一种非居民用户非侵入式负荷用电信息采集方法与流程
本发明属于智能用电及技术领域,具体涉及一种非居民用户非侵入式负荷识别方法。
背景技术:
负荷监测技术对于智能电网的建立具有重要意义。一方面,它可以把采集到的用户用电信息提供给电网侧,提高电网的利用效率,另一方面,它可以把用户的用电信息反馈给用户,改善用电行为。
目前,负荷监测技术主要分为“侵入式”和“非侵入式”。通常,侵入式负荷监测需要把传感器放置在用户内部各用电负荷处,在传感器的安装与维护过程中,需要对用户进行断电。因此,虽然这种技术得到的数据可靠,但用户的接受程度较低。相比之下,非侵入式负荷监测只需在用户电力供给的入口加入一个监测设备便可对整个用户内部负荷进行监测,对用户几乎没有影响,因此具有很强的实用性。
通过把ai芯片放在检测设备从而实时处理数据是负荷识别是非侵入式负荷监测中最重要的一步,它直接反映了用户负荷的使用信息。非侵入式负荷监测中收集的数据通常由多个负荷的运行状态决定。但是现有技术对于多个负荷同时运行的混合信号的识别仍然存在较大问题。
技术实现要素:
本发明为了解决现有技术中无法有效对于多个负荷同时运行的混合信号的识别的问题,通过对负荷特征采用随机森林算法建立模型进行识别的方案。
具体而言本发明提供了一种非居民用户非侵入式负荷识别方法,其特征在于,所述负荷识别方法包括以下步骤:
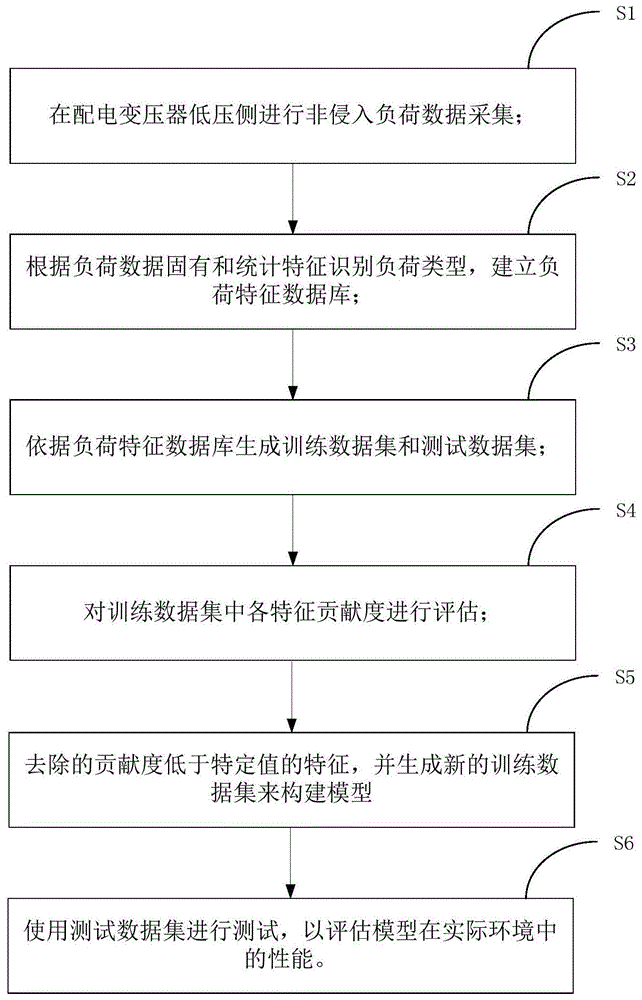
步骤s1:在配电变压器低压侧进行非侵入负荷数据采集;
步骤s2:根据负荷数据固有和统计特征识别负荷类型,建立负荷特征数据库;
步骤s3:依据负荷特征数据库生成训练数据集和测试数据集;
步骤s4:对训练数据集中各特征贡献度进行评估;
步骤s5:去除的贡献度低于特定值的特征,并生成新的训练数据集来构建模型;
步骤s6:使用测试数据集进行测试,以评估模型在实际环境中的性能。
更进一步地,在步骤s2中,所述负荷特征数据库实时根据用户新增的电器更新数据库。
更进一步地,步骤s3中,所述训练数据集包括样本数据和与样本数据相关标签集;
所述与样本数据相关标签集包括数据库中所有负荷种类的标志位,并对参与叠加的负荷种类的标志位将被标记为“1”,未参与叠加的负荷种类的标志位将被标记为“0”。
更进一步地,步骤s3中,所述样本数据是由所述负荷特征数据库中多种负荷的模板波形叠加形成的混合信号。
更进一步地,步骤s4中,所述特征包括电流均方根irms,振幅系数ic,电流最大值imax,有功功率p,无功功率q,功率因数pf,基波fw和第三谐波har3rd。
更进一步地,步骤s4中,所述训练数据集中任一特征的贡献度可表示为:
其中,c代表所述训练数据集中特征总数,
更进一步地,步骤s5中,所述特定值为5%。
更进一步地,步骤s6中,所述评估方式包括准确率;
所述准确率acc可表示为:
其中,tp和tn分别代表对正样本和负样本预测正确的数量,而fp和fn则分别代表对正样本和负样本预测错误的数量。
更进一步地,步骤s6中,所述评估方式包括f-score计算;
所述f-score计算可表示为:
其中,pa代表第a种负荷的精确率,即预测结果为正的样本中实际为正的样本的比例;ra代表第a种负荷的召回率,即所有正样本中被正确预测为正的样本的数量;b是识别负荷的总数。
精确率和召回率之间互相排斥,因此选用f-score这个概念对其进行平衡。
精确率p可表示为:
召回率r可表示为:
本发明的有益效果是:
本发明根据在非侵入用电数据采集条件下,将采集到的负荷进行特征提取并建立特征库,利用基于随机森林算法的多标签分类方法对非居民用户负荷依据特征进行识别,具有良好的识别速度和精确度。
本发明同时对特征库中的负荷特征贡献度进行评判,筛选出影响较大的特征,去除贡献度较小的特征,简化了分类模型的计算复杂程度,降低了模型构建,在构建完成的分类器对实际数据的识别时间上同样具有优越性。
附图说明
图1是本发明实施例提供的一种非居民用户非侵入式负荷识别方法的流程示意图;
图2是本发明实施例提供的一种非居民用户非侵入式负荷识别方法中对训练数据集各特征贡献度计算的示意图。
具体实施方式
下面通过实施例,并结合附图1-2,对本发明的技术方案作进一步具体的说明。
如附图1所示,本申请的实施例提供了一种非居民用户非侵入式负荷识别方法,包括以下步骤:
步骤s1:在配电变压器低压侧进行非侵入负荷数据采集;
步骤s2:根据负荷数据固有和统计特征识别负荷类型,建立负荷特征数据库;
步骤s3:依据负荷特征数据库生成训练数据集和测试数据集;
步骤s4:对训练数据集中各特征贡献度进行评估;
步骤s5:去除的贡献度小的特征,并生成新的训练数据集来构建模型;
步骤s6:使用测试数据集进行测试,以评估模型在实际环境中的性能。
具体的,在步骤s1中,首先在配电变压器低压侧进行非侵入负荷数据采集,对变压器侧三相电流、电压等数据进行准确的采集。
在步骤s2中,在实际运行中,不能直接从混合信号中获得独立负载的运行状态。对于相同类型的负荷,不同的品牌将导致负荷波形的显著差异。
因此,本发明为独立用户构建负荷特征库,该特征库为不同用户的每种负荷建立相应的电流信号模板。用户的所有信号模板构成该用户的专属负荷特征库。同时,负荷特征数据库实时根据用户新增的电器更新特征库。虽然采样保证了负荷特征数据库的实时更新,但是在现实生活中,一旦完成了特征数据库的建立,在短时间内就很少有新的负荷加入。因此,特征库将每天定时更新,而这一过程将不会在其他时间执行以节省时间。
具体的,首先通过由变压器侧非侵入式数据实时采集的负荷数据,并对负荷数据进行事件检测、负荷分解、负荷分簇和利用生活习惯等先验数据对负荷进行识别,并将每种负荷的特征进行存储,建立负荷特征数据库。
在步骤s3中,建立训练数据集和测试集,多标签分类作为一种典型的有监督学习方法,需要数据集来构建模型。将数据集分为训练数据集和测试数据集两类。训练数据集用于构建模型,而测试集用于评估模型在实际中的性能。训练数据集由两部分组成:一部分是样本数据,一部分是与样本数据相关标签集。对于测试集,它只包含从实际场景中获取的样本数据。在分类模型构建完成后,测试数据集将作为模型的输入,而输出结果将会被用来评判模型的依据。
样本数据是由负荷特征数据库中多种负荷的模板波形叠加形成的混合信号,首先计算数据库中负荷种类的数目,并从其中随机选取负荷,将抽取出的负荷进行叠加生成混合信号,最后冲混合信号中提取特征作为样本数据,由相同负荷叠加产生的混合信号波形是固定的。对于与样本数据相关标签集中,包括数据库中所有负荷种类的标志位,并对参与叠加的负荷种类的标志位将被标记为“1”,未参与叠加的负荷种类的标志位将被标记为“0”。
在步骤s4中,本发明通过随机森林法对各特征的贡献度进行计算,根据各特征的贡献度比较进行特征选择,并进一步来识别负荷。由于不同种类的负荷在混合信号中各特征表现也不尽相同,有一些特征具有较大的影响,而有一些特征影响较小,因此从混合信号中提取了多个特征用来进行负荷识别,通过对各特征贡献度的计算来进行评估,找到最适合用于负荷识别的特征,这些特征由f表示:
f={irms,ic,imax,p,q,pf,fw,har3rd}(1)
式中:irms代表电流均方根,ic代表振幅系数,imax代表电流最大值,p和q分别代表有功功率和无功功率。pf代表功率因数,fw代表基波而har3rd代表第三谐波。irms,ic,imax都可以直接从电流信号中获得;p,q,pf通过计算电流和电压得到;而fw和har3rd可以由fft得到。
如附图2所示,训练数据集中有l个训练子集,训练子集是一个包含一个或多个特征的叠加混合信号,每个子集对应一棵决策树,每棵决策树上有n个节点。
贡献度由gini系数得分进行评定。第j个特征在节点m处的gini系数得分可由公式2计算:
其中,gim代表第j个特征在节点m处的gini系数,可以由公式3得到。gil和gir代表第j个特征在从节点m分裂产生的节点l和r上的gini系数,j的范围为1-7的整数,分别对应f中的各特征。
其中,pmj代表第j个特征在节点m处的权重。
当在第i棵决策树上有n个节点时,第j个特征在树i的贡献度可表示为:
随机森林中有l棵决策树时,第j个特征的贡献度可表示为:
最后,当所有特征的贡献度都计算完毕后,第j个特征的gini系数得分可由归一化计算得到,可表示为:
其中,c代表训练样本中特征总数,
在步骤s5中,对特征贡献度评价完成后,为了降低将计算复杂性,将舍弃那些对结果影响贡献度低于5%的特征,并通过保留的对结果影响较大的特征来构建模型。
保留的特征及其相关标签将被重组成新的训练数据集。并且新的数据集将会作为输入来构建模型。模型的建立需要大量的数据来修改参数,从而最大限度地提高模型的分类性能。
在步骤s6中,在建立模型之后,使用测试数据集进行测试,以评估模型在实际环境中的性能。
用准确率和f-score作为评价分类效果的指标,准确率被用来评估分类的整体效果,代表预测结果正确的比例。准确率acc可表示为:
其中,tp和tn分别代表对正样本和负样本预测正确的数量,而fp和fn则分别代表对正样本和负样本预测错误的数量。
f-score是一种对pa和ra的加权平均计算,可表示为:
其中,pa代表第a种负荷的精确率,即预测结果为正的样本中实际为正的样本的比例;ra代表第a种负荷的召回率,即所有正样本中被正确预测为正的样本的数量;b是识别负荷的总数。
精确率和召回率之间互相排斥,因此选用f-score这个概念对其进行平衡。
精确率p可表示为:
召回率r可表示为:
虽然本发明已经以较佳实施例公开如上,但实施例并不是用来限定本发明的。在不脱离本发明之精神和范围内,所做的任何等效变化或润饰,同样属于本发明之保护范围。因此本发明的保护范围应当以本申请的权利要求所界定的内容为标准。
- 还没有人留言评论。精彩留言会获得点赞!