一种基于深度迁移学习的小样本雷达一维像目标识别方法
1.本发明属于雷达目标识别技术领域,具体涉及一种基于深度迁移学习的小样本雷达一维像目标识别方法。
背景技术:
2.雷达高分辨距离像以其稳定、易获取、易处理等特点,成为了雷达目标识别领域的研究热点,而基于深度学习的方法在目标识别领域中也取得了很好的效果。但由于非合作目标的实测样本难以提前大量获取,导致系统识别性能受到制约,严重影响识别系统的实际应用能力。研究如何在小样本情况下,充分利用样本信息,提高模型泛化能力是亟待解决的关键性问题。本研究围绕小样本情况下的高分辨一维距离像目标识别问题,开展小样本下的目标有效特征提取、目标识别等研究工作,解决实际训练样本较少情况下的目标有效识别的关键科学问题。迁移学习的方法能够有效缓解小样本问题,而在迁移学习的基础上将模型参数迁移和样本统计量迁移结合起来,更能提高小样本情况下模型的识别精度。
技术实现要素:
3.针对传统方法对小样本情况下的一维像识别效果不理想的缺陷,本发明提出了一种基于模型迁移和分布校准的小样本雷达一维像目标识别方法。将迁移学习、注意力机制、平滑标签、分布校准等结合,提高小样本情况下的目标识别精度。
4.本发明的技术方案为:
5.一种基于深度迁移学习的小样本雷达一维像目标识别方法,包括以下步骤:
6.s1、构建数据集:
7.取一维像数据的幅度作为模型的输入,将数据划分为源数据集和目标数据集,两个数据集无交叉部分,设源数据集的训练样本数量为k1,目标数据集的训练样本为k2,k1》》k2;
8.s2、对获得的数据集进行预处理:
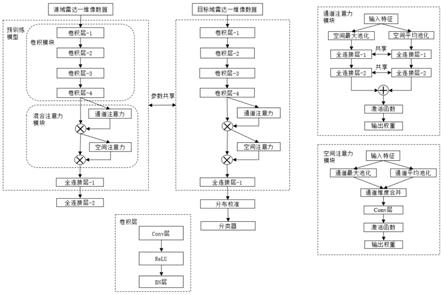
9.对s1获得的所有样本进行重心对齐和能量归一化,每个样本维度为1
×
n,n为采样点个数;源数据集训练样本矩阵大小为k1
×1×
n,对应的标签矩阵为k1
×
1,目标数据集训练样本矩阵大小为k2
×1×
n,对应标签矩阵为k2
×
1;
10.s3、构建预训练网络模型:
11.构建卷积神经网络,共四层卷积层,每层卷积层的后面使用relu函数作为激活函数层,激活函数后面接批归一化层;每层卷积层的卷积核大小都为3,步长都为1,通道变化为1
→
16
→
64
→
128
→
64;在最后的批归一化层后面接一个混合注意力模块,该混合注意力模块为一个通道注意力和一个空间注意力串行连接,通道注意力结构中,对输入进行全局平均池化和全局最大池化,两个池化后的结果分别通过两个不加偏置的全连接层,将得到的结果求和并通过sigmoid激活函数,得到每个通道0~1的权重,与输入逐元素相乘,通道注意力机制表示为:
[0012][0013]
通过通道注意力后接一个空间注意力,在空间注意力结构中,计算所有通道在每个空间位置的平均值和最大值,并在通道维度进行连接,形成一个2通道特征图,之后通过一个卷积核大小为7且不加偏置的的卷积层,将两个通道合并为一个通道,最后通过sigmoid激活函数得到每个空间位置0~1的权重,再与输入逐元素相乘;空间注意力机制表示为:
[0014][0015]
最后将得到的特征图转化为一个多维向量,并通过一个dropout层和两个全连接层,实现数据的降维和分类;
[0016]
损失函数采用的是平滑标签的交叉熵损失,设one-hot标签为l=[0,0,
…
,1i,
…
0],i表示第i类样本,平滑后的标签为其中α为平滑系数,0《α≤1;β为噪声系数,损失函数其中zi为第i个节点的输出值,优化器使用的是adam优化器;
[0017]
利用源数据集的训练样本,采用梯度下降法更新网络参数,迭代至损失收敛,保存验证集中结果最优的网络模型作为预训练最终的模型;
[0018]
s4、对s3得到的模型进行修改,冻结整个特征提取层和第一层全连接层的参数,剔除最后一层softmax分类层,得到修改后的网络模型;
[0019]
s5、利用s4得到的修改后的网络模型提取源数据集各类样本的特征,将其转化为特征向量后计算每个类别的均值和协方差统计量并保存为μi和σi,其中i为第i类样本;
[0020]
s6、利用目标数据集中的样本进行训练,具体训练步骤为:
[0021]
s61、将训练样本输入模型中,得到每个样本的特征向量,对训练样本进行分布校准,校准的方式利用的是幂变换:x为原始分布的数据,λ为一个可以调整数据分布偏度的超参;
[0022]
s62、将s5得到的每个类别的统计信息迁移到当前任务中,为当前任务中的每个训练样本在特征空间计算源数据集中与其最近的前k个类,距离度量采用的是欧氏距离,距离集其中cb为源数据集,最近的类集其中topk()表示最近的k个类,然后通过源数据集的统计量来校准当前任务数据分布的均值和协方差,新分布的均值协方差矩阵其中γ是一个控制分布离散程度的超参;然后,从均值为μ
′
,协方差矩阵为σ
′
的高斯分布中生成若干个新样本,
与目标数据集的训练样本合并成一个新的训练集;
[0023]
s7、利用s6得到的新的训练集训练一个逻辑回归分类器,迭代多次直至收敛,然后将目标的特征向量输入到逻辑回归分类器中进行分类识别。
[0024]
本发明的技术方案,针对小样本情况下的雷达一维像识别问题,首先构建无交叉的源数据集和目标数据集,并进行重心对齐和能量归一化。然后在源数据集上预训练一个特征提取网络,该网络是由卷积模块和混合注意力模块组合而成,损失函数采用平滑标签损失,以增强模型泛化能力。由于目标数据集中训练样本很少,得到特征提取器后需要将参数全部固定。在目标任务中,利用源数据集中的相似信息,校准小样本的分布,并从新的分布中生成新的数据,联合真实的小样本数据共同训练一个分类器。
[0025]
本发明的有益效果是:本发明针对小样本情况下的雷达一维像识别问题,基于迁移学习的方式,将混合注意力机制、平滑标签和分布校准方法结合,利用其他数据集的信息,有效地弥补了小样本情况下模型难训练的问题,减轻了模型过拟合现象,增强了模型表征能力,提高了识别率。
附图说明
[0026]
图1为本发明的网络模型结构示意图;
[0027]
图2为传统迁移学习方法和本发明方法的部分测试样本的特征向量在进行tsne降维后的可视化结果对比示意图。
具体实施方式
[0028]
下面结合附图对本发明的技术方案做进一步的详细描述:
[0029]
利用仿真软件获取各类型飞机和导弹的一维距离像进行训练和测试。数据集分源数据集和目标数据集。源数据集供预训练使用,共6类目标,每类目标俯仰角分布为:{0
°
,5
°
,10
°
,15
°
,20
°
,25
°
,30
°
,40
°
},每组俯仰角下的方位角分布为0
°
~180
°
,共6
×8×
1800个样本,每个样本的维度为1
×
300,取70%作为预训练的训练样本,其余作为验证集。目标数据集为小样本数据集,供训练和测试使用,共4类目标,每类目标俯仰角分布为:{0
°
,5
°
,10
°
,15
°
,20
°
,25
°
},每组俯仰角下的方位角分布为0
°
~90
°
,共4
×6×
900个样本,每个样本维度为1
×
300,评估每类训练样本数量分别取1、5、10情况下的测试结果,每轮测试150个样本。训练样本和测试样本都是随机抽取,总共测试500次,取平均准确率作为最终的识别结果。
[0030]
具体步骤如下:
[0031]
s1、构建数据集:
[0032]
取一维像数据的幅度作为模型的输入。将数据划分为源数据集和目标数据集,两个数据集无交叉部分,设源数据集的训练样本数量为k1,目标数据集的训练样本为k2(按照实验设置取1、5、10),其中k1》》k2。
[0033]
s2、对获得的数据集进行预处理:
[0034]
对s1所述所有样本进行重心对齐和能量归一化,以解决平移敏感性和幅度敏感性。每个样本维度为1
×
n,n为采样点个数。源数据集训练样本矩阵大小为k1
×1×
n,对应的标签矩阵为k1
×
1,目标数据集训练样本矩阵大小为k2
×1×
n,对应标签矩阵为k2
×
1。
[0035]
s3、构建卷积神经网络,设计各个网络结构层。如图1所示,共四层卷积层,每层卷积层的后面使用relu函数作为激活函数层,激活函数后面接批归一化层。卷积模块的卷积核大小都为3,四层卷积层的通道变化依次为:1
→
16、16
→
64、64
→
128、128
→
64。混合注意力模块接在最后一层卷积层后面,输入通道数为64。
[0036]
首先经过一个通道注意力模块,先对特征图进行全局最大池化和平均池化,池化后的输出分别通过两个全连接层,按4的倍率降维再升维,只计算全连接层的权重不计算偏置,然后将两者的输出求和,最后通过sigmoid激活函数,得到每个通道的权重,再与特征图逐元素相乘,通道注意力表示为:
[0037][0038]
相乘后的特征图再经过一个空间注意力模块,先在通道维度上计算每个位置的平均值和最大值,然后在通道维度上进行拼接得到通道为2的特征图,然后通过一个卷积核大小为7且不加偏置的卷积层,将通道数降为1,最后通过sigmoid激活函数,得到每个位置的权重,再与特征图逐元素相乘,空间注意力表示为:
[0039][0040]
之后再将特征图转化为高维的特征向量,经过dropout层和两个全连接层进行降维和分类,第一层全连接层的输出为一个256维的向量作为每个样本最终的特征向量。
[0041]
损失函数采用的是平滑标签的交叉熵损失,设one-hot标签为l=[0,0,
…
,1i,
…
0],i表示第i类样本。平滑后的标签为其中α为平滑系数,0《α≤1;β为噪声系数,为一个较小的值。本实验的α取0.9,β取0.05。损失函数为噪声系数,为一个较小的值。本实验的α取0.9,β取0.05。损失函数其中zi为第i个节点的输出值。优化器使用的是adam优化器。
[0042]
利用源数据集的训练样本,采用梯度下降法更新网络参数,迭代至损失收敛,保存验证集中结果最优的网络模型作为预训练最终的模型。
[0043]
s4、对s3得到的模型进行修改,由于实验设置的小样本数量很少,因此冻结整个特征提取层和第一层全连接层的参数,剔除最后一层softmax分类层。
[0044]
s5、利用s4得到的网络提取源数据集各类样本的特征,将其转化为特征向量后计算每个类别的均值和协方差统计量并保存为μi和∑i,其中i为第i类样本。
[0045]
s6、利用目标数据集中的小样本进行训练,具体训练步骤为:
[0046]
s61、根据实验设置,每类目标训练样本数为1、5、10。将训练样本和测试样本输入模型中,得到每个样本的特征向量。由于小样本容易存在偏态分布,因此先对小样本数据的训练样本和测试样本进行分布校准,校准的方式利用的是幂变换:x为原始分布的数据,λ为一个可以调整数据分布偏度的超参,本实验λ设置为0.7。
[0047]
s62、将s5得到的每个类别的统计信息迁移到当前任务中,为当前任务中的每个训
练样本在特征空间计算源数据集中与其最近的前k个类,距离度量采用的是欧氏距离,距离集其中cb为源数据集。最近的类集其中topk(
·
)表示最近的k个类。然后通过源数据集的统计量来校准分布的均值和协方差,新分布的均值协方差其中γ是一个控制分布离散程度的超参。然后,从均值为μ
′
,方差为σ
′
的高斯分布中生成若干个新样本,与实际的小样本合并成一个新的训练集。本实验设置k=1,γ=0.5,为每个训练样本生成的样本数量随着真实训练样本数的增加而减少,1个训练样本时为每个样本生成300个新样本,5个训练样本时为每个样本生成30个新样本,10个训练样本时为每个样本生成5个新样本。
[0048]
s7、利用s6得到的训练集训练一个逻辑回归分类器,迭代多次直至收敛。然后将测试样本的特征向量输入到逻辑回归分类器中进行分类识别,一次测试150个样本,总共测试500次,取最终的平均准确率。
[0049]
从图2的视化结果可以看出,本实验方法的特征提取网络类别聚集性更强,分布更整齐。小样本识别方法的平均识别率统计如下表1所示:
[0050]
表1小样本识别方法的平均识别率统计表
[0051][0052][0053]
由识别率结果可以看出,本发明相较于一般的迁移学习方法,具有更高的识别率。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1