一种使用血液标志物预测性别的方法与流程
本发明涉及生物信息领域,具体为一种使用血液标志物预测性别的方法。
背景技术:
性别指男女两性的区别。在染色体层面上,人类具有22对常染色体和一对性染色体,男性的性染色体为xy,女性的性染色体为xx,y染色体的存在也是判断人类性别的方法之一;基因层面上通常使用sry睾丸决定基因作为性别判断的依据,sry基因位于y染色体上,因此具有sry基因的个体为男性,不具有的为女性;在更宏观的层面上看,性腺、生殖器等都可以作为划分性别的依据。
国内外的研究表明,一些血液指标在男女个体中存在差异,并且这些差异性指标已应用于临床。成年男女两性的红细胞计数存在显著差异,这种差异在新生儿和婴幼儿时期无明显表现,到青春期和成年期后才表现出显著差异。在我国成年男性红细胞为400万-550万/μl,女性为350万-500万/μl,但女性到40岁以后,其体内红细胞数又逐渐升高,与男性水平相接近。据医学研究发现,这种差异与性腺功能的成熟有一定关系。在青春期,男性体内雄性激素水平开始升高,而雄性激素可通过两方面的作用来刺激红细胞的增加,一方面雄性激素可直接作用于骨髓造血组织,刺激骨髓造血组织加速有核红细胞的分裂活动和血红蛋白的合成,另一方面,雄性激素可刺激肾脏产生一种酶—红细胞生成酶,这种酶又能使肝脏产生的促红细胞生成素原转变为促红细胞生成素,后者可刺激骨髓内原始的血细胞加速分化形成原始红细胞,并能促进有核红细胞的有丝分裂过程,使其成熟过程加快。对红细胞的主要成分—血红蛋白的生物合成也有推动作用。此外,促红细胞生成素还能促进骨髓中成熟的红细胞向周围的血液中释放。正是由于以上原因,青春期开始,男性体内雄性激素水平明显高于女性,而雌性激素又无雄性激素的此种功能,导致成人男女体内红细胞的差异。成年男性血红蛋白(hb)浓度正常参考值大约在135~180g/l之间,女性大约在115~155g/l之间,且随着年龄增长,对应的血红蛋白浓度将逐渐升高,血红蛋白在两性中的差异性也和雄性激素的调控相关。同时性激素的调控也会引起不同性别个体体内葡萄糖平衡的调控,因此血糖、糖耐量等在两性个体中也存在差异性。
在没有个体实体只有个体相关样本的情况下,在宏观层面判断个体性别无法实现,染色体和基因层面上需要获取个体的染色体或基因信息才可判定个体性别,常见方法可以通过pcr方式对样本中纯化过的dna进行扩增,以获取染色体和基因信息。
现有判断或预测个体性别的方法需要个体实体的参与,或使用dna信息,但是dna信息获取难度大、成本高,因此,设计了一种使用血液标志物预测性别的方法,将临床使用上更加普遍、更易获取的血液标志物作为预测个体性别的特征值,降低了性别判定的成本和难度,具有现实意义和良好的应用前景。
技术实现要素:
针对上述背景技术中的不足,本发明提供一种使用血液标志物预测性别的方法,使用更加易获取的血液标志物,降低了技术成本。
为实现上述目的,本发明提供如下技术方案:一种使用血液标志物预测性别的方法,其特征在于,包括如下步骤:
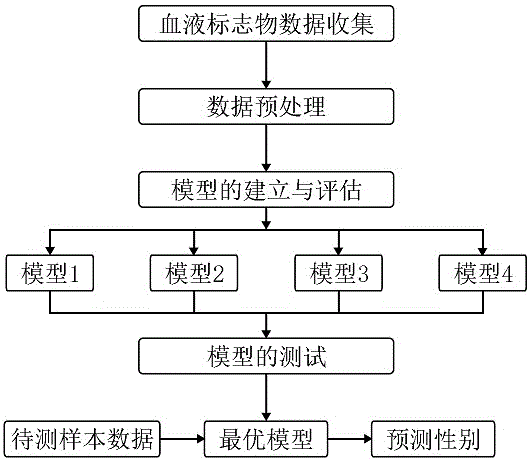
第一步,血液标志物数据收集,奇云诺德从多个相关数据库总计获取92062个样本的血液标志物数据,所述每个样本中包含个体性别和19项血液标志物数据,所述血液标志物数据即为血液生化指标,常见于医院和体检机构的血常规和血液生化指标检测报告单;
第二步,数据预处理,移除有遗漏数据的样本和有明显错误离群值(outliar)的样本后,总计获得26754例完整样本用于模型的训练和测试,随后对19项血液标志物数据进行标准化处理,将所有标志物数据的数值都映射在[0,1]范围内;
第三步,模型的建立与评估,预处理后的数据按照7:3的比例随机分为训练集和测试集进行模型的训练,使用深度神经网络(dnn)机器学习算法训练26754个样本的19个血液标志物数据,调整隐藏层数量、神经元个数和dropout数量等模型参数,训练多个性别预测模型;
第四步,模型的测试,在所用的26754个样本数据中,随机获取30%的数据输入模型预测性别,进行模型内部数据的验证,在每个模型上进行对应验证测试,最终挑选其中计算功效最好的模型为性别的预测模型。
优选的,所述19项血液标志物包括白蛋白、葡萄糖、尿素、胆固醇、总蛋白、血清钠、肌酸酐、血红蛋白、总胆红素、甘油三酯、高密度脂蛋白胆固醇、低密度脂蛋白胆固醇、血清钙、血清钾、血细胞比容、平均红细胞血红蛋白浓度、平均红细胞体积、血小板计数和红细胞计数。
优选的,所述性别预测使用深度神经网络(dnn)分类算法。
优选的,所述根据dnn算法建立的性别预测模型使用19个血液标志物作为主要特征,来预测样本的性别。
与现有技术相比,本发明具备以下有益效果:
1.使用血液标志物为性别的特征值,相较于其他方法技术,成本更低,因为选取的19项血液标志物是临床和体检机构中最常见的指标,常见于血常规和血液生化检测报告单,获取难度低、成本低;
2.使用dnn算法训练出的性别预测模型为机器学习模型,计算度比常规方法高、但是计算难度降低,且计算模型中的各项参数和模型结构经过多次验证,因此用该方法预测个体性别时有更高的准确性和更低的使用难度。
附图说明
图1为本发明流程示意图;
图2为模型性能统计结果。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,一种使用血液标志物预测性别的方法,该方法是一种利用常见血液标志物对受试者样本进行性别预测的方法,基于统计学检验获得的19个与性别显著相关的血液标志物为特征,结合公司收集的92062例样本的血液标志物数据及表型数据,利用深度神经网络(dnn)算法构建机器学习模型,并进行内部测试,dnn算法建立的模型经验证,在结果准确率上显著高于其他机器学习算法(k近邻算法、随机森林、支持向量机等)建立的模型,同时dnn算法引入的隐藏层和神经元增强了模型的表达能力,其在自动缩放神经元权重方面的特性也最大程度的丰富了模型的发展方向。该性别预测方法包括血液标志物数据收集、数据预处理、模型的建立与评估和模型的测试四个步骤,所述血液标志物按照以下方法预测性别:
第一步,血液标志物数据收集,奇云诺德从多个相关数据库总计获取92062个样本的血液标志物数据,所述每个样本中包含个体性别和19项血液标志物数据,所述血液标志物数据即为血液生化指标,常见于医院和体检机构的血常规和血液生化指标检测报告单;
第二步,数据预处理,移除有遗漏数据的样本和有明显错误离群值(outliar)的样本后,总计获得26754例完整样本用于模型的训练和测试,随后对19项血液标志物数据进行标准化处理,将所有标志物数据的数值都映射在[0,1]范围内;
第三步,模型的建立与评估,预处理后的数据按照7:3的比例随机分为训练集和测试集进行模型的训练,使用深度神经网络(dnn)机器学习算法训练26754个样本的19个血液标志物数据,调整隐藏层数量、神经元个数和dropout数量等模型参数,训练多个性别预测模型;
第四步,模型的测试,在所用的26754个样本数据中,随机获取30%的数据输入模型预测性别,进行模型内部数据的验证,在每个模型上进行对应验证测试,最终挑选其中计算功效最好的模型为性别预测模型。
其中,所述19项血液标志物包括白蛋白、葡萄糖、尿素、胆固醇、总蛋白、血清钠、肌酸酐、血红蛋白、总胆红素、甘油三酯、高密度脂蛋白胆固醇、低密度脂蛋白胆固醇、血清钙、血清钾、血细胞比容、平均红细胞血红蛋白浓度、平均红细胞体积、血小板计数和红细胞计数。
其中,所述性别预测使用深度神经网络(dnn)分类算法。
其中,所述根据dnn算法建立的性别预测模型使用19个血液标志物作为主要特征,来预测样本的性别。
该性别预测方法的测试验证参数包括交叉熵和准确率,通过设置不同的神经元数量、隐藏层数量、激活函数、dropout数量等,总计构建了4个结构不同的性别预测模型,模型性能统计结果请参照图2,最后挑选了性能最好的模型作为性别预测模型,最优模型的性能为:交叉熵=0.1453,准确率=0.9697。
模型使用时,仅需将待测样本的19个血液标志物数据传入模型,经计算后将输出待测样本的性别。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!