一种基于GPU的SAR后向投影成像并行加速优化方法
一种基于gpu的sar后向投影成像并行加速优化方法
技术领域
1.本发明涉及合成孔径雷达技术领域,具体涉及一种基于gpu的sar后向 投影成像的并行加速优化方法。
背景技术:
2.sar(合成孔径雷达,synthetic aperture radar)是一种高分辨的成像雷达, 在军事和民用领域得到了广泛应用。随着sar分辨率和测绘带宽度的提高,对 成像的速度也提出了更高的要求,而回波数据量的增加和算法的更加复杂,给 后续的数据高效处理带来了挑战。
3.sar回波数据的预处理和成像算法的快慢直接影响着后续图像处理的时效 性,后向投影成像算法能够适应任意模型下的sar成像,该算法采用逐点遍历 的方式可以得到精确的聚焦图像,但逐点运算却引入了庞大的运算量,成了制 约高效获取sar图像的瓶颈问题。
技术实现要素:
4.鉴于后向投影成像算法庞大的运算量和算法逻辑的高并行性,本公开提出 一种基于gpu的并行加速优化方案,以实现后向投影成像算法的高效性,满足 精确测量等领域的需求。
5.gpu(graphics processing unit,图像处理单元)具有强大的浮点计算能力 和可高度并行的架构,在计算规模大、逻辑分支简单、数据密度高的并行计算 中有明显优势,因此适合处理大型复杂并行运算。
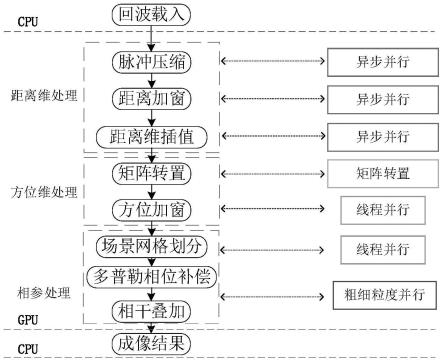
6.本公开提供的基于gpu的sar后向投影成像并行加速优化方法,包括以 下步骤:
7.将解包后的雷达回波数据载入gpu设备端;
8.在gpu设备端对雷达回波数据进行距离维处理,包括脉冲压缩、距离加窗、 距离维插值处理;
9.在gpu设备端,对经过所述距离维处理的雷达回波数据进行方位维处理, 包括:基于共享内存,通过并行读取进行雷达回波矩阵转置,和通过分配线程 资源进行并行方位加窗处理;
10.在gpu设备端,对经过所述距离维和方位维处理的雷达回波数据进行相参 处理,包括:成像空间网格划分,基于线程资源的粗细粒度并行进行多普勒相 位计算和多普勒相位补偿,以及相干叠加处理,完成成像。
11.进一步地,所述将解包后的雷达回波数据载入gpu设备端的步骤,具体包 括:
12.将解包后的回波数据矩阵echo_cpu[m,n]划分成s个数据流,即在一个数据 流中以距离维数据连续优先存储;
[0013]
通过异步并行技术将s个数据流依次载入已分配好的gpu显存空间 echo[m,n]中,此时每个流对应的数据以距离维数据连续的形式加载并存储在 gpu中;
[0014]
其中:echo_cpu[m,n]为cpu端回波矩阵的存储空间,m为方位脉冲重复 时间数,n为距离采样点数;
[0015]
一个数据流包含个方位时刻的回波数据,流的数量依据gpu多流所能 达到的最优效果确定。
[0016]
进一步地,所述在gpu设备端对雷达回波数据进行距离维处理的步骤具体 包括:
[0017]
对第s(s∈[0,s])个数据流中的多个距离维数据依次进行脉冲压缩;
[0018]
对第s个流的多个距离脉冲压缩结果依次进行距离维加窗;
[0019]
将距离维加窗得到的结果变换到频域,采用在频域补零的方式对距离维数 据进行插值处理;
[0020]
当目前流s还未执行结束时,即s≤s,阻塞等到所有流执行结束,并销毁 流。
[0021]
进一步地,所述基于共享内存,通过并行读取进行雷达回波矩阵转置的具 体步骤包括:
[0022]
将所述距离维处理得到的矩阵填充为方阵;
[0023]
将所述方阵分成等大的子方阵;
[0024]
细粒度并行层面,将子方阵按行并行读取并写入共享内存中,再从共享内 存中按列并行读取并写入原子方阵中,实现子方阵的转置;
[0025]
粗粒度并行层面,借助共享内存,将子方阵并行写入原显存空间转置后所 对应的子方阵中,完成子方阵间数据交换;
[0026]
将转置后的矩阵去除填充零,即完成矩阵的转置操作。
[0027]
进一步地,所述相参处理的具体步骤包括:
[0028]
在gpu端分配线程资源,进行成像空间网格的划分,一个网格对应一个像 素点;
[0029]
通过gpu调用线程资源,实现粗细粒度两层并行,以计算双程距离和多普 勒相位:将成像空间像素点映射到gpu线程块,一个像素对应对应一个线程块, 实现粗粒度并行;将方位时刻映射到所述线程块内包含的线程,实现细粒度并 行;
[0030]
将经过距离维和方位维处理的雷达回波矩阵映射到成像空间上,并在同一 像素网格上计算每个方位时刻对应的多普勒相位并进行多普勒相位补偿,将结 果存储到单个像素对应的线程块所独有的共享内存中;
[0031]
对共享内存中的数据进行累加,得到成像空间中的每一个像素点,得到最 终的图像矩阵,完成成像。
[0032]
进一步地,所述优化方法还包括:将gpu设备端处理得到的图像矩阵拷贝 到cpu主机端的步骤。
[0033]
可见,本公开针对sar后向投影成像算法运算量庞大,数据处理效率低下 的问题,利用gpu的强大运算能力,将成像计算的所有步骤均在gpu端进行 处理,同时,基于gpu的共享内存和并行处理能力,对sar后向投影成像过 程中的矩阵转置、点乘运算和相参计算进行了分析优化,能够有效提升sar的 后向投影成像处理速度。
[0034]
与现有技术相比,本公开的有益效果是:
①
以gpu为处理平台,对sar 后向投影成像算法进行并行加速优化;
②
将成像计算所有步骤均在gpu端处理, 避免cpu与gpu频繁通信引入的耗时,提高了数据处理效率;
③
采用异步并 行技术,有效隐藏数据传输与处理的
耗时;
④
提出一种新的矩阵转置方法,尽 可能少的使用显存资源,可处理更大的回波矩阵;
⑤
实现多普勒相位计算及补 偿在方位时刻和空间像素的粗细粒度两层次并行处理,明显提升了成像处理速 度。
附图说明
[0035]
图1为根据本公开的示例性实施例流程图;
[0036]
图2为本公开的异步并行技术示意图;
[0037]
图3为本公开的矩阵转置操作示意图;
[0038]
图4为本公开的相参计算流程示意图;
[0039]
图5为本公开的相参计算粗细粒度并行示意图。
具体实施方式
[0040]
下面结合附图并举实施例,对本发明进行详细描述。
[0041]
本发明提供了一种基于gpu的sar后向投影成像并行加速优化方法,如 图1所示,包括以下步骤:
[0042]
步骤1:将解包后的合成孔径雷达回波数据载入gpu设备端。
[0043]
将解包后的回波数据矩阵echo_cpu[m,n]划分成s个数据流,即在一个数据 流中以距离维数据连续优先存储。如图2所示,通过异步并行技术将s个数据 流依次载入已分配好的gpu显存空间echo[m,n]中,此时每个流对应的数据以 距离维数据连续的形式加载并存储在gpu中。待将cpu端所有的回波数据全 部传输至gpu端后,本发明成像计算的所有步骤均在gpu端进行处理,避免 了cpu与gpu端频繁通信引入的耗时。
[0044]
其中,echo_cpu[m,n]为cpu端回波矩阵,m为方位脉冲重复时间数,n 为距离采样点数,s为cuda(运算平台)流数量,一个流包含个方位时刻 的回波数据;echo[m,n]为gpu端回波矩阵的存储空间;流的数量依据gpu多 流所能达到的最优效果而定,本实例中,优选流数量s=4。
[0045]
图2所示为异步并行技术示意图,通过将cpu端回波数据进行分块,由流 依次传入传输至gpu端对应的显存空间中,缩短了距离维处理的等待时长,多 个流的并行传输及处理操作,可以使得gpu运算核心绝大部分时间处于忙碌状 态,有效掩盖了数据不分块情况下cpu与gpu进行数据传输的时间。
[0046]
步骤2:在gpu设备端对雷达回波数据进行距离维处理。
[0047]
具体步骤如下:
[0048]
2.a脉冲压缩:由于步骤1传入的数据以距离维优先存储在gpu端,因此 可以对第s(s∈[0,s])个数据流中的多个距离维数据echo[m,:]依次进行脉冲压缩,该 操作采用cuda cufft库函数,通过创建cufft执行计划完成对距离维数据 的脉冲压缩,并存储在gpu端原始距离维矩阵echo[m,:]中。
[0049]
2.b距离加窗:在gpu端通过调用线程创建距离窗rwin[n],其长度为距离 维采样点数。对步骤2.a得到的第s个流的多个距离脉冲压缩结果依次进行距离 维加窗,其通过分配线程资源实现并行加窗,即:
[0050]
echo[m,idx]=echo[m,idx]*rwin[idx],
[0051]
并存储在gpu端原始距离维矩阵echo[m,:]中。
[0052]
其中,echo[m,idx]为第m个方位时刻对应的距离维矩阵,idx为开辟的gpu 线程资源。
[0053]
2.c距离维插值:本发明所有的数据处理均在gpu进行,没有相应的插值 函数以供使用,所以采用在频域补零的方式实现对距离维数据的插值处理。首 先对步骤2.b得到的第m个方位时刻的距离加窗结果做cufft变换到频域,进 行补零,将矩阵echo[m,n]扩充为矩阵echo[m,np],其中np为补零填充后距离维 点数,然后进行cuifft变换到时域完成距离维插值,并存储在gpu端原始距 离维矩阵echo[m,:]中。至此,完成步骤1异步并行技术第s个流的数据处理阶段, 第s个流执行结束。
[0054]
2.d当目前流s还未执行结束时,即s≤s,阻塞等到所有流执行结束,并销 毁流,此时gpu端echo[m,np]中存储的为距离维处理后的数据。
[0055]
步骤3:在gpu设备端对步骤2处理得到的数据进行方位维处理。
[0056]
3.a矩阵转置:通过借助共享内存辅助读写操作,实现对全局内存的合并读, 合并写。如图3矩阵转置操作示意图,为了更好的适应方阵回波数据和非方阵 回波数据,提高矩阵转置方法的通用性,首先,对步骤2距离维处理得到的矩 阵echo[m,np]进行填充为方阵echo[p,p],再将矩阵分成等大的子方阵,其中 p=max(m,np),本实例中np》m,p=np。
[0057]
细粒度并行层面,将子方阵按行读取并写入共享存储器中,从共享内存中在按列读取并写入原子方阵中实现子方阵的转置,如图3(b)子方阵(0,2)和图3(c)子方阵(0,2)。粗粒度并行层面,将子方阵写入原显存空间转置后所对应的子方阵中,完成子方阵间数据交换,如图3(c)中子方阵(0,2)和图3(d)子方阵(2,0)。将转置后的矩阵去除填充零,及完成矩阵的转置操作,得到echo
t
[m,np],使得矩阵中数据以方位维优先存储在gpu端,便于后续的方位维加窗和相参计算。
[0058]
3.b方位加窗:对步骤3.a矩阵转置后的数据矩阵echo
t
[m,n]在方位维进行 加窗,并存储在原显存空间echo
t
[m,n]中。
[0059]
在gpu端通过调用线程创建方位窗awin[n],其长度为方位时刻点数。对步 骤3.a得到的转置矩阵echo
t
[m,np]依次进行方位维加窗,其通过分配线程资源实 现并行加窗,即:echo
t
[idx,n]=echo
t
[idx,n]
·
awin[idx],并存储在gpu端原始距离 维矩阵echo
t
[:,n]中。
[0060]
其中,echo
t
[:,n]为第n个距离门对应的方位维矩阵,idx为开辟的gpu线 程资源,idx∈[0,n-1]。
[0061]
步骤4:在gpu设备端对步骤3处理得到的数据进行相参处理。
[0062]
如图4所示,为sar相参计算过程流程示意图。
[0063]
4.a成像空间网格划分:在gpu端分配线程资源,进行成像空间网格 img[gx,gy]的划分,其分别存储了空间网格中的x、y坐标,即:
[0064]
img[bidx.x,bidx.y].x=x
start
+idx
×
δx
[0065]
img[bidx.x,bidx.y].y=y
start
+idx
×
δy
[0066]
其中,bidx.x,bidx.y为线程块索引,idx为线程资源,δx,δy分别为方位维网 格分辨率和距离维网格分辨率,img[gx,gy]为成像空间,gx为方位维网格长度, gy为距离维
网格长度,img(bidx.x,bidx.y)为像素点(bidx.x,bidx.y)的空间坐标。
[0067]
4.b计算双程延时及多普勒相位:如图5所示,本发明通过将成像空间像素 点映射到gpu线程块实现粗粒度并行,将方位时刻映射到线程块内线程实现细 粒度并行,通过gpu调用线程资源实现粗细粒度两层并行以计算双程延时相位, 即
[0068]
其中,δr为雷达和空间像素点的单程距离,bidx.x,bidx.y为线程块索引, 表示线程块(bidx.x,bidx.y),可以在像素空间img内唯一标识一个像素点 (bidx.x,bidx.y)。idx为线程块内的线程索引,pos(idx)为方位时刻idx雷达的空间坐 标,|img(bidx.x,bidx.y)-pos(idx)|为在方位时刻idx时,雷达坐标pos(idx)与成像空间 像素点(bidx.x,bidx.y)的单程距离模值。
[0069]
4.c多普勒相位补偿:通过将步骤3所得结果矩阵echo
t
[m,n]映射到成像空 间img[gx,gy]上,并在同一个像素网格上进行多普勒相位补偿,并将结果存储到 单个像素所独有的共享内存中,即
[0070]
其中,idx为线程块(bidx.x,bidx.y)内的线程,sm为该线程块所拥有的共享内 存,每一个线程块都分配一个共享内存,仅供该线程块内所有线程访问。
[0071]
4.d相参累加:通过对步骤4.c中共享内存中的数据进行累加,计算出成像 空间中的每一个像素点,得到最终的图像矩阵image[gx,gy],并存储在显存空间, 完成成像。即
[0072]
其中,image[bidx.x,bidx.y]为所有方位时刻在像素点(bidx.x,bidx.y)的散射值累 加值,也即图像幅度值。
[0073]
步骤5:将gpu设备端处理得到的图像矩阵拷贝到cpu主机端。
[0074]
使用cuda内置函数cudamemcpy()进行gpu设备端与cpu主机端通信, 将步骤4中所得图像image[gx,gy]拷贝回cpu主机端。
[0075]
综上所述,以上仅为本发明的较佳实施例而已,并非用于限定本发明的保 护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等, 均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1