一种基于射频技术获取人体感知模型的方法及其利用方法与流程
1.本技术属于计算机技术领域,具体涉及一种基于射频技术和机器学习获取人体感知模型的方法,同时还涉及利用相应模型进行人体感知的方法。
背景技术:
2.传统的人体感知方案中,被检测人需要通过佩戴或穿戴各种设备主动向感知系统提供数据,如需进行长期监测,则需要被检测人24小时不间断佩戴或穿戴相应设备,增加了被检测人的负担,影响被检测人的正常生活。
3.近年来,随着视觉识别技术应用的不断推广,在人体感知方面,通过视觉识别技术也能够对人体的动作等信息进行感知和判断,但通过视觉识别的方式对人体的动作或行为进行感知,容易对被检测人的个人隐私造成影响,难以大范围推广。
4.通过激光雷达和超声波雷达扫描获取点云信息,进而反演出扫描对象的三维模型,在测绘和导航领域已有广泛应用。点云是在同一空间参考系下表达目标空间分布和目标表面特性的海量点集合,数据量非常庞大。以设备每秒采集17.5m个样本、4组采样设备、16bit复采样为例,每秒采样数据量高达1.6gbps。现在有些类似的算法设计和试验基础都是基于直接用pc和服务器进行算法实现,成本极高,严重制约了相关技术在家庭监控领域的应用。
技术实现要素:
5.本技术旨在提供一种基于射频技术获取人体感知模型的方法,同时还提供了利用相应的人体感知模型进行人体感知的方法,以及相应的电子设备。
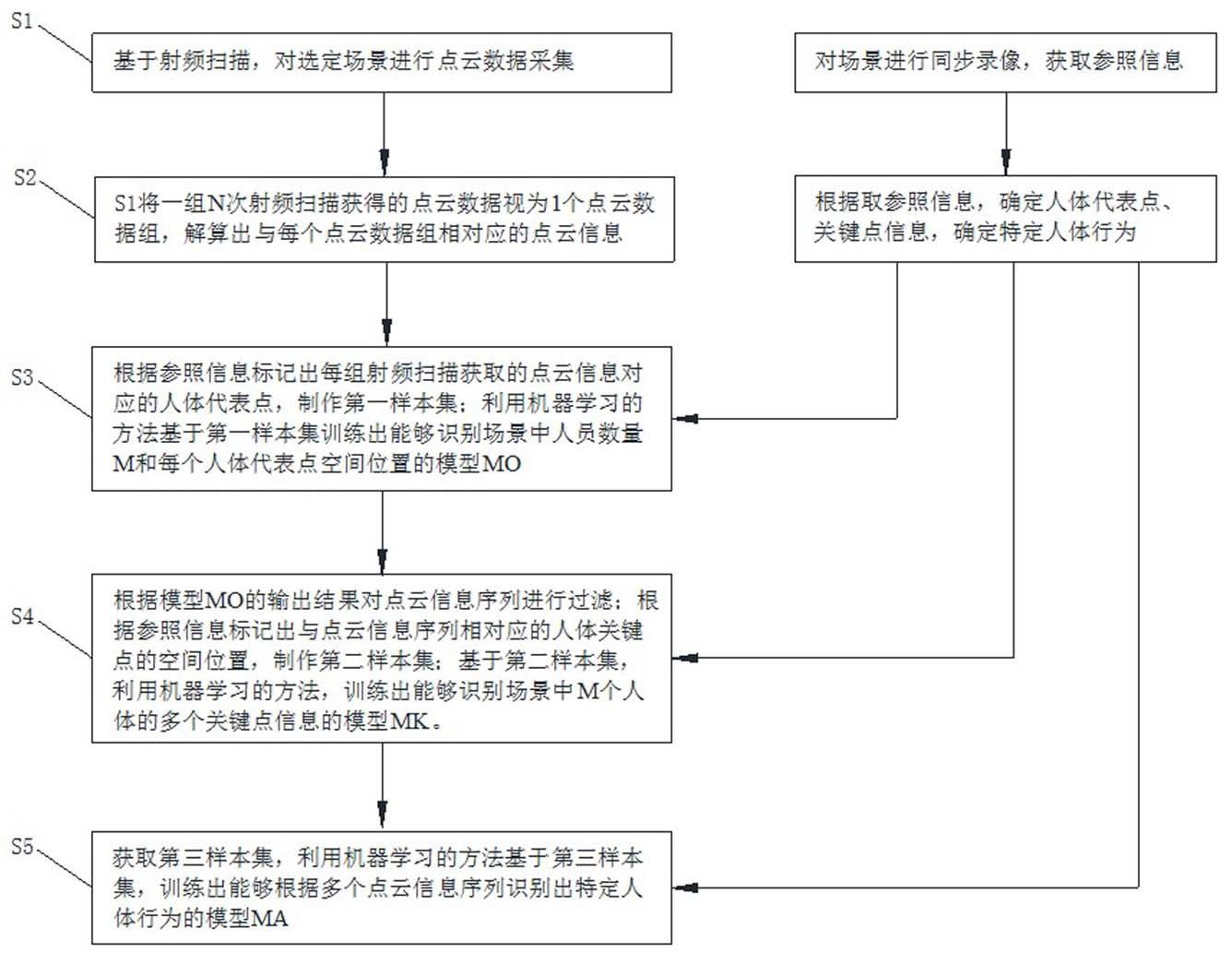
6.为实现上述目的,本技术采取了以下四个方面的技术方案:第一方面,本技术提供了一种基于射频技术获取人体感知模型的方法,包括以下步骤:s1:基于射频扫描,对某个选定场景进行点云数据采集;s2:将一组n次射频扫描获得的点云数据视为1个点云数据组,解算出与每个点云数据组相对应的点云信息,所述点云信息中与每一个反射点相对应的信息至少包括该反射点的空间位置、速度和信号强度信息;n为大于等于2的整数;s3:根据数据采集过程中记录的参照信息,标记出场景中与每组射频扫描获取的点云信息相对应的人体代表点的空间位置信息;收集多组射频扫描获得的点云信息和相应的人体代表点空间位置信息,形成第一样本集;基于第一样本集,利用机器学习的方法,训练出能够识别场景中人员数量m和每个人体代表点空间位置的模型mo。
7.进一步地,所述模型mo的输出目标为o={(prm,psm),m=1,2,3,
……
,m},prm为第m个待检测人体目标存在的概率,psm为第m个待检人体目标其代表点的空间位置,m为场景中的人数。
8.进一步地,所述方法还包括步骤s4:将n
pk
组(n
pk
×
n次)射频扫描获得的点云信息视为一个点云信息序列,根据模型mo的输
出结果对点云信息序列进行过滤,仅保留人体代表点附近特定距离范围的点云信息,得到过滤后的点云信息序列;n
pk
为大于1的整数;基于人体关节点在人体上选择多个关键点,根据数据集形成中记录的参照信息,标记出与每个过滤后的点云信息序列相对应的人体关键点的空间位置信息,收集多个信息序列并进行过滤、标记,形成第二样本集;基于第二样本集,利用机器学习的方法,训练出能够识别场景中m个人体的多个关键点信息的模型mk。
9.进一步地,所述模型mk的输出目标为每个待检人体目标的关键点信息ok={(prk,psk),k=1,2,3,
……
,k},k为选定的人体关键点个数;prk为某一个待检人体目标的第k个关键点存在的概率;psk为某一个待检人体目标的第k个关键点存在的空间位置。
10.进一步地,所述方法还包括步骤s5:获取第三样本集,第三样本集包括正例样本和反例样本,正例样本包括从参照信息中获取的某种特定人体行为和与之对应的n
ma
次mk的连续输出结果,其余mk输出结果作为未发生某种特定行为的反例样本;n
ma
为大于1的整数;基于第三样本集,利用机器学习的方法,训练出能够根据多个点云信息序列识别出特定人体行为的模型ma。
11.进一步地,所述模型ma的输出目标为某一个待检人体目标发生某种特定行为的概率。
12.进一步地,所述射频信号频率为3ghz-90ghz,带宽500mhz-20ghz。
13.进一步地,进行步骤s3之前先根据射频扫描无人场景获得的数据对射频扫描获得的点云数据进行过滤,滤除固定场景信息。
14.第二方面,利用第一方面任一实现方式获得的模型进行人体感知的方法,包括以下步骤:s10:基于射频扫描,对场景进行点云数据采集;s20:将一组n次射频扫描获得的点云数据视为1个点云数据组,解算出与每个点云数据组相对应的点云信息,所述点云信息中与每一个反射点p相对应的信息至少包括该反射点的空间位置、速度和信号强度信息;s30:将步骤s20解算出的点云信息输入到模型mo中,输出场景中的人员数量信息和每个人体代表点的空间位置信息。
15.进一步地,所述利用模型进行人体感知的方法还包括步骤s40:当mo输出的人体数量m≥1时,根据模型mo输出的人体代表点空间位置信息对射频扫描获得的点云信息进行过滤,仅保留人体代表点附近特定距离范围的点云信息;将过滤后的点云信息输入模型mk,模型mk使用滑动窗口法对输入的点云信息进行扫描识别,窗口长度对应n
pk
组射频扫描,输出m个人体的多个关键点信息。
16.进一步地,所述利用模型进行人体感知的方法还包括步骤还包括步骤s50:将模型mk的输出结果输入模型ma,模型ma使用滑动窗口法对输入信息进行扫描识别,窗口长度对应n
ma
次mk连续输出结果,输出特定的人体行为。
17.进一步地,一个射频扫描周期tc=20~2000μs,每个点云数据组对应的射频扫描次数n=2~4096。
18.所述参照信息为射频扫描过程中同步获取的视频记录或音视频记录;训练集的标记可以人工标记,作为更优选的方案,可以利用现有人工智能识别的方法从参照信息中提取人体代表点位置、关键点位置以及人体行为信息,进而基于同一时间轴对点云信息进行自动标记。
19.为提升机器学习的效率和准确性,所述点云信息对应与每一个反射点相对应的信息还可以进一步包括加速度和噪声幅度信息。
20.第三方面,本技术提供了一种电子设备,包括:一个或多个处理器;存储装置,其上存储有一个或多个程序;当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现第一方面任一所述的方法或第二方面任一所述的方法。
21.第四方面,本技术提供了一种计算机可读介质,其上存储有计算机程序,其中,所述程序被处理器执行时实现第一方面任一所述的方法或第二方面任一所述的方法。
22.与现有技术相比,本技术能够在被检测者无感知的情况下对被检测者的位置、动作或行为进行感知,不似视频监控等监测手段容易侵犯个人隐私。具体是利用射频信号形成射频波场,进而获得表达待测场景空间分布和待检人体目标表面特性的点云信息;利用获得的点云信息和参照信息,制作第一样本集,通过机器学习训练出能够识别人体代表点位置的模型mo;进一步地,利用mo的输出结果对获取的点云信息进行过滤,仅保留高度关联信息,制作第二样本集,大幅减少了设备的运算负担。基于第二样本集,训练出能够识别出人体的关键点信息的模型mk,基于mk的输出结果制作第三样本集,进一步训练模型ma,进一步降低了计算需求,能够有效降低设备成本。相应的,利用训练获得的模型进行人体感知,先利用mo和/或mk对点云信息进行过滤,有助于区分人体和其他运动物体如风扇、宠物等,提升下一级识别的准确性;进一步的,应用mo、mk、ma逐步推理,能够在很大程度上节约运算量,降低用户负担,促进射频感知或识别技术在公共养老机构、医院尤其家庭或居家养老场所进行广泛应用。
附图说明
23.图1是实施例1的流程图;图2是人体关键点的一种布局示意图;图3是实施例2的流程图;图4是滑动窗口的原理图。
具体实施方式
24.下面结合附图和具体实施例对本技术做进一步说明。
25.实施例1一种基于射频技术获取人体感知模型的方法,图1示出了该方法的一个流程,可以包括以下步骤:s1:基于射频扫描,对某个选定场景,进行点云数据采集。可接受的射频信号的频率范围在3ghz-90ghz,带宽500mhz-20ghz。射频信号的发射和接收,可以通过预装在场景中的
mimo天线实现。为了获得立体信号,可以在场景中布局多组天线,以获得网格化点云数据。射频扫描过程中对场景进行同步录像或采用其他标记手段,获取参照信息。
26.s2:将一组n次(n为大于等于2的整数)射频扫描获得的点云数据视为1个点云数据组,解算出与每个点云数据组相对应的点云信息;点云信息中与每一个反射点p相对应的信息至少包括该反射点的空间位置(x,y,z)、速度v(n大于等于2时即可获得速度信息)和信号强度g信息,还可以进一步包括加速度a(n大于等于3时可获得加速度信息)和噪声幅度n,记为p{(x,y,z),v,g,a,n}。
27.待检测目标的空间位置信息获取,需要设备在tc时间段内线性扫描b带宽频段,发射射频同时接收射频,将两者混频后过滤掉高频信号,得到中频信号,再对该信号进行采样,由于扫描频率为线性增长,得到,其中τ为发射信号从设备到待检测目标之间的一个来回所需要的时间,tc为时间段,
ƒ
τ为接收到中频信号的频率,b为带宽频段,得到待检测目标与设备之间的距离为d=,其中c为光速,通过对采样信号做傅里叶变换,得出反射点的
ƒ
τ值,进而获得反射点即待检测目标的距离信息。
28.待检测目标的加速度信息获取,此时待检测目标为移动状态,两次探测接收到的射频由于多普勒现象的存在,相位会产生很大的变化,通过相位变化可以获得待检测目标两个反射点之间的位移为,瞬时速度为,其中为所使用的射频的波长,为两次扫描的相位差,通过至少三次扫描,获取待检测目标在每个反射点的加速度。通常,一个射频扫描周期tc=20~3500μs。
29.为减少后续数据运算负担,解算过程中可以先根据射频扫描无人场景获得的数据对射频扫描获得的点云数据进行过滤,滤除固定场景信息。
30.s3:根据数据采集过程中记录的参照信息,标记出场景中与每组射频扫描获取的点云信息相对应的人体代表点的空间位置信息,作为一种实施方式,可以选择人体躯干的中心点作为代表点;标记时可利用现有人工智能识别的方法从参照信息中提取人体代表点位置,进而基于同一时间轴对点云信息进行自动标记;收集多组射频扫描获得的点云信息和相应的人体代表点空间位置信息,形成第一样本集;基于第一样本集,利用机器学习的方法,例如随机森林、支持向量机、基于决策树的adaboost或gradient tree boosting、神经元网络等,训练出能够识别场景中人员数量m和每个人体代表点空间位置的模型mo,模型mo的输出目标为o={(prm,psm),m=1,2,3,
……
,m},prm为第m个待检测人体目标存在的概率,psm为第m个待检人体目标的代表点空间位置,m为场景中的人数。根据所选择算法,使用数值类损失函数如输入值和输出值之间mse、麦哈顿距离等作为评估方法来提高模型准确度。
31.s4:将n
pk
组(n
pk
×
n次,n
pk
为大于1的整数,优选2~25)射频扫描获得的点云信息视为一个点云信息序列,根据模型mo的输出结果对点云信息序列进行过滤,仅保留人体代表点附近特定距离范围、甚至特定速度范围(将人体大小范围的数据作为有效数据,有利于进
一步降低数据运算量)的点云信息,得到过滤后的点云信息序列;基于人体关节点在人体上选择多个关键点,根据数据集形成中记录的参照信息,标记出与每个过滤后的点云信息序列相对应的人体关键点的空间位置信息,收集多个信息序列并进行过滤、标记,形成第二样本集;人体关键点的选择可以参考图2,在图2所示的实施方式中,k=8,图2中的序号1-8分别指示8个人体关键点,分别为躯干1(与人体代表点位置一致),头部2,肘部3和4,膝关节5和6,手部7和8;基于第二样本集,利用机器学习的方法,例如随机森林、支持向量机、基于决策树的adaboost或gradient tree boosting、神经元网络等,训练出能够识别场景中m个人体的多个关键点信息的模型mk;模型mk的输出目标为每个待检人体目标的关键点信息ok={(prk,psk),k=1,2,3,
……
,k},k为选定的人体关键点个数;prk为某一个待检人体目标的第k个关键点存在的概率;psk为某一个待检人体目标的第k个关键点存在的空间位置。根据所选择算法,使用数值类损失函数如输入值和输出值之间mse、麦哈顿距离等作为评估方法来提高模型准确度。
32.s5:获取第三样本集,第三样本集包括正例样本和反例样本,正例样本包括从参照信息中获取的某种特定人体行为(例如:摔倒)和与之对应的n
ma
次(n
ma
为大于1的整数,优选18~750)连续mk输出结果,其余mk输出结果作为未发生某种特定行为的反例样本;基于第三样本集,利用机器学习的方法,例如,随机森林、支持向量机、基于决策树的adaboost或gradient tree boosting、神经元网络等训练出能够根据多个点云信息序列识别出特定人体行为的模型ma;模型ma的输出目标为某一个待检人体目标发生某种特定行为的概率。根据所选择算法,使用类别损失函数如神经元网络中的交叉熵或支持向量机中的hinge 作为评估方法来提高模型准确度。
33.同样的,参照步骤s5设定其他特定人体行为,如跑动、跳跃等,根据动作发生时长调整参数n
ma
,重复步骤s5,可以获得能够识别不同人体行为的多个模型ma。
34.作为一种实施方式,tc=1000μs,n=3,n
pk
=10,n
ma
=50,通过ma监测摔倒行为,监测n
ma
次数据对应时间为1500ms,与发生一次摔倒行为所需要的时间基本相同。
35.为提升模型应用的广泛性,可以对场景进行不同的设定,安排不同数量的人员在场景内做不同的活动,从而获得更丰富的样本集。
36.实施例2利用实施例1获得的模型进行人体感知的方法,图3示出了该方法的一个流程,可以包括以下步骤:s10:基于射频扫描,对场景进行点云数据采集;s20:将一组多次射频扫描获得的点云数据视为1个点云数据组,解算出与每个点云数据组相对应的点云信息,所述点云信息中与每一个反射点p相对应的信息至少包括该反射点的空间位置、速度和信号强度信息;s30:将步骤s2解算出的点云信息输入到模型mo中,输出场景中的人员数量信息和每个人体代表点的空间位置信息;s40:对mo的输出结果进行判定,当mo输出的人体数量m≥1时,根据模型mo输出的人体代表点空间位置信息对射频扫描获得的点云信息进行过滤,仅保留人体代表点附近特定距离范围、甚至特定速度范围内的点云信息,将过滤后的点云信息输入模型mk,启动模型mk;
模型mk使用滑动窗口法对输入的点云信息进行扫描识别,窗口长度对应n
pk
组射频扫描,输出m个人体的多个关键点信息。滑动窗口的原理如图4所示,在图4所示的实施例方式中窗口长度对应n
pk
=10,窗格宽度s
pk
=2,即当模型mk收到4组射频扫描获得的点云信息时,构成窗口初始状态,对应步骤s401,进行一次扫描识别;mk继续再接收2组射频扫描获得的点云信息,窗口向前滑动1次,减去最前面的2组失效信息并加上2组最新信息构成当前窗口,对应步骤s402,针对当前窗口信息,mk进行第二次扫描识别;mk继续再接收2组射频扫描获得的点云信息,窗口向前滑动1次,减去s402窗口靠前的2组失效信息并加上2组最新信息再次构成新的当前窗口,对应步骤s403,针对新窗口对应的信息,进行第三次扫描识别;以此类推,遍历所有接收信息。当然,s
pk
可以取更小的值,例如s
pk
=1,或更大的整数,s
pk
越大,设备的运算负担越低,但识别的准确性也会随之降低。当人体处于睡眠等活动幅度较小的状态时,可适当提高s
pk
的取值,例如s
pk
=n
pk
/2=5或者s
pk
=n
pk
=10。
37.s50:将模型mk的输出结果输入到一个或多个模型ma,模型ma使用滑动窗口法对输入信息进行扫描识别,窗口长度对应n
ma
次mk连续输出结果,输出特定的人体行为。滑动窗口的工作原理与s40中描述的一致,但作为一种实施方式,在步骤s50中窗格宽度s
ma
优选为n
ma
/2(与实施例1保持一致,n
ma
=50)。可以理解的是,s
ma
也可以适当减小,通过计算量来换取准确率;或者增加,可能的用准确率牺牲来换取速度。用于识别多个不同人体行为的模型ma同步运行,每个模型ma以各自设定的间隔进行扫描识别,推理识别出发生不同行为的可能性,并输出。
38.进一步地,可增加对模型ma输出的人体行为类型的判断步骤,针对不同的人体行为给窗格宽度s
pk
指定取值并反馈至步骤s40,针对不同的人体行为给窗格宽度s
ma
指定取值并反馈至步骤s50。
39.利用上述人体感知方法对家庭、敬老院、医院等场景进行人体感知,模型能够持续输出场景中人的个数、人的位置、人体的关键点信息,识别出人的特定行为,当模型识别出有人发生摔倒等危险动作时,可以进一步将信号传递给警报系统,提醒监护人及时采取措施。
40.实施例3一种电子设备,包括:一个或多个处理器;存储装置,其上存储有一个或多个程序;当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现实施例1描述的方法。
41.实施例4一种电子设备,包括:一个或多个处理器;存储装置,其上存储有一个或多个程序;当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现实施例2描述的方法。
42.实施例5一种计算机可读介质,其上存储有计算机程序,其中,该程序被处理器执行时实现实施
例1描述的方法。
43.实施例6一种计算机可读介质,其上存储有计算机程序,其中,该程序被处理器执行时实现实施例2描述的方法。
44.最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1