一种拖拉机发动机故障诊断及预测方法与流程
本发明涉及一种故障诊断及预测方法,具体是一种拖拉机发动机故障诊断及预测方法。
背景技术:
故障诊断是根据设备运行状态信息查找故障源,该技术经过30多年的发展,已经取得了长足的进步。从最初以信号分析为基础到现在以知识处理为基础的智能诊断系统,使得故障诊断的精度不断的提高,故障诊断的应用范围也越来越广泛。就目前我国的国情来说,农业生产仍然占有很大的比重,而拖拉机作为农业活动中应用最为广泛的农业机械设备,是农业生产活动的主要动力来源,拖拉机故障的发生直接会影响农业生产的进行。无论何种机械设备,在故障发生前都会产生相应的故障征兆,而故障征兆是导致故障发生的萌芽因素,对于拖拉机来说也不例外。所以如果能够在拖拉机发动机故障发生前,就根据故障征兆所能产生的故障类型进行及时的预测或者在拖拉机发动机故障发生后根据故障征兆的类型对故障进行精确诊断,及时提醒拖拉机用户及厂家注意,并根据故障征兆的类型采取相应的措施,把故障遏制在萌芽状态,这样既能减少拖拉机故障发生率,又能提高拖拉机维修效率。
就目前来说,拖拉机发动机故障事故在拖拉机故障中占有很大的比重,而对于拖拉机发动机的故障诊断往往是拖拉机发生故障后相关技术人员通过经验或者专业的故障诊断仪器进行具体故障部位及故障类型的判断,确定一个具体的故障原因往往花费大量的时间和精力。拖拉机发动机的故障信息不像一些简单的设备故障和原因具有一一对应的关系,拖拉机发动机的故障征兆及故障原因之间具有复杂的对应关系,一个故障的产生可能由多种因素造成,而一个因素又可能引发多种故障发生,所以如何对拖拉机发动机的故障做出精确判断和及时诊断变得很复杂。故如何实时对拖拉机发动机的故障诊断及预测是本行业研究的方向。
技术实现要素:
针对上述现有技术存在的问题,本发明提供一种拖拉机发动机故障诊断及预测方法,能实时对拖拉机发动机的运行状态进行监测,并采用模糊神经petri网络进行故障诊断及预测,不仅具有很好地及时性,而且具有较高的精确性。
为了实现上述目的,本发明采用的技术方案是:一种拖拉机发动机故障诊断及预测方法,具体步骤为:
a、建立拖拉机发动机的故障征兆和原因的数据信息:收集拖拉机发动机的各种故障征兆和原因的相关数据,然后形成关于故障征兆和原因的故障数据集,根据故障征兆和原因的故障数据集对采集的拖拉机发动机数据进行筛选(即剔除与故障征兆和原因不相关的数据),然后将数据通过标准化的方法(如标准差法)整理成标准化的故障数据集;
b、确定petri网络的输入量、输出量及中间变量:在拖拉机发动机状态参数中选取发动机转速值、冷却液温度值、燃油率、扭矩值作为输入量;然后选取发动机油耗过高、发动机起动困难、发动机怠速不稳和冷却液温度过高,这四种故障征兆作为中间变量;将发动机发生故障作为输出量;
c、输入量与中间变量的模糊化处理:通过查询现有的拖拉机发动机故障文献及结合本领域技术人员的公知常识对发动机转速值、冷却液温度值、燃油率、扭矩值进行模糊化处理,将发动机故障征兆和故障原因以知识表达式规则的形式建立对应关系;发动机各参量的调控要确保发动机的运行状态,且各参量是相互影响的;
d、构建模糊神经petri网络模型:模糊神经petri网络模型采用分级诊断网络模块的方法,对于各个级别的诊断网络,相同结点采用数值调用的方式,具有相同的诊断信息;在模糊神经petri网络模型中,变迁的发生即拖拉机发动机故障征兆的发生;对模糊神经petri网络模型中的各个库所进行权值分配,将模糊神经petri网络模型(fnpn)定义为十二元组,即
fnpn=(p,t,d,a,w,s,kp,kt,cf,α,β,θ)
其中,p,t,d,a,w,s,kp,kt,cf,α,β,θ的定义分别是p=(p1,p2,...,pn)为有限库的集合;t=(t1,t2,...,tn)为变迁的有限集合;d=(k,g,u)为命题集合,其中k=(k1,k2,...,kn)为初始命题集,g=(g1,g2,...,gn)为中间命题集,u=(u1,u2,...,un)为结论命题集;a为有向弧的集合;s=(sp,st)为状态集合,sp为库所的状态集合,st为变迁的状态集合;cf为变迁引发结果的可信度;α为库所到真值的一一映射;β为库所与命题的一一映射;θ为变迁阈值;w为输入库所对应的变迁的权值集合,w=(w1,w2,...,wn),n为一个输入库所对应的变迁的个数,且满足
由于模糊神经petri网络模型的一个变迁发生后,输入库所的托肯值并不发生改变,因此在该网络中设置一个变迁发生标志位flag,一个计数位count,一个网络层级标志位lr,一个最大网络层级标志位mlr和一个阈值位thr;当一个变迁发生后,将flag置为1,同时计数位count自动加1,当满足条件count≥thr时,自动转入下一层次的变迁过程;在故障诊断的过程中,每发生一次变迁,即有标志位标出,这样可以预防变迁复发生;
对于一个变迁t∈t,t为拖拉机发动机采集数据的时间段;若存在
一个变迁引发后,它的输入库所当中的标记值不会改变,而会向输出库所传递新的标记值;这个标记值规定如下:若库所p是单个变迁的输出,则输出库所的标记值为m(p)=k×πiu(pi),pi∈i(t),k为变迁可信度;若库所p为多个变迁的输出库所时,m(p)=πikj{1-πiu(pij)},
e、采用模糊神经petri网络模型对拖拉机发动机故障诊断及预测:将实时采集的拖拉机发动机状态特征参数输入模糊神经petri网络模型,在拖拉机出现相应的故障征兆时,模糊神经petri网络模型实现对拖拉机发动机的故障诊断及预测。
进一步,所述步骤c中知识表达式规则的具体得出过程为:设拖拉机发动机故障诊断规则库有n条规则r(r1,r2,...,rn),那么第k条的模糊产生式规则的表述形式为:
rk:ifakthenbk(cf=σk)
其中ak代表的是故障症状,取值范围是ak∈(0,1);bk代表的是故障原因,σk代表的是第k条规则的置信度,σk越大,则第k条规则越可信;
将模糊神经petri网络共分为六层,依次为输入层、隶属度函数生成层、规则推理层、模糊化层、去模糊化层、输出层,该网络的推理过程如下:
输入层:将输入的信号变换到[0,1]论域中,系统将根据输入量的变化自动调整连接权系数;
隶属度函数生成层:该层寻找一个模糊隶属函数,确定各输入量的模糊隶属程度,选用高斯函数
αjl(xj)=exp(-(xj*-bjl)2/σjl2),l=1,2,...,n
其中bjl,σjl分别为隶属函数的中心和宽度,j为隶属度函数所在层数,l为层中的节点数,由此得到该层的输出为:
oil=αjl,l=1,2,...,mj,j=1,2,...,n,i=1,2,....,m
规则推理层:在模糊推理中采用madina推理算法,即由隶属函数的最小值算出;
模糊化层:将节点采用n表示,它对各条规则的适用度做归一化处理;
去模糊化层:把模糊集合映射成精确输出集合,采用重心加权求和的方法,得到精确输出;
输出层:该层节点是固定节点,其输出为:
最终将步骤b中确定的输入量根据上述各层规则计算得出各自的知识表达式规则。
进一步,所述步骤d中学习训练的具体过程为:
步骤1:对模糊神经petri网络进行初始化,设定各个权值及变迁可信度的初始值,给相应的输入命题和中间命题的总个数赋值为m,变迁的总个数赋值为n,样本总数赋n,i和j分别为1,学习步长为ξ;
步骤2:由目标函数的设计思路,按照目标误差不大于误差限的思想在网络中自动生成目标函数为
步骤3:由初始权值和可信度以及前面的引发规则计算出一组网络的可靠度,得到初始误差为
步骤4:依据公式
步骤5:依据调整后的权值,重新计算得到的误差值,将当前计算得到的误差值fi同fi-1进行比较,若有fi<fi-1,则转至步骤4,否则进入下一步;
:步骤6:改变动量因子α的值,重新调整原来的权值,说明原来的权值调整方式不正确;
步骤7:令i=i+1,判断i是否大于n,若不大于,则转向步骤3,将权值加以调整;否则转入下一步;
步骤8:判断此时的fi是否已经达到规定的误差限,若已经达到,则结束训练;若还没有达到,判断权值训练次数是否超过规定的训练次数,若没有,则将fi赋给f0并重新使得i=1转到步骤3,开始下一轮的训练;如果已经超过了规定的训练次数,则进行下一步;
步骤9:对可信度进行训练,逐个调整信任度,使其不超过1,并逐次计算误差值fk并判断是否达到误差限,若已达到,则结束训练;若还未达到,则一直调整可信度直到达到规定的可信度训练次数为止,若此时还未达到要求,则要修改引发条件和模糊规则,返回步骤1重新进行训练。
与现有技术相比,本发明采用模糊神经petri网络对发动机故障进行诊断及预测,由于模糊神经petri网适合于描述系统状态和行为的改变,而故障是以设备状态和行为变化为特征的,故障诊断和传播是一个动态过程,petri网络既能表示诊断对象的结构组织关系又能反映诊断推理过程,同时能很好的表示系统状态和行为的变化关系,准确描述故障的产生和传播特性。将petri网络应用于拖拉机发动机故障诊断及预测中在诊断准确性及效率上相较于其他诊断方法有着很大的提高。因此本发明能实时对拖拉机发动机的运行状态进行监测,并采用模糊神经petri网络对发动机进行故障诊断及预测,不仅具有很好地及时性,而且具有较高的精确性。
附图说明
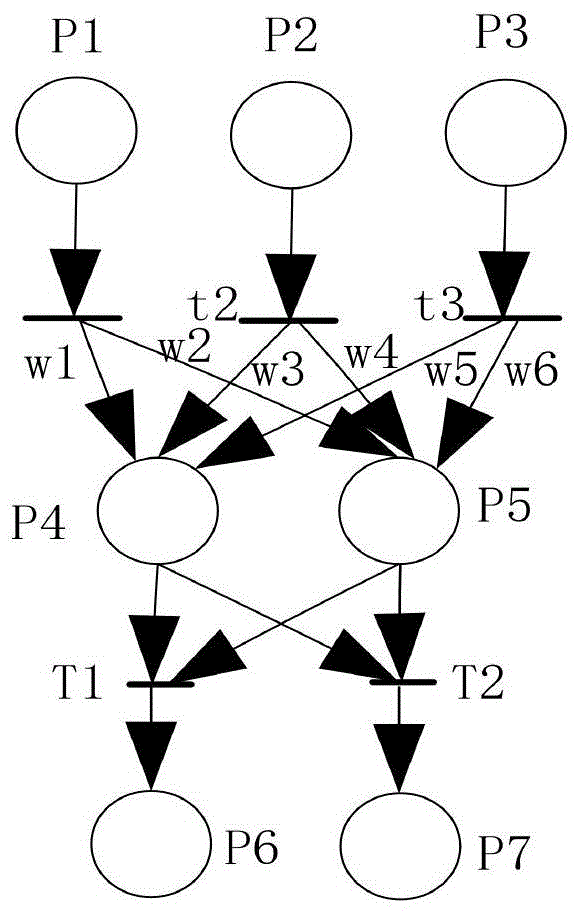
图1是本发明中petri系统网络结构图;
图2是本发明中拖拉机发动机起动困难系统诊断网络结构图;
图3是本发明中对petri网络模糊处理的模糊网络框图;
图4是本发明中petri网络故障诊断结构图;
图5是本发明中petri网络变迁状态发生流程图。
具体实施方式
下面将对本发明做进一步说明。
如图所示,本发明具体步骤为:
a、建立拖拉机发动机的故障征兆和原因的数据信息:收集拖拉机发动机的各种故障征兆和原因的相关数据,然后形成关于故障征兆和原因的故障数据集,根据故障征兆和原因的故障数据集对采集的拖拉机发动机数据进行筛选(即剔除与故障征兆和原因不相关的数据),由于拖拉机发动机数据中有转速、油压、冷却液温度、扭矩,这些参数的单位、数量级都不相同,为了使后续使用数据方便,因此进行数据标准化处理;最终将数据通过标准化的方法(如标准差法)整理成标准化的故障数据集;
b、确定模糊神经petri网络的输入量、输出量及中间变量:在拖拉机发动机状态参数中选取发动机转速值、冷却液温度值、燃油率、扭矩值作为输入量;选取这四组发动机状态参数作为特征参量,因为这几个参数对发动机的运行状态有着高度的敏感性,而且方便检测,更重要的是系统状态与征兆参量之间存在一一对应的关系;然后选取发动机油耗过高、发动机起动困难、发动机怠速不稳和冷却液温度过高,这四种故障征兆作为中间变量;将发动机发生故障作为输出量;
c、输入量与中间变量的模糊化处理:通过查询现有的拖拉机发动机故障文献及结合本领域技术人员的公知常识对发动机转速值、冷却液温度值、燃油率、扭矩值进行模糊化处理,将发动机故障征兆和故障原因以知识表达式规则的形式建立对应关系;发动机各参量的调控要确保发动机的运行状态,且各参量是相互影响的;
d、构建模糊神经petri网络模型:模糊神经petri网络模型采用分级诊断网络模块的方法,,共分成三级诊断模块,其中第三级诊断模块为基本故障事件诊断模块,指通过测得的数据经过相关网络模型计算分析判断得到的故障诊断子模块;第二级诊断模块为中间故障事件诊断模块,指的是系统通过基本故障事件的分析,通过相关网络模型的分析得到的故障诊断模块;第一级诊断模块为终事件模块,指由中间事件故障得到的关于设备故障的诊断模块。这三级诊断模块是逐一递进的关系,犹如树状结构的形式;对于各个级别的诊断网络,相同结点采用数值调用的方式,具有相同的诊断信息;在模糊神经petri网络模型中,变迁的发生即拖拉机发动机故障征兆的发生;对模糊神经petri网络模型中的各个库所进行权值分配,将模糊神经petri网络模型(fnpn)定义为十二元组,即
fnpn=(p,t,d,a,w,s,kp,kt,cf,α,β,θ)
其中,p,t,d,a,w,s,kp,kt,cf,α,β,θ的定义分别是p=(p1,p2,...,pn)为有限库的集合;t=(t1,t2,...,tn)为变迁的有限集合;d=(k,g,u)为命题集合,其中k=(k1,k2,...,kn)为初始命题集,g=(g1,g2,...,gn)为中间命题集,u=(u1,u2,...,un)为结论命题集;a为有向弧的集合;s=(sp,st)为状态集合,sp为库所的状态集合,st为变迁的状态集合;cf为变迁引发结果的可信度;α为库所到真值的一一映射;β为库所与命题的一一映射;θ为变迁阈值;w为输入库所对应的变迁的权值集合,w=(w1,w2,...,wn),n为一个输入库所对应的变迁的个数,且满足
如图1所示,p1,p2,p3为输入库所;p4,p5为隐含库所;p6,p7为输出库所。输入库所主要就是托肯传递,不具备数据处理的能力,这些托肯值从外界观察而来,是模糊神经petri网络的初始标识。输入变迁t1~t3为普通变迁,不具有阈值的功能。由于一个输入库所对应一个变迁,则输入库所和变迁之间的权值为1,输出库p6,p7所根据f函数计算而来,当输出值超出阈值θi时,变迁ti将被激活;
如图5所示,由于模糊神经petri网络模型的一个变迁发生后,输入库所的托肯值并不发生改变,因此在该网络中设置一个变迁发生标志位flag,一个计数位count,一个网络层级标志位lr,一个最大网络层级标志位mlr和一个阈值位thr;当一个变迁发生后,将flag置为1,同时计数位count自动加1,当满足条件count≥thr时,自动转入下一层次的变迁过程;在故障诊断的过程中,每发生一次变迁,即有标志位标出,这样可以预防变迁复发生;
对于一个变迁t∈t,t为拖拉机发动机采集数据的时间段;若存在
一个变迁引发后,它的输入库所当中的标记值不会改变,而会向输出库所传递新的标记值;这个标记值规定如下:若库所p是单个变迁的输出,则输出库所的标记值为m(p)=k×πiu(pi),pi∈i(t),k为变迁可信度;若库所p为多个变迁的输出库所时,m(p)=πikj{1-πiu(pij)},
e、采用模糊神经petri网络模型对拖拉机发动机故障诊断及预测:将实时采集的拖拉机发动机状态特征参数输入模糊神经petri网络模型,在拖拉机出现相应的故障征兆时,模糊神经petri网络模型实现对拖拉机发动机的故障诊断及预测。
其中,所述步骤c中知识表达式规则的具体得出过程为:模糊产生式规则常用于表述事件的不确定性关系,常常用if(aandb),then(candd)之类形式表述;设拖拉机发动机故障诊断规则库有n条规则r(r1,r2,...,rn),那么第k条的模糊产生式规则的表述形式为:
rk:ifakthenbk(cf=σk)
其中ak代表的是故障症状,取值范围是ak∈(0,1);bk代表的是故障原因,σk代表的是第k条规则的置信度,σk越大,则第k条规则越可信;
将模糊神经petri网络共分为六层,依次为输入层、隶属度函数生成层、规则推理层、模糊化层、去模糊化层、输出层,该网络的推理过程如下:
输入层:将输入的信号变换到[0,1]论域中,系统将根据输入量的变化自动调整连接权系数;
隶属度函数生成层:该层寻找一个模糊隶属函数,确定各输入量的模糊隶属程度,选用高斯函数
αjl(xj)=exp(-(xj*-bjl)2/σjl2),l=1,2,...,n
其中bjl,σjl分别为隶属函数的中心和宽度,j为隶属度函数所在层数,l为层中的节点数,由此得到该层的输出为:
oil=αjl,l=1,2,...,mj,j=1,2,...,n,i=1,2,....,m
规则推理层:在模糊推理中采用madina推理算法,即由隶属函数的最小值算出;
模糊化层:将节点采用n表示,它对各条规则的适用度做归一化处理;
去模糊化层:把模糊集合映射成精确输出集合,采用重心加权求和的方法,得到精确输出;
输出层:该层节点是固定节点,其输出为:
最终将步骤b中确定的输入量根据上述各层规则计算得出各自的知识表达式规则;具体为:
1、“油耗过高”=0.9/100km油耗高出出厂标定90%以上+0.7/100km油耗高出出厂标定60%以上+0.3/100km油耗高出出厂标定30%以上+0.1/100km油耗高出出厂标定10%以下
2、“发动机起动困难”=1/发动机不转动+0.8/发动机转动但点不着火+0.3/能起动但立即熄火+0/能正常起动
3、“发动机怠速不稳”=1/不能怠速+0.7/怠速时发动机抖动剧烈+0.4/怠速时发动机转速不平稳+0/怠速时发动机转速平稳
4、“冷却液温度过高”=1/100℃以上+0.7/95℃~100℃+0.3/85℃~95℃+0/85℃以下
其中,所述步骤d中学习训练的具体过程为:
步骤1:对模糊神经petri网络进行初始化,设定各个权值及变迁可信度的初始值,给相应的输入命题和中间命题的总个数赋值为m,变迁的总个数赋值为n,样本总数赋n,i和j分别为1,学习步长为ξ;
步骤2:由目标函数的设计思路,按照目标误差不大于误差限的思想在网络中自动生成目标函数为
步骤3:由初始权值和可信度以及前面的引发规则计算出一组网络的可靠度,得到初始误差为
步骤4:依据公式
步骤5:依据调整后的权值,重新计算得到的误差值,将当前计算得到的误差值fi同fi-1进行比较,若有fi<fi-1,则转至步骤4,否则进入下一步;
:步骤6:改变动量因子α的值,重新调整原来的权值,说明原来的权值调整方式不正确;
步骤7:令i=i+1,判断i是否大于n,若不大于,则转向步骤3,将权值加以调整;否则转入下一步;
步骤8:判断此时的fi是否已经达到规定的误差限,若已经达到,则结束训练;若还没有达到,判断权值训练次数是否超过规定的训练次数,若没有,则将fi赋给f0并重新使得i=1转到步骤3,开始下一轮的训练;如果已经超过了规定的训练次数,则进行下一步;
步骤9:对可信度进行训练,逐个调整信任度,使其不超过1,并逐次计算误差值fk并判断是否达到误差限,若已达到,则结束训练;若还未达到,则一直调整可信度直到达到规定的可信度训练次数为止,若此时还未达到要求,则要修改引发条件和模糊规则,返回步骤1重新进行训练。
- 还没有人留言评论。精彩留言会获得点赞!