一种二维多快拍无网格压缩波束形成声源识别方法与流程
本发明属于声场识别技术领域。
背景技术:
基于平面传声器阵列测量的压缩波束形成是实现声源二维波达方向(direction-of-arrival,doa)估计和强度量化的有效途径。传统压缩波束形成假设声源分布在一组预先设置的离散网格点上,每个网格点代表一个观测方向,施加稀疏约束体现为最小化声源分布向量的
为从根本上解决该问题,先后发展了二维单快拍和多快拍无网格压缩波束形成策略,相比于单快拍,多快拍方法更稳健,但现有的基于原子范数最小化(atomicnormminimization,anm)的二维多快拍无网格压缩波束形成声源识别存在对声源彼此间距较小产生失效的缺陷。
技术实现要素:
针对现有技术存在的问题,本发明所要解决的技术问题就是提供一种二维多快拍无网格压缩波束形成声源识别方法,它使用迭代重加权原子范数最小化,能提高分辨率、去噪声能力和声源识别精度。
本发明所要解决的技术问题是通过这样的技术方案实现的,它包括步骤:
步骤1、获取测量声压矩阵p★;
测量声压矩阵
p★=p+n
测量声压矩阵p★通过传声器阵列测量得到,
步骤2、重构声源在阵列传声器处产生的声压p;
步骤1)、建立重构p的数学模型
式中,
tb(u)中,每个块ta(0≤a≤a-1)都是一个b×b维的toeplitz矩阵:
步骤2)、求解p
初始化
1.使用matlab的cvx工具箱中的sdpt3求解器求解:
2.确定规则化参数κl+1:
3.第l+1次迭代确定的权矩阵wl+1:
步骤3、估计声源doa;
步骤4、估计声源强度。
本发明的技术效果是:
本发明能准确估计声源彼此间距较小的doa,并能定量获得声源的强度,克服了现有anm的二维多快拍无网格压缩波束形成的缺陷,提高了分辨率、去噪声能力和声源识别精度。
附图说明
本发明的附图说明如下:
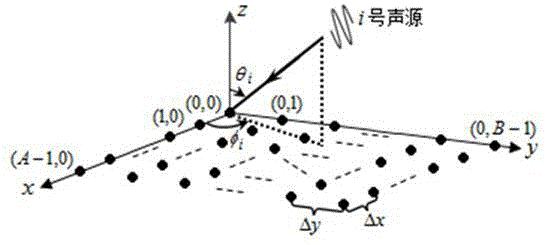
图1为传声器阵列测量布局;
图2为声源频率为2000hz、3000hz、4000hz和4900hz时的仿真重构结果对比图;
图2(a)、(c)、(e)、(g)为anm;图2(b)、(d)、(f)、(h)为本发明;
图3为本发明与现有的anm的声压p的重构精度、声源doa的估计精度和声源强度的量化精度曲线对比图;
图3(a)
图3(b)
图3(c)
图4为试验布局图;
图5为声源频率为2000hz、3000hz、4000hz和4900hz时的实验声场重构结果对比图;
图5(a)、(c)、(e)、(g)为anm;图5(b)、(d)、(f)、(h)为本发明。
具体实施方式
下面结合附图和实施例对本发明作进一步说明:
本发明包括以下步骤:
步骤1、获取测量声压矩阵p★
二维无网格压缩波束形成声源识别是利用矩形传声器阵列测量声信号。如图1所示的传声器阵列测量布局,符号“●”表示传声器,a=0,1,…,a-1,b=0,1,…,b-1分别为x、y维的传声器索引,δx、δy分别为x、y维的传声器间隔,θi、φi分别为i号声源doa的仰角和方位角(0°≤θ≤90°、0°≤φ≤360°)。记
假设声源辐射平面声波,波长为λ,t1i≡sinθicosφiδx/λ,t2i≡sinθisinφiδy/λ,则各快拍下声源在(a,b)号传声器处产生声压组成的行向量
式(1)中,k为声源总数,
构建矩阵:
列向量
存在噪声干扰
p★=p+n(3)
在仿真试验中,添加噪声为独立同分布高斯白噪声,信噪比(signal-to-noiseratio,snr)定义为snr=20log10(||p||f/||n||f),由此可确定||n||f=||p||f10-snr/20,其中,“||·||f”表示frobenius范数。
试验测试时,
步骤2、重构声源在阵列传声器处产生的声压p
步骤1)、建立重构p的数学模型
二维多快拍无网格压缩波束形成后处理的第一步是滤除测量声压p★中的噪声、重构声源在阵列传声器处产生的声压p,该步骤通过对声源施加稀疏约束来实现。建立源稀疏性的度量:
式(4)中,
定义tb(·)为二重toeplitz算子,对任意给定向量u映射为a×a维的块toeplitz型hermitian矩阵:
式(5)中,每个块ta(0≤a≤a-1)都是一个b×b维的toeplitz矩阵:
p的重构问题可写为:
式(7)中,ε为噪声控制参数,通常取为||n||f。
联立式(4)、(7)可得:
式(8)中,
现有的anm二维多快拍无网格压缩波束形成声源识别方法采用p的原子范数
当声源间分离较小时,现有的anm二维多快拍无网格压缩波束形成会因上式获得的
步骤2)、使用本方法发明求解p
记
式(9)中,
式(10)为凸优化问题,可用cvx工具箱中的sdpt3求解器求解。
初始化
式(11)中,
因此,初始化
1.使用matlab的cvx工具箱中的sdpt3求解器求解:
2.确定规则化参数κl+1:
3.第l+1次迭代确定的权矩阵wl+1:
步骤3、估计声源doa;
该步骤的运算与现有技术anm二维多快拍无网格压缩波束形成声源识别方法相同。参考文献z.yang,l.xie,p.stoica.vandermondedecompositionofmultileveltoeplitzmatriceswithapplicationtomultidimensionalsuper-resolution[j].ieeetransactionsoninformationtheory,2016,62(6):3685-3701.(“多重toeplitz矩阵的范德蒙德分解及其在多维超分辨率中的应用[j].”,杨在,谢利华,p.stoica,《ieee信息理论学报》,2016,62(6):3685-3701)。
获得声源个数
步骤4、估计声源强度;
记
式中,a为感知矩阵,上标“+”表示伪逆,
仿真模拟试验
为验证建立本发明的准确性和对比其性能的提高,进行声源识别仿真模拟。
仿真设置如下:在特定位置假设具有特定强度辐射特定频率声波的点声源(假设六个声源,仰角依次为60°、60°、50°、40°、30°、70°,方位角依次为180°、190°、90°、90°、200°、300°,强度(均方根:
仿真具体流程为:
1、根据式(2)及式(3)计算各传声器接收声压信号(用a=b=8、δx=δy=0.035m的传声器阵列测量声信号,信噪比snr取20db,快拍总数设为10);
2、根据步骤2的本方法发明迭代求解声压
3、根据步骤3估计声源doa;
4、根据步骤4估计声源强度。
本方法发明与用anm方法的结果进行对比,如图2所示,声源辐射声波的频率:图2(a)和图2(b)为2000hz,图2(c)和图(d)为3000hz,图2(e)和图2(f)为4000hz;图2(g)和图2(h)为4900hz;每幅图中,“*”指示重构声源分布,“○”指示真实声源分布,并为便于对比,各图中均参考最大输出值进行db缩放,显示动态范围均为0~-20db,同时,每幅图的上方还列出了以标准声压大小2.0×10-5pa为参考的最大输出值。2000hz、3000hz、4000hz、4900hz下,声源间的最小分离
由图2可以看出:使用anm的二维多快拍无网格压缩波束形成(图2(a)、图2(c)、图2(e)、图2(g))仅准确重构了4900hz时的声源分布,而使用本发明的二维多快拍无网格压缩波束形成(图2(b)、图2(d)、图2(f)、图2(h))在四个频率下的重构结果均准确,所以证明:本发明克服了anm的缺陷,具有更高分辨率。
定义标准frobenius范数误差
由图3可以看出:与使用anm的二维多快拍无网格压缩波束形成相比,本发明具有更强的去噪声能力和更好的分辨率,能更准确地重构声源在阵列传声器处产生的声压、更准确地估计彼此间分离较小的声源的doa和量化其强度。
试验验证
为检验仿真结论的正确性和使用本发明的二维多快拍无网格压缩波束形成在实际应用中的有效性和优越性,进行验证试验。
图4为试验布局图,测量阵列为
图5给出了声源频率为2000hz、3000hz、4000hz和4900hz的结果,每幅图中,“*”指示重构声源分布,参考最大输出值进行db缩放,“○”指示真实声源doa,不包含强度信息。四个频率下,声源间的最小分离依次为0.032、0.048、0.065、0.079。
由图5可以看出:使用anm,在2000hz(图5(a))和3000hz(图5(c))重构的声源分布严重偏离真实声源分布,仅在4000hz(图5(e))和4900hz(图5(g))准确估计出了六个主要声源的doa。使用本发明,图5(b)、5(d)、5(f)、5(h)在四个频率下的声源doa估计结果均准确。
试验结论与仿真结论一致,证明仿真结论正确,使用本发明的二维多快拍无网格压缩波束形成在实际应用中更有效。
- 还没有人留言评论。精彩留言会获得点赞!