基于高光谱图像技术的窖泥总酸预测模型建立的方法与流程
本发明涉及一种基于高光谱图像技术的窖泥总酸预测模型建立的方法,属于固态发酵指标检测技术领域。
背景技术:
固态发酵技术在我国有着悠久的历史,也是我国特有的酿造工艺。在白酒酿造行业中,窖泥是发酵的基础,其中以己酸菌为主的有益微生物菌群,利用糟醅中的营养物质进行产酸产酯,己酸乙酯是浓香型白酒的主体香味成分,因此窖泥在生产过程中对浓香型白酒质量起着决定性作用,评价窖泥好坏就显得比较重要。没有好的窖泥,就不能生产上乘的优质酒。
目前很多酒厂都面临入窖酸度过高的情况,这会严重影响酒糟的正常发酵,且导致出酒率过低。因为参与糖化和发酵的各种酶系,需要在适宜的酸度条件下才能发挥显著作用。因此入窖前,实时在线监测窖泥酸度,以便及时做出工艺调整,对防止窖泥酸化、老化是很有必要的。目前常用的总酸检测方法是电位滴定法,此方法耗时耗力,影响因素众多,导致误差偏大,并且检测结果往往滞后于实际生产。针对此问题,有学者研究用其他方法进行检测,如专利:高光谱图像技术定量检测固态发酵指标分布差异的方法(cn201510641747),采集镇江香醋醋醅的全波段高光谱图像,筛选最优特征波数,建立含量预测模型;计算每个像素点对应的ph值;绘制含量分布图;计算目标区域所有像素点ph均值、标准差、nu值,以此定量分析指标含量分布图像的分布差异。
该专利的不足:该专利检测的是ph值,即游离氢离子浓度,因此ph与酸性物质的种类及含量息息相关,发酵基质对光谱的特征吸收性能也通过各种酸类物质所携带的发色基团表现,因为一种物质的光学特性一般是通过官能团表现出来的,不同官能团对不同波段光的吸收强弱存在差异,与分子结构有关。经前期预实验以及资料查询发现,总酸主要是通过羧基表现出其光学特性,并且在近红外波段有较强的吸收,而该专利仅采集了可见光区域的图像和光谱信息;未做全光谱与特征光谱的比较,直接筛选特征波长对应的光谱信息作为模型的输入变量,容易漏掉重要信息;未进行预处理去噪,易将非样本信号纳入计算;建模方式也较单一。
技术实现要素:
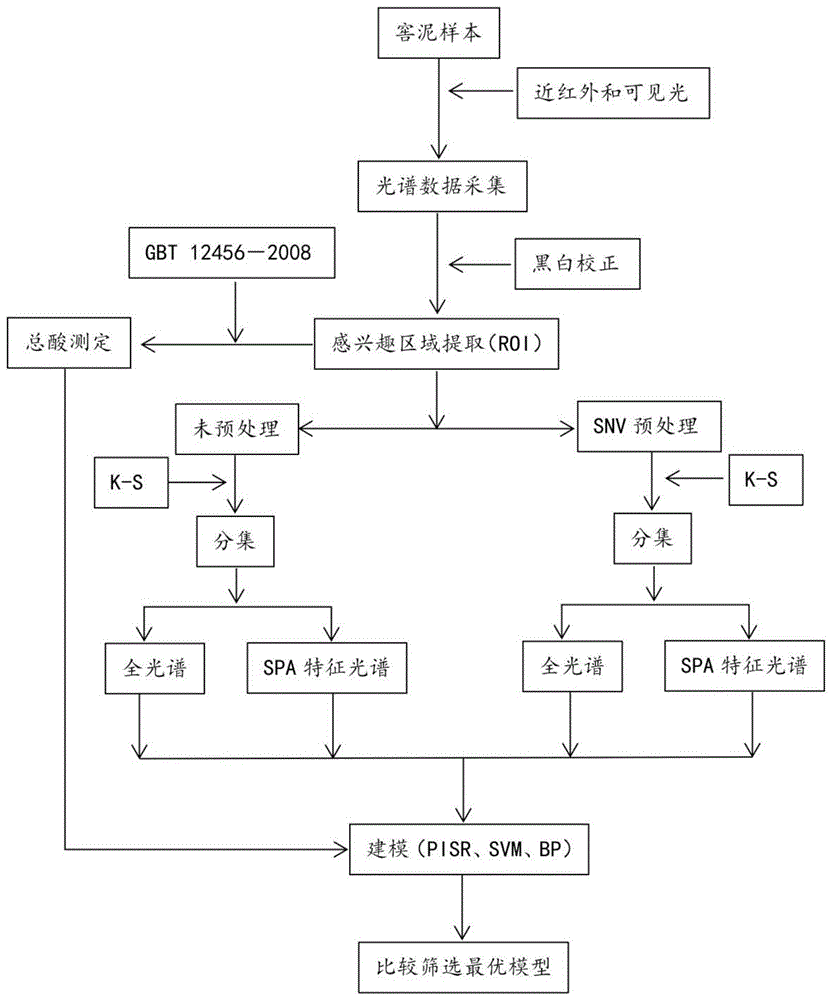
本发明的目的是提供一种基于高光谱图像技术的窖泥总酸预测模型建立的方法,通过搭建高光谱数据采集系统,采集不同窖龄不同层次窖泥的光谱数据,对其进行校正处理,提取具有代表性的感兴趣区域每个像素点的平均光谱反射率,利用近红外以及可见光、不做处理以及snv、全光谱以及特征光谱,结合不同的建模方式,建立窖泥总酸的预测模型,根据模型在训练集和测试集数据上的表现性能,筛选最优模型。本发明为白酒酿造产业化的转型升级以及数字化、智能化在线实时监测提供一种强有力的技术支持。
本发明采取的技术方案是:
基于高光谱图像技术的窖泥总酸预测模型建立的方法,包括以下步骤:
步骤一、光谱采样标定:为了消除光照不均匀等因素引起的误差,需要在采样之前,通过标定板对样品光谱数据进行黑白校正;
标定板颜色要与样品接近,否则容易干扰对样品光谱数据的采集,且反射性能要略优于样品的标定板才能实现对样品原始光谱的校正,此外,样品在可见光和近红外区域下的光谱反射性能不同,因此需要选择不同颜色的标定板,才能获取接下来可分析的数据信息。
针对近红外(900~1700nm)和可见光(400~1000nm)波段的差异,在可见光下选择灰色标定板,近红外光下选择米黄色标定板,同时对两个波段的标定分别进行参数设置,所述参数包括打光峰值、曝光频率、时间、平台移动速度;参数设置详见表格。
步骤二、高光谱数据采集:在设置好的参数下,分别采集n份窖泥样本在近红外和可见光波段的全光谱数据,通过envi软件进行黑白校正并将原始光谱信息转化成光谱反射率,提取感兴趣区域(roi),保证能代表样本绝大部分信息;
全光谱数据指的是近红外波段下的224个波长对应的光谱数据和可见光波段下的448个波长对应的光谱数据,而原始光谱信息指的是未经过任何处理的光谱数据。
步骤三、表征指标含量的测定:本发明参考gbt12456-2008中ph电位法,对样品总酸进行检测,为提高模型预测效果,总酸的测定区域要与手动选择的感兴趣区域对应;
步骤四、预处理:考虑到数据采集过程中的噪音、基线漂移等因素可能影响模型精度,将步骤二提取出的光谱信息经过snv预处理后,得到用于后续分析的数据,同时不做处理对照;
步骤五、数据分集:将近红外以及可见光范围内的窖泥样本分别通过k-s算法分为训练集和测试集;
训练集数据主要用于模型的建立,测试集数据主要用于检验模型的预测效果。
步骤六、筛选特征光谱:运用spa算法分别从近红外以及可见光的全光谱数据中筛选出与总酸表征指标紧密相关的特征光谱,其与全光谱相对应;因可见光和近红外,不做处理的和snv预处理得到的用于后续分析的光谱数据不同,经过spa筛选分别得到4组特征波长。
考虑到总酸对光谱的吸收具有选择性,窖泥内部存在多种化合物对光能的吸收,可能会造成相关波长的波谷或波峰的叠加,为提高模型的稳健性和预测效果,需寻找与总酸紧密相关的特征波长,剔除不相关波长。
步骤七、建模:选取近红外区域的前180个波长、可见光区域全部波长的光谱信息,分别基于全光谱和特征光谱对训练集样本建立不同的定量预测模型(plsr、svm、bp),共计24种模型,通过训练集和测试集的决定系数和均方根误差来评价并筛选出最优预测模型,从而建立一种快速预测窖泥水总酸量的方法。
进一步的,训练集和测试集按照一定的比例进行划分,最终近红外训练集样本72个,测试集样本33个;可见光训练集样本72个,测试集样本36个。
本发明的有益效果:
首次将高光谱成像技术与窖泥总酸实测值相结合,从而建立一种新型、快速、高效的窖泥总酸检测方法,为白酒产业数字化在线监控提供强有力的技术支持。
经过预实验以及前期资料查询发现,总酸所含的分子结构在可见光和近红外波段均有吸收。为筛选与总酸密切相关的特征波段,本发明在可见光(400~1000nm)和近红外(900~1700nm)波段下分别采集窖泥总酸光谱信息,用于后续分析,力争建立窖泥总酸预测的最佳模型。
在前期进行采样标定时,本发明针对特定样品,选择与之相近的,并在光谱反射性能上略优于样品的标定板。此外,考虑近红外和可见光波段的差异,本发明在可见光下选择灰色标定板,近红外下选择米黄色标定板。
考虑到玻璃器皿较强的反光性能,本发明优先选用石英材质的器具用于样本光谱数据的采集,提高模型的精度。
为获得窖泥总酸预测的最优模型,后期做了大量分析工作,包括不做处理以及snv预处理,全光谱以及特征光谱、不同建模方法等。
附图说明
图1最优模型建立流程图;
图2不同窖泥近红外光谱反射率曲线图;
图3不同窖泥可见光光谱反射率曲线图;
图4近红外光谱训练集模型总酸指标检测效果图;
图5近红外光谱测试集模型总酸指标检测效果图;
图6可见光光谱训练集模型总酸指标检测效果图;
图7可见光光谱测试集模型总酸指标检测效果图。
具体实施方式
窖泥总酸定量预测模型建立的工艺流程如图1所示。
(1)窖泥样本采集:样本采自四川省宜宾市某知名酒厂,采样时工人刨开遗漏的酒糟,以黄水为分界线,用铁铲收集同一水平面四周的窖泥,将其用取样袋封好即成一个样本,同一窖池的采样部位包括窖帽、黄水中和窖底泥三层,共3个样。以此方式获得不同窖龄的窖泥总计108份。
(2)高光谱采集系统:采用芬兰specimfx17系列高光谱相机,2组160w的y型光纤卤素灯作为光源,利用lumoscanner软件控制相机和精密电控载物台进行光谱数据采集。
(3)参数设置及光谱数据采集:通过调节电动载物台运行速率,使其与相机图像扫描频率相匹配,设置高光谱近红外相机下的标定板为米黄色,曝光时间为4.02ms,采集频率为50hz,载物台的移动速度为16.42mm/sec;高光谱可见光相机下的标定板为灰色,曝光时间为8.00ms,采集频率为50hz,载物台的移动速度为10.79mm/sec。将装好窖泥并铺平的石英器皿放置于载物台中心位置,在400~1000和900~1700波段下分别采集108份窖泥样本的高光谱原始图像信息,通过envi软件手动提取像素为100x100的矩形感兴趣区域(roi),并进行校正处理转化为每个像素点的平均光谱反射率,从而分别得到近红外波段105条包含224个波长下的光谱数据以及可见光范围108条包含448个波长的光谱数据。为方便观察,本发明以两个窖池的窖泥为例,阐述不同窖龄窖泥在近红外和可见光波段下光谱反射率曲线的差异,选取了6条分别包含近红外全波段(224个波长)以及可见光全波段(448个波长)的光谱反射率曲线,如图2、3所示,图中一个是6年的新窖,一个是30年的老窖,30年的窖泥光谱反射率普遍高于6年的光谱反射率。不同层级的窖泥光谱反射率曲线也不同,说明高光谱可以对不同年份不同层级的窖泥进行识别。
(4)窖泥总酸检测:为提高模型的精度,取样部位与感兴趣区域对应,总酸的测定方法参考gbt12456-2008中ph电位法。
(5)光谱数据预处理:光谱数据包含大量的噪声信号,需要对其去噪,经前期大量分析工作发现,标准变量变换(snv)能有效去除高频噪音、防止基线漂移,优化光谱信号,因此本发明采用的光谱预处理方法是snv。
(6)样本分集:在数据建模前,通常会将数据集划分为训练集和测试集,训练集数据主要用于模型的建立,测试集数据主要用于检验模型的预测效果,根据预测效果筛选最优模型。通过k-s算法将样本数据划分为训练集和测试集。训练集和测试集按照一定的比例进行划分,最终近红外训练集样本72个,测试集样本33个;可见光训练集样本72个,测试集样本36个。
(7)特征光谱的筛选:总酸对光谱的吸收具有选择性,窖泥内部存在多种化合物对光能的吸收,会造成相关波长的波谷或波峰的叠加,为提高模型的稳健性和预测效果,需寻找与总酸紧密相关的特征波长,剔除不相关波长。本发明采用spa算法筛选特征波长。因不做处理和snv预处理得到的用于后续分析的光谱数据不一致,经过spa筛选分别得到4组特征波长,如表1所示。
表1特征波长统计表
(8)预测模型的建立:为比较获得最佳预测模型,将近红外、可见光、不做处理及预处理、全光谱及特征光谱得到的光谱数据分别结合窖泥总酸实测值建立plsr、ls-svm、bp三种模型,通过对最终拟合模型的训练集和测试集均方根误差的比较获得最优模型。鉴于经过不同处理的拟合模型较多,本发明以snv-spa-plsr为例,分别阐述基于近红外和可见光的偏最小二乘模型,近红外的训练集和测试集模型的总酸检测效果如图4、5所示,训练集的决定系数r2=0.9982,均方根误差rmse=0.1058;测试集的决定系数r2=0.9953,均方根误差rmse=0.3023。可见光的训练集和测试集模型的总酸检测效果如图6、7所示,训练集的决定系数r2=0.9997,均方根误差rmse=0.0668;测试集的决定系数r2=0.9946,均方根误差rmse=0.2858。说明在所选取的两种建模方式中,基于可见光的snv-spa-plsr模型在训练集上真实值与预测值的拟合效果更好,但模型在测试集上的性能相对较差,基于近红外的snv-spa-plsr模型的稳健性和泛化性能更好,抗干扰能力更强,更适合应用于窖泥总酸的快速检测。经过不同处理的拟合模型在训练集和测试集上的表现性能如表2所示,从表2可以看出,与bp相比,plsr与svr两种建模效果更好。近红外波段下,经过snv预处理后的特征光谱svr与可见光下的不做处理特征光谱svr两种模型的泛化性能较好,精度较高,抗干扰能力较一致。在可见光波段下,经过snv预处理,分别基于全光谱和特征光谱建立的plsr两种模型在训练集上各真实值与预测值的拟合效果最好,但对模型的预测效果稍差,模型的稳健性欠缺。因此,综合考虑,通过对比分析各拟合模型的检测效果,最终选定基于可见光波段下的不做处理特征光谱的svr模型做为窖泥总酸定量预测的最佳模型。
表2各拟合模型在训练集和测试集上的表现性能统计表
- 还没有人留言评论。精彩留言会获得点赞!