一种适用于早期发现、早期预测或早期诊断重度慢阻肺的生物标志物及其应用和筛选方法与流程
文档序号:30754155发布日期:2022-07-13 10:04阅读:2055来源:国知局
导航: X技术> 最新专利>测量装置的制造及其应用技术
1.本发明属于蛋白组-代谢组学技术领域,具体涉及一种适用于早期发现、早期预测或早期诊断重度慢阻肺的生物标志物及其应用和筛选方法。
背景技术:
2.慢性阻塞性肺疾病(chronic obstructive pulmonary disease,copd,慢阻肺)是一种严重危害人类健康的重要慢性呼吸系统疾病。研究估计2017年全球慢阻肺的患病率为3.92%(95%ci为3.52%-4.32%),慢阻肺导致的死亡率估计为42/100,000(占所有原因死亡的4.72%),估计伤残调整寿命年(dalys)率为1068.02/100,000(2017年全球疾病负担研究报告)。2020年,慢阻肺已成为全球第三大致死病因,是全球范围内致残率和死亡率增加的主要原因之一,导致严重的经济和社会负担,且这种状况日益加重,但重度慢阻肺的早期发现和早期治疗仍面临严重挑战。重度慢阻肺对患者的生命质量、肺功能、疾病进程和社会经济负担均产生严重的负面影响,也是慢阻肺患者医疗费用居高不下的主要原因。因此,早期发现、早期诊断和早期治疗是临床上的一项重大和艰巨的医疗任务。
3.目前,重度慢阻肺的定义和诊断均为临床症状的描述,缺乏特异、灵敏的生物标志物、缺乏量化指标且实验室检测方法均存在不同程度的敏感性差异等问题,难以满足临床诊断要求,易造成漏诊和误诊。因此,寻求新的诊断方法及筛选有效的重度慢阻肺早期发现和早期诊断的标志物以促进慢阻肺的快速、准确诊断对重度慢阻肺的控制至关重要。
4.蛋白组学技术和代谢组学技术是筛选疾病诊断标志物的经典方法,随着蛋白组学和代谢组学相关技术的发展和对慢阻肺的诊断有了进一步的认知,两者在临床的应用逐渐广泛。蛋白组学以全面的蛋白质性质研究为基础,在蛋白质水平对疾病机理、细胞模式、功能联系等方面进行探索,基于高度敏感性和精确性的串联质谱方法,不需要凝胶,就可以获得相对和绝对定量的蛋白质结果。代谢组学主要通过检测小分子代谢物的变化来获得生物体内代谢产物随时间以及病理生理进程的动态变化信息,包括糖、脂质、氨基酸、维生素等。代谢物作为细胞生理活动的最终产物,能真实灵敏地反映细胞的功能状态。重度慢阻肺在发生和发展的过程中必然引起内源性小分子代谢产物的特征性改变,而借助于先进的分离、分析及计算手段的蛋白组学和代谢组学,恰好具有从整体上区分不同病理生理条件下的特征蛋白质、代谢物的能力和优势,可以从整体上探讨这一复杂的临床综合征的发病机制。
5.尽管肺功能检查是诊断慢阻肺的金标准,但其操作相对复杂、慢阻肺患者存在明显的异质性及重症慢阻肺患者依从性、耐受性差等问题,导致我国慢阻肺患者中确诊前接受过肺功能检查者所占比例较低仅6.5%(冉丕鑫等,中华结核和呼吸杂志,2007)。作为一种慢性病,目前,重度慢阻肺的早期发现和早期诊断仍有不足,借助蛋白组学,依托高通量、高灵敏度的蛋白分析平台,可定性或定量分析重度慢阻肺患者内源性蛋白小分子,寻找出特异性的生物标志物,以便早期诊断、早期干预。蛋白组学在慢阻肺疾病诊断、机制探讨、证
候诊断及药效机制等方面的研究已有开展,但目前仍处于起步阶段、且存在价格昂贵及重复性验证不足等问题。未来随着蛋白组学数据库日趋完善,分析方法进一步成熟、辨证分型逐步规范、动物模型更加稳定可重复,蛋白组学在重度慢阻肺患者研究中的应用将会越来越深入,有利于深入了解慢阻肺的发病机制,更加有助于疾病的早期发现和早期诊断,在疾病诊断的客观化、规范化及药效机制探索等方面具有广阔的前景。
技术实现要素:
6.本发明的目的在于提供一种适用于早期发现、早期预测或早期诊断重度慢阻肺的生物标志物。
7.本发明的目的还在于提供上述生物标志物在制备用于早期发现、早期预测或早期诊断重度慢阻肺风险的产品中的应用。
8.本发明的最后一个目的在于提供上述生物标志物的筛选方法。
9.本发明的上述第一个目的可以通过以下技术方案来实现:一种适用于早期发现、早期预测或早期诊断重度慢阻肺的生物标志物,所述生物标志物为蛋白群体生物标志物、代谢物群体生物标志物或蛋白组-代谢组联合群体生物标志物,其中:
10.所述蛋白群体生物标志物为类粘蛋白(alpha-1-acid glycoprotein,orm1)、过氧化还原酶2 (peroxiredoxin-2,prdx2)和钙粘着蛋白5(cadherin5,cdh5);
11.所述代谢物群体生物标志物为十六酰胺乙醇(palmitoylethanolamide)、癸酰基左旋肉碱 (decanoyl-l-carnitine)、甜菜碱(betaine)、茶碱(theophylline)和次黄嘌呤(hypoxanthine);
12.所述蛋白组-代谢组联合群体生物标志物为十六酰胺乙醇(palmitoylethanolamide)、茶碱 (theophylline)和次黄嘌呤(hypoxanthine)三个代谢物和一个钙粘着蛋白5(cadherin5,cdh5)。
13.本发明的上述第二个目的可以通过以下技术方案来实现:上述的生物标志物在制备用于早期发现、早期预测或早期诊断重度慢阻肺风险的产品中的应用。
14.作为本发明的其中一种优选的技术方案,所述蛋白群体生物标志采用类粘蛋白、过氧化还原酶2和钙粘着蛋白5这三种蛋白作为联合指标p3-pro,用于早期发现、早期预测或早期诊断重度慢阻肺风险的产品中。
15.作为本发明的其中一种优选的技术方案,所述代谢物群体生物标志物采用三种阳离子代谢物和两种阴离子代谢物作为联合指标p5-met,其中所述阳离子代谢物为十六酰胺乙醇、癸酰基左旋肉碱和甜菜碱,所述阴离子代谢物为茶碱和次黄嘌呤,用于早期发现、早期预测或早期诊断重度慢阻肺风险的产品中。
16.作为本发明的其中一种优选的技术方案,所述蛋白组-代谢组联合群体生物标志物采用三种代谢物-十六酰胺乙醇(palmitoylethanolamide)、茶碱(theophylline)、次黄嘌呤(hypoxanthine) 三个代谢物和一个蛋白-钙黏着蛋白5(cadherin-5,cdh5)作为联合指标p4-met+pro,用于早期发现(早期辅助筛查)、早期预测或早期诊断重度慢阻肺风险的产品中。
17.所述产品包括试剂、试剂盒等。
18.所述产品包括通过高效液相色谱、高效质谱(lc-ms/m)等进行检测所述生物标志
物为蛋白群体生物标志物、代谢物群体生物标志物或蛋白组-代谢组联合群体生物标志物及其含量或者浓度的试剂等。
19.本发明的上述最后一个目的可以通过以下技术方案来实现:上述生物标志物的筛选方法,所述蛋白群体生物标志物的筛选中,
20.采用多因素logistic回归方法建立预测模型,预测模型:y(慢阻肺=1|健康对照=0)=
ꢀ‑
10.323+2.354*类粘蛋白+6.834*钙粘着蛋白5+1.694*过氧化还原酶2;
21.所述代谢物群体生物标志物的筛选中,
22.采用多因素logistic回归方法建立预测模型,预测模型:y(慢阻肺=1|健康对照=0)=
ꢀ‑
14.645+(0.41*十六酰胺乙醇+1.41*癸酰基左旋肉碱-4.83*甜菜碱+0.15*茶碱+1.17*次黄嘌呤)/10000;
23.所述蛋白组-代谢组联合群体生物标志物的筛选中,
24.采用多因素logistic回归方法建立预测模型,联合判断建立预测模型:y(慢阻肺=1|健康对照=0)=-17.934+(0.46*十六酰胺乙醇+0.13*茶碱+0.77*次黄嘌呤)/10000+8.340* 钙粘着蛋白5。
25.其中:
26.(一)蛋白群体生物标志物的筛选方法,包括以下步骤:
27.(1)收集重度慢阻肺患者和健康人群外周静脉血样品;
28.(2)将每个分析样品采用包括tmt高通量蛋白组测序、高效液相色谱分级技术和基于质谱的prm靶向蛋白组验证,对样品进行定量蛋白组的研究,内容包括蛋白提取、胰酶酶解、 tmt标记、高效液相色谱分级、液相色谱-质谱串联分析、数据库搜索和生物信息学分析;
29.(3)根据步骤(2)中获取的数据建立预测模型,筛选出潜在的重度慢阻肺疾病早期发现、预测或诊断的蛋白群体生物标志物类粘蛋白、过氧化还原酶2和钙粘着蛋白5。
30.本发明中的蛋白群体生物标志物通过以下方法获得:将tmt标记、高效液相色谱分级技术、基于质谱的定量蛋白质组学技术联合prm靶向蛋白质组验证等一系列前沿技术方法的有机结合,对样品进行定量蛋白组的研究,内容包括蛋白提取、胰酶酶解、tmt标记、高效液相色谱分级、液相色谱-质谱串联分析、数据库搜索和生物信息学分析等。
31.本发明通过从蛋白质组层面揭示重度慢阻肺的生物标志物,发现适用于重度慢阻肺早期发现、早期预测、早期诊断的新型生物标志物或生物标志物群:应用tmt高通量蛋白质组学方法+prm靶向蛋白质组验证,对临床样品的蛋白表达进行比较分析,结合生物信息学,选出潜在的生物标志物包括:类粘蛋白、过氧化还原酶2和钙粘着蛋白5。
32.根据我国人群生物标志物的特征通过单变量分析及多变量间不同组合分析,以灵敏度和特异度为参数,结合曲线下面积(auc)建立重度慢阻肺风险预测模型,用于重度慢阻肺发病风险的评估及分子诊断。
33.(二)代谢物群体生物标志物的筛选方法,包括以下步骤:
34.(1)收集样品:收集重度慢阻肺患者和健康人群外周静脉血样品;
35.(2)代谢组学测序:采用基于液相色谱-质谱/质谱联用(lc-ms/ms)分析的非靶向代谢组学对样品进行分析,获得一级质谱和二级质谱数据,采用xcms(基于r语言设计的程序包(r package))对数据进行峰提取和代谢物鉴定,主要步骤包括样品预处理、代谢物提
取、 lc-ms全扫描检测、数据预处理、统计分析及差异物结构鉴定;
36.(3)数据分析:对步骤(2)获取的数据,先进行基础分析,接着进行单变量分析,再进行显著性差异代谢物分析及生物信息学分析;
37.(4)建立预测模型,并通过逐步回归法筛选代谢物指标,获得适用于重度慢阻肺早期发现、早期预测或早期诊断的代谢物群体生物标志物十六酰胺乙醇、癸酰基左旋肉碱、甜菜碱、茶碱和次黄嘌呤。
38.本发明通过将高效质谱(lc-ms/m)等一系列前沿技术方法的有机结合,对血清样品进行非靶向代谢组学研究,内容包括样品制备、质控样品(qc)制备、样品lc-ms/ms质谱分析、数据分析和预测模型建立等。
39.(三)蛋白组-代谢组联合群体生物标志物,包括以下步骤:
40.(1)样品收集:收集重度慢性阻塞性肺患者和健康人群外周静脉血样品;
41.(2)tmt高通量蛋白组测序+prm靶向蛋白组验证:将每个分析样品采用包括tmt 高通量蛋白组测序、高效液相色谱分级技术和基于质谱的prm靶向蛋白组验证,对样品进行定量蛋白组的研究,内容包括蛋白提取、胰酶酶解、tmt标记、高效液相色谱分级、液相色谱-质谱串联分析、数据库搜索和生物信息学分析,通过逐步回归法筛选蛋白指标,并建立预测模型,筛选出潜在的蛋白群体生物标志物类粘蛋白、过氧化还原酶2和钙粘着蛋白5;
42.(3)代谢组学测序:采用基于液相色谱-质谱/质谱联用(lc-ms/ms)分析的非靶向代谢组学对样品进行分析,获得一级质谱和二级质谱数据,采用xcms对数据进行峰提取和代谢物鉴定,主要步骤包括样品预处理、代谢物提取、lc-ms全扫描检测、数据预处理、统计分析及差异物结构鉴定,通过逐步回归法筛选代谢物指标,并建立预测模型,获得代谢物群体生物标志物十六酰胺乙醇、癸酰基左旋肉碱、甜菜碱、茶碱和次黄嘌呤;
43.(4)联合蛋白组-代谢组预测重度慢阻肺风险:联合蛋白群体生物标志物和代谢物群体生物标志物,将十六酰胺乙醇、茶碱、次黄嘌呤三个代谢物和钙粘着蛋白5,作为联合指标 p4-met+pro,得到蛋白组-代谢组联合群体生物标志物。
44.本发明通过将tmt标记、高效液相色谱分级技术、高效质谱(lc-ms/m)、基于质谱的定量蛋白组学技术联合prm靶向蛋白组验证等一系列前沿技术方法的有机结合,对血清样品进行定量蛋白组学研究和非靶向代谢组学研究,内容包括蛋白提取、胰酶酶解、tmt标记、高效液相色谱分级、液相色谱-质谱串联分析、lc-ms/m、数据库搜索、生物信息学分析和模型建立等。
45.进一步的,本发明提供的生物标志物的筛选方法,包括以下步骤:
46.(一)蛋白群体生物标志物的筛选
47.(1)信息收集;
48.(2)样本采集:采集重度慢阻肺患者和健康人群外周静脉血样本;
49.(3)tmt高通量蛋白组测序+prm靶向蛋白组验证:将每个分析样本采用包括tmt高通量蛋白组测序、高效液相色谱分级技术和基于质谱的prm靶向蛋白组验证,对样本进行定量蛋白组的研究,内容包括蛋白提取、胰酶酶解、tmt标记、高效液相色谱分级、液相色谱
‑ꢀ
质谱串联分析、数据库搜索和生物信息学分析;
50.通过多次全蛋白定量重复实验,分别得到了每个样本在多次重复中的定量值:
51.第一步:计算比较组中两个样本间蛋白的差异表达量,首先计算出每个样本在多
次重复中定量值的平均值,然后再计算两个样本之间平均值的比值,该比值作为比较组最终的差异表达量;
52.第二步:计算该蛋白在两个样本中的差异表达显著性p-value,首先将各个样本的相对定量值取log2,然后用双样本双尾t检验方法计算p-value,当p-value<0.05时,以差异表达量变化超过1.2作为显著上调的变化阈值,小于1/1.2作为显著下调的变化阈值;
53.第三步:对显著差异表达的蛋白进一步做prm靶向蛋白组验证;
54.(4)数据分析
55.(4.1)基础分析:采用r进行统计学分析,连续变量服从正态分布时以均数
±
标准差表示,非正态分布时以p50、p25或p75表示,分类变量以频率(%)表示,组间比较时连续变量采用非配对的student-t检验或mann-whitney u非参数检验,分类变量采用pearson卡方检验或fisher精确检验;
56.(4.2)生物信息学分析:
57.从基因本论(gene ontology,以下简称go)、蛋白结构域(protein domain)、京都基因与基因组百科全书(kyoto encyclopedia of genes and genomes,kegg)、cog功能分类以及亚细胞结构定位、聚类分析、蛋白互作网络各方面进行详细的分析,目的是发现差异表达蛋白是否在某些功能类型上有显著性的富集趋势,对于富集检验得到的p-value通过图形方式展现差异蛋白显著富集的功能分类和通路;
58.(5)数据结果
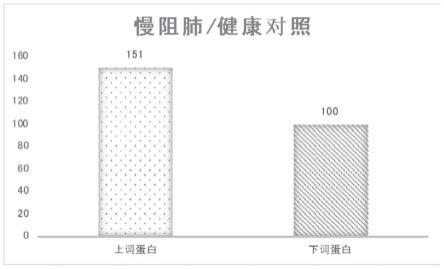
59.结果表明一共鉴定到1919.0个蛋白质,其中1432.0个蛋白质包含定量信息,如果以1.2 倍为差异表达变化阈值,以统计学检验t-test p-value<0.05为显著性阈值,那么在定量到的蛋白质中,发现在avsb比较组中有151个蛋白表达发生上调,100个蛋白表达发生下调,基于上述数据,对所有鉴定到的蛋白质进行了系统的生物信息学分析,并且对所有差异表达蛋白进行了功能分类、功能富集及基于功能富集的聚类分析;
60.(6)建立预测模型
61.采用多因素logistic回归方法建立预测模型,并根据最小赤池信息标准选择最佳的模型参数,计算优势比和95%可信区间,绘制预测模型的列线图,同时绘制校准曲线以显示列线图的预测精度,以及绘制预测模型的受试者工作特征曲线,并获得曲线下面积及其95%ci,再应用 z统计量比较建模组和验证组的auc(roc曲线下面积),所有统计检验均为双侧检验,以p <0.05被认为具有统计学差异;
62.(6.1)对重度慢阻肺和健康对照样本的蛋白表达进行比较分析,结合生物信息学,选出潜在的重度慢阻肺疾病标志物:类粘蛋白、过氧化还原酶2及钙粘着蛋白5;
63.(6.2)根据我国人群生物标志物的特征通过单变量分析及多变量间不同组合分析,以灵敏度和特异度为参数,结合auc建立重度慢阻肺风险预测模型,用于重度慢阻肺发病风险的评估及分子诊断;
64.通过逐步回归法筛选蛋白指标,最终筛选后的差异蛋白包括类粘蛋白、过氧化还原酶2及钙粘着蛋白5,其预测重度慢阻肺的准确度分别为0.690,0.769及0.863,但三种蛋白作为联合指标p3-pro,其推断重度慢阻肺的准确度为0.936,其相应的灵敏度和特异度分别为0.88和0.90;
65.预测模型:y(慢阻肺=1|健康对照=0)=-10.323+2.354*类粘蛋白+6.834*钙粘
着蛋白5+1.694*过氧化还原酶2;
66.(二)代谢物群体生物标志物的筛选
67.(1)信息收集;
68.(2)样本收集:收集重度慢阻肺疾病患者和健康人群外周静脉血样本;
69.(3)代谢组学测序:采用基于液相色谱-质谱/质谱联用分析的非靶向代谢组学对样本进行分析,获得一级质谱和二级质谱数据,采用xcms对数据进行峰提取和代谢物鉴定,主要步骤包括样品预处理、代谢物提取、lc-ms全扫描检测、数据预处理、统计分析及差异物结构鉴定;
70.(4)数据分析:
71.(4.1)基础分析:采用r进行统计学分析,连续变量服从正态分布时以均数
±
标准差表示,非正态分布时以p50、p25或p75表示,分类变量以频率(%)表示,组间比较时连续变量采用非配对的student-t检验或mann-whitney u非参数检验,分类变量采用pearson卡方检验或 fisher精确检验;
72.(4.2)单变量分析:利用单变量分析显示两样本间代谢物变化的显著性,筛选出潜在的标志代谢物;
73.(4.3)显著性差异代谢物分析:根据opls-da模型得到的变量权重值(vip)米获取差异代谢物,以vip>1为筛选标准,初步筛选出各组间的差异物,进一步采用单变量统计分析,验证差异代谢物是否具有显著性,选择同时具有多维统计分析vip>1和单变量统计分析p value<0.05的代谢物,作为具有显著性差异的代谢物,而vip>1且0.05<p value<0.1则作为差异代谢物;
74.(4.4)生物信息学分析:原始数据经proteowizard转换成.mzxml格式,然后采用xcms 程序进行峰对齐、保留时间校正和提取峰面积,代谢物结构鉴定采用精确质量数匹配和二级谱图匹配的方式,检索数据库,数据经pareto-scaling预处理后,进行多维统计分析,包括无监督主成分分析(pca)分析,有监督偏最小二乘法判别分析(pls-da)和正交偏最小二乘法判别分析(opls-da),单维统计分析包括student’s t-test和变异倍数分析,r软件绘制火山图。
75.(5)数据结果
76.采用多因素logistic回归方法建立预测模型,并根据最小赤池信息标准选择最佳的模型参数,计算优势比(odds ratio,or)和95%可信区间(ci),绘制预测模型的列线图;
77.共鉴定到阳离子代谢物峰数目3720个,其中模式差异代谢物24个,阴离子代谢物峰数目 3694个,其中模式差异代谢物22个,共发现13个显著差异性代谢物,包括7个阳离子和6 个阴离子,其中:
78.7个阳离子为:十六酰胺乙醇(palmitoylethanolamide);反式-脱氢异雄甾酮(trans-dehydroandrosterone);癸酰基左旋肉碱(decanoyl-l-camitine);甜菜碱(betaine);假尿嘧啶核苷(pseudouridine);莰酮(camphor);1-硬脂酰基-2-油酰基-sn-甘油3-磷酸胆碱 (1-stearoyl-2-oleoyl-sn-glycerol3-phosphocholine(sopc))。
79.6个阴离子为:茶碱(theophylline);l-异亮氨酸(l-isoleucine);硫酸孕烯醇酮(pregnenolonesulfate);壬二酸(azelaic acid);舒尼替尼(sunitinib);次黄嘌呤(hypoxanthine)。
80.(6)建立预测模型
81.通过单变量分析及多变量间不同组合分析,以灵敏度和特异度为参数,结合曲线下面积 (auc)建立重度慢阻肺疾病风险预测模型,用于重度慢阻肺发病风险的评估及分子诊断,结果如下:
82.(6.1)通过阳离子代谢物预测重度慢阻肺疾病分险:单变量分析发现,显著差异的代谢物十六酰胺乙醇、反式-脱氢异雄甾酮、癸酰基左旋肉碱及甜菜碱推测重度慢阻肺的准确度分别为0.784、0.742、0.729及0.715,但四种阳离子代谢物作为联合指标p4-pos-met,其推断重度慢阻肺的准确度为0.977,其相应的灵敏度和特异度分别为0.83和0.85;
83.(6.2)通过阴离子代谢物预测重度慢阻肺疾病分险:单变量分析发现,显著差异的代谢物茶碱、次黄嘌呤及l-异亮氨酸推测重度慢阻肺的准确度分别为0.740、0.639及0.785;但三种阴离子代谢物作为联合指标p3-neg-met,其推断重度慢阻肺的准确度为0.959,其相应的灵敏度和特异度分别为0.90和0.90;
84.(6.3)联合阳离子和阴离子代谢物预测重度慢阻肺疾病分险:通过逐步回归法筛选代谢物指标,筛选后的差异代谢物包括十六酰胺乙醇、癸酰基左旋肉碱、甜菜碱、茶碱及次黄嘌呤,其预测重度慢阻肺疾病的准确度分别为0.784、0.729、0.715、0.740及0.724,为进一步提高疾病预测的准确度,将五种代谢物作为联合指标p5-met,其推断重度慢阻肺的准确度为0.970,其相应的灵敏度和特异度分别为0.88和0.93;
85.预测模型:y(慢阻肺=1|健康对照=0)=-14.645+(0.41*十六酰胺乙醇+1.41*癸酰基左旋肉碱-4.83*甜菜碱+0.15*茶碱+1.17*次黄嘌呤)/10000;
86.(三)蛋白组-代谢组联合群体生物标志物的筛选
87.步骤(1)~(3)同(一)蛋白群体生物标志物的筛选中的步骤(1)~(3);
88.步骤(4)同(二)代谢物群体生物标志物的筛选中的步骤(3);
89.步骤(5)同(一)蛋白群体生物标志物的筛选中的步骤(4);
90.步骤(6)同(二)代谢物群体生物标志物的筛选中的步骤(4);
91.(7)蛋白数据结果:同(一)蛋白群体生物标志物的筛选中的步骤(5);
92.(8)代谢物数据结果:同(二)代谢物群体生物标志物的筛选中的步骤(5);
93.(9)建立预测模型
94.(9.1)建立蛋白组预测模型:同(一)蛋白群体生物标志物的筛选中的步骤(6);
95.(9.2)建立代谢物预测模型:同(二)代谢物群体生物标志物的筛选中的步骤(6);
96.(9.3)联合蛋白组和代谢组预测重度慢阻肺风险:为进一步提高疾病预测的准确度,将十六酰胺乙醇、茶碱、次黄嘌呤三个代谢物和钙粘着蛋白5,作为联合指标p4-met+pro,其推重度慢阻肺的准确度为0.977,其相应的灵敏度和特异度分别为0.94和0.95;
97.联合判断建立预测模型:y(慢阻肺=1|健康对照=0)=-17.934+(0.46*十六酰胺乙醇 +0.13*茶碱+0.77*次黄嘌呤)/10000+8.340*钙粘着蛋白5。
98.本发明具有以下优点:
99.(1)目前,医院对于重度慢阻肺特异性诊断依旧处于缺乏可靠的生物标志物这一现状,蛋白组学以及代谢组学改变了单一标志物检测的传统思路,以蛋白群体生物标志物、代谢物群体生物标志物或蛋白组-代谢组联合群体生物标志物作为“模式标记物”来诊断疾病,具有独特的优势;
100.(2)本发明的优点是采用外周血血清样品对重度慢阻肺患者和健康对照进行蛋白组学、代谢组学分析,筛选出差异表达的蛋白和代谢物,并对差异表达的蛋白和代谢物进行蛋白注释、功能富集等,对有研究价值的蛋白和代谢物进行深入研究,针对重度慢阻肺缺乏有效治疗措施这一现状提供有价值的参考;
101.(3)本发明通过tmt高通量蛋白质组学和prm靶向蛋白质验证方法相结合,对患者和相应的健康对照血清进行蛋白特征分析,筛选出潜在的重度慢阻肺特异性差异蛋白,建立的早期预测模型其准确性超过90%,灵敏度和特异度(分别为88%和90%)也有较高的水平;本发明利用代谢组学找到重度慢阻肺的特异性差异代谢产物,其准确性超过90%,灵敏度和特异度也有较高的水平;本发明通过tmt高通量蛋白组学方法和prm靶向蛋白组对患者血清进行蛋白组学分析,筛选出潜在的慢阻肺蛋白标志物,联合代谢组学找到重度慢阻肺的特异性差异代谢产物建立预测模型,其准确性达97.7%,灵敏度和特异度分别为94%和95%;
102.(4)本发明提供了一种适合于重度慢阻肺早期发现和早期诊断的标志物,以及该诊断标志物在重度慢阻肺诊断中的应用,具有较高临床使用和推广价值,为临床治疗提供指导思路,以解决上述背景技术中提出的问题。
附图说明
103.图1是本发明实施例1中tmt定量蛋白组学技术路线图;
104.图2是本发明实施例1中质谱鉴定到肽段的长度分布;
105.图3是本发明实施例1中质谱仪的质量精度分布;
106.图4是本发明实施例1中质谱数据结果基本统计图;
107.图5是本发明实施例1中不同比较组中差异表达蛋白数量分布柱形图;
108.图6是本发明实施例1中差异表达蛋白定量火山图;
109.图7是本发明实施例1中的蛋白碎片离子峰面积分布图(以p02763蛋白为例);
110.图8是本发明实施例1中prm靶向蛋白质定量结果图;
111.图9是本发明实施例1中基于代谢组组学技术对样品进行代谢物鉴定的工作流程示意简图;
112.图10是本发明实施例1中qc样品正离子模式tic重叠图谱;
113.图11是本发明实施例1中qc样品负离子模式tic重叠图谱;
114.图12是本发明实施例1中正、负离子模式下样品的pca得分图,a图是正离子,b图是负离子;
115.图13是本发明实施例1中正、负离子模式下qc样品相关性图谱。
具体实施方式
116.下面结合具体实施例详细说明本发明的技术方案,以便本领域技术人员更好理解和实施本发明的技术方案。实施例中所用试剂或材料,如未特别说明,均来源于商业渠道。
117.实施例1
118.本实施例提供的适用于早期发现、早期预测或早期诊断重度慢阻肺的生物标志物,生物标志物为蛋白群体生物标志物、代谢物群体生物标志物或蛋白组-代谢组联合群体
生物标志物,其中:
119.蛋白群体生物标志物为类粘蛋白(alpha-1-acid glycoprotein,orm1)、过氧化还原酶2 (peroxiredoxin-2,prdx2)和钙粘着蛋白5(cadherin5,cdh5);
120.代谢物群体生物标志物包括十六酰胺乙醇(palmitoylethanolamide)、癸酰基左旋肉碱 (decanoyl-l-carnitine)、甜菜碱(betaine)、茶碱(theophylline)和次黄嘌呤(hypoxanthine);
121.蛋白组-代谢组联合群体生物标志物包括十六酰胺乙醇(palmitoylethanolamide)、茶碱 (theophylline)和次黄嘌呤(hypoxanthine)三个代谢物和一个钙粘着蛋白5(cadherin5,cdh5)。
122.上述生物标志物可以在制备用于早期发现、早期预测或早期诊断重度慢阻肺风险的产品中的应用。
123.蛋白群体生物标志采用类粘蛋白、过氧化还原酶2和钙粘着蛋白5这三种蛋白作为联合指标p3-pro,用于早期发现、早期预测或早期诊断重度慢阻肺风险的产品中。
124.或代谢物群体生物标志物采用三种阳离子代谢物和两种阴离子代谢物作为联合指标 p5-met,其中所述阳离子代谢物为十六酰胺乙醇、癸酰基左旋肉碱和甜菜碱,所述阴离子代谢物为茶碱和次黄嘌呤,用于早期发现、早期预测或早期诊断重度慢阻肺风险的产品中。
125.或蛋白组-代谢组联合群体生物标志物采用三种代谢物十六酰胺乙醇、茶碱、次黄嘌呤三个代谢物和一个钙黏着蛋白5作为联合指标p4-met+pro,用于早期发现、早期预测或早期诊断重度慢阻肺风险的产品中。
126.产品包括试剂、试剂盒等。
127.产品包括通过高效液相色谱、高效质谱(lc-ms/m)等进行检测所述生物标志物为蛋白群体生物标志物、代谢物群体生物标志物或蛋白组-代谢组联合群体生物标志物及其含量或者浓度的试剂等。
128.上述生物标志物的筛选方法,包括以下步骤:
129.一、对象和方法
130.1.样品来源
131.经广州医科大学附属第一医院伦理委员会批准及受试者知情同意,进行以下信息和样品采集。在取得患者同意后,收集广州医科大学附属第一医院2017年8月~2019年12月40例重症慢阻肺患者和40例肺功能正常的健康对照外周静脉血(采血时间均为清晨空腹状态),所有患者或健康对照均经肺功能检测证实。首先受试者(慢阻肺和健康对照)问诊后,对符合纳入、排除标准的受试者采集信息,包括以下内容:
132.(1.1)慢阻肺纳入标准:
133.中国汉族人群;40到80岁之间;稳定期患者(例如急性加重入院患者为出院后一个月左右样品);肺功能分级:慢性阻塞性肺病全球倡议组织(gold)iii-iv级(gold iii级:吸入支气管舒张剂之后fev1/fvc%<70%,fev1(1秒量)小于50%(实测占预计值的百分比),大于等于30%(实测占预计值的百分比),伴或不伴有慢性症状(咳嗽、咳痰、呼吸困难;goldiv:级吸入支气管舒张剂之后fev1/fvc%<70%,fev1(1秒量)小于30%(实测占预计值的百分比),伴有慢性症状(咳嗽、咳痰、呼吸困难或呼吸衰竭)。慢阻肺亚型分级采用吸气
‑ꢀ
呼
气高分辨率胸腔ct,判断患者肺实质及气道疾病的表现和严重程度。
134.(1.2)慢阻肺排除标准:
135.孕期女性(ct扫描可能对胎儿带来风险);肺疾病史:排除有除哮喘外的其他肺疾病史(如肺纤维化、支气管扩张症等);一个或以上肺叶切除病史;治疗中的进展期癌症,疑似肺癌(肺部性质未明的肿块);眼部手术患者;急性心肌梗死,其他急性期心脏病患者;接受胸腔或腹腔放射治疗的患者;不能耐受沙丁胺醇的患者;多重种族患者。
136.(1.3)健康对照纳入标准:
137.中国汉族人群;40到80岁之间;肺功能正常;对照需与慢阻肺患者在性别上大致配比。
138.(1.4)信息收集:受试者的年龄和性别等个人基本信息、环境暴露史(例如吸烟史、职业、危险因素暴露史等)、疾病家族史(例如癌症家族史、慢阻肺家族史和呼吸疾病家族史等);给予支气管扩张剂(沙丁胺醇)雾化吸入前后两次肺功能数据;药物治疗史;及临床检测信息。
139.2.样品采集
140.对符合纳入、排除标准的受试者采集外周静脉血5ml(促凝胶管),4℃、1600g、10分钟后取上清分装(300μl/每管),分装完成后尽快-80℃冰箱保存。
141.二、tmt高通量蛋白组学实施方案
142.1.主要试剂如下表1所示。
143.表1主要试剂
144.试剂供应商蛋白酶抑制剂calbiochem胰酶(trypsin)promega乙腈(acetonitrile)fisher chemical三氟乙酸(trifluoroacetic acid)sigma-aldrich甲酸(formic acid)fluka碘代乙酰胺(iodoacetamide)sigma二硫苏糖醇(dithiothreitol)sigma尿素(urea)sigma三乙基碳酸氢铵(teab)sigma超纯水(h2o)fisher chemicalbca试剂盒碧云天tmt标记试剂盒thermo乙二胺四乙酸(edta)sigma超纯水(h2o)fisher chemical
145.2.实验方法
146.(1)蛋白提取
147.样品从-80℃取出,4℃,12000g离心10分钟,去除细胞碎片,上清液转移至新的离心管,用thermo公司生产的试剂盒参照pierce
tm top 12 abundant protein depletion spin columnskit说明书去除高丰度蛋白。利用bca试剂盒进行蛋白浓度测定。
148.(2)蛋白浓度测定
149.取5μl蛋白样品,使用bca试剂盒测定蛋白浓度,方法如下:
150.1)将标准品按0μl、5μl、10μl、15μl、20μl加到酶标条的样品孔中,加样品稀释液补足到20μl,各检测3个复孔;
151.2)将5μl待测蛋白样品加到酶标条的样品孔中,加样品稀释液补足到20μl,各检测3个复孔;
152.3)各孔加入200μlbca工作液,37℃静置反应30分钟;
153.4)用酶标仪测定a570(最佳吸收波长为562nm,540-595nm之间的其他波长也可应用);
154.5)根据标准曲线和使用的样品体积计算出样品的蛋白浓度。
155.(3)sds-page
156.1)样品准备:根据蛋白浓度测定结果,每个样品取等量蛋白到离心管中,加入5μl4
×
loadingbuffer,再加入2%sds使体积为20μl;
157.2)上样:依次上样1μl预染蛋白marker和20μl蛋白样品,样品相邻的空白孔上样20μl1
×
loadingbuffer封闭;
158.3)电泳:浓缩胶15ma/gel置蛋白浓缩为一条线,约15min;分离胶35ma至dye电泳到胶底部;
159.4)染色和脱色:胶取出后于考马斯亮蓝g250染液中室温染色2h,然后加入脱色液,脱色至背景无色、条带清晰。银染:胶取出后经过固定、敏化、银染等步骤,再转入显色液中室温显色10min左右,待条带清晰、显色效果适中时,弃去显色液,加入终止液即可。
160.(4)胰酶酶解
161.各样品蛋白取等量进行酶解,加入适量标准蛋白,再加入二硫苏糖醇(dtt)使其终浓度为5mm,56℃还原30min。之后加入碘乙酰胺(iaa)使其终浓度为11mm,室温避光孵育15min。最后加入teab稀释尿素,确保浓度低于2m。以1∶50的比例(蛋白酶∶蛋白,m/m)加入胰蛋白酶,酶解过夜。再以1∶100的比例(蛋白酶∶蛋白,m/m)加入胰蛋白酶,继续酶解4h。
162.(5)标记
163.胰酶酶解的肽段用stratax(phenomenex)除盐后真空冷冻干燥。用0.5mteab溶解肽段,根据标记试剂盒操作说明进行肽段标记。简单的操作如下:标记试剂解冻后用乙腈溶解,与肽段混合后室温孵育2h,标记后的肽段混合后除盐,真空冷冻干燥,取1μg上质谱检测标记效率。
164.(6)液相色谱-质谱联用分析
165.肽段用液相色谱流动相a相(0.1%(v/v)甲酸水溶液)溶解后使用easy-nlc1000超高效液相系统进行分离。流动相a为含0.1%甲酸和2%乙腈的水溶液;流动相b为含0.1%甲酸和90%乙腈的水溶液。液相梯度设置:0~40min,6%-25%b;40~52min,25%-35%b;52~56min,35%-80%b;56~60min,80%b,流速维持在350nl/min。
166.肽段经由超高效液相系统分离后被注入nsi离子源中进行电离然后进qexactive
tm
plus质谱进行分析。离子源电压设置为2.0kv,肽段母离子及其二级碎片都使用高分辨的orbitrap进行检测和分析。一级质谱扫描范围设置为400-1080m/z,扫描分辨率设置为70,000;二级质谱orbitrap扫描分辨率设置为17,500。数据采集模式使用数据非
依赖型扫描(dia)程序,hcd 碰撞池的碎裂能量设置为27。一级质谱自动增益控制(agc)设置为3e6,最大离子注入时间(maxumum it)设置为50ms;二级质谱自动增益控制(agc)设置为1e5,最大离子注入时间(maxumum it)设置为180ms,隔离窗口(isolation window)设置为1.6m/z;
167.肽段参数:蛋白酶设置为trypsin[kr/p],最大漏切位点数设置为0,肽段长度设置为7-25 个氨基酸残基,设置半胱氨酸烷基化为固定修饰。transition参数:母离子电荷设置为2,3,子离子电荷设置为1,离子类型设置为b,y。碎片离子选择从第三个开始到最后一个,离子匹配的质量误差容忍度设置为0.02da。
[0168]
(7)数据库搜索
[0169]
质谱数据使用mascot 2.3进行搜索,在蛋白组数据库中进行匹配,匹配同时使用了反库以排除随机匹配造成的假阳性率(fdr)。蛋白酶设置为trypsin/p,肽段最小长度设置为7个氨基酸残基,最大漏切位点设置为2个,最大电荷数设置为5个。一级母离子的最大容忍质量误差设置为10ppm,二级子离子最大容忍质量误差设置为0.02da。固定修饰设置为半胱氨酸烷基化,可变修饰设置为甲硫氨酸氧化。肽段打分值大于20分。
[0170]
因此,本发明通过将tmt标记、高效液相色谱分级技术以及基于质谱的定量蛋白组学技术等一系列前沿技术的有机结合,对样品进行定量蛋白组的研究。其技术路线如图1所示。
[0171]
三、tmt高通量蛋白组学蛋白鉴定结果
[0172]
1.质谱质控检测结果:
[0173]
研究结果所得大部分肽段分布在7-20个氨基酸,符合基于trypsin酶解和hcd碎裂方式的一般规律。其中小于5个氨基酸的肽段由于产生的碎片离子过少,不能产生有效的序列鉴定。大于20个氨基酸的肽段由于质量和电荷数较高,不适合hcd的碎裂方式。质谱鉴定到的肽段长度的分布符合质控要求。
[0174]
质谱鉴定到肽段的长度分布如图2所示。
[0175]
如图3所示,绝大多数谱图的一级质量误差在10ppm以内,符合轨道阱质谱的高精度特性。表明质谱仪的质量精度正常,不会由于质量偏差过大而影响到蛋白的定性定量分析。谱图匹配肽段的得分(表征肽段鉴定的可信度)与质量偏差的分布成负相关关系。得分越高,质量偏差越小。
[0176]
2.蛋白组鉴定结果:
[0177]
本发明一共鉴定到1919.0个蛋白质,其中1432.0个蛋白质包含定量信息。如果以1.2倍为差异表达变化阈值,以统计学检验t-test p-value<0.05为显著性阈值,那么在定量到的蛋白质中,发现在慢阻肺vs健康对照比较组中有151个蛋白表达发生上调,100个蛋白表达发生下调。基于上述数据,对所有鉴定到的蛋白质进行了系统的生物信息学分析(蛋白功能注释),并且对所有差异表达蛋白进行了功能分类、功能富集及基于功能富集的聚类分析。并综合以上信息,对下游基于蛋白组的深入研究提供了参考方向。
[0178]
在本发明实验中,通过质谱分析共得到3454658.0张二级谱图。质谱二级谱图经蛋白理论数据搜库后,得到可利用有效谱图数为365761,谱图利用率为10.6%。通过谱图解析共鉴定到 41257.0条肽段,其中特异性肽段为37925.0。一共鉴定到1919.0个蛋白,其中1432.0个可定量(定量蛋白表示至少一个比较组有定量信息)。实验结果详细统计如下(表
2)。
[0179]
表2质谱数据结果基本统计表
[0180][0181]
本实施例通过多次全蛋白定量重复实验,分别得到了每个样品在多次重复中的定量值。
[0182]
第一步计算比较组中两个样品间蛋白的差异表达量,首先计算出每个样品在多次重复中定量值的平均值,然后再计算两个样品之间平均值的比值,该比值作为比较组最终的差异表达量。
[0183]
第二步计算该蛋白在两个样品中的差异表达显著性p-value,首先将各个样品的相对定量值取log2(以使得数据符合正态分布),然后用双样品双尾t检验方法计算p-value。当p-value <0.05时,以差异表达量变化超过1.2作为显著上调的变化阈值,小于1/1.2作为显著下调的变化阈值。
[0184]
质谱数据结果基本统计图如图4所示。
[0185]
本实施例所有差异表达的蛋白汇总数据参见表3。
[0186]
表3差异表达蛋白统计信息
[0187][0188]
不同比较组中差异表达蛋白数量分布柱形图如图5所示。
[0189]
图6为差异表达蛋白定量火山图,图6中横轴为蛋白相对定量值经过log2对数转换后的值,纵轴为差异显著性检验p-value值经过-log10对数转换后的值。图中倒三角表示显著差异表达量上调蛋白,正三角表示显著差异表达下调蛋白。
[0190]
四、prm靶向蛋白组实施方案
[0191]
1.材料与试剂
[0192]
表4.样品制备所需材料和试剂
[0193]
试剂名称供应商胰酶(trypsin)promega乙腈(acetonitrile)fisher chemical三氟乙酸(trifluoroacetic acid)sigma-aldrich甲酸(formic acid)fluka碘代乙酰胺(iodoacetamide)sigma二硫苏糖醇(dithiothreitol)sigma尿素(urea)sigma蛋白酶抑制剂calbiochem超纯水(h2o)fisher chemicalbca试剂盒碧云天
[0194]
2.实验方法
[0195]
1)蛋白提取
[0196]
使用thermo公司生产的试剂盒参照pierce
tm top 12 abundant protein depletion spincolumns kit说明书去除高丰度蛋白。利用bca试剂盒进行蛋白浓度测定。
[0197]
2)胰酶酶解
[0198]
蛋白溶液中加入二硫苏糖醇使其终浓度为5mm,56℃还原30min。之后加入碘代乙酰胺使其终浓度为11mm,室温避光孵育15min。最后将样品的尿素浓度稀释至低于2m。以 1∶50的质量比例(胰酶∶蛋白)加入胰酶,37℃酶解过夜。再以1∶100的质量比例(胰酶∶蛋白)加入胰酶,继续酶解4h。
[0199]
3)液相色谱-质谱联用分析
[0200]
肽段用液相色谱流动相a相(0.1%(v/v)甲酸水溶液)溶解后使用easy-nlc 1000超高效液相系统进行分离。流动相a为含0.1%甲酸和2%乙腈的水溶液;流动相b为含0.1%甲酸和90%乙腈的水溶液。液相梯度设置:0~40min,6%-25%b;40~52min,25%-35%b;52~56min,35%-80%b;56~60min,80%b,流速维持在350nl/min。
[0201]
肽段经由超高效液相系统分离后被注入nsi离子源中进行电离然后进q exactive
tm plus 质谱进行分析。离子源电压设置为2.0kv,肽段母离子及其二级碎片都使用高分辨的orbitrap 进行检测和分析。一级质谱扫描范围设置为400-1080m/z,扫描分辨率设置为70,000;二级质谱orbitrap扫描分辨率设置为17,500。数据采集模式使用数据非依赖型扫描(dia)程序,hcd 碰撞池的碎裂能量设置为27。一级质谱自动增益控制(agc)设置为3e6,最大离子注入时间(maxumum it)设置为50ms;二级质谱自动增益控制(agc)设置为1e5,最大离子注入时间(maxumum it)设置为180ms,隔离窗口(isolation window)设置为1.6m/z。
[0202]
3.数据处理
[0203]
肽段参数:蛋白酶设置为trypsin[kr/p],最大漏切位点数设置为0,肽段长度设置为7-25 个氨基酸残基,设置半胱氨酸烷基化为固定修饰。transition参数:母离子电荷设置为2,3,子离子电荷设置为1,离子类型设置为b,y。碎片离子选择从第三个开始到最后一个,离子匹配的质量误差容忍度设置为0.02da。
[0204]
四、prm靶向蛋白组数据结果
[0205]
1.定量结果总览
[0206]
在本项目实验中,在60个样品中对所选择的18个目的蛋白进行了prm定量,受限于部分蛋白的特性和其表达的丰度,定量到了其中的16个蛋白,具体结果见表5。
[0207]
表5prm靶向蛋白定量表
[0208][0209][0210]
注释:实验设计中每个蛋白使用2条以上unique peptides进行定量,部分蛋白因为灵敏度等原因只鉴定到了一条肽段。
[0211]
2.肽段碎片离子峰面积分布
[0212]
prm是采用峰面积定量的。
[0213]
所选肽段的碎片离子峰面积在60个样品中的分布图参见下图7:“肽段碎片离子峰面积分布图(以蛋白p02763为例)”。
[0214]
图7是蛋白p02763碎片离子峰面积分布图。在60个样品中肽段eqlgefyealdclr(对应蛋白p02763)的碎片离子峰面积分布情况。
[0215]
3.prm靶向蛋白质定量结果:
[0216]
prm靶向蛋白质定量结果如图8所示。
[0217]
五、非靶向代谢组学实施方案
[0218]
1、实验流程,如图9所示。
[0219]
2、实验仪器和试剂
[0220]
表6主要试剂
[0221]
试剂/仪器供应商质谱仪(ab sciex)ab triple tof 5600/6600超高压液相色谱仪(agilent)agilent 1290 infinity lc低温高速离心机eppendorf 5430r色谱柱acquity uplc beh amide/acquity uplc hss t3乙腈merck,1499230-935乙酸sigma,7022
[0222]
3、实验方法
[0223]
1)样品信息
analysis)、 t检验,以及综合前两种分析方法的火山图(volcano plot)。利用单变量分析可以直观地显示两样本间代谢物变化的显著性,从而帮助我们筛选潜在的标志代谢物。
[0239]
(4.3)显著性差异代谢物分析:根据opls-da模型得到的变量权重值(variable importancefor the projection,vip)来衡量各代谢物的表达模式对各组样本分类判别的影响强度和解释能力,挖掘具有生物学意义的差异代谢物。以vip>1为筛选标准,初步筛选出各组间的差异物。进一步采用单变量统计分析,验证差异代谢物是否具有显著性。选择同时具有多维统计分析vip> 1和单变量统计分析p value<0.05的代谢物,作为具有显著性差异的代谢物;而vip>1且0.05 <p value<0.1则作为差异代谢物(p value<0.05的代谢物为具有显著性差异代谢物)。
[0240]
(4.4)生物信息学分析:
[0241]
原始数据经proteowizard转换成.mzxml格式,然后采用xcms程序进行峰对齐、保留时间校正和提取峰面积。代谢物结构鉴定采用精确质量数匹配(<25ppm)和二级谱图匹配的方式,检索实验室自建数据库。数据的完整性和准确性是后续获得具有统计学和生物学意义的分析结果的必要条件。在确保实验设计的合理性和实验数据的准确性的基础上,我们首先对数据的完整性进行检查,对缺失值进行删除或者补充,删除极值,并对数据进行样品间和代谢物间的归一化处理,以确保各样品之间和代谢物之间可平行比较。
[0242]
数据经pareto-scaling预处理后,进行多维统计分析,包括无监督主成分分析(pca)分析,有监督偏最小二乘法判别分析(pls-da)和正交偏最小二乘法判别分析(opls-da),通过逐步回归法筛选代谢物指标。单维统计分析包括student’s t-test和变异倍数分析,r软件绘制火山图。
[0243]
(4.4.1)主成分分析(principal component analysis,pca)是一种非监督的数据分析方法,它将原本鉴定到的所有代谢物重新线性组合,形成一组新的综合变量,同时根据所分析的问题从中选取几个综合变量,使它们尽可能多地反映原有变量的信息,从而达到降维的目的。同时,对代谢物进行主成分分析,还能从总体上反映样品组间和组内的变异度。
[0244]
以慢阻肺vs健康对照组为示例组进行pca分析,详见pca模型参数表(a:表示主成分数;r2x:表示模型对x变量的解释率)。
[0245]
pca得分图见图10,横坐标表示第一主成分pc1用t[1]表示,纵坐标表示第二主成分pc2 用t[2]表示,pca模型参数主要参考r2x的值,r2x越接近1表明模型越稳定可靠。
[0246]
pca模型参数表如下表8所示。
[0247]
表8 pca模型参数表
[0248]
分组极性ar2x(cum)质控样品阳离子90.514质控样品阴离子90.517慢阻肺vs健康对照阳离子90.523慢阻肺vs健康对照阴离子90.521
[0249]
(4.4.2)偏最小二乘判别分析(pls-da)
[0250]
研究发现,很多动植物及微生物的生理和病理变化通常伴随着代谢过程的异常改变。但是这些生理病理的变化通常只与部分代谢物的表达水平变化特异相关。因此,从海量
的代谢组学数据中筛选标志代谢物并建立准确的判别模型,对于疾病的早期诊断和预后、以及生理过程的类型和时期的判别等具有重要意义。
[0251]
不同于主成分分析(pca)法,偏最小二乘判别分析(partial least squares discriminationanalysis,pls-da)是一种有监督的判别分析统计方法。该方法运用偏最小二乘回归建立代谢物表达量与样品类别之间的关系模型,来实现对样品类别的预测;同时通过计算变量投影重要度(variable importance for the projection,vip)来衡量各代谢物的表达模式对各组样品分类判别的影响强度和解释能力,从而辅助标志代谢物的筛选(通常以vip score>1.0作为筛选标准)。
[0252]
建立示例组的pls-da模型,模型得分图见下表9。经七次循环交互验证得到的模型评价参数(r2y,q2)列于pls-da模型的评价参数表(a:表示主成分数;r2x:表示模型对x 变量的解释率;r2y:表示模型对y变量的解释率;q2:表示模型预测能力),r2y和q2 越接近1表明模型越稳定可靠,一般q2大于0.5模型稳定可靠,0.3<q2≤0.5模型稳定性较好,q2<0.3模型可靠性较低。
[0253]
表9 pls-da模型的评价参数表
[0254][0255][0256]
(4.4.3)正交偏最小二乘判别分析(opls-da)
[0257]
不同于主成分分析(pca)法,正交偏最小二乘判别分析(opls-da)是一种有监督的判别分析统计方法。该方法运用偏最小二乘回归建立代谢物表达量与样品类别之间的关系模型,来实现对样品类别的预测。该方法在偏最小二乘判别分析(pls-da)的基础上进行修正,滤除与分类信息无关的噪音,提高了模型的解析能力和有效性。在opls-da得分图上,有两种主成分,即预测主成分和正交主成分。预测主成分只有1个,即t1;正交主成分可以有多个。 opls-da将组间差异最大化的反映在t1上,所以从t1上能直接区分组间变异,而在正交主成分上则反映了组内的变异。
[0258]
建立示例组的opls-da模型,模型得分情况见下表10,经7-fold cross-validation(7次循环交互验证)得到的模型评价参数(r2y,q2)列于opls-da模型的评价参数表(a:表示主成分数;r2x:表示模型对x变量的解释率;r2y:表示模型对y变量的解释率;q2:表示模型预测能力),r2y和q2越接近1表明模型越稳定可靠,一般q2大于0.5模型稳定可靠,0.3<q2≤0.5模型稳定性较好,q2<0.3模型稳定性较低。
[0259]
置换检验通过随机改变分类变量y的排列顺序,建立200次opls-da模型以获取随机模型的r2和q2值,横坐标表示置换检验的置换保留度,纵坐标表示r2或q2的取值,所有的 q2点从左到右均低于最右侧原始蓝色的q2点表明模型稳健可靠未发生过拟合。示例组的置换检验图如图正、负离子模式opls-da置换检验。
[0260]
表10 opls-da模型的评价参数表
[0261]
分组极性anr2x(cum)r2y(cum)q2慢阻肺vs健康对照阳离子1+1810.1120.7740.436
慢阻肺vs健康对照阴离子1+4810.13380.69280.425
[0262]
六、非靶向代谢组学数据结果
[0263]
6.1质量控制(qc)结果
[0264]
1)qc样品总离子流图(tic)的比较
[0265]
将qc样品uhplc-q-tof ms总离子流图,进行谱图重叠比较,下图结果表明各色谱峰的响应强度和保留时间基本重叠,说明在整个实验过程中仪器误差引起的变异较小。
[0266]
将qc样品uhplc-q-tof ms总离子流图,进行谱图重叠比较,图10和图11结果表明各色谱峰的响应强度和保留时间基本重叠,说明在整个实验过程中仪器误差引起的变异较小。
[0267]
2)总体样品主成分分析(pca)
[0268]
采用xcms软件对代谢物离子峰进行提取,见离子峰数目表11。将所有实验样品和qc 样品提取得到的峰,经pareto-scaling得到的pca模型,如下图12(图中t[1]代表主成分1、 t[2]代表主成分2)所示正、负离子模式下qc样品紧密聚集在一起,表明本项目实验的重复性好。
[0269]
表11离子峰数目表
[0270]
样品分组峰数目正离子3720负离子3694
[0271]
图12正、负离子模式下样品的pca得分图综上所述,本次试验的仪器分析系统稳定性较好,试验数据稳定可靠。在试验中获得的代谢谱差异能反映样品间自身的生物学差异。
[0272]
3)总体样品霍特林t平方分布(hotellings t2)分析
[0273]
hotellings t2分析可以检测是否有离群样品存在,通常全部样品在99%置信区间内。
[0274]
6.2样品相关性图谱
[0275]
qc样品的相对标准偏差(rsd值,relative standard deviation)≤30%的强度值之和与总体强度值之和的比值大于70%,说明仪器分析系统稳定性较好,数据可以用于后续分析。对 qc样品进行pearson相关性分析,横坐标和纵坐标分别标记强度值的对数值,一般相关系数大于0.9表明相关性较好。
[0276]
正、负离子模式下qc样品相关性图谱如图13所示。
[0277]
本实验采用基于uhplc-q-tof ms技术的代谢组学方法分别对样品进行了代谢轮廓变化分析。质量控制实验表明,本次实验的仪器分析系统稳定性较好,试验数据稳定可靠。在实验中获得的代谢谱差异能反映样品间自身的生物学差异。
[0278]
6.3筛选到的差异代谢物
[0279]
采用多因素logistic回归方法建立预测模型,并根据最小赤池信息标准选择最佳的模型参数,计算优势比(odds ratio,or)和95%可信区间(ci);绘制预测模型的列线图,该列线图可以直观地显示每个磨玻璃结节的预测概率,同时绘制校准曲线以显示列线图的预测精度,以及绘制预测模型的受试者工作特征曲线,并获得曲线下面积及其95%ci,再应用z统计量比较建模组和验证组的auc,所有统计检验均为双侧检验,以p<0.05被认为具有统计学差异。
[0280]
本发明一共鉴定到阳离子代谢物峰数目3720个,其中模式差异代谢物24个;阴离子代谢物峰数目3694个,其中模式差异代谢物22个,共发现13个显著差异性代谢物(包括7个阳离子和6 个阴离子)。
[0281]
7个阳离子如下:
[0282]
十六酰胺乙醇(palmitoylethanolamide);反式-脱氢异雄甾(trans-dehydroandrosterone);癸酰基左旋肉碱(decanoyl-l-carnitine);甜菜碱(betaine);假尿嘧啶核苷(pseudouridine);莰酮(camphor);1-硬脂酰基-2-油酰基-sn-甘油3-磷酸胆碱 (1-stearoy1-2-oleoyl-sn-glycerol3-phosphocholine(sopc));
[0283]
6个阴离子如下:茶碱(theophylline);l-异亮氨酸(l-isoleucine);硫酸孕烯醇酮 (pregnenolone sulfate);壬二酸(azelaic acid);舒尼替尼(sunitinib);次黄嘌呤(hypoxanthine)。
[0284]
七、建立预测模型
[0285]
根据我国人群生物标记物的特征通过单变量分析及多变量间不同组合分析,以灵敏度和特异度为参数,结合曲线下面积建立重度慢阻肺疾病风险预测模型,用于重度慢阻肺发病风险的评估及分子诊断,结果如下:
[0286]
7.1通过蛋白组预测重度慢阻肺风险:通过逐步回归法筛选蛋白指标,筛选后的差异蛋白包括类粘蛋白、过氧化还原酶2及钙粘着蛋白5,其预测重度慢阻肺的准确度分别为0.690、0.769 及0.863,将三种蛋白作为联合指标p3-pro,其推断重度慢阻肺的准确度为0.936,其相应的灵敏度和特异度分别为0.88和0.90;
[0287]
单纯蛋白组建立预测模型:y(慢阻肺=1|健康对照=0)=-10.323+2.354*类粘蛋白+6.834* 钙粘着蛋白5+1.694*过氧化还原酶2。
[0288]
可以将上述代蛋白群体生物标志物单独用于早期发现、早期预测或早期诊断罹患重度慢阻肺风险的产品中。
[0289]
所述产品包括试剂、试剂盒等。
[0290]
所述产品包括通过质谱法等进行检测所述蛋白群体生物标志物及其含量或者浓度的试剂等。
[0291]
进一步的,还可以基于本发明提供的蛋白标志物制备检测试剂盒,该试剂盒包括如下成分:类粘蛋白、过氧化还原酶2及钙粘着蛋白5。
[0292]
该试剂盒是基于本发明提供的蛋白标志物群而设计的,可以用于筛选治疗或缓解重度慢阻肺的药物。
[0293]
7.2通过阳离子代谢物预测重度慢阻肺风险:单变量分析发现,显著差异的代谢物十六酰胺乙醇、反式-脱氢异雄甾酮、癸酰基左旋肉碱及甜菜碱推测重度慢阻肺的准确度分别为0.784、 0.742、0.729及0.715;为进一步提高疾病预测的准确度,对四种阳离子代谢物作为联合指标 p4-pos-met进行疾病判断,其推断重度慢阻肺的准确度为0.977,其相应的灵敏度和特异度分别为0.83和0.85;
[0294]
7.3通过阴离子代谢物预测重度慢阻肺风险:单变量分析发现,显著差异的代谢物茶碱、次黄嘌呤及l-异亮氨酸推测重度慢阻肺的准确度分别为0.740、0.639和0.785,为进一步提高疾病预测的准确度,对三种阴离子代谢物作为联合指标p3-neg-met进行疾病判断,其推断重度慢阻肺的准确度为0.959,其相应的灵敏度和特异度分别为0.90和0.90;
[0295]
7.4联合阳离子和阴离子代谢物预测重度慢阻肺风险:通过逐步回归法筛选代谢物指标,筛选后的差异代谢物包括十六酰胺乙醇、癸酰基左旋肉碱、甜菜碱、茶碱及次黄嘌呤,其预测重度慢阻肺的准确度分别为0.784、0.729、0.715、0.740及0.724。但五种代谢物作为联合指标 p5-met,其推断重度慢阻肺的准确度为0.970,其相应的灵敏度和特异度分别为0.88和0.93;
[0296]
单纯代谢组建立预测模型:y(慢阻肺=1|健康对照=0)=-14.645+(0.41*十六酰胺乙醇+1.41*癸酰基左旋肉碱-4.83*甜菜碱+0.15*茶碱+1.17*次黄嘌呤)/10000。
[0297]
本发明模型通过逐步回归法筛选代谢物指标,先单变量分析、再多变量分析,准确度逐步提高,最终选择准确度最高的,即本发明的联合预测模型。
[0298]
可以将上述代谢物群体生物标志物单独用于早期(辅助)发现(辅助筛查)、早期(辅助) 预测或早期(辅助)诊断罹患重度慢阻肺风险的产品中。
[0299]
产品包括试剂、试剂盒等。
[0300]
产品包括通过高效质谱法等进行检测所述代谢物群体生物标志物及其含量或者浓度的试剂等。
[0301]
进一步的,还可以基于本发明提供的代谢标志物制备检测试剂盒,该试剂盒包括如下成分:十六酰胺乙醇、癸酰基左旋肉碱、甜菜碱、茶碱及次黄嘌呤。
[0302]
该试剂盒是基于本发明提供的代谢标志物群而设计的,可以用于筛选治疗或缓解重度慢阻肺的药物。
[0303]
也可以进一步的:
[0304]
7.5联合蛋白组和代谢组预测重度慢阻肺风险:为进一步提高疾病预测的准确度,将十六酰胺乙醇、茶碱、次黄嘌呤三个代谢物和钙粘着蛋白5,作为联合指标p4-met+pro,其推测重度慢阻肺的准确度为0.977,其相应的灵敏度和特异度分别为0.94和0.95;
[0305]
联合判断建立的预测模型:y(慢阻肺=1|健康对照=0)=-17.934+(0.46*十六酰胺乙醇+0.13*茶碱+0.77*次黄嘌呤)/10000+8.340*钙粘着蛋白5。
[0306]
综上,得出的蛋白组-代谢组联合群体生物标志物包括十六酰胺乙醇、茶碱、次黄嘌呤三个代谢物和钙粘着蛋白5。
[0307]
通过比较分析发现,蛋白组与代谢组联合分析指标显著优于代谢物联合分析指标,也优于蛋白联合分析指标。
[0308]
因此,更佳的可以将上述蛋白组-代谢组联合群体生物标志物一起用于早期发现(早期辅助筛查)、早期预测或早期诊断罹患重度慢阻肺风险的产品中。
[0309]
产品包括试剂、试剂盒等。
[0310]
产品包括通过高效液相色谱分级技术、高效质谱(lc-ms/m)等进行检测所述蛋白组-代谢组群体生物标志物及其含量或者浓度的试剂等。
[0311]
可以基于本发明提供的蛋白组-代谢组联合群体生物标志物制备检测试剂盒,该试剂盒包括如下成分:十六酰胺乙醇、茶碱、次黄嘌呤三个代谢物和钙粘着蛋白5。
[0312]
该试剂盒是基于本发明提供的蛋白组-代谢组联合群体生物标志物而设计的,可以用于筛选治疗或缓解重度慢阻肺的药物。
[0313]
以上实施例仅用于阐述本发明,而本发明的保护范围并非仅仅局限于以上实施例。所属技术领域的普通技术人员依据以上本发明公开的内容均可实现本发明的目的,任
何基于本发明构思基础上做出的改进和变形,均落入本发明的保护范围之内,具体保护范围以权利要求书记载的为准。
- 该技术已申请专利。仅供学习研究,如用于商业用途,请联系技术所有人。
- 技术研发人员:卢文菊 张子丽 林范杰
- 技术所有人:广州瑞能精准医学科技有限公司
- 我是此专利的发明人
- 该领域下的技术专家
- 如您需求助技术专家,请点此查看客服电话进行咨询。
- 1、邢老师:1.机械设计及理论 2.生物医学材料及器械 3.声发射检测技术。
- 2、王老师:1.数字信号处理 2.传感器技术及应用 3.机电一体化产品开发 4.机械工程测试技术 5.逆向工程技术研究
- 3、王老师:1.机器人 2.嵌入式控制系统开发
- 4、张老师:1.机械设计的应力分析、强度校核的计算机仿真 2.生物反应器研制 3.生物力学
- 5、赵老师:检测与控制技术、机器人技术、机电一体化技术
- 如您是高校老师,可以点此联系我们加入专家库。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
精彩留言,会给你点赞!
专利分类正在加载中....