一种复杂GPS轨迹中的重要地点挖掘方法及装置
一种复杂gps轨迹中的重要地点挖掘方法及装置
技术领域
1.本发明涉及gps技术领域,提供了一种复杂gps轨迹中的重要地点挖掘方法及装置。
背景技术:
2.现有的重要地点挖掘方法主要分为基于速度特征的重要地点挖掘方法,基于方向特征的重要地点挖掘方法和基于概率的重要地点挖掘方法三类。基于速度特征的重要地点挖掘方法以速度为特征,将一定领域范围内速度较低的轨迹点聚类到一起,得到重要地点。然而,对于对速度不敏感的应用场景,该方法会产生误报。基于方向特征的重要地点挖掘方法首先计算出所有点的方向角,再根据相邻点的方向角改变量对轨迹点进行聚类得到结果。基于速度特征的重要地点挖掘方法虽然在一定程度上能够增加对速度不敏感的应用场景的适应性,但高度依赖方向变化,难以扩展到日常行进方向基本不变的应用场景中。基于概率的重要地点挖掘方法通过定义高斯核函数算出每个点的停止概率,然后根据停止概率将重要地点挖掘出来,但停止概率难以指定。目前的方法阈值参数较多,对用户指定的阈值参数高度敏感,同时存在挖掘准确度不高,可扩展性弱,挖掘效率较低的问题。
3.现有技术问题存在分析:
4.问题1:需要用户提前指定的阈值参数过多(5个以上),没有先验知识或者经验的用户难以在短时间内获得最优的阈值参数组合;
5.问题2:现有的基于密度的聚类算法在一定条件下产生了有意义且充分的结果,但当存在不同密度的聚类时,其结果并不令人满意
6.对于c1上的每个物体p来说,物体p和它最近的邻居之间的距离大于02和c2之间的距离。因此,在存在不同密度的簇时,我们难以选择合适的距离半径eps值。如果距离半径eps值小于02到c2的距离,则c1中的某些对象被指定为噪声对象。如果距离半径eps值大于02到c2的距离,则02不被指定为噪声对象。
7.总结一下:当各个簇的局部密度不统一时,用户难以用一个全局距离半径eps值来区分出这些密度不同的簇。
8.问题3:存在性能问题,比如速度较慢,目前存在的方法的最快时间复杂度最快是0(nlogn),而我们的方法的时间复杂度接近0(n),几乎是线性。在描述算法复杂度时,经常用到0(1),0(n),0(logn),0(nlogn)来表示对应复杂度程度。
9.问题4:没有充分考虑轨迹点的时间特征和空间特征,导致重要地点挖掘的精度较低。
技术实现要素:
10.本发明的目的在于解决目前基于密度距离测量的方法来挖掘重要地点存在的当各个簇的局部密度不统一时,用户难以用一个全局距离半径eps值来区分出这些密度不同的簇的技术问题。
11.为了实现上述目的本发明采用以下技术手段:
12.本发明提供了一种复杂gps轨迹中的重要地点挖掘方法,其特征在于,
13.步骤1:获取gps定位数据,得到轨迹tr={p1,p2,...,pi,...,pn},其中轨迹点pi包含纬度:pi.lat,经度:pi.long和时间戳:pi.t,i=1,2,...,n且p1.t<p2.t<...<pn.t。
14.步骤2:根据领域索引半径indexr,获取每一个轨迹点pi的索引领域in(pi);
15.步骤3:根据索引领域in(pi)获取每一个轨迹点pi索引领域速度nv(pi);
16.步骤4:获取轨迹tr中索引领域速度nv(pi)小于等于给定速度阈值minvelocity的轨迹点,记为特征点cpi,从轨迹tr中提取特征点后得到特征点集合cps={cp1,cp2,...,cp
i,
...,cpm};
17.步骤5:根据索引领域半径indexr,获取每个特征点cpi特征索引领域cpin(cpi)={cpa,cp
a+1
,...,cpi,...,cp
b-1
,cpb};
18.步骤6:将一条轨迹上所有特征点cpi与在特征点cpi索引领域半径indexr内的其他特征点cpj连边,构建索引领域图;
19.步骤7:获取特征点cpi的在特征索引领域cpin(cpi)的停留时间nst(cpi),nst(cpi)=cpb.t-cpa.t,其中,cpb.t和cpa.t分别是两个特征点cpb和cpa的时间戳。两个特征点cpi和特征点cpj间的互停留时间mst(cpi,cpj)表示为)表示为
20.步骤8:通过数据场理论计算特征点集合cps中特征点cpi的电势,得到步骤6中连边的特征点cpi和特征点cpj间的相对电势rp(cpi,cpj),然后根据相对电势rp(cpi,cpj)和互停留时间mst(cpi,cpj)得到特征点cpi和cpj间的边的时空权重w(cpi,cpj);
21.步骤9:对特征点集合cps中的每一个特征点cpi分配一个唯一的标签,从特征点cpi中选取未更新过的电势p(cpi)最大的特征点cpi,然后根据最大的时空权重w(cpi,cpj)确定对应的特征点cpj,将特征点cpi的标签更新为特征点cpj的标签,重复上述步骤直到所有特征点的标签不再改变时停止,最后把标签相同的点聚集为同一个簇,然后通过用户指定的时间阈值minduration过滤持续时间小于minduration的簇得到最终的重要地点,簇的持续时间定义为簇中点的最大时间戳与最小时间戳的差。
22.定义任意两个轨迹点pi和pj间的距离其中1≤i<j≤n,dist(pk,p
k+1
)定义了两个相邻的轨迹点pk和p
k+1
的欧式距离;
23.在上述技术方案的基础上,步骤2中索引领域技术方案的基础上,步骤2中索引领域其中indexr是一个控制索引领域in(pi)的半径大小的正数pk中的k就对应了索引下标k。
24.在上述技术方案的基础上,步骤3中,获取每一个轨迹点pi索引领域速度nv(pi),轨迹点pi的索引领域in(pi)={pa,p
a+1
,...,pi,...,p
b-1
,pb},则},则其中dist(pa,ph)为索引领域nv(pi)中所有相邻轨迹点的欧式距离的和,pb.t-pa.t为最大时间差。
25.在上述技术方案的基础上,步骤5具体为:获取每个特征点cpi特征索引领域cpin(cpi),其中indexr是一个控制特征索引领域cpin(cpi)半径大小的正数,值与提取特征点中的索引领域半径indexr大小一致。
26.在上述技术方案的基础上,步骤8中:
27.特征点cpi的电势
28.相对电势rp(cpi,cpj)=rp(cpi,cpj)=-|p(cpi)-p(cpj)|。
29.时空权重其中dist(cpi,cpj)是顶点cpi到cpj中所有相邻轨迹点的欧式距离的和,中所有相邻轨迹点的欧式距离的和,其中1≤a<b≤m,dist(cpk,cp
k+1
),为两个相邻的轨迹点cpk和cp
k+1
的欧式距离。
30.本发明还提供了一种复杂gps轨迹中的重要地点挖掘装置,其特征在于,
31.gps数据获取模块:获取gps定位数据,得到轨迹tr={p1,p2,...,pi,...,pn},其中轨迹点pi包含纬度:pi.lat,经度:pi.long和时间戳:pi.t,i=1,2,...,n且p1.t<p2.t<...<pn.t;
32.轨迹点索引领域模块:根据领域索引半径indexr,获取每一个轨迹点pi的索引领域in(pi);
33.轨迹点引领域速度模块:根据索引领域in(pi)获取每一个轨迹点pi索引领域速度nv(pi);
34.特征点模块:获取轨迹tr中索引领域速度nv(pi)小于等于给定速度阈值minvelocity的轨迹点,记为特征点cpi,从轨迹tr中提取特征点后得到特征点集合cps={cp1,cp2,...,cpi,...,cpm};
35.特征点索引领域模块:根据索引领域半径indexr,获取每个特征点cpi特征索引领域cpin(cpi)={cpa,cp
a+1
,...,cpi,...,cp
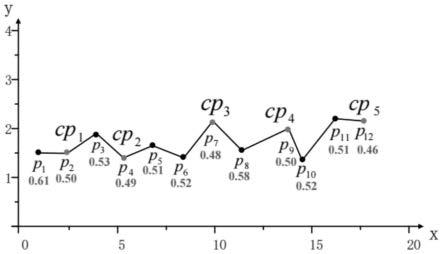
b-1
,cpb};
36.特征点连边模块:将一条轨迹上所有特征点cpi与在特征点cpi索引领域半径indexr内的其他特征点cpj连边;
37.停留时间模块:获取特征点cpi的在特征索引领域cpin(cpi)的停留时间nst(cpi),nst(cpi)=cpb.t-cpa.t,其中,cpb.t和cpa.t分别是两个特征点cpb和cpa的时间戳,两个特征点cpi和特征点cpj间的互停留时间mst(cpi,cpj)表示为)表示为
38.时空权重模块:通过数据场理论计算特征点集合cps中特征点cpi的电势,得到特征点连边模块中连边的特征点cpi和特征点cpj间的相对电势rp(cpi,cpj),然后根据相对电势rp(cpi,cpj)和互停留时间mst(cpi,cpj)得到特征点cpi和cpj间的边的时空权重w(cpi,cpj);
39.结果模块:对特征点集合cps中的每一个特征点cpi分配一个唯一的标签,从特征
点cpi中选取未更新过的电势p(cpi)最大的特征点cpi,然后根据最大的时空权重w(cpi,cpj)确定对应的特征点cpj,将特征点cpi的标签更新为特征点cpj的标签,重复上述步骤直到所有特征点的标签不再改变时停止,最后把标签相同的点聚集为同一个簇,然后通过用户指定的时间阈值minduration过滤持续时间小于minduration的簇得到最终的重要地点,簇的持续时间定义为簇中点的最大时间戳与最小时间戳的差。
40.在上述技术方案的基础上,轨迹点索引领域模块中索引领域在上述技术方案的基础上,轨迹点索引领域模块中索引领域其中indexr是一个控制索引领域in(pi)的半径大小的正数pk中的k就对应了索引下标k。
41.在上述技术方案的基础上,获取每一个轨迹点pi索引领域速度nv(pi),轨迹点pi的索引领域in(pi)={pa,p
a+1
,...,pi,...,p
b-1
,pb},则其中dist(pa,pb)为索引领域nv(pi)中所有相邻轨迹点的欧式距离的和,pb.t-pa.t为最大时间差。
42.在上述技术方案的基础上,获取每个特征点cpi特征索引领域cpin(cpi),其中indexr是一个控制特征索引领域cpin(cpi)半径大小的正数,值与提取特征点中的索引领域半径indexr大小一致。
43.在上述技术方案的基础上,特征点cpi的电势σ
tr
为整条轨迹tr所有相邻点pi,p
i-1
的欧式距离的方差;
44.相对电势rp(cpi,cpj)=rp(cpi,cpj)=-|p(cpi)-p(cpj)|,
45.时空权重其中dist(cpi,cpj)是顶点cpi到cpj中所有相邻轨迹点的欧式距离的和,中所有相邻轨迹点的欧式距离的和,其中1≤a<b≤m,dist(cpk,cp
k+1
)为两个相邻的轨迹点cpk和cp
k+1
的欧式距离。
46.因为本发明采用上述技术手段,因此具备以下有益效果:
47.(1)通过提取特征点构建索引领域图,当轨迹上的点离的比较远时,我们通过索引半径indexr得到的点间的相对距离半径eps就比较大,当轨迹上的点距离比较近时,我们通过索引半径indexr得到的点间的相对距离半径eps就比较小,这样我们就能动态的捕获不同的局部密度,能用一个全局参数indexr较好的区分不同的簇,解决了问题2。同时,我们减少了阈值参数,只保留了3个必要的阈值参数,方便没有先验知识的用户更方便地获得最优的阈值参数组合,解决了问题1。
48.(2)通过定义时空权重更新措施,充分考虑了特征点的时间和空间特征,扩展了标签传播算法lpa挖掘重要地点的能力,提高了重要地点挖掘结果精确度,解决了问题4。
49.(3)此外,其他的重要地点挖掘方法的时间复杂度在特定情况下最快可达o(nlogn),而我们首先提取了特征点,大大减少了需要参与运算的轨迹点的数量,降低了计算复杂度,其次通过时空权重更新措施扩展后的标签传播算法elpa几乎是线性时间复杂度
o(n),因此重要地点挖掘结果的效率得到进一步的提升,解决了问题3。
附图说明
50.图1为特征点提取过程示意图;
51.图2为特征点索引领域图cping;
52.图3为不同局部密度的簇的示例图。
具体实施方式
53.以下将对本发明的实施例给出详细的说明。尽管本发明将结合一些具体实施方式进行阐述和说明,但需要注意的是本发明并不仅仅只局限于这些实施方式。相反,对本发明进行的修改或者等同替换,均应涵盖在本发明的权利要求范围当中。
54.另外,为了更好的说明本发明,在下文的具体实施方式中给出了众多的具体细节。本领域技术人员将理解,没有这些具体细节,本发明同样可以实施。
55.提取特征点
56.一条轨迹tr定义为tr={p1,p2,...,pi,...,pn},其中轨迹点pi包含纬度pi.lat,经度pi.long和时间戳pi.t,i=1,2,...,n且p1.t<p2.t<...<pn.t。
57.一个轨迹点pi的索引领域其中indexr是一个控制索引领域in(pi)的半径大小的正数,tr是trajectory的缩写,这里就用tr来定义了什么是轨迹。pk中的k就对应了索引下标k。假设有n个轨迹点放到集合中,得到{p1,p2,p3,p4,p5,p6,.....,pn},它们然后依次对应索引下标为1,2,3,4,5,6,....,n,比如现在要求第四个点p4的索引领域,也就是索引下标为4对应的点p4,假设索引半径为2,那么索引领域就是{p
4-2
,...,p
4+2
}={p2,...,p6},也就是索引下标为2,3,4,5,6对应的点p2,p3,p4,p5,p6都是下标为4对应的点p4的索引领域。
58.一个轨迹点pi的索引领域速度nv(pi)定义为索引领域nv(pi)中所有点的欧式距离和与最大时间差的比值,最大时间差是指在索引领域nv(pi)中的最大时间戳pi.t的最大值减去最小值。
59.一个特征点cpi定义为索引领域速度nv(pi)小于等于给定速度阈值minvelocity的轨迹点。
60.如图1所示为特征点提取示意图,其中横轴和纵轴对应的纬度和经度转换到x,y平面直角坐标系的坐标值。在上图中p1到p
12
为轨迹点,轨迹点下方的数字(0.61,0.50
……
0.51,0.46)为索引领域速度,假设给定的速度阈值minvelocity=0.5,可以得到cp
l
,cp2,cp3,cp4,cp5这5个标记的特征点。
61.根据特征点构建特征点索引领域,从轨迹tr中提取特征点后得到特征点集合cps={cp1,cp2,...,cpi,...,cpm}。
62.一个特征点cpi的特征索引领域cpin(cpi)定义为)定义为其中indexr是一个控制特征索引领域cpin(cpi)半径大小的正数,值与提取特征点中的索引领域半径indexr大小一致。
63.本发明可以有两种实施方式,一种是直接用特征点cpi特征点索引领域图cp ing,
第二种是将cpi看成顶点vi,现对第二种方法进行如下说明:
64.将一条轨迹上所有特征点cpi看成顶点vi,即vi=cpi,然后根据indexr将顶点vi与其特征索引领域中的其他顶点连边,这样我们就可以得到对应的特征点索引领域图cping。将轨迹数据建模为索引领域图可以隔离在时间和空间上彼此距离太远的点,降低计算复杂度,并保存轨迹中重要的结构信息。特征点索引领域图cping如图2所示。
65.为方便本领域技术人员理解本发明的技术构思,对根据indexr将顶点vi与其特征索引领域中的其他顶点连边的具体实施细节做进一步表述,
66.如图2中,在一个特征点集合cps={cp1,cp2,cp3,cp4,cp5},则对应有{v1,v2,v3,v4,v5}5个顶点,此时特征索引领域cpin(vi)领域半径indexr=3,然后根据indexr将特征索引领域内的顶点与在其领域半径indexr=3内的点进行连接,
67.如v1左边没有点,如v1右边有点v2,v3,v4,则连接v1v2,v1v3,v1v4;
68.如v2左边有点v1,如v2右边有点v3,v4,v5,则连接v1v2,v2v3,v2v4,v2v5;
69.如v3左边有点v1,v2,如v3右边有点v4,v5,则连接v1v3,v2v3,v3v4,v3v4;
70.如v4左边有点v1,v2,v3,如v4右边有点v5,则连接v1v4,v2v4,v3v4,v4v5;
71.如v5左边有点v1,v2,v3,v4,如v5右边没有点,则连接v1v5,v2v5,v3v5,v4v5;
72.上述涉及的连接关系,连接一次即可,本领域技术人员也应当得知,也可二连接,不影响效果。从上述例子可以看出,每个顶点对应的领域半径indexr内,仅取存在的顶点连接,如v1左边没有顶点,则不用连接。
73.定义时空权重更新措施
74.从时间角度,我们首先定义顶点vi的领域停留时间nst(vi),其中nst(vi)为vi特征索引领域中的最大时间差,一开始轨迹点是按照时间数据排序的,假设vi的索引领域中的特征点为cp1,cp2,...,cp7,那么这cp1到cp7也是按照时间顺序排序的,即cp1对应的时间最早,cp7对应的时间最晚,那么最大时间差为cp7.t-cp1.t,其中时间戳cpi.t。接着,两个顶点vi和vj间的互停留时间间的互停留时间
75.从空间角度,给定vi的特征索引领域cpin(vi)={v
l
,v
l+1
,...,v
j-1
,vj},我们通过数据场理论定义点vi的电势其中dist(vi,v
i+1
)为两个顶点的欧式距离,σ
tr
为整条轨迹tr所有相邻点特征点(cpi,cp
i+1
),即对应的相邻的顶点(vi,v
i+1
)的欧式距离的方差。接着,顶点vi与其索引领域半径indexr内的其他vj间的相对电势rp(vi,vj)表示为rp(vi,vj)=-|p(vi)-p(vj)|。
76.则有两个顶点vi和vj间的一种时空权重更新措施,即vivj连接的边的权重其中dist(vi,vj)是顶点vi到vj中所有相邻轨迹点的欧式距离的和。dist(vi,vj)=dist(vi,v
i+1
)+dist(v
i+i
,v
i+2
)+...dist(v
j-1
,vj);
77.标签传播聚类
78.基于索引领域图,通过定义的时空权重更新措施扩展经典的标签传播算法lpa,使之能够更加准确高效地挖掘重要地点。首先对所有顶点分配不一样的标签,比如第一个顶点分配标签1,第二个顶点分配标签2,以此类推。然后计算所有点的电势p(vi),并按照从小
到大的顺序排序。接着选取尚未更新过的电势p(vi)最大的顶点开始更新。假设选定的顶点为vi,通过时空权重更新措施计算该点出发的所有边的权重w(vi,vj),然后选取权重最大的边vivj,把顶点vi的标签更新为顶点vj的标签,并记录vi的标签已经更新过了。重复上述步骤直到所有点的标签不再改变时停止。最后把标签相同的点聚集为同一个簇,然后通过用户指定的时间阈值minduration过滤持续时间小于minduration的簇得到最终的重要地点。簇的持续时间定义为簇中点的最大时间戳与最小时间戳的差。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1