基于ATR-FTIR同时检测牡蛎产地及糖原含量的方法
基于atr-ftir同时检测牡蛎产地及糖原含量的方法
技术领域
1.本发明涉及牡蛎检测技术领域。更具体地说,本发明涉及一种基于atr-ftir同时检测牡蛎产地及糖原含量的方法。
背景技术:
2.牡蛎又名蚝、海蛎子、蛎黄、蛎蛤、牡蛤、古贲、蚵,属软体动物门双壳纲珍珠贝目的曲蛎科和牡蛎科,是世界上最重要的养殖贝类和我国四大养殖贝类之一。牡蛎作为一种受欢迎的海鲜,因其高营养含量和美味的口感而备受关注。除了珍贵的食物资源外,几个世纪以来,牡蛎被广泛用作海洋中药材。它的肉被认为在治疗慢性疾病和保健方面有效。
3.地理标志产品,是指“利用产自特定地域的原材料,按照传统工艺在特定地域内所生产的,质量、特色或者声誉在本质上取决于其原产地域地理特征并依照本规定经审核批准以原产地域进行命名的产品。现阶段,如乳山牡蛎,湛江牡蛎等由于其独特的地域特色和品质特征已被认证的国家地理标志产品。牡蛎产地溯源认证体系关系到食品安全,消费权益保障,牡蛎养殖业发展等问题。目前我国的海产品可溯源性研究和追溯体系仍相对落后,急需建立可靠准确海产品认证方法。
4.糖原是细菌、真菌、哺乳动物细胞和双壳类软体动物葡萄糖储备的主要形式,被认为是风味和质量的关键分子贡献者。糖原含量较高的牡蛎通常口感更好。据报道,牡蛎糖原具有抗氧化、保肝、抗肿瘤、抗炎等生物活性。目前测定糖原含量多采用比色法,这些往往需要使用危险和有毒的溶剂和更长的样品制备和分析程序。因此,需要一种简便、绿色的糖原分析方法来提高牡蛎的糖原检测效率。
技术实现要素:
5.本发明的一个目的是解决至少上述问题,并提供至少后面将说明的优点。
6.为了实现根据本发明的这些目的和其它优点,提供了一种基于atr-ftir同时检测牡蛎产地及糖原含量的方法,包括以下步骤:
7.步骤一、检测不同产地的牡蛎组织干粉的atr-ftir数据和糖原含量;
8.步骤二、将步骤一中的atr-ftir数据导入光谱分析软件,进行二阶导数预处理得到产地的预处理光谱数据;
9.将步骤一中的atr-ftir数据导入光谱分析软件,进行多元散射校正和二阶导数的预处理得到糖原含量的预处理光谱数据;
10.步骤三、基于产地的预处理光谱数据和产地建立产地的偏最小二乘判别分析模型,即产地判别模型;
11.基于糖原含量的预处理光谱数据和糖原含量数据建立协同区间偏最小二乘回归模型,即得糖原含量定量模型;
12.步骤四、采用步骤一和步骤二的方法得到待测样品的牡蛎组织干粉的产地的预处理光谱数据和糖原的预处理光谱数据,并分别输入至产地判别模型和糖原含量定量模型,
分别对应输出得到该待测样品的产地和糖原含量。
13.优选的是,牡蛎组织的产地包括广西壮族自治区钦州市、广东省湛江市、福建省东山县、浙江省苍南县、河北省秦皇岛市、辽宁省大连市黄海海域、辽宁省大连市渤海海域、山东省乳山市。
14.优选的是,atr-ftir的光谱范围为650~4000cm-1
。
15.优选的是,建立所述产地判别模型的方法具体包括:
16.采用kennard-stone算法将各产地的牡蛎组织干粉的产地的预处理光谱数据和产地划分为训练集和验证集,其中,训练集为所有样品数的3/4,所述训练集用于建立产地的偏最小二乘判别分析模型,所述验证集用于验证产地的偏最小二乘判别分析模型;
17.将步骤二所得的产地预处理数据作为输入变量,产地变量作为输出变量导入统计分析软件进行归一化处理,得到所述产地判别模型。
18.优选的是,建立所述糖原含量定量模型的方法具体包括:
19.采用kennard-stone算法将各产地的牡蛎组织干粉的糖原含量的预处理光谱数据和糖原含量数据划分为训练集和验证集,其中,训练集为所有样品数的3/4,所述训练集用于建立协同区间偏最小二乘回归模型,所述验证集用于验证协同区间偏最小二乘回归模型;
20.将糖原含量的预处理光谱数据作为输入变量,糖原含量作为输出变量导入统计分析软件建立得所述糖原含量定量模型。
21.优选的是,制备牡蛎组织干粉的方法包括:将牡蛎样品洗净,剖取完整的牡蛎组织,冷冻干燥,研磨至牡蛎组织的粒径小于100目。
22.本发明至少包括以下有益效果:提供了一种绿色、环保、简单的牡蛎地理认证和糖原检测方法,以保证牡蛎的品质。该方法同时解决了牡蛎产地鉴别难、传统糖原检测耗时费的问题。本发明的检测方法具有精准性高,样品用量少,无需标准品等优点。该方法产地判别准确度达100%,糖原含量预测相关系数达0.96,预测相对分析误差rpd为3.58。
23.本发明的其它优点、目标和特征将部分通过下面的说明体现,部分还将通过对本发明的研究和实践而为本领域的技术人员所理解。
附图说明
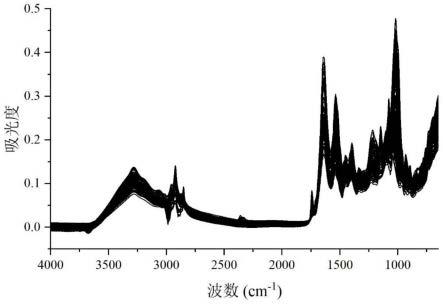
24.图1为所有牡蛎样本atr-ftir谱图;
25.图2为不同产地牡蛎代表atr-ftir谱图;
26.图3为二阶求导预处理后的pls-da模型三维得分图;
27.图4为二阶导数预处理后的pls-da模型200次置换检验;
28.图5为si-pls模型的区间选择结果;
29.图6为si-pls模型糖原含量预测结果。
具体实施方式
30.下面结合附图对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
31.需要说明的是,下述实施方案中所述实验方法,如无特殊说明,均为常规方法,所
述试剂和材料,如无特殊说明,均可从商业途径获得。
32.1、仪器设备
33.atr-ftir光谱获取采用美国赛默飞公司nicolet is20傅里叶变换红外光谱仪,配备znse atr晶体;
34.lc-12n-50b真空冷冻干燥机(上海力辰邦西仪器科技有限公司)。
35.样品原始谱图通过omnic9.0采集。tq analyst ez edition9.1软件用于对光谱进行预处理。
36.2、样品
37.实验采集8种不同产地的牡蛎,共128个样品。产地分别为广东湛江市(n=16)、浙江苍南县(n=17)、山东乳山市(n=12)、广西钦州市(n=16)、河北秦皇岛市n=17)、辽宁大连市黄海海域(n=16)、福建东山县(n=18)、辽宁大连市渤海海域(n=16),每组样本数以n表示。洗净待检的不同产地牡蛎样品,剖取完整的牡蛎组织冷冻干燥48h,将干燥后的牡蛎研磨均匀得到牡蛎干粉,最后通过100目的标准筛获得样品。所有样品最后保存于-20℃下备用;牡蛎样本糖原参考值通过糖原检测试剂盒(北京索莱宝科技有限公司)检测获取。
38.3、检测方法及检测结果
39.3.1红外光谱采集
40.在室温下对每个样品进行检测,扫描次数为16次,分辨率为4cm-1
,扫描范围为650~4000cm-1
。将牡蛎样品压在硒化锌晶体上,然后使用扭矩旋钮在测试过程中保持相同的压力。在测试完每个牡蛎样本后,用无水乙醇清洗硒化锌晶体。每个样本重复测量3次取均值。
41.3.2atr-ftir谱图解析与表征
42.如图2所示,3000~2800cm-1
处的峰为c-h振动区,主要由脂类和蛋白质引起。在1745cm-1
处出现的酯羰基(c=o)伸缩振动是由脂类中的酯官能团引起的。酰胺i带的c=0伸缩振动与1644cm-1
的峰有关。1546cm-1
处的峰属于c-n,n-h官能团的振动吸收(酰胺ii带)。酰胺i带和酰胺ii带出的峰主要是由蛋白质中的各种氨基酸组成。1200~1000cm-1
峰主要与c-c伸缩振动、c-o-c伸缩振动、po-2对称伸缩振动和so3对称伸缩振动有关,主要与蛋白质、磷脂、糖原和核酸等物质相关。
43.3.3光谱预处理方法
44.牡蛎原始光谱图存在背景和噪音信息干扰,为达到最大化样品之间所需信息的变异性和最小化无关信息,将原始光谱数据进行预处理,减少噪音信息。不同的预处理方法会使结果有所差异,研究对不同的信号预处理方法进行了比较,以改善分类模型、定量模型的性能,这些处理方法包括多元散射校正、一阶导数、二阶导数预处理、多元散射校正+一阶导数、多元散射校正+二阶导数。
45.定性模型拟合过程采用q2来评价,q2表示分类模型的预测能力,数值越接近1说明模型越好,越低说明模型的拟合准确性越差。定量模型采用内部交叉验证相对分析误差(rpd
cv
)、外部验证相对分析误差(rpd
cv
)来评估预处理方法对偏最小二乘回归(plsr)模型性能的影响。rpd》3代表模型性能高,稳健性好。结果如表1和表2,二阶导数预处理的偏最小二乘判别模型q2值最高,因此二阶导数被用来作为判别模型的预处理方法。定量模型中多元散射校正+二阶导数的rpd
cv
和rpdv均大于3,因此多元散射校正+二阶导数被用来作为糖原定量模型的预处理方法。
46.表1基于不同预处理方法的偏最小二乘判别模型(pls-da模型)参数
47.编号预处理方法r2xr2yq21原始谱图0.9940.6660.5242多元散射校正0.9970.8210.6283多元散射校正+一阶导数0.8440.9830.9444多元散射校正+二阶导数0.7270.9840.9495一阶导数0.8880.9860.956二阶导数0.720.9860.96
48.表2不同预处理方法对偏最小二乘回归模型(si-pls)的影响
[0049][0050]
rcv(训练集交叉验证相关系数);rmsec(训练集交叉验证均方根误差);rpdcv(训练集交叉验证相对分析误差);rv(验证集相关系数);rmsep(验证集均方根误差);rpdv(验证集相对分析误差)
[0051]
3.4偏最小二乘判别分析模型建立
[0052]
采用kennard-stone算法将各产地牡蛎干粉的光谱数据划分为训练集和验证集。训练集用来建立产地的判别模型,验证集用于验证上述模型的准确性。将原始数据用二阶导数预处理后,导入simca-p+14.1软件中,用7折交叉验证验证优化建模主成分数。采用200次置换检验评价偏最小二乘判别分析模型是否过拟合。置换检验结果如图4所示,所有左边r2和q2所有的点都低于原始点,且截距q2《0,表明所建模型可靠,过拟合风险低。图3为建立的pls-da模型的三维得分图,从图3中可以看出不同产地牡蛎样本呈现出了明显的分离趋势。
[0053]
3.5产地判别
[0054]
将验证集数据导入偏最小二乘判别分析模型中,对牡蛎产地进行判别。不同预处理下的支持向量机模型分类结果如表3所示,误判数为0,分类正确率为100%。表明atr-ftir结合偏最小二乘判别分析模型可以准确鉴别牡蛎的产地。
[0055]
表3基于二阶导数的pls-da模型验证集分类结果
[0056] 数量正确率abcdefgh无组别a6100%600000000b0100%000000000c3100%003000000d8100%000800000e7100%000070000f5100%000005000g1100%000000100h2100%000000020无组别0 000000000总数32100.00%433444640
[0057]
备注:a为福建东山县,b为浙江苍南县,c为辽宁大连市(渤海海域),d为辽宁大连市(黄海海域),e为广西钦州市,f为河北秦皇岛市,g为山东乳山市,h为辽广东湛江市。
[0058]
3.6协同区间偏最小二乘回归模型建立。
[0059]
采用kennard-stone算法将各产地牡蛎干粉的光谱数据和糖原含量划分为训练集和验证集。训练集用于建立模型,验证集用于验证模型。将全谱分为10、15、20、25、30等宽的光谱子区间,进行2,3,4个光谱子区间组合,并将组合的光谱数据作为输入变量,糖原含量作为输出变量建立协同的偏最小二乘回归模型(plsr)。
[0060]
3.7牡蛎糖原预测
[0061]
将验证集数据导入协同偏最小二乘回归模型中,协同偏最小二乘回归模型对验证集糖原含量预测结果如表4所示。当光谱被划分为25个区间,且区间组合方式为4的时候预测均方根误差和相对分析误差最小,分别为0.0174和3.58。此时模型选择的区间如图5所示,分别为2794~2928cm-1
、1320~1588cm-1
、1052~1186cm-1
。协同区间偏最小二乘回归模型预测结果如图6所示,预测值和参考值(实测值)具有较高的相关性,预测相关系数为0.9565。以上结果表明该协同区间偏最小二乘回归模型可以很好预测牡蛎中糖原的含量,具有较高的准确性。
[0062]
表4区间划分及组合方式对plsr模型预测效果的影响
[0063]
划分区间区间组合方式rmseprpdv1020.0183.461030.01783.501040.01823.431520.02142.911530.02152.901540.02092.982020.01843.392030.023.122040.01993.132520.01843.392530.01853.37
2540.01743.583020.02073.013030.02092.983040.02073.01
[0064]
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1