胃癌分型的蛋白标志物的筛选方法、筛选装置及其筛选的蛋白标志物的应用与流程
本发明涉及肿瘤检测领域,具体而言,涉及一种胃癌分型的蛋白标志物的筛选方法、筛选装置及其筛选的蛋白标志物的应用。
背景技术:
胃癌在全球肿瘤死亡原因中排名第三,我国是胃癌高发地区之一,每年新发病例接近全世界的一半左右。目前对胃癌的预后的评估手段主要有三种:第一种是基于组织形态学的lauren分型,该分型将胃癌分为肠型、弥漫型以及混合型。其中,肠型胃癌预后最好,5年生存率65%;弥漫型胃癌预后最差,5年生存率48%。第二种是tnm分期,该分期按照肿瘤的大小、侵袭能力、淋巴结节个数以及是否发生近端或者远端转移,对胃癌病人进行分期。其中预后最好的是iia型,5年生存率78%;预后最差的是iiic型,5年生存率15%。第三种是acrg研究机构的基于基因组和转录组的分型,分别为:msi型、微卫星稳定/上皮细胞向间充质细胞转化型(mss/emt)、微卫星稳定/tp53阳性型和微卫星稳定/tp53阴性型。其中msi型预后最好,5年生存率71%;mss/emt型预后最差,5年生存率33%。
lauren分型的方法对预后的评估能力最为有限,其中5年生存率差异最大仅为17%(肠型65%;弥漫型48%)。这三种方法中,tnm分期能够最好地对胃癌患者的预后进行评估,其中5年生存率差异最大为63%(iia型78%;iiic型15%)。然而,不管是lauren分型还是tnm分型,都存在一个问题,就是这两种预后评估的方法都不是基于分子的胃癌预后评估方法,因此无法为患者的化疗用药方案提出个性化的选择。
acrg的基于基因组的胃癌分型首次从分子层面对胃癌进行分析,基于该方法的预后评估能力虽然比tnm分型要差(5年生存率差异最大为35.85%(msi型71%;mss/emt型33%),却从某种程度上解释了胃癌的成因。然而,基于基因组的方法依然无法对患者的化疗和不同药物的选择,给出有效的预后评估。
因此,如何更准确地对人群中的胃癌进行分型已成为了一个亟待解决的问题。
技术实现要素:
本发明的主要目的在于提供一种胃癌分型的蛋白标志物的筛选方法、筛选装置及其筛选的蛋白标志物的应用,以更准确地对人群中的胃癌进行分型。
为了实现上述目的,根据本发明的一个方面,提供了一种胃癌分型蛋白标志物的筛选方法,该筛选方法包括:从多个样本形成的蛋白表达质谱数据库中筛选出满足保留条件的蛋白,作为有效蛋白集;对有效蛋白集依次进行两次降维处理,得到降维蛋白集;对降维蛋白集进行聚类分析,得到不同类别的蛋白标志物。
进一步地,两次降维处理包括:采用主成分分析法对有效蛋白集进行第一次降维处理,得到第一降维数据集;采用t-sne对第一降维数据集进行第二次降维处理,得到降维蛋白集。
进一步地,保留条件包括质量条件和/或频次条件,质量条件包括如下至少之一:具有至少两条满足质量要求的肽段且其中至少一条为满足质量要求的唯一性肽段、至少具有三条满足质量要求的肽段;频次条件为至少在80%的样本中都出现的蛋白。
进一步地,采用t-sne对第一降维数据集进行第二次降维处理的步骤中,学习速率设为10~500,迭代次数设为7500以上,迭代停止设为100~400。
进一步地,聚类分析的步骤中,类内平均距离≤4.58,类间平均距离≥9.68。
进一步地,在对有效蛋白集依次进行两次降维处理之前,方法还包括:对有效蛋白集进行标准化处理,得到标准化的有效蛋白集;优选地,标准化处理是指使有效蛋白集中的蛋白的均值为0,方差为1。
进一步地,不同类别的蛋白标志物为基于方差检验p值小于10的-35次方的蛋白标志物;优选地,基于方差检验p值小于10的-35次方的蛋白标志物包括:c0,h2afz、h2afj、h2afv;c1,actg2、acta2、actc1;c2,flna、col6a2、col6a1;c3,tubb2b、tubb2a、tubb;c4,h3f3c、h3f3a、h3f3b;c5,x;c6,pabpc1、hnrnpk、ddx39b。
进一步地,不同类别的蛋白标志物还包括基于方差检验p值低于10的-20次方的蛋白标志物,优选地,基于方差检验p值低于10的-20次方的蛋白标志物包括:
c0,hist2h2ac、hist2h2aa3、hist2h2aa4、hist1h2aj、hist1h2al、hist1h2ag、hist1h2am、hist1h2ai、hist1h2ak、hist1h2ah、hist1h2ad、hist1h2aa、hist1h2ac、hist1h2ae、hist1h2ab、hist3h2a、h2afx、rps3a、hist1h1b、eef1a2、ran、lmnb1、hist2h2ab;
c1,acta1、des、synm、myl9、pgm5、sorbs1;
c2,tpm1、myh11、tpm2、lmod1、tagln、myh10、ehd2、col6a3、flnc、cnn1、hspb6、tpm4、synpo2、mylk、cald1、dpysl3、cryab、actn1、tf、tln1、vcl、hspg2、tgfbi、ckb、tpm3、kng1、pdlim7、ilk、rras、csrp1、lum、ttr、sod3、myl6、alb、aoc3、ogn、actbl2;
c3,tubb3、tuba3d、tuba3c、tuba3e、capza2、iqgap1、tubb4b、gdi1、hpx、myh9、tuba4a、tubb6、tuba1a、tuba1c、tuba1b、tubb4a、anxa5、pls3、capza1、actr2、srsf3、npepps、cltcl1、serpinh1、pdlim3、hnrnpd、tuba8;
c4,hist3h3、hist1h3a、hist1h3d、hist2h3c、hist2h3a、hist2h3d、hist1h3c、hist1h3j、hist1h3i、hist1h3b、hist1h3f、hist1h3e、hist1h3g、hist1h3h;
c5,x;
c6,hspa8、ddx39a、eif4a1、pabpc3、eef1g、hnrnpm、rpn1、rpl4、ncl、ilf3、dhx9、rps9、rps19、rps4x、xrcc5、hnrnpr、hsp90aa1、syncrip、rps15a、eif4a3、ganab、rbmx、eef2、rpl13a、rpl7、rps16、psma6、rps24、fubp1、eif4a2、eif2s1、rpl36、srsf1、rpl7a、rplp0、rpl6、tubb8、arf1、arf3、rpsa、rab14、eef1a1、rpl27、dhx15、ilf2、srsf7、stip1、hnrnpa2b1、rpl10a、rpl23a、arf4、rps18、rpl38、nme1-nme2、gnb2l1、rps6、pdia6、hnrnpa1、pa2g4、rps3、rab7a、nono、rpl9、ywhaq、qars、pdia3、hnrnpa3、cct5、rps20、xrcc6、hsp90ab1、rps28、pcbp2、hnrnph2、ddx3x、arpc1b、tagln2、eif3f、ddost、hspa4、hnrnpa1l2、cndp2、ppib、ctnnd1、rps13、hspa9、prkdc、rps27a、ubb、uba52、ubc、cct6a、rpl15、nme2、eif3a、hnrnpc、rpl13、khsrp、ddx5、sarnp、alyref、atp2a2、elavl1、ruvbl2、atp6v1a、rab5c、uba1、cct8、stt3b、hspa2、copb2、dad1、p4hb、rrbp1、rpl24、hsp90b1、efhd2、pgd、ddx3y、anxa2、eef1d、arcn1、ywhab、pkm、psma7、idh1、sars、snrnp200、psmd2、hnrnpf、tmed10、hnrnph1、eno1、eif6、hnrnph3、pgk2、parp1、hdlbp、stt3a、prdx6、hspd1、pgk1、phb、ppa1、hspe1、dnm2、capn1、otub1、atp6v1b2。
根据本申请的第二个方面,提供了一种人群中胃癌的分型方法,分型方法包括利用上述任一种胃癌分型蛋白标志物的筛选方法所筛选到的不同类别的蛋白标志物进行分型,得到不同的分型。
根据本申请的第三个方面,提供了一种对个体胃癌样本进行分型的方法,包括按照胃癌分型标准进行分型,胃癌分型标准为上述任一种筛选方法筛选到的不同类别的蛋白标志物所划分的不同的分型,或者上述任一种人群中胃癌的分型方法所获得的不同的分型。
根据本申请的第四个方面,提供了一种对个体胃癌样本进行分型的方法,该方法包括:根据上述任一种人群中胃癌的分型方法对已知胃癌样本集进行分型;从待测胃癌样本的蛋白质谱数据中筛选出符合保留条件的蛋白,作为待测蛋白集;按照与已知胃癌样本集中的有效蛋白集相同的条件,对待测蛋白集依次进行两次降维处理,得到待测胃癌样本的降维蛋白集;对待测胃癌样本的降维蛋白集进行聚类分析,得到与已知胃癌样本集中相似度最高的分型即为待测胃癌样本对应的分型。
进一步地,两次降维处理包括:采用主成分分析法对待测蛋白集进行第一次降维处理,得到第一降维数据集;采用t-sne对第一降维数据集进行第二次降维处理,得到降维蛋白集。
进一步地,保留条件包括质量条件和/或频次条件,质量条件包括如下至少之一:具有至少两条满足质量要求的肽段且其中至少一条为满足质量要求的唯一性肽段、至少具有三条满足质量要求的肽段;频次条件为至少在已知胃癌样本集中80%的样本中都出现的蛋白。
进一步地,采用与对已知胃癌样本集中的蛋白质谱数据进行主成分分析降维处理相同的参数,对待测胃癌样本的蛋白质谱数据进行第一次降维处理,得到第一降维数据集。
进一步地,采用与对已知胃癌样本集中的蛋白质谱数据进行t-sne降维处理相同的参数,对第一降维数据进行第二次降维处理,得到降维蛋白集。
进一步地,聚类分析的步骤中,类内平均距离≤4.58,类间平均距离≥9.68。
进一步地,在对有效蛋白集依次进行两次降维处理之前,方法还包括:对有效蛋白集进行标准化处理,得到标准化的有效蛋白集;优选地,标准化处理是指使有效蛋白集中的蛋白的均值为0,方差为1。
根据本申请的第五个方面,提供了一种检测胃癌的试剂、试剂盒或芯片,其中,试剂、试剂盒或芯片包括上述任一种筛选方法筛选得到的不同类别的蛋白标志物。
进一步地,检测包括分型诊断、生存预后评估及化疗治疗用药筛选中的任意一种或多种。
根据本申请的第六个方面,提供了上述任一种筛选方法筛选得到的不同类别的蛋白标志物在制备用于检测胃癌的试剂、试剂盒或芯片中的应用。
进一步地,蛋白标志物为表达量在所属类别中显著高于在其余类别中的蛋白标志物。
进一步地,检测包括分型诊断、生存预后评估及化疗治疗用药筛选中的任意一种或多种。
根据本申请的第七个方面,提供了一种胃癌分型蛋白标志物的筛选装置,该筛选装置包括:筛选模块a,用于从多个样本形成的蛋白表达质谱数据库中筛选出满足保留条件的蛋白,作为有效蛋白集;降维模块a,用于对有效蛋白集依次进行两次降维处理,得到降维蛋白集;聚类分型模块a,用于对降维蛋白集进行聚类分析,得到不同类别的蛋白标志物。
进一步地,降维模块a包括:主成分降维模块a,用于采用主成分分析法对有效蛋白集进行第一次降维处理,得到第一降维数据集;t-sne降维模块a,用于采用t-sne对第一降维数据集进行第二次降维处理,得到降维蛋白集。
进一步地,保留条件包括质量条件和/或频次条件,质量条件包括如下至少之一:具有至少两条满足质量要求的肽段且其中至少一条为满足质量要求的唯一性肽段、具有三条满足质量要求的肽段;频次条件为至少在80%的样本中都出现的蛋白。
进一步地,t-sne降维模块a中:学习速率设为10~500,迭代次数设为7500以上,迭代停止设为100~400。
进一步地,聚类分型模块a中,类内平均距离≤4.58,类间平均距离≥9.68。
进一步地,筛选装置还包括:标准化处理模块a,用于对有效蛋白集进行标准化处理,得到标准化的有效蛋白集;优选地,标准化处理模块a用于指使有效蛋白集中的蛋白的均值为0,方差为1。
进一步地,不同类别的蛋白标志物为基于方差检验p值小于10的-35次方的蛋白标志物;优选地,基于方差检验p值小于10的-35次方的蛋白标志物包括:c0,h2afz、h2afj、h2afv;c1,actg2、acta2、actc1;c2,flna、col6a2、col6a1;c3,tubb2b、tubb2a、tubb;c4,h3f3c、h3f3a、h3f3b;c5,x;c6,pabpc1、hnrnpk、ddx39b。
进一步地,不同类别的蛋白标志物还包括基于方差检验p值低于10的-20次方的蛋白标志物,优选地,基于方差检验p值低于10的-20次方的蛋白标志物包括:
c0,hist2h2ac、hist2h2aa3、hist2h2aa4、hist1h2aj、hist1h2al、hist1h2ag、hist1h2am、hist1h2ai、hist1h2ak、hist1h2ah、hist1h2ad、hist1h2aa、hist1h2ac、hist1h2ae、hist1h2ab、hist3h2a、h2afx、rps3a、hist1h1b、eef1a2、ran、lmnb1、hist2h2ab;
c1,acta1、des、synm、myl9、pgm5、sorbs1;
c2,tpm1、myh11、tpm2、lmod1、tagln、myh10、ehd2、col6a3、flnc、cnn1、hspb6、tpm4、synpo2、mylk、cald1、dpysl3、cryab、actn1、tf、tln1、vcl、hspg2、tgfbi、ckb、tpm3、kng1、pdlim7、ilk、rras、csrp1、lum、ttr、sod3、myl6、alb、aoc3、ogn、actbl2;
c3,tubb3、tuba3d、tuba3c、tuba3e、capza2、iqgap1、tubb4b、gdi1、hpx、myh9、tuba4a、tubb6、tuba1a、tuba1c、tuba1b、tubb4a、anxa5、pls3、capza1、actr2、srsf3、npepps、cltcl1、serpinh1、pdlim3、hnrnpd、tuba8;
c4,hist3h3、hist1h3a、hist1h3d、hist2h3c、hist2h3a、hist2h3d、hist1h3c、hist1h3j、hist1h3i、hist1h3b、hist1h3f、hist1h3e、hist1h3g、hist1h3h;
c5,x;
c6,hspa8、ddx39a、eif4a1、pabpc3、eef1g、hnrnpm、rpn1、rpl4、ncl、ilf3、dhx9、rps9、rps19、rps4x、xrcc5、hnrnpr、hsp90aa1、syncrip、rps15a、eif4a3、ganab、rbmx、eef2、rpl13a、rpl7、rps16、psma6、rps24、fubp1、eif4a2、eif2s1、rpl36、srsf1、rpl7a、rplp0、rpl6、tubb8、arf1、arf3、rpsa、rab14、eef1a1、rpl27、dhx15、ilf2、srsf7、stip1、hnrnpa2b1、rpl10a、rpl23a、arf4、rps18、rpl38、nme1-nme2、gnb2l1、rps6、pdia6、hnrnpa1、pa2g4、rps3、rab7a、nono、rpl9、ywhaq、qars、pdia3、hnrnpa3、cct5、rps20、xrcc6、hsp90ab1、rps28、pcbp2、hnrnph2、ddx3x、arpc1b、tagln2、eif3f、ddost、hspa4、hnrnpa1l2、cndp2、ppib、ctnnd1、rps13、hspa9、prkdc、rps27a、ubb、uba52、ubc、cct6a、rpl15、nme2、eif3a、hnrnpc、rpl13、khsrp、ddx5、sarnp、alyref、atp2a2、elavl1、ruvbl2、atp6v1a、rab5c、uba1、cct8、stt3b、hspa2、copb2、dad1、p4hb、rrbp1、rpl24、hsp90b1、efhd2、pgd、ddx3y、anxa2、eef1d、arcn1、ywhab、pkm、psma7、idh1、sars、snrnp200、psmd2、hnrnpf、tmed10、hnrnph1、eno1、eif6、hnrnph3、pgk2、parp1、hdlbp、stt3a、prdx6、hspd1、pgk1、phb、ppa1、hspe1、dnm2、capn1、otub1、atp6v1b2。
根据本申请的第八个方面,提供了一种人群胃癌分型装置,该胃癌分型装置包括:筛选模块b,用于从多个样本形成的蛋白表达质谱数据库中筛选出满足保留条件的蛋白,作为有效蛋白集;降维模块b,用于对有效蛋白集依次进行两次降维处理,得到降维蛋白集;聚类分型模块b,用于对降维蛋白集进行聚类分析,得到按照不同类别的蛋白标志物所划分的不同的分型。
进一步地,降维模块b包括:主成分降维模块b,用于采用主成分分析法对有效蛋白集进行第一次降维处理,得到第一降维数据集;t-sne降维模块b,用于采用t-sne对第一降维数据集进行第二次降维处理,得到降维蛋白集。
进一步地,保留条件包括质量条件和/或频次条件,质量条件包括如下至少之一:具有至少两条满足质量要求的肽段且其中至少一条为满足质量要求的唯一性肽段、至少具有三条满足质量要求的肽段;频次条件为至少在80%的样本中都出现的蛋白。
进一步地,t-sne降维模块b中:学习速率设为10~500,迭代次数设为7500以上,迭代停止设为100~400。
进一步地,聚类分型模块b中,类内平均距离≤4.58,类间平均距离≥9.68。
进一步地,胃癌分型装置还包括标准化处理模块b,用于对有效蛋白集进行标准化处理,得到标准化的有效蛋白集;优选地,标准化处理模块b用于使有效蛋白集中的蛋白的均值为0,方差为1。
进一步地,不同类别的蛋白标志物为基于方差检验p值小于10的-35次方的蛋白标志物;优选地,基于方差检验p值小于10的-35次方的蛋白标志物包括:c0,h2afz、h2afj、h2afv;c1,actg2、acta2、actc1;c2,flna、col6a2、col6a1;c3,tubb2b、tubb2a、tubb;c4,h3f3c、h3f3a、h3f3b;c5,x;c6,pabpc1、hnrnpk、ddx39b。
进一步地,不同类别的蛋白标志物还包括基于方差检验p值低于10的-20次方的蛋白标志物,优选地,基于方差检验p值低于10的-20次方的蛋白标志物包括:
c0,hist2h2ac、hist2h2aa3、hist2h2aa4、hist1h2aj、hist1h2al、hist1h2ag、hist1h2am、hist1h2ai、hist1h2ak、hist1h2ah、hist1h2ad、hist1h2aa、hist1h2ac、hist1h2ae、hist1h2ab、hist3h2a、h2afx、rps3a、hist1h1b、eef1a2、ran、lmnb1、hist2h2ab;
c1,acta1、des、synm、myl9、pgm5、sorbs1;
c2,tpm1、myh11、tpm2、lmod1、tagln、myh10、ehd2、col6a3、flnc、cnn1、hspb6、tpm4、synpo2、mylk、cald1、dpysl3、cryab、actn1、tf、tln1、vcl、hspg2、tgfbi、ckb、tpm3、kng1、pdlim7、ilk、rras、csrp1、lum、ttr、sod3、myl6、alb、aoc3、ogn、actbl2;
c3,tubb3、tuba3d、tuba3c、tuba3e、capza2、iqgap1、tubb4b、gdi1、hpx、myh9、tuba4a、tubb6、tuba1a、tuba1c、tuba1b、tubb4a、anxa5、pls3、capza1、actr2、srsf3、npepps、cltcl1、serpinh1、pdlim3、hnrnpd、tuba8;
c4,hist3h3、hist1h3a、hist1h3d、hist2h3c、hist2h3a、hist2h3d、hist1h3c、hist1h3j、hist1h3i、hist1h3b、hist1h3f、hist1h3e、hist1h3g、hist1h3h;
c5,x;
c6,hspa8、ddx39a、eif4a1、pabpc3、eef1g、hnrnpm、rpn1、rpl4、ncl、ilf3、dhx9、rps9、rps19、rps4x、xrcc5、hnrnpr、hsp90aa1、syncrip、rps15a、eif4a3、ganab、rbmx、eef2、rpl13a、rpl7、rps16、psma6、rps24、fubp1、eif4a2、eif2s1、rpl36、srsf1、rpl7a、rplp0、rpl6、tubb8、arf1、arf3、rpsa、rab14、eef1a1、rpl27、dhx15、ilf2、srsf7、stip1、hnrnpa2b1、rpl10a、rpl23a、arf4、rps18、rpl38、nme1-nme2、gnb2l1、rps6、pdia6、hnrnpa1、pa2g4、rps3、rab7a、nono、rpl9、ywhaq、qars、pdia3、hnrnpa3、cct5、rps20、xrcc6、hsp90ab1、rps28、pcbp2、hnrnph2、ddx3x、arpc1b、tagln2、eif3f、ddost、hspa4、hnrnpa1l2、cndp2、ppib、ctnnd1、rps13、hspa9、prkdc、rps27a、ubb、uba52、ubc、cct6a、rpl15、nme2、eif3a、hnrnpc、rpl13、khsrp、ddx5、sarnp、alyref、atp2a2、elavl1、ruvbl2、atp6v1a、rab5c、uba1、cct8、stt3b、hspa2、copb2、dad1、p4hb、rrbp1、rpl24、hsp90b1、efhd2、pgd、ddx3y、anxa2、eef1d、arcn1、ywhab、pkm、psma7、idh1、sars、snrnp200、psmd2、hnrnpf、tmed10、hnrnph1、eno1、eif6、hnrnph3、pgk2、parp1、hdlbp、stt3a、prdx6、hspd1、pgk1、phb、ppa1、hspe1、dnm2、capn1、otub1、atp6v1b2。
根据本申请的第九个方面,提供了一种对个体胃癌样本进行分型的装置,该装置包括:胃癌分型装置,用于根据已知胃癌样本集对胃癌进行分型,胃癌分型装置为上述任一种胃癌分型装置;筛选模块c,用于从待测胃癌样本的蛋白质谱数据中筛选出符合保留条件的蛋白,作为待测蛋白集;降维模块c,用于按照与胃癌分型装置中对已知胃癌样本集中的有效蛋白集相同的条件,对待测蛋白集依次进行两次降维处理,得到待测胃癌样本的降维蛋白集;聚类分型模块c,用于对待测胃癌样本的降维蛋白集进行聚类分析,得到与已知胃癌样本集中相似度最高的分型即为待测胃癌样本对应的分型。
进一步地,降维模块c包括:主成分降维模块c,用于采用主成分分析法对待测蛋白集进行第一次降维处理,得到第一降维数据集;t-sne降维模块c,用于采用t-sne对第一降维数据集进行第二次降维处理,得到降维蛋白集。
进一步地,保留条件包括质量条件和/或频次条件,质量条件包括如下至少之一:具有至少两条满足质量要求的肽段且其中至少一条为满足质量要求的唯一性肽段、至少具有三条满足质量要求的肽段;频次条件为至少在已知胃癌样本集中80%的样本中都出现的蛋白。
进一步地,主成分降维模块c中,降维处理的参数设置与分型装置中对已知胃癌样本集中的蛋白质谱数据进行主成分分析降维处理的参数相同。
进一步地,t-sne降维模块c中:降维处理的参数设置与分型装置中对已知胃癌样本集中的蛋白质谱数据进行t-sne降维处理的参数相同。
进一步地,聚类分型模块c中,类内平均距离≤4.58,类间平均距离≥9.68。
进一步地,装置还包括标准化处理模块c,用于对待测蛋白集进行标准化处理,得到标准化的待测蛋白集;优选地,标准化处理模块c用于使待测蛋白集中的蛋白的均值为0,方差为1。
根据本申请的第十个方面,提供了一种存储介质,该存储介质包括存储的程序,其中,程序执行上述任一种胃癌分型蛋白标志物的筛选方法;或者程序执行上述任一种对人群中胃癌进行分型的方法;或者程序执行上述任一种对个体胃癌样本进行分型的方法。
根据本申请的第十一个方面,提供了一种处理器,处理器用于运行程序,其中,其中,程序执行上述任一种胃癌分型蛋白标志物的筛选方法;或者程序执行上述任一种对人群中胃癌进行分型的方法;或者程序执行上述任一种对个体胃癌样本进行分型的方法。
应用本发明的技术方案,。
附图说明
构成本申请的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
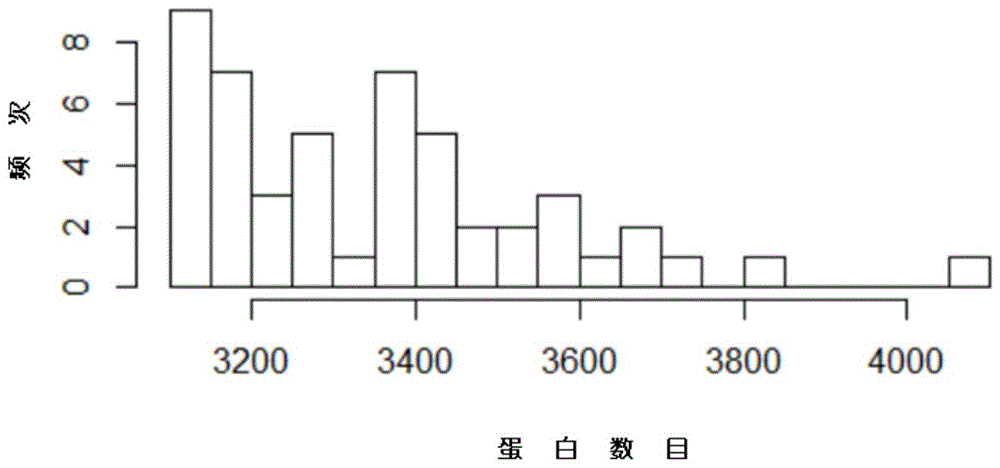
图1示出了根据本发明的实施例1的50例样本中,每例样本可鉴定到的蛋白数目(3109~4064个)。
图2示出了实施例1聚类分析而分成的7种不同的类(cluster)对应7种胃癌分型。
图3示出了图2中不同的分型的胃癌之间在生存率上存在的显著差异,其中c0型生存预后效果最好,其次是c4型,最差为c2型。
图4示出了图2中c6分型的患者的生存与化疗治疗的预后生存率之间的关系。
图5示出了根据本发明的实施例3中的224例样本的术后生存时间与分型结果之间的关系,术后生存时间显示c0型生存预后效果最好,其次是c4型,最差为c2型,与实施例1所提供的分型的预测结果一致。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将结合实施例来详细说明本发明。
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分的实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本申请保护的范围。
需要说明的是,本申请的说明书和权利要求书中的术语“……a模块”、“……b模块”、“……c模块”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本申请的实施例。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
为了便于描述,以下对本申请实施例涉及的部分名词或术语进行说明:
蛋白质组学:是指利用高分辨率的蛋白质分离技术和高效的蛋白质鉴定技术在蛋白质水平上整体性、动态和定量地研究生命现象及规律的科学。
蛋白质组学的定性原理:随着高效液相色谱技术和静电场轨道阱质谱技术的发展,液相色谱串联质谱(lc-ms/ms)成为研究蛋白质组学的主要技术,其鉴定蛋白的基本步骤(bottom-up)包括:收集样本后进行总蛋白提取---消化切割蛋白为多肽片段---hplc分离---分级进入ms电场进一步离子化---ms获得各离子质荷比和峰型信息---软件计算氨基酸组成---数据库检索比对获得蛋白质的定性和序列信息。
降维:即在2维或3维中展现多维数据的技术。常见的降维方法有:主成分分析法、t-sne、萨蒙映射、等距映射、局部线性嵌入、规范相关分析、sne、最小方差无偏估计及拉普拉斯特征图等。
主成分分析法(principalcomponentanalysis,pca)将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法,又称主分量分析。
t-sne:t-分布式随机邻域嵌入是一种用于挖掘高纬数据的非线性降维算法。它将多维数据映射到适合人类观察的2个或3个维度。
聚类分析:(clusteranalysis)又称群分析,根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法,其所讨论的对象是大量的样品,能够按各自的特性进行合理地分类,没有任何模式可供参考或依循,即是在没有先验知识的情况下进行的。其是将研究对象分为相对同质的群组/簇(clusters)的统计分析方法,所以同一簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。
质谱数据一般有以下特征参数:psm、peptide、uniquepeptides、strictpeptides、protein,psm是拿数据库中的多肽与质谱图进行比对,并输出最高分数值的多肽作为一个psm,psm值越高,则表明可信度相对越高。蛋白质(protein)由肽段(peptide)组装而来,因此一种蛋白质可以对应很多肽段,而检测到的肽段数目越多,则说明该种蛋白确实被鉴定到的几率越大。由于质谱检测到的有些肽段只在某一种蛋白中出现,因此当鉴定到这种肽段时,我们就可以确信对应的该种蛋白的出现,这些肽段我们称之为唯一性肽段(uniquepeptide)。此外,如果肽段在搜库软件mascot中的ionscore打分值很高(大于20分),则称该肽段为高质量肽段(strictpeptide),这一衡量标准也能够比较好的表征该蛋白的存在。
如背景技术所提到的,现有技术中胃癌的分型标准不够准确,为了进一步提高胃癌分型的准确性,本申请的发明人对现有的分型进行了改进研究,认为现有的分型不够准确的原因在于,要么是从发病部位进行分型,要么是从外观症状进行分型,而acrg分型虽然提出了从分子层面上对胃癌进行分型,但这种分型仅是基因层面上的,仅仅通过基因组无法预测实际的生命活动,因为蛋白质才是生命活动的执行者,只有通过蛋白质组层面上的变化才能更接近真实的生命活动状况。为此,本申请从蛋白质组学的层面上探究了与胃癌相关的蛋白标志物,并根据这些蛋白标志物的不同分子特征与临床上术后生存时间之间的关系,将胃癌进行了分型,这种分型结果相对更准确,对不同胃癌状况的生存预后评估相对更准确,从而也更有利于进行化疗治疗的用药指导,因而临床应用价值高。
在上述研究结果的基础上,申请人提出了本申请的技术方案。在一种典型的实施方式中,提供了一种筛选胃癌分型蛋白标志物的方法,该方法包括:从多个样本形成的蛋白表达质谱数据库中筛选出满足保留条件的蛋白,作为有效蛋白集;对有效蛋白集依次进行两次降维处理,得到降维蛋白集;对降维蛋白集进行聚类分析,得到不同类别的蛋白标志物。
本申请的上述筛选胃癌分型蛋白标志物的方法,通过先从从多个样本形成的蛋白表达质谱数据库中筛选出有效蛋白集,从而排除了准确性低的蛋白,提高用于检测的蛋白的准确性;然后通过两次降维处理,获得蛋白质组与临床信息的关系库紧密关联的蛋白,然后对这些蛋白进行聚类分析,从而可以得到不同类别的蛋白标志物。该方法通过从大量的胃癌样本的蛋白质谱数据库中筛选出在癌症样本中显著高表达的蛋白标志物,并根据不同蛋白标志物与生存率之间的相互关系,将胃癌分成不同类别的蛋白标志物,这些标志物在不同类别之间存在显著性差异,因而能够更准确地对胃癌进行分型。
需要说明的是,上述多个样本形成的蛋白表达质谱数据库是指已知胃癌病例,具体包括胃癌病例的年龄、性别、癌细胞比例、lauren分型、tnm分型、生存时间、死亡与否、化疗与否、化疗方案等已知信息。
上述两次降维处理的目的是去除变化幅度很小的蛋白、将与临床信息相关性很高的蛋白进行合并从而降低构建模型的复杂度、便于计算样本与样本之间的距离从而保证相似的个体之间的距离尽量小,因而,任何能够实现该目的的降维处理方法均适用于本申请。为了实现抓取出大量蛋白信息中的胃癌特征并实现相似胃癌病人聚在一起的更好的效果,在本申请一种优选的实施例中,上述两次降维处理包括:采用主成分分析法对有效蛋白集进行第一次降维处理,得到第一降维数据集;采用t-sne对第一降维数据集进行第二次降维处理,得到降维蛋白集。
pca降维方法是从样本总集的整体相似性角度去进行降维,而t-sne降维方法则更关注样本的局部相似性,上述优选实施例中,先采用主成分分析法进行降维,然后再采用t-sne进行降维,能够实现同时兼顾总体和局部的有益效果。
上述从数据库中筛选出有效蛋白集的过程中,筛选的具体条件可以根据实际质谱数据情况进行合理调整。在本申请一些优选的实施例中,满足的保留条件包括质量条件和/或频次条件,质量条件包括如下至少之一:具有两条满足质量要求的肽段且其中至少一条为满足质量要求的唯一性肽段(uniquepeptide,也翻译成特异性肽段,指仅在一种蛋白质中可能出现的肽段)、及至少具有三条满足质量要求的肽段;频次条件为至少在80%的样本中都出现的蛋白。
此处的质量要求根据所用的数据库中的蛋白质谱肽段的谱图质量合理设定,为了提高所筛选的蛋白的准确性,本申请中所需要满足的质量要求为高质量的肽段,所谓“高质量”是指mascot对肽段的打分(ionscore)大于20分。具有高质量的唯一性肽段就是指仅在一种蛋白质中可能出现的肽段且该肽段的打分(ionscore)大于20分,具有两条满足高质量要求的肽段是指该蛋白至少包含两条肽段打分大于20分的肽段。至少具有三条满足质量要求的肽段是指该蛋白至少包含三条肽段打分大于20分的肽段。而频次要求在数据库中80%以上的样本中都出现的蛋白,这样保证该蛋白是具有普遍性的蛋白。
在上述第一次降维处理过程中,使用默认设置的pca主成分分析法进行降维即可。
在一种优选的实施例中,采用t-sne对上述第一降维数据集进行第二次降维处理的步骤中,学习速率设为10~500,迭代次数设为7500以上,迭代停止设为100~400。
上述方法中,聚类分析步骤中可以在现有的聚类分析原则基础上进行合理调整得到,其具体调整的原则是反复迭代后确保类内距离尽量小,类间距离尽量大,当结果收敛时,计算终止,得到聚类结果。在本申请一种优选的实施例中,上述聚类分析的步骤中,类内平均距离≤4.58,类间平均距离≥9.68。
在数据分析之前,通常需要先将数据进行标准化(normalization),利用标准化处理之后再进行数据分析。数据标准化处理包括数据同趋化处理和无量纲化处理两个方面。其中,数据无量纲化处理主要解决数据的可比性,方法有多种,经标准化处理,原始数据均转化为无量纲化指标测评值,即各指标处理同一个数量级别上,可以进行综合测评分析。
对于蛋白质组学的质谱数据而言,上述方法中,在对有效蛋白集依次进行两次降维处理之前,也还包括对有效蛋白集进行标准化处理,得到标准化的有效蛋白集的步骤。具体的标准化处理的方式可以采用现有的方法,比如z-score标准化。在一种优选的实施例中,标准化处理是指使有效蛋白集中的蛋白的均值为0,方差为1。
本申请的上述筛选胃癌分型蛋白标志物的方法,根据聚类分析,可以分成不同类别的蛋白标志物。在本申请一种优选的实施例中,不同类别的蛋白标志物为基于方差检验p值小于10的-35次方的蛋白标志物。在本申请一种更优选的实施例中,基于方差检验p值小于10的-35次方的不同类别的蛋白标志物包括:c0,h2afz、h2afj、h2afv;c1,actg2、acta2、actc1;c2,flna、col6a2、col6a1;c3,tubb2b、tubb2a、tubb;c4,h3f3c、h3f3a、h3f3b;c5,x;c6,pabpc1、hnrnpk、ddx39b。
上述不同类别的蛋白标志物,在其所属类别与其余类别中的表达量存在极其显著的差异,因而能够准确地标志不同分型的胃癌所具有的分子特征(即蛋白表达特征,就是指各类中蛋白标志物的表达量都显著高于其他类别中该相应蛋白的表达量)。上述c5类中,x是指无一个蛋白在该类中的表达量显著高于其他类。
在采用上述各类的蛋白标志物对胃癌进行分型时,可以采用每类中的任意一个蛋白标志物显著高于其余类中的任意一个蛋白标志物来进行分型,也可以采用每类中的任意两个或三个蛋白标志物显著高于其余类中的任意两个或三个蛋白标志物来进行分型。当所采用的蛋白标志物数量越多时,分型的结果相对越准确。
为了进一步提高对胃癌分型的准确性,在本申请另一些优选的实施例中,不同类别的蛋白标志物除了含有上述各蛋白标志物外,还包括基于方差检验p值低于10的-20次方的蛋白标志物。在一些更优选的实施例中,基于方差检验p值低于10的-20次方的蛋白标志物包括:
c0,hist2h2ac、hist2h2aa3、hist2h2aa4、hist1h2aj、hist1h2al、hist1h2ag、hist1h2am、hist1h2ai、hist1h2ak、hist1h2ah、hist1h2ad、hist1h2aa、hist1h2ac、hist1h2ae、hist1h2ab、hist3h2a、h2afx、rps3a、hist1h1b、eef1a2、ran、lmnb1、hist2h2ab;
c1,acta1、des、synm、myl9、pgm5、sorbs1;
c2,tpm1、myh11、tpm2、lmod1、tagln、myh10、ehd2、col6a3、flnc、cnn1、hspb6、tpm4、synpo2、mylk、cald1、dpysl3、cryab、actn1、tf、tln1、vcl、hspg2、tgfbi、ckb、tpm3、kng1、pdlim7、ilk、rras、csrp1、lum、ttr、sod3、myl6、alb、aoc3、ogn、actbl2;
c3,tubb3、tuba3d、tuba3c、tuba3e、capza2、iqgap1、tubb4b、gdi1、hpx、myh9、tuba4a、tubb6、tuba1a、tuba1c、tuba1b、tubb4a、anxa5、pls3、capza1、actr2、srsf3、npepps、cltcl1、serpinh1、pdlim3、hnrnpd、tuba8;
c4,hist3h3、hist1h3a、hist1h3d、hist2h3c、hist2h3a、hist2h3d、hist1h3c、hist1h3j、hist1h3i、hist1h3b、hist1h3f、hist1h3e、hist1h3g、hist1h3h;
c5,x;
c6,hspa8、ddx39a、eif4a1、pabpc3、eef1g、hnrnpm、rpn1、rpl4、ncl、ilf3、dhx9、rps9、rps19、rps4x、xrcc5、hnrnpr、hsp90aa1、syncrip、rps15a、eif4a3、ganab、rbmx、eef2、rpl13a、rpl7、rps16、psma6、rps24、fubp1、eif4a2、eif2s1、rpl36、srsf1、rpl7a、rplp0、rpl6、tubb8、arf1、arf3、rpsa、rab14、eef1a1、rpl27、dhx15、ilf2、srsf7、stip1、hnrnpa2b1、rpl10a、rpl23a、arf4、rps18、rpl38、nme1-nme2、gnb2l1、rps6、pdia6、hnrnpa1、pa2g4、rps3、rab7a、nono、rpl9、ywhaq、qars、pdia3、hnrnpa3、cct5、rps20、xrcc6、hsp90ab1、rps28、pcbp2、hnrnph2、ddx3x、arpc1b、tagln2、eif3f、ddost、hspa4、hnrnpa1l2、cndp2、ppib、ctnnd1、rps13、hspa9、prkdc、rps27a、ubb、uba52、ubc、cct6a、rpl15、nme2、eif3a、hnrnpc、rpl13、khsrp、ddx5、sarnp、alyref、atp2a2、elavl1、ruvbl2、atp6v1a、rab5c、uba1、cct8、stt3b、hspa2、copb2、dad1、p4hb、rrbp1、rpl24、hsp90b1、efhd2、pgd、ddx3y、anxa2、eef1d、arcn1、ywhab、pkm、psma7、idh1、sars、snrnp200、psmd2、hnrnpf、tmed10、hnrnph1、eno1、eif6、hnrnph3、pgk2、parp1、hdlbp、stt3a、prdx6、hspd1、pgk1、phb、ppa1、hspe1、dnm2、capn1、otub1、atp6v1b2。
上述蛋白标志物进行分型时,每类所使用的蛋白标志物的数量越多,对胃癌的分型越准确。当同时采用上述蛋白标志物进行分析时,分型的结果更准确。
根据上述筛选胃癌分型标志物的方法所筛选的蛋白标志物,能够更准确地从蛋白分子水平上对胃癌进行分型,不同分型对应的5年生存率存在差异。因此,利用这些蛋白标志物分成的不同分型,可以对任意未知的胃癌样本的分型进行检测或诊断。
需要说明的是,本申请的上述筛选胃癌分型蛋白标志物的方法一方面能够把属于不同类别的蛋白标志物筛选出来,同时,该筛选蛋白标志物的方法也可以用来对胃癌进行分型,即对人群中胃癌进行分型的方法与上述筛选胃癌分型蛋白标志物的方法步骤相同。
当然,对人群中胃癌进行分型的方法也可以利用上述蛋白标志物进行分型。在本申请第二种典型的实施方式中,还提供了一种对人群中胃癌进行分型的方法,该方法包括利用上述任一种筛选胃癌分型蛋白标志物的方法所筛选到的蛋白标志物进行分型,得到不同的胃癌分型。本申请的分型方法是从蛋白水平上进行的分型,更接近真实的生命状态,因而也相对更准确。
上述筛选胃癌蛋白标志物的方法所筛选到的蛋白标志物及其所分成的不同胃癌分型可以用来对任何一个个体样本进行胃癌筛查或生存率预后分型,尤其适合对胃癌个体进行准确分型。因此,在本申请第三种典型的实施方式中,还提供了一种对个体胃癌样本进行分型的方法,包括按照胃癌分型标准进行分型,胃癌分型标准为上述任一种筛选方法筛选到的不同类别的蛋白标志物所划分的不同的分型,或者为上述对人群中胃癌进行分型的方法所获得的不同的分型。利用本申请的蛋白标志物所划分得到的不同的分型对个体的分型诊断更准确。
在本申请第四种典型的实施方式中,还提供了一种对个体胃癌样本进行分型的方法,该方法包括:根据上述任一种对人群中胃癌的分型方法对已知胃癌样本集进行分型;从待测胃癌样本的蛋白质谱数据中筛选出符合保留条件的蛋白,作为待测蛋白集;按照与已知胃癌样本集中的有效蛋白集相同的条件,对待测蛋白集依次进行两次降维处理,得到待测胃癌样本的降维蛋白集;对待测胃癌样本的降维蛋白集进行聚类分析,得到与已知胃癌样本集中相似度最高的分型即为待测胃癌样本对应的分型。
上述对个体胃癌样本进行分型的方法,通过基于与数据库中已知的多个胃癌样本相似性的比对方法,即首先在已有的样本库中建立蛋白质谱数据与临床信息知识库之间的分型信息,并且得到了数据标准化、两次降维、聚类的具体参数,随后用待测样本的蛋白质谱数据与已知的样本的蛋白质谱数据进行比对,从而找到出与其相似度最高的已知样本所在的分型及其对应的化疗与治疗方案的预后信息。
上述分型方法中,两次降维处理的目的与前述人群胃癌分型方法中两次降维的目的相同,也是为了去除变化幅度很小的蛋白、将与临床信息相关性很高的蛋白进行合并从而降低匹配模型的复杂度以及便于计算待测样本与各已知样本之间的距离,进而保证相似的个体之间的距离尽量小,使得待测样本与已知样本匹配的结果更准确,从而使得对待测样本的分型结果更准确。
因此,任何能够实现上述效果的降维方法均适用于本申请。在本申请一种优选的实施例中,上述两次降维处理包括:采用主成分分析法对待测蛋白集进行第一次降维处理,得到第一降维数据集;采用t-sne对第一降维数据集进行第二次降维处理,得到降维蛋白集。
pca降维方法是从样本总集的整体相似性角度去进行降维,而t-sne降维方法则更关注样本的局部相似性,上述优选实施例中,先采用主成分分析法进行降维,然后再采用t-sne进行降维,能够实现同时兼顾总体和局部的有益效果。
具体的主成分分析法和t-sne降维方法中具体的参数设置条件,是根据已经样本的蛋白质谱数据库进行胃癌分型过程中所计算得到的参数进行设置,具体参数与胃癌分型方法中的参数条件相同。
上述分型的方法中,保留条件包括质量条件和/或频次条件可以根据实际所用的样本的蛋白质谱数据的质量进行合理选择设定。在本申请一种优选的实施例中,上述质量条件包括如下至少之一:具有两条满足质量要求的肽段且其中至少一条为满足质量要求的唯一性肽段、至少具有三条满足质量要求的肽段;频次条件为至少在已知胃癌样本集中80%的样本中都出现的蛋白。
此处的质量要求为与已知胃癌样本集中高质量的肽段相同要求质量要求。所谓“高质量”是指mascot对肽段的打分(ionscore)大于20分。具有高质量的唯一性肽段就是指仅在一种蛋白质中可能出现的肽段且该肽段的打分(ionscore)大于20分,具有两条满足高质量要求的肽段是指该蛋白至少包含两条肽段打分大于20分的肽段。至少具有三条满足质量要求的肽段是指该蛋白至少包含三条肽段打分大于20分的肽段。而频次要求在数据库中80%以上的样本中都出现的蛋白,这样保证该蛋白是具有普遍性的蛋白。
上述方法中,聚类分析步骤中可以在现有的聚类分析原则基础上进行合理调整得到,其具体调整的原则是确保类内距离尽量小,类间距离尽量大。在本申请一种优选的实施例中,上述聚类分析的步骤中,类内平均距离≤4.58,类间平均距离≥9.68。
在数据分析之前,通常需要先将数据进行标准化(normalization),利用标准化处理之后再进行数据分析。数据标准化处理包括数据同趋化处理和无量纲化处理两个方面。其中,数据无量纲化处理主要解决数据的可比性,方法有多种,经标准化处理,原始数据均转化为无量纲化指标测评值,即各指标处理同一个数量级别上,可以进行综合测评分析。
对于蛋白质组学的质谱数据而言,上述方法中,在对待测蛋白集依次进行两次降维处理之前,也还包括对待测蛋白集进行标准化处理,得到标准化的待测蛋白集的步骤。具体的标准化处理的方式可以采用现有的方法,比如z-score标准化。在一种优选的实施例中,标准化处理是指使待测蛋白集中的蛋白的均值为0,方差为1。
在本申请第五种典型的实施方式中,还提供了一种检测胃癌的试剂、试剂盒或芯片,该试剂、试剂盒或芯片包括上述任一种方法筛选得到的不同类别的蛋白标志物。含有本申请的上述方法所筛选的蛋白标志物具有分型相对更准确地预测不同胃癌患者的预后,进而利于更准确地对患者的化疗与否以及各种用药方案的疗效进行评估。
需要说明的是,上述检测胃癌的试剂、试剂盒或芯片中的检测包括分型诊断、生存预后评估及化疗治疗用药筛选中的任意一种或多种。
在本申请第六种典型的实施方式中,还提供了上述任一种方法筛选得到的不同类别的蛋白标志物在制备用于检测胃癌的试剂、试剂盒或芯片中的应用。
在一种优选的实施例中,上述蛋白标志物为表达量在所属类别中显著高于在其余类别中的蛋白标志物。在另一些优选的实施例中,上述蛋白标志物分为7类(与前述筛选方法中的7类蛋白标志物相对应,此处不再赘述),每类蛋白标志物在各自类别中表达量都显著高于在其余类别中。
此处的应用,包括但不仅限于分型诊断、生存预后评估及化疗治疗用药筛选。
在本申请第七种典型的实施方式中,还提供了一种胃癌分型蛋白标志物的筛选装置,该筛选装置包括:筛选模块a,用于从多个样本形成的蛋白表达质谱数据库中筛选出满足保留条件的蛋白,作为有效蛋白集;降维模块a,用于对有效蛋白集依次进行两次降维处理,得到降维蛋白集;聚类分型模块a,用于对降维蛋白集进行聚类分析,得到不同类别的蛋白标志物。
该筛选装置通过运行筛选模块a先从数据库中筛选出有效蛋白集,从而排除了准确性低的蛋白,提高用于检测的蛋白的准确性;然后执行降维模块a对有效蛋白集进行两次降维处理,获得蛋白质组与临床信息的关系库紧密关联的蛋白,最后执行聚类分型模块a对这些蛋白进行聚类分析,从而可以不同类别的蛋白标志物,同时获得的是这些不同类别的蛋白标志物所标志的胃癌的不同分型,分别标志在临床上不同的5年生存率。该筛选装置能够从大量的胃癌样本的蛋白质谱数据库中筛选出在癌症样本中显著高表达的蛋白标志物,并根据不同蛋白标志物与5年生存率之间的相互关系,将胃癌分成不同类别的蛋白标志物,这些标志物在不同类别之间存在显著性差异,因而对胃癌的分型更准确。
在一种优选的实施例中,降维模块a包括:主成分降维模块a及t-sne降维模块a,其中,主成分降维模块a用于采用主成分分析法对有效蛋白集进行第一次降维处理,得到第一降维数据集;t-sne降维模块a用于采用t-sne对第一降维数据集进行第二次降维处理,得到降维蛋白集。
主成分降维模块a是采用pca降维方法,从样本总集的整体相似性角度去进行降维,而t-sne降维模块a则采用t-sne降维方法,更关注样本的局部相似性。上述优选实施例中,先采用主成分降维模块a进行降维,然后再采用t-sne降维模块a进行降维,能够实现同时兼顾总体和局部的有益效果。
在一种优选的实施例中,上述筛选模块a中的保留条件包括质量条件和/或频次条件,质量条件包括如下至少之一:具有两条满足质量要求的肽段且其中至少一条为满足质量要求的唯一性肽段、至少具有三条满足质量要求的肽段;频次条件为至少在80%的样本中都出现的蛋白。
此处的质量要求根据所用的数据库中的蛋白质谱肽段的谱图质量合理设定,为了提高所筛选的蛋白的准确性,本申请中所需要满足的质量要求为高质量的肽段,所谓“高质量”是指mascot对肽段的打分(ionscore)大于20分。具有高质量的唯一性肽段就是指仅在一种蛋白质中可能出现的肽段且该肽段的打分(ionscore)大于20分,具有两条满足高质量要求的肽段是指该蛋白至少包含两条肽段打分大于20分的肽段。至少具有三条满足质量要求的肽段是指该蛋白至少包含三条肽段打分大于20分的肽段。而频次要求在数据库中80%以上的样本中都出现的蛋白,这样保证该蛋白是具有普遍性的蛋白。
在一种优选的实施例中,主成分降维模块采用默认设置进行上述第一次降维。
在一种优选的实施例中,上述t-sne降维模块a中:学习速率设为10~500,迭代次数设为7500以上,迭代停止设为100~400。
上述聚类分型模块a可以在现有的聚类分析模块的基础上进行合理调整得到,其具体调整的原则是反复迭代后确保类内距离尽量小,类间距离尽量大,当结果收敛时,计算终止,得到聚类结果。在本申请一种优选的实施例中,上述聚类分型模块a中,类内平均距离≤4.58,类间平均距离≥9.68。
对于蛋白质组学的质谱数据而言,上述筛选装置在采用降维模块a对有效蛋白集依次进行两次降维处理之前,也还包括标准化处理模块a。具体的标准化处理模块a可以采用现有的模块,比如z-score标准化模块。在一种优选的实施例中,标准化处理模块a用于使有效蛋白集中的蛋白的均值为0,方差为1。
在本申请一种优选的实施例中,上述筛选装置所筛选出的不同类别的蛋白标志物为基于方差检验p值小于10的-35次方的蛋白标志物。在本申请一种更优选的实施例中,基于方差检验p值小于10的-35次方的不同类别的蛋白标志物包括:c0,h2afz、h2afj、h2afv;c1,actg2、acta2、actc1;c2,flna、col6a2、col6a1;c3,tubb2b、tubb2a、tubb;c4,h3f3c、h3f3a、h3f3b;c5,x;c6,pabpc1、hnrnpk、ddx39b。
上述不同类别的蛋白标志物,在其所属类别与其余类别中的表达量存在极其显著的差异,因而能够准确地标志不同分型的胃癌所具有的分子特征(即蛋白表达特征,就是指各类中蛋白标志物的表达量都显著高于其他类别中该相应蛋白的表达量)。上述c5类中,x是指无一个蛋白在该类中的表达量显著高于其他类。
在采用上述筛选装置筛选出的各类的蛋白标志物对胃癌进行分型时,可以采用每类中的任意一个蛋白标志物显著高于其余类中的任意一个蛋白标志物来进行分型,也可以采用每类中的任意两个或三个蛋白标志物显著高于其余类中的任意两个或三个蛋白标志物来进行分型。当所采用的蛋白标志物数量越多时,分型的结果相对越准确。
为了进一步提高对胃癌分型的准确性,在本申请另一些优选的实施例中,上述筛选装置筛选到的不同类别的蛋白标志物除了含有上述各蛋白标志物外,还包括基于方差检验p值低于10的-20次方的蛋白标志物。在一些更优选的实施例中,基于方差检验p值低于10的-20次方的蛋白标志物包括:
c0,hist2h2ac、hist2h2aa3、hist2h2aa4、hist1h2aj、hist1h2al、hist1h2ag、hist1h2am、hist1h2ai、hist1h2ak、hist1h2ah、hist1h2ad、hist1h2aa、hist1h2ac、hist1h2ae、hist1h2ab、hist3h2a、h2afx、rps3a、hist1h1b、eef1a2、ran、lmnb1、hist2h2ab;
c1,acta1、des、synm、myl9、pgm5、sorbs1;
c2,tpm1、myh11、tpm2、lmod1、tagln、myh10、ehd2、col6a3、flnc、cnn1、hspb6、tpm4、synpo2、mylk、cald1、dpysl3、cryab、actn1、tf、tln1、vcl、hspg2、tgfbi、ckb、tpm3、kng1、pdlim7、ilk、rras、csrp1、lum、ttr、sod3、myl6、alb、aoc3、ogn、actbl2;
c3,tubb3、tuba3d、tuba3c、tuba3e、capza2、iqgap1、tubb4b、gdi1、hpx、myh9、tuba4a、tubb6、tuba1a、tuba1c、tuba1b、tubb4a、anxa5、pls3、capza1、actr2、srsf3、npepps、cltcl1、serpinh1、pdlim3、hnrnpd、tuba8;
c4,hist3h3、hist1h3a、hist1h3d、hist2h3c、hist2h3a、hist2h3d、hist1h3c、hist1h3j、hist1h3i、hist1h3b、hist1h3f、hist1h3e、hist1h3g、hist1h3h;
c5,x;
c6,hspa8、ddx39a、eif4a1、pabpc3、eef1g、hnrnpm、rpn1、rpl4、ncl、ilf3、dhx9、rps9、rps19、rps4x、xrcc5、hnrnpr、hsp90aa1、syncrip、rps15a、eif4a3、ganab、rbmx、eef2、rpl13a、rpl7、rps16、psma6、rps24、fubp1、eif4a2、eif2s1、rpl36、srsf1、rpl7a、rplp0、rpl6、tubb8、arf1、arf3、rpsa、rab14、eef1a1、rpl27、dhx15、ilf2、srsf7、stip1、hnrnpa2b1、rpl10a、rpl23a、arf4、rps18、rpl38、nme1-nme2、gnb2l1、rps6、pdia6、hnrnpa1、pa2g4、rps3、rab7a、nono、rpl9、ywhaq、qars、pdia3、hnrnpa3、cct5、rps20、xrcc6、hsp90ab1、rps28、pcbp2、hnrnph2、ddx3x、arpc1b、tagln2、eif3f、ddost、hspa4、hnrnpa1l2、cndp2、ppib、ctnnd1、rps13、hspa9、prkdc、rps27a、ubb、uba52、ubc、cct6a、rpl15、nme2、eif3a、hnrnpc、rpl13、khsrp、ddx5、sarnp、alyref、atp2a2、elavl1、ruvbl2、atp6v1a、rab5c、uba1、cct8、stt3b、hspa2、copb2、dad1、p4hb、rrbp1、rpl24、hsp90b1、efhd2、pgd、ddx3y、anxa2、eef1d、arcn1、ywhab、pkm、psma7、idh1、sars、snrnp200、psmd2、hnrnpf、tmed10、hnrnph1、eno1、eif6、hnrnph3、pgk2、parp1、hdlbp、stt3a、prdx6、hspd1、pgk1、phb、ppa1、hspe1、dnm2、capn1、otub1、atp6v1b2。
上述蛋白标志物进行分型时,每类所使用的蛋白标志物的数量越多,对胃癌的分型越准确。当同时采用上述蛋白标志物进行分析时,分型的结果更准确。
上述胃癌分型蛋白标志物的筛选装置本质上也可以执行人群胃癌分型的功能,即也可以称为是一种人群胃癌分型装置。在本申请第八种典型的实施方式中,还提供了一种胃癌分型装置,该分型装置包括筛选模块b,用于从多个样本形成的蛋白表达质谱数据库中筛选出满足保留条件的蛋白,作为有效蛋白集;降维模块b,用于对有效蛋白集依次进行两次降维处理,得到降维蛋白集;聚类分型模块b,用于对降维蛋白集进行聚类分析,得到按照不同类别的蛋白标志物所划分的不同的分型。
该分型模块通过运行筛选模块b先从数据库中筛选出有效蛋白集,从而排除了准确性低的蛋白,提高用于检测的蛋白的准确性;然后执行降维模块b对有效蛋白集进行两次降维处理,获得蛋白质组与临床信息的关系库紧密关联的蛋白,最后执行聚类分型模块b对这些蛋白进行聚类分析,从而可以不同类别的蛋白标志物。该筛选装置能够从大量的胃癌样本的蛋白质谱数据库中筛选出在癌症样本中显著高表达的蛋白标志物,并根据不同蛋白标志物与5年生存率之间的相互关系,将胃癌分成不同类别的蛋白标志物,这些标志物在不同类别之间存在显著性差异,因而能够更准确地对胃癌进行分型。
在一种优选的实施例中,降维模块b包括:主成分降维模块及t-sne降维模块,其中,主成分降维模块用于采用主成分分析法对有效蛋白集进行第一次降维处理,得到第一降维数据集;t-sne降维模块用于采用t-sne对第一降维数据集进行第二次降维处理,得到降维蛋白集。
在一种优选的实施例中,上述筛选模块b中的保留条件包括质量条件和/或频次条件,质量条件包括如下至少之一:具有两条满足质量要求的肽段且其中至少一条为满足质量要求的唯一性肽段、至少具有三条满足质量要求的肽段;频次条件为至少在80%的样本中都出现的蛋白。
在一种优选的实施例中,t-sne降维模块b中学习速率设为10~500,迭代次数设为7500以上,迭代停止设为100~400。
在一种优选的实施例中,上述聚类分型模块b中,类内平均距离≤4.58,类间平均距离≥9.68。
在一种优选的实施例中,上述分型装置还包括标准化处理模块b,标准化处理模块b用于对有效蛋白集进行标准化处理,得到标准化的有效蛋白集。
在另一种优选的实施例中,标准化处理b用于使有效蛋白集中的蛋白的均值为0,方差为1。
上述人群胃癌分型装置中,各优选实施例对应的效果与前述胃癌分型蛋白标志物的筛选装置中各优选实施例的效果相同,具体可参见前述相关内容。
在本申请第九种典型的实施方式中,还提供了一种对个体胃癌样本进行分型的装置,该装置包括:胃癌分型装置,用于根据已知胃癌样本集对胃癌进行分型,胃癌分型装置为上述任一种胃癌分型装置;筛选模块c,用于从待测胃癌样本的蛋白质谱数据中筛选出符合保留条件的蛋白,作为待测蛋白集;降维模块c,用于按照与胃癌分型装置中对已知胃癌样本集中的有效蛋白集相同的条件,对待测蛋白集依次进行两次降维处理,得到待测胃癌样本的降维蛋白集;聚类分型模块c,用于对待测胃癌样本的降维蛋白集进行聚类分析,得到与已知胃癌样本集中相似度最高的分型即为待测胃癌样本对应的分型。
该装置通过基于与数据库中已知的多个胃癌样本相似性的比对方法,即首先在已有的样本库中建立蛋白质谱数据与临床信息知识库之间的分型模型,并且得到了数据标准化、两次降维、聚类的具体参数,随后用待测样本的蛋白质谱数据与已知的样本的蛋白质谱数据进行比对,从而找到出与其相似度最高的已知样本所在的分型及其对应的化疗与治疗方案的预后信息。这种基于待测样本与已知样本的相似性的比对分型检测方法,从而使得待测样本的分型结果更准确。
上述对个体样本进行分型的装置中,两次降维处理的目的也是为了去除变化幅度很小的蛋白、将与临床信息相关性很高的蛋白进行合并从而降低匹配模型的复杂度以及便于计算待测样本与各已知样本之间的距离,进而保证相似的个体之间的距离尽量小,使得待测样本与已知样本匹配的结果更准确,从而使得对待测样本的分型结果更准确。
因此,任何能够实现上述效果的降维方法均适用于本申请。在本申请一种优选的实施例中,上述降维模块c包括:主成分降维模块c,用于采用主成分分析法对待测蛋白集进行第一次降维处理,得到第一降维数据集;t-sne降维模块c,用于采用t-sne对第一降维数据集进行第二次降维处理,得到降维蛋白集。
主成分降维模块c是从样本总集的整体相似性角度去进行降维,而t-sne降维模块c则更关注样本的局部相似性,上述优选实施例中,先采用主成分降维模块c进行降维,然后再采用t-sne降维模块c进行降维,能够实现同时兼顾总体和局部的有益效果。
具体的主成分降维模块c和t-sne降维模块c中具体的参数设置条件,是根据已经样本的蛋白质谱数据库进行胃癌分型过程中所计算得到的参数进行设置,具体参数与胃癌分型装置中的参数条件相同。
上述分型的装置中,保留条件包括质量条件和/或频次条件可以根据实际所用的样本的蛋白质谱数据的质量进行合理选择设定。在本申请一种优选的实施例中,上述质量条件包括如下至少之一:具有两条满足质量要求的肽段且其中至少一条为满足质量要求的唯一性肽段、至少具有三条满足质量要求的肽段;频次条件为至少在已知胃癌样本集中80%的样本中都出现的蛋白。
此处的质量要求为与已知胃癌样本集中高质量的肽段相同要求质量要求。所谓“高质量”是指mascot对肽段的打分(ionscore)大于20分。具有高质量的唯一性肽段就是指仅在一种蛋白质中可能出现的肽段且该肽段的打分(ionscore)大于20分,具有两条满足高质量要求的肽段是指该蛋白至少包含两条肽段打分大于20分的肽段。至少具有三条满足质量要求的肽段是指该蛋白至少包含三条肽段打分大于20分的肽段。而频次要求在数据库中80%以上的样本中都出现的蛋白,这样保证该蛋白是具有普遍性的蛋白。
上述装置中,聚类分析模块c中可以在现有的聚类分析模块原则基础上进行合理调整得到,其具体调整的原则是确保类内距离尽量小,类间距离尽量大。在本申请一种优选的实施例中,上述聚类分析模块c中,类内平均距离≤4.58,类间平均距离≥9.68。
在数据分析之前,通常需要先将数据进行标准化(normalization),利用标准化处理之后再进行数据分析。数据标准化处理包括数据同趋化处理和无量纲化处理两个方面。其中,数据无量纲化处理主要解决数据的可比性,方法有多种,经标准化处理,原始数据均转化为无量纲化指标测评值,即各指标处理同一个数量级别上,可以进行综合测评分析。
对于蛋白质组学的质谱数据而言,上述在利用降维模块c对待测蛋白集依次进行两次降维处理之前,所述装置还包括标准化处理模块c,用于对待测蛋白集进行标准化处理,得到标准化的待测蛋白集的步骤。具体的标准化处理模块c可以采用现有的模块,比如z-score标准化模块。在一种优选的实施例中,标准化处理模块c用于使待测蛋白集中的蛋白的均值为0,方差为1。
在本申请第十种典型的实施方式中,还提供了一种存储介质,存储介质包括存储的程序,其中,程序执行上述任一种胃癌分型蛋白标志物的筛选方法;或者程序执行上述任一种对人群中胃癌进行分型的方法;或者程序执行上述任一种对个体胃癌样本进行分型的方法;或者程序执行上述任一种对个体胃癌样本进行分型的方法。
在本申请第十一种典型的实施方式中,还提供了一种处理器,处理器用于运行程序,其中,其中,程序执行上述任一种胃癌分型蛋白标志物的筛选方法;或者程序执行上述任一种对人群中胃癌进行分型的方法;或者程序执行上述任一种对个体胃癌样本进行分型的方法;或者程序执行上述任一种对个体胃癌样本进行分型的方法。
下面将结合具体的实施例来进一步说明本申请的有益效果。
实施例1
第一部分,基于石蜡包埋样本的样本制备方法
针对50例已知胃癌病例(具体包括胃癌病例的年龄、性别、癌细胞比例、lauren分型、tnm分型、生存时间、死亡与否、化疗与否、化疗方案等已知信息)的石蜡包埋组织样本进行蛋白质提取和分析,详细步骤如下:
(一)、切片:
取已经包埋好的蜡块,用解剖刀去除组织块周围多余的石蜡,把组织块修成梯形;
将蜡块固定在切片机上,调整切片厚度为5微米,进行切片;
用毛笔或牙签挑取切片到展片机中进行展片,温度为45℃;
用载玻片捞片(至少捞两个载玻片,一片实验,一片备用),蜡片摆正后,铅笔编号,竖直放置载玻片晾干,然后置于烤片机上60℃烤片2小时;
置于切片盒-20℃存放。
(二)、蛋白提取
切片-20℃取出后,置于切片架上,60℃烤箱烘烤1小时;
复室温后,进行脱蜡,具体过程和时间如下:
二甲苯ⅰ,10分钟
二甲苯ⅱ,10分钟
二甲苯ⅲ,10分钟
100%乙醇,10分钟
95%乙醇,10分钟
90%乙醇,10分钟
85%乙醇,10分钟
75%乙醇,10分钟
蒸馏水ⅰ,10分钟
蒸馏水ⅱ,10分钟
置于通风处干燥后,用手术刀片把切片刮至装有100微升的50mmnh4hco3溶液的ep管中。
(三)、蛋白还原烷基化,酶解肽段:
加入0.5微升1mdtt,56℃加热30分钟后,恢复室温,加入1miaa,室温避光30分钟;再加入0.5微升1mdtt,室温15分钟;
加入3微克质谱测序级胰酶,37℃混匀消化过夜;
次日,加入200微升50%乙腈和0.1%甲酸溶液,室温震荡混匀5分钟,10000g离心5分钟,取上清置于一新管;重复一次,两次上清合并,真空浓缩仪60℃抽干肽段。
(四)、脱盐:
1.抽干后的肽段用100微升0.1%甲酸溶液复溶;脱盐程序如下:
自制脱盐柱:t400枪头+2层c18膜+1mgc18粉末;
脱盐柱活化:
100%acn,100微升,1000g、离心1min
50%acn,100微升,1000g、离心3min
80%acn,100微升,1000g、离心2min
50%acn,100微升,1000g、离心3min
脱盐柱平衡:0.1%fa,100微升,1000g、离心4min;重复一次;
肽段上样:溶解的肽段加入到脱盐柱,1000g、离心4min;离心后的液体重复上样一次;
清洗盐分:0.1%fa,100微升,1000g、离心4min;重复一次;
肽段洗脱:脱盐柱至于一新的收集管中,加入100微升25%acn+0.1%fa,1000g、离4min,收集洗脱的样品真空浓缩仪60℃抽干肽段,送于液质联用质谱分析。
第二部分,基于石蜡包埋样本的胃癌蛋白质组数据进行胃癌分型的方法或进行胃癌分型蛋白标志物的筛选方法,详细步骤如下:
1.蛋白准确性筛选。对已知样本检测到的蛋白进行筛选,保留至少检测到两个高质量肽段的蛋白且其中一个为唯一高质量肽段,或者至少检测到三个高质量肽段的蛋白。
2.蛋白频次筛选。对所有已知样本(又称为已知胃癌样本集)进行蛋白频次的筛选,保留在80%的样本中都出现的蛋白。
3.对所有已知样本做蛋白水平的标准化,确保库中每个蛋白都被标准化到均值为0,方差为1的队列值。
4.使用主成分分析法对已知胃癌样本集进行主成分分析,在蛋白水平进行降维,需确保降维后的主成分能够解释绝大多数的样本特征。具体参数为:奇异值分解方法设为自动选择。
5.对已知胃癌样本集使用t-sne进行进一步的降维,具体参数学习速率设为100,迭代次数20000,迭代停止设为300。
6.对降维后的已知胃癌样本集的降维数据进行聚类分析,确保类内平均距离≤4.58,类间平均距离≥9.68,从而将该已知胃癌样本集分成不同的类别,每个类别中均存在一些表达量显著高于其余类别中的蛋白,这些蛋白即为该对应类别的蛋白标志物,而所在的不同的类别即为人群中胃癌的不同分型。
第三部分结果
50例胃癌石蜡包埋组织样本按照上述方法鉴定到总计8550个蛋白,每个样本鉴定到3109~4064个蛋白,具体见图1。图1的横坐标为鉴定到的蛋白数目,纵坐标为样本的频次,从图1中可以看出,50例样本中,每例样本可鉴定到3109~4064个蛋白。
对50例胃癌石蜡包埋组织样本进行分型的结果见表1、表2和图2和图3,其中表1和表2分别示出了在不同类中存在显著差异表达的蛋白标志物,图2示出了聚类分析而分成的7种不同的类(cluster)对应7种胃癌分型,图3示出了图2中不同的分型的胃癌之间在生存率上存在的显著差异(p值为0.00005772),其中c0型的生存预后效果最好,其次是c4型,最差的是c2型。
表1:
从上述表1可以看出,上述蛋白标志物在不同类别之间具有显著性差异(方差检验p值都是小于10的-35次方)且上述结果的fdr(falsediscoveryrate,伪发现率,其意义是错误拒绝的个数占所有被拒绝的原假设的个数的比例的期望值)均为0。
表2:
从上述表2可以看出,上述蛋白标志物在不同类别之间具有显著性差异(方差检验p值至少是小于10的-20次方)且上述结果的fdr也均为0。表明表2中的蛋白标志物同样可以用于对胃癌进行分型。
实施例2
针对实施例1的分型结果,该实施例进一步检测了不同胃癌分型的患者对化疗的敏感性与用药的敏感性与生存预后之间的关联,其中,图4示出了c6分型的患者的生存与化疗治疗的预后生存率之间的关系。
实施例3
利用实施例1所建立的分型结果,对新收取的224例胃癌样本分别逐一进行分型诊断检测,蛋白分离提取及质谱分离的步骤同实施例1。分型检测的步骤如下:
1.蛋白准确性筛选。对待测样本检测到的蛋白进行筛选,保留至少检测到两个高质量肽段的蛋白且其中一个为唯一高质量肽段,或者至少检测到三个高质量肽段的蛋白。
2.蛋白频次筛选。待测样本中检测到的蛋白,若在实施例1的已知胃癌样本集中80%的样本中都出现过,则保留该蛋白。
3.按照实施例1的已知胃癌样本集中蛋白标准化的参数,对待测样本中经过上述筛选后的蛋白进行标准化处理,以使待测样本的有效检测蛋白质谱数据与已知胃癌样本集中蛋白的质谱数据具有可比性,即确保待测样本的每个蛋白被标准化至与已经分型的样本中的蛋白可比的水平。
4.采用与实施例1中相同的具体参数,通过主成分分析法对待测胃癌样本进行主成分分析,在蛋白水平进行降维,得到第一降维数据。
5.采用与实施例1中相同的t-sne设置参数,对第一降维数据使用t-sne进一步的降维,得到待测胃癌样本的降维蛋白集。
6.采用与实施例1中相同的聚类分析设置参数,对待测胃癌样本的降维蛋白集进行聚类分析,从而将该待测胃癌样本的蛋白分到不同的类别中,根据与已知胃癌样本集中相似度高低,即可判定相似度最高的分型即为待测胃癌样本对应的分型。分型结果见表3。
表3:
根据表3中对各病例的分型检测结果,以及对这些病例随访的生存时间记录,经计算得出:
c0型,术后平均生存时间为5.09年,共23例;
c1型,术后平均生存时间为3.93年,共39例;
c2型,术后平均生存时间为2.97年,共30例;
c3型,术后平均生存时间为3.93年,共28例;
c4型,术后平均生存时间为4.59年,共36例;
c5型,术后平均生存时间为3.94年,共31例;
c6型,术后平均生存时间为4.06年,共37例。
从各分型病例的术后平均生存时间及图5所示的结果可以看出,c0型生存预后最好,c4型次之,c2型最差。该结果与实施例1中的分型预测结果完全一致。由此可见,采用本申请的方法进行分型检测,结果更准确。
从以上的描述中,可以看出,本申请上述的实施例实现了如下技术效果:本申请根据石蜡组织的特点开发了一套提取石蜡包埋样本中蛋白质的方法,该方法结合有针对性的质谱条件及参数设置,能够从超微量的石蜡包埋样本中实现在短时间内单次lc-ms质谱鉴定3000多个蛋白质,从而快速、高效地把庞大的组织蜡块样品转化为深度、准确的蛋白质组数据。
在上述基础上,本申请进一步从蛋白质分子层面,根据不同类别的蛋白标志物,将胃癌分为7型,建立了一种胃癌的预后评估模型,其中预后最好的一型5年生存率达到了80.29%,预后最差的一型5年生存率为35.85%。预测水准高于lauren方法,与acrg方法持平,略微低于tnm方法。根据本申请所获取的7种胃癌分型的蛋白质组分子特征,指导或评估患者的化疗与否和各种用药方案的疗效,为胃癌患者的治疗方案提供了与生存相关的有价值的个性化选择。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
在一个典型的配置中,计算设备包括一个或多个处理器(cpu)、输入/输出接口、网络接口和内存。
存储器可能包括计算机可读介质中的非永久性存储器,随机存取存储器(ram)和/或非易失性内存等形式,如只读存储器(rom)或闪存(flashram)。存储器是计算机可读介质的示例。
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitorymedia),如调制的数据信号和载波。
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括要素的过程、方法、商品或者设备中还存在另外的相同要素。
本领域技术人员应明白,本申请的实施例可提供为方法、系统或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!