一种面粉中呕吐毒素的定量检测方法与流程
本发明涉及一种面粉中呕吐毒素的定量检测方法。
背景技术:
小麦是全世界的主要粮食作物之一,面粉作为小麦的主要加工产品在人们的饮食结构中占有很大的比重,然而小麦在自身生长过程中受赤霉病影响会产生呕吐毒素,又名脱氧雪腐镰刀菌烯醇(don)这种有毒化合物。呕吐毒素因能引起人类及动物的呕吐反应而命名。当人过量食用了被don污染的食物后会发生呕吐、发烧、厌食、腹泻等急性中毒症状。因此,我国规定面粉制品中don浓度含量应低于1ppm。
目前,对于don的测定方法,主要有:液相色谱—串联质谱法;免疫亲和层析净化高效液相色谱法;薄层色谱测定法等。这些检测方法样本的预处理成本高,检测周期长,操作难度大,需要专业技术人员操作,且设备昂贵,已不能满足市场需求。近年来,近红外光谱技术因其快速、无损、无污染等优点,已广泛应用于农作物、农副产品的定量定性分析中。但是,由于绝大多数农业物料其特定成分的近红外光谱信号都很微弱,尤其是当某种成分含量很低时,近红外光谱能反映的信号就更弱,加之各种因素干扰,因此,限制了近红外光谱技术对低含量成分的检测能力,一般而言,当某种成分的含量低于5ppm时,采用近红外光谱技术对其进行定量分析就很困难,检测误差较大。
技术实现要素:
本发明要解决的技术问题是克服现有技术的缺陷,提供一种。
为了解决当面粉中呕吐毒素的含量低于5ppm时,采用近红外光谱技术对其进行定量分析就很困难,检测误差较大的问题,本发明先通过一种富集技术,制成高浓度don面粉样本,然后采用近红外光谱技术对该高浓度don面粉样本中的don进行测量,最后再换算成原始面粉样本的don含量。
1、一种面粉中呕吐毒素的定量检测方法,其特征在于,包括以下步骤:
s1:样本富集处理
向样本中加入聚乙二醇和去离子水混合均匀后,用离心机离心,然后取适量上层清夜置于玻璃器皿中,放于恒温烘干箱,将析出固体取出备用;
s2光谱扫描
将s1中析出的固体,研磨成细粉末与溴化钾粉末混合均匀,装入模具内,压制成片,将压好的片放在仪器上扫描光谱;
s3采集光谱
将s2获得的光谱数据转换成csv文件,导入origin8.0软件制图,得到样本的光谱图;
s4光谱预处理
剔除异常样本并将光谱扣除大气背景、矫正基线和savitzky-golay多点平滑;
s5建模参数选取
采取mapminmax()将数据归一化到(-1,1),训练目标误差设置为10^-8;学习率设置有为0.1,隐含层的层数设定为3,隐含层节点取8。然后随机选取三分之二样本的数据作为训练数据用于模型训练,其余的三分之一样本作为测试数据进行模型验证;
s5中建模时建立基于bp神经网络的模型
bp神经网络的bp是指backpropagation(反向传播),即为误差的反向传播,其信号是向前传播的,bp神经网络作为ann的一个分支,与大部分神经网络类似,主要差别在于神经元的差异,其中典型的神经元模型如图:
通过这个模型,每个神经元都接受来自其它神经元的输入信号,每个信号都通过一个带有权重的连接传递,神经元把这些信号加起来得到一个总输入值,然后将总输入值与神经元的阈值进行对比,最终经激活函数计算得到最终输出,输出又会作为之后神经元的输入一层一层传递下去。
假设输入层的节点为n,隐含层的节点数为l,输出层的节点数为m,输入层到隐含层的权重为wij,隐含层到输出层的权重为wjk,输入层到隐含层的偏置为aj,隐含层到输出层的偏置为bk,学习速率为τ,激励函数为g(x),取sigmoid函数,形式为
隐含层的输出为:
输出层的输出为:
取误差公式为:
为使误差函数达到最小值,即mine,在误差反向传播的过程中,我们使用了梯度下降法,从而推算输入层到隐含层的权重更新:
得出:
隐含层到输出层的权重更新公式为:(wjk=wjk+τhjek)
当相邻的两次误差之间的差值小于指定的数值,算法达到指定的迭代次数等设定条件时,判断算法已经收敛。
本发明所达到的有益效果是:本发明先通过一种富集技术,制成高浓度don面粉样本,然后采用近红外光谱技术对该高浓度don面粉样本中的don进行测量,最后再换算成原始面粉样本的don含量。本研究采用分离富集技术提升don浓度,然后建立基于bp神经网络的don定量分析模型,相关系数达到0.92以上,建模效果良好。相对沈飞等人,神经网络模型的r有了较大提升,rmsep也从0.426降至0.273ppm,进一步增加了模型的稳定性和适应性。采用分离富集后的面粉预测集误差均方根相对较小,说明其与真实值相差较小,大型面粉厂检测don含量时,可采用直接扫描面粉光谱的方法进行出厂测量,为其提供一种初步筛选检测方法。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
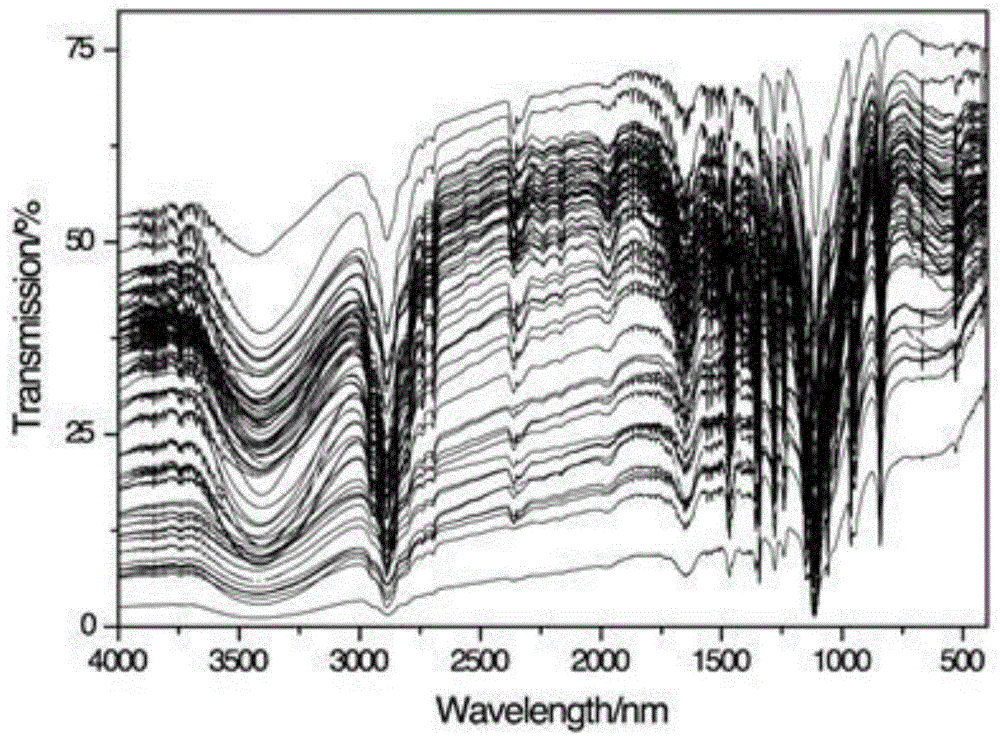
图1是实施例中全体样本的光谱图;
图2是样本的马氏距离分布图;
图3是预处理后的样本光谱图;
图4是分离富集后模型的拟合曲线
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
实施例
1.1实验材料与装置
在小麦扬花期,在不同田块,喷撒不同浓度脱氧雪腐镰刀菌的试剂使小麦不同程度发病,然后待小麦成熟后收割,按国家标准粉工艺流程和标准,制成含有不同浓度don的标准粉,共计103个实验样本。
实验仪器:nicoletis10傅立叶变换红外光谱仪:美国thermonicoletcorporation公司;高效液相色谱仪(配有紫外检测器):日本岛津公司;101-1a型电热恒温干燥箱:上海锦昱科学仪器有限公司;红外压片机:天津天光光学仪器制造;自动分级振动筛:淄博龙资环保设备有限公司;jm-a20002型电子天平:上海光正医疗仪器有限公司。
1.2试验方法
实验中共采集103个样本,每个样本分为两部分,第一部分按食品安全国家标准gb5009.111—2016中免疫亲和层析净化高效液相色谱法测定其don含量。第二部分经分离富集处理后,进行光谱扫描实验。
1.2.1样本富集处理
从第二部分的每个样本,取5g面粉,加入1g聚乙二醇和200ml去离子水混合均匀后,用离心机在7000r/min的条件下离心8min,然后取10ml溶液中上层清夜置于玻璃器皿中,放于恒温烘干箱,以35℃的温度烘干24h,将析出固体取出备用。
1.2.2光谱扫描
取2mg的经过富集处理的面粉样本,在玛瑙研钵中研磨成细粉末与溴化钾(光谱纯)粉末(200mg,粒度200目)混合均匀,装入模具内,以20mpa压力在压片机上压20s制成片。将压好的片放在仪器上扫描光谱,该仪器的光谱波长范围为400~4000cm-1,分辨率为4cm-1、平均扫描次数为32,仪器在正式扫描前预热至少60min,实验温度控制在20℃左右,尽量减少环境温度对实验结果造成影响,确保采集得到的光谱数据的一致性。
2.1采集光谱
样本的准备及光谱的扫描是接下来进行定量分析工作的基础,得到的数据是决定后续数据分析与处理方法选择的源头,会直接影响到模型学习效果和预测能力。
将分离富集前后两部分样本采集的光谱数据转换成csv文件,导入origin8.0软件制图,得到全体样本的光谱图如图2所示。don化学结构为3α,7α,15-三羟基-12,13-环氧单端孢霉-9烯-8酮,分子式,不饱和酮基的存在使得其在短波紫外下有吸收峰,但与许多其它物质在此处的紫外吸收峰相重叠,属非特征性的。
观察图1中的光谱曲线可知,虽然每个样本中don含量都不相同,但其光谱曲线在整个波段区域内都表现出极为相似的变化趋势,尤其在波峰和波谷处,表明各样本在化学组成成分和特征波长方面具有相似性。
所测波段中,1677~1537cm-1均是蛋白质的特征吸收峰;1525~1479cm-1为脂肪的特征吸收峰;1785cm-1为脂肪酸特征吸收峰;而1824cm-1吸收值很小,可能为噪声等杂峰。而don的产生主要与淀粉、蛋白质和脂肪相关,所以通过光谱波峰变化可以完整的读取到其中所含物质的信息。
经分离富集后,样本的don浓度可以提升5倍左右。将样本或分为训练集和预测集,保证划分后的样本能均匀分布并对全样本具有良好的代表性,以增强模型的精确度和代表性。表1为样本分离富集后don常规数据统计分析。
表1样本don常规数据统计分析
tab.1partialsampledoncontent
2.2异常样本的剔除
光谱分析过程中,经常产生异常样本,导致该情况发生的原因较多,包括测量背景变化,仪器噪声干扰等都可能使光谱数据出现偏差,常表现为参考值异常和光谱值异常。对于浓度异常或者光谱异常样本,建模之前需将异常样本剔除,保证模型的准确性,已提高模型的预测精度。此次研究中采用马氏距离法对异常样本进行了剔除。
马氏距离法是一种基于一组点与多变量空间质心之间的距离的判别方法。该方法基于样本光谱矩阵对样本数据进行标准化和中心化,计算出所有样本的空间马氏距离,通过设定阈值将样本马氏距离超过阈值的样本判定为异常样本。
马氏距离法假设其中为来自的n个样本,其中,则样本到重心的马氏平方距离定义为。其中可由样本协方差阵来估计。
易证,当n较大时,近似服从,其临界值可由分布表来查出。当时,将第i个样本判为异常。
由图2可知,处于马氏距离阈值附近的11,14,89,100号样本在建模样本中易造成模型预测精度下降。因此样本被认定为异常样本并将其剔除。对分离富集后的样本进行同样操作后,剔除6个异常样本。
2.3光谱预处理及分析
受外界环境因素的干扰、仪器的不稳定等客观因素,近红外光谱中包含有各种噪音,在建模之前则需要先预处理近红外光谱数据,抑制光谱的散射,漂移等,减小模型的误差,从而提升模型的预测精度。通过阅读相应参考文献,本实验中对原始光谱进行扣除大气背景,矫正基线,savitzky-golay多点平滑,分离富集前后,两部分样本经过预处理的近红外光谱图如图3:
2.4建模参数选取
为加快训练网络的收敛性,采取mapminmax()将数据归一化到(-1,1),训练目标误差设置为10^-8;学习率的设置不应过大,过大虽然在开始时会加快收敛效果,但临近最佳点时,会产生动荡,而致使无法收敛,将其设置为0.1。针对隐含层的层数设定,为了加快网络的训练速度,实验中将其数量设定为3层。隐含层节点数会影响网络模型的性能,取8。测试数据:随机的选取83个样本的数据作为训练数据,其余20个作为测试数据进行检验。
检验结果如表2:
表2don含量预测结果
样本分离富集后真实值与预测值拟合曲线如图4所示,斜率为0.93,截距为63.86,拟合曲线的r2为0.9278,说明拟合效果较好。相同浓度条件下,较直接扫描时的拟合效果更为精准。采用分离富集对样本预测集的建模,计算结果略有变化,预测集均方根误差由516.84降至273.56,误差区间在62.3到583.2间,说明模型偏离真实值的程度显著降低。
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!