,在以下的说明中,特别省略矢量符号。
(处理1-6)通过该概率,检出、识别在第2种数据所含的、起因于分析物以外的要素(不仅是前述的碱基分子由来的,还有电极表面的金属原子的摇动或者杂质)而被检出的不合适数据。检出了的不合适数据是在ram4的规定区域被记录、保存。
对于识别处理程序,能够使用在非专利文献2公开的、机械学习platformfreewareweka的分类器用软件。
图6是由本发明的识别精度的验证中使用了22种的分类器用软件的罗列。作为识别处理程序,22种的任一者都是使用可能的,在ram3中变成收纳可能的。pu法中的p(s=1|x)的计算时,对于由pu法的噪声数据除去后的识别处理的任一者都使用weka的程序进行了验证。
计测了的脉冲波形数据,由于不管波长还是波高都是各式各样,因此为了通过机械学习分类器来识别碱基种类,有次元整合了的属性矢量作为输入而使用的必要,在机械学习处理程序的执行之际,作为与输入形式吻合的预处理,实施一种的粗视化,制作反映了脉冲波形的属性矢量的预处理在(处理1-1)及(处理1-2)中进行。
计测了的脉冲波形数据,由于不管波长还是波高都是各式各样,因此为了通过机械学习分类器来识别碱基种类,有次元整合了的属性矢量作为输入而使用的必要,在识别处理程序的执行之际,作为与输入形式吻合的预处理,实施一种的粗视化,制作反映了脉冲波形的属性矢量的预处理在(处理1-3)中进行。
图7表示波高矢量。图8表示波长方向时间矢量。
如图7所示,关于计测脉冲波形,在波长方向进行dh分割,在每个分割区部分计算计测电流值的平均值,将此作为成分的dh次元的属性矢量作为波高矢量。对此属性矢量,制作在波高方向规格化了的和不规格化的2种类。
如图8所示,脉冲的峰前后将计测电流值分成2个组,在波高方向进行dw分割时,脉冲的计测电流值被分割成2dw的组。此每分割区部分算出从脉冲开始时点的步骤数的平均值,制作这些值作为成分持有2dw次元的波长方向时间矢量。还有,实施了从脉冲开始时点到结束时点的时间作为「1」规格化的规格化波长方向时间矢量也被制作。以上的波高矢量和波长方向时间矢量之外,仅是连结了这些的属性矢量也被制作。这些矢量数据在ram4的规定区域被记录。
为了构成本实施形态中2值分类器,使用波高和波长的2个特征量。验证本实施形态涉及的不合适数据的识别精度的验证实验中,从1个的脉冲波形数据制作了的、使用下记的v1~v8的8样的属性矢量进行了验证。
(v1)将脉冲峰值规格化为「1」的波高矢量(hvnrmd)
(v2)不规格化的波高矢量(hvraw)
(v3)将脉冲波长时间规格化为「1」的波长方向时间矢量(wvnrmd)
(v4)不规格化的波长方向时间矢量(wvraw)
(v5)连结了v1和v2的(dh+2dw)次元矢量
(v6)连结了v1和v4的(dh+2dw)次元矢量
(v7)连结了v2和v3的(dh+2dw)次元矢量
(v8)连结了v2和v4的(dh+2dw)次元矢量
验证实验中,制作上述8样的属性矢量,进行这些识别精度的比较。属性矢量制作时的分割数是进行了预备解析的,一律为dh=10,dw=5。
通常的2值分类器的情况,从正例和负例赋予的数据进行学习,分类器被生成。对此,本实施形态中,由于在计测数据混在不合适数据的情况,因此使用由pu法的分类器。本实施形态中使用的pu法,如非专利文献3详述的那样,是从正例和无标识数据进行学习,用于正例/负例的2值分类的半教师学习算法的一种。在rom3收纳了pu法的学习算法的处理顺序的概要如以下的那样。
图9是用于说明pu法的学习算法的处理顺序的概要的图。同图(9a)表示在学习中使用的变数及标识记,(9b)是表示(9a)的前提条件的详细。图10是表示pu法中的主要解析内容的图。图11在以下进行说明,是将由pu法的分类器的处理内容归纳了的概要说明图。图11中,将正例集合、负例集合分别作为p、n,在p中,包含带标识部分集合l和无标识部分集合u,在n中仅包含u。
将事例x(输入数据)作为关于脉冲波形的属性矢量,将y作为其级标识,将在事例中表示是否带级标识的记作为s。输入事例的集合之中,仅正例(y=1)的一部分被标识(s=1),其它的正例和全部的负例(y=0)没被标识(s=0)。即,样本为负例的话,被标识的概率为零,p(s=1|x,y=0)=0。将如此的事例集合作为2值分类器的学习算法的输入,能够求出样本被标识的概率g(x)=p(s=1|x)。再有,本来想求的由于不是g(x),而是p(y=1|x),所以使用以下的补正,p(y=1|x)被提取。
全部事例集合中,样本被标识的概率,g(x)=p(s=1|x),通过图10的(10a)所示的导出过程,导出g(x)=p(y=1|x)p(s=1|y=1)的关系式。当c=p(s=1|y=1)时,样本为正例的概率,赋予p(y=1|x)=g(x)/c。
在此,正事例集合中带标识的概率为均匀随机,即不根据x而假定p(s=1|y=1,x)=p(s=1|y=1)=c为一定值。这是由于操作的计测数据并非有意地偏在的任意的数据所致。
在此,c如以下那样进行推定是可能的。正事例集合中,均匀随机地带着标识的话,g(x)与x为正例的情况下正例中所含的带标识事例集合的比率一致,成为g(x)=p(s=1|y=1)=c。因此,使用不根据pu法的通常的2值分类器来求出的g(x),作为正事例的带标识事例集合l中的平均(c在下式的数1)能够推定c。
【数1】
图12是表示(处理1-5)中的由pu法的2值分类器的识别处理。
处理p1-1中,学习g(x)通过数据集合进行学习的处理。其次,处理p1-2中,基于数1对c通过验证用数据集合进行推定的处理。处理p1-3中,通过从g(y=1|x)=g(x)/c的关系确定了的g(y=1|x)进行相对于测试数据的正例/负例的识别的处理在进行。此情况的判断基准,能够设g(y=1|x)>0.5。
本发明,在图11所示由pu法的分类器的构成中,能够提取无标识事例为正例的概率。在以下,说明提取无标识事例为正例的概率的提取顺序。
带标识事例为全部正例,但无标识事例为正例、负例的任一者的可能性也有。无标识事例为正例的概率作为w(x)时,其负例的概率为1-w(x)。因此,将无标识事例全部复制2倍,一方作为正例进行操作,另一方作为负例进行操作。对作为正例进行操作的无标识事例x赋予加重w(x),对作为负例进行操作的无标识事例x赋予加重「1-w(x)」。带标识事例,由于全部为正例,以加重「1」作为正例进行操作。将这些加重事例集合作为学习数据来制作分类器。
在此,c和g(x)=p(s=1|x)是通过在图9~图11所示的手法而得到的情况,无标识事例为正例的概率w(x)是通过图10的(10b)所示的导出过程,由于成为w(x)=(1-c)g(x)/(c(1-g(x))),通过c及g(x)的提取,能够求出无标识事例为正例的概率w(x)。
由本实施形态的识别精度的验证实验在以下进行说明。
将dna构成分子作为分析物,从使用纳米间隙电极而计测了的计测脉冲集合,1)首先作为预处理,由pu法的分类器,识别噪声由来的脉冲(不合适数据)(参照图12),将提取了的不合适数据从第2种数据除去,取得了仅碱基由来的脉冲的数据集合。2)如此,相对于得到的碱基由来的脉冲集合,评价碱基种类的识别精度。
噪声除去相对于仅是预先不含碱基(rithiou、ttf)的溶媒,取得通过纳米间隙电极计测了的隧道电流脉冲。此脉冲集合是与碱基没关系的噪声由来的脉冲,称为「噪声脉冲集合」。其次,对于在溶媒混入了碱基rithiou的溶液,取得计测了的电流脉冲。对于ttf也是同样地取得。此脉冲集合,包含碱基由来的「碱基脉冲」和噪声脉冲的双方。因此,将此称为「碱基+噪声脉冲集合」。
由于噪声脉冲集合中的脉冲肯定是噪声脉冲,将其看作正事例集合(第1数据的数据集合),由于碱基+噪声脉冲集合中的脉冲不明是哪一个的脉冲,将其看作无标识事例集合,通过图12所示的pu分类器处理,能够进行噪声脉冲(正例)和碱基脉冲(负例)的识别,通过除去正例的噪声数据,能够得到几乎仅是碱基脉冲的集合(碱基脉冲集合)。
pu分类器处理,为了此噪声脉冲和碱基脉冲的正负例分类,仅1次使用,由于不发生由过学习导致的问题,将全脉冲集合作为学习用数据使用来制作pu分类器,因此进行将全脉冲集合分离成噪声脉冲和碱基脉冲的分类分析。如此,从rithiou的碱基+噪声脉冲集合通过pu分类器取得了rithiou的碱基脉冲集合,从ttf的碱基+噪声脉冲集合通过pu分类器取得了ttf的碱基脉冲集合。
为了碱基脉冲和碱基+噪声脉冲的识别精度评价,除去噪声数据,相对于分离了的rithiou和ttf的碱基脉冲集合,进行由通常的2值分类器的碱基种类的识别实验。识别实验中,2种碱基的碱基脉冲数的任一者不满10的情况,由于学习用事例过少,从实验对象除外。识别精度的指标,使用f-measure(在后述的图71所示,f-尺度),通过10倍交差检定(10-foldcrossvalidation:以下,简称10cv)进行精度评价。在10cv之际,rithiou和ttf的碱基脉冲数设为同数.即,由pu分类器得到的rithiou和ttf的碱基脉冲数分别为nb、nt时,将10cv中使用的碱基脉冲数与rithiou、ttf一起撮合成n=min(nb,nt)。对于脉冲数比n大的碱基脉冲集合,随机提取了n个的碱基脉冲。还有,为了看由pu分类的噪声除去的效果,相对于噪声数据除去实施以前的碱基+噪声脉冲集合,也进行rithiou和ttf的识别实验。相对于从rithiou、ttf各自的碱基+噪声脉冲集合随机提取n个而得到的脉冲集合,碱基脉冲同样地以10cv进行精度评价。
以下说明验证实验的实验条件。
根据图6所示的机械学习软件,以22种的分类器在各种的分析条件之下研究识别精度。
作为脉冲提取参数,在脉冲提取之际,使用从计测电流值的基线偏离多少来判定脉冲开始这样的波高阈值α、和超过了多少步骤以上波高阈值来判定为脉冲这样的波长阈k值的2个参数(后述的图22所示的调整因子)。对这些参数进行各种测试,相对于「对于波高阈值α的4类型×对于波长阈值k的4类型的合计16类型」进行实验。作为属性矢量,对于v1~v8的8种类的属性矢量进行了测试。
作为分类分析用的分类器,采用集成学习「rotationforest」,作为在其内部使用的基础分类器,在weka被实装的分类器之中,可进行输入事例连续值矢量的2值分类,使用了图6的22种类的分类器。作为pu手法,使用了图10所示的g(x)及w(x)的2种手法。
上述的实验条件下进行不合适数据的识别实验,上述的实验条件下进行不合适数据的识别实验,是关于在脉冲提取参数16类型×属性矢量8类型×weka被实装了的22分类器×pu手法2类型的全部组合之中,碱基脉冲数与2碱基均为10以上的3272实例来进行。在此识别实验中,为了单纯化,相对于提取了的脉冲,在1)rithiou的噪声除去,2)ttf的噪声除去,3)噪声除去后的2碱基识别的这些3者中使用的条件(脉冲提取参数、属性矢量、分类器、pu分类器手法)是全部共通的。在同样的条件没用由pu分类器的噪声除去对碱基+噪声脉冲集合也进行了识别实验。
图13是表示从3272实例得到的,f-measure>0.9的1事例(在f-measure为0.93的解析条件使用了的计测脉冲集合),关于判定为碱基的脉冲、和判定为噪声的脉冲的脉冲峰波高的柱状图。横轴表示脉冲峰波高(na),纵轴表示脉冲数。(13a)表示关于rithiou的噪声脉冲和碱基脉冲的柱状图,(13b)表示关于ttf的噪声脉冲和碱基脉冲的柱状图。(13a)中,在噪声脉冲和碱基脉冲中,分别在0~0.3、0.02~0.4的波高范围进行分布。(13b)中,在噪声脉冲和碱基脉冲中,分别在0~0.2、0~1.2的波高范围进行分布。
从图133可知的那样,脉冲峰波高的柱状图是噪声脉冲和碱基脉冲之间重合的部分多,仅在脉冲峰波高中,可知噪声脉冲和碱基脉冲的识别为困难的。
图14是表示对于噪声除去有/无的分别3272实例而得到的,f-尺度(f-measure)的柱状图。横轴表示碱基识别精度,纵轴表示有/无噪声除去的其它各种条件下的解析事例数。在无噪声除去的情况、和有噪声除去的情况,分别在0.3~0.6、0.5~1.0的精度范围进行分布。解析事例总数为脉冲提取参数和属性矢量和分类器的各种组合的3272。
从图14可知的那样,在无噪声除去的情况、和有噪声除去的情况,重合部分大的,100%乃至近100%的精度,提高了识别精度。因此,对于由pc1的不合适数据的识别处理性能,仅脉冲峰波高,即使碱基/噪声的判定为困难的情况,通过使用确实把握了脉冲波形特征的特征量的属性矢量,适当地除去噪声脉冲,能够得到高的碱基分类精度。
由pc1的分类分析装置具有相对于将通过上述的识别处理被识别的不合适数据除去了被分析数据的高精度的分类分析机能。此分类分析机能由以下的分析顺序来构成的。
(c1)通过上述的识别处理识别了的、起因于分析物以外的要素而被检出的不合适数据记录于不合适数据记录设备的ram4的规定区域。不合适数据在pc1不是仅检出而记录,也可以将预先在外部末端记录了的不合适数据文件导入pc1而记录。
(c2)从在计测空间导入含有分析物的试样并检出了脉冲状信号的数据,将除去了记录的不合适数据的数据群作为被分析数据在ram4的规定区域进行记录。也可以将预先除去了不合适数据的数据群作为被分析数据导入pc1而记录。
(c3)在pc1搭载的电脑控制程序中,包含进行使用了机械学习的分类分析的分类分析程序,在rom3被收纳。
(c4)预先求出表示脉冲状信号的波形形态的特征的特征量,将预先求出了的特征量作为用于机械学习的学习数据,将从除去了不合适数据的被分析数据的脉冲状信号得到的特征量作为变数,通过执行分类分析程序,使关于分析物的分类分析成为执行可能。
根据由pc1的分类分析装置,预先求出表示脉冲状信号的波形形态的特征的特征量,就预先求出了的特征量作为用于机械学习的学习数据,将从通过基于pu分类手法的分类器以高精度除去了识别的不合适数据的被分析数据得到的特征量作为变数,通过执行分类分析程序,进行关于分析物的分类分析,通过该被分析数据,关于分析物的分类分析能够以高精度地执行。
本实施形态中,由于能够进行高精度的不合适数据的识别和分类分析,例如,开创人工碱基的识别成为可能的途径,能够策划dna记录介质的信息压缩技术,以及对使用了人工碱基对的医药品创药等的应用展开。
本发明不限于上述的实施形态中的电流输出波形,能够适用于宽广范围的输出波形,例如,相对于电压波形、阻抗波形等的不合适数据的识别及分类分析。
本发明不限于由纳米间隙电极的测定系统的检出波形,能够适用于试样对象通过的与试样对象相当的微小构造,例如,贯通孔、坑(凹型)、柱(凸型)、流路等测定系统的检出波形。本发明中的计测数据的适应范围为时间系列的计测数据中的全部,不限于电気计测,包含光计测、音等物理现象的检出数据是可能的。
本发明中的起因于分析物以外的要素的除去对象,不限于上述的实施形态中的量子水平的要素,也可以适用于例如,计测器、计测元件、在溶液中存在的分析物以外混入的信号。即,本发明能够适用于例如,在计测试样混入的微细尘埃,或者血液等中所含的分析物质作为计测对象的情况中的,起因于红细胞、白细胞、血小板等微小物质等的不合适数据的识别-除去技术。
在本发明涉及的识别处理及分类分析中使用的特征量,不限于上述的波高-波长,能够使用波形形态由来的各种特征量。本发明人达到了以使用了微-纳米孔设备的粒子检出技术从登场的波形数据的解析把握有效的特征量。使用了微-纳米孔设备的粒子检出技术在专利文献1等中公开。以下,本发明详述有效的特征量及使用了有效的特征量时的分类分析处理。
图15は表示使用微-纳米孔设备8的粒子检出装置的概略构成。
粒子检出装置由微-纳米孔设备8以及离子电流检出部来构成。微-纳米孔设备8具有腔室9、将腔室9划分为上下收容空间的分隔壁11、和在分隔壁11的表里侧配置的一对的电极13、14。分隔壁11形成在基板10之上。在分隔壁11的中央付近,贯穿设置有微小孔径的贯通孔12。在贯通孔12的下方,设置有将基板10的一部分向下凹状地去除的凹部18。微-纳米孔设备8由使用半导体设备等的制造技术(例如,电子束描画法或影印版术)来制作。即,基板10由si材料所构成,表面上由si3n4膜的分隔壁11形成薄膜。凹部18通过将基板10的一部分蚀刻去除而形成。
分隔壁11是由在大小10mm见方、厚度0.6mm的si基板上层积有50nm的sin膜而形成。si3n4膜涂布有抗蚀剂,通过电子束描画法,形成有直径3μm的圆形的开口模式,贯穿设置有贯通孔12。在贯通孔12的里侧,由koh进行湿法蚀刻形成50μm见方的开口并设置为凹部18。凹部18的形成,不限于湿法蚀刻,能够通过例如,由cf4系气体的干法蚀刻等的各向同性蚀刻等来进行。
分隔壁11用的膜,除sin膜以外,还可使用sio2膜、al2o3膜、玻璃、蓝宝石、陶瓷、树脂、橡胶、弹性体等的绝缘性膜。基板10的基板材料也不限于si,还可使用玻璃、蓝宝石、陶瓷、树脂、橡胶、弹性体、sio2、sin、al2o3等。
贯通孔12不限于在所述的基板上的薄膜形成的情况,例如,通过将形成有贯通孔12的薄膜状薄片粘合在基板上,也可形成具有贯通孔的分隔壁。
离子电流检出部由电极13、14的电极对、电源15、放大器16以及电压表20所构成。电极13、14介由贯通孔12相向配置。放大器16由运算放大器17和反馈电阻19所构成。运算放大器17的(-)输入端子和电极13接通。运算放大器17的(+)输入端子被接地。运算放大器17的输出侧和电源15之间接连配置有电压表20。通过电源15,在电极13、14之间,可使用0.05~1v的施加电压,在本实施例中成为施加0.05v的方式。放大器16将电极间流动的电流放大并输出到电压表20侧。作为电极13、14的电极材料,可使用例如,ag/agcl电极、pt电极、au电极等,优选ag/agcl电极。
腔室9为密闭状包围微-纳米孔设备8周围的流动性物质收容容器,由电学以及化学性质非活性的材质,例如,玻璃、蓝宝石、陶瓷、树脂、橡胶、弹性体、sio2、sin、al2o3等所形成。
在腔室9内,从注入口(未图示)充填有包含检体21的电解质溶液24。检体21为例如,细菌、微小粒子状物质、分子状物质等的分析物。将检体21混入流动性物质的电解质溶液24,由微-纳米孔设备8进行检测。由离子电流检出部的检测结束时,可从排出口(未图示)排出充填溶液。在电解质溶液中,除例如,磷酸缓冲生理盐水(pbs)、tris-edta(te)缓冲液或其稀释液以外,可使用与此同样的全部的电解质溶液剂。检测不限于每次进行将含有检体的电解质溶液导入、充填至腔室9内的情况,从溶液储藏通过简易泵装置将含有检体的电解质溶液(流动性物质)汲取并由注入口充填进腔室9内,检测后从排出口排出,还有,构成其它的溶液储藏或者将新的溶液储存于溶液储藏中,重新汲取为进行下次的检测的连续检测系统也是可行的。
在将电解质溶液24充填进腔室9内的状态下,贯通孔12的上下的电极13、14间进行电源15的施加电压,则与贯通孔12成比例的一定的离子电流在电极间流动。电解质溶液24中的细菌等的检体在通过贯通孔12之际,由于一部分的离子电流由检体阻碍,所以通过电压表20能够检测脉冲状的离子电流減少。因此,根据使用微-纳米孔设备8的粒子检出装置,通过检出检测电流的波形变化,能够高精度地检出因逐个检体(例如,粒子)通过贯通孔12而流动性物质中所包含的各个粒子的存在。在检测方式中,不限于强制性地使流动性物质一边流动一边检测的情况,还可包含将流动性物质非强制性地一边流动一边检测的情况。
由电压表20对离子电流的检测输出向外部输出成为可能。此外部输出通过变换电路装置(未图示)变换为数字信号数据(检测电流数据)并暂且保存于记录装置(未图示)后,被数据文件记录部5所收纳。在数据文件记录部5中,通过使用了微-纳米孔设备8的粒子检出装置而预先取得的计测电流数据能够进行外部输入。
图68表示用于相对于由pc1的分析物(例如,大肠杆菌ec或枯草杆菌bs)的分类分析处理的概要进行说明的概要图。
图68的分类分析处理是通过以下的分析步骤(a)~(d)来构成的。
(a)对于含有规定的分析物(例如,大肠杆菌ec或者枯草杆菌bs)的流动性物质,由纳米孔设备8a的计测的结果,作为各种类型的检出信号,预先求出得到的对与贯通孔8b的分析物通过对应的脉冲状信号de、db的波形形态的特征进行表示的特征量。脉冲状信号de、db分别是由大肠杆菌ec、枯草杆菌bs的贯通孔8b通过而得到的信号。
(b)在电脑解析部1a中,内蔵着进行由机械学习的分类分析的分类分析程序。(a)中预先求出的特征量是从大肠杆菌ec、枯草杆菌bs的已知数据得到的特征量,作为用于机械学习的学习数据,被使用于电脑解析部1a中。
(c)例如,大肠杆菌ec及枯草杆菌bs的含有比或者含有数为未知的状态时在流动性物质中混入的混合物作为被分类分析物mb的情况,与(a)的已知数据取得的情况同样,进行由纳米孔设备8c的计测。通过这个计测,由被分类分析物mb的贯通孔8d通过,作为被分析数据,得到脉冲状信号dm。
(d)由已知数据的特征量作为学习数据,从被分析数据的脉冲状信号dm得到的特征量作为变数,通过执行分类分析程序,能够进行关于该被分析数据中规定的分析物的分类分析。
通过上述的分类分析,基于特征量,进行由机械学习的分类分析,将种类未知的被分析数据能够分类成来源于大肠杆菌ec或者枯草杆菌bs的通过的1b和不来源于这些的。即,本实施形态涉及的分类分析装置,作为由机械学习的分类器,能够进行被分析数据的分类分析。另外,本发明涉及的特征量是在电脑解析部1a中制作也可以,使用别的特征量制作程序而制作之后提供给电脑解析部1a也可以。
图69是表示由pc1的主要控制处理。
在主要的控制处理中,包括输入处理(步骤s100)、从输入数据取得特征量的特征量取得处理(步骤s101)、分类分析处理(步骤s104)、个数分析处理(步骤s105)及输出处理(步骤s106)。在输入处理(步骤s100)中,进行在pc操作中必要的各种输入、内蔵程序的起动输入、各种分析的执行指示输入、计测电流数据及/或者特征量数据的输入、输出态様的设定输入、在分析时指定特征量的情况的指定特征量的输入等。此输入处理中,也包含不合适数据的除去处理。通过进行由输入设备6的各分析种类的指定操作,使分类分析处理(步骤s104)或者个数分析处理(步骤s105)执行成为可能(步骤s102、s103)。分类分析处理是在特征量取得处理(步骤s101)中,使用从输入数据取得的特征量的矢量值数据使分类分析成为可能。个数分析处理是在特征量取得处理中,使用从输入数据取得的特征量的标量数据使个数分析成为可能。本实施形态是在分类分析处理机能之外,具备个数分析处理机能的实施形态,但本发明是通过具备仅分类分析处理机能的实施形态就能够实施的。
本实施形态涉及的电脑控制程序,包括用于分析粒子种类的个数或者个数分布的个数分析程序。在个数分析处理(步骤s105)中,个数分析程序的执行成为可能。在输出处理(步骤s106)中,分类分析处理(步骤s104)及个数分析处理(步骤s105)中的分析结果数据的输出是可能的,例如,在显示设备7显示和输出各种分析结果数据。当在pc1连接作为输出设备的打印机(未图示)的情况下,各种分析结果数据的打印输出成为可能。
<关于个数分析处理>
本实施形态涉及的分类分析装置,是通过个数分析程序的执行,将包含作为分析对象,例如,1种或者2种以上的粒子(分析物的一例)的流动性物质(电解质溶液24)供给至隔壁11上侧的一面侧,基于由粒子通过贯通孔12而产生的电极13、14间的通电变化检出了检出信号的数据(计测电流数据),具有分析粒子类别的个数或者个数分布的个数分析机能。即,pc1是在cpu2的控制下通过执行在rom3存储了的个数分析程序,能够进行对于在数据文件记录部5存储、记录了的计测电流数据的个数分析处理。个数分析处理是基于在检出信号所含的对应于粒子通过的脉冲状信号的波形形态的特征进行表示的特征量的数据组进行确率密度推定,导出各个粒子种类的个数的个数分析方法,能够进行各个粒子种类个数的自动分析。
图16表示在pc1的分析处理的说明所必要的处理程序构成。各处理程序存储于rom3。作为分析对象的数据实施例,使用包含作为分析物的2种粒子(大肠杆菌和枯草杆菌)的电解质溶液24而提取了的检测电流数据(各粒子的脉冲提取数据)用做原始数据。
在个数分析用处理程序(个数分析程序)中,包含:作为检出信号获得的、从基于对与贯通孔12的粒子通过所对应的脉冲状信号的波形形态的特征进行表示的特征量的数据组求出概率密度函数的概率密度函数模块程序,和从概率密度推定的结果导出粒子类别个数的粒子种类分布推定程序。在分类分析及个数分析中使用的处理程序,包含:以从数据组提取的基线为基准,提取表示脉冲状信号的波形形态的特征的特征量的特征量提取程序,和由基于提取了的特征量所获得的逐个粒子的脉冲特征量数据制作数据文件的数据文件制作程序。分类分析处理及个数分析处理是对通过数据文件制作程序制作了的数据来进行。特征量提取程序,包括从原来的计测电流数据提取该基线的基线推定处理程序。在特征量取得处理(步骤s101)中,执行特征量提取程序及数据文件制作程序、从在输入处理(步骤s100)输入了的数据制作特征量、进行在ram4的特征量记录用数据文件中记录的处理。分类分析用的输入数据是在用作学习数据的特征量的制作中必要的已知数据、和被分析用的数据(分析数据)。从已知数据制作了的特征量数据是在由已知数据的特征量记录用数据文件da中被记录的,从分析数据制作了的特征量数据是在由分析数据的特征量记录用数据文件db中被记录的。当进行分类分析的情况,从这些的数据文件da、db读取特征量的矢量值数据,使执行分析处理成为可能。个数分析用的输入数据仅是被分析用的数据(分析数据)。从个数分析用的输入数据制作了的特征量数据是在个数分析用数据文件dc中被记录的,当进行个数分析的情况,从该数据文件dc读取特征量的标量数据,使执行分析处理成为可能。
作为粒子种类分布推定的前提,由于真的概率密度函数的形式未知,所以通过概率密度函数模块程序的执行,进行被称之为核方法(kernelmethod)的非参数(不指定函数形式)概率密度推定。推定对象的原始数据是从脉冲状信号获得的,包含例如,波高h-时间幅δt-出现数等的脉冲出现分布数据。将原始的检测数据分布的各数据用导入检测误差不确定性的高斯分布来表示,通过各高斯分布的重合获得概率密度函数。通过概率密度函数模块程序的执行来进行概率密度推定处理,能够将原始数据基于该原始数据的未知的复杂的概率密度函数(例如,特征量的脉冲波高-脉冲幅-出现概率)来表示
图46表示使用微-纳米孔设备8,3种粒子33a、33b、33c通过贯通孔12所获得的检出信号的波形例和基于特征量所获得的概率密度函数的导出例。同图(33a)为模拟表示使用微-纳米孔设备8的粒子检出装置。同图(33b)~(33d)表示各检出信号的波形数据。同图(33e)~(33g)表示从各波形数据获得的概率密度函数的3次元分布图。在(33e)~(33g)中表示x轴、y轴、z轴分别为特征量的脉冲波高、脉冲幅以及通过概率密度推定获得的概率密度。
如上所述,基于作为非参数的密度函数的推定法之一的核方法进行概率密度推定处理。核方法是将在一个数据点有的函数(核函数)适用,将此对全部的数据点进行,将被配置的函数重合的推定法,适于获得平滑的推定值。
通过执行概率密度函数模块程序,从检测电流波形的脉冲波高、脉冲幅等的数据被视作多变数多次元概率密度,将扩张到2次元以上并进行加重的最适推定并进行粒子类别个数分布的推定处理。加重的最适推定中,使用基于hasselblad迭代法而执行的em算法软件。em算法是预先已经安装在pc1中。通过粒子类别个数分布的推定处理获得的粒子类别个数分布结果是在显示设备7相对于粒子类别的出现频度(粒子个数)的柱状图而显示输出成为可能。
本发明涉及的特征量,作为脉冲状信号由来的参数是表示该脉冲状信号的波形的局部特征的属于第1类型、和表示该脉冲状信号的波形的整体特征的属于第2类型中的任一者。根据使用这些当中的1或者2个以上的特征量进行个数分析,能够高精度地分析相应于粒子种类等的分析物类别的个数或者个数分布。
图24为将大肠杆菌22和枯草杆菌23的2种粒子混合在电解质溶液24中的样子以模拟表示了的贯通孔12周边的扩大图。
<关于特征量>
图17表示对于实施例的大肠杆菌和枯草杆菌实测了由粒子通过所致的脉冲波形例。图17的(4-1)~(4-9)表示大肠杆菌的实测脉冲波形例(9种类),(4-10)~(4-18)表示枯草杆菌的实测脉冲波形例(9种类)。以外观比较二者,二者间在波高及波长上并无差异,但峰位置及波形尖度等的粒子通过脉冲波形形态的属性可见显著的差异。例如,大肠杆菌的情况,峰在伴随着时间经过有前倒倾向,整体波形尖锐(波形尖度大)。枯草杆菌的情况,峰在伴随着时间经过有后倒倾向,波形尖度小。
本发明人基于所述的粒子通过脉冲波形形态的属性的不同,着眼于将在概率分布制作的基础中使用的特征量从脉冲波形数据按照粒子种类(大肠杆菌和枯草杆菌)分别能够提取。
图18是用于说明本发明涉及的各种特征量的脉冲波形图。在图18中表示横轴为时间,纵轴为脉冲波高。
第1类型的特征量为如下的任一者:
在规定的时间幅内的波形的波高值,
脉冲波长ta,
从脉冲开始至脉冲峰的时间tb与ta之比tb/ta表示的峰位置比,
表示该波形的锐度(峰波形的扩大)的尖度,
表示从脉冲开始至脉冲峰的倾斜的俯角,
表示将波形按照每规定的时间进行了划分的时间划分面积的总和的面积,以及
表示从脉冲开始至脉冲峰的时间划分面积之和相对于全部波形面积的面积比。
图18的5a~5d分别表示脉冲波长、波高值、峰位置比、尖度。图18的bl表示从脉冲波形数据提取(参照后述的bl提取处理)了的基准线(以下,称之为基线)。这些4种类的脉冲特征量是基于图18所示,以如下的(1)~(4)来定义。
(1)波长(脉冲幅)δt:δt=te-ts(ts为脉冲波形的开始时间,te为脉冲波形的结束时间,δt=ta)
(2)波高|h|:h=xp-xo(以bl的xo为基准,至脉冲峰pp的xp的脉冲波形的高)
(3)峰位置比r:r=(tp-ts)/(te-ts)(脉冲波长(=δt)和从脉冲开始至脉冲峰pp的时间tb(=tp-ts)之比)
(4)峰尖度κ:以成为波高|h|=1、ts=0、te=1的方式而正规化,收集从脉冲峰pp到与波高30%的水平线交叉时刻的时刻集合[t]=[[ti]|i=1、···、m],如下述数2所示,时刻集合[t]的数据的分散作为脉冲波形扩大可求κ。
【数2】
图47是用于说明俯角、面积以及面积比的特征量的脉冲波形图。在同图中表示横轴为时间,纵轴为脉冲波高。这些3种类的脉冲特征量如基于图所示,以如下的(5)、(6)、(7)来定义。
(5)俯角θ如(34a)所示,是从脉冲开始至脉冲峰的倾斜,通过下述数3来定义。
【数3】
(6)面积m如下述数4所示,是由单位矢量[u]和波高矢量[p]的内积而得的面积[m]来定义。另外,在以下的说明中,变数a的矢量标记以[a]表示。例如,如在(34b)的10分割例中所示,面积m是将一个波形以每个规定的时间进行10分割时的时间划分面积hi(若幅hx、高hy时,hi=hx×hy,i=1~10)的总和进行表示的面积。
【数4】
m=(u,p)=∑i1·hi
在此,作为特征量计算的准备,有必要将以下定义的d次元波高矢量[p](=(h1、h2、···、hd))事先计算并求出。
图48是用于说明波高矢量的取得方法的图。
如(35a)所示,对于一个波形数据,将波长d等分进行d个的数据组的分化。然后,如(35b)所示,按每个各组(各分割区间)将波高的值平均化,例如,在10等分时,可求出平均值a1~a10。在此平均化中,可包含不进行规格化波高值的情况、和进行规格化波高值的情况。以数4标记的面积[m]表示不进行规格化的情况。将以此所求的平均值作为成分的d次元矢量被定义为「波高矢量」。
图49是用于说明d次元的波高矢量和数据抽样的关系的图。
如(36a)所示,脉冲数据取得涉及的抽样率为大的情况,由于在脉冲部分中的步骤数(数据数)t超过矢量的次元数d,所以能够获得通过所述的取得顺序将各划分的平均值作为成分的波高矢量。另一方面,将抽样率降低,则在脉冲部分中的步骤数t低于矢量的次元数d(>t)的事态产生。t<d的情况,通过所述的取得顺序无法取得各划分的平均值,根据3次样条插值(cubicsplineinterpolation)能够取得d次元的波高矢量。
在特征量提取程序中,包含为了取得波高矢量数据的波高矢量取得程序。通过执行波高矢量取得程序,脉冲步骤数t超过(t>d)或同等于(t=d)矢量的次元数d的情况,求出以时间方向d等分的各划分的平均值,取得以该平均值作为成分的d次元波高矢量,脉冲步骤数t低于矢量的次元数d情况(t<d),执行3次样条插值以取得d次元波高矢量。即,通过使用3次样条插值法进行插值处理,脉冲步骤数为少的情况也能够确定矢量的次元数。
(7)面积比rm是以在(34b)图示的时间划分面积hi从脉冲开始脉冲峰至区间之和相对于全部波形面积的面积比来定义的。下述数5表示面积比rm。
【数5】
第1类型的特征量明确地源于脉冲波高、脉冲波长、脉冲面积等的脉冲状信号的波形,是表示局部特征的特征量。第2类型的特征量相对于第1类型的局部特征是表示整体特征的特征量。
第2类型的特征量为如下的任一者:
以脉冲开始时点作为中心,将所述时间划分面积作为质量,并且将从该中心至所述时间划分面积的时间作为旋转半径进行了拟制时所确定的时间惯性力矩;
相对于所述时间惯性力矩以波高成为基准值的方式而规格化时的被规格化的时间惯性力矩;
将波形按波高方向同等分割,脉冲峰前后分别计算出在各个分割単位中的时刻值的平均值,将以同一波高位置的平均值作为矢量的成分的平均值矢量,
相对于所述平均值矢量以波长成为基准值的方式而规格化时的被规格化的平均值矢量,
将波形在波高方向同等分割,脉冲峰前后分别计算出在各个分割单位的时刻值的平均值,将以同一波高位置的平均值之差作为矢量的成分的平均值的差矢量拟制为质量分布并以波形底部的时间轴作为旋转中心时所确定的波幅平均值惯性力矩;
相对于所述波幅平均值惯性力矩以波长成为基准值的方式而规格化时的被规格化的波幅平均值惯性力矩;
将波形在波高方向同等分割,从每个分割单位的时刻值求出分散,将以该分散作为矢量的成分的分散矢量拟制为质量分布并以波形底部的时间轴作为旋转中心时所确定的波幅分散惯性力矩;以及
相对于所述波幅分散惯性力矩以波长成为基准值的方式而规格化时的被规格化的波幅分散惯性力矩。
图50是用于说明关于时间(波长)以及波幅的第2类型的特征量的脉冲波形图。在同图中表示横轴为时间,纵轴为脉冲波高。这些脉冲特征量如基于同图所示,则以如下的(8)~(15)来定义。
(8)时间惯性力矩是与(34b)同样地将一个波形按每个规定的时间以i次元进行同等分割时的时间划分面积hi作为质量,并且从该中心至时间划分面积hi的时间作为旋转半径进行拟制时所确定的特征量。即,时间惯性力矩的特征量如下述数6所示,是由矢量[v]和波高矢量[p]的内积[i]来定义。在此,若将矢量的次元为n时,有[v]=(12、22、32、···n2)以及[p]=(h1、h2、···、hd)。例如,时间惯性力矩如在(37a)的10分割例所示,与(34b)同样地将一个波形按每个规定的时间进行10分割时,以时间划分面积hi(若设幅hx、高hy时,hi=hx×hy、i=1~10)作为质量,并且从该中心至时间划分面积hi的时间作为旋转半径进行拟制时所确定的特征量,与(6)的面积m同样,能够通过波高矢量求得。
【数6】
i=(v,p)=∑ii2·hi
(9)被规格化的时间惯性力矩是相对于(8)所示的制作了时间区面积的波形,以波高成为基准值的「1」的方式使用按波高方向规格化了的波形,通过与(8)同样地制作了的波高矢量hi在数6所定义的特征量。
(10)平均值矢量,如(37b)的10分割例中表示的那样,将一个波形按波高方向以i次元进行同等分割,脉冲峰前后分别计算出在各个分割単位(分割领域wi)中的时刻值的平均值,将以分割领域wi的同一波高位置的平均值作为矢量的成分的特征量。
(11)被规格化的平均值矢量是相对于(10)的平均值矢量以波长成为基准值的方式而规格化时的特征量。
(12)波幅平均值惯性力矩,如在(37b)的10分割例中表示的那样,将一个波形按波高方向以i次元进行同等分割,脉冲峰前后分别计算出在每个各分割单位(分割区域wi)中的时刻值的平均值,将以分割区域wi的同一波高位置的平均值的差为矢量成分的平均值的差矢量拟制为质量分布hi(将矢量的次元数为n时,i=1~n)并将波形底部的时间轴at为旋转中心的情况作为惯性力矩来定义的特征量。定义式是与数6相同,(12)的特征量是通过矢量[v]和质量分布hi的内积能够求得。
(13)被规格化的波幅平均值惯性力矩是相对于制作了所述的分割区域wi的波形,以波长成为基准值的「1」的方式使用按波长方向所规格化的波形,通过与(12)同样地制作了的质量分布hi,以数6来定义的特征量。
(14)波幅分散惯性力矩是与波幅平均值惯性力矩同样,将一个波形按波高方向以i次元进行同等分割,在脉冲峰前后分别从每个各分割单位(分割区域wi)的时刻值求出分散,将以该分散作为矢量成分的分散矢量拟制为质量分布hi(将矢量的次元数为n时,i=1~n)并将波形底部的时间轴at为旋转中心的情况作为惯性力矩来定义的特征量,与波幅平均值惯性力矩同样,以数6来定义。
(15)被规格化的波幅分散惯性力矩是相对于制作了所述的分割区域wi的波形,以波长成为基准值的「1」的方式使用按波长方向规格化了的波形,通过与(14)同样地制作了的质量分布hi,以数6来定义的特征量。
波幅平均值惯性力矩以及波幅分散惯性力矩,如上所述,是以数6来定义的特征量,该定义中的矢量[p],在波幅平均值惯性力矩的情况,为时刻值的平均值的差的矢量,在波幅分散惯性力矩的情况,为时刻值的分散矢量。在以下的说明中,将关于(12)~(15)的波幅的惯性力矩中的矢量[p]表示为[pw]。
在关于(12)~(15)的波幅的惯性力矩的数据制作演算中,使用图36所示的将波高矢量的纵横轴交换了的波幅矢量[pw](=[p1、p2、···、pdw])来进行。波幅矢量是在(12)~(15)的特征量的定义所示的平均值的差矢量或者分散矢量。通过将波幅矢量作为密度分布捕捉,能够求出(12)和(13)的波幅平均值惯性力矩以及(14)和(15)的波幅分散惯性力矩。波幅矢量是将脉冲波形数据按波高方向进行dw等分,在毎个各划分求出的波高值的平均值的差或者将分散作度为成分具有的dw次元矢量。在(37b)的情况中,波幅矢量的次元为10次元。(37b)所示的时间轴at与基线bl不同,是从波幅矢量所获得的脉冲底部周边的旋转轴线。
图51是用于说明dw次元的波幅矢量和数据抽样的关系的图。
在特征量提取程序中,包含通过以下的dw次元的波幅矢量的制作演算处理而用于取得波幅矢量的波幅矢量取得程序。
脉冲波形数据,因为在波高方向以各种各样的间隔分布,所以在按波高方向分割了的区划中,产生包含1或者2个以上不存在数据点的不存在区域bd的情况。在(38a)中,以箭头表示不存在区域bd的1例。不存在区域bd是数据间隔变粗而不存在数据点,无法获得以所述的数6定义的关于波幅的惯性力矩的成分。由此,与前述的脉冲波形扩大的情况同样,通过收集至脉冲峰的波高按dw等分时的各波高的时刻集合[tk]=[[ti]|i=1、···、m]制作波幅矢量的成分。此时,在不存在数据点的不存在区域bd中,通过线形插值能够进行成分数据的取得。该线形插值是相对于脉冲峰的(10k+5)%(k=0、1、2、3、···)值以延伸连续的两个数据来进行。(38b)表示关于数据点ti和ti+1之间产生的不存在区域bd的高度k的线形插值点tk的一例。另外,在波幅矢量的制作之际,如(38c)所示,脉冲波形数据的底部区域ur与波高数据产生分歧的情况,向接近脉冲峰向靠齐,在远离脉冲峰之侧的波高数据du被舍弃。在波幅矢量取得程序的执行处理中,包含对于不存在区域bd的线形插值处理,和相对于波高数据的分歧的波高数据du的舍弃处理。
图52是用于说明关于波幅的将惯性力矩通过波幅矢量取得的取得过程的图。
(39a)是将波形按高方向10等分的例,表示相对于一个波形39a,通过进行所述的线形插值处理以及舍弃处理获得的波幅矢量的分割区域39b以及旋转轴线39c。
如(39b)所示,在每个各分割单位,脉冲峰前后分别计算出时刻值的平均值,能够取得将分割区域的同一波高位置的平均值的差作为矢量成分的平均值的差矢量的波幅矢量。能够制作将此平均值的差矢量拟制为质量分布并以旋转轴线39c(时间轴)为旋转中心的(12)的波幅平均值惯性力矩。还有,从毎个分割单位的时刻值求出分散,能够取得以该分散作为矢量成分的分散矢量。能够制作以此分散矢量拟制为质量分布并以旋转轴线39c(时间轴)为旋转中心的(14)的波幅分散惯性力矩。另外,(10)、(11)的平均值矢量是算出时刻值的平均值,
将分割领域的同一波高位置的各平均值作为成分的矢量,在dw等分的情况,以2dw次元的时刻矢量来表示。
用于特征量制作的波高矢量以及波幅矢量的矢量次元数是无需拘泥于分割数而能够任意设定。波高矢量以及波幅矢量虽有按波长或者波高的一个方向细分化了的情况,但在特征量的制作中,能够使用将在复数方向细分化了的矢量。
图53是用于说明在复数的方向分割了的情况的特征量制作所用波形矢量的一例的图。
(40a)表示将一个波形数据以网格状分割了的数据地图40a。数据地图40a是将波形数据以横轴的时间轴方向进行dn分割,以纵轴的波高方向进行dw分割使数据点的数的分布状态表示为矩阵状。(40b)表示将矩阵状的区划(格子)一部分扩大了的分布状态。在(40b)的分布状态中,11×13个的格子中分布有0~6个的数据点数。通过此矩阵分割,将作为各格子内的数据点数/总数据点数以dn×dw次元矢量成分的波形矢量,通过将其变换成以矩阵排列的数据组重排为扫描状的矢量来代替波高矢量及波幅矢量能够用于特征量的制作。
<关于基线的推定>
一般地,细菌等为具有微细差异的形态的微小物体。例如,平均的大肠杆菌的情况,2~4μm的体长而外径为0.4~0.7μm。平均的枯草杆菌的情况,2~3μm的体长而外径为0.7~0.8μm。还有,在大肠杆菌等中,付随有20~30nm的鞭毛。
作为检体粒子使用细菌等的情况下,若忽略从脉冲波形数据中细微的不同,将会招致个数判定精度的降低。为此,为了将特征量正确地算出以作为概率分布的推定基础,有必要正确地把握通粒子过脉冲波高,其中有必要进行检测信号的基线的推定。但是,在检测信号的原始数据的基线中,因为包含噪声数据及由微弱的检测电流引起的摆动,所以有必要确定在去除此摆动成分等的基线后检出脉冲波高等。基线的推定(以下,称之为bl的推定)在实际应用中,优选通过电脑在线(即刻地)进行。
作为将bl的推定在电脑上进行的手法,如果使用从有离散性误差的观测推定时时刻刻变化的量适合的卡尔曼滤波器,由此,去除干扰(系统噪声及观测噪声)而能够推定基线bl。
所谓卡尔曼滤波器,就是离散的控制过程通过在图19的(6a)所示的线形差分方程式所定义,对更新可能的状态矢量[x]的时刻[t]中的值进行推定的手法。在卡尔曼滤波器中,状态矢量[x]以及系统控制输入[ut]的值被认为不能直接观测。
状态矢量[x]是通过图19的(6b)所示的观测模型,被认为是间接地推定的。关于系统控制输入[ut],仅将其统计的变动幅[σu,t]假定为参数。
在本实施形态中的检测电流数据[x]并非矢量而是标量,还有各种行列也是标量,能够视为[f]=[g]=[h]=[1]。因此,将时刻t的实际的电流值的基线等级、在时刻t所检测的电流、时刻t的观测噪声分别设为[xt]、[yt]、[νt]时,则[xt]以及[yt]为如图19的(6c)所示那样地表示。[xt]、[ut]、[νt]为不可观测的因子,[yt]为可观测的因子。将由离子电流检出部的检测频率数设为f(hz),则时刻数据会成为1/f(秒)刻度。假定系统控制输入[ut]的影响实际上非常小而能够进行基线的推定。
图20为将所述的各因子以实际的检测电流数据所示的图。由离子电流检出部的实际检测之际,粒子堵塞于贯通孔12,虽然会产生基线的歪曲,由于检测时在歪曲的发生时点中断,将歪曲原因除去后检测才进行,所以在原始的数据集合中收集有仅包含没有歪曲的基线的数据。
由卡尔曼滤波器的推定通过预测和更新的重复而进行。对于基线的推定,也重复由卡尔曼滤波器的预测和更新得以执行。
图21表示在卡尔曼滤波器中预测(8a)和更新(8b)的重复细节的图。在图21中,矢量标记所付加的「冒号」记号表示推定值。附加文字的「t|t-1」是基于(t-1)时点的值,表示为t时点的值的推定值。
图22表示基于bl推定处理程序的bl推定处理。对于bl推定处理,进行bl的推定和基于bl推定的脉冲波高值的提取。
在bl推定处理的执行之际,在卡尔曼滤波器中预测和更新的处理所必要的调整因子的开始时刻m、定数k、α的值是相应于推定对象的数据属性有必要事先调整(调节)并决定为合适的值。α的值为用于将基线的推定值的分散进行调整的值。k的值为与在图21所示的卡尔曼滤波器中更新a的执行次数有关系的值(参照图9的步骤s57、s62)。开始时刻m为将检测抽样的1个部分作为1步骤所计算的步骤数部分的时间数据。
图23表示用于该调整的珠子模型的波形图。在图15中表示着作为粒子混入有与细菌等相同程度大小的微小珠子球的情况(珠子模型)的溶液状态。图23的(10a)为通过离子电流检出部以抽样频率数900000hz所取得的波形数据。在(10a)所示的珠子模型的波形表示平缓地进行衰减的波形。在(10a)的右端部分产生有剧烈的跌落,将其扩大表示在(10b)。
从珠子模型的波形检出了在(10b)所示的基线的段差部分(10c)的情况,在其不久之前的期间成为初期值计算期间。例如,若m=100000的情况,将当该初期值计算期间去除的期间中能够用肉眼确认显著性的脉冲为11~12个。
图25是表示相应于调整因子的m、k、α的组合从珠子模型的波形拾取了脉冲的数的表。
图25的(12a)表示由m=10000的情况的k值(10、30、50、70、90)、α值(2、3、4、6)的组合的脉冲数。同图(12b)表示由m=50000的情况的k值(10、30、50、70、90)、α值(2、3、4、6)的组合的脉冲数。(12c)表示由m=100000的情况的k值(10、30、50、70、90)、α值(2、3、4、6)的组合的脉冲数。
比较图25的3种模拟结果,则(12a)和(12b)的情况,应被检测的脉冲数成为12,而在(12c)中成为11。因此,在实施例中,采用脉冲数的最大值中最小的(12c),进行m=100000、k=50、α=6的调节设定。这些调节设定数据事先被记录、设定于ram23的设定区域。
图22的bl推定处理在所述调节设定下,进行由图21所示的卡尔曼滤波器的bl推定。首先,于步骤s51中,在时刻m中卡尔曼滤波器的初期值被设定在ram23的工作区域。此时,在数据文件记录部5收纳了的脉冲波形数据被读取到ram23的工作区域。然后,执行在时刻(m+1)中卡尔曼滤波器的预测和更新(图21的a以及b)(步骤s52)。在预测和更新中,执行如图21所示的卡尔曼滤波器的各演算,被记录于ram23。之后,按规定的各个单位时间重复执行预测和更新(a以及b),在时刻t的卡尔曼滤波器的预测和更新a进行时,判断下述数6的条件被满足与否(步骤s53、s54)。单位时间为通过原始数据的抽样频率数所确定的值,事先被设置于ram23。
【数7】
在数7的条件不被满足的情况,在时刻t的卡尔曼滤波器的更新b被执行,就单位时间经过的毎个数据重复步骤s53~s55的处理。在所述数7的条件被满足的情况,其次数值每1次都被累积记录于ram23的计数区域(步骤s54、s56)。然后,基于该计数值,判断数7的条件以时刻s作为起点是否k次连续满足(步骤s57)。没有k次连续的情况进入步骤s55,进行更新b。
k次连续的情况则进入步骤s58,被判定为开始了用于bl确定的持有必要期间。此时,将持有必要期间的持有开始时刻作为s记录于ram23的同时,时刻(s+1)~时刻(s+k-1)的期间的卡尔曼滤波器的演算结果不被记录地进行舍弃。
通过持有必要期间的开始,在时刻t的脉冲下落最大值可更新地记录于ram23(步骤s59)。然后,与步骤s54同样,在持有必要期间,进行下述数8的条件是否被满足的判断(步骤s60)。
【数8】
在所述数8的条件不被满足的情况,进行脉冲的下落最大值的更新(步骤s59、s60)。在数8的条件被满足的情况,其次数值每一次都被累积记录于ram23的计数区域(步骤s60、s61)。然后,基于该计数值,判断数8的条件以时刻s2作为起点是否k次连续满足(步骤s62)。没有k次连续的情况则返回步骤s59。
k次连续的情况则进入步骤s63,此时被更新记录的脉冲的下落最大值作为脉冲波高值的推定值被记录于ram23。脉冲波高值的推定值与脉冲开始时刻以及脉冲结束时刻的数据一起被记录。脉冲波高值的推定完成后,持有必要期间被判定为结束。通过此结束,持有必要期间的持有结束时刻作为s2被记录于ram23(步骤s64)。其次,进入步骤s65,时刻s的值作为卡尔曼滤波器的演算处理的重启时的初期值,对于时刻s2~时刻(s+k-1)的期间进行追溯并执行卡尔曼滤波器的演算。步骤s65之后,判断全部脉冲波形数据的bl推定处理是否进行(步骤s66),以全部脉冲波形数据的推定完成为结束,有残存数据时则移至步骤s53。
<关于特征量提取>
图26表示特征量提取程序的执行处理内容的概要。
特征量提取处理是通过图22的所述bl推定处理的执行以脉冲波高值(波高|h|)的提取数据存在为条件成为可执行(步骤s41)。脉冲波高值的提取数据存在的情况,执行前述的波高矢量取得程序以及波幅矢量取得程序,执行各种矢量的数据制作演算(步骤s42)。当完成波高矢量以及波幅矢量的全部数据的取得,则该矢量数据被保存(步骤s43、s44)。然后,执行各种特征量的提取处理(步骤s45)。在波高矢量以及波幅矢量的数据取得之际,随时进行使用了3次样条插值法插值处理、线形插值处理以及舍弃处理。
图54表示特征量的提取处理(步骤s45)的执行处理内容。步骤s71~s83分别表示在所述(1)~(13)定义的第1类型以及第2类型的特征量的算出、和被算出的特征量的记录、保存的处理。
第1类型的特征量是在步骤s71~s76中被算出。波长(脉冲幅)δt是相对于脉冲波高值的提取数据组以时间序列被依次算出并被记录(步骤s71)。被算出的特征量是被记录于ram4的特征量记录用存储区域。脉冲幅是演算δt(=te-ts;ts为脉冲波形的开始时刻,te为脉冲波形的结束时刻)而可求出。峰位置比r是相对于脉冲波高值的提取数据组以时间序列被依次算出并被记录(步骤s72)。峰位置比r是演算r=(tp-ts)/(te-ts)(脉冲幅δt、和从脉冲开始至脉冲峰pp的时间(=tp-ts)之比)而可求出。
峰尖度κ是相对于脉冲波高值的提取数据组以时间序列被依次算出并被记录(步骤s73)。以成为脉冲波高值|h|=1、ts=0、te=1的方式而正规化,收集从脉冲峰pp与波高30%的水平线交叉的时刻的时刻集合t=[[ti]|i=1,···,m],演算时刻集合t的数据的分散并作为脉冲波形扩大可求出κ。
俯角θ是基于从脉冲开始至脉冲峰的时刻与波高的数据、和前示的数3的演算可求出(步骤s74)。面积m是通过波高矢量的数据来求出,时间划分面积hi根据划分数来求出,通过求出这些的总和而算出,并被记录(步骤s75)。该划分数是可任意地设定的,例如,10。面积比rm是分别求出全部波形面积、和时间划分面积hi从脉冲开始至脉冲峰的区间的部分和,算出部分和相对于全部波形面积的面积比并被记录(步骤s76)。
第2类型的特征量是在步骤s77~s82中被算出。时间惯性力矩是通过波高矢量的数据来求出,基于相应于划分数所求的时间划分面积hi、和前示的数6的演算而算出并被记录(步骤s77)。(9)的被规格化的时间惯性力矩是相对于在步骤s77中所获得的时间惯性力矩,以波高成为基准值的「1」的方式而按波高方向进行规格化处理(波高矢量和规格化矢量的内积)的作为规格化数据被记录(步骤s78)。波幅平均值惯性力矩是从在步骤s42~s44求出的波幅矢量(平均值的差矢量)的数据,基于分别在脉冲峰前后以毎个分割单位(事先被设定的划分数:10)算出了的时刻值的平均值的差、和前示的数7的演算而被算出,并被记录(步骤s79)。(11)的被规格化的波幅平均值惯性力矩是相对于在步骤s79中所获得的波幅平均值惯性力矩,以波长成为标准值「1」的方式而沿波长方向进行规格化处理(平均值的差矢量和规格化矢量的内积)的作为规格化数据被记录(步骤s80)。波幅分散惯性力矩是从波幅矢量(分散矢量)的数据,基于以毎个分割单位算出了的时刻值的分散、和前示的数7的演算而被算出,并被记录(步骤s81)。(13)的被规格化的波幅分散惯性力矩是相对于在步骤s81中所获得的波幅分散惯性力矩,以波长成为基准值「1」的方式而沿波长方向进行规格化处理(分散矢量和规格化矢量的内积)的作为规格化数据被记录(步骤s82)。
从全部数据的特征量提取完成后,则进行各数据的文件保存,判断是否还有其它的数据组(步骤s83、s84)。如果还有其它文件的数据组,所述处理(步骤s71~s82)还可重复执行。如果没有需要处理的数据,特征量的提取处理完成(步骤s85)。在所述的提取处理中,求出全部的第1类型以及第2类型的特征量,但通过输入设备6的指定输入可以指定所希望的特征量,能够提取仅由该指定的特征量。
图27表示基于粒子种类分布推定程序而执行的粒子种类推定处理。<关于概率密度函数的推定>由于即使为同种粒子而被检测的脉冲波形也不尽相同,所以作为用于粒子种类分布推定的准备,从测试数据预先进行粒子类别的脉冲波形的概率密度函数的推定。通过概率密度函数的推定而根据被导出的概率密度函数能够表示各脉冲的出现概率。
图28的(15b)为在大肠杆菌和枯草杆菌的粒子种类中,相对于作为脉冲波形的特征量使用脉冲幅和脉冲波高而获得的脉冲波形的概率密度函数的方案图,通过图中的深浅来表示脉冲的出现概率。图28的(15a)表示关于1个波形数据的第1类型的特征量的一部分。
由于脉冲幅δt和脉冲波高h的真的密度函数为未知,所以有必要进行非参数的概率密度函数的推定。在本实施形态中,使用作为核函数采用了高斯函数的核密度推定。
所谓核密度推定,就是假设就检测数据由核函数赋予概率密度分布,将这些分布重合了的分布视为概率密度函数的手法。作为核函数使用了高斯函数的情况,相对于各数据假设为正规分布,将这些重合了的分布能够视为概率密度函数。
图29为由大肠杆菌和枯草杆菌的粒子种类的各个所获得的概率密度分布的重合的方案图。同图(16c)表示从脉冲幅δt和脉冲波高h的特征量数据(16a),将对于各粒子所求的概率密度分布(16b)重合了的状态。
相对于输入数据[x]的概率密度函数[p(x)]是使用教师数据(teacherdata)数[n]、教师数据[μi]、分散共分散行列[σ],以下述数9来表示。
【数9】
相对于输入数据
还有,概率密度函数[p(x)]如下述数10所示,能够以各次元的高斯函数之积来表示。
【数10】
为了计算的简单,将分散共分散∑的共分散项作为0,记为
如从数10可知,相当于假定各脉冲属性为服从正规分布的独立的概率变数,这个同样也可扩张到3次元以上。因此,在本实施形态中,2种以上的粒子种类个数的分析是可能的。
概率密度函数模块程序具有演算并求出相对于2种的特征量的概率密度函数的机能。即,使用由两个特征量[(β、γ)]的推定对象数据的情况,在作为核函数采用了高斯函数的核密度推定中的概率密度函数[p(β、γ)]是以下述数11来表示。
【数11】
当将分散共分散行列∑的共分散项作为0,有
基于数11,通过概率密度函数模块程序而执行的概率密度函数推定处理如根据后述的图33详述的那样,进行在两个特征量中的概率密度函数的推定处理。
图30是表示k个的粒子类别的粒子总数、粒子类别的出现概率、和数据整体的出现频度的期待值的关系的方案图。同图(17a)表示数据整体的出现频度。同图(17-1)~(17-k)表示粒子类别的出现频度。脉冲[x]被检测的出现频度的期待值是成为根据粒子类别的概率密度函数而脉冲[x]被检测的出现频度的期待值之和。如图30所示,从粒子类别的粒子总数[ni]、和粒子类别出现概率[pi(x)]作为粒子类别的期待值之和能够以下述数12来表示。
【数12】
在本实施形态中,对事先求出的粒子类别的概率密度函数的推定进行了的概率密度函数数据(参照数10)作为分析参照数据记录于ram23中。粒子类别个数分析是基于数12,通过将分析对象的整体数据的出现频度从各分析数据辩出适合的粒子类别的个数来进行。个数分析是通过推定不同的粒子种类的柱状图(相对于粒子种类的出现频度(粒子数))来进行。
在图27的粒子种类推定处理中,进行通过数据的编集来制作由特征量的数据文件的数据文件制作处理(步骤s1)、粒子数的推定处理(步骤s2)、和推定粒子种类分布的算出处理(柱状图制作处理)(步骤s3)。在粒子数的推定处理中,能够使用由最大似然估计、拉格朗日未定乘数法以及hasselblad迭代法的推定手法。<关于最大似然估计(maxiumlikelihoodestimation:在统计学中,从被赋予的数据来点推定其所服从的概率分布的总体的方法)>
现在,作为实际的脉冲推定结果,设为已获得数据集[d]=[x1、x2、x3、···xn]。被推定的第j个的脉冲波高数据出现的似然(likelihood)由下述数13表示。
【数13】
于是,数据集d出现的似然由下述数14表示。
【数14】
将数14的似然最大化这样的粒子种类分布的值集合[n]=[n1、···、nk]t为最具似然的粒子种类分布。
<关于拉格朗日未定乘数法(为在束缚条件的基础上进行最佳化的解析学方法,相对于各束缚条件准备未定乘数,根据将这些转为系数的线形结合作为新函数(未定乘数也为新的变数)捕捉而将束缚问题作为通常的极值问题解决的方法)>将数据集d出现的似然最大化,与将数据集[d]出现的对数似然最大化等同。下述数15表示为了调查拉格朗日未定乘数法的适合与否的导出对数似然的过程。
【数15】
在数15中,途中的系数1/nn在最终式予以省略。
在此,在粒径个数分布的值集合n=[n1、···、nk]t中,有「总计为n」的约束(参照下述数16)。
【数16】
因此,获得最具似然的粒子种类分布的命题,由于转变为带有约束的对数似然最大化的问题,所以通过拉格朗日未定乘数法进行最佳化是可能的。通过拉格朗日未定乘数法进行最佳化的带有约束的对数似然最大化式能够以下述数17来表示。
【数17】
从数17所示的带有约束的对数似然最大化式,经过图31所示的数学的导出过程能够导出下述数18所示的[k]个的联立方程式。
【数18】
将数18所示的联立方程式以数值求解时,能够使用hasselblad提倡的迭代法而进行。根据hasselblad迭代法,进行下述数19的迭代计算即可。这个迭代法的细节在提倡论文(hasselbladv.,1966,estimationofparametersforamixtureofnormaldistributions.technomerics,8,pp.431-444)中有记述。
【数19】
在数19的迭代计算中,利用在市面上出售的em算法的软件进行。em算法,如从命名的由来可知,是将概率分布的参数,通过以似然函数最大化来进行计算的方法,即能够将作为似然函数的概率分布的期待值(expectation)最大化(maximization)的算法。根据em算法,设定所求的参数的初期值,从其值计算似然(期待值),在大多数情况,使用似然函数的偏微分成为0的条件,以重复计算能够计算出最大似然的参数。使用em算法进行hasselblad迭代法的演算处理,具有设定所求参数的初期值,从其值计算似然(期待值),还使用似然函数的偏微分成为0的条件进行重复计算来计算最大似然的参数的工程。
<关于粒子种类推定处理>
在图27所示的粒子种类推定处理中可执行的数据文件制作处理(步骤s1)、概率密度函数的推定处理(步骤s2)、粒子数的推定处理(步骤s3)以及推定粒子种类分布的算出处理(步骤s4)详述如下。
图32表示通过数据文件制作程序执行的数据文件制作处理(步骤s1)。
使用pc1的输入设备6,制作数据文件各k个(在实施例中为2个)的特征量的指定操作能够进行。被指定的特征量的组合输入在ram23被设定(步骤s30)。特征量的各个设定的特征量数据文件的数据被读取至ram23的工作区域(步骤s31)。特征量数据文件是在图22的bl推定处理以及图26的特征量推定处理中被推定并被提取的、被文件保存的特征量(脉冲波高值等)数据。
通过指定k个用于个数推定的特征量,制作n行k列的行列数据(步骤s32)。所制作的行列数据,输出至粒子种类分布推定用数据文件,按各个指定特征量被保存(步骤s33)。相对于指定特征量的全部的数据文件的生成完成后便会结束(步骤s34)。
图33表示通过概率密度函数模块程序执行的概率密度函数的推定处理(步骤s2)。概率密度函数推定处理是基于数6进行2个特征量中的概率密度函数的推定处理。
将在数据文件制作处理(步骤s1)中制作的、概率密度函数推定对象的数据文件的数据读取,制作n行2列的行列[d](步骤s20、s21)。行列[d]的每列的如下述数20所示的分散被算出(步骤s22)。
【数20】
然后,下述数21所示的分散参数使用标准偏差系数c如下述数22所示的那样被设定(步骤s23)。
【数21】
【数22】
【数23】
图34表示粒子数的推定处理(步骤s3)。
首先,与所述的步骤s20、s21同样,读取在数据文件制作处理中制作了的、粒子数推定对象的数据文件的数据,制作n行2列的行列[d](步骤s10、s11)。相对于行列[d]数据,执行由hasselblad迭代法的推定处理(步骤s12)。
图35表示通过em算法被执行的由hasselblad迭代法的粒子数推定处理。图36表示由em算法的处理顺序。
首先,在进行初期值的设定(处理23a)后,依次执行基于概率密度函数的个数计算(处理23b)(步骤s12a、s12b)。个数计算的迭代是被执行直到满足如(23c)所示的收敛条件(convergencecondition)(步骤s12c)。em算法的执行结果(每个粒子种类的推定个数数据)被收纳于ram23的规定区域(步骤s12d)。
在步骤4中,通过粒子数推定处理而获得的各粒子种类的推定个数数据被编辑成粒子类别的个数分布数据,根据显示指定,将柱状图显示输出至显示设备7成为可能。在图27中有省略,但在本实施形态中,当收到了分散图输出的指定的情况下,将由特征量数据的粒子类别的分散图进行显示输出成为可能。
图37表示通过本实施形态涉及的粒子种类个数分析装置分析了的结果的一例。同图(24a)以及(24b)是分析对象的粒子种类的大肠杆菌、枯草杆菌的显微镜放大照片。(24c)以及(24d)是表示作为特征量集中于脉冲波高以及脉冲尖度,通过粒子数推定处理的执行而获得的各粒子种类的推定个数数据的柱状图、分散图。
<关于由特征量的粒子种类个数的分析精度的验证1>
本发明人使用所述实施例的大肠杆菌和枯草杆菌的检测电流数据在下述的评价条件下进行粒子种类个数的分析性能的验证1。
验证1的评价条件如下。
(1)以大肠杆菌和枯草杆菌的1000khz实验测定数据进行评价。
(2)作为特征量,将波长δt、波高h、峰位置比r、峰尖度k的4个的第1类型的特征量算出并使用。
(3)关于各特征量的组合,实施个数推定处理。
(4)将大肠杆菌和枯草杆菌的实测数据随机地分为学习用和测试用来进行推定评价。10次反复这个推定评价而实施,算出那些的平均精度和标准偏差。这个情况,通过评价与实际接近的精度的交叉验证法(crossvalidation)来进行。
(5)将验证粒子(大肠杆菌和枯草杆菌)的实测数据的一部分进行个别地个数分析,将其余通过规定的混合比δ进行随机地混合来作为验证用,进行比较个数分析结果。将随机数据混合用数据混合程序收纳于rom3,利用pc1执行数据的随机混合,进行相对于其随机混合了的数据的个数推定。即,在图32的步骤s32的行列数据中,使用通过数据混合程序制作了的n行k列的随机置换行列数据。在混合比δ中,作为大肠杆菌的混合率使用10、20、30、35、40、45、50%的7种类。bl推定用的参数(调整因子)m、k、α的值分别使用100000、400、6,在概率密度函数的推定用的标准偏差系数c中设定为0.1。粒子种类个数推定时的收敛条件α设定为0.1。另外,对于在评价中使用了的所述调整因子的值,使用与在图25所示的模拟例同样地进行严密的调整而获得的值。
图38的(25a)以及(25b)表示作为特征量使用了脉冲波长、波高的验证例,和作为特征量使用了脉冲波长、峰位置比的验证例的各推定结果数据。
通过本验证而获得的全部脉冲的数是大肠杆菌为146个、枯草杆菌为405个。
图39的(26a)以及(26b)表示作为特征量使用了峰付近波形的扩大、脉冲波长的验证例,和作为特征量使用了峰付近波形的扩大、波高的验证例的各推定结果数据。
粒子类别个数的评价能够通过以在图40的(27b)所示的数式表示的「加重平均相对误差」来进行。「加重平均相对误差」是各粒径的相对误差乘以其粒径的真的个数比例的值,并加上其对全粒径而获得的数值。
图40的(27a)表示作为特征量使用了尖度、和脉冲波高的情况中的个数推定结果。
图41的(28a)以及(28b)表示作为特征量使用了脉冲波长、脉冲波高的情况中的各混合比δ的个数推定结果,和作为特征量使用了脉冲波长、峰位置比的情况中的各混合比δ的个数推定结果。
图42的(29a)~(29d)是表示将大肠杆菌和枯草杆菌的混合比分别为1:10、2:10、3:10、35:100的情况的各个数推定结果的柱状图。
图43的(30a)~(30c)是表示将大肠杆菌和枯草杆菌的混合比分别为4:10、45:100、1:2的情况的各个数推定结果的柱状图。
图44的(31a)以及(31b)是将作为特征量使用了脉冲波长、脉冲波高的情况的各粒子的散布状态进行合成的图。
图45的(32a)、(32b)以及(32c)是将作为特征量使用了峰付近波形的扩大、脉冲波长的情况,作为特征量使用了峰付近波形的扩大、峰位置比的情况,使用了峰付近波形的扩大、脉冲波高的情况的各粒子的散布状态进行合成的图。
从所述的性能评价实验,获得以下的评价结果。
(1)在图44以及图45的数据散布图中,关于4个的特征量,大肠杆菌和枯草杆菌的特征大幅重叠,但能够认可存在明显的不同。
(2)从在图40的(27a)等所示的类别个数分布的推定结果来看,此评价验证的特征量之中组合了脉冲波高和峰尖度的特征量的情况是精度最好,能够获得在加重平均相对误差的评价中4~12%的分析精度。所述实施形态中,提取4种类全部的特征量,但基于所述验证结果,仅提取一部分的特征量(例如,脉冲波高和峰尖度)进行个数分析也是可行的。
<关于由特征量的粒子种类个数的分析精度的验证2>
本发明人使用所述实施例的大肠杆菌和枯草杆菌的检测电流数据,进行了与验证1不同的粒子种类个数的分析性能的验证2。在验证2中,与验证1不同,算出第1类型以及第2类型的特征量((1)~(13)的13种类)而使用,验证了这些的组合涉及的特征量和抽样数据数的相关性以及各组合的分析性能。
图55的(42a)以及(42b)分别表示在全部数据之中,以1mhz、500khz进行抽样时的关于各特征量组合的推定评价结果。图56的(43a)以及(43b)分别表示在全部数据之中,以250khz、125khz进行抽样时的关于各特征量组合的推定评价结果。图57的(44a)以及(44b)分别表示在全部数据之中,以63khz、32khz进行抽样时的关于各特征量组合的推定评价结果。图58的(45a)以及(45b)分别表示在全部数据之中,以16khz、8khz进行抽样时的关于各特征量组合的推定评价结果表示。图59是以4khz进行抽样时的关于各特征量组合的推定评价结果。这些的表中的每个各组合的推定评价结果是与验证1的(4)同样地通过交叉验证法而获得的、表示在上侧记载的平均精度,和在下侧以括号书写所示的标准偏差。表中的惯性i、惯性i(规格化)、惯性i_w、惯性i_wv、惯性i_w(规格化),惯性i_wv(规格化)分别表示(8)的时间惯性力矩、(9)的被规格化的时间惯性力矩、(10)的波幅平均值惯性力矩、(12)的波幅分散惯性力矩、(11)的被规格化的波幅平均值惯性力矩、(13)的被规格化的波幅分散惯性力矩的特征量。
图60表示全部抽样数据中的关于各特征量组合的推定评价结果。图61表示在全部数据之中以1mhz~125khz的高密度抽样时的关于各特征量组合的推定评价结果。图62表示在全部数据之中以63khz~4khz的低密度抽样时的关于各特征量组合的推定评价结果。
图63是使用了全部抽样数据时(50a)以及以高密度抽样时(50b)高的个数推定精度所获得的关于上位5种特征量的组合的抽样频率数-加重平均相对误差(平均值)的图。图63中的上位5种的特征量的组合为波长δt-面积m、波长δt-惯性i、峰位置比r-惯性i、俯角θ-惯性i、惯性i-惯性i_w(规格化)。
图64是以低密度抽样时高的个数推定精度所获得的关于上位5种的特征量的组合的抽样频率数-加重平均相对误差(平均值)的图(51a),和使用了全部抽样数据时的关于4种类的特征量的组合的抽样频率数-加重平均相对误差(平均值)的图(51b)。图63以及图64的纵轴的值是进行50次的交叉验证而获得的加重平均相对误差的平均值。在51a中的上位5种的特征量的组合为波长δt-面积m、波长δt-惯性i、峰位置比r-面积m、俯角θ-面积m、面积m-惯性i_wv(规格化)。在51b中的4种类的特征量的组合为波长δt-面积m、波长δt-惯性i、尖度k-波高|h|、尖度k-峰位置比r。
从验证2获得的结果为如下。
(r1)如图60以及图63所示,使用了全部抽样数据时,上位5种的组合,即,波长δt-惯性i、波长δt-面积m、峰位置比r-惯性i、俯角θ-惯性i、惯性i-惯性i_w(规格化)的特征量的情况,能够获得高的个数推定精度。由这些的特征量的组合的个数推定精度(加重平均相对误差),例如,在波长δt-惯性i以250~1000khz的抽样区域中为约9~10%,在波长δt-面积m以125~250khz的抽样区域中为约9~10%,在波长δt-惯性i以16~63khz的抽样区域中为约13~15%。
(r2)如图61所示,比全部抽样数据少但使用了高密度的抽样数据时高的个数推定精度所获得的特征量,如果以上位5种的组合来表示的话,为波长δt-惯性i、波长δt-面积m、峰位置比r-惯性i、惯性i-惯性i_w、俯角θ-惯性i的5种。由这些的特征量的组合的个数推定精度(加重平均相对误差),例如,在波长δt-惯性i以250~1000khz的抽样区域中为约9~10%,在波长δt-面积m以125~250khz的抽样区域中为约9~10%,在波长δt-惯性i以16~63khz的抽样区域中为约13~15%。
(r3)如图62所示,使用了与高密度抽样数据相比更少的低密度抽样数据的情况下高的个数推定精度所获得的特征量,如果以上位5种的组合来表示的话,为波长δt-面积m、波长δt-惯性i、俯角θ-面积m、面积m-惯性i_wv(规格化)、峰位置比r-面积m的5种。由这些的特征量的组合的个数推定精度(加重平均相对误差),在波长δt-惯性i以250~1000khz的抽样区域中为约9~10%,在波长δt-面积m以125~250khz的抽样区域中为约9~10%,在波长δt-惯性i以16~63khz的抽样区域中为约13~16%。
(r4)从(r1)~(r3)可知,即使使用第1类型和第2类型的特征量的组合也能够进行高精度的个数推定。还有,根据本发明涉及的个数分析方法,抽样数即使不是十分多,如能得到规定的抽样数,就能够以与十分之时相同程度的精度进行个数分析。例如,在验证1研究的尖度k和峰位置比r的组合中,产生12%的最大误差,但是例如,在由波长δt-惯性i的特征量的情况下,即使不使用全部数据,而使用在1mhz~125khz的高密度抽样数据,也就是说,即使是部分的数据,也能够以约9%的高精度进行个数推定处理。因此,本实施形态涉及的个数分析机能并非仅用于常规的个数分析,例如,在有紧急危急的检疫检查及医疗现场中,在菌类等的粒子有无或者个数的判定中能够使用作为应急实施的适宜检查工具。
<关于个数分析处理时间的验证3>
在个数推定中,由于由hasselblad法的迭代计算所需的所需计算时间要花费,因此关于这个所需计算时间与抽样频率数的关系,在验证3验证了特征量的比较验证。在验证3的比较验证例中,使用了图64的(51b)所示的波长δt-面积m、波长δt-惯性i、尖度k-波高|h|、尖度k-峰位置比r的4种类的特征量的组合。这些的组合与其它的组合进行比较,为交叉验证精度的好的组合。在个数分析的计算所需的时间中,由于包含特征量制作所需的时间,和由hasselblad法的迭代计算所需的计算时间,所以关于特征量制作所需的计算时间ct1、由hasselblad法的迭代计算所需的计算时间ct2以及这些的总计计算时间ct3(=ct1+ct2)进行了比较验证。这个情况也是各自的所需计算时间为进行50次的交叉验证而获得的各计算时间的平均值。
图65是将相对于4种类的各特征量的组合的总计计算时间ct3进行表示的抽样频率数(khz)-所需计算时间(秒)的图(52a),和将相对于各特征量组合的特征量制作所需的计算时间ct1进行表示的抽样频率数(khz)-所需计算时间(秒)的图(52b)。图66是将相对于各特征量组合的计算时间ct2进行表示的抽样频率数-所需计算时间(秒)的图。
如在(52a)所示,波长δt-面积m和波长δt-惯性i的特征量组合g1成为几乎相同的总计计算时间,尖度k-波高|h|和尖度k-峰位置比r的特征量组合g2成为几乎相同的总计计算时间。如在(52b)所示,特征量组合g1的各自的特征量制作所需的计算时间是相同的,特征量组合g2的各自的特征量制作所需的计算时间是相同的。如在图53所示,由hasselblad法的迭代计算所需的时间,即使在特征量组合g1、g2的任一者中,在以1mhz~16khz的抽样区域中,在约3、5秒以下的短时间处理成为可能。
从验证3的特征量组合g1、g2的比较结果可明确,不管是与第1类型和第2类型的同一类型的组合还是不同的混合组合,使用特征量就能够实现所需计算时间的短缩化。因此,根据本实施形态涉及的个数分析机能并非仅用于常规的个数分析,例如,在有紧急危急的检疫检查及医疗现场中,也能够迅速地进行菌类等的粒子有无或者个数的判定处理。
从以上的性能评价可知,以由纳米孔设备8检出了的检出信号的数据组为基础,通过个数导出机制的粒子种类分布推定程序的执行,从基于将作为该检出信号获得的粒子通过所对应的脉冲状信号的波形形态的特征进行表示的特征量的数据组进行概率密度推定,能够导出粒子类别的个数。因此,pc1个数分析机能,能够高精度地分析例如,细菌及微小粒子状物质等的分析物类别所相应的个数或者个数分布,能够在个数分析检查中实现简易化以及低成本化。通过将由纳米孔设备8的检出信号直接地读入个数分析装置并可数据保存,也可构建统合了检查和分析的粒子种类统合分析系统。
从基于特征量的数据组进行概率密度推定,将导出了的粒子类别的个数的结果能够在输出设备的显示设备7显示输出或者在打印机进行打印输出。因此,根据本实施形态,由于将高精度的导出结果(粒子个数、粒子个数分布、推定精度等)能够以例如,柱状图及散布图的输出形态可认知并即刻地告知,所以例如,作为在需要迅速地对应的医疗现场及检疫场中有用的检查工具,能够使用本实施形态涉及的个数分析机能。
本发明不限于搭载了识别处理程序的特定的pc等的电脑终端,能够适用于记录了该识别处理程序的一部分或者全部的识别分析用记录介质。即,在规定的电脑终端安装记录了该识别分析用记录介质的识别分析程序而使所希望的电脑能够进行识别分析工作,所以能够简便并且廉价进行识别分析。在本发明的可适用的记录介质中,能够选择软盘、磁盘、光盘、cd、mo、dvd、硬盘、移动终端等由电脑可读取的记录介质的任一者而使用。
图69是表示本实施形态涉及的分类分析处理。
图67的电脑解析部1a是对应于本实施形态的pc1。作为分析处理的准备工作,是在输入处理(步骤s100)中进行不合适数据的除去处理、特征量的指定、已知数据及被分析数据对pc1的输入。特征量是能够在所述的(1)~(15)表示的第1类型及第2类型的一部或者全部或者1种以上的组合的特征量于该输入处理中预先进行指定。例如,将大肠杆菌ec及枯草杆菌bs作为以粒子种类分别被特定的分析物(特定分析物)的情况,对于这些的特定分析物的各个,进行由纳米孔设备8a的计测、分别的脉冲状信号的数据作为已知数据输入至pc1、输入数据是收纳于ram4的已知数据记录用存储区域。对于特定分析物的含有状态为不明的被分析对象进行的由纳米孔设备8a的计测而得到的脉冲状信号的数据作为分析数据输入至pc1,输入数据是收纳于ram4的分析数据记录用存储区域。
分类分析处理是通过起动操作来起动的、和已知数据的输入有无来判定(步骤s110)。已知数据的未输入的情况,进行通过显示设备7来促使已知数据的输入的引导表示。图69中省略了由各种的引导表示的报知处理步骤。已知数据被输入的、和被输入的已知数据收纳于ram4的已知数据记录用存储区域,供于特征量的制作(步骤s100、s101)。
有已知数据输入的情况,判断是否有特征量的指定(步骤s110、s111)。有特征量的指定的情况,是从由ram4的已知数据的特征量记录用数据文件da被指定的特征量的矢量值数据在ram4的学习数据记录区域获取(步骤s113)。没有特征量的指定的情况,从由ram4的已知数据的特征量记录用数据文件da的所有特征量的矢量值数据是在ram4的学习数据记录区域获取(步骤s112)。
接着,判定分析数据的输入有无(步骤s114)。没有分析数据输入的情况,进行通过显示设备7来促进分析数据输入的引导表示。分析数据被输入的、和取得了的分析数据是收纳于ram4的分析数据记录用存储区域(步骤s100)。分析数据被输入的,如记述的那样,制作关于分析数据的特征量,被记录于ram4(步骤s101)。有分析数据的输入的情况,从由ram4的分析数据的特征量记录用数据文件db的特征量的矢量值数据是在ram4的变数数据记录区域中获取(步骤s115)。
当已知数据及分析数据的输入结束在特征量的取得状态中,进行促使分类分析的执行的引导显示。通过基于该引导显示而进行规定的指示操作,分类分析程序被起动,进行由机械学习的分类分析的执行处理(步骤s116)。本实施形态中,例如,在基于随机森林法的算法而构成的由机械学习的分类分析程序是预先装入于rom3。由已知数据的特征量作为学习数据、从分析数据得到的特征量作为变数、执行该分类分析程序,由此能够进行关于该被分析数据中的特定分析物的分类分析。该分类分析程序的执行之际,将脉冲波形变换成同一次元的数值矢量、判定各矢量是如何的不同,由此识别个别的脉冲,进行分类分析。
在本发明涉及的由机械学习的分类分析手法中,不限于随机森林法,还能够使用例如,k-最近邻算法、朴素贝叶斯分类器、决策树、神经网络、支持向量机、套袋法、集成法等的由集団学习的手法。
由机械学习的分类分析的执行处理是进行对由分析数据的所有特征量执行的、分类分析处理已经结束、和分类分析结果的输出处理(步骤s117)。在输出处理中,关于各种未知的分析数据,来源于作为特定分析物例示的大肠杆菌ec或者枯草杆菌bs的通过的这些比例的分类结果在显示设备7显示成为可能。在输出可能的显示方式中,不限于各个分析数据的分类结果,能够使用分析物(例如,大肠杆菌ec或者枯草杆菌bs)的对应总数、两者的对应比率等的显示方式。
<分类分析处理的处理精度的验证>
对于所述的分类分析处理的处理精度,适用由各种的机械学习的分析手法而尝试分类分析来验证了由本实施形态的分类分析处理的精度。
图70的(57a)是使用同图(57b)中表示的分析试样,在特征量(feature)和由机械学习的分析手法的算法(以下,称为分类器)进行各种组合的情况,显示执行了本发明涉及的分类分析处理(图69参照)的评价结果。
作为分析试样,如(57b)中表示的那样,有2种类的细菌种(大肠杆菌、枯草杆菌)。相对于各细菌种,使用贯通孔12的内径为4.5φ、贯通孔12的贯通距离(孔深)为1500mm的微-纳米孔设备8来计测通过波形而得到的脉冲状信号数据以42个(大肠杆菌的情况,以计测脉冲的所有,枯草杆菌的情况,以计测脉冲数265个之中的42个)进行使用。分类器的执行之际,脉冲状信号数据之中约9成作为学习数据,将其余的数据划分为变数。
作为评价项目,如(57a)中表示的那样,以f-尺度(f-measure)来显示,包括真阳性率(tprate)、伪阳性率(fprate))、适合率(precision)、再现率(recall)、f值(fmeasure)、受信者操作特性曲线面积(roc(receiveroperatingcharacteristic)curvearea)的项目。
图71为f-尺度的说明图。
对于f-尺度,如(58a)中表示的那样,相对于2种类的细菌种的实数(大肠杆菌的实数:p、枯草杆菌的实数:n),在各细菌种的预想值被指定的情况,各组合中的真阳性(tp)、伪阳性(fp)、真阴性(fn)及伪阴性(tn)的总和作为1,如(58b)中表示的那样,以2tp/(2tp+fp+fn)来显示。
这个验证中,使用算法不同的67种类的分类器、使用各种特征量或者特征量的组合对约4000种的模式进行尝试分类分析。这个结果是对于60种的特征量的组合而得到的有意义的分析结果。图70的(57a)是表示在这个验证得到的f-尺度的优异上位10位内的分类结果的表。
在上位10位内的特征量中,如在(57a)表示的那样,包含并列了(1)~(11)、(14)及(15)的13种类的特征量的13次元的特征量矢量(在表中以「hv&f」略记)、波高矢量(在表中以「h」略记)和(10)的平均值矢量(在表中以「wv」略记)的组合(在表中以「h&wv」略记)、波高矢量和(11)的被规格化的平均值矢量(在表中以「wnrmdv」略记)的组合(在表中以「h&wnrmdv」略记)。在(57a)中最优异的分类精度的情况是作为特征量而使用了h&wv的组合的、由随机森林法的分类器(「4meta.randomcommittee」)所致的情况,其分类精度为约98.9%的高精度。
本发明并不限于搭载了分类分析程序的特定pc等的电脑末端,能够适用于记录了该分类分析程序的一部分或者全部的分类分析用记录介质。即,由于在规定的电脑末端装入有该分类分析用记录介质记录了的分类分析程序、在所望的电脑能够使分类分析动作,所以能够进行简便且便宜地分析。在本发明适用可能的记录介质中,能够选择软盘、磁盘、光盘、cd、mo、dvd、硬盘、移动终端等、通过电脑可读取的记录介质的任一者来使用。
另外,本发明不限定于所述实施形态,对于在不脱离本发明的技术思想的范围中的各种改变例、设计变更等,不必说是包含在该技术的范围内。
产业上的可利用性
根据本发明,由于能够进行高精度地不合适数据的识别和分类分析,因此能够在例如,dna记录介质的信息压缩技术以及使用了人工碱基对的医药品创药,或者,在计测试样混入的微细尘埃,或者体液等中所含的分析物质作为计测对象的情况中的、起因于红细胞、白细胞、血小板等的微小物质等的不合适数据的识别-除去技术等的领域进行宽广范围的应用发展。特别是本发明能够适用于以含有dna或rna和夹杂物的试样作为分析对象,例如,进行下水中的dna含有分析而检知病毒发生的检知技术中的数据分析。
符号的说明
1个人电脑
2cpu
3rom
4ram
5数据文件记录部
6输入设备
7显示设备
8微-纳米孔设备
9腔室
10基板
11分隔壁
12贯通孔
13电极
14电极
15电源
16放大器
17运算放大器
18凹部
19反馈电阻
20电压表
21检体
22大肠杆菌
23枯草杆菌
24电解质溶液
ms计测空间
d1电极
d2电极
me电流计测器
- 还没有人留言评论。精彩留言会获得点赞!