一种确定地层流体饱和度的方法、装置及设备
1.本技术涉及油气勘探技术领域,特别涉及一种确定地层流体饱和度的方法、装置及设备。
背景技术:
2.页岩油作为一种重要的非常规油气资源,已成为近年来油气勘探开发的热点。在页岩的储层评价中,准确求取不同流体的饱和度对于确定储层质量、确定射孔位置等非常重要。然而,在非常规储层中,地层孔隙度低、孔隙结构复杂以及流体类型复杂等原因,导致不同流体在反演t1‑
t2谱上的分辨率低,只能定性识别流体,无法满足定量评价流体的要求。
3.现有技术中主要通过三类方法解决在t1‑
t2谱上定量评价流体难的问题。其中,第一种方法是基于nmr(nuclear magnetic resonance,核磁共振)实验方法,其通过区域划分的方式得到不同流体的饱和度信息,由于这种方法的精度有限,在区域划分时容易受到人工影响,使得利用这种方式求取的流体饱和度不准确。第二种方法是人工智能聚类的方法,其通过对t1‑
t2谱上的信号进行聚类来表征不同的流体信号,这种方法只能定性判断流体的存在,无法定量得到不同流体的饱和度。第三种方法是基于统计学的方法,其首先需要通过传统pca(principal component analysis)方法确定地层中流体类型个数,然而传统pca方法受流体饱和度分布范围和反演nmr谱质量的影响,会使确定的流体类型个数存在误差,并且,通过统计学的方法得到不同流体在t1‑
t2谱上的特征,当地层中流体饱和度分布范围小时,此类方法效果一般,求取的流体饱和度不准确。
4.因此,业内亟需一种可以解决上述问题的技术方案。
技术实现要素:
5.本说明书实施例提供了一种确定地层流体饱和度的方法、装置及设备,可以更加准确地确定不同流体类型饱和度,解决在非常规储层中,由于地层孔隙度低、孔隙结构复杂、赋存孔隙中的流体类型复杂等原因,导致不同流体在反演t1‑
t2谱上的分辨率低,利用nmr测井定量求取地层中不同流体饱和度困难的问题。
6.本说明书提供的一种确定地层流体饱和度的方法、装置及设备是包括以下方式实现的。
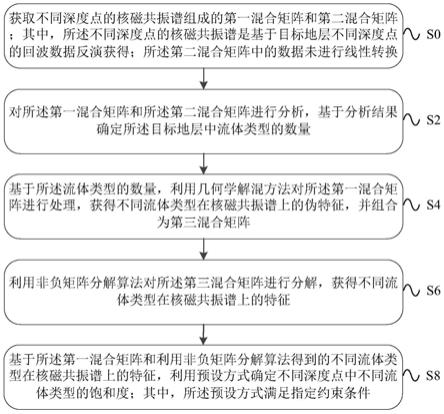
7.一种确定地层流体饱和度的方法,包括:获取不同深度点的核磁共振谱组成的第一混合矩阵和第二混合矩阵;其中,所述不同深度点的核磁共振谱是基于目标地层不同深度点的回波数据反演获得;所述第二混合矩阵中的数据未进行线性转换;对所述第一混合矩阵和所述第二混合矩阵进行分析,基于分析结果确定所述目标地层中流体类型的数量;基于所述流体类型的数量,利用几何学解混方法对所述第一混合矩阵进行处理,获得不同流体类型在核磁共振谱上的伪特征,并组合为第三混合矩阵;利用非负矩阵分解算法对所述第三混合矩阵进行分解,获得不同流体类型在核磁共振谱上的特征;基于所述第一混合矩阵和利用非负矩阵分解算法得到的不同流体类型在核磁共振谱上的特征,利用预设方式
确定不同深度点中不同流体类型的饱和度;其中,所述预设方式满足指定约束条件。
8.一种确定地层流体饱和度的装置,包括:获取模块,用于获取不同深度点的核磁共振谱组成的第一混合矩阵和第二混合矩阵;其中,所述不同深度点的核磁共振谱是基于目标地层不同深度点的回波数据反演获得;所述第二混合矩阵中的数据未进行线性转换;分析模块,用于对所述第一混合矩阵和所述第二混合矩阵进行分析,基于分析结果确定所述目标地层中流体类型的数量;获得模块,用于基于所述流体类型的数量,利用几何学解混方法对所述第一混合矩阵进行处理,获得不同流体类型在核磁共振谱上的伪特征,并组合为第三混合矩阵;分解模块,用于利用非负矩阵分解算法对所述第三混合矩阵进行分解,获得不同流体类型在核磁共振谱上的特征;确定模块,用于基于所述第一混合矩阵和利用非负矩阵分解算法得到的不同流体类型在核磁共振谱上的特征,利用预设方式确定不同深度点中不同流体类型的饱和度;其中,所述预设方式满足指定约束条件。
9.一种确定地层流体饱和度的设备,包括处理器及用于存储可执行指令的存储器,所述处理器执行所述指令时实现本说明书实施例中任意一个方法实施例的步骤。
10.本说明书提供的一种确定地层流体饱和度的方法、装置及设备。一些实施例中通过将不同深度点的多维核磁共振回波数据反演得到的nmr谱组合为混合矩阵,对混合矩阵进行小波pca、2dpca、非负矩阵分解以及全约束最小二乘方法,可以更加准确地、更加快速确定不同流体类型饱和度,从而可以有效解决在非常规储层中,地层孔隙度低、孔隙结构复杂以及赋存孔隙中的流体类型复杂等原因导致利用nmr测井定量求取不同流体饱和度困难的问题。采用本说明书提供的实施方案,可以更加准确地确定不同流体类型饱和度。
附图说明
11.此处所说明的附图用来提供对本说明书的进一步理解,构成本说明书的一部分,并不构成对本说明书的限定。在附图中:
12.图1为本说明书实施例提供的一种确定地层流体饱和度的方法的流程示意图;
13.图2为对第一混合矩阵进行小波分解的示意图;
14.图3为分别利用pca、dwpca、2dpca获得的流体类型个数与贡献量的关系示意图;
15.图4为利用pca方法获得的在不同信噪比下不同流体分布范围数据的流体类型个数与累积贡献量的关系示意图;
16.图5为不同信噪比下不同流体分布范围数据的dwpca的流体类型个数与贡献量和2dpca的流体类型个数与贡献量的差值示意图;
17.图6为t1‑
t2测井中四种流体类型的t1‑
t2谱模型;
18.图7为窄饱和度范围内四种流体类型的饱和度信息;
19.图8为宽饱和度范围内四种流体类型的饱和度信息;
20.图9为三个具有不同流体饱和度的地层的t1‑
t2谱模型、信噪比为15的回波数据、信噪比为15的回波数据的反演结果、信噪比为30的回波数据以及信噪比为30的回波数据的反演结果;
21.图10为窄饱和度范围内信噪比为15时利用ppi方法提取的流体特征分布;
22.图11为窄饱和度范围内信噪比为15时利用vca方法提取的流体特征分布;
23.图12为窄饱和度范围内信噪比为15时利用n
‑
findr方法提取的流体特征分布;
24.图13为窄饱和度范围内信噪比为15时利用nmf方法提取的流体特征分布;
25.图14为窄饱和度范围内信噪比为15时利用本技术方法提取的流体特征分布;
26.图15为窄饱和度范围内信噪比为15时,利用vca方法求取的流体特征分布通过全约束最小二乘方法求取的饱和度;
27.图16为窄饱和度范围内信噪比为15时,利用n
‑
findr方法求取的流体特征分布通过全约束最小二乘方法求取的饱和度;
28.图17为窄饱和度范围内信噪比为15时,利用nmf方法求取的流体特征分布通过饱和度物理意义求取的饱和度;
29.图18为窄饱和度范围内信噪比为15时,利用nmf方法求取的流体特征分布通过全约束最小二乘方法求取的饱和度;
30.图19为窄饱和度范围内信噪比为15时,利用本技术方法求取的流体特征分布通过全约束最小二乘方法求取的饱和度;
31.图20为本说明书实施例提供的一种确定地层流体饱和度的装置的模块结构示意图;
32.图21为本说明书实施例提供的一种确定地层流体饱和度的服务器的硬件结构框图。
具体实施方式
33.为了使本技术领域的人员更好地理解本说明书中的技术方案,下面将结合本说明书实施例中的附图,对本说明书实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本说明书中的一部分实施例,而不是全部的实施例。基于本说明书中的一个或多个实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都应当属于本说明书实施例保护的范围。
34.下面以一个具体的应用场景为例对本说明书实施方案进行说明。具体的,图1为本说明书实施例提供的一种确定地层流体饱和度的方法的流程示意图。虽然本说明书提供了如下述实施例或附图所示的方法操作步骤或装置结构,但基于常规或者无需创造性的劳动在所述方法或装置中可以包括更多或者部分合并后更少的操作步骤或模块单元。
35.本说明书提供的一种实施方案可以应用到客户端、服务器等中。所述客户端可以包括终端设备,如智能手机、平板电脑等。所述服务器可以包括单台计算机设备,也可以包括多个服务器组成的服务器集群,或者分布式系统的服务器结构等。
36.需要说明的是,下述实施例描述并不对基于本说明书的其他可扩展到的应用场景中的技术方案构成限制。具体的一种实施例如图1所示,本说明书提供的一种确定地层流体饱和度的方法的一种实施例中,所述方法可以包括以下步骤。
37.s0:获取不同深度点的核磁共振谱组成的第一混合矩阵和第二混合矩阵;其中,所述不同深度点的核磁共振谱是基于目标地层不同深度点的回波数据反演获得;所述第二混合矩阵中的数据未进行线性转换。
38.其中,第一混合矩阵表示对每个深度点的核磁共振谱进行线性转换后组成的矩阵。第二混合矩阵表示直接由每个深度点的核磁共振谱组成的矩阵。第一混合矩阵中的数据是经过转换后的数据。第二混合矩阵中的数据是未经过数据转化的数据,第二混合矩阵
中数据保留了流体特征的空间信息。
39.一些实施例中,可以先获取不同深度点的多维核磁共振回波数据,然后将不同深度点的多维核磁共振回波数据进行反演得到不同深度点的核磁共振谱(以下记为nmr谱)。其中,回波数据可以包括nmr测井采集的数据和实验室中nmr仪器测量的数据。
40.一些实施场景中,每个深度点的nmr谱大小可以表示为n1
×
n2的矩阵形式,其中n1、n2为nmr谱中两个坐标的布点个数。例如,t1‑
t2测井中,n1为t1的布点个数,n2为t2布点个数。
41.一些实施例中,在获得不同深度点的nmr谱后,可以将不同深度点的nmr谱组合为混合矩阵。
42.由于几何学解混方法或者非负矩阵分解时处理的对象是线性数据,而nmr谱是二维数据,因此为了方便后续处理,可以将每个深度点的nmr谱进行转换。例如一些实施场景中,在将不同深度点的nmr谱组合为混合矩阵前,可以对每个深度点的nmr谱进行线性转换,然后根据转换后的数据生成第一混合矩阵。例如,可以将每个深度点的nmr谱对应的n1
×
n2矩阵转换为1
×
n的矩阵,然后将每个深度点对应的1
×
n矩阵组合为m
×
n的混合矩阵a,其中,n为n1与n2的乘积,m为地层深度点个数,m
×
n表示混合矩阵的大小。
43.一些实施场景中,在获得不同深度点的nmr谱后,可以不进行线性转换,直接将每个深度点的nmr谱进行组合,生成第二混合矩阵。例如,可以将每个深度点的nmr谱对应的n1
×
n2矩阵直接进行组合,生成混合矩阵b。其中,混合矩阵b的大小为m
×
n1
×
n2。
44.本说明书实施例中,通过将不同深度点的核磁共振谱组合成混合矩阵a和混合矩阵b,可以为后续确定地层中流体类型的数量、获得不同流体类型在核磁共振谱上的特征提供基础。
45.s2:对所述第一混合矩阵和所述第二混合矩阵进行分析,基于分析结果确定所述目标地层中流体类型的数量。
46.本说明书实施例中,在获取不同深度点的核磁共振谱组成的第一混合矩阵和第二混合矩阵后,可以对第一混合矩阵和第二混合矩阵进行分析,基于分析结果确定目标地层中流体类型的数量。其中,流体类型可以包括沥青、黏土束缚水、oil in op、water in ip等。其中,oil in op表示有机孔中油,water in ip表示无机孔中水。
47.一些实施例中,所述对所述第一混合矩阵和所述第二混合矩阵进行分析,基于分析结果确定所述目标地层中流体类型的数量,可以包括:利用小波pca算法对所述第一混合矩阵进行分析,获得第一分析结果;其中,所述第一分析结果表示流体类型个数与贡献量的第一关系;利用2dpca算法对所述第二混合矩阵进行分析,获得第二分析结果;其中,所述第二分析结果表示流体类型个数与贡献量的第二关系;根据所述第一分析结果和所述第二分析结果,确定所述目标地层中流体类型的数量。
48.一些实施场景中,所述利用小波pca算法对所述第一混合矩阵进行分析,获得第一分析结果,可以包括:对所述第一混合矩阵进行小波分解,获得小波近似系数和小波细节系数;对所述小波细节系数进行软阈值处理,获得处理后的小波细节系数;基于所述小波近似系数和所述处理后的小波细节系数,重构所述第一混合矩阵对应的小波处理数据;对所述小波处理数据进行主成分分析,获得第一分析结果。
49.例如一些实施场景中,第一混合矩阵记为维度为m
×
n,流体类型个数与贡献量
的第一关系记为c1,则利用小波pca算法对进行分析获得c1的过程可以包括如下步骤。其中,本实施例中使用的小波基函数为harr小波函数,分解尺度为3。
50.(1)对进行小波分解,获得小波近似系数和小波细节系数。
51.具体的,对进行二维小波变换1层分解,得到小波近似系数和小波细节系数如下:
[0052][0053][0054][0055][0056]
其中,ψ为小波基函数,φ为正交尺度函数,b1为1层分解后的小波近似系数,h1为1层分解后的水平方向(horizontal direction)的细节系数,v1为1层分解后的垂直方向(vertical direction)的细节系数,d1为1层分解后的对角线方向(horizontal direction)的细节系数,x1为横坐标序号,x2为坐标轴序号,为横坐标为x1、纵坐标为x2的的值,为分解尺度为1、平移参数为k1沿x1方向的正交尺度函数,为分解尺度为1、平移参数为k2沿x2方向的正交尺度函数,为分解尺度为1、平移参数为k1沿x1方向的小波基函数,为分解尺度为1、平移参数为k2沿x2方向的小波基函数。
[0057]
当进行k层分解时,即对k
‑
1层的小波近似系数b
k
‑1进行二维小波变换1层分解,分别得到k层分解的小波近似系数b
k
和水平方向的细节系数h
k
、垂直方向的细节系数v
k
、对角线方向的细节系数d
k
。具体分解过程如图2所示,其中,从左到右依次为原始数据经过1层小波分解的结果、经过2层小波分解的结果和经过3层小波分解的结果。
[0058]
经过k层分解后,可以得到第k层的小波近似系数和第1层到第k层的小波细节系数。
[0059]
(2)对小波细节系数进行软阈值处理,获得处理后的小波细节系数。
[0060]
例如,小波细节系数包括h1、v1、d1、h2、v2、d2和h3、v3、d3,则可以对小波细节系数进行软阈值处理,获得处理后的小波细节系数。其中,对小波细节系数进行软阀值处理可以对数据进行降噪。
[0061]
(3)利用小波近似系数和处理后的小波细节系数重构得到小波变换后的数据。
[0062]
其中,小波变换后的数据可以记为维度为m
×
n。
[0063]
(4)对进行主成分分析,获得c1。
[0064]
其中,主成分分析(principal component analysis,pca)是一种统计方法,其通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。
[0065]
具体的,对进行主成分分析时,可以按照下述方式求取的均值m和协方差矩阵cov1:
[0066][0067][0068]
进一步,可以计算协方差矩阵cov1的特征值ev1和特征向量ef1,并将特征值ev1归一化,得到流体类型个数与贡献量的关系c1。
[0069]
本说明书实施例中,在对第一混合矩阵进行小波分解后,通过对小波细节系数进行软阈值处理,基于小波近似系数和处理后的小波细节系数重构第一混合矩阵对应的小波处理数据,可以降低第一混合矩阵中包括的噪声数据,从而为后续准确确定目标地层中流程类型数量提供保证。
[0070]
一些实施场景中,所述利用2dpca算法对所述第二混合矩阵进行分析,获得第二分析结果时,可以记第二混合矩阵记为x,x的维度为m
×
n1
×
n2。流体类型个数与贡献量的第二关系记为c2,利用2dpca对x进行分析,获得c2过程为:首先基于m3=mean(x)求取x的均值m3,然后基于m3和求取协方差矩阵cov2,最后计算协方差矩阵cov2的特征值ev2和特征向量ef2,并将特征值ev2归一化,得到流体类型个数与贡献量的关系c2。其中,2dpca是一种对二维数据进行主成分分析的一种方法,该方法无需将二维数据进行线性转换。
[0071]
一些实施例中,在获得第一分析结果和第二分析结果后,可以基于第一分析结果和第二分析结果确定目标地层中流体类型的数量。
[0072]
一些实施场景中,所述根据所述第一分析结果和所述第二分析结果,确定所述目标地层中流体类型的数量,可以包括:根据所述第一分析结果和所述第二分析结果中相同流体类型个数对应的贡献量,确定流体类型个数与dwpca的流体类型个数与贡献量和2dpca的流体类型个数与贡献量的差值的关系;基于流体类型个数与上述两者贡献量差值的关系,确定贡献量差值满足预设条件时所对应的流体类型个数;将所述贡献量差值满足预设条件时所对应的流体类型个数作为所述目标地层中流体类型的数量。其中,dwpca表示小波pca算法。
[0073]
一些实施场景中,上述预设条件可以为贡献量差值最先接近0时。相应的,可以当贡献量差值首先接近0时对应的流体类型个数作为所述目标地层中流体类型的数量。当然,上述只是进行示例性说明,预设条件不限于上述举例,所属领域技术人员在本技术技术精髓的启示下,还可能做出其它变更,但只要其实现的功能和效果与本技术相同或相似,均应涵盖于本技术保护范围内。
[0074]
如图3所示,图3为分别利用pca、dwpca、2dpca获得的流体类型个数与贡献量的关系示意图,其中,dwpca表示小波pca算法,横坐标表示流体类型个数,纵坐标表示贡献量。
[0075]
由于不同信噪比下不同饱和度分布范围的数据中,通过传统pca方法求取的累积贡献量的阈值难以选取,很多情况下不能找到一个明显的折点来判断地层中流体类型个数。如图4所示,图4为利用pca方法获得的在不同信噪比下不同流体分布范围数据的流体类型个数与累积贡献量的关系示意图,其中,横坐标表示流体类型个数,纵坐标表示累积贡献量,按照从上到下、从左到右的顺序依次对应信噪比为15时在宽饱和度范围数据、信噪比为15时在窄饱和度范围数据、信噪比为30时在宽饱和度范围数据、信噪比为30时在窄饱和度
范围数据。所以本说明书实施例中利用dwpca贡献量和2dpca贡献量的差值δc进行判断。由于后面无关的特征值相差较小,这样可以当两者差值出现小的值时对应的流体类型个数作为目标地层中流体类型的数量。如图5所示,图5为不同信噪比下不同流体分布范围数据的dwpca的流体类型个数与贡献量和2dpca的流体类型个数与贡献量的差值示意图,其中,差值为dwpca贡献量和2dpca贡献量的差值,横坐标表示流体类型个数,纵坐标表示贡献量差值,按照从上到下、从左到右的顺序依次表示信噪比为15时在宽饱和度范围数据的差值、信噪比为15时在窄饱和度范围数据的差值、信噪比为30时在宽饱和度范围数据的差值、信噪比为30时在窄饱和度范围数据的差值。由图5可知,贡献量差值首先接近0时对应的流体类型个数为4,因此可以确定目标地层中流体类型的数量为4。
[0076]
s4:基于所述流体类型的数量,利用几何学解混方法对所述第一混合矩阵进行处理,获得不同流体类型在核磁共振谱上的伪特征,并组合为第三混合矩阵。
[0077]
本说明书实施例中,在确定目标地层中流体类型的数量后,可以基于流体类型的数量,利用几何学解混方法对第一混合矩阵进行处理,获取不同流体在核磁共振谱上的伪特征,并组合为第三混合矩阵。
[0078]
一些实施例中,所述基于所述流体类型的数量,利用几何学解混方法对所述第一混合矩阵进行处理,获得不同流体类型在核磁共振谱上的伪特征,并组合为第三混合矩阵,可以包括:基于所述流体类型的数量,利用不同几何学解混方法对所述第一混合矩阵进行处理,获取不同流体在核磁共振谱上的伪特征;其中,不同流体在核磁共振谱上的伪特征为几何学解混方法得到的端元矩阵;对不同几何学解混方法对应的端元矩阵中数据进行硬阈值处理;将硬阈值处理后的端元矩阵进行组合,获得第三混合矩阵。
[0079]
一些实施场景中,所述利用不同几何学解混方法对所述第一混合矩阵进行处理,获得不同几何学解混方法求取的不同流体在核磁共振谱上的伪特征,其中,不同流体在核磁共振谱上的伪特征为几何学解混方法得到的端元矩阵,可以包括:将所述第一混合矩阵作为单行体;利用不同几何学解混方法确定所述单行体的顶点,获得对应的端元矩阵。其中,所述单行体的顶点对应纯像元,纯像元可以表示不同流体类型在核磁共振谱上的分布特征。其中,设n维空间有c个仿射独立的点e1,e2,e3…
e
c
,这些点的线性组合可以表示为一个点集,该点集在空间的散布图就可以理解为一个单形体。e
i
是单形体的顶点(端元),单形体内部的点称为混合像元,单形体的顶点组成的矩阵可以称为端元矩阵e,其对应着不同流体类型在核磁共振谱上的分布特征。
[0080]
其中,基于几何学解混方法提取流体分布特征是基于纯流体的分布特征在空间上的分布特点进行的。几何学解混方法提取流体分布特征可以理解为是求取单形体的顶点(端元),其可以包括基于投影的解混方法和单形体体积最大化解混算法。具体的,基于投影的解混方法的基础是所求的纯流体的特征分布位于单形体的顶点,该顶点可以通过特定方向的投影得到,常见的方法有像元纯度指数法(pixel purity index,ppi)、顶点成分分析法(vertex component analysis,vca)和正交子空间投影法(orthogonal subspace projection,osp)等。单形体体积最大化解混算法的目标是在混合数据中搜索一个包含整个数据集的体积最大的单形体,常见的方法有n
‑
findr法、单形体生长算法(simplex growing algorithm,sga)、正交基算法(orthogonal bases algorithm,oba)等。其中,ppi是通过投影的方式寻找端元,其将混合数据的高维空间投影到一维空间,由于端元位于单
形体的顶点,混合像元在单形体内部,这样投影到一维空间后,可以记录两端的端点为潜在的端元,然后通过随机生成大量不同方向穿过数据集的测试向量,记录每个像元被投影到测试向量端点的次数,被记录的次数越多,则它们是端元的概率越大。vca同样是基于投影的方式寻找端元,相比于ppi方法,vca改进了投影的方式,第一次迭代时,vca将具有最大投影长度的像元作为第一个端元,计算与该端元正交的方向作为第二次迭代使用的投影方向,以此类推,每次新的投影方向与已提取的端元所张成的空间正交。n
‑
findr法不同于vca和ppi,其是通过计算单形体的体积的方式确定端元位置,由于端元是单形体的顶点,混合像元属于单形体的内点,端元所围成的体积一定大于由内点所围成的体积,所以通过选择能够支撑出最大体积的像元作为端元。
[0081]
需要说明的是,本说明书实施例中,利用一种几何学解混方法对第一混合矩阵进行处理,获得的端元矩阵中包括c个流体类型在核磁共振谱上的分布特征。其中,c为目标地层中流体类型的数量。端元矩阵中每一行可以表示一种流体类型在核磁共振谱上的分布特征。例如,上述实施例中确定的目标地层中流体类型的数量为4,则利用ppi对第一混合矩阵进行处理,获得的端元矩阵中包括4个流体类型在核磁共振谱上的分布特征,利用vca对第一混合矩阵进行处理,获得的端元矩阵中包括4个流体类型在核磁共振谱上的分布特征。
[0082]
本说明书实施例中,利用多种不同的几何学解混方法对第一混合矩阵进行处理,获得不同几何学解混方法对应的端元矩阵后,可以对端元矩阵中不同流体的分布特征进行硬阈值处理,进一步,可以将硬阈值处理后的分布特征进行组合,获得第三混合矩阵。
[0083]
一些实施场景中,进行硬阈值处理时,可以将低于端元矩阵中最大值的1/4置零,即如果e(i)<max(e)/4,则e(i)=0。
[0084]
一些实施场景中,获得的第三混合矩阵可以记为其中,的大小为q
×
n,q=h
×
c,h为采用的几何学解混方法的数量,c为目标地层中流体类型的数量。
[0085]
s6:利用非负矩阵分解算法对所述第三混合矩阵进行分解,获得不同流体类型在核磁共振谱上的特征。
[0086]
本说明书实施例中,在获得第三混合矩阵后,可以基于流体类型的数量,利用非负矩阵分解算法对所述第三混合矩阵进行分解,获得不同流体类型在核磁共振谱上的特征。其中,非负矩阵分解(nonnegative matrix factorization,nmf)可以用于解决盲源分离问题。nmf由于具有非负性的约束、其分离的结果具有更好的可解释性而受到广泛的应用。通常,对于任意给定的一个非负矩阵(其中,的大小为q
×
n),nmf算法能够寻找到一个非负矩阵u和一个非负矩阵v,使得满足从而实现将一个非负的矩阵分解为左右两个非负矩阵的乘积。其中,r表示流体类型的数量。
[0087]
一些实施场景中,可以使用基于极大似然的nmf算法获得不同流体类型在核磁共振谱上的特征。具体算法如下:
[0088]
输入:混合矩阵,
[0089]
输出:非负矩阵u和非负矩阵v。其中,u包含不同流体的体积分数,v包含不同流体在二维核磁共振谱上的特征。
[0090]
具体的,第一步,随机初始化矩阵u0和v0,使矩阵中的元素为正值,对矩阵u0的列向量进行归一化处理,初始化迭代次数t=0;
[0091]
第二步,根据下述公式迭代u;
[0092][0093]
其中,x
g
为混合矩阵,u
ia
为u的第i行第a列的元素,j表示x
g
、(uv)和v的列数,x
gij
为x
g
的第i行第j列的元素,v
aj
为v的第a行第j列的元素,(uv)
ij
为u和v乘积后的第i行第j列的元素。需要说明的是,t=0时,上述迭代公式u、v指初始化矩阵u0和v0,t大于0时,上述迭代公式u、v指上次迭代更新后的u和v。
[0094]
第三步,根据下述公式对u的列向量进行归一化;
[0095][0096]
其中,u
ia
为u的第i行第a列的元素。
[0097]
第四步,根据下述公式迭代v;
[0098][0099]
其中,v
ia
为v的第i行第a列的元素,j表示x
g
和(uv)的列数,x
gij
为x
g
的第i行第j列的元素,(uv)
ij
为u和v乘积后的第i行第j列的元素。
[0100]
第五步,更新迭代次数t=t+1,并判断目标函数是否收敛,未收敛则转到第二步继续执行,收敛则获得矩阵u和矩阵v。
[0101]
本实施例中,目标函数为
[0102]
其中,收敛时,可以获取投影系数矩阵v,投影系数矩阵v的每一行可以表示不同流体类型在nmr谱上的特征。
[0103]
一些实施场景中,在获得不同流体类型在nmr谱上的特征后,可以将得到的不同流体类型在nmr谱的特征对应的孔隙度归一化。
[0104]
本说明书实施例,基于流体类型的数量利用几何学解混方法对第一混合矩阵进行处理,可以使获得的第三混合矩阵中的数据量远小于第一混合矩阵中的数据量,从而可以提高获取不同流体类型在核磁共振谱上的特征的效率。
[0105]
s8:基于所述第一混合矩阵和利用非负矩阵分解算法得到的不同流体类型在核磁共振谱上的特征,利用预设方式确定不同深度点中不同流体类型的饱和度;其中,所述预设方式满足指定约束条件。
[0106]
本说明书实施例中,在利用非负矩阵分解算法得到不同流体类型在核磁共振谱上的特征后,可以基于第一混合矩阵和利用非负矩阵分解算法得到的不同流体类型在核磁共振谱上的特征,利用预设方式确定不同深度点中不同流体类型的饱和度。其中,所述预设方式满足指定约束条件。
[0107]
一些实施场景中,所述预设方式可以为最小二乘法或反演方法。当然,上述只是进行示例性说明,上述预设方式不限于上述举例,所属领域技术人员在本技术技术精髓的启示下,还可能做出其它变更,但只要其实现的功能和效果与本技术相同或相似,均应涵盖于本技术保护范围内。
[0108]
一些实施场景中,所述指定约束条件可以包括饱和度非负约束和饱和度和为1约束。
[0109]
一些实施场景中,可以基于第一混合矩阵和表示不同流体类型在核磁共振谱的特征的矩阵v,利用全约束最小二乘方法求取不同深度点不同流体类型的饱和度。具体的,可以根据下述公式求取不同深度点不同流体类型的饱和度:
[0110][0111]
其中,s为待求的饱和度矩阵。
[0112]
对公式(1)等号两端进行转置得到公式(2):
[0113][0114]
由于用无约束的最小二乘方法对上述公式(2)求解,得到的结果不准确,本实施例中,根据饱和度的特性(即饱和度和为一约束和饱和度的非负性约束)对最小二乘方法添加饱和度和为一约束和饱和度非负约束进行求解。
[0115]
需要说明的是,上述只是以利用全约束最小二乘方法求取不同深度点不同流体类型的饱和度为例进行示例性说明,本说明书实施例中还可以通过其他反演法求取不同深度点不同流体类型的饱和度。其中,在通过其他反演方法求取不同深度点不同流体类型的饱和度时只需加入饱和度非负约束和饱和度和为一约束。
[0116]
当然,上述只是进行示例性说明,本说明书实施例不限于上述举例,所属领域技术人员在本技术技术精髓的启示下,还可能做出其它变更,但只要其实现的功能和效果与本技术相同或相似,均应涵盖于本技术保护范围内。
[0117]
下面结合具体实施例对上述方法进行说明,然而,值得注意的是,为了更好地说明本技术,下述具体实施例以t1‑
t2测井为例进行说明,其并不构成对本技术的不当限定,例如其仍适用于所有多维nmr测井,如t2‑
d测井和t1‑
t2‑
d测井等。
[0118]
具体的,图6为t1‑
t2测井中四种流体类型的t1‑
t2谱模型,其中,按照从上到下、从左到右的顺序依次表示沥青流体类型在nmr谱的特征、黏土束缚水流体类型在nmr谱的特征、oil in op流体类型在nmr谱的特征、water in ip流体类型在nmr谱的特征,横坐标t2表示横向弛豫时间,纵坐标t1表示纵向弛豫时间。图7为窄饱和度范围内四种流体类型的饱和度信息,其中,横坐标表示饱和度,纵坐标表示深度点,从左到右依次对应沥青、黏土束缚水、oop(oil in op)和wip(oil in op),每个深度点的四种流体类型饱和度分布范围为0~0.6。图8为宽饱和度范围内四种流体类型的饱和度信息,其中,横坐标表示饱和度,纵坐标表示深度点,从左到右依次对应沥青、黏土束缚水、oop(oil in op)和wip(oil in op),每个深度点的四种流体类型饱和度分布范围为0~0.8。图9为三个具有不同流体饱和度的地层的t1‑
t2谱模型、信噪比为15的回波数据、信噪比为15的回波数据的反演结果、信噪比为30的回波数据以及信噪比为30的回波数据的反演结果。其中,第一行分别表示三个具有不同流体饱和度的地层的t1‑
t2谱模型,横坐标t2表示横向弛豫时间,纵坐标t1表示纵向弛豫时间;第二行分别为与第一行对应的信噪比为15的回波数据,横坐标echo train表示回波串(图中共采集了10组回波串),纵坐标time(ms)表示时间,轴向坐标表示回波串的幅度,轴向坐标刻度到了孔隙度porosity;第三行分别为与第一行对应的信噪比为15的回波数据的反演结果,横坐标t2表示横向弛豫时间,纵坐标t1表示纵向弛豫时间;第四行分别为与第一行
对应的信噪比为30的回波数据;第五行分别为与第一行对应的信噪比为30的回波数据的反演结果。图10为窄饱和度范围内信噪比为15时利用ppi方法提取的流体特征分布。图11为窄饱和度范围内信噪比为15时利用vca方法提取的流体特征分布。图12为窄饱和度范围内信噪比为15时利用n
‑
findr方法提取的流体特征分布。图13为窄饱和度范围内信噪比为15时利用nmf方法提取的流体特征分布。图14为窄饱和度范围内信噪比为15时利用本技术方法提取的流体特征分布。其中,图10
‑
图14中四幅子图从上到下、从左到右依次对应沥青、黏土束缚水、oop(oil in op)和wip(oil in op)。由图10
‑
图14可知,本技术方法得到的结果中重叠较小,更准确。
[0119]
图15为窄饱和度范围内信噪比为15时,利用vca方法求取的流体特征分布通过全约束最小二乘方法求取的饱和度,其中,横坐标(ground truth saturation)表示模拟的真饱和度,纵坐标(calculated saturation)表示计算的饱和度,四幅子图从上到下、从左到右依次对应沥青、黏土束缚水、oop(oil in op)和wip(oil in op)。图16为窄饱和度范围内信噪比为15时,利用n
‑
findr方法求取的流体特征分布通过全约束最小二乘方法求取的饱和度,其中,横坐标(ground truth saturation)表示模拟的真饱和度,纵坐标(calculated saturation)表示计算的饱和度,四幅子图从上到下、从左到右依次对应沥青、黏土束缚水、oop(oil in op)和wip(oil in op)。图17为窄饱和度范围内信噪比为15时,利用nmf方法求取的流体特征分布通过饱和度物理意义求取的饱和度,其中,横坐标(ground truth saturation)表示模拟的真饱和度,纵坐标(calculated saturation)表示计算的饱和度,四幅子图从上到下、从左到右依次对应沥青、黏土束缚水、oop(oil in op)和wip(oil in op)。图18为窄饱和度范围内信噪比为15时,利用nmf方法求取的流体特征分布通过全约束最小二乘方法求取的饱和度,其中,nmf_fcls表示利用nmf方法求取的流体特征分布通过全约束最小二乘方法求取的饱和度,其中,横坐标(ground truth saturation)表示模拟的真饱和度,纵坐标(calculated saturation)表示计算的饱和度,四幅子图从上到下、从左到右依次对应沥青、黏土束缚水、oop(oil in op)和wip(oil in op)。图19为窄饱和度范围内信噪比为15时,利用本技术方法求取的流体特征分布通过全约束最小二乘方法求取的饱和度其中,横坐标(ground truth saturation)表示模拟的真饱和度,纵坐标(calculated saturation)表示计算的饱和度,四幅子图从上到下、从左到右依次对应沥青、黏土束缚水、oop(oil in op)和wip(oil in op)。
[0120]
本实施例中,在通过不同方法求取饱和度后,可以通过se=sum(abs(s
‑
s_m))/num_depth计算饱和度误差se,其中,s为不同方法求取的饱和度,s_m为地层模型饱和度,num_depth为地层点个数,此处取1000。具体的在窄饱和度范围内信噪比为15时不同方法对应的饱和度误差结果如表1所示,其中,the proposed method表示本技术方法。
[0121]
表1
[0122]
[0123]
由表1可以可知,通过几何学解混方法(vca、n
‑
findr)求取流体分布特征不准确,因而反演得到的饱和度误差很大,nmf方法的特提取结果通过全约束最小二乘方法求取不同流体饱和度误差低于nmf方法通过饱和度物理意义求取饱和度误差,本技术方法求取的不同流体饱和度误差最小。
[0124]
此外,本技术还获取了利用不同方法求取不同流体的分布特征以及饱和度所对应的平均耗时,如表2所示。
[0125]
表2
[0126] vcan
‑
findrnmfnmf_fclsg
‑
nmftime(s)0.370.381.211.410.39
[0127]
由表2可知,几何学解混方法和本技术方法(g
‑
nmf)的耗时明显低于nmf以及nmf_fcls方法的耗时,证明本技术方法的运算复杂度低,计算效率高效。
[0128]
由此可见,本技术方法可以更加准确、更加快速确定不同流体类型饱和度。
[0129]
需要说明的是,以上所有计算结果均为采用同一台计算机(intel(r)core(tm)i5
‑
4200u 2.3
‑
ghz,6
‑
gb ram)由matlab r2014a软件运行得到。
[0130]
从以上的描述中,可以看出,本技术实施例可以实现如下技术效果:通过将不同深度点的多维核磁共振回波数据反演得到的nmr谱组合为混合矩阵,对混合矩阵进行小波pca、2dpca、非负矩阵分解以及全约束最小二乘方法,可以更加准确地、更加快速确定不同流体类型饱和度,从而可以有效解决在非常规储层中,地层孔隙度低、孔隙结构复杂以及赋存孔隙中的流体类型复杂等原因导致利用nmr测井定量求取不同流体类型饱和度困难的问题。
[0131]
本说明书中上述方法的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参照即可,每个实施例重点说明的都是与其他实施例的不同之处。相关之处参见方法实施例的部分说明即可。
[0132]
基于上述所述一种确定地层流体饱和度的方法,本说明书一个或多个实施例还提供一种确定地层流体饱和度的装置。所述的装置可以包括使用了本说明书实施例所述方法的系统(包括分布式系统)、软件(应用)、模块、组件、服务器、客户端等并结合必要的实施硬件的装置。基于同一创新构思,本说明书实施例提供的一个或多个实施例中的装置如下面的实施例所述。由于装置解决问题的实现方案与方法相似,因此本说明书实施例具体的装置的实施可以参见前述方法的实施,重复之处不再赘述。以下所使用的,术语“单元”或者“模块”可以实现预定功能的软件和/或硬件的组合。尽管以下实施例所描述的装置较佳地以软件来实现,但是硬件,或者软件和硬件的组合的实现也是可能并被构想的。
[0133]
具体地,图20为本说明书实施例提供的一种确定地层流体饱和度的装置的模块结构示意图,如图20所示,本说明书提供的一种确定地层流体饱和度的装置可以包括:获取模块120,分析模块122,获得模块124,分解模块126,确定模块128。
[0134]
获取模块120,可以用于获取不同深度点的核磁共振谱组成的第一混合矩阵和第二混合矩阵;其中,所述不同深度点的核磁共振谱是基于目标地层不同深度点的回波数据反演获得;所述第二混合矩阵中的数据未进行线性转换;
[0135]
分析模块122,可以用于对所述第一混合矩阵和所述第二混合矩阵进行分析,基于分析结果确定所述目标地层中流体类型的数量;
[0136]
获得模块124,可以用于基于所述流体类型的数量,利用几何学解混方法对所述第一混合矩阵进行处理,获得不同流体类型在核磁共振谱上的伪特征,并组合为第三混合矩阵;
[0137]
分解模块126,可以用于利用非负矩阵分解算法对所述第三混合矩阵进行分解,获得不同流体类型在核磁共振谱上的特征;
[0138]
确定模块128,可以用于基于所述第一混合矩阵和利用非负矩阵分解算法得到的不同流体类型在核磁共振谱上的特征,利用预设方式确定不同深度点中不同流体类型的饱和度;其中,所述预设方式满足指定约束条件。
[0139]
需要说明的,上述所述的装置根据方法实施例的描述还可以包括其他的实施方式,具体的实现方式可以参照相关方法实施例的描述,在此不作一一赘述。
[0140]
本说明书还提供一种确定地层流体饱和度的设备的实施例,包括处理器及用于存储处理器可执行指令的存储器,所述处理器执行所述指令时可以实现上述任意一项方法实施例。例如,所述指令被所述处理器执行时实现包括以下步骤:获取不同深度点的核磁共振谱组成的第一混合矩阵和第二混合矩阵;其中,所述不同深度点的核磁共振谱是基于目标地层不同深度点的回波数据反演获得;所述第二混合矩阵中的数据未进行线性转换;对所述第一混合矩阵和所述第二混合矩阵进行分析,基于分析结果确定所述目标地层中流体类型的数量;基于所述流体类型的数量,利用几何学解混方法对所述第一混合矩阵进行处理,获得不同流体类型在核磁共振谱上的伪特征,并组合为第三混合矩阵;利用非负矩阵分解算法对所述第三混合矩阵进行分解,获得不同流体类型在核磁共振谱上的特征;基于所述第一混合矩阵和利用非负矩阵分解算法得到的不同流体类型在核磁共振谱上的特征,利用预设方式确定不同深度点中不同流体类型的饱和度;其中,所述预设方式满足指定约束条件。
[0141]
需要说明的,上述所述的设备根据方法或装置实施例的描述还可以包括其他的实施方式。具体的实现方式可以参照相关方法实施例的描述,在此不作一一赘述。
[0142]
本说明书所提供的方法实施例可以在移动终端、计算机终端、服务器或者类似的运算装置中执行。以运行在服务器上为例,图21为本说明书实施例提供的一种确定地层流体饱和度的服务器的硬件结构框图,该服务器可以是上述实施例中的确定地层流体饱和度的装置或确定地层流体饱和度的系统。如图21所示,服务器10可以包括一个或多个(图中仅示出一个)处理器100(处理器100可以包括但不限于微处理器mcu或可编程逻辑器件fpga等的处理装置)、用于存储数据的存储器200、以及用于通信功能的传输模块300。本领域普通技术人员可以理解,图21所示的结构仅为示意,其并不对上述电子装置的结构造成限定。例如,服务器10还可包括比图21中所示更多或者更少的组件,例如还可以包括其他的处理硬件,如数据库或多级缓存、gpu,或者具有与图21所示不同的配置。
[0143]
存储器200可用于存储应用软件的软件程序以及模块,如本说明书实施例中的确定地层流体饱和度的方法对应的程序指令/模块,处理器100通过运行存储在存储器200内的软件程序以及模块,从而执行各种功能应用以及数据处理。存储器200可包括高速随机存储器,还可包括非易失性存储器,如一个或者多个磁性存储装置、闪存、或者其他非易失性固态存储器。在一些实例中,存储器200可进一步包括相对于处理器100远程设置的存储器,这些远程存储器可以通过网络连接至计算机终端。上述网络的实例包括但不限于互联网、
企业内部网、局域网、移动通信网及其组合。
[0144]
传输模块300用于经由一个网络接收或者发送数据。上述的网络具体实例可包括计算机终端的通信供应商提供的无线网络。在一个实例中,传输模块300包括一个网络适配器(network interface controller,nic),其可通过基站与其他网络设备相连从而可与互联网进行通讯。在一个实例中,传输模块300可以为射频(radio frequency,rf)模块,其用于通过无线方式与互联网进行通讯。
[0145]
上述对本说明书特定实施例进行了描述。其它实施例在所附权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于实施例中的顺序来执行并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
[0146]
本说明书提供的上述实施例所述的方法或装置可以通过计算机程序实现业务逻辑并记录在存储介质上,所述的存储介质可以计算机读取并执行,实现本说明书实施例所描述方案的效果。所述存储介质可以包括用于存储信息的物理装置,通常是将信息数字化后再以利用电、磁或者光学等方式的媒体加以存储。所述存储介质可以包括:利用电能方式存储信息的装置如,各式存储器,如ram、rom等;利用磁能方式存储信息的装置如,硬盘、软盘、磁带、磁芯存储器、磁泡存储器、u盘;利用光学方式存储信息的装置如,cd或dvd。当然,还有其他方式的可读存储介质,例如量子存储器、石墨烯存储器等等。
[0147]
本说明书提供的上述确定地层流体饱和度的方法或装置实施例可以在计算机中由处理器执行相应的程序指令来实现,如使用windows操作系统的c++语言在pc端实现、linux系统实现,或其他例如使用android、ios系统程序设计语言在智能终端实现,以及基于量子计算机的处理逻辑实现等。
[0148]
需要说明的是说明书上述所述的装置、设备、系统根据相关方法实施例的描述还可以包括其他的实施方式,具体的实现方式可以参照对应方法实施例的描述,在此不作一一赘述。
[0149]
本技术中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于硬件+程序类实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1