一种室内纯视觉机器人障碍物感知方法与流程
本发明涉及机器人,具体涉及一种室内纯视觉机器人障碍物感知方法。
背景技术:
1、在机器人的规划导航任务中,实时感知障碍物是必要的,这是实现机器人导航的必要条件。在室内环境中,由于场景比较简单。很多时候我们可以简化成二维的方式,直接利用单线激光或者多线激光将扫描到的障碍信息作为可行驶区域的边界。在该边界内,可以保证机器人的安全移动。
2、在现有的室内自主机器人导航系统中,大多使用双目相机和激光雷达的组合方案。双目能够提供周边物体的三维信息,但是存在近距离的盲目以及在远处深度信息效果严重下降等问题。单线激光价格相较于多线激光更加便宜,但是只能在二维平面内提供周边的障碍物信息。而多线激光虽然能够提供三维信息,但是价格十分昂贵,且在大多数时候点云是稀疏的。这些传感器虽然在一定程度上给自主移动机器人提供了一定的环境感知能力,但在很多时候是受限制的。并且一台机器人上往往需要搭载多个双目相机和激光雷达,这给自主机器人的硬件部署带来了挑战。
3、现如今自动驾驶技术发展迅猛,以特斯拉为代表的纯视觉自动驾驶技术迭代迅速,在很多时候已经能够胜任自动驾驶任务。特斯拉使用神经网络来对输入的图像进行各种处理,来实现各种检测任务,包括目标检测、道路线检测、道路边缘检测和各种场景的决策等。这是的神经网络技术主要是通过卷积神经网络提取特征,卷积神经网络由一个或多个卷积层和顶端的全连通层(对应经典的神经网络)组成,同时也包括关联权重和池化层(poolinglayer)。这一结构使得卷积神经网络能够利用输入数据的二维结构。与其他深度学习结构相比,卷积神经网络在图像和语音识别方面能够给出更好的结果。这一模型也可以使用反向传播算法进行训练。相比较其他深度、前馈神经网络,卷积神经网络需要考量的参数更少。
4、如上文所述使用神经网络可以完成诸多任务,现如今的主流方案是使用鸟瞰图(birdeye’view,bev)视角来对障碍物进行检测,因为无人驾驶场景中的大多数的目标物体都处在同一地面上。相比正视图,bev中的目标在不同位置大小固定,我们可以用已知的常见物体大小优化检测效果。
5、目前在室内场景,通常需要使用单线或者多线的激光雷达来进行障碍物的精准避碰,但激光雷达会带来昂贵的硬件成本不利于自主导航的部署和普及。且大部分的障碍物感知系统中都使用了双目相机通过视差的原理来获取环境深度,但存在近距离盲区以及在远处深度效果严重下降的情况。
技术实现思路
1、本发明的目的在于提供一种室内纯视觉机器人障碍物感知方法,将实验用设备集成化,形成一体化设备,以解决上述背景技术中提出的问题。
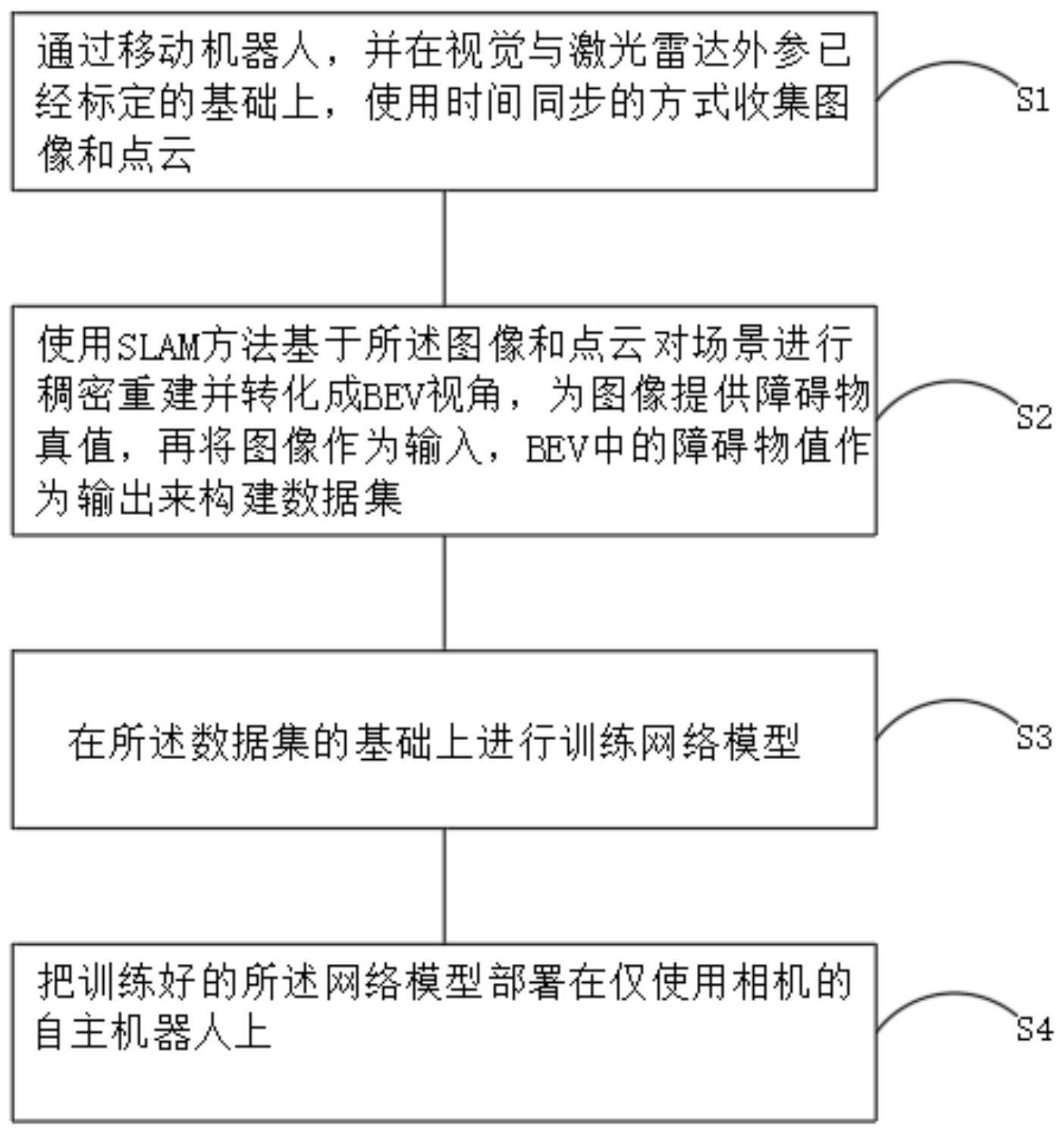
2、为实现上述目的,本发明提供如下技术方案:一种室内纯视觉机器人障碍物感知方法,包括:s1、通过移动机器人,并在视觉与激光雷达外参已经标定的基础上,使用时间同步的方式收集图像和点云;s2、使用slam方法基于所述图像和点云对场景进行稠密重建并转化成bev视角,为图像提供障碍物真值,再将图像作为输入,bev中的障碍物值作为输出来构建数据集;s3、在所述数据集的基础上进行训练网络模型;s4、把训练好的所述网络模型部署在仅使用相机的自主机器人上。
3、进一步的,所述通过移动机器人,并在视觉与激光雷达外参已经标定的基础上,使用时间同步的方式收集图像和点云,包括:在所述机器人的移动底盘上布置激光雷达传感器和多个单目相机;使用相机标定方法对相机内参进行标定,使用激光-相机标定方法对相机和激光雷达的外参进行标定。
4、进一步的,在所述使用相机标定方法对相机内参进行标定,包括:相机矩阵标定,包括焦距(fx,fy),光学中心(cx,cy),可用矩阵表示如下:
5、
6、畸变系数,畸变数学模型的5个参数,d=(k1,k2,p1,p2,k3),其中,k1,k2,k3为径向畸变系数,p1,p2切向畸变系数;
7、使用棋盘格标定法对相机内参进行标定,得到相机内参k。
8、进一步的,所述畸变系数包括径向畸变和切向畸变;
9、所述畸变系数表达式为:
10、xcorrected=x(1+k1r2+k2r4+k3r6)
11、ycorrected=y(1+k1r2+k2r4+k3r6);
12、所述切向畸变表达式为:
13、xcorrected=x+[2p1xy+p2(x2+2x2)]
14、ycorrected=y+[p1(r2+2y2)+2p2xy+]。
15、进一步的,在所述使用激光-相机标定方法对相机和激光雷达的外参进行标定,包括:对激光-相机进行固定,相机部分使用pnp算法检测棋盘格标定板的姿态,激光雷达部分在对收集到的激光点云圈出标定板所在的区域之后,进行ransac拟合来得到标定板在激光雷达坐标下的空间位置,移动标定板,在采样几组数据之后,计算得出两者的外参;
16、
17、其中,pc为收集到的视觉识别到空间信息,pl为激光识别到的空间信息,为求出的外参关系。
18、进一步的,在所述使用时间同步的方式收集图像和点云,包括:使用相机来实现视觉里程计,并通过词袋法实现场景回环检测;激光雷达通过边缘点-平面点提取器提取激光点云中的特征点,通过特征点匹配估计前后帧之间的机器人位姿变化,形成激光里程计;通过非线性位姿图优化的方式融合激光里程计、视觉惯性里程计和回环约束,获得整个场景的点云。
19、另一方面,本发明还提出一种室内纯视觉机器人障碍物感知装置,包括:数据收集模块,用于通过移动机器人,并在视觉与激光雷达外参已经标定的基础上,使用时间同步的方式收集图像和点云;数据前处理模块,用于使用slam方法基于所述图像和点云对场景进行稠密重建并转化成bev视角,为图像提供障碍物真值,再将图像作为输入,bev中的障碍物值作为输出来构建数据集;网络训练模块,用于在所述数据集的基础上进行训练网络模型;实机部署模块,用于把训练好的所述网络模型部署在仅使用相机的自主机器人上。
20、进一步的,所述数据收集模块包括移动底座、激光雷达传感器及相机;其中,所述相机设置四组,分布在移动底座的四个方向上,所述激光雷达传感器连接在移动底座的顶部。
21、另一方面,本发明还提出一种计算机可读存储介质,所述计算机可读存储介质存储有多条指令,所述指令适于处理器进行加载,以如上述的室内纯视觉机器人障碍物感知方法。
22、另一方面,本发明还提出一种终端设备,包括处理器和存储器,所述存储器存储有多条指令,所述处理器加载所述指令以执行如上所述的室内纯视觉机器人障碍物感知方法。
23、综上所述,由于采用了上述技术,本发明的有益效果是:
24、本发明中使用自动生成数据集的方法来减少人工的参与,并且在实机部署中,仅使用单目相机,降低了硬件成本和传感器部署的复杂度,在实机部署后亦可通过改进场景重建的方法,使得系统可以不断的生成新的数据集,从而不断迭代地提高效果;另外,基于室内机器人在平面移动的特点,使用基于鸟瞰图的方式将周边的障碍物信息通过深度学习的方法投影到平面后,再提供给规划模块来实现障碍物的避碰,成本低,鲁棒性高,应用场景广泛。
- 还没有人留言评论。精彩留言会获得点赞!