一种超宽带雷达人体目标姿态可视化增强方法与流程
本发明涉及雷达信号处理领域,特别是一种超宽带雷达人体目标姿态可视化增强方法。
背景技术:
超宽带雷达相比于窄带雷达具有宽频和低频的特点,可获取更为丰富的目标散射信息,可对墙体、挡板、树叶等非透明介质进行穿透探测,在目标成像、目标识别、穿墙探测、叶簇透视等方面有较大的优势。其中,穿墙雷达人体探测是超宽带雷达的一个重要应用,穿墙雷达可获取墙后人体目标的位置和运动信息,提升人们对建筑物的透视感知能力,辅助决策人员对建筑物内部情况进行判断,在反恐维稳、战场监视、灾后救援等方面发挥了重要的作用,因此超宽带雷达技术的研究具有重要的实践意义和应用价值。
雷达成像是穿墙雷达系统使用人员了解墙后人体目标情况最直观、有效的手段,尤其对于三维超宽带穿墙雷达,可以从三维成像结果中获取目标的距离-方位-高度信息,甚至是人体目标各个肢体部位的位置信息。然而,受应用需求以及硬件水平的限制,超宽带雷达系统的距离分辨率和方位分辨率通常较低,导致成像结果的分辨率比较低,无法给出直观的人体目标姿态可视化结果,不利于非专业使用人员对墙后目标的正确判读。
近年来,神经网络技术飞速发展,在信号和图像处理方面得到了广泛应用。在光学图像处理领域,基于深度神经网络的人体目标姿态估计已经取得了一定的成效,并且优于传统的人体姿态数据库匹配方法。然而,相比于光学图像,低频超宽带雷达的成像结果分辨率较低,传统方法很难准确估计出人体目标的姿态并得到较好的可视化结果,而基于深度神经网络的研究也比较少。因此,借助深度神经网络强大的非线性拟合能力对超宽带雷达图像的人体姿态可视化增强方法进行研究是很有必要的。
技术实现要素:
本发明所要解决的技术问题是针对现有技术不足,提供了一种超宽带雷达人体目标姿态可视化增强方法,通过深度神经网络工具从抽象的低分辨率雷达数据中估计人体姿态,并进行三维显示,提高了传统超宽带雷达系统的人体目标姿态可视化能力。
本发明所采用的技术方案是:
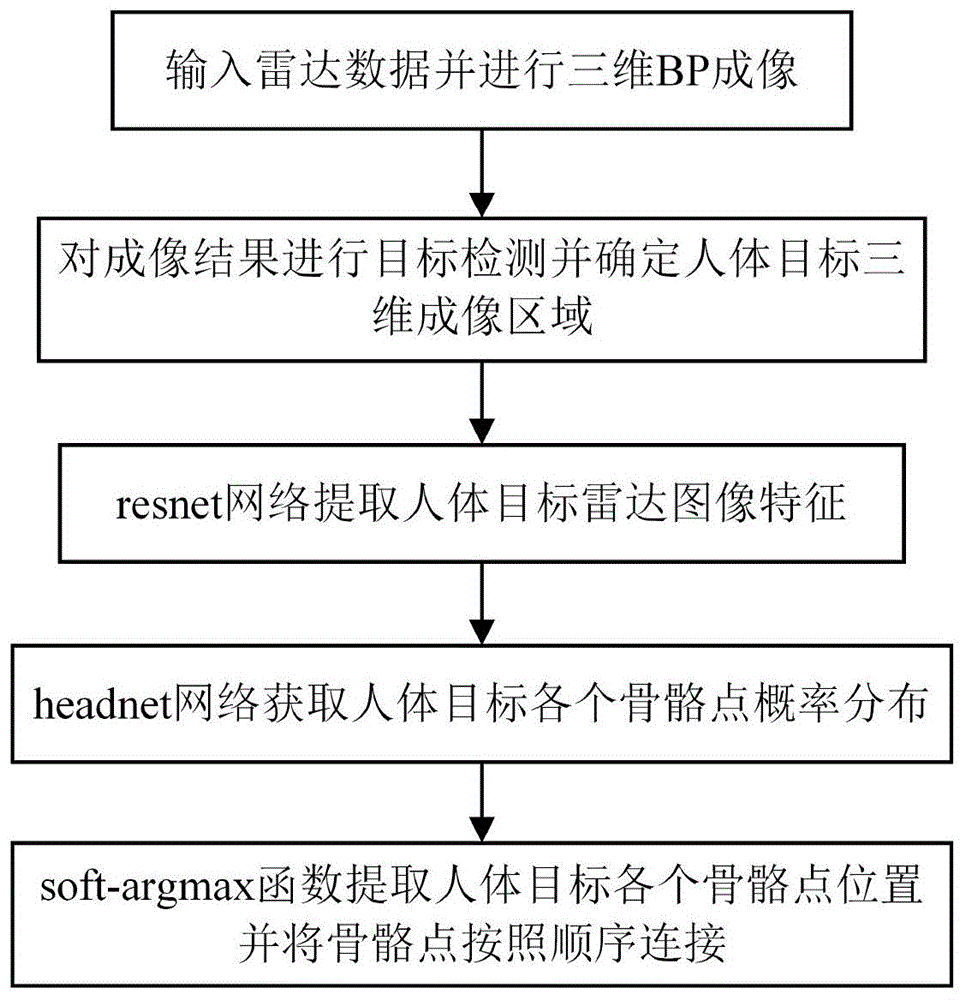
一种超宽带雷达人体目标姿态可视化增强方法,包括以下步骤:
1)输入接收的雷达信号并进行三维bp成像,得到探测场景的三维成像结果;
2)对成像结果进行检测,获得人体目标的三维成像区域;
3)将连续多帧人体目标雷达成像结果输入resnet网络进行特征提取;
4)使用headnet网络将resnet网络提取的特征转换为人体目标各个骨骼点概率分布;
5)使用soft-argmax函数从骨骼点概率分布中提取人体目标各个骨骼点的位置坐标,并将所有骨骼点坐标按照顺序连接。
步骤1)中,将雷达回波信号表示为smn(t),第k个频点回波表示为smn,k(t)=σexp(-j2πfkτmn),其中σ为目标的散射系数,fk为第k个频点对应的频率,τmn为目标关于第mn个收发通道的总延时;使用后向投影(bp)方法对回波进行成像,得到三维成像结果为
步骤2)中,将三维成像结果沿着高度向取最大值,得到方位-距离平面最大值投影结果ixy,对该结果进行检测确定人体目标在方位-距离平面的位置,根据目标位置从测试场景的整体三维成像结果中截取目标附近的三维成像区域作为人体目标的三维成像结果。
步骤3)中,对人体目标的三维成像结果分别做方位向、距离向和高度向的最大值投影,得到三个成像结果iyz、ixz、ixy,将人体目标的连续多帧最大值成像结果输入已经训练好的resnet-18网络中,对人体目标对应雷达图像进行特征提取,生成特征矩阵。
步骤4)中,使用headnet网络将特征矩阵转换为人体目标各个骨骼点的概率分布hk(p),其中k指第k个骨骼点,p是成像空间中不同的位置,人体目标各个骨骼点的概率分布是指人体各个骨骼点在成像空间中的不同位置的概率。
步骤5)中,使用soft-argmax函数从人体目标各个骨骼点的概率分布hk(p)中提取最大值位置索引作为该骨骼点的三维坐标位置jk,即
与现有技术相比,本发明所具有的有益效果为:
本发明提供了一种超宽带雷达人体目标姿态可视化增强方法,针对传统超宽带雷达人体成像结果比较抽象且分辨率低,很难直观理解的问题,通过首先对探测场景进行三维成像;检测人体目标的位置,获取人体目标的成像结果;然后使用resnet网络对人体目标对应的雷达图像进行特征提取;使用headnet网络将特征矩阵转化为人体骨骼点的概率分布;最后使用soft-argmax函数提取人体骨骼点位置坐标,并将坐标点进行连接显示,得到人体目标的可视化三维姿态图。本方法借助深度神经网络工具从抽象的三维雷达图像中估计出三维人体姿态,增强了超宽带雷达人体目标探测的可视化性能,辅助使用人员对人体目标的姿态进行更高精度的判读。
附图说明
图1是本发明实施例的总体流程图;
图2是本发明实施例采用的深度神经网络结构图;
图3是本发明实施例的超宽带雷达人体目标姿态增强结果图。
具体实施方式
下面结合附图和具体实施例对本发明进一步详细说明。
参照附图1,本发明提出的一种超宽带雷达人体目标姿态可视化增强方法,具体通过以下步骤实现:
步骤1,输入接收的雷达信号并进行三维bp成像,得到探测场景的三维成像结果。
本实施例中,将雷达回波信号表示为smn(t),第k个频点回波表示为smn,k(t)=σexp(-j2πfkτmn),其中σ为目标的散射系数,fk为第k个频点对应的频率,τmn为目标关于第mn个收发通道的总延时;使用后向投影(bp)方法对回波进行成像,得到三维成像结果为
本实施例中,雷达发射信号的中心频率为2.3ghz,带宽为1ghz,发射信号采用步进频信号体制,系统总频点数为256个,发射天线个数是10,接收天线个数是10,总的收发通道数是100。
步骤2,对成像结果进行检测,获得人体目标的三维成像区域。
本实施例中,将三维成像结果沿着高度向取最大值,得到方位-距离平面最大值投影结果ixy,对该结果进行恒虚警检测和聚类处理,确定目标在方位-距离平面的位置。根据目标位置从测试场景的整体三维成像结果中截取目标附近的三维成像区域作为人体目标的三维成像结果,截取的人体成像区域的大小为(64,64,64),即人体目标的成像结果的距离向、方位向、高度向的长度都是64个成像单元。
步骤3,将连续多帧人体目标雷达成像结果输入resnet网络进行特征提取。
本实施例中,对人体目标的三维成像结果分别做方位向、距离向和高度向的最大值投影,得到最大值成像结果iyz、ixz、ixy,将人体目标的连续多帧最大值成像结果输入已经训练好的resnet-18网络中,对人体目标对应雷达图像进行特征提取,生成特征矩阵。
本实施例中,为了防止当前时刻人体目标成像结果中部分身体部位信息缺失而导致姿态估计误差变大,本发明采用多帧数据联合估计的方法。当前时刻人体目标的三个最大值投影的大小都是(64,64),再取当前时刻以前的19帧数据,共20帧连续数据作为网络输入,即输入信号的大小为(10,20*3,64,64),其中10是batchsize。resnet-18网络的结构如附图2所示,该网络内部权重是由大量的数据训练得到的,网络的输出特征矩阵大小为(10,512,2,2)。
步骤4,使用headnet网络将resnet网络提取的特征转换为人体目标各个骨骼点概率分布。
本实施例中,使用headnet网络将特征矩阵转换为人体目标各个骨骼点的概率分布hk(p),其中k指第k个骨骼点,p是成像空间中不同的位置,人体目标各个骨骼点的概率分布是指人体各个骨骼点在成像空间中的不同位置的概率。
本实施例中,使用的headnet网络主要由5个kernelsize为4*4的反卷积层和1个kernelsize为1*1的卷积层组成,内部权重是由大量的数据训练得到的,具体结构如附图2所示。headnet网络输出数据大小为(10,16*64,64,64),其中16是人体骨骼点总个数,对应16个身体部位,分别是头、脖子、左肩、左肘、左手、右肩、右肘、右手、脊柱底部、脊柱中部、左臀、左膝盖、左脚、右臀、右膝盖、右脚。输出结果中的三个64分别指人体姿态图显示场景的距离、方位、高度单元数。
步骤5中,使用soft-argmax函数从骨骼点概率分布中提取人体目标各个骨骼点的位置坐标,并将骨骼点坐标按照顺序连接。
本实施例中,使用soft-argmax函数从人体目标各个骨骼点的概率分布hk(p)中提取最大值位置索引作为该骨骼点的三维坐标位置jk,即
本实施例中,先将headnet输出的大小为(10,16*64,64,64)的数据转换为(10,16,64,64,64)的格式,然后使用soft-argmax函数估计出16个骨骼点在人体姿态显示空间中的坐标位置,并按照(头-脖子-左肩-左肘-左手,脖子-右肩-右肘-右手,脖子-脊柱中部-脊柱底部-左臀-左膝盖-左脚,脊柱底部-右臀-右膝盖-右脚)的顺序将坐标点连接显示,其中显示空间的距离向、方位向、高度向长度都是64。具体结果如附图3所示,三个图像分别是真实人体目标姿态、作为深度网络输入的多帧雷达成像结果方位-高度平面投影,以及本方法人体目标姿态增强结果。由增强结果可知,本方法从低分辨率的雷达图像中估计出高分辨率的三维人体姿态,实现了超宽带雷达人体目标姿态的可视化增强。
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!