用于离子光谱中的结构识别的理化性质评分的制作方法
1.本发明涉及将分子结构与包含在光谱数据中的信号峰相关联的方法,所述光谱数据根据一种或多种理化性质从分离中获得。光谱数据可以包括离子光谱数据。离子光谱数据可能是从根据气相中的物理化学特性进行的分离中获得的,例如离子迁移率k或离子质量m或离子质荷比m/z。离子光谱数据同样可以从根据在电离和/或转移到气相之前的物理-化学性质,例如液相色谱中的保留时间进行的分离中获得。
背景技术:
2.在本说明中结合具体方面对相关技术进行了说明。然而,这不应理解为限制本发明的以下公开内容。相关领域中已知的有用的发展和其修改也可以超出本说明的相对狭窄的范围应用,并且在阅读本说明之后的本发明的公开内容后,对于本领域的技术人员来说将是显而易见的。
3.自1994年首次引入sequest软件包(jimmy k.eng等人,j.am.soc.mass spectrom.1994,5,976-989)以来,用于识别蛋白质的数据库搜索算法已经取得了进步。搜索引擎通过将来自ms/ms数据的实验光谱与来自蛋白质数据库的计算机内光谱(in-silico spectra)进行比较来计算分数。尽管已经在改进蛋白质识别方面投入了大量努力,但仍然有大量光谱无法识别。障碍之一是频谱模糊。例如,来自蛋白质数据库的多个候选肽通常可以具有相同的前体质量和相似的碎片离子模式,从而产生竞争性的肽谱匹配搜索分数。
4.在下文中,将给出处理这种已有类型的频谱评估的出版物的简要说明,但不要求完整性:
5.例如,专利文献wo 2004/013635 a2提出了一种用于对肽匹配进行评分的系统和方法。实施方案包括引入基于适当信号检测的评分系统,包括基于与第一肽、第二肽及其片段相关的一个或多个匹配特征生成随机模型,以对第一肽和第二肽之间的匹配进行评分。基于随机模型计算第一肽与第二肽匹配的第一概率,和第一肽与第二肽不匹配的第二概率。并且至少部分地基于第一概率和第二概率之间的比率对第一肽和第二肽之间的匹配进行评分。
6.进一步举例而言,专利文献wo 2020/016428 a1公开了一种用于从至少一个实体的质谱和选择性地从来自所述至少一个实体的化学、物理、生物化学或生物分析的附加数据确定所述至少一个实体的种类的方法,对于每个实体而言包括以下步骤:a)从实体的质谱收集分析数据,并且选择性地从实体的化学、物理、生化或生物分析收集额外的分析数据;b)获取实体的多个候选种类,并获取所述实体的候选种类的流行度,而对于每个候选种类,所有具有较高流行度的候选种类都包括在多个候选种类中;c)对于实体的每个候选种类,计算其得分,所述计算至少涉及实体的流行度,或至少实体的流行度以及与质谱的一致性,d)确定作为具有这样的分数的候选种类的实体种类,即其具有最接近对应于实体真实种类的分数。
7.在进一步的科学发展过程中,通过在测量循环中增加额外的分离维度,出现了精
确分辨大量光谱的解决方案,该维度迄今为止通常包括来自液相色谱的保留时间和来自(串联)质谱离子质量或质荷比m/z。额外的分离维度是源自离子迁移分离阶段的ccs(碰撞截面),视情况与上游和/或下游质量分离阶段和/或上游色谱分离阶段连接。
8.在下文中,将给出处理此类增强型频谱评估的出版物的简要说明,同样不要求完整性:
9.shei la c.henderson等人(anal.chem.1999,71,291-301)报告了一种通过综合方法鉴定具有不可区分分子量的许多不同肽序列的方法,包括通过其迁移率的差异解析不同寡聚体序列的能力以及基于与分子模型的比较来分配峰的方法。
10.philip d.mosier等人(anal.chem.2002,74,1360-1370)报告了定量结构-性质关系(qspr)以使用来自拓扑分子结构和各种氨基酸参数的信息来预测单质子化赖氨酸封端肽的离子迁移谱(ims)碰撞截面。研究发现,单独的一级氨基酸序列就足以准确预测碰撞截面。这些模型是使用多元线性回归(mlr)和计算神经网络(cnn)构建的。
11.专利文献wo 2010/119289 a2和wo 2010/119293 a2分别公开了一种估计分子横截面面积的方法,用于预测离子迁移率,给出气相相互作用半径确定和横截面算法计算来提供结构相关异构体的分离和表征。
12.专利文献wo 2011/027131 a1公开了一种筛选样品来确定一种或多种已知感兴趣化合物是否存在的方法。碎片化设备在碎片化运行模式和非碎片化运行模式之间重复切换。确定候选目标母离子(m1)是否存在于非碎片化数据集中,以及一个或多个相应的目标碎片离子(m2、m3、m4...)是否存在于碎片化数据集中。进一步确定候选目标母离子(m1)和一个或多个相应的目标碎片离子(m2、m3、m4...)是否具有基本相似的洗脱或保留时间和/或离子迁移率漂移时间。
13.stephen j.valentine等人(j proteome res.2011 may 6;10(5)2318
–
2329)报告了一种使用从漂移管气相离子迁移分离器获得的漂移时间来帮助鉴定肽离子的评分方案。
14.专利文献wo 2011/128703 a1公开了一种用于鉴定和/或表征样品的方法和装置,该样品可以掺入两种或更多种异构或同量异位化合物,例如羟基化代谢物。该方法包括对两种或更多种已知异构体或同量异位化合物中的每一种的可能结构的集合进行建模,计算每个建模结构的理论碰撞截面,并对每个已知化合物的计算值求平均值以为每个已知化合物提供理论碰撞截面的值。行波离子迁移率池用于测量样品化合物的碰撞截面值,然后将测量值与理论值进行比较,以确定样品化合物与两种或更多种已知化合物中的哪一种最相似。
15.专利文献wo 2014/170664 a2公开了一种针对至少一种感兴趣的化合物筛选样品的方法。该方法包括将目标化合物的离子的离子迁移率和至少一种另外的物理化学性质与样品中候选离子的相同性质进行比较。目标化合物的特性与样品中候选离子的特性相匹配,然后确定样品包含目标化合物。
16.专利文献wo 2015/136272 a1公开了一种质谱分析方法,其中通过实验确定或测量一个或多个分析物离子的碰撞或相互作用截面以及质量或质荷比,并且根据确定或测量的质量或质荷比编制可能的候选化合物的第一列表。然后为第一列表中的每个候选化合物理论计算、估计或确定碰撞或相互作用横截面。然后使用理论计算、估计或确定的碰撞或相互作用横截面从第一列表中过滤或去除候选化合物或降低与第一列表中的一个或多个候
选化合物相关联的似然值。
17.鉴于上述内容,仍然需要一种改进的方法,将分子结构与光谱数据中的信号峰相关联,该光谱数据是根据一种或多种物理化学性质从分离中获得的。在阅读以下公开内容后,技术教导的进一步优点和益处对于技术人员来说将是显而易见的。
技术实现要素:
18.在第一方面,本发明涉及一种将分子结构与(包含在)从根据一个或多个物理化学性质进行的分离中获得的光谱数据中的信号峰相关联的方法,包括,视情况可重复:
19.在获取的光谱数据中提供一个或多个与(气相离子)迁移率或相关特性的实验值相关的信号峰;
20.确定一种或多种适合与一个或多个信号峰相关联的候选分子结构;
21.通过计算、估计、派生和推导中的一种为每个候选分子结构提供作为迁移率或相关特性的函数的第一匹配分数的(个体)分布;
22.在应用一个或多个信号峰的迁移率或相关特性的实验值时,为每个候选分子结构将假定的第一匹配分数定义为来自相应分布的输出;并且
23.在将分子结构与一个或多个信号峰相关联的步骤中使用假定的第一匹配分数。
24.在多种实施例中,假定的第一匹配分数可用于从关联中排除分子结构。可以在匹配分数标度上为第一匹配分数建立界标,该界标定义了表明从关联中排除分子结构的第一范围和表明潜在真实关联的第二范围。
25.在多种实施例中,一个或多个信号峰可以具有第二物理化学性质的一个或多个实验值并且每个候选分子结构可以与第二物理化学性质的一个或多个候选值相关。一个或多个候选值可以显示与第二物理化学性质的一个或多个实验值的一致性水平,从而暗含了每个候选分子结构的第二匹配分数。第二匹配分数还可用在将分子结构与一个或多个信号峰相关联的步骤中。第二匹配分数和假定的第一匹配分数可以在(二次)判别分析中单独但联合使用,以便从不太可能的匹配或识别中分辨出可能的匹配或识别。
26.在多种实施例中,可以组合假定的第一匹配分数和第二匹配分数以生成第三匹配分数。第三匹配分数可以用在将分子结构与一个或多个信号峰相关联的步骤中。优选地,可以将具有假定的第一匹配分数、第二匹配分数和第三匹配分数中的至少一个的最极端值的候选分子结构用于将分子结构与一个或多个信号峰相关联。尤其地,可以采用具有假定的第一匹配分数、第二匹配分数和第三匹配分数中的至少一个的最高分数的候选分子结构来将分子结构与一个或多个信号峰相关联。此外,相对于上述最高分数具有较低分数的所有候选分子结构可被视为不指示有效关联。
27.在多种实施例中,与每个候选分子结构相关的第二物理化学性质的一个或多个实验值和第二物理化学性质的一个或多个候选值可以指示前体离子种类和在解离时前体离子种类的相关碎片离子种类中的至少一种的分子量。可以通过解离单个前体离子种类来产生碎片离子种类,或者可以通过同时解离两个或更多个前体离子种类来产生多个碎片离子种类。在后一种情况下,一起解离的前体离子种类的数量可以通过迁移分离阶段的设置和在迁移分离阶段与解离或裂解阶段之间发生的额外质量过滤来控制。
28.在多种实施例中,根据(气相离子)迁移率或相关特性进行的分离至少在根据第二
物理化学特性进行分离之前或之后。优选地,根据第二物理化学性质的分离可以包括质量或质荷比(m/z)过滤和质量或质荷比色散中的至少一种,例如在飞行管中的飞行时间(tof)色散。飞行管可以基本上是无场的或者可以包含无场区和反射器。质量或质荷比的过滤可尤其提供可用于从大量普遍可用的候选分子结构中确定潜在候选分子结构的子集的信息,否则由于其庞大的规模而无法进行处理,尤其是对于感兴趣的特定分子类别,例如肽和蛋白质等,其中数百万个分子结构是可以想象的。
29.在多种实施例中,每个分布可以被配置成使得其可以导致彼此偏离的第一匹配分数。优选地,可通过将实验性的或实验确定的迁移率或相关特性值应用于(或将其插入)分布而产生的第一匹配分数可作为距分布的迁移率或相关特性种子值的距离的函数而偏离,例如表征分布中心或分数最高的位置。每个分布可以是单独的,例如每个分布都可以用单独的和明确的参数来表征,例如定位其中心或分数最高位置的种子值,和宽度值,其指示作为距中心或分数最高位置的距离的函数的下降率。
30.在多种实施例中,每个分布可以被配置为使得其可以沿着迁移率或相关的特性标度导致具有最高第一匹配分数的区域和与其相邻的具有降低的第一匹配分数的(第一)相邻区域。优选地,每个分布还可以被配置为使得其可以导致相对于具有最高第一匹配分数的区域和具有降低的第一匹配分数的第一相邻区域具有降低的第一匹配分数的第二相邻区域。尤其地,分布可以呈现三个或更多个不同的第一匹配分数,这取决于迁移率或相关特性的实验值的定位。优选地,每个分布可以遵循解析函数,例如高斯函数或其他合适的数学函数。例如,这种数学函数可以由一个或多个迁移率或相关特性种子值和一个或多个宽度参数定义。在高斯函数的情况下,宽度参数可以是sigma(σ)宽度或半高全宽(fwhm)宽度。sigma宽度可以占迁移率或相关特性种子值(例如中心值或最高分数值)的百分之二十(20)、百分之十五(15)、百分之十(10)、百分之五(5)或百分之一(1)。该函数可以是基本连续的或可以是按步连续的。通常,分布可以被配置为例如显示单个顶点。此外,分布可以被配置为对称的,使得其从迁移率或相关特性种子值开始,例如高斯函数的中心值开始,在迁移率或相关特性尺度的任一方向上具有相同的形式或形状。分布同样可以被配置为不对称的,使得其根据从种子值开始的沿迁移率或相关特性尺度的方向具有不同的形式或形状。换句话说,分布也可能是偏斜或扭曲的。第一候选分子结构的第一分布和第二候选分子结构的第二分布可能部分重叠。
31.在多种实施例中,第一匹配分数可以指示第一值(排除匹配)和第二值(匹配确定)之间的标度上的概率。更一般地,第一匹配分数可以是标量。尤其地,第一值可以等于零并且第二值可以等于一。
32.在多种实施例中,计算、估计、派生或推算可包括基于先前获取和表征的光谱测量数据集的(i)统计评估、(i i)机器学习和(i i i)深度学习中的至少一种的方法。第一匹配分数的分布可以代表特定候选分子结构的多个现有光谱数据集中的标准偏差(或指示再现性的其他参数)。如果不存在特定候选分子结构的先前光谱数据,则分布同样可以代表估计、回归、内插或外推。在多种实施例中,可以使用混合密度网络(mdn)模型来执行机器学习或深度学习。
33.在多种实施例中,一个或多个信号峰可以由生物分子来源的离子种类产生。优选地,离子峰可以由肽、蛋白质、脂质、聚糖、多糖、寡核苷酸、代谢物等产生。
34.在各种实施方案中,可以从指示可能分子结构的目标候选池和指示不可能分子结构的诱饵候选池确定一个或多个候选分子结构。假定的第一匹配分数可用于定义有助于区分可信关联和不可信关联的度量,尤其是利用诱饵候选匹配不可能为真的认知。
35.在第二个方面,本发明涉及一种将分子结构与从(包含在)根据一种或多种物理化学性质进行的分离中获得的光谱数据中的信号峰相关联的方法,包括:
36.在获取的光谱数据中提供多个信号峰组和多个(气相离子)迁移率或相关特性的实验值,每个信号峰组与(气相离子)迁移率或相关特性的实验值相关联并具有一个或多个信号峰值;
37.从指示可能分子结构的目标候选池和指示不可能分子结构的诱饵候选池中确定多个候选分子结构组,每个候选分子结构组具有一个或多个候选分子结构且适合与一个或多个信号峰组相关联;
38.通过计算、估计、推导和推算为每个候选分子结构提供一个或多个(气相离子)迁移率或相关性质的候选值;
39.通过将每个候选分子结构的一个或多个匹配分数定义为(气相离子)迁移率或相关特性的一个或多个候选值与多个信号峰组的(气相离子)迁移率或相关特性的实验值之间的一致性水平的函数来提供多个匹配分数,并且
40.使用多个匹配分数来定义有助于区分可信关联和不可信关联的度量。
41.在多种实施例中,匹配分数可以是标量。优选地,标量可取介于零和一之间(between zero and unity)的值。
42.在多种实施例中,可以在匹配分数标度上建立匹配分数界标,其定义了:假定为指示不可信关联的第一范围,无论潜在候选分子结构是来自诱饵候选池还是目标候选池;和被假定为指示值得信赖的关联的第二范围。
43.优选地,匹配分数界标可以被定义为小于发现与诱饵候选池中的候选分子结构相关的信号峰组的百分之五(5)、百分之四(4)、百分之三(3)、百分之二(2)和百分之一(1)中的一个的百分比位于第二范围内。
44.在第三方面,本发明涉及一种用于记录根据一种或多种物理化学性质分离产生的离子种类的装置,包括被设计和配置用于执行如上文所述的方法的数据处理单元。
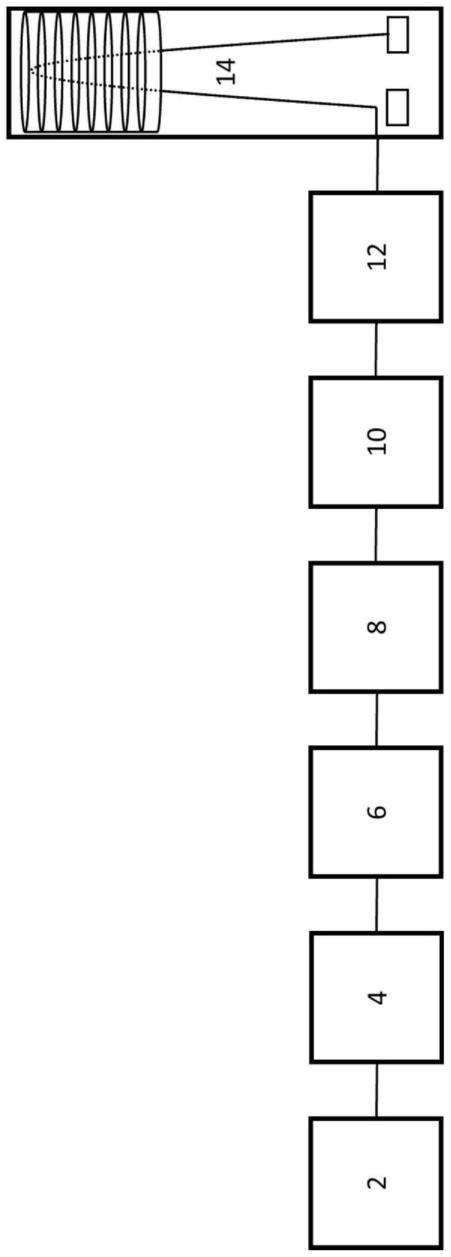
附图说明
45.通过参考以下附图可以更好地理解本发明。图中的元素不一定按比例绘制,而是强调说明本发明的原理(通常是示意性的):
46.图1示出了离子光谱仪的示意图,利用该光谱仪可以获得已经根据多种物理化学性质进行分离的光谱数据,例如保留时间、气相离子迁移率和质量或质荷比。
47.图2示意性地示出了应用于光谱数据的结构识别工作流程中的各个步骤,该数据例如来自图1中描绘的设备。
48.图3a示出了一个候选分子结构的匹配分数分布。
49.图3b示出了两个候选分子结构的两个部分重叠的匹配分数分布。
50.图4示出了作为假定的碰撞截面匹配分数的函数的光谱匹配频率的示例性图,这里以肽为例。
具体实施方式
51.虽然已经参考本发明的多个不同实施例示出和说明了本发明,但是本领域技术人员将认识到,在不脱离如所附权利要求所定义的本发明的范围的情况下,可以在本文中进行形式和细节的各种改变。
52.图1示出了可能的离子光谱仪设备的示意图,其包括多个不同的分离级,利用这些分离级可以获得根据几种物理化学特性色散的光谱数据。
53.可以首先在色谱级中分离样品,如2所示。色谱级可以包括具有柱的液相色谱级,该柱包含合适的固定相,溶解在合适的流动相中的样品流过该固定相。结果可能是一系列随后在特征性的保留时间洗脱的色谱峰,这取决于色谱条件的设置。
54.色谱级的洗脱液可以传递到离子源,如4所示,其可以将洗脱液峰中包含的样品分子转变为气载带电分析物分子或分析物离子。离子源可以是电喷雾离子源,其利用在喷嘴处相对于反电极建立的高压差来雾化和电离液体样品,例如从液相色谱柱洗脱的样品。通常,离子可以例如通过使用喷雾电离(例如,电喷雾(esi)或热喷雾)、解吸电离(例如,基质辅助激光/解吸电离(maldi)或sims电离)、化学电离(ci)、光电离(pi)、电子碰撞电离(ei)或气体放电电离产生。
55.分析物离子可以被收集并汇集到良好准直的离子束中,促进其有效地转移到离子迁移率分离级,如6所示。离子迁移率分离级可以利用在施加电场时分析物离子与移动或停滞的气体的相互作用,该电场保持恒定或随时间变化。举例来说,可以根据俘获离子迁移率分离(tims)的原理来设计和配置离子迁移率分离级。专利公布us7,838,826b1(通过引用以其整体并入本文)给出了tims分离级的实例。离子迁移率分离的结果可能是一系列随后在特征性的时间的洗脱离子迁移率峰,这取决于迁移率分离装置的条件。其他合适类型的气相离子迁移率分离器可能包括漂移管离子迁移率分离器(dtims),行波离子迁移率分离器(twims),或气相离子迁移率过滤器,如场不对称离子迁移率分离器(faims)。
56.洗脱的迁移率峰可以通过离子引导级,如8所示,其可以用于使分析物离子通过离子迁移率分离级中相对较高的压力与用于进一步的气相离子处理和操作的后续级中保持的较低压力之间的压差。这种离子引导级可以包括不同离子引导器,例如,多极杆组离子引导器和/或堆叠环形离子引导器。
57.过滤器级,如10所示,可以紧随离子引导器级。过滤器级可以包括质量过滤器,例如四极质量过滤器,其有助于以宽带或前体筛选模式传输分析物离子,其目的是分选尽可能少的离子,或者换言之,传输尽可能多的进入离子,以及有助于以带通滤波器模式、高通滤波器模式和低通滤波器模式之一传输分析物离子,其目的是将传输窗口减小到相对较窄的质量或质荷比(m/z)范围,从而使得消除离子不落入该传输窗口中。宽带或前体筛选模式和任何一种过滤器模式可以(快速)连续交替。
58.如在12处所指示的碎片级可以跟在过滤级之后。碎片级可以包括填充有碰撞气体的离子引导器,并且还配备有电极,该电极促进加速电压的切换,以将分析物离子高速拉入碰撞气体中以诱导解离。从分析物离子中选择的前体离子可以碎片化成多个特征碎片离子。通常,离子可以例如在碎片级中通过碰撞诱导解离(cid)、表面诱导解离(sid)、光解离(pd)、电子捕获解离(ecd)、电子转移解离(etd)、电子转移解离后的碰撞活化(etcd)、与电子转移解离同步的活化(ai-etd)或通过与高度激发或自由基中性粒子的反应而碎片化。
59.从碰撞池发出的离子可以传递到质量分离级,如14所示。质量分离级可以采用反射器飞行时间(rtof)分离级的形式,其中将正交离子注入飞行时间飞行管。在飞行管内的弯曲飞行路径的末端,离子可由碰撞检测器,例如二次电子倍增器检测器记录。结果可能是在分子量或质量相关的尺度,例如飞行时间上绘制的离子丰度,例如离子强度的光谱。连同来自色谱级2和离子迁移率分离级6的信息,光谱数据可以在不同的图中呈现,例如3d图,其中每个轴对应于下列物理化学性质的尺度:(i)来自色谱级2的保留时间,(i i)来自离子迁移分离级6的气相离子迁移率或相关特性,以及(i ii)来自质量分离级14的质量或质荷比或相关特性,同时信号峰的丰度可以用颜色或其他合适的图形特征来表示。
60.图2示意性地示出了在几个步骤中将分子结构与从根据一种或多种物理化学性质进行的分离(例如参考图1所举例说明)中获得的光谱数据中包含的信号峰相关联的方法。
61.首先,提供所获得的光谱数据,例如光谱中的一个或多个信号峰,如图左侧的20所示。该一个或多个信号峰可以由生物分子来源的离子种类产生,例如肽、蛋白质、脂质、聚糖、多糖、寡核苷酸、代谢物等。光谱数据可能与气相离子迁移率km或相关特性的实验性或实验确定的值有关,例如由图1中的离子迁移率分离级6中的分离产生的。相关特性例如可以包括代替指标(proxy),例如离子种类通过漂移管离子迁移分离器的漂移时间t
d,m
或衍生或推导出的参数,例如碰撞横截面ccsm(与1/k成比例)或碰撞横截面-电荷比(ccs/z)m。
62.可以确定一种或多种适合与一个或多个信号峰相关联的候选分子结构。确定可以基于在光谱数据的采集期间的质量或质荷比过滤,例如使用四极质量过滤器,以便定义候选物必须符合的有限质量或质荷比范围,例如由图1中的滤波器级10产生。一个或多个信号峰可能具有第二物理化学性质的多个实验值,并且每个候选分子结构可能与第二物理化学性质的一个或多个候选值相关,如22所示。与每个候选分子结构相关的第二物理化学性质的一个或多个实验值和第二物理化学性质的一个或多个候选值可以指示前体离子种类和在解离时前体离子种类的相关碎片离子种类中的至少一种的分子量。优选地,第二物理化学性质可以包括离子质量m或离子质荷比m/z。也可能的是,第二物理化学性质可以包括离子质量m的代替指标,例如在飞行时间分离器的飞行管中的飞行时间。
63.在匹配步骤中,一个或多个候选值可以显示出与m/z或相关特性的一个或多个实验值的一致性水平,从而隐含每个候选分子结构的m/z或相关特性匹配分数sc
m/z
,如24所示。此外,m/z或相关特性匹配分数sc
m/z
可用于将分子结构与一个或多个信号峰相关联的步骤中。m/z或相关特性匹配分数sc
m/z
可以是标量并且可以通过每次一个或多个信号峰的m/z或相关特性值一致于或落入与作为被检查的候选分子结构的候选值m/z或相关特性值相同的m/z或相关特性集合中时统一(unity)叠加计算得到。匹配的信号峰越多,m/z或相关特性匹配分数sc
m/z
可能变得越高。在这样的算法中,m/z或相关特性匹配分数sc
m/z
越高,识别结果就越可信。
64.可以设置根据一种或多种物理化学性质进行的分离的顺序,使得根据(气相离子)迁移率或相关特性进行的分离至少在根据m/z或相关特性进行的分离之前和之后。例如,根据m/z或相关特性进行的分离可以包括质量或质荷比过滤和质量或质荷比色散中的至少一种,例如飞行管中的飞行时间色散,两者均示例性地在根据迁移率或相关特性进行的分离后执行,如参考图1中的示意图所说明的。
65.对于每个候选分子结构,可以通过计算、估计、推导或推算中的一种来提供迁移率
或相关特性匹配分数sc
ccs
作为迁移率或相关特性的函数的个体分布,如图3a所示。计算、估计、推导或推算可以包括计算、估计、推导或推算可包括基于先前获取和表征的光谱测量数据集的(i)统计评估、(i i)机器学习和(i i i)深度学习中的至少一种的方法。每个分布可以以一个或多个迁移率或相关特性种子值为特征,其例如定义了分布的中心或分数最高的位置。迁移率或相关特性匹配分数sc
ccs
可以指示第一值(排除匹配)和第二值(匹配确定)之间的尺度上的概率。如图所示,第一值可以是零并且第二值可以是一(unity)。每个分布可以被配置为使得其可以导致彼此偏离的迁移率或相关特性匹配分数sc
ccs
。优选地,每个分布可以被配置为使得其可以导致沿着迁移率或相关特性尺度的具有最高迁移率或相关特性匹配分数sc
ccs
的区域,例如在接近分布中心的位置处指示的,其呈现值0.97(第一垂直虚线),以及与其相比迁移率或相关特性匹配分数sc
ccs
降低的相邻区域,例如在分布的下降侧翼上指示的,其呈现值0.27(第二垂直虚线)。很明显,在分布过程中可能存在更多的偏离的迁移率或相关特性匹配分数的区域。
66.每个分布可以遵循分析函数,例如高斯函数或其他合适的数学函数,例如按步函数或按步连续函数,其代表被检查的候选分子结构先前观察到或实验确定的迁移率或相关特性值的概率加权偏差或扩展。分布还可以代表对不存在先前光谱数据的候选分子结构的迁移率或相关特性匹配分数的估计、推导和/或推算,尤其是通过对现有数集据利用深度学习和/或机器学习的方法。在多种实施例中,可以使用混合密度网络(mdn)模型来执行机器学习或深度学习。
67.第一候选分子结构的第一分布和第二候选分子结构的第二分布有可能部分重叠,例如在图3b中示例性地显示。这可能意味着假定的迁移率或相关特性匹配分数sc
ccs,p
在第一候选分子结构的情况下比在另一竞争候选分子结构的情况下结果更高,在左分布#1中的下降侧翼上部,呈现值0.68,比右侧分布#2中的上升侧翼下部更高,呈现值0.17,这在匹配判断中提供进一步考虑的因素,并允许提高匹配质量。在图3b所示的示例中,这可以解释为所检查的光谱数据中的一个或多个信号峰与分布#1的候选分子结构的关联比与分布#2的候选分子结构的关联更可靠。
68.如图3a和3b所示,可以将每个候选分子结构的推定迁移率或相关性质匹配分数sc
ccs,p
定义为在应用或插入一个或多个信号峰的迁移率或相关特性ccsm(或km或(ccs/z)m)的实验值或实验确定的值时,从相应分布中的输出。换言之,假定的迁移率或相关特性匹配分数sc
ccs,p
可以为每个候选分子结构定义为一个或多个信号峰的迁移率或相关特性ccsm的实验值位于被检验的候选分子结构的迁移率或相关特性分布中位置的函数。这在图3a中的两条垂直虚线中示例性示出,图中显示,一个实验迁移率或相关特性值落入靠近中心的候选迁移率或相关特性分布中,从而导致高置信度假定匹配分数(0.97),并且一个实验迁移率或相关特性值落入远离中心的候选迁移率或相关特性分布中,从而导致较低置信度假定匹配分数(0.27)。
69.从图3b中的单个垂直虚线可以看出另一个实例,其显示出,单个实验迁移率或相关特性值落入靠近中心的第一候选迁移率或相关特性分布#1中,从而导致高置信度,左侧分布#1中在sc
ccs,p
=0.68处,同时落入远离中心的第二竞争候选迁移率或相关特性分布#2内,从而导致低置信度,右侧分布#2中在sc
ccs,p
=0.17处。这一发现表明与左侧分布#1相关的候选分子结构相比于右侧分布#2相关的候选分子结构是更可能或更值得信赖的匹配。
70.回到图2,如26处所示的假定的迁移率或相关特性匹配分数sc
ccs,p
可以用于将分子结构与一个或多个信号峰相关联的步骤中。在第一种变体方案中,假定的迁移率或相关特性匹配分数sc
ccs,p
可用于从关联中排除分子结构。在图2中,假定的迁移率或相关特性匹配分数sc
ccs,p
的低值可能表明潜在的分子结构与光谱数据20中观察到的信号峰不匹配。可以建立迁移率或相关特性匹配分数sc
ccs
的界标值,其在匹配评分标度上定义将分子结构视为不适用而排除的第一范围,以及将分子结构视为可能真实而接受的第二范围。
71.在一个实施例中,假定的迁移率或相关特性匹配分数sc
ccs,p
可以单独地并且与m/z或相关特性匹配分数sc
m/z
(并且进一步匹配或分数参数例如从保留时间、碎片离子种类的强度、离子种类的同位素分布、离子种类的电荷状态等推导出或导出)联合使用,用于执行(二次)判别分析以区分可信匹配和不可信匹配。
72.在进一步的实施例中,可以组合假定的迁移率或相关特性匹配分数sc
ccs,p
和m/z或相关特性匹配分数sc
m/z
以生成如28所示的第三匹配分数,并且第三匹配分数可以在将分子结构与一个或多个信号峰相关联的步骤中使用。组合可包括假定的迁移率或相关特性匹配分数sc
ccs,p
和m/z或相关特性匹配分数sc
m/z
的乘法或其他合适的数学运算,如30所示。具有迁移率或相关特性匹配分数sc
ccs
、m/z或相关特性匹配分数sc
m/z
和第三匹配分数中的至少一个的最极端值的候选分子结构可以用来将分子结构与一个或多个信号峰相关联。优选地,m/z或相关特性匹配分数sc
m/z
、假定的迁移率或相关特性匹配分数sc
ccs,p
和第三匹配分数中的至少一个的最高匹配分数可以指示一个或多个信号峰与候选分子结构的关联可能为真。
73.一种或多种候选分子结构可以从指示可能分子结构的目标候选池和指示不可能分子结构的诱饵候选池中确定,如图2中的32所示。假定的迁移率或相关特性匹配分数sc
ccs,p
可用于定义有助于区分可信关联和不可信关联的度量。使用尤其从离子迁移率分离、错误发现率(fdr)或诱饵命中率(dhr)计算中得出的此附加信息可以更准确。
74.图4示例性示出了图示,其在纵轴(y轴)上显示肽谱匹配(psm)频率,其作为在横轴(x轴)上示出的假定碰撞横截面匹配分数sc
ccs,p
的函数,涉及目标候选匹配(实心列)以及诱饵候选匹配(空心列)两者。可以看出,在接近1的高匹配分数时,目标候选匹配占优势,而在低匹配分数时,频率在目标候选匹配和诱饵候选匹配之间几乎平均分布。众所周知,诱饵候选匹配不可能为真,而目标候选匹配是否为真始终至少有一点不确定性,尤其是在没有经验丰富的从业者仔细检查结果的自动化处理中,来自诱饵候选匹配的信息可以用于以统计方法来定义匹配分数标度上的界标,其定义了匹配分数的第一范围,其由于低置信度而被视为不可信,无论是诱饵还是目标候选匹配,以及第二范围,其中候选匹配可以被视为可能或最有可能是真的。
75.这作为示例由图4中的垂直实线在大约0.5的匹配分数处指示。在此界标左侧(≤0.5),匹配可被视为不可信,而在此界标右侧(>0.5),匹配可被假定为可信或可能为真。可以这样选择界标并按照期望的置信水平建议进行移动。可以这样选择界标,使得只有特定低百分比的诱饵候选匹配位于指示可信度的范围内(正确的范围,更高的分数),例如匹配总数的百分之五,或更少。例如,该附加的迁移率相关度量可以有利地用于计算错误发现率或诱饵命中率。
76.上面已经参考本发明的多个不同实施例示出和说明了本发明。然而,本领域技术
人员理解,在不脱离本发明范围的情况下,如果可行,本发明的各个方面或细节可以改变,或者不同实施例的各个方面或细节可以任意组合。总体而言,前述说明内容仅用于说明的目的,并不用于限制仅由所附权利要求限定的本发明,包括任何等效实施方式,视情况而定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1