一种利用机器学习预测粉煤灰中玻璃相含量的方法
1.本发明涉及固废处理领域,具体说是一种基于机器学习预测粉煤灰中玻璃相含量的方法。
背景技术:
2.经济的快速发展和工业生产推动了对能源的日益增长的需求。煤炭等化石燃料因其高热值和低成本一直是全球能源供应的主要来源。煤炭的产量高,消耗量大,主要用于电力生产和工业生产。目前最主要的发电方式还是燃煤发电,约占总发电量的40%。粉煤灰作为火力发电厂燃煤的副产品,每年产生的量约为8亿吨。粉煤灰的大量排放不仅占用土地资源,还会增加水中有害元素,破坏土壤结构和功能,对环境造成严重破坏,危害人类健康。因此,工业界和学术界越来越关注粉煤灰的资源利用。粉煤灰不仅可用于制造陶瓷玻璃、铺路和矿山回填,还可用作吸附剂以吸附污水中的重金属离子。此外,还尝试使用碳水化合物来制备用于土壤修复的复合灌浆,或从粉煤灰渗滤液中回收有价值的稀土元素和超塑化结构材料。近年来,由于使用地质聚合物作为硅酸盐水泥替代品的重大发展,粉煤灰被广泛用作混凝土或地质聚合物中的辅助胶凝材料。
3.粉煤灰的活性是其能作为辅助胶凝材料的关键,目前现有对粉煤灰活性测试的方法主要有依赖于x射线衍射(xrd)试验,其操作复杂,耗时及成本高且需要专业知识,因此测试尚未大规模推广,严重阻碍了粉煤灰的资源化利用。因此,对粉煤灰活性的预测需要一种更为高效准确的技术方法,来为粉煤灰的回收利用提供一定的指导意义。
技术实现要素:
4.本发明的目的是为了克服现有技术中的不足,提供一种利用机器学习预测粉煤灰中玻璃相含量的方法,利用机器学习方法对粉煤灰中玻璃相含量进行快速、高精度、高准确率的预测,具有广泛的实际应用意义,从而为我国固废利用领域提供有力的技术支撑。
5.本发明的目的是通过以下技术方案实现的:
6.一种利用机器学习预测粉煤灰中玻璃相含量的方法,包括以下步骤:
7.p1.确定影响粉煤灰玻璃相含量的化学组成因素,进行特征选择得到有效特征;
8.p2.收集粉煤灰有效特征及玻璃相含量数据,构成样本数据集;
9.p3.将样本数据集内的数据进行预处理后划分为训练集和测试集;
10.p4.选择并建立机器学习算法模型;
11.p5.在训练集上通过优化算法确定机器学习算法模型的超参数,得到最优粉煤灰玻璃相含量预测模型,用测试集验证最优粉煤灰玻璃相含量预测模型的效果。
12.进一步的,步骤p1中,影响粉煤灰玻璃相含量的化学组成因素包括sio2、al2o3、fe2o3、cao、mgo、na2o、k2o、p2o5;每个化学组成因素的含量能够反映粉煤灰中的玻璃相含量。
13.进一步的,步骤p2中粉煤灰有效特征及玻璃相含量数据的收集来源包括室内试验、文件调研。
14.进一步的,步骤p3中数据预处理的方法有数据清理、数据集成、数据变换和数据归约;数据预处理完成后,将处理好的数据划分为训练集和测试集,训练集用来对最优粉煤灰玻璃相含量预测模型进行训练,而测试集则用来对最优粉煤灰玻璃相含量预测模型进行评估,其中训练集和测试集大小通过收敛性测试得到。
15.进一步的,步骤p4中,根据划分后的训练集建立机器学习算法模型,机器学习算法模型包括随机森林、决策树、神经网络、支持向量机。
16.进一步的,步骤p5中,将训练集通过优化算法确定机器学习算法模型的超参数,得到了粉煤灰玻璃相含量的最优粉煤灰玻璃相含量预测模型,其中的优化算法包括梯度下降法、牛顿法、人工蜂群算法和启发式优化方法;然后采用测试集验证最优粉煤灰玻璃相含量预测模型的效果;测试最优粉煤灰玻璃相含量预测模型效果的方法有均值误差(mse)、均方根误差(rmse)、平均绝对误差(mae)、r方(r-squared)。
17.与现有技术相比,本发明的技术方案所带来的有益效果是:
18.1.本发明是基于机器学习的方法,利用粉煤灰化学组成-玻璃相含量数据集构建最优粉煤灰玻璃相含量预测模型,将该预测模型应用于实际中,可以对不同化学物质组成的粉煤灰的玻璃相含量进行高准确、高效、快速的预测。对于粉煤灰的综合利用和固废处理领域具有指导作用。
19.2.本发明具有效率高、经济环保、准确性高的优点,弥补了传统的xrd方法周期长、昂贵的缺点。本发明的实际应用性强大,操作也快速便利,仅需要对训练集进行训练,就可以建立高准确、高效的预测模型,其经济性和实用性十分显著。
附图说明
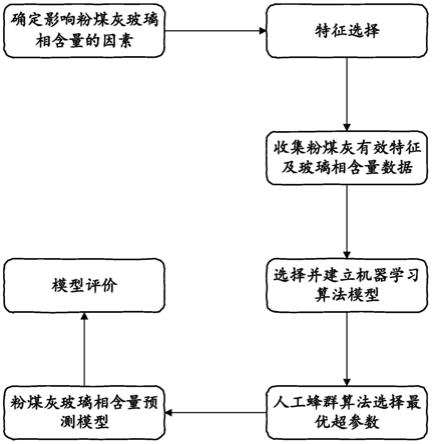
20.图1是具体实施例中基于机器学习预测粉煤灰玻璃相含量的方法的流程示意图。
21.图2是玻璃相含量的预测值和真实值之间的拟合结果图。
具体实施方式
22.以下结合附图和具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
23.如图1所示,本发明实例所提供的是一种基于机器学习预测粉煤灰玻璃相含量的方法,具体实施方式采取以下步骤:
24.1.根据已知影响粉煤灰中玻璃相含量的因素确定特征值,本实例将粉煤灰中的8种氧化物作为特征值,其中特征值包括sio2,al2o3,fe2o3,cao,mgo,na2o,k2o和p2o5。它们是组成粉煤灰的主要化学物质,其含量会影响粉煤灰中的玻璃相含量。
25.2.根据步骤1所确定的特征,本实例收集了123个粉煤灰的样本,用x射线荧光光谱分析法(xrf)测量粉煤灰氧化物的质量分数,用x射线衍射方法(xrd)测量粉煤灰中玻璃相的质量分数。将这些粉煤灰样本中的氧化物的质量分数作为数据集中的特征值,将玻璃相的质量分数作为目标值,由此来构建出一个完整的样本数据集。
26.3.由步骤2收集来的样本数据集需要进行数据预处理来提高后续建模过程的准确率和效率,由于样本数据集不完整,存在缺失值,因此采用均值来填补缺失值,提高数据的可用性。将样本数据集分为训练数据集和测试数据集,本实施例中划分训练集和数据集的
评估标准是相关系数r。计算r的公式如下:
[0027][0028]
其中r∈[-1,1],cov(x,y)是x和y的协方差,var[x]是x的方差,var[y]是y的方差;
[0029]
使用的训练集过小可能会导致模型性能低下,但使用过大的训练集会导致过拟合和泛化能力下降。通过计算比较,当训练集大小为85%,测试集大小为15%时,相关系数r在训练集和测试集中相对最优。因此数据集的划分标准为训练集大小占85%,测试集大小占15%。
[0030]
4.由步骤3对数据集的划分,训练数据集x_train=(
‘
sio2的质量分数’,
‘
al2o3的质量分数’,
‘
fe2o3的质量分数’,
‘
cao的质量分数’,
‘
mgo的质量分数’,
‘
na2o的质量分数’,
‘
k2o的质量分数’,
‘
p2o5的质量分数’),训练目标值y_train=(
‘
玻璃相的质量分数’),本实例选择随机森林回归算法作为机器学习算法模型,流程如图1所示。
[0031]
5.为了对机器学习算法模型进行优化处理,本实例采用人工蜂群算法(abc)对机器学习算法模型的超参数进行优化,选择种群规模为200,最大迭代次数为50。为了避免结果的随机性,采用5折交叉验证。重复对数据集划分20次左右,在节省计算资源的前提下,可以获得训练集上比较稳定的r值。因此,取r的平均值作为一次迭代的结果,然后继续迭代直到得到最优解,以此构建最终的最优粉煤灰玻璃相含量预测模型,以下简称为rf-abc模型。基于训练集建立的rf-abc模型需要通过测试集的数据进行评估。本实例不仅采用了上述相关系数r,还采用了平均绝对误差(mae)、均方根误差(rmse)和r2三个评价指标来评价rf-abc模型的泛化能力,以保证评价结果的合理性。mae计算所有样本的预测值与真实值之差的绝对平均值,而rmse则对每个样本的预测值与真实值之差进行平方并取平均值,然后取结果的平方根。这两个指标的值越小,拟合效果越好。r2为决定系数,其值反映了预测数据变异解释占总变异的比例。正常值范围是[0,1],越接近1,模型拟合越好。mae、rmse和r2分别由下列公式解释。
[0032][0033][0034][0035]
n是样本的数量,yi是实际值,是预测值,是样本的平均值。
[0036]
6.图2为玻璃相真实值和预测值之间的拟合结果图,在训练集和测试集中真实值和预测值的拟合效果都较好,在训练集中的r值为0.953,在测试集中的r值为0.733。因此该rf-abc模型的模拟效果较好
[0037]
最后需要指出的是:以上实例仅用以说明本发明的计算过程,而非对其限制。尽管参照前述实例对本发明进行了详细的说明,本领域的普通技术人员应当理解,其依然可以对前述实例所记载的计算过程进行修改,或者对其中部分参数进行等同替换,而这些修改
或者替换,并不使相应计算方法的本质脱离本发明计算方法的精神和范围。
[0038]
本发明并不限于上文描述的实施方式。以上对具体实施方式的描述旨在描述和说明本发明的技术方案,上述的具体实施方式仅仅是示意性的,并不是限制性的。在不脱离本发明宗旨和权利要求所保护的范围情况下,本领域的普通技术人员在本发明的启示下还可做出很多形式的具体变换,这些均属于本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1