大豆的产量预测方法与流程
1.本发明涉及一种早期预测大豆的产量的方法。
背景技术:
2.大豆是重要的谷物,在包括日本在内的世界范围内被广泛食用。另外,与作为其它代表性的谷物的大米、小麦、玉米不同,蛋白质及脂质的比例高、营养价值也丰富。因此,作为饲料或油脂原料也是重要的,正在进行增加产量的技术的开发。
3.大豆的生长期根据品种、栽培条件而略有不同,通常从播种到收获需要4
‑
5个月这样的长时间。因此,在使大豆的产量增加的技术的开发中,为了进行产量评价而在栽培中需要较多的时间。另外,在如日本那样的季节
·
气候条件下,到收获为止需要4
‑
5个月的大豆的栽培每年通常为1次。在室外栽培的产量评价每年仅能进行一次,这成为产量增加技术的开发的障碍,因此,寻求早期预测产量的方法。另外,在实际的生产场景中,如果能够早期预测产量,则生产者为了确保稳定的产量,能够容易地做出是否应该投入耗费费用成本的追加技术的判断。
4.迄今为止,对利用了生长中的植物体的生长状态与产量的相关性的早期评价产量性的方法进行了各种研究。例如,在非专利文献1中公开了利用在大豆播种后40天左右测定的主茎长与产量的相关(r=0.51)的方法,在非专利文献2中公开了利用在播种后60
‑
70天左右测定的地上部分的干燥重量与产量的相关(r=0.66)的方法。另外,在非专利文献3及4中公开了使用图像诊断技术,在田间测定ndvi(标准化植被指标)、lai(叶面积指数)及群落分光反射率,评价生长及产量性的尝试。
5.但是,非专利文献1的方法有可能能够比较早期地预测产量,另一方面,相关性不充分,另外,在非专利文献2的方法中,虽然相关性提高,但预测时期从栽培开始为2个月以上,经过生长期的一半,并且为了测定地上部分干重是侵袭性的,不适合想要使每个个体的预测因子与产量对应的情况下的评价。非专利文献3和4的方法可以说是非破坏且简易的测定,但预测时期在开花期、即播种后50天左右以后,而且精度方面也不能说是充分的。
6.除此之外,报告了在稻子中,通过gc
‑
ms罗网性地测定从播种后15天左右的地上部分提取的代谢物,使用这些数据制作了杂交水稻产量预测模型(非专利文献5),但在该报告中,不进行在通常的预测模型构筑时进行的交叉验证这样的模型的预测性评价,验证不能说是充分的。另外,是侵袭性的,不适合想要使每个个体的预测因子与产量对应的情况下的评价。
7.[非专利文献1]藤田与一等,平成21年度“关东东海北陆农业”研究成果信息,“基于重粘土地带的大豆“enrei”的高产案例的产量构成要素和生长指标”,http://www.naro.affrc.go.jp/org/narc/seika/kanto21/12/21_12_04.html
[0008]
[非专利文献2]井上健一、高桥正树,第229次日本农作物学会讲座会要点集,2010,p50,“从物质生产和氮的蓄积观察到的大豆的高产生长相”[0009]
[非专利文献3]长南友也等,第245次日本农作物学会讲座会要点集,2018,p83,
“
大豆的简单的开花前生长诊断技术”[0010]
[非专利文献4]渡边智也等,第245次日本农作物学会讲座会要点集,2018,p84,“利用了非破坏测量和卷积神经网络的大豆的产量评价”[0011]
[非专利文献5]dan,z.et al.,scientific reports,2016,6,21732
技术实现要素:
[0012]
第一,本发明提供一种大豆的产量预测方法,其由从大豆采集的叶样品中获取1个以上的成分的分析数据,利用该数据与大豆产量的相关性来预测大豆的产量。
[0013]
第二,本发明提供一种大豆的产量预测方法,所述方法是由从大豆采集的叶样品中获取1个以上的成分的分析数据,利用该数据与大豆产量的相关性来预测大豆的产量,成分为选自2
‑
羟基吡啶、胆碱、柠檬酸、甘油酸、甘氨酸、l
‑
焦谷氨酸、丙二酸、蔗糖及苏糖醇中的1种以上。
附图说明
[0014]
图a1是表示由使用全部125个数据构筑的opls模型得到的产量的预测值与实测值的关系的图。
[0015]
图a2是表示由使用全部125个数据构筑的机器学习模型得到的产量的预测值与实测值的关系的图。
[0016]
图a3是表示学习用数据及验证用数据各自的预测值与实测值的关系的图。将全部125个数据矩阵随机分成2组(学习用和验证用),将一方的63个矩阵数据作为学习用,将剩余62个矩阵数据作为验证用使用。
[0017]
图a4是表示使用图a1的模型中的vip值11位以下全部成分的分析数据、21位以下全部成分的分析数据、31位以下全部成分的分析数据
…
及351位以下全部成分的分析数据且通过opls法构筑的各个模型的r2(在图中显示为r2y)值及q2(在图中显示为q2)值的图。
[0018]
图a5是表示对于图a1的模型中的从vip值第1位到10位的成分的分析数据内任意的两个的组合(45种)通过opls法构筑的各个模型的r2(在图中显示为r2y)值及q2(在图中显示为q2)值的图。
[0019]
图a6是表示使用图a1的模型中的vip值第1位和2位、11位和12位、21位和22位、
…
及201位和202位的成分的分析数据且通过opls法构筑的各个模型的r2(在图中显示为r2y)值及q2(在图中显示为q2)值的图。
[0020]
图a7是表示使用图a1的模型中的vip值第1位和2位和3位、11位和12位和13位、21位和22位和23位、
…
及221位和222位和223位的成分的分析数据且通过opls法构筑的各个模型的r2(在图中显示为r2y)值及q2(在图中显示为q2)值的图。
[0021]
图a8是表示使用图a1的模型中的vip值第1位和2位和3位和4位、11位和12位和13位和14位、21位和22位和23位和24位、
…
及221位和222位和223位和224位的成分的分析数据且通过opls法构筑的各个模型的r2(在图中显示为r2y)值及q2(在图中显示为q2)值的图。
[0022]
图a9是表示使用图a1的模型中的vip值第1位~5位、11位~15位、21位~25位、
…
及251位~255位的成分的分析数据且通过opls法构筑的各个模型的r2(在图中显示为r2y)值及q2(在图中显示为q2)值的图。
[0023]
图a10是表示使用图a1的模型中的vip值第1位~6位、11位~16位、21位~26位、
…
及281位~286位的成分的分析数据且通过opls法构筑的各个模型的r2(在图中显示为r2y)值及q2(在图中显示为q2)值的图。
[0024]
图a11是表示使用图a1的模型中的vip值第1位~7位、11位~17位、21位~27位、
…
及281位~287位的成分的分析数据且通过opls法构筑的各个模型的r2(在图中显示为r2y)值及q2(在图中显示为q2)值的图。
[0025]
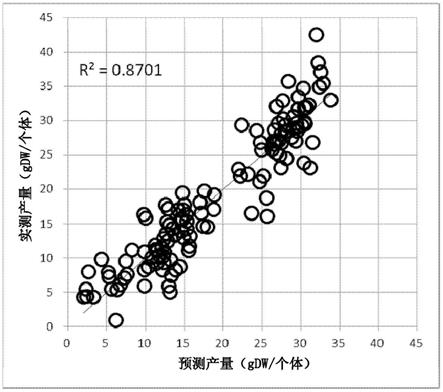
图a12是表示使用图a1的模型中的vip值第1位~8位、11位~18位、21位~28位、
…
及281位~288位的成分的分析数据且通过opls法构筑的各个模型的r2(在图中显示为r2y)值及q2(在图中显示为q2)值的图。
[0026]
图a13是表示使用图a1的模型中的vip值第1位~9位、11位~19位、21位~29位、
…
及281位~289位的成分的分析数据且通过opls法构筑的各个模型的r2(在图中显示为r2y)值及q2(在图中显示为q2)值的图。
[0027]
图a14是表示使用图a1的模型中的vip值第1位~10位、11位~20位、21位~30位、
…
及281位~290位的成分的分析数据且通过opls法构筑的各个模型的r2(在图中显示为r2y)值及q2(在图中显示为q2)值的图。
[0028]
图a15是表示由每1个数据使用100个成分的分析数据构筑的opls模型(模型a)得到的产量的预测值与实测值的关系的图。
[0029]
图a16是表示试验区1~10的使用了模型a的产量预测的结果(与试验区1的差)的图。
[0030]
图a17是表示mix堆肥施用区的使用了模型a的田间预测产量的图。
[0031]
图a18是表示mix堆肥施用的田间产量的图。
[0032]
图a19是表示播种后2周及8周的使用了模型a的预测产量与实测产量的比较的图。
[0033]
图a20是表示由使用田间数据(每1个数据431个成分的分析数据)构筑的opls模型得到的产量的预测值与实测值的关系的图。
[0034]
图b1是表示由使用全部125个数据构筑的opls模型得到的产量的预测值与实测值的关系的图。
[0035]
图b2是表示使用图b1的模型中的vip值1位以下、2位以下、3位以下、4位以下、5位以下及6位以下的全部成分数据且通过opls法构筑的各个模型的r2(在图中显示为r2y)值及q2(在图中显示为q2)值的图。
[0036]
图b3是表示使用图b1的模型中的vip值1位及2位、vip值1位~3位及vip值1位~4位的成分数据且通过opls法构筑的各个模型的r2(在图中显示为r2y)值及q2(在图中显示为q2)值的图。
[0037]
图b4是表示使用图b1的模型中的vip值第1位~4位、2位~5位、3位~6位、4位~7位、5位~8位及6位~9位的成分数据且通过opls法构筑的各个模型的r2(在图中显示为r2y)值及q2(在图中显示为q2)值的图。
[0038]
图b5是表示使用图b1的模型中的vip值第1位~5位、2位~6位、3位~7位、4位~8位及5位~9位的成分数据且通过opls法构筑的各个模型的r2(在图中显示为r2y)值及q2(在图中显示为q2)值的图。
[0039]
图b6是表示使用图b1的模型中的vip值第1位~6位、2位~7位、3位~8位及4位~9
位的成分数据且通过opls法构筑的各个模型的r2(在图中显示为r2y)值及q2(在图中显示为q2)值的图。
[0040]
图b7是表示使用图b1的模型中的vip值第1位~7位、2位~8位及3位~9位的成分数据且通过opls法构筑的各个模型的r2(在图中显示为r2y)值及q2(在图中显示为q2)值的图。
具体实施方式
[0041]
本发明涉及一种早期高精度地预测大豆的产量的方法。
[0042]
本发明人等对大豆的产量性评价进行了各种研究,其结果发现,在叶中所含的代谢物中存在其存在量与产量相关的成分,而且,在播种后1个月左右的早期采集1片展开叶,对叶中所含的成分进行分析、解析,由此,能够以个体水平评价最终的产量。
[0043]
根据本发明的方法,能够早期预测大豆的产量。由此,例如,除了用于确保产量的追加技术投入的判断变得容易以外,还能够实现产量增加技术的开发的大幅的效率化。
[0044]
在本发明中,大豆是指作为豆科的一年生植物的大豆(学名glycine max)。其品种有福丰(fukuyutaka)、
エンレイ
(enrei)、里
のほほえみ
(satonohohoemi)、湯上
がり
娘(yuagari musume)、
リュウホウ
(ryuho)、铃丰(suzuyutaka)等多种,但在本发明中不限定于这些。
[0045]
大豆的出芽到落叶的生长阶段分为vc:初生叶展开期(播种后7天左右)、r1
‑
2:开花期(播种后50天左右)、r3
‑
4:结荚期(播种后70天左右)、r5
‑
6:籽粒膨大期(播种后90天左右)(fehr,w.r.,caviness,c.e.,1977.stages of soybean development.cooperative extension service,agriculture and home economics experiment station,iowa state university,ames,iowa)。在本发明中,作为样品使用的大豆的叶的采集期只要在从叶能够采集的初生叶展开期(vc)到籽粒膨大期(r5
‑
6)之间进行即可,优选可以举出初生叶展开期~r3
‑
4期,更优选为播种后14天~r3
‑
4期,更优选为播种后21天~r1
‑
2期,进一步优选为播种后28天~r1
‑
2期的大豆。需要说明的是,上述各生长阶段中的左右的天数宽度优选为10天以内。
[0046]
或者,大豆的叶的采集期可以为播种后7天以上、优选为第14天以上,更优选为第21天以上,进一步优选为28天以上,且优选为播种后50天之前,更优选为播种后40天之前,进一步优选为第35天之前。另外,可以为播种后第7~50天、优选为第14~40天、更优选为第28~35天。例如,优选从播种后第30天
±
3~5天的大豆中采集叶子。
[0047]
叶的采集部位没有特别限定,例如可以举出采集在顶部展开的构成真叶的1或2叶龄的老的真叶的3片复叶中中央的复叶。
[0048]
在本发明中,作为所获取的成分的分析数据,可以举出使用高效液相色谱(hplc)、气相色谱(gc)、离子色谱、质谱(ms)、近红外分光分析(nir)、傅立叶变换红外分光分析(ft
‑
ir)、核磁共振分析(nmr)、傅立叶变换核磁共振分析(ft
‑
nmr)、电感耦合等离子体质谱仪(icp
‑
ms)、组合了液相色谱和质谱的lc/ms等的设备分析方法所分析
·
测定得到的数据,优选为质谱数据,更优选为利用lc/ms的质谱数据。
[0049]
作为质谱数据,可以举出精确质量(“m/z值”)、离子强度、保持时间等,但优选为精确质量的信息。
[0050]
为了将叶样品应用于上述设备分析方法,根据分析方法适当进行前处理,通常采集的叶用铝箔包裹,立即在液氮中冻结使代谢反应停止,在施以冷冻干燥进行了干燥后,供于提取操作。
[0051]
提取通过使用珠式粉碎机等将冷冻干燥后的叶样品粉碎后,添加提取溶剂并搅拌来进行。作为在此使用的提取溶剂,可以举出:甲醇、乙醇、丁醇、乙腈、氯仿、乙酸乙酯、己烷、丙酮、异丙醇、水等及将它们混合而成的混合物。在使用lc/ms作为分析方法的情况下,优选使用添加了内部标准物质的80v/v%甲醇水溶液等。
[0052]
在第一发明中,作为被分析的叶中的成分,可以举出由lc/ms分离检测的大豆的代谢物质。优选可以举出通过质谱提供的精确质量(m/z)为139~1156的成分。更优选举出由通过质谱提供的精确质量(m/z值)规定的下述表a1a~1c中记载的431个成分。需要说明的是,在利用lc/ms的分离检测的过程中,在由代谢物质产生部分分解物和加合物(m+h、m+na等)的不同的分子离子峰的情况下,被检测的部分分解物作为与原来的代谢物质不同的成分。
[0053]
[表a1a]
[0054]
成分编号m/z成分编号m/z成分编号m/z成分编号m/z1139.038941209.154581259.0827121288.29112141.959242209.154882259.2076122289.07273147.043543211.060883261.1501123289.12284147.044644213.150384261.2233124291.04015149.023445214.253985263.2381125291.19736149.024146217.196186264.2335126291.19757161.060647219.175487265.1440127291.23408163.039848219.195088269.0818128293.21189163.132549220.113789271.0618129293.213010165.055050221.045690271.0619130293.249811170.097451221.602091271.2280131295.093612171.150152225.150092273.0769132295.103713175.148653225.197293274.0541133295.129914177.055154226.099194274.0928134295.228815179.071755226.161095274.1606135297.243616181.123256226.181296275.2020136298.098617181.123757227.128697275.2023137299.202318183.186558227.129498277.2184138301.142419186.092159228.195499277.2186139305.067420189.127860228.2321100277.2186140305.990721190.050661231.0512101279.0512141307.012822191.143762233.9842102279.0515142307.094323191.143963234.0928103279.0951143309.207524193.085964235.1702104279.1610144309.2228
25193.086165239.0562105279.1611145315.006226193.159766241.1446106279.2320146316.213427194.118267242.2485107279.2333147316.286528195.065568243.0667108279.2340148318.280629196.112769243.1608109279.2343149319.153630197.118170243.2114110281.2485150319.285331199.133371245.2281111282.1376151320.991632199.181872249.0621112282.2236152321.063233200.238273252.0874113282.2800153321.098334205.087274252.0882114284.2960154321.146335205.098375253.2170115285.1255155322.276536207.065076255.0669116285.1713156323.075137207.139077256.2649117285.1718157323.129038209.117178256.2650118285.6271158325.144439209.117879257.0660119287.0566159327.079540209.153880257.1908120287.0567160327.2336
[0055]
[表a1b]
[0056]
成分编号m/z成分编号m/z成分编号m/z成分编号m/z161327.2340201363.2553241401.0882281435.1300162329.1613202363.3128242401.0907282435.1304163331.1409203364.3237243401.0909283436.1466164333.1528204365.3202244401.2869284439.1991165335.1237205366.1783245401.7112285439.3603166335.1542206366.3393246403.2351286440.2333167335.2595207367.0343247404.1215287440.2513168335.2595208367.2635248404.2102288441.3741169335.2600209367.2652249405.1316289441.3746170336.3128210369.0831250405.3534290442.2570171337.0938211369.1268251405.3538291443.1002172337.1724212371.1876252406.1362292443.1020173338.3440213371.1881253406.2078293445.2077174339.0715214371.2075254407.3688294448.1949175339.0734215372.1673255407.3692295449.1093176341.1385216373.0778256409.0757296449.1101177341.1451217373.1291257409.2738297454.2944178341.2680218374.1088258409.2749298455.1197179342.2139219374.1459259410.7059299457.2091180342.3390220375.2710260411.0022300457.2096181343.1022221379.0634261411.1627301461.1784182343.1042222380.3389262412.3808302466.2667
183343.2288223382.2026263419.1201303468.2829184343.2292224383.0771264420.2238304468.3930185344.1358225383.2574265423.2245305469.1831186346.1516226383.2591266423.2762306471.2180187349.0912227385.2945267423.3643307471.2243188349.1485228387.0938268423.3644308473.1087189349.2761229387.1832269424.3649309473.2048190351.2558230387.2032270424.3681310474.1748191352.2528231388.1627271425.1943311477.1435192353.2713232390.1035272427.1044312478.1385193355.0832233390.1892273431.1017313479.1907194355.1027234391.2862274432.2476314482.3270195357.1584235393.2811275432.2597315483.0931196357.1705236393.7143276433.1140316484.2764197358.1656237394.2089277433.1149317489.0813198358.9809238398.2341278433.1355318489.2158199361.2551239399.1645279434.1386319489.3604200362.0177240399.2520280434.2406320492.2465
[0057]
[表a1c]
[0058][0059]
该431个成分是从大豆的代谢物质中选择提取的,其选择方法详细如实施例所示,大致如下:1)在2015年~2017年,栽培改变了土壤、品种、肥料的大豆125株,2)分别在播种后1个月左右采集1片叶子,3)使用80v/v%甲醇水溶液进行成分提取后,进行4)lc/ms分析,获取分子离子信息(精确质量,m/z)和源自片段的结构信息,5)提取来源于成分的峰,接着进行使各峰在各样品间排列的对准处理、同位素峰的除去、样品间的峰强度校正、噪声的除去,获取431个成分的分析数据。需要说明的是,样品间的峰强度校正的方法没有特别限定,
可以举出集中qc(pooled qc)法或使用了内部标准物质的校正。集中qc法是制作从同一批次内的全部样品中混合了一定量的被称为集中qc的样品,在各样品之间以一定的频率(5~9次中进行1次左右)实施集中qc的分析,由此,计算“如果在分析各样品时假设分析qc样品,则各自的峰强度如何变化”这样的推定值,进行用该值进行校正的处理,进行各样品间的灵敏度的校正。使用了内部标准物质的校正是进行用与各样品等量添加的内部标准物质(利多卡因、10
‑
樟脑磺酸等)的峰面积的值进行校正的处理来进行各样品间的灵敏度的校正。需要说明的是,数据的校正方法不会对与产量的相关性及预测模型的性能产生大的影响。
[0060]
另外,对所获取的125个叶中431个成分的分析数据与对应的产量数据进行了相关分析(通过各成分的分析数据的峰面积与产量的单相关系数r及无相关的检验来算出p值),其结果示于一定的成分与产量显著相关(参照后述表a3a~3f)。
[0061]
因此,431个成分中,作为本发明的分析对象成分,优选包含与产量的相关显著(p<0.05)且相关系数的绝对值|r|>0.51的成分,即选自成分编号13、14、17、20、21、22、23、28、35、36、37、39、41、42、44、47、48、51、52、54、57、58、68、71、73、80、85、86、90、91、96、98、99、100、107、108、110、122、125、131、134、135、137、139、142、149、150、153、157、159、160、161、171、174、176、179、181、182、188、202、208、209、214、215、217、218、228、230、235、244、245、246、247、249、251、252、253、261、264、268、275、278、279、280、282、283、284、288、294、296、298、299、305、308、310、313、317、325、327、329、330、341、347、353、355、356、363、367、369、370、384、389、395、421、422、423、428及431中的1种以上。需要说明的是,上述成分的后述的vip值均为1.16以上,如果为1.30以上,则相关系数的绝对值|r|>0.51。
[0062]
另外,431个成分中,作为本发明的分析对象成分,更优选包含与产量的相关显著(p<0.05)且相关系数的绝对值|r|>0.63的成分,即选自成分编号14、22、23、36、37、41、42、51、52、68、90、122、139、149、159、214、228、230、235、247、249、252、253、268、275、278、284、288、298、305、308、313、317、329、347、363、395、421、422及428中的1种以上。需要说明的是,上述成分的后述的vip值全部为1.522以上,如果为1.62以上,则相关系数的绝对值|r|>0.63。
[0063]
另外,431个成分中,作为本发明的分析对象成分,更优选包含与产量的相关显著(p<0.05)且相关系数的绝对值|r|>0.66的成分,即选自成分编号14、23、36、37、41、51、68、90、122、149、214、230、235、247、249、252、275、284、298、305、308、313、317、347、363、421、422及428中的1种以上。需要说明的是,上述成分的后述的vip值均为1.59以上,如果为1.652以上,则相关系数的绝对值|r|>0.66。
[0064]
在表a1a~1c中,以通过质谱得到的精确质量来规定431个成分,但能够根据这些精确质量数据来推定化合物的组成式。另外,根据分析时同时获取的ms/ms数据,可以得到化合物的部分结构信息。因此,能够根据组成式和部分结构信息来推定对象的成分,进而能够对能够与试剂进行比较的成分进行鉴定。
[0065]
例如,431个成分中,作为解析的结果鉴定出的成分,可以举出以下。成分编号10推定为4
‑
香豆酸,成分编号68、90、122及308为相同成分,其组成式以c
21
h
22
o
11
表示,并且推定为在糖苷配基的组成式为c
15
h
12
o6的脱氢黄酮醇键合有葡萄糖的单糖苷体,成分编号92推定为樱桃苷(柚皮素
‑7‑
o
‑
葡萄糖苷),成分编号119推定为组成式c
15
h
10
o6的类黄酮,成分编号139其组成式以c
21
h
22
o
12
表示,并且推定为在糖苷配基的组成式为c
15
h
12
o7的脱氢黄酮醇键合
有葡萄糖的单糖苷体,成分编号277其组成式以c
26
h
30
o
10
表示并且推定为组成式c
15
h
10
o5的类黄酮的异戊二烯化体,成分编号295推定为在组成式c
15
h
10
o6的黄酮醇键合有葡萄糖和鼠李糖的二糖苷体,成分编号296及成分编号395为相同成分,其组成式以c
33
h
40
o
19
表示,并且推定为在糖苷配基的组成式为c
15
h
10
o6的黄酮醇键合有1个葡萄糖和2个鼠李糖的三糖苷体,成分编号302以组成式c
21
h
36
o
10
表示并且推定为在香叶醇键合有葡萄糖和阿拉伯糖的二糖苷体,成分编号429推定为大豆皂苷βg。另外,根据与试剂的一致,成分编号76鉴定为黄豆苷元,成分编号89鉴定为染料木素,成分编号276鉴定为染料木苷,成分编号399鉴定为丙二酰染料木苷(malonylgenistin),并且成分编号421和成分编号422为相同成分并且鉴定为大豆皂苷bb。
[0066]
其中,作为本发明的分析对象成分,优选可以举出:与产量的相关显著(p<0.05)且相关系数的绝对值|r|>0.51的成分,例如大豆皂苷bb;组成式以c
21
h
22
o
11
表示,且在糖苷配基的组成式为c
15
h
12
o6的脱氢黄酮醇键合有葡萄糖的单糖苷体;组成式以c
33
h
40
o
19
表示,且在糖苷配基的组成式为c
15
h
10
o6的黄酮醇键合有1个葡萄糖和2个鼠李糖的三糖苷体;组成式以c
21
h
22
o
12
表示,且在糖苷配基的组成式为c
15
h
12
o7的脱氢黄酮醇键合有葡萄糖的单糖苷体等。
[0067]
大豆的产量的预测方法是对上述431个成分、优选与产量的相关显著(p<0.05)且相关系数的绝对值|r|>0.51的成分、更优选显著(p<0.05)且相关系数的绝对值|r|>0.63的成分、进一步优选显著(p<0.05)且相关系数的绝对值|r|>0.66的成分的存在量,例如想要预测相关系数为
‑
0.777的精确质量m/z 473.1087的峰面积的样品进行测定,能够根据已知的产量与峰面积的相关关系推定产量值。
[0068]
另外,通过从上述431个成分的分析数据中使用多个,并与使用多变量分析方法构筑的产量预测模型进行对照,能够预测产量。
[0069]
即,采集从播种经过规定时间后的大豆的叶,得到分析样品,将该分析样品供于设备分析得到设备分析数据,将该设备分析数据与产量预测模型进行对照,由此,能够预测该大豆的产量。
[0070]
产量预测模型能够通过进行在解释变量采用具有各精确质量的完成校正的成分的分析数据的峰面积值,并且在目标变量使用了产量值的回归分析来构筑。作为回归分析法,例如,除了主成分回归分析、pls(对潜在结构的偏最小二乘投影,partial least squares projection to latent structures)回归分析、opls(对潜在结构的正交投影orthogonal projections to latent structures)回归分析、广义线性回归分析以外,还能够举出:套袋(bagging)、支持向量机、随机森林、神经网络回归分析等机械学习
·
回归分析方法等多变量回归分析方法。其中,优选使用pls法、作为pls法的改良版的opls法、或机械学习
·
回归分析方法。opls法与pls法相比,虽然预测性相同,但用于解释的视觉化变得更容易这一点在如本次的目的方面是优异的。pls法及opls法都是从高维的数据中总结信息并置换为少量的潜在变量,使用该潜在变量来表现目标变量的方法。适当地选择潜在变量的数量是重要的,为了决定潜在变量的数量而经常利用的是交叉验证(cross validation)。即,将模型构筑用数据分割成几个组,将某个组用于模型验证,将其它组用于模型构筑来估计预测误差,交换组并且重复该操作,选择预测误差的合计成为最小的潜在变量的数量。
[0071]
预测模型的评价主要由2个指标来判断。1个是表示预测精度的r2,另一个是表示预测性的q2。r2是预测模型构筑中使用的数据的实测值与用模型计算出的预测值的相关系数的2次方,越接近1,则表示预测精度越高。另一方面,q2是上述交叉验证的结果,表示实测值与作为重复实施的模型验证的结果的预测值的相关系数的2次方。在本发明的大豆产量预测模型中,优选将q2>0.50作为模型评价的基准。需要说明的是,通常r2>q2,因此,q2>0.50同时满足r2>0.50。
[0072]
以下,示出制作上述431个成分的全部或其一部分的分析数据的峰面积值和使用了籽粒产量的各种大豆产量预测模型并验证其精度的结果。其中,关于opls模型,优选可以使用q2>0.50的模型。
[0073]
(1)使用了431个全部成分信息的产量预测模型的构筑
[0074]
从每1个数据中具有431个成分的分析数据的峰面积值和产量值的全部125个数据矩阵构筑opls模型(图a1)。需要说明的是,在构筑时,各成分的分析数据的峰面积值及产量数据通过自动缩放而变换为平均0、方差1。r2=0.87、q2=0.78,可以说是具有高预测性能的模型。
[0075]
在上述模型中,算出被称为vip(variable importance in the projection,投影中的变量重要性)值的各成分所给予的对模型性能的贡献度。
[0076]
vip值通过下述式1求出。
[0077]
[式1]
[0078][0079]
vip值的值越大,则对模型的贡献度越大,与相关系数的绝对值也越相关。将vip值的列表示于后述表a4a~4f中。
[0080]
(2)使用根据(1)的模型算出的vip值前97个成分的分析数据构筑的机械学习模型
[0081]
作为解析工具,使用visual mining studio(以下,记为vms,(株)ntt数据数理系统)。
[0082]
(2
‑
1)每1个数据具有vip值前97个成分的分析数据的峰面积值和产量值,将全部125个数据矩阵作为学习数据,导入vms构筑了模型(随机森林)(图a2)。r2为0.92。
[0083]
(2
‑
2)每1个数据具有vip值前97个成分的分析数据的峰面积值和产量值,将全部125个数据矩阵随机地分为2组(学习用和验证用),将一方的63个矩阵数据用作学习用,通过vms构筑模型(神经网络)(图a3)。r2为0.83。需要说明的是,验证用数据中的r2为0.58,可以说是具有良好的预测性能的模型。
[0084]
(3)以根据(1)的模型算出的vip值为指标的模型构筑(使用了2个以上的成分的分析数据的模型)
[0085]
(3
‑
1)使用了vip值为下位的成分的分析数据的模型
[0086]
使用vip值11位以下全部成分的分析数据、21位以下全部成分的分析数据、31位以下全部成分的分析数据
…
及351位以下全部成分的分析数据,通过opls法构筑模型(图a4)。
[0087]
满足q2>0.50的是使用了11位以下全部成分的分析数据~251位以下全部成分的
分析数据的模型。即使使用vip值261位以下的成分的全部分析数据,也不会成为q2>0.50。
[0088]
(3
‑
2)使用了两个到vip值前10位的成分的分析数据的模型对于vip值第1位至10位的成分的分析数据中的任意2个的组合(45种),通过opls法构筑模型(图a5)。
[0089]
在任一模型中均成为q2>0.50。
[0090]
(3
‑
3)使用了基于vip值的连续的2个成分的分析数据的模型
[0091]
使用vip值第1位和2位、11位和12位、21位和22位、
…
及201位和202位的成分的分析数据且通过opls法构筑模型(图a6)。
[0092]
只要是使用从vip值30位以上中选择的任意2个成分的分析数据制作的模型,则q2的值成为q2>0.50的模型较多。
[0093]
(3
‑
4)使用了基于vip值的连续的3个成分的分析数据的模型
[0094]
使用vip值第1位和2位和3位、11位和12位和13位、21位和22位和23位、
…
及221位和222位和223位的成分的分析数据且通过opls法构筑模型(图a7)。
[0095]
只要是使用从vip值70位以上中选择的任意3个成分的分析数据制作的模型,则q2的值成为q2>0.50的模型较多。
[0096]
(3
‑
5)使用了基于vip值的连续的4个成分的分析数据的模型
[0097]
使用vip值第1位和2位和3位和4位、11位和12位和13位和14位、21位和22位和23位和24位、
…
及221位和222位和223位和224位的成分的分析数据,通过opls法构筑模型(图a8)。
[0098]
只要是使用从vip值100位以上中选择的任意4个成分的分析数据制作的模型,则q2的值成为q2>0.50的模型较多。
[0099]
(3
‑
6)使用了基于vip值的连续的5个成分的分析数据的模型
[0100]
采用vip值第1位~5位、11位~15位、21位~25位、
…
及251位~255位的成分的分析数据且通过opls法构筑模型(图a9)。
[0101]
只要是使用从vip值100位以上中选择的任意5个成分的分析数据制作的模型,则q2的值成为q2>0.50的模型较多。
[0102]
(3
‑
7)使用了基于vip值的连续的6个成分的分析数据的模型
[0103]
采用vip值第1位~6位、11位~16位、21位~26位、
…
及281位~286位的成分的分析数据且通过opls法构筑模型(图a10)。
[0104]
只要是使用从vip值130位以上中选择的任意6个成分的分析数据制作的模型,则q2的值成为q2>0.50的模型较多。
[0105]
(3
‑
8)使用了基于vip值的连续的7个成分的分析数据的模型
[0106]
采用vip值第1位~7位、11位~17位、21位~27位、
…
及281位~287位的成分的分析数据且通过opls法构筑模型(图a11)。
[0107]
只要是使用从vip值140位以上中选择的任意7个成分的分析数据制作的模型,则q2的值成为q2>0.50的模型较多。
[0108]
(3
‑
9)使用了基于vip值的连续的8个成分的分析数据的模型
[0109]
采用vip值第1位~8位、11位~18位、21位~28位、
…
及281位~288位成分的分析数据且通过opls法构筑模型(图a12)。
[0110]
只要是使用从vip值140位以上中选择的任意8个成分的分析数据制作的模型,则
q2的值成为q2>0.50的模型较多。
[0111]
(3
‑
10)使用了基于vip值的连续的9个成分的分析数据的模型
[0112]
采用vip值第1位~9位、11位~19位、21位~29位、
…
及281位~289位的成分的分析数据且通过opls法构筑模型(图a13)。
[0113]
只要是使用从vip值140位以上中选择的任意9个成分的分析数据制作的模型,则q2的值成为q2>0.50的模型较多。
[0114]
(3
‑
11)使用了基于vip值的连续的10个成分的分析数据的模型
[0115]
采用vip值第1位~10位、11位~20位、21位~30位、
…
及281位~290位的成分的分析数据且通过opls法构筑模型(图a14)。
[0116]
只要是使用从vip值160位以上中选择的任意10个成分的分析数据制作的模型,则q2的值成为q2>0.50的模型较多。
[0117]
就预测中使用的成分数量而言,在简便地进行预测的情况下,成分数量越少越好,例如为10个以下,优选为5个以下,更优选为3个以下,最优选为1个。另外,在想要提高精度的情况下,成分数量越多越好,例如为11个以上,优选为20个以上,更优选为50个以上,更优选为90个以上,最优选为97个。在以较少的成分数量进行预测的情况下,优选将vip值上位的成分或相关系数更高的成分用于预测。
[0118]
(4)使用了从431个选择的一部分成分信息的产量预测模型的构筑
[0119]
除了使用表a3a~f的全部431个成分峰以外,通过使用从中选择的成分峰,也能够构筑精度高的预测模型。
[0120]
例如,在表a3a~f的全部431个成分峰中,选择考虑了峰的形状、样品间的平均的检测强度等的301个成分的峰数据,适当校正该成分峰,同样地构筑opls模型,进一步算出构筑出的模型的vip值(后述表a6a~6d),使用其前100个成分(下述)的分析数据构筑预测模型时,能够构筑表示预测精度的r2=0.82、表示预测性的q2=0.78的精度高的模型(在后述实施例中称为预测模型a,图a15)。
[0121]
<预测模型a中的vip值前100位的成分编号>
[0122]
7、15、17、20、21、22、23、35、37、39、42、44、51、54、57、58、68、71、73、80、85、86、90、93、95、108、116、122、131、139、149、153、157、158、160、161、165、171、176、179、187、208、214、223、227、233、237、245、252、253、261、278、279、282、283、284、294、298、299、300、304、305、308、309、310、313、316、317、318、320、325、327、328、329、330、331、352、353、355、356、357、358、359、362、363、367、380、381、385、388、389、390、392、395、396、399、421、422、428、431。
[0123]
在第二发明中,作为被分析的叶中的成分,为选自2
‑
羟基吡啶(2
‑
hydroxypyridine)、胆碱(choline)、柠檬酸(citric acid)、甘油酸(glyceric acid)、甘氨酸(glycine)、l
‑
焦谷氨酸(l
‑
pyroglutamic acid)、丙二酸(malonic acid)、蔗糖(sucrose)及苏糖醇(threitol)中的1种以上。
[0124]
该9个成分是从大豆的代谢物质中选择提取的,其选择方法详细如实施例所示,概略地与第一发明同样地是,1)在2015年~2017年栽培改变了土壤、品种、肥料的大豆125株,2)分别在播种后1个月左右采集1片叶子。接着,3)使用甲醇/水/氯仿的混合溶剂(5:2:2,v/v/v)进行成分提取,进行了衍生化之后,4)进行gc/ms分析,将得到的来源于各成分的峰信
息(保持时间、质量信息)与现有的gc/ms质谱图谱库进行对照,由此,鉴定峰,5)进行分析数据与对应的产量数据的相关分析,获取判定为与产量相关的成分。
[0125]
获取的125个叶中9个成分的分析数据与对应的产量数据的相关分析的结果(通过各成分的分析数据的峰面积与产量的单相关系数r及无相关的检验算出p值)如后述表b2所示,其中,2
‑
羟基吡啶、甘氨酸、l
‑
焦谷氨酸及蔗糖这4种相关系数的绝对值|r|超过0.51。因此,作为本发明的分析对象成分,更优选包含选自2
‑
羟基吡啶、甘氨酸、l
‑
焦谷氨酸及蔗糖中的1种以上。
[0126]
因此,大豆的产量的预测方法是能够对于想要预测的样品,获取选自上述9个成分、优选为2
‑
羟基吡啶、甘氨酸、l
‑
焦谷氨酸及蔗糖中的1种以上的分析数据,根据已知的产量与峰面积的相关关系推定产量值。
[0127]
另外,通过从上述9个成分的分析数据中使用多个,并与使用多变量分析方法构筑的产量预测模型进行对照,能够预测产量。
[0128]
即,采集从播种经过规定时间后的大豆的叶,得到分析样品,将该分析样品供于设备分析得到设备分析数据,将该设备分析数据与产量预测模型进行对照,由此,能够预测该大豆的产量。
[0129]
关于产量预测模型的构筑及评价,与在第一发明中说明的方法相同。
[0130]
以下,示出制作使用了上述9个成分的质谱分析数据的峰面积值和籽粒产量的各种大豆产量预测模型并验证其精度的结果。
[0131]
(1)使用了全部成分信息的产量预测模型的构筑
[0132]
由每1个数据具有9个成分的分析数据的峰面积值和产量值的全部125个数据矩阵构筑opls模型(图b1)。需要说明的是,在构筑时,各成分的分析数据的峰面积值及产量数据通过自动缩放而变换为平均0、方差1。r2=0.56、q2=0.55,可以说是具有高预测性能的模型。
[0133]
需要说明的是,仅由l
‑
焦谷氨酸的分析数据构筑的模型中r2=0.32、q2=0.29,因此,通过使用多个成分数据,能够构筑更高精度的模型。
[0134]
与第一发明同样地,在后述表b3中示出根据上述模型算出的vip值的列表。
[0135]
(2
‑
1)使用了来源于由(1)的模型算出的vip值下位的成分的峰的模型
[0136]
使用vip值1位以下的成分的全部分析数据、vip值2位以下的成分的全部分析数据或vip值3位以下的成分的全部分析数据构筑的opls模型满足q2>0.50,优选作为产量预测模型(图b2)。使用vip值4位以下及5位以下的成分的全部分析数据构筑的opls模型均不满足q2>0.50。
[0137]
(2
‑
2)使用了多个由(1)的模型算出的vip值上位的成分的分析数据的模型
[0138]
使用从9个成分的分析数据中选择的任意4个以上的数据构筑的模型中,满足q2>0.50的模型优选作为产量预测模型。具体而言,可以举出以下的1)~4)所示的模型。
[0139]
1)使用了从vip值上位依次连续的4个成分的分析数据的模型
[0140]
对于vip值6位以上的成分,使用从vip值上位依次连续的4个成分的分析数据构筑的opls模型满足q2>0.50,优选作为产量预测模型。另外,使用vip值3位~6位的成分的分析数据构筑的opls模型满足q2>0.50,因此,认为如果是vip值6位以上,则通过使用任意的4个成分的分析数据,能够得到满足q2>0.50的预测模型。
[0141]
例如,可以举出使用vip值第1位~4位、2位~5位、3位~6位的成分的分析数据构筑的opls模型(图b4)。
[0142]
2)使用了从vip值上位依次连续的5个成分的分析数据的模型
[0143]
对于vip值7位以上的成分,使用从vip值上位依次连续的5个成分的分析数据构筑的opls模型满足q2>0.50,优选作为产量预测模型。另外,由于使用vip值3位~7位的成分的分析数据构筑的opls模型满足q2>0.50,因此,认为如果是vip值7位以上,则通过使用任意的5个成分的分析数据,能够得到满足q2>0.50的预测模型。
[0144]
例如,可以举出使用vip值第1位~5位、2位~6位、3位~7位的成分的分析数据构筑的opls模型(图b5)。
[0145]
3)使用了从vip值上位依次连续的6个成分的分析数据的模型
[0146]
对于vip值8位以上的成分,使用从vip值上位依次连续的6个成分的分析数据构筑的opls模型满足q2>0.50,优选作为产量预测模型。另外,使用vip值3位~8位的成分的分析数据构筑的opls模型满足q2>0.50,因此,认为如果是vip值8位以上,则通过使用任意的6个成分的分析数据,能够得到满足q2>0.50的预测模型。
[0147]
例如可以举出使用vip值第1位~6位、2位~7位、3位~8位的成分的分析数据构筑的opls模型(图b6、图b2)。
[0148]
4)使用了从vip值上位依次连续的7个成分的分析数据的模型
[0149]
使用从vip值上位依次连续的7个成分的分析数据构筑的opls模型满足q2>0.50,优选作为产量预测模型。另外,使用vip值3位~9位的成分的分析数据构筑的opls模型满足q2>0.50,因此,认为通过使用9个成分中任意的7个成分的分析数据,能够得到满足q2>0.50的预测模型。
[0150]
例如,可以举出使用vip值第1位~7位、2位~8位或3位~9位的成分的分析数据构筑的opls模型(图b7)。
[0151]
以下示出本发明的方式和优选的实施方式。
[0152]
<1>一种大豆的产量预测方法,其中,由从大豆采集的叶样品获取1个以上的成分的分析数据,利用该数据与大豆产量的相关性来预测大豆的产量。
[0153]
<2>根据<1>所述的方法,其中,通过集中qc法校正所述1个以上的成分的分析数据。
[0154]
<3>根据<1>所述的方法,其中,通过内部标准物质校正所述1个以上的成分的分析数据。
[0155]
<4>根据<1>~<3>中任一项所述的方法,其中,所述成分为选自通过质谱提供的精确质量(m/z)为139~1156的成分中的1种以上。
[0156]
<5>根据<1>~<3>中任一项所述的方法,其中,所述成分为由通过质谱提供的精确质量(m/z)规定的选自所述表a1a~1c所记载的成分中的1种以上。
[0157]
<6>根据<5>所述的方法,其中,成分为选自所述表a1a~1c所记载的成分编号13、14、17、20、21、22、23、28、35、36、37、39、41、42、44、47、48、51、52、54、57、58、68、71、73、80、85、86、90、91、96、98、99、100、107、108、110、122、125、131、134、135、137、139、142、149、150、153、157、159、160、161、171、174、176、179、181、182、188、202、208、209、214、215、217、218、228、230、235、244、245、246、247、249、251、252、253、261、264、268、275、278、279、280、
282、283、284、288、294、296、298、299、305、308、310、313、317、325、327、329、330、341、347、353、355、356、363、367、369、370、384、389、395、421、422、423、428及431中的1种以上。
[0158]
<7>根据<5>所述的方法,其中,成分为选自所述表a1a~1c所记载的成分编号14、22、23、36、37、41、42、51、52、68、90、122、139、149、159、214、228、230、235、247、249、252、253、268、275、278、284、288、298、305、308、313、317、329、347、363、395、421、422及428中的1种以上。
[0159]
<8>根据<5>所述的方法,其中,成分为选自所述表a1a~1c所记载的成分编号14、23、36、37、41、51、68、90、122、149、214、230、235、247、249、252、275、284、298、305、308、313、317、347、363、421、422及428中的1种以上。
[0160]
<9>根据<5>所述的方法,其中,成分包含选自大豆皂苷bb;组成式以c
21
h
22
o
11
表示且在糖苷配基的组成式为c
15
h
12
o6的脱氢黄酮醇键合有葡萄糖的单糖苷体;组成式以c
33
h
40
o
19
表示且在糖苷配基的组成式为c
15
h
10
o6的黄酮醇键合有1个葡萄糖和2个鼠李糖的三糖苷体;及组成式以c
21
h
22
o
12
表示且在糖苷配基的组成式为c
15
h
12
o7的脱氢黄酮醇键合有葡萄糖的单糖苷体中的1种以上。
[0161]
<10>根据<1>~<9>中任一项所述的方法,其中,从初生叶展开期至籽粒膨大期的大豆采集叶样品。
[0162]
<11>根据<1>~<9>中任一项所述的方法,其中,从初生叶展开期至开花期的大豆采集叶样品。
[0163]
<12>根据<1>~<11>中任一项所述的方法,其中,分析数据为质谱数据。
[0164]
<13>根据<5>~<12>中任一项所述的方法,其中,包括将从叶样品获取的成分的分析数据与使用所述表a1a~1c所记载的成分的分析数据构筑的产量预测模型进行对照的工序。
[0165]
<14>根据<13>所述的方法,其中,产量预测模型从所述表a1a~1c所记载的成分中的vip值前10个中使用至少2个。
[0166]
<15>根据<13>所述的方法,其中,产量预测模型从所述表a1a~1c所记载的成分中的vip值前22个中使用至少2个。
[0167]
<16>根据<13>所述的方法,其中,产量预测模型从所述表a1a~1c所记载的成分中的vip值前63个中使用至少3个。
[0168]
<17>根据<13>所述的方法,其中,产量预测模型从所述表a1a~1c所记载的成分中的vip值前94个中使用至少4个。
[0169]
<18>根据<13>所述的方法,其中,产量预测模型从所述表a1a~1c所记载的成分中的vip值前95个中使用至少5个。
[0170]
<19>根据<13>所述的方法,其中,产量预测模型从所述表a1a~1c所记载的成分中的vip值前126个中使用至少6个。
[0171]
<20>根据<13>所述的方法,其中,产量预测模型从所述表a1a~1c所记载的成分中的vip值前137个中使用至少7个。
[0172]
<21>根据<13>所述的方法,其中,产量预测模型从所述表a1a~1c所记载的成分中的vip值前138个中使用至少8个。
[0173]
<22>根据<13>所述的方法,其中,产量预测模型从所述表a1a~1c所记载的成
分中的vip值前139个中使用至少9个。
[0174]
<23>根据<13>所述的方法,其中,产量预测模型从所述表a1a~1c所记载的成分中的vip值前160个中使用至少10个。
[0175]
<24>根据<14>~<23>中任一项所述的方法,其中,vip值通过使用所述表a1a~1c所记载的全部成分的成分信息构筑的产量预测模型而算出。
[0176]
<25>根据<5>所述的方法,其中,包括将从叶样品获取的成分的分析数据与使用从所述表a1a~1c所记载的成分中选择的后述表a6a~a6d所记载的成分的分析数据构筑的产量预测模型进行对照的工序。
[0177]
<26>根据<5>所述的方法,其中,包括将从叶样品获取的成分的分析数据与使用选自所述表a1a~1c所记载的成分中的下述的100个成分的分析数据构筑的产量预测模型进行对照的工序,
[0178]
成分编号7、15、17、20、21、22、23、35、37、39、42、44、51、54、57、58、68、71、73、80、85、86、90、93、95、108、116、122、131、139、149、153、157、158、160、161、165、171、176、179、187、208、214、223、227、233、237、245、252、253、261、278、279、282、283、284、294、298、299、300、304、305、308、309、310、313、316、317、318、320、325、327、328、329、330、331、352、353、355、356、357、358、359、362、363、367、380、381、385、388、389、390、392、395、396、399、421、422、428、431。
[0179]
<27>根据<25>或<26>所述的方法,其中,从初生叶展开期至籽粒膨大期的大豆采集叶样品。
[0180]
<28>根据<25>或<26>所述的方法,其中,从初生叶展开期至开花期的大豆采集叶样品。
[0181]
<29>根据<25>~<28>中任一项所述的方法,其中,分析数据为质谱数据。
[0182]
<30>根据<13>~<29>中任一项所述的方法,其中,产量预测模型为使用opls法构筑的模型。
[0183]
<31>根据<13>~<29>中任一项所述的方法,其中,产量预测模型为使用机械学习
·
回归分析方法构筑的模型。
[0184]
<32>根据<4>~<31>中任一项所述的方法,其中,精确质量是以小数点后4位以上的精度测得的。
[0185]
<33>一种方法,其中,所述方法是由从大豆采集的叶样品中获取1个以上的成分的分析数据,利用该数据与大豆产量的相关性来预测大豆的产量的大豆的产量预测方法,成分为选自2
‑
羟基吡啶、胆碱、柠檬酸、甘油酸、甘氨酸、l
‑
焦谷氨酸、丙二酸、蔗糖及苏糖醇中的1种以上。
[0186]
<34>根据<33>所述的方法,其中,成分为选自2
‑
羟基吡啶、甘氨酸、l
‑
焦谷氨酸及蔗糖中的1种以上。
[0187]
<35>根据<33>或<34>所述的方法,其中,从初生叶展开期至籽粒膨大期的大豆采集叶样品。
[0188]
<36>根据<33>~<34>中任一项所述的方法,其中,从初生叶展开期至开花期的大豆采集叶样品。
[0189]
<37>根据<33>~<36>中任一项所述的方法,其中,分析数据为质谱数据。
[0190]
<38>根据<33>~<37>中任一项所述的方法,其中,包括将从叶样品获取的成分的分析数据与使用从所述9个成分中选择的分析数据构筑的产量预测模型进行对照的工序。
[0191]
<39>根据<38>所述的方法,其中,产量预测模型对于所述9个成分中的分析数据中的vip值为6位以上的成分使用任意的4个数据。
[0192]
<40>根据<38>所述的方法,其中,产量预测模型对于所述9个成分的分析数据中的vip值为7位以上的成分使用任意的5个数据。
[0193]
<41>根据<38>所述的方法,其中,产量预测模型对于所述9个成分的分析数据中的vip值为8位以上的成分使用任意的6个数据。
[0194]
<42>根据<38>所述的方法,其中,产量预测模型使用所述9个成分的分析数据中的任意的7个数据。
[0195]
<43>根据<38>所述的方法,其中,产量预测模型使用所述9个成分的分析数据中的vip值1位以下的成分的全部数据、vip值2位以下的成分的全部数据、或vip值3位以下的成分的全部数据。
[0196]
<44>根据<38>所述的方法,其中,产量预测模型使用所述9个成分的分析数据中的vip值第1位~4位、2位~5位或3位~6位的成分的分析数据。
[0197]
<45>根据<38>所述的方法,其中,产量预测模型使用所述9个成分的分析数据中的vip值第1位~5位、2位~6位或3位~7位的成分的分析数据。
[0198]
<46>根据<38>所述的方法,其中,产量预测模型使用所述9个成分的分析数据中的vip值第1位~6位、2位~7位或3位~8位的成分的分析数据。
[0199]
<47>根据<38>所述的方法,其中,产量预测模型使用所述9个成分的分析数据中的vip值第1位~7位、2位~8位或3位~9位的成分的分析数据。
[0200]
<48>根据<38>~<47>中任一项所述的方法,其中,产量预测模型为使用opls法构筑的模型。
[0201]
<49>根据<38>~<47>中任一项所述的方法,其中,产量预测模型为使用回归分析方法构筑的模型。
[0202]
<50>根据<37>~<47>中任一项所述的方法,其中,质谱数据为小数点后4位以上的精度。
[0203]
实施例
[0204]
a1.各栽培试验
[0205]
对2015年至2017年实施的室外盆栽培试验数据进行详细地说明。试验全部实施4个试验。
[0206]
1)2015年盆试验(1):
[0207]
在栃木县内实施了盆栽培。土壤使用国内的田间土,以氮:磷酸:钾=3:6:6(kg/10a)的方式进行施肥,用耕耘机耕耘土壤。土壤使用了该耕耘后的土壤。盆使用1/2000a瓦氏盆,将上述土壤每1盆装约8l,准备15盆。2015年6月25日播种3粒播种于各盆内两处(每1盆使用6粒)。需要说明的是,品种使用了“里
のほほえみ
(satonohohoemi)”。在初生叶展开期每1处间苗成1株,制成各盆2株。收获在11月9日实施(播种后137天)。需要说明的是,产量预测用使用5盆10株。
[0208]
2)2015年盆试验(2):
[0209]
在和歌山县内实施了盆栽培。土壤使用国内的田间土,以氮:磷酸:钾=1:6:6、3:6:6和10:6:6(kg/10a)的方式进行施肥,使用耕耘后的土壤(设定仅氮量不同的3种施肥条件)。盆使用1/2000a瓦氏盆,将上述土壤每1盆装约8l,在各施肥条件下分别准备15盆共计45盆。2015年7月1日播种3粒播种于各盆内两处(各盆使用6粒)。需要说明的是,品种使用了“福丰(fukuyutaka)”。在初生叶展开期中每1处间苗成1株,制成各盆2株。收获在11月11日实施(播种后133天)。需要说明的是,产量预测用是使用各5盆10株的计划,但由于缺少了1株,因此,使用了共计29株。
[0210]
3)2016年盆试验:
[0211]
在栃木县内实施了盆栽培。土壤使用国内的田间土,实施试验。盆使用1/2000a瓦氏盆,将上述土壤每1盆装约8l,准备75盆。静置数日后,与2015年同样地进行播种。播种在2016年7月1日进行,在11月15日进行收获。需要说明的是,品种使用了“里
のほほえみ
(satonohohoemi)”。另外,产量预测用使用了23盆46株。
[0212]
4)2017年盆试验:
[0213]
在栃木县内实施了盆栽培。土壤使用国内田间土,使用了向其中添加作为肥料的苦土石灰(协和)125g/m2和含磷酸的油渣(大荣物产)100g/m2的土壤(1
×
)以及将添加了肥料的土壤和未添加土壤各一半量混合而成的土壤(0.5
×
)这2种。另外,品种使用了“里
のほほえみ
(satonohohoemi)”、“福丰(fukuyutaka)”,
“エンレイ
(enrei)”及“湯上
がり
娘(yuagari musume)”这4个品种。盆使用1/2000a瓦氏盆,将上述土壤每1盆装约8l,各土壤各准备5盆,准备4个品种共计40盆。静置数日后,按照品种播种4粒,播种于各盆内两处(各盆使用8粒)。在初生叶展开期每1处间苗成1株,制成各盆2株。播种在2017年7月4日进行,收获在10月以后,从达到成熟期且判断为最佳收获期的株开始依次进行收获。
[0214]
a2.叶的采样
[0215]
叶的采样在各个栽培试验中在播种后28~32天的日子中实施(大致10点
‑
15点)。此时的大豆生长阶段根据年度、栽培条件、品种略有不同,但大致为叶龄5
‑
7左右。在此所说的叶龄是将初生叶设为1时在最顶部展开的真叶从下方数数到第几片时的值。叶的采样是从构成最顶部展开的真叶的1或2叶龄的老的真叶的复叶3片中采集中央的复叶。但是,在中央的复叶受到虫害等显著损伤的情况下,采取其它的复叶。采集的叶子用铝箔包裹,立即在液氮中冻结,使代谢反应停止。冻结样品在维持冻结状态的状态下带回实验室,施以冷冻干燥使其干燥。将该干燥后的样品供于后述的提取操作。需要说明的是,在2015年及2016年的盆栽培试验中,每1个个体进行采集,产量数据使用对应的个体的数据。另一方面,在2017年盆栽培试验中,按每1盆、即每2个个体实施采样,产量数据使用2个个体的平均值。
[0216]
另外,对叶子进行采样时的从播种起的天数如下。
[0217]
*2015年盆试验(1):2015年7月25日(播种后30天)
[0218]
*2015年盆试验(2):2015年7月29日(播种后28天)
[0219]
*2016年盆试验:2016年8月2日(播种后32天)
[0220]
*2017年盆试验:2017年8月3日(播种后30天)
[0221]
a3.最终的籽粒产量的测定
[0222]
从栽培试验后的各个体回收全部籽粒,在80℃下干燥2
‑
3天。产量数据使用该干燥
重量(gdw/个体)。如2
‑
2中已述那样,2017年的试验中的2个体(每1盆)的平均数据作为1个进行计数,2015
‑
17年的盆试验数据共计125个。产量数据如表a2a~2c所示,最小为0.9gdw/个体、最大为42.5gdw/个体。
[0223]
[表a2a]
[0224]
试验名称样品名称年度条件品种干燥籽粒重(g/株)2015年盆试验(1)t12015氮量:3satonohohoemi30.6 t102015氮量:3satonohohoemi27.1 t22015氮量:3satonohohoemi28.0 t32015氮量:3satonohohoemi28.4 t42015氮量:3satonohohoemi26.6 t52015氮量:3satonohohoemi29.3 t62015氮量:3satonohohoemi27.0 t72015氮量:3satonohohoemi25.3 t82015氮量:3satonohohoemi27.1 t92015氮量:3satonohohoemi23.82015年盆试验(2)n1
‑
12015氮量:1福丰11.0 n1
‑
22015氮量:1福丰11.3 n1
‑
32015氮量:1福丰13.0 n1
‑
42015氮量:1福丰10.3 n1
‑
52015氮量:1福丰19.4 n1
‑
62015氮量:1福丰13.9 n1
‑
72015氮量:1福丰11.8 n1
‑
82015氮量:1福丰16.3 n1
‑
92015氮量:1福丰17.7 n3
‑
12015氮量:3福丰12.8 n3
‑
102015氮量:3福丰7.5 n3
‑
22015氮量:3福丰9.4 n3
‑
32015氮量:3福丰15.2 n3
‑
42015氮量:3福丰11.8 n3
‑
52015氮量:3福丰10.1 n3
‑
62015氮量:3福丰15.8 n3
‑
72015氮量:3福丰8.3 n3
‑
82015氮量:3福丰11.2 n3
‑
92015氮量:3福丰5.9 n10
‑
12015氮量:10福丰17.1 n10
‑
102015氮量:10福丰11.0 n10
‑
22015氮量:10福丰13.5 n10
‑
32015氮量:10福丰8.3 n10
‑
42015氮量:10福丰13.3 n10
‑
52015氮量:10福丰14.6
ꢀ
n10
‑
62015氮量:10福丰10.8 n10
‑
72015氮量:10福丰9.8 n10
‑
82015氮量:10福丰15.3 n10
‑
92015氮量:10福丰17.0
[0225]
[表a2b]
[0226]
试验名称样品名称年度品种干燥籽粒重(g/株)2016年盆试验kg12016satonohohoemi30.3 kg22016satonohohoemi33.0 kg32016satonohohoemi29.8 kg42016satonohohoemi23.1 kg52016satonohohoemi26.8 kg62016satonohohoemi24.9 kg72016satonohohoemi28.9 kg82016satonohohoemi28.4 kg92016satonohohoemi23.0 kg102016satonohohoemi24.4 mg12016satonohohoemi29.5 mg22016satonohohoemi35.4 mg32016satonohohoemi31.9 mg42016satonohohoemi32.2 mg52016satonohohoemi27.0 mg62016satonohohoemi29.6 mg72016satonohohoemi26.8 mg82016satonohohoemi34.9 mg92016satonohohoemi34.8 mg102016satonohohoemi35.7 tc12016satonohohoemi22.9 tc22016satonohohoemi29.3 tc32016satonohohoemi22.2 tc42016satonohohoemi21.9 tc52016satonohohoemi21.1 tc62016satonohohoemi25.7 tc72016satonohohoemi21.9 tc82016satonohohoemi26.8 tc92016satonohohoemi28.6 tc102016satonohohoemi32.1 tc112016satonohohoemi28.6 tc122016satonohohoemi25.8 tc132016satonohohoemi32.9
ꢀ
tc142016satonohohoemi29.6 tc152016satonohohoemi16.5 tc162016satonohohoemi18.7 wk12016satonohohoemi37.1 wk22016satonohohoemi29.3 wk32016satonohohoemi31.9 wk42016satonohohoemi31.7 wk52016satonohohoemi16.1 wk62016satonohohoemi42.5 wk72016satonohohoemi33.4 wk82016satonohohoemi27.5 wk92016satonohohoemi29.0 wk102016satonohohoemi38.4
[0227]
[表a2c]
[0228]
试验名称样品名称年度条件品種干燥籽粒重(g/株)2017年盆试验y1/2_120171/2
×
肥料yuagari musume5.4 y1/2_220171/2
×
肥料yuagari musume4.3 y1/2_320171/2
×
肥料yuagari musume4.4 y1/2_420171/2
×
肥料yuagari musume5.4 y1/2_520171/2
×
肥料yuagari musume4.3 y1_120171
×
肥料yuagari musume13.2 y1_220171
×
肥料yuagari musume14.3 y1_320171
×
肥料yuagari musume9.3 y1_420171
×
肥料yuagari musume11.1 y1_520171
×
肥料yuagari musume12.4 f1/2_120171/2
×
肥料福丰5.5 f1/2_220171/2
×
肥料福丰7.1 f1/2_320171/2
×
肥料福丰9.8 f1/2_420171/2
×
肥料福丰7.9 f1/2_520171/2
×
肥料福丰5.9 f1_120171
×
肥料福丰14.2 f1_220171
×
肥料福丰17.1 f1_320171
×
肥料福丰17.0 f1_420171
×
肥料福丰17.7 f1_520171
×
肥料福丰5.1 s1/2_120171/2
×
肥料satonohohoemi6.1 s1/2_220171/2
×
肥料satonohohoemi8.0 s1/2_320171/2
×
肥料satonohohoemi10.3 s1/2_420171/2
×
肥料satonohohoemi8.7
ꢀ
s1/2_520171/2
×
肥料satonohohoemi8.7 s1_120171
×
肥料satonohohoemi15.6 s1_220171
×
肥料satonohohoemi19.8 s1_320171
×
肥料satonohohoemi19.2 s1_420171
×
肥料satonohohoemi18.1 s1_520171
×
肥料satonohohoemi14.5 e1/2_120171/2
×
肥料enrei8.3 e1/2_220171/2
×
肥料enrei7.6 e1/2_320171/2
×
肥料enrei7.2 e1/2_420171/2
×
肥料enrei9.6 e1/2_520171/2
×
肥料enrei0.9 e1_120171
×
肥料enrei11.4 e1_220171
×
肥料enrei16.4 e1_320171
×
肥料enrei15.7 e1_420171
×
肥料enrei14.8 e1_520171
×
肥料enrei16.5
[0229]
<使用了由lc/ms分离检测的大豆的代谢物质的评价>
[0230]
a4.采集的叶的成分的提取
[0231]
对于表a2a~2c所示的125株的冷冻干燥后的叶样品,使用刮刀通过手工操作尽可能地进行粉碎。粉碎后,在2ml的管(safe
‑
lock管、eppendorf)中称量10mg,将直径5mm的1个氧化锆制球加入管中,用珠式粉碎机(mm400,retsch)以25hz粉碎1分钟。提取溶剂使用以成为500ng/ml的方式添加利多卡因(和光纯药工业,#120
‑
02671)作为内部标准的80v/v%甲醇水溶液。向粉碎后的管中添加1ml所制备的提取溶剂,利用该珠式粉碎机,以20hz进行5分钟的均质提取。提取结束后,用2,000
×
g左右的台式离心机(chibitan)离心30秒左右,用0.45μm的亲水性ptfe过滤器(dismic
‑
13hp0.45μm syringe filter,advantec)过滤,得到分析样品。
[0232]
a5.利用lc/ms进行的叶样品的分析
[0233]
关于叶提取样品的分析,将agilent公司制造的hplc系统(infinity1260系列)作为前部,使用ab sciex公司制造的q
‑
tofms装置(triple tof 4600)作为检测器进行lc/ms分析。hplc中的分离柱使用(株)资生堂株式会社制造的核壳柱capcell core c18(2.1mm i.d.
×
100mm,粒子计2.7μm)及保护柱(2.1mm i.d.
×
5mm,粒子计2.7μm),柱温度设定为40℃。自动进样器在分析中保持5℃。分析样品注入5μl。洗脱液使用a:0.1v/v%甲酸水溶液和b:0.1v/v%甲酸乙腈溶液。对于梯度洗脱条件,用1v/v%b(99v/v%a)保持0分钟~0.1分钟,在0.1分钟~13分钟之间使洗脱液b的比率从1v/v%b上升至99.5v/v%b,以99.5v/v%b保持至13.01分钟~16分钟。流速设为0.5ml/min。
[0234]
对于质谱装置条件,将电离模式设为正模式,电离法使用esi。在本分析体系中,一边重复利用tofms对洗脱的离子进行0.1秒的扫描,选择其中强度大的离子10个,并分别施加0.05秒钟的ms/ms的循环,一边获取由tofms扫描得到的分子离子信息(精确质量,m/z)和源自由ms/ms扫描所产生的片段的结构信息。质量测定范围设定为tofms为m/z 100
‑
1,250、
ms/ms为m/z 50
‑
1,250。对于各扫描的参数,关于tofms扫描,设定为gs1=50、gs2=50、cur=25、tem=450、isvf=5500、dp=80及ce=10,关于ms/ms扫描,设定为gs1=50、gs2=50、cur=25、tem=450、isvf=5500、dp=80、ce=30、ces=15、ird=30及irw=15。
[0235]
a6.数据矩阵的制作
[0236]
数据处理如下进行。首先,使用markerview
tm software(ab sciex)进行峰的提取。峰提取条件(“peak finding option”)设为相当于保持时间0.5分钟~16分钟的峰,将“enhance peak finding”的项目中的subtraction offset设定为20次扫描,将minimum spectral peak width设定为5ppm,将subtraction multi.factor设定为1.2,将minimum rt peak width设定为10次扫描,将noise threshold设定为5,对“more”的项目中的assign charge state输入检查。其结果,得到12,444的峰信息。
[0237]
接着,进行使检测到的峰在分析的各样品间排列的对准处理。对准的处理条件(“alighmment&filtering”)是将“alignment”的项目中的retention time tolerance设定为0.20分钟并且将mass tolerance设定为10.0ppm。另外,将“filtering”的项目中的intensity threshold设定为10,在retention time filtering输入检查,设为remove peaks in<3样品,将maximum number of peaks设定为50,000。在“internal standards”的项目中,使用利多卡因的峰进行保持时间的校正。
[0238]
接着,进行同位素峰的除去。同位素峰在提取峰的时刻软件自动地识别,在峰列表上标注“isotopic”的标签,因此,用“isotopic”进行排序并删除相应的峰。其结果,峰减少至10,112个峰。
[0239]
接着,进行样品间的峰强度校正。在本次的分析中,除了样品以外,制作从所有样品中混合了一定量的被称为集中qc的样品,以九分之一的频率实施了集中qc的分析。根据这些全部qc分析结果,实施如下的处理:计算“假定在分析各样品时分析qc样品,则各个峰强度如何变化”的推定值,实施以该值进行校正的处理,进行同一批次内的各样品间的灵敏度的校正。需要说明的是,本处理使用了理研提供的免费软件(lowess
‑
normalization
‑
tool)。最后,使用测得的30个qc分析数据计算10,112个峰的相对标准偏差(rsd),除去rsd>30%的偏差大的峰,最终得到431个峰数据、即431个成分的分析数据。将得到的分析数在表a3a~3f中表示。使用这些数据,进行以后的解析。
[0240]
[表a3a]
[0241]
成分编号m/z保持时间成分编号m/z保持时间1139.03893.9241209.15454.602141.95928.8442209.15485.023147.04355.0243211.06083.694147.04463.7444213.15039.615149.023415.0945214.25397.876149.024111.3946217.19618.557161.060613.1947219.17546.658163.03984.6648219.19509.899163.13255.4949220.113710.8410165.05503.7350221.04563.69
11170.09749.7351221.60203.5312171.15015.9052225.15004.6413175.14865.6553225.19728.0714177.05513.8754226.099111.3915179.071713.1955226.161011.9416181.12327.6256226.18127.1217181.12379.6057227.12864.5018183.18654.6558227.12946.0519186.09217.5459228.19547.7820189.12784.5560228.232112.0921190.05063.9261231.05126.8122191.14376.5262233.98423.8923191.14395.9263234.092810.2424193.08599.9064235.170210.7025193.086110.4865239.05623.6926193.159710.5066241.14465.2127194.11829.0067242.248511.4828195.06553.8368243.06674.5529196.112711.8369243.16085.9230197.11815.4670243.211412.5831199.13337.7871245.228113.2932199.18187.4472249.06216.8033200.23827.7773252.08744.9434205.087211.4174252.08824.5135205.09833.4875253.21707.4936207.06503.9376255.06696.0437207.13904.6577256.264912.7638209.117110.8478256.265011.9539209.11784.5179257.06603.7440209.15385.5380257.19088.66
[0242]
[表a3b]
[0243]
成分编号m/z保持时间成分编号m/z保持时间81259.08275.89121288.29117.5482259.207612.81122289.07274.5483261.150115.02123289.12289.9684261.223312.62124291.04015.9285263.238113.29125291.197313.1686264.23356.64126291.19757.7087265.14403.96127291.234011.76
88269.08187.57128293.21189.6389271.06186.93129293.213010.2690271.06194.54130293.249814.2891271.22807.42131295.09364.7092273.07695.55132295.10375.9093274.054111.48133295.12993.9794274.09283.74134295.228810.7595274.160612.33135297.243611.5396275.20208.66136298.09863.6297275.202310.26137299.202312.2798277.21849.64138301.142411.4199277.218610.75139305.06744.07100277.21869.95140305.99073.75101279.05126.30141307.01285.93102279.05158.46142307.09434.29103279.09518.04143309.20757.54104279.161011.57144309.222810.39105279.161114.98145315.00625.92106279.232010.11146316.21344.15107279.233311.46147316.28658.21108279.234010.52148318.28067.65109279.234312.60149319.15363.88110281.248513.28150319.285312.12111282.137613.05151320.99166.78112282.223613.75152321.06327.22113282.280013.02153321.09835.06114284.296013.94154321.14635.01115285.12559.94155322.27658.84116285.171312.07156323.07513.95117285.17186.80157323.12905.55118285.62719.92158325.14445.51119287.05667.03159327.079510.47120287.05674.76160327.233610.40
[0244]
[表a3c]
[0245]
成分编号m/z保持时间成分编号m/z保持时间161327.234010.73201363.255314.49162329.161312.34202363.312812.10163331.14095.64203364.32379.15164333.152812.59204365.32028.55
165335.12375.99205366.17835.63166335.154212.59206366.33939.59167335.259512.89207367.03435.90168335.259514.99208367.263512.24169335.26009.94209367.265211.77170336.312812.11210369.08313.87171337.09384.63211369.126812.08172337.17245.70212371.187610.38173338.344015.10213371.188111.33174339.07153.71214371.20755.47175339.07347.19215372.16734.12176341.13855.50216373.07783.67177341.145112.60217373.12915.55178341.268012.17218374.10883.73179342.21393.61219374.14595.06180342.33909.90220375.271012.10181343.10223.62221379.06343.74182343.10423.92222380.338912.11183343.22889.46223382.202612.00184343.22929.75224383.07716.31185344.13584.14225383.257410.80186346.15163.92226383.259111.24187349.09124.14227385.294512.11188349.148510.75228387.09383.84189349.276111.70229387.18328.47190351.25589.32230387.20324.56191352.25288.39231388.16275.55192353.271311.82232390.10353.67193355.08328.46233390.189212.05194355.10274.02234391.286214.98195357.15848.16235393.281112.10196357.170510.51236393.71436.30197358.16569.23237394.20896.74198358.980910.61238398.234112.86199361.255111.55239399.16456.78200362.01776.81240399.252010.98
[0246]
[表a3d]
[0247]
成分编号m/z保持时间成分编号m/z保持时间241401.08826.31281435.13005.57
242401.09078.99282435.13044.10243401.09098.48283436.14663.86244401.286912.48284439.19915.92245401.71126.16285439.36038.46246403.235112.28286440.233311.67247404.12154.21287440.25135.89248404.21028.47288441.37418.00249405.13165.58289441.37468.56250405.35348.56290442.25705.93251405.35387.88291443.10026.89252406.13623.87292443.10207.22253406.20784.47293445.20775.90254407.36888.13294448.19493.88255407.36928.82295449.10935.46256409.07573.87296449.11014.95257409.273811.56297454.294410.19258409.274911.23298455.11974.30259410.70596.48299457.20915.91260411.00223.73300457.20964.83261411.16274.49301461.17845.96262412.38089.25302466.26676.23263419.12013.87303468.28295.95264420.22386.96304468.393012.08265423.22455.91305469.18315.21266423.276210.07306471.218011.03267423.36438.56307471.22436.25268423.36447.83308473.10874.54269424.364912.10309473.20485.00270424.36817.86310474.17483.65271425.194310.51311477.14355.93272427.10448.96312478.13857.19273431.10176.81313479.19075.83274432.247611.69314482.327011.35275432.25974.62315483.09317.19276433.11405.30316484.27645.90277433.11495.61317489.08134.51278433.13554.31318489.21588.84279434.13864.32319489.360412.07280434.24064.50320492.24655.01
[0248]
[表a3e]
[0249]
成分编号m/z保持时间成分编号m/z保持时间321495.251612.87361567.40598.60322495.29838.29362568.428214.59323496.344110.26363577.36077.08324497.31519.93364589.485914.12325499.22848.05365593.283613.61326501.74258.86366595.16875.32327503.19485.56367595.37167.02328503.22437.98368599.39878.52329511.12805.88369599.39907.99330511.38037.94370599.414913.19331511.75577.99371607.258812.42332512.236310.80372607.296814.67333512.255512.18373608.300014.69334513.275310.68374609.455012.00335514.04528.48375611.16404.98336514.75197.44376611.469014.01337517.13786.45377611.471112.91338517.393212.04378612.475314.02339519.11715.94379613.484915.68340519.20905.59380613.487114.88341519.74038.03381614.490014.89342520.12005.81382617.40828.58343520.34389.88383617.426313.19344521.261010.68384618.07198.48345523.12728.48385621.273513.66346524.374911.40386623.30306.58347525.36565.63387627.467211.70348529.392211.70388636.425512.87349529.392213.38389638.442312.20350535.28288.59390660.426112.32351541.390812.92391666.30336.72352545.387212.07392673.33985.71353547.14746.41393686.453212.06354549.39568.56394691.407312.02355550.24667.89395741.22904.95356551.26177.94396742.479412.07357551.426514.59397743.44238.54
358562.77217.95398747.431912.05359563.398312.07399748.481912.79360566.16878.96400758.22484.76
[0250]
[表a3f]
[0251]
成分编号m/z保持时间401759.22814.73402771.509012.02403773.21754.52404773.526612.91405773.527114.02406786.42276.30407796.555813.57408806.546914.21409808.558213.99410811.501414.18411813.518514.01412820.40716.50413824.553713.91414824.560313.35415829.514513.32416840.549013.23417842.568311.69418847.525511.66419923.50638.86420923.50668.53421943.53498.06422945.53598.02423969.550010.88424970.615012.94425973.556613.16426975.574912.91427986.611212.964281013.53617.964291069.56538.574301073.56107.884311155.56838.75
[0252]
a7.相关解析
[0253]
使用与所获取的125个叶中431个成分的分析数据对应的产量数据、即125
×
432的矩阵数据进行相关解析。通过各成分的分析数据与产量数据的单相关系数r及无相关的检
验,算出p值。将结果在表a4a~4f中表示。需要说明的是,表中的“成分编号”是方便起见而在按质量顺序排列431个成分时从质量数小的一方开始标注编号而得到的。另外,在分析结果中还包含质量信息和保持时间的信息,但根据日本特开2016
‑
57219号公报,表示如果使用小数点后4位以上的精确质量数,则不管保持时间都可以在多个质谱用试样之间进行质谱数据的比较及解析。因此,除去保持时间的信息,仅记载了精确质量信息。
[0254]
[表a4a]
[0255]
成分编号m/z与产量的相关性rp成分编号m/z与产量的相关性rp1139.0389
‑
0.0500.57941209.15450.7460.0002141.9592
‑
0.1730.05442209.15480.6450.0003147.04350.0970.28243211.0608
‑
0.3190.0004147.0446
‑
0.3960.00044213.15030.5240.0005149.0234
‑
0.1670.06345214.2539
‑
0.1430.1116149.0241
‑
0.2890.00146217.1961
‑
0.2540.0047161.0606
‑
0.4800.00047219.1754
‑
0.5590.0008163.03980.2000.02548219.1950
‑
0.5580.0009163.1325
‑
0.0300.74449220.11370.0690.44110165.0550
‑
0.3880.00050221.0456
‑
0.3220.00011170.0974
‑
0.0490.59051221.60200.6970.00012171.1501
‑
0.2190.01452225.15000.6490.00013175.14860.5140.00053225.1972
‑
0.2280.01014177.0551
‑
0.7060.00054226.0991
‑
0.5950.00015179.0717
‑
0.4580.00055226.16100.3380.00016181.1232
‑
0.3740.00056226.18120.1890.03417181.12370.5410.00057227.1286
‑
0.5690.00018183.18650.1950.02958227.1294
‑
0.6240.00019186.0921
‑
0.1870.03759228.19540.2810.00120189.12780.5390.00060228.2321
‑
0.0170.84921190.05060.5330.00061231.05120.1880.03522191.1437
‑
0.6590.00062233.9842
‑
0.0540.54623191.14390.7130.00063234.0928
‑
0.1010.26524193.0859
‑
0.2280.01164235.1702
‑
0.2620.00325193.0861
‑
0.1880.03565239.0562
‑
0.3000.00126193.1597
‑
0.4350.00066241.1446
‑
0.3310.00027194.11820.3000.00167242.24850.0670.45628195.0655
‑
0.6190.00068243.0667
‑
0.7020.00029196.1127
‑
0.4400.00069243.16080.1490.09730197.1181
‑
0.2970.00170243.2114
‑
0.3490.00031199.1333
‑
0.0320.72471245.2281
‑
0.6160.00032199.18180.3090.00072249.06210.1590.07733200.2382
‑
0.0960.28573252.0874
‑
0.5380.00034205.0872
‑
0.3620.00074252.0882
‑
0.2690.00235205.0983
‑
0.6040.00075253.2170
‑
0.4890.00036207.0650
‑
0.6770.00076255.0669
‑
0.3330.000
37207.13900.6750.00077256.2649
‑
0.0880.33038209.11710.0560.53678256.26500.0110.90239209.1178
‑
0.5250.00079257.0660
‑
0.3470.00040209.15380.4640.00080257.1908
‑
0.5670.000
[0256]
[表a4b]
[0257]
成分编号m/z与产量的相关性rp成分编号m/z与产量的相关性rp81259.08270.2160.016121288.2911
‑
0.0240.78682259.2076
‑
0.5070.000122289.0727
‑
0.6860.00083261.1501
‑
0.0300.737123289.12280.1310.14684261.2233
‑
0.4660.000124291.04010.3440.00085263.2381
‑
0.6160.000125291.1973
‑
0.5450.00086264.2335
‑
0.5500.000126291.1975
‑
0.1250.16587265.14400.2900.001127291.2340
‑
0.4750.00088269.0818
‑
0.2050.022128293.2118
‑
0.3310.00089271.0618
‑
0.4560.000129293.2130
‑
0.4500.00090271.0619
‑
0.6910.000130293.2498
‑
0.3220.00091271.2280
‑
0.5160.000131295.09360.6110.00092273.0769
‑
0.3800.000132295.10370.1740.05293274.05410.1400.121133295.1299
‑
0.3610.00094274.0928
‑
0.3530.000134295.2288
‑
0.6030.00095274.16060.3950.000135297.2436
‑
0.5930.00096275.2020
‑
0.6290.000136298.09860.4350.00097275.2023
‑
0.4580.000137299.20230.5460.00098277.2184
‑
0.5560.000138301.14240.0020.98199277.2186
‑
0.5830.000139305.0674
‑
0.6430.000100277.2186
‑
0.5170.000140305.9907
‑
0.1800.044101279.0512
‑
0.3650.000141307.01280.3060.001102279.05150.3260.000142307.0943
‑
0.5390.000103279.0951
‑
0.4240.000143309.2075
‑
0.3950.000104279.1610
‑
0.2350.008144309.2228
‑
0.4000.000105279.1611
‑
0.0470.601145315.00620.1490.098106279.2320
‑
0.1440.109146316.2134
‑
0.0820.365107279.2333
‑
0.6050.000147316.2865
‑
0.4080.000108279.2340
‑
0.6030.000148318.2806
‑
0.2980.001109279.2343
‑
0.4760.000149319.1536
‑
0.7640.000110281.2485
‑
0.5930.000150319.2853
‑
0.5190.000111282.13760.1600.075151320.9916
‑
0.0350.699112282.22360.4050.000152321.0632
‑
0.0840.352113282.2800
‑
0.0510.576153321.0983
‑
0.5280.000114284.2960
‑
0.0650.474154321.14630.0930.304115285.12550.1190.187155322.2765
‑
0.1780.047116285.17130.4800.000156323.0751
‑
0.0720.422117285.17180.1790.046157323.12900.5580.000
118285.62710.0210.816158325.14440.5040.000119287.0566
‑
0.4410.000159327.0795
‑
0.6500.000120287.0567
‑
0.4090.000160327.2336
‑
0.5760.000
[0258]
[表a4c]
[0259]
成分编号m/z与产量的相关性rp成分编号m/z与产量的相关性rp161327.2340
‑
0.5650.000201363.2553
‑
0.0610.501162329.1613
‑
0.2790.002202363.3128
‑
0.5690.000163331.1409
‑
0.1320.141203364.3237
‑
0.3110.000164333.1528
‑
0.4930.000204365.3202
‑
0.4050.000165335.12370.4930.000205366.1783
‑
0.2680.002166335.1542
‑
0.4800.000206366.3393
‑
0.2310.010167335.2595
‑
0.1500.094207367.03430.2490.005168335.25950.1090.227208367.2635
‑
0.5930.000169335.26000.0280.757209367.2652
‑
0.5990.000170336.3128
‑
0.4110.000210369.0831
‑
0.3620.000171337.0938
‑
0.5310.000211369.12680.2420.006172337.17240.4550.000212371.1876
‑
0.3370.000173338.34400.1810.043213371.1881
‑
0.0800.374174339.0715
‑
0.5400.000214371.20750.7000.000175339.0734
‑
0.0850.344215372.1673
‑
0.5520.000176341.13850.5660.000216373.07780.3060.001177341.14510.1020.257217373.1291
‑
0.5580.000178341.2680
‑
0.1810.043218374.1088
‑
0.5680.000179342.21390.6220.000219374.1459
‑
0.2700.002180342.3390
‑
0.2350.008220375.2710
‑
0.4790.000181343.1022
‑
0.5810.000221379.0634
‑
0.4900.000182343.1042
‑
0.5790.000222380.3389
‑
0.4920.000183343.2288
‑
0.1700.058223382.20260.5020.000184343.2292
‑
0.0580.519224383.0771
‑
0.3940.000185344.1358
‑
0.4990.000225383.2574
‑
0.1700.058186346.1516
‑
0.0460.612226383.25910.0210.820187349.0912
‑
0.1700.058227385.2945
‑
0.0520.566188349.1485
‑
0.5630.000228387.0938
‑
0.6370.000189349.2761
‑
0.3210.000229387.18320.0750.408190351.2558
‑
0.4000.000230387.20320.6720.000191352.2528
‑
0.0020.984231388.1627
‑
0.0020.987192353.2713
‑
0.4500.000232390.1035
‑
0.4380.000193355.08320.3030.001233390.18920.4880.000194355.10270.4140.000234391.2862
‑
0.0960.286195357.15840.4140.000235393.2811
‑
0.7070.000196357.1705
‑
0.3350.000236393.71430.3620.000197358.1656
‑
0.4710.000237394.2089
‑
0.0060.950198358.98090.1700.058238398.2341
‑
0.3100.000
199361.2551
‑
0.1100.223239399.1645
‑
0.1320.143200362.01770.0440.627240399.2520
‑
0.4820.000
[0260]
[表a4d]
[0261]
成分编号m/z与产量的相关性rp成分编号m/z与产量的相关性rp241401.0882
‑
0.3530.000281435.1300
‑
0.4130.000242401.09070.2010.024282435.1304
‑
0.6140.000243401.09090.4760.000283436.1466
‑
0.5870.000244401.28690.5870.000284439.19910.7100.000245401.71120.5130.000285439.3603
‑
0.4980.000246403.2351
‑
0.5130.000286440.23330.3040.001247404.1215
‑
0.6690.000287440.25130.0540.552248404.21020.0660.465288441.3741
‑
0.6440.000249405.13160.7280.000289441.3746
‑
0.3110.000250405.3534
‑
0.3780.000290442.2570
‑
0.0050.958251405.3538
‑
0.5600.000291443.10020.0780.387252406.1362
‑
0.6620.000292443.10200.0020.982253406.2078
‑
0.6350.000293445.20770.1200.184254407.3688
‑
0.3890.000294448.19490.5680.000255407.3692
‑
0.0500.580295449.1093
‑
0.3930.000256409.0757
‑
0.3740.000296449.1101
‑
0.5380.000257409.2738
‑
0.1820.042297454.2944
‑
0.3050.001258409.2749
‑
0.1430.112298455.1197
‑
0.6840.000259410.70590.3680.000299457.20910.5920.000260411.0022
‑
0.0100.909300457.20960.4150.000261411.1627
‑
0.5460.000301461.17840.0940.299262412.38080.2870.001302466.2667
‑
0.4390.000263419.1201
‑
0.4890.000303468.28290.3110.000264420.2238
‑
0.5810.000304468.3930
‑
0.1350.133265423.22450.2040.022305469.18310.7400.000266423.2762
‑
0.3750.000306471.21800.4730.000267423.3643
‑
0.3800.000307471.2243
‑
0.3940.000268423.3644
‑
0.6540.000308473.1087
‑
0.7770.000269424.3649
‑
0.3710.000309473.20480.4890.000270424.3681
‑
0.3620.000310474.1748
‑
0.6280.000271425.19430.1130.211311477.14350.1620.071272427.10440.1470.101312478.1385
‑
0.1390.122273431.10170.1390.122313479.19070.6860.000274432.24760.2880.001314482.3270
‑
0.3570.000275432.25970.6630.000315483.0931
‑
0.2480.005276433.1140
‑
0.3540.000316484.27640.2650.003277433.1149
‑
0.3800.000317489.0813
‑
0.7250.000278433.1355
‑
0.6470.000318489.21580.1800.045279434.1386
‑
0.5710.000319489.36040.1950.029
280434.2406
‑
0.5880.000320492.24650.3430.000
[0262]
[表a4e]
[0263]
成分编号m/z与产量的相关性rp成分编号m/z与产量的相关性rp321495.2516
‑
0.0630.483361567.4059
‑
0.1920.032322495.29830.3940.000362568.42820.0090.918323496.3441
‑
0.1870.037363577.36070.6650.000324497.31510.0540.553364589.4859
‑
0.2740.002325499.2284
‑
0.5880.000365593.2836
‑
0.5050.000326501.74250.3110.000366595.1687
‑
0.4490.000327503.19480.5210.000367595.37160.6020.000328503.2243
‑
0.4640.000368599.3987
‑
0.2900.001329511.12800.6430.000369599.3990
‑
0.5920.000330511.3803
‑
0.5200.000370599.41490.6260.000331511.7557
‑
0.4410.000371607.2588
‑
0.4630.000332512.2363
‑
0.4850.000372607.2968
‑
0.3180.000333512.2555
‑
0.0130.887373608.3000
‑
0.2090.019334513.2753
‑
0.0230.801374609.45500.0420.641335514.04520.1790.045375611.1640
‑
0.1050.245336514.75190.2890.001376611.46900.1460.104337517.1378
‑
0.0500.577377611.4711
‑
0.1870.037338517.39320.2690.002378612.47530.1050.245339519.11710.1430.111379613.48490.1780.047340519.2090
‑
0.2710.002380613.48710.0010.994341519.7403
‑
0.5390.000381614.4900
‑
0.0940.295342520.12000.2390.007382617.4082
‑
0.0910.315343520.3438
‑
0.0880.328383617.42630.5040.000344521.26100.0690.444384618.07190.5610.000345523.12720.5090.000385621.27350.4520.000346524.3749
‑
0.2200.014386623.30300.1130.211347525.36560.6900.000387627.46720.2350.008348529.39220.2350.008388636.42550.4870.000349529.39220.1420.113389638.44230.6040.000350535.2828
‑
0.3050.001390660.42610.5020.000351541.39080.1990.026391666.3033
‑
0.2970.001352545.38720.4830.000392673.33980.3610.000353547.14740.5330.000393686.45320.1310.146354549.3956
‑
0.1940.030394691.40730.2320.009355550.2466
‑
0.5690.000395741.2290
‑
0.6530.000356551.2617
‑
0.5560.000396742.47940.4740.000357551.42650.2560.004397743.4423
‑
0.1630.070358562.7721
‑
0.4360.000398747.43190.4880.000359563.39830.4780.000399748.48190.4330.000360566.16870.3730.000400758.2248
‑
0.0440.628
[0264]
[表a4f]
[0265]
成分编号m/z与产量的相关性rp401759.2281
‑
0.0480.594402771.50900.0450.619403773.2175
‑
0.3870.000404773.5266
‑
0.1890.035405773.52710.1690.059406786.42270.2650.003407796.55580.1520.091408806.54690.2940.001409808.55820.1870.037410811.50140.2000.025411813.51850.1490.098412820.40710.3150.000413824.55370.0780.390414824.56030.1550.084415829.51450.1110.218416840.54900.0410.651417842.56830.1600.074418847.52550.2020.024419923.5063
‑
0.0140.877420923.5066
‑
0.4660.000421943.5349
‑
0.7230.000422945.5359
‑
0.7110.000423969.5500
‑
0.5960.000424970.6150
‑
0.2070.021425973.5566
‑
0.1410.118426975.5749
‑
0.1120.215427986.6112
‑
0.2490.0054281013.5361
‑
0.6630.0004291069.5653
‑
0.4820.0004301073.5610
‑
0.3690.0004311155.5683
‑
0.5460.000
[0266]
根据通过相关解析得到的结果,表示具有一定的相关系数的成分与产量显著地相关。可知相关系数的绝对值|r|>0.51的成分为118个,|r|>0.66的成分为28个。
[0267]
a8.模型构筑
·
评价
[0268]
在使用2个以上的多个成分的分析数据的产量预测模型的构筑中使用多变量分析方法,作为解析工具使用simca ver.14(umetrics)。对于预测模型,进行在解释变量使用了具有各精确质量的已校正的成分的分析数据的峰面积值,并且在目标变量使用了产量值的
回归分析。回归分析通过作为pls法的改良版的opls法进行。
[0269]
预测模型的评价方法主要由两个指标来判断。一个是表示预测精度的r2,另一个是表示预测性的q2。r2是预测模型构筑中使用的数据的实测值与用模型计算出的预测值的相关系数的2次方,越接近1,则表示预测精度越高。另一方面,q2是上述交叉验证的结果,表示实测值与反复实施的模型验证的结果即预测值的相关系数的2次方。从预测的观点出发,只要至少q2>0.50,则该模型具有良好的预测性(triba,m.n.et al.,mol.biosyst.2015,11,13
‑
19.),将q2>0.50作为模型评价的基准。另外,由于通常r2>q2,因此,q2>0.50同时满足r2>0.50。
[0270]
a8
‑
1.使用了431个成分的全部数据的模型的构筑
·
评价
[0271]
每1个数据具有431个成分的分析数据的峰面积值和产量值,由全部125个数据矩阵构筑预测产量的opls模型。在构筑时,各成分的分析数据的峰面积值及产量数据通过自动缩放而变换为平均0、方差1。模型构筑的结果是,表示预测精度的r2=0.87,表示预测性的q2=0.78。将结果在图a1中表示。根据该预测模型示出,通过使用栽培1个月左右的叶中所含的成分组成,能够构筑具有高预测性能的模型,能够进行早期产量预测。
[0272]
a8
‑
2.vip值的算出
[0273]
在8
‑
1中构筑的模型中,给出了被称为vip(variable importance in the projection,投影中的变量重要性)值的各成分所给予的对模型性能的贡献度。vip值的值越大,对模型的贡献度越大,与相关系数的绝对值也越相关。vip值的列表在表a5a~5f中表示。
[0274]
[表a5a]
[0275][0276]
[表a5b]
[0277][0278]
[表a5c]
[0279][0280]
[表a5d]
[0281][0282]
[表a5e]
[0283][0284]
[表a5f]
[0285][0286]
a8
‑
3.机器学习模型
[0287]
预测模型构筑并不限定于opls法,能够通过各种方法来构筑。作为另一例,进行了使用机器学习的预测模型构筑。机器学习是人工智能,即ai的研究课题之一,目前正在进行在各个领域中的应用。
[0288]
在此,使用根据上述8
‑
1中构筑的利用了全部数据的模型算出的vip值前97个成分的分析数据,通过机器学习进行模型构筑。解析工具使用visual mining studio(以下,记载为vms,(株)ntt数据数理系统)。
[0289]
a8
‑3‑
1.使用了全部125个数据的模型构筑
[0290]
每1个数据具有vip值前97个成分的分析数据的峰面积值和产量值,将全部125个数据矩阵输入vms,作为学习数据。在模型构筑中,通过model optimizer功能,从决策树、随机森林、神经网络及支持向量机这4种探索最佳的模型。在模型的计算中,使各模型的参数最佳化,另外,也实施交叉验证,构筑不引起过学习的模型。其结果,在模型中选择了随机森林。实测值与预测值的相关的2次方(r2)为0.92,构筑了精度高的模型。将结果在图a2中表示。
[0291]
a8
‑3‑
2.使用了一半数据的模型构筑和利用剩余一半的预测验证
[0292]
每1个数据具有vip值前97个成分的分析数据的峰面积值和产量值,将全部125个数据矩阵随机分成2组,使用一方的63个矩阵数据通过vms构筑模型,用剩余的62个数据进行预测验证。与8
‑3‑
1同样地,通过model optimizer进行了模型构筑,结果模型选择了神经网络。模型中使用的63个数据的实测值与预测值的相关的2次方为0.83,模型中未使用的62个数据的实测值与预测值的相关的2次方为0.58。验证数据中的预测值与学习数据相比精度降低,但表示可以进行一定的预测。将结果在图a3中表示。
[0293]
a8
‑
4.以vip值为指标的模型构筑(使用了2个以上的成分的分析数据的模型)
[0294]
以各成分对a8
‑
1中构筑的模型的贡献度即vip值的排序(表a4a~4f)为基础,用多个成分构筑模型。虽然没有特别限定,但为了方便起见,将模型性能的基准设为q2>0.50。
[0295]
a8
‑4‑
1.采用了vip值下位的成分的分析数据的模型
[0296]
使用vip值11位以下全部成分的分析数据、21位以下全部成分的分析数据、31位以下全部成分的分析数据
…
及351位以下全部成分的分析数据,分别进行opls模型的构筑。其结果可知,满足q2>0.5的是使用了11位以下全部的成分的分析数据~251位以下全部的成分的分析数据的模型,即使使用vip值261位以下的成分的全部分析数据,也不会q2>0.50(图a4)。
[0297]
a8
‑4‑
2.使用了2个至vip值前10位的成分的分析数据的模型对于vip值第1位至10位的成分的分析数据中的任意2个的组合(45种)进行了opls模型的构筑。其结果可知,在任一模型中均满足q2>0.50。由此表示,如果含有至vip值前10位的代谢物2个,则能够构筑具有一定的预测性的模型(图a5)。
[0298]
a8
‑4‑
3.使用了基于vip值的连续的2个成分的分析数据的模型
[0299]
使用vip值第1位和2位、11位和12位、21位和22位、
…
及201位和202位的成分的分析数据分别进行opls模型的构筑。其结果,在使用31位和32位的2个成分的分析数据时的模型中,首次不满足q2>0.50。其以后q2趋于降低。由此,表示如果是vip值30位左右以上,则从其中使用任意2个成分的分析数据,由此,大致满足q2的基准,但仅是vip值30位左右以下的成分的分析数据2个时不满足基准(图a6)。
[0300]
a8
‑4‑
4.使用了基于vip值的连续的3个成分的分析数据的模型
[0301]
使用vip值第1位和2位和3位、11位和12位和13位、21位和22位和23位、
…
及221位和222位和223位的成分的分析数据分别进行了opls模型的构筑。其结果,在使用71位、72位
和73位的3个成分的分析数据时的模型中,首次不满足q2>0.50。其以后q2趋于降低。由此,暗示了如果是vip值70位左右以上,则通过从其中使用任意3个成分的分析数据从而大致满足q2的基准,但仅是vip值70位左右以下的成分的分析数据3个时不满足基准(图a7)。
[0302]
a8
‑4‑
5.使用了基于vip值的连续的4个成分的分析数据的模型
[0303]
使用vip值第1位和2位和3位和4位、11位和12位和13位和14位、21位和22位和23位和24位、
…
及221位和222位和223位和224位的成分的分析数据分别进行了opls模型的构筑。其结果,在使用101位、102位、103位和104位的4个成分的分析数据时的模型中,首次不满足q2>0.50。其以后q2趋于降低。由此,暗示了如果是vip值100位左右以上,则通过从其中使用任意的4个成分的分析数据,从而大致满足q2的基准,但仅是vip值100位左右以下的成分的分析数据4个时不满足基准(图a8)。
[0304]
a8
‑4‑
6.使用了基于vip值的连续的5个成分的分析数据的模型
[0305]
采用vip值第1位~5位、11位~15位、21位~25位、
…
及251位~255位成分的分析数据分别进行了opls模型的构筑。其结果,在使用了101位~105位的5个成分的分析数据时的模型中,首次不满足q2>0.50。其以后q2趋于降低。由此,暗示了如果是vip值100位左右以上,则通过从其中使用任意的5个成分的分析数据,从而大致满足q2的基准,但仅是vip值100位左右以下的成分的分析数据5个时不满足基准(图a9)。
[0306]
a8
‑4‑
7.使用了基于vip值的连续的6个成分的分析数据的模型
[0307]
采用vip值第1位~6位、11位~16位、21位~26位、
…
及281位~286位成分的分析数据分别进行了opls模型的构筑。其结果,在使用了131位~136位的6个成分的分析数据时的模型中,首次不满足q2>0.50。其以后q2趋于降低。由此,暗示了如果是vip值130位左右以上,则通过从其中使用任意的6个成分的分析数据,从而大致满足q2的基准,但仅是vip值130位左右以下的成分的分析数据6个时不满足基准(图a10)。
[0308]
a8
‑4‑
8.使用了基于vip值的连续的7个成分的分析数据的模型
[0309]
采用vip值第1位~7位、11位~17位、21位~27位、
…
及281位~287位成分的分析数据分别进行了opls模型的构筑。其结果,在使用141位~147位的7个成分的分析数据时的模型中,首次不满足q2>0.50。其以后q2趋于降低。由此,暗示了如果是vip值140位左右以上,则通过从其中使用任意的7个成分的分析数据,从而大致满足q2的基准,但仅是vip值140位左右以下的成分的分析数据7个时不满足基准(图a11)。
[0310]
a8
‑4‑
9.使用了基于vip值的连续的8个成分的分析数据的模型
[0311]
采用vip值第1位~8位、11位~18位、21位~28位、
…
及281位~288位成分的分析数据分别进行了opls模型的构筑。其结果,在使用141位~148位的8个成分的分析数据时的模型中,首次不满足q2>0.50。其以后q2趋于降低。由此,暗示了如果是vip值140位左右以上,则通过从其中使用任意的8个成分的分析数据,从而大致满足q2的基准,但仅是vip值140位左右以下的成分的分析数据8个时不满足基准(图a12)。
[0312]
a8
‑4‑
10.使用了基于vip值的连续的9个成分的分析数据的模型
[0313]
采用vip值第1位~9位、11位~19位、21位~29位、
…
及281位~289位成分的分析数据分别进行了opls模型的构筑。其结果,在使用141位~149位的9个成分的分析数据时的模型中,首次不满足q2>0.50。其以后q2趋于降低。由此,暗示了如果是vip值140位左右以上,则通过从其中使用9个成分的分析数据,从而大致满足q2的基准,但仅是vip值140位左
右以下的成分的分析数据9个时不满足基准(图a13)。
[0314]
a8
‑4‑
11.使用了基于vip值的连续的10个成分的分析数据的模型
[0315]
采用vip值第1位~10位、11位~20位、21位~30位、
…
及281位~290位成分的分析数据分别进行了opls模型的构筑。其结果,在使用161位~170位的10个成分的分析数据时的模型中,首次不满足q2>0.50。其以后q2趋于降低。由此,暗示了如果是vip值160位左右以上,则通过从其中使用任意的10个成分的分析数据,从而大致满足q2的基准,但仅是vip值140位左右以下的成分的分析数据9个时不满足基准(图a14)。
[0316]
a8
‑
5.使用了100个成分的分析数据的预测模型构筑
·
评价
[0317]
考虑上述表a3a~f的全部431个成分峰中的峰的形状、样品间的平均的检测强度等,选择301个峰数据。对于该301个成分峰,代替利用上述的集中qc的峰强度的校正,算出相对于作为内部标准添加的利多卡因的峰面积的各峰面积相对值来进行了校正。使用校正数据,使用上述的解析工具simca,与上述的8
‑
1所记载的方法同样地进行模型构筑。即,每1个数据具有301个成分的分析数据的峰面积值和产量值,从全部125个数据矩阵构筑预测产量的opls模型。算出构筑出的模型的vip值(将vip值的列表在表a6a~6d中表示。),使用前100个成分的分析数据进一步构筑模型,结果能够构筑出表示预测精度的r2=0.82、表示预测性的q2=0.78的精度高的模型(以下,称为“预测模型a”)。将结果在图a15中表示。
[0318]
[表a6a]
[0319][0320]
[表a6b]
[0321][0322]
[表a6c]
[0323][0324]
[表a6d]
[0325][0326]
a9.最适于各田间的施肥及材料的选择
[0327]
a9
‑
1.材料的选择方法
[0328]
在2019年3月8日从作为评价对象的大豆生产预定田间(稻田转化田、水稻
‑
大麦
‑
大豆的2年3茬)采集土壤。在3月18日采集到的田间土10l中添加了作为共同的基肥的最佳匹配(湯上
がり
娘(yuagari musume)专用600,kaneko seeds co.,ltd.)1g(作为混合后的土壤的深度20cm,相当于20kg/10a,与向田间的施用量相同量)。在其中设定包含成为选择候补的下述6种材料单体或它们的组合在内的不同的试验区1~10,添加各材料的推荐量并充分混合后,各1l充填于8个塑料盆中。在各塑料盆中播种大豆种子(品种:里
のほほえみ
(satonohohoemi),山形县产平成30年品,种子尺寸8.5mm以上),在1个缸中各配置2个盆,然后在室内的栽培架(荧光灯下)上开始栽培。需要说明的是,适当地在相同条件下对所有的缸进行供水。
[0329]
播种后4周后的4月17日与上述2所记载的方法同样地实施叶片的采样。将从各缸2个个体采样的叶片混合,作为1个样品,进行上述的4和5所记载的提取
·
分析,获取各样品的成分数据。需要说明的是,选择的材料的候补使用如下。另外,试验区的详细情况在表a7
中表示。
[0330]
·
mix堆肥(川口肥料株式会社)
[0331]
·
天然皂苷粕(琦玉农工几料销售株式会社)
[0332]
·
大豆油渣(the nisshin oillio group,ltd.)
[0333]
·
砂状熔融磷肥(赤城物产株式会社)
[0334]
·
微量元素8(aminol kagaku kenkyu
‑
sho)
[0335]
·
硫酸铵(akagi engei co.,ltd.)
[0336]
[表a7]
[0337]
试验区12345678910最佳匹配(yuagari musume专用600)1111111311mix堆肥09000000009000天然皂苷粕0050000055大豆油渣000100000100砂状熔融磷肥0000400044微量元素80000030033硫酸铵0000000.500.50
[0338]
数字是添加量(单位:g/10l)
[0339]
将获取的成分数据导入上述的模型a,进行产量预测,其结果在图a16中表示。需要说明的是,在图a16中,使用各试验区n=4的数据,以平均值
±
标准偏差表示与作为对照区的试验区1的预测产量差。在施用了mix堆肥的试验区2(单独施用)和9(与含有mix堆肥的其它制剂的混合)中,相对于对照区预测产量较高。因此,选择试验区2和试验区9中共用的mix堆肥作为在田间栽培中使用的材料。
[0340]
a9
‑
2.田间试验中的预测值确认及实测产量结果
[0341]
在作为评价对象的大豆生产预定田间同年实施所选择的材料(mix堆肥)的田间的产量评价试验。在作为播种日的6月25日的播种前,向田间3处(反复3次)施用材料。另外,作为比较对照的未施用区也设定重复3次。需要说明的是,每1处的试验区面积为2m2,与面积相应地施用与室内栽培试验相同量的材料。在播种后1个月后的7月26日进行叶片的采样,与选择试验同样地实施产量预测,研究田间试验的产量预测性是否与室内相同。需要说明的是,关于叶的采样,将各反复中的5个个体混合而成的样品取得2个,3次反复获取共6个样品。将其结果在图a17中表示。需要说明的是,在图a17中表示使用了未施用区及mix堆肥区的n=6的数据的预测产量的平均值
±
标准偏差。
[0342]
田间试验的预测产量在mix堆肥施用区与未施用相比显著(p<0.05,student's t检验)变高,确认了与选择试验同样的结果。
[0343]
在叶的采样以后也继续栽培,在11月12日进行收获。通过上述3所记载的方法获取产量数据。未施用区和mix堆肥区的产量值由从各反复中各收获10个个体的全部30株中除去了产量最大的2株和最小的2株后的26株的值算出。
[0344]
将其结果在图a18中表示。另外,在图a18中表示使用了未施用区和mix堆肥区的n=26的数据的实测产量的平均值
±
标准偏差。
[0345]
在未施用区中为18.7gdw/株,相对于此,在mix堆肥区中成为20.7gdw/株,观测到
10.7%的增收倾向。
[0346]
根据以上的结果表示,通过使用本产量预测模型,在田间栽培前的短时间内选择与当年的该田间相符的材料,通过该材料的施用能够在田间栽培中增收。
[0347]
a10.播种后2周及8周可否产量预测的研究
[0348]
在上述中,在播种后1个月左右实施了产量预测。对更早期(播种后2周)或更晚的时期(播种后8周)的产量预测性进行了以下的研究。
[0349]
本试验从2019年3月在神奈川县内的玻璃房内用盆栽培来实施。盆使用30个1/5000a瓦氏盆,土壤使用国内的田间土在各盆中充填4l。将全部30盆分成施肥量不同的3个试验区a、b及c的各10盆3组,实施栽培。需要说明的是,在肥料中使用magamp k(hyponex japan co.,ltd.),在试验区a中在播种前施用10g/盆,在试验区b中在播种前施用5g/盆并且在试验区c中在播种前施用20g/盆。大豆种子使用enrei,在3月14日进行播种。需要说明的是,在1盆中播种两个种子,在初生叶展开期以成为1株/盆的方式进行间苗。在播种的2周后的4月1日和8周后的5月9日与上述2所记载的方法同样地实施叶片的采样,进行上述4和5所述的提取
·
分析,获取各样品的成分数据。最终的收获在6月27日进行,按照上述3中记载的方法获取每株的产量数据。需要说明的是,从播种后至收获适当进行灌溉。
[0350]
将根据在播种后2周及8周时采样的叶片使用模型a算出的各试验区的预测产量与收获时测得的实测产量进行比较。将结果在图a19中表示。另外,在图a19中,使用试验区a~c的n=10的数据,表示预测产量及实测产量的平均值
±
标准偏差。
[0351]
播种后2周时的预测产量反映了各试验区间的实测产量的差,表示在播种后2周也能够评价产量性。另一方面,在播种后8周中虽然更接近收获期,但未反映各试验区间的实测产量的差。
[0352]
根据这些结果表示,在播种后2~4周等生长初期能够进行更高精度的预测是本产量预测方法的特征。
[0353]
a11.使用了田间数据的产量预测模型构筑
[0354]
a11
‑
1.各田间试验的概要
[0355]
a11
‑1‑
1. 2015年田间试验
[0356]
在枥木县内的生产者田间(稻田转化田、水稻
‑
大麦
‑
大豆的2年3茬)实施栽培。播种前的施肥以成为氮:磷酸:钾=2.4:8:8(kg/10a)的方式实施,进而每10a加入40kg的硅酸钙肥料。品种使用了里
のほほえみ
(satonohohoemi)。在2015年6月15日进行播种。如后所述进行叶的采样,收获在11月1日实施(播种后138天)。需要说明的是,在产量预测用中,从田间3个地点起各9个个体或10个个体进行共计29个个体的采集。
[0357]
a11
‑1‑
2. 2016年田间试验(1)
[0358]
在宫城县实施栽培。播种前的施肥以氮:磷酸:钾=1.5:1.5:1.5(kg/10a)的方式实施。品种使用了enrei。在2016年6月10日进行播种。如后所述进行叶的采样,收获在11月中旬实施。需要说明的是,根据土壤的外观将田地划分为a和b 2个区域,为了产量预测从区域a和区域b分别进行各12个个体共计24个个体的采集。
[0359]
a11
‑1‑
3. 2016年田间试验(2)
[0360]
在枥木县内的生产者田间(稻田转化田、水稻
‑
大麦
‑
大豆的2年3茬,其中,与2015年田间试验不同的田地)实施栽培。播种前的施肥与2015年同样地进行。品种使用了里
のほ
ほえみ
(satonohohoemi)。在2016年6月7日进行播种。如后所述进行叶的采样,收获在11月下旬实施(播种后约160
‑
170天)。需要说明的是,虽然计划为了产量预测用从田地中进行3个地点各10个个体共计30个个体的采集,但在2016年田间,产生大量症青,能够收获产量预测用的是8个个体(30个个体中)。
[0361]
a11
‑1‑
4. 2017年田间试验
[0362]
利用枥木县内的生产者的3块田地(t、ys、ym)实施栽培。播种前的施肥如例年那样实施。品种使用了里
のほほえみ
(satonohohoemi)。在田地t中在2017年6月27日实施播种,在田地ym中在6月29日实施播种,然后在田地ys中在7月7日实施播种。如后述那样进行叶的采样,在田地t中在11月28日实施收获,在田地ym中在11月2日实施收获,并且在田地ys中在11月2日实施收获。需要说明的是,为了产量预测用,从田地中5个地点各采集5个个体,将5个个体汇总作为1个样品。即,进行各田地5个样品(25个个体)的共计15个样品(75个个体)的采集。需要说明的是,在各田地的种植体系中,田地t是水稻
‑
小麦
‑
大豆的2年3茬,在田地ym中是水稻
‑
水稻
‑
小麦
‑
大豆的3年4茬,另外在田地ys中是10年以上的水稻的单作。
[0363]
a11
‑
2.叶的采样
[0364]
与上述2所记载的方法同样地进行叶的采样。各田间试验中的采样时的从播种起的天数及日程如下。
[0365]
*2015年田间试验:2015年7月15日(播种后30天)
[0366]
*2016年田间试验(1):2016年7月21日(播种后41天)
[0367]
*2016年田间试验(2):2016年7月6日(播种后29天)
[0368]
*2017年田间试验_田地t:2017年7月28日(播种后31天)
[0369]
*2017年田间试验_田地ym:2017年7月31日(播种后32天)
[0370]
*2017年田间试验_田地ys:2017年8月7日(播种后31天)
[0371]
a11
‑
3.预测模型构筑
[0372]
对在2015
‑
2017年实施的田间试验中得到的共计76个叶样品进行上述的4和5所记载的提取
·
分析,获取各样品的分析数据。这些数据进行上述6所记载的解析,与盆试验数据同样地对各样品得到431个成分的分析数据。预测模型构筑中使用的实测产量值使用各田地的每个(其中,2016年田间试验(1)分成区域a及区域b)的平均值。各田地的平均产量值如表a8所示,最小为10.27gdw/个体,最大为27.66gdw/个体。
[0373]
[表a8]
[0374]
试验名称试验区/田地区别名样品数品种平均产量(gdw/株)2015年田间试验无29satonohohoemi20.392016年田间试验(1)区域a12enrei21.64 区域b12enrei16.042016年田间试验(2)无8satonohohoemi10.272017年田间试验t5satonohohoemi27.66 ym5satonohohoemi23.98 ys5satonohohoemi27.26
[0375]
根据这些结果,使用上述的解析工具simca构筑了预测各田地每个的产量的opls模型。模型构筑的结果,表示预测精度的r2=0.86,表示预测性的q2=0.76。将结果在图a20
中表示。
[0376]
由该预测模型示出,通过使用栽培1个月左右的叶中含有的成分组成,在田间采集的样品中也能够构筑具有高的预测性能的模型,可以进行早期产量预测。
[0377]
<使用了2
‑
羟基吡啶、胆碱、柠檬酸、甘油酸、甘氨酸、l
‑
焦谷氨酸、丙二酸、蔗糖及苏糖醇的9个成分的评价>
[0378]
b1.采集的叶的成分的提取
[0379]
对于表a2a~2c所示的125株的冷冻干燥后的叶样品,使用刮刀通过手工操作尽可能地进行粉碎。粉碎后,在2ml的管(safe
‑
lock管、eppendorf)中称量10mg,将直径5mm的氧化锆制球1个加入管中,用珠式粉碎机(mm400,retsch)以25hz进一步进行粉碎1分钟。向其中加入甲醇(hplc级,关东化学)、纯水(milliq,merk millipore)、氯仿(特级、关东化学)的混合溶剂(5:2:2,v/v/v)1ml,在37℃下进行30分钟提取。提取后,用2000
×
g左右的台式离心机(chibitan)进行5分钟离心分离,与固体物分离。离心分离后,将上清液600μl分注到1.5ml管中,向其中添加纯水300μl。使用涡旋进行混合后,再次进行5分钟离心分离。将离心后的上清液400μl重新分注于1.5ml管中。数据的质量检查和保持时间的校正中使用的qc样品是从离心分离后的各样品中与400μl分开收集各200μl,然后将400μl分注到另外的1.5ml管中。将残留于各样品的甲醇以speedvac(sc
‑
210a,thermo scientific)进行10分钟浓缩。浓缩后,用液氮冻结残留的水分,进行一夜冷冻干燥。
[0380]
b2.衍生化
[0381]
向b1中得到的提取物中,添加5μl的肉豆蔻酸
‑
d
27
(cambridge isotope laboratories)的吡啶溶液(50μg/ml)作为内部标准(后述的库对照用)。另外,作为其它的内部标准(样品间的峰强度校正),添加了5μl的核糖醇(东京化成工业)的吡啶溶液(50μg/ml)。另外,添加100μl甲氧基胺盐酸盐的吡啶溶液(20mg/ml),在37℃下进行90分钟孵育(第一衍生化“甲基肟化”)。孵育后,用台式离心机与不溶物分离后,将上清液50μl分注至小玻璃瓶中。接着,使用搭载于gc系统的自动进样器(agilent 7693)的自动分注器,进行了第二衍生化。在加入了甲基肟化后的吡啶溶液的小瓶中,以在分析前自动添加50μl的n
‑
甲基
‑
n
‑
(三甲基甲硅烷基)三氟乙酰胺(mstfa:thermo scientific)的方式编程,在加热部分以37℃孵育30分钟后(第二衍生化“甲硅烷基化”),直接进行gc
‑
ms分析。需要说明的是,溶剂中使用的吡啶使用脱水吡啶(关东化学)。
[0382]
b3.gc
‑
ms分析
[0383]
将b2中得到的1μl的分析样品以分流模式注入gc
‑
ms(10:1,v/v)。gc
‑
ms装置使用将agilent 7890b gc系统(agilent)、单四极杆分析仪agilent 5977b gc/msd(agilent)及agilent 7693a自动进样器(agilent)连结而成的装置。在该系统中安装在具有0.25μm的膜厚的30m的分析柱中组装有10m的保护柱的40m
×
0.25mm i.d的熔融石英毛细管柱(zorbax db5
‑
ms+10m duragard capillary column,122
‑
5532g,agilent)来使用。注入温度设为250℃,通过柱的氦气的流速设定为0.7ml/min。柱温度在60℃下保持等温1分钟,接着以10℃/分钟上升至325℃,然后保持等温10分钟。输送线和离子源温度分别为300℃及230℃。通过(70.0kv)电子冲击(ei)生成离子后,在m/z 50
‑
600的质量范围内每1秒进行2.7次扫描记录数据。加速电压在5.9分钟的溶剂延迟后使其工作。
[0384]
需要说明的是,qc样品在样品的分析样品的每5
‑
6次分析中加入1个。
[0385]
b4.数据矩阵的制作
[0386]
由gc
‑
ms获取的数据转换为netcdf文件格式,用作为峰检测及对准软件的metalign(wageningen univ.)制作了数据矩阵。在样品间的各峰的保持时间和峰强度的校正中,另外以作为内部标准添加的核糖醇为指标进行。
[0387]
最终,以csv格式制作数据矩阵。向其中合并各大豆样品的产量值,用于数据解析。
[0388]
b5.峰鉴定
[0389]
通过gc
‑
ms分析得到的分析数据,以作为内部标准物质添加的肉豆蔻酸d27的保持时间为基准,使用agilent公司制造的fiehn代谢学rtl库(以下,fiehn库)进行峰鉴定。峰鉴定的基准是从基于fiehn库的光谱一致率为70%以上的候补代谢物中保持时间的误差为0.05分钟以内。
[0390]
b6.与产量相关的候补成分的探索
[0391]
使用2016年数据进行与产量相关的候补成分的探索。使用表b1所示的20个样品,使用来源于叶中成分的峰和与各样品对应的产量数据的矩阵数据进行解析。通过保持时间对来自认为相同的成分的峰进行整理
·
去除重复后,进行来源于各成分的峰数据与产量的相关分析。
[0392]
[表b1]
[0393]
样品名称年度品种干燥籽粒重量(g/个体)kg22016satonohohoemi32.97kg42016satonohohoemi23.1kg62016satonohohoemi24.87kg82016satonohohoemi28.42mg22016satonohohoemi35.39mg42016satonohohoemi32.21mg52016satonohohoemi26.97mg62016satonohohoemi29.61mg72016satonohohoemi26.8mg92016satonohohoemi34.75tc12016satonohohoemi22.87tc42016satonohohoemi21.94tc52016satonohohoemi21.06tc122016satonohohoemi25.77tc152016satonohohoemi16.52wk12016satonohohoemi37.08wk32016satonohohoemi31.91wk42016satonohohoemi31.74wk62016satonohohoemi42.53wk92016satonohohoemi29
[0394]
在各峰数据与产量的相关分析中,通过单相关系数r和无相关的检验计算出p值。另外,通过根据来源于各成分的峰信息(保持时间、质量信息)与fiehn库进行对照,选择9种
成分,即2
‑
羟基吡啶、胆碱、柠檬酸、甘油酸、甘氨酸、l
‑
焦谷氨酸、丙二酸、蔗糖及苏糖醇作为鉴定为与产量相关的成分的候补。使用选择出的9种成分,还包含剩余的样品,进行2015
‑
2017年的全部样品125个样品的分析。
[0395]
首先,使用全部分析数据,进行各成分相对量与产量的相关分析。
[0396]
在现有技术中,报道了使用大豆的生长过程中的指标,分析了与产量的相关性的研究。例如,在非专利文献(“基于重粘土地带的大豆“enrei”的高产案例的产量构成要素和生长指标”新泻农总研)中,表示播种后40天的主茎长度与产量相关,其相关系数r为0.51,另外,在非专利文献6(“利用土壤物理化学性的改善得到的小麦微量种植地带中的大豆高产栽培体系的建立”福井县农试、福井县大)中,表示播种后50
‑
60天的根粒活性与产量相关,其相关系数为0.63,进而在另一报告(“从物质生产和氮的蓄积中观察到的大豆的高产生长相”福井县农试)中,表示播种后60
‑
70日的地上部分干物重与产量相关,其相关系数为0.66。这些见解表示通过以上述的播种后天数来评价特定的指标,可以进行一定的产量预测。但是,本技术中的播种后30天左右的预测时期均早于现有技术,因此,可以说至少来源于相关系数的绝对值大于0.51的成分的峰是比现有技术优异的产量预测指标。
[0397]
分析的结果,9种成分与产量的相关如表b2所示,作为相关系数的绝对值超过0.51的成分,发现有2
‑
羟基吡啶、甘氨酸、l
‑
焦谷氨酸及蔗糖这4种。
[0398]
[表b2]
[0399]
成分与产量的相关性rp2
‑
羟基吡啶
‑
0.520.000胆碱0.010.945柠檬酸
‑
0.380.000甘油酸
‑
0.100.288甘氨酸
‑
0.580.000l
‑
焦谷氨酸
‑
0.570.000丙二酸0.410.000蔗糖0.570.000苏糖醇
‑
0.230.011
[0400]
b7.模型构筑
·
评价
[0401]
在使用了2个以上的多个成分的分析数据的产量预测模型的构筑中使用多变量分析方法,作为解析工具使用simca ver.14(umetrics)。预测模型进行在解释变量使用了各成分的分析数据的峰面积值,并且在目标变量使用了产量值的回归分析。回归分析通过作为pls法的改良版的opls法进行。
[0402]
预测模型的评价方法主要由两个指标来判断。1个是表示预测精度的r2,另一个是表示预测性的q2。r2是预测模型构筑中使用的数据的实测值与用模型计算出的预测值的相关系数的2次方,越接近1,则表示预测精度越高。另一方面,q2是上述交叉验证的结果,表示实测值与反复实施的模型验证的结果即预测值的相关系数的2次方。从预测的观点出发,如果至少q2>0.50,则该模型具有良好的预测性(triba,m.n.et al.,mol.biosyst.2015,11,13
‑
19.),因此,将q2>0.50作为模型评价的基准。需要说明的是,由于通常r2>q2,因此,q2>0.50同时满足r2>0.50。
[0403]
b8
‑
1.使用了全部数据的模型的构筑
·
评价
[0404]
每1个数据具有9个成分的相对量和产量值,从全部125个数据矩阵构筑预测产量的opls模型。构筑时,来源于各成分的峰和产量数据通过自动缩放转化为平均0、方差1。模型构筑的结果是,表示预测精度的r2=0.56,表示预测性的q2=0.55。将结果在图b1中表示。作为模型的预测性能的基准满足设定的q2>0.50。根据该预测模型,通过使用栽培1个月左右的叶中含有的成分组成,能够构筑具有一定的预测性能的模型,可以进行早期产量预测。
[0405]
b8
‑
2.vip值的计算
[0406]
在b8
‑
1中构筑的模型中,给出被称为vip(variable importance in the projection,投影中的变量重要性)值的来源于各成分的峰所赋予的对模型性能的贡献度。vip值的值越大,则对模型的贡献度越大,与相关系数的绝对值也越相关。将vip值的列表在表b3中表示。
[0407]
[表b3]
[0408]
成分vip值vip值排序l
‑
焦谷氨酸1.441甘氨酸1.3522
‑
羟基吡啶1.243蔗糖1.204丙二酸0.985柠檬酸0.926苏糖醇0.507甘油酸0.268胆碱0.119
[0409]
b8
‑
3.以vip值为指标的模型构筑(使用了2个以上的成分峰信息的模型)
[0410]
以来源于各成分的峰对b8
‑
1中构筑的模型的贡献度即vip值的排序(b8
‑
2)为基础,通过多个成分构筑模型。虽然没有特别限定,但为了方便起见,将模型性能的基准设为q2>0.50。
[0411]
b8
‑3‑
1.使用了来源于vip值下位的成分的峰的模型
[0412]
使用vip值1位以下、2位以下、3位以下、4位以下、5位以下及6位以下的全部成分数据分别进行了opls模型的构筑。其结果可知,满足q2>0.50的是使用了vip值1位以下全部~3位以下全部的成分数据的模型,即使使用vip值4位以下的全部成分数据,也不会q2>0.50(图b2)。
[0413]
b8
‑3‑
2.使用了多个vip值上位的成分数据的模型
[0414]
从vip值上位开始依次使用多个成分数据,即vip值1位和2位、vip值1位~3位和vip值1位~4位的成分数据进行opls模型的构筑。其结果可知,在前3个成分时,不满足q2>0.50,通过使用至前4位,满足q2>0.50。由此,暗示了在模型构筑的情况下,至少需要从9个中使用4个以上的成分数据(图b3)。
[0415]
即,判断在使用从9个成分数据中选择的任意4个以上的成分数据构筑的模型中,满足q2>0.50的模型具有预测性。具体而言,可以举出以下的模型。
[0416]
1)使用了从vip值上位依次连续的4个成分数据的模型
[0417]
使用vip值第1位~4位、2位~5位、3位~6位、4位~7位、5位~8位及6位~9位的成分数据,分别进行opls模型的构筑。其结果,在使用vip值4位~7位的成分数据时的模型中,首次不满足q2>0.50。其以后q2趋于降低。由此,暗示了如果是vip值6位以上,则通过从其中使用任意的4个成分数据,从而大致满足q2的基准,但仅从vip值4位以下中选择的任意的4个成分数据时不满足基准(图b4)。
[0418]
2)使用了从vip值上位依次连续的5个成分数据的模型
[0419]
使用vip值第1位~5位、2位~6位、3位~7位、4位~8位和5位~9位的成分数据分别进行opls模型的构筑。其结果,在使用vip值4位~8位的成分数据时的模型中,首次不满足q2>0.50。其以后q2趋于降低。由此,暗示了如果是vip值7位以上,则从其中使用任意的5个成分数据,由此,大致满足q2的基准,但仅从vip值4位以下中选择的任意5个成分数据时不满足基准(图b5)。
[0420]
3)使用了从vip值上位依次连续的6个成分数据的模型
[0421]
使用vip值第1位~6位、2位~7位、3位~8位和4位~9位的成分数据,分别进行opls模型的构筑。其结果,在使用vip值4位~9位的成分数据时的模型中,首次不满足q2>0.50。由此,可知如果是vip值8位以上,则从其中使用任意的6个成分数据,由此,大致满足q2的基准,但仅从vip值4位以下选择的任意的6个成分数据、即4位以下全部时不满足基准(图b6、图b2)。
[0422]
4)使用了从vip值上位依次连续的7个成分数据的模型
[0423]
使用vip值第1位~7位、2位~8位及3位~9位的成分数据,分别进行opls模型的构筑。其结果,在全部的模型中满足q2>0.50。由此,可知通过使用9个成分数据中的任意7个以上的成分数据,大致满足q2的基准(图b7)。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1