一种基于在线校正的视觉增强激光里程计方法
本发明属于计算机视觉的一种无监督视觉-激光里程计方法,特别是涉及了一种基于在线校正的视觉增强激光里程计方法。
背景技术:
1、里程计方法又称位姿估计,是无人驾驶、增强现实等任务中的关键问题。传统的里程计方法往往遵循特征提取、特征匹配、位姿解算的三步流程,但是这类方法高度依赖手工设计的特征,在光照变化剧烈、存在弱纹理区域的复杂场景中易受到影响。近期深度学习方法在图像分类、目标检测等许多计算机视觉问题中都证明了其在特征提取上的卓越性能,因此基于深度学习的里程计方法也开始得到越来越多的研究者关注。如zhou等人发表在《proceedings of the ieee/cvf conference on computer vision and patternrecognition》的《unsupervised learning of depth and ego-motion from video》以及cho等人发表在《2020ieee international conference on robotics and automation》的《unsupervised geometry-aware deep lidar odometry》,分别为无监督的弹幕视觉里程计和激光里程计方法,可以在没有任何真值的情况下直接从单目图像序列或三维点云序列进行学习。
2、然而截至目前,基于深度学习里程计方法的相关研究中很大一部分都集中在视觉里程计(visual odometry,vo)或激光里程计(lidar odometry,lo)上,视觉-激光里程计(visual-lidar odometry,vlo)的研究还相对较少。而视觉-激光信息的互补优势,已经在许多的计算机视觉任务(如3d目标检测,深度补全以及场景流估计)中得到应用,因此对于vlo的研究依旧是很有前景的研究方向。
3、现有的深度学习视觉-激光里程计方法都采用了视觉主导的融合策略,如li等人发表在《2021ieee winter conference on applications of computer vision》的《self-supervised visual-lidar odometry with flip consistency》,将激光雷达采集的三维点云投影到相机成像平面得到与单目彩色图像分辨率相同的稀疏深度图,输入彩色图像序列和稀疏深度图序列来预测帧间位姿。但是这种方法面临两个问题,首先是稀疏深度图和稠密彩色图像之间的特征融合存在困难,另外这种方法需要同时预测一张稠密深度图和帧间位姿才能实现无监督训练,而这也导致位姿很容易受预测深度图的噪声影响。
4、无监督学习可以使用在线优化方法,在测试阶段进一步优化网络模型预测结果。根据优化过程中的优化参数类型可以分为在线学习和在线校正两种。前者对网络权重进行优化,后者则直接将网络的预测结果作为待优化变量。相比于在线学习来说,在线校正方法可以显著减少待优化参数数量,有更高的计算效率。但是现有的采用在线优化的里程计方法均采用了视觉主导的策略,如zhang等人发表在《2021ieee international conferenceon robotics and automation》的《deep online correction for monocular visualodometry》,这种方法需要同时预测稠密深度图和帧间位姿来构建优化目标函数,导致位姿优化的性能极易受预测深度的噪声干扰。
技术实现思路
1、为了解决背景技术中存在的问题,本发明提供了一种基于在线校正的视觉增强激光里程计方法,采用激光主导的融合策略,通过球面投影将三维点云投影成一张稠密的顶点图,并找到顶点图上每个3d点在彩色图像上的对应像素位置,用对应像素的颜色为该点进行着色,得到顶点着色图。本发明将顶点图和顶点着色图序列输入视觉增强激光里程计网络预测位姿。由于顶点图和顶点着色图都是2d稠密图像,本发明可以更好地进行视觉-激光模态融合。同时本发明的方法不需要额外预测深度图,只需要预测帧间位姿就可以构建损失函数进行无监督训练。随后在测试阶段本发明引入位姿在线校正模块对训练好的视觉增强激光里程计网络posenet的预测位姿做进一步优化,并引入难例挖掘技术筛选对优化贡献更高的难例促进优化效果。
2、本发明利用了激光主导融合策略来设计视觉-激光里程计,相比于采用了将三维点云投影成稀疏深度图的视觉主导融合策略的方法来说,不仅可以更好地进行视觉-激光模态融合,而且还只需要预测帧间位姿就可以进行训练,简化了优化问题的难度,极大提高了在线优化的效果,取得了显著的性能提升。与采用在线优化的视觉主导里程计方法相比,本发明在主要误差指标上都取得了更好的表现。
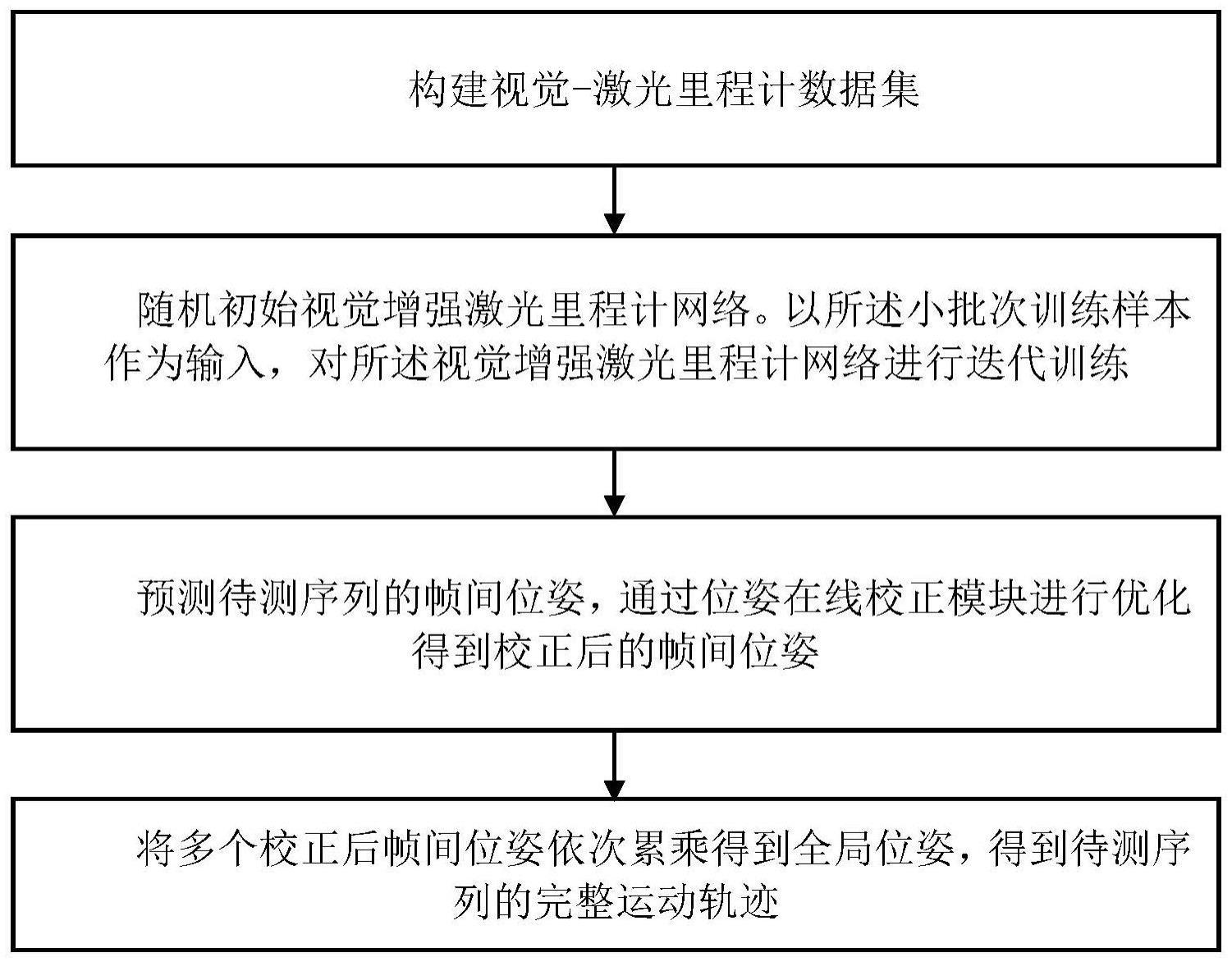
3、本发明采用的技术方案是:
4、1)使用彩色相机和激光雷达联合采集后获得场景的彩色图像序列和对应的三维点云序列,再对场景的彩色图像序列和对应的三维点云序列预处理后生成对应的顶点图序列、法向量图序列、顶点着色图序列,由彩色图像序列和对应的顶点图序列、法向量图序列、顶点着色图序列组成视觉-激光里程计数据集;
5、2)利用视觉-激光里程计数据集对视觉增强激光里程计网络posenet进行训练,获得训练好的视觉增强激光里程计网络posenet;
6、3)待测的彩色图像序列和对应的三维点云序列中,由相邻两帧的待测彩色图像和对应的三维点云组成一个待测图像输入对,将各个待测图像输入对预处理后生成对应的待测顶点图与顶点着色图输入对,再将所有待测顶点图与顶点着色图输入对依次输入到训练好的视觉增强激光里程计网络posenet中,分别输出各个待测图像输入对对应的预测帧间位姿;
7、4)根据待测的彩色图像序列,利用位姿在线校正模块对各个待测图像输入对对应的预测帧间位姿分别进行优化校正,获得各个校正后的帧间位姿;
8、5)将各个校正后的帧间位姿依次累乘后获得全局位姿。
9、所述1)具体为:
10、由彩色相机采集连续时刻下场景的彩色图像,获得彩色图像序列,再由激光雷达采集同样连续时刻下相同场景的三维点云,获得三维点云序列;对于三维点云序列中每帧三维点云,首先将每帧三维点云进行球面投影后得到对应的顶点图,接着基于顶点图求解每个点的法向量,得到对应的法向量图,最后通过相机成像投影找到顶点图上每个点在对应彩色图像中的相应颜色,得到顶点着色图,遍历三维点云序列后,基于三维点云序列处理获得对应的顶点图序列、法向量图序列和顶点着色图序列,由彩色图像序列及对应的顶点图序列、法向量图序列和顶点着色图序列组成视觉-激光里程计数据集。
11、所述2)中,视觉增强激光里程计网络posenet的总损失函数是根据彩色图像、顶点图、顶点着色图、法向量图以及预测帧间位姿进行计算,每次训练时,视觉增强激光里程计网络posenet的输入为顶点图序列中连续两帧的顶点图以及对应的两帧顶点着色图,视觉增强激光里程计网络posenet的输出为当前两帧的预测帧间位姿。
12、所述视觉增强激光里程计网络posenet由特征编码器和位姿预测器相连组成;
13、特征编码器由11个卷积模块依次连接构成,视觉增强激光里程计网络posenet的输入经通道级联后再作为第一卷积模块的输入,第十一卷积模块的输出作为特征编码器的输出,位姿预测器包括两个卷积模块和两个卷积池化单元,特征编码器的输出作为第十二卷积模块的输入,第十二卷积模块与第十三卷积模块相连,第十三卷积模块与两个卷积池化单元相连,两个卷积池化单元分别输出帧间位姿中的平移向量和欧拉角向量,两个卷积池化单元的输出作为视觉增强激光里程计网络posenet的输出。
14、所述两个卷积池化单元的结构均相同,由卷积模块、全局平均池化模块和卷积层依次连接构成,所有的卷积模块的结构均相同,由卷积层、批归一化层和激活函数层依次连接组成。
15、所述视觉增强激光里程计网络posenet的总损失函数是根据彩色图像、顶点图、顶点着色图、法向量图以及预测帧间位姿进行计算,具体为:
16、s1:根据每张顶点图生成对应的有效顶点二值掩膜图mv,计算公式如下:
17、
18、其中,mv(u)表示有效顶点二值掩模图mv中像素位置u处的顶点有效性,v(u)表示顶点图中像素位置u的点坐标,为指示函数,||||为l2范数;
19、s2:计算法向量图中每个点与周围四个邻点的法向量之间的余弦相似度,获得当前点的置信度,从而获得法向量图对应的置信度图c,基于法向量图和置信度图c生成对应的有效法向量二值掩膜mn,计算公式如下:
20、
21、
22、其中,δc表示置信度的阈值,表示像素位置u相邻的4个像素位置集合,mn(u)表示有效法向量二值掩膜mn中像素位置u的法向量有效性,c(u)表示置信度图中像素位置u的法向量置信度,n(u)表示法向量图中像素位置u的法向量,n(ui)表示法向量图中像素位置u的相邻像素ui的法向量;
23、s3:基于顶点着色图vc生成对应的有效颜色二值掩膜mc,计算公式如下:
24、
25、其中,mc(u)表示有效颜色二值掩膜mc中像素位置u的顶点对应颜色有效性,vc(u)表示顶点着色图vc中像素位置u的颜色;
26、s4:根据有效顶点二值掩膜图mv和有效法向量二值掩膜mn构建几何损失函数,公式如下:
27、
28、
29、mgeo=mvt+1⊙mnt+1
30、pt=vt(π(p′t))
31、其中,表示几何损失函数值,p′t表示通过利用网络预测的帧间位姿pt←t+1转换得到的变换矩阵tt←t+1将第t+1帧的顶点图中每个点pt+1变换到第t帧得到投影点,表示投影点p′t在第t帧的顶点图vt中的匹配点,dgeo()表示计算两个匹配点p′t和之间的点-面匹配误差的函数,mgeo表示局部平面区域二值掩膜,⊙表示逐元素乘法;||||1表示取l1范数的操作,mgeo(ut+1)表示局部平面区域二值掩膜mgeo中像素ut+1的几何误差有效性,mvt+1表示第t+1帧的有效顶点二值掩膜图,mnt+1表示第t+1帧的有效法向量二值掩膜,vt表示第t帧的顶点图;ct()表示第t帧的置信度图中每一像素位置的置信度,π()表示球面投影;
32、s5:根据有效颜色二值掩膜mc和有效法向量二值掩膜mn构建视觉损失函数,公式如下:
33、
34、mvis=mct+1⊙(1-mnt+1)
35、
36、其中,表示视觉损失函数值,mvis表示法向量置信度较低的有效像素的二值掩膜;u′t表示通过利用网络预测的帧间位姿pt←t+1转换得到的变换矩阵tt←t+1将第t+1帧的顶点图中每个点pt+1变换到第t帧后得到投影点p′t,再利用相机投影函数找到得到投影点p′t在彩色图像it上的投影像素坐标,表示投影像素坐标u′t在彩色图像it上的颜色,dvis(ut+1)表示计算像素ut+1和u′t之间颜色差异的函数;
37、s6:根据几何损失函数和视觉损失函数构建总损失函数:
38、
39、其中,表示总损失函数值,λ表示视觉损失函数的权重。
40、所述4)具体为:
41、4.1)将每个待测图像输入对对应的预测帧间位姿pt←t+1作为当前两帧的初始帧间位姿
42、4.2)根据当前两帧的当前帧间位姿计算后一帧的顶点图中各个点在前一帧顶点图中对应的匹配点,基于前一帧顶点图中对应的匹配点计算后一帧的顶点图中各个点的相对标准差,从而获得当前两帧的相对标准差图rsd;
43、4.3)根据当前两帧的相对标准差图rsd,利用以下公式筛选获得难例二值掩膜
44、rsd(ut+1)=std(dp)/mean(dp)
45、
46、其中,rsd(ut+1)表示第t+1帧的顶点图vt+1中点pt+1对应的相对标准差,std()表示计算标准差的函数,mean()表示计算均值的函数,表示像素ut+1处是否存在难例;
47、4.4)根据局部平面区域的二值掩膜mgeo和难例二值掩膜计算获得只包含难例的局部平面区域掩膜
48、
49、4.5)根据视觉损失函数和只包含难例的局部平面区域掩膜构建难例挖掘的损失函数,公式如下:
50、
51、
52、其中,表示难例挖掘的损失函数值,表示视觉损失函数值,表示在难例区域计算的几何损失函数值,λ表示视觉损失函数的权重;
53、4.5)以难例挖掘的损失函数为优化目标函数,对当前两帧的当前帧间位姿进行梯度下降更新,获得优化后的帧间位姿;
54、4.6)重复4.2)-4.5)n次,获得当前两帧的校正后的帧间位姿;
55、4.7)重复4.1)-4.6),对剩余待测图像输入对对应的预测帧间位姿pt←t+1进行优化校正,获得所有校正后的帧间位姿。
56、所述4.2)中,对于前一帧顶点图中每个匹配点pt,首先,将以当前匹配点pt为中心、大小为5×7的局部窗口内的点作为候选匹配点,接着计算当前匹配点pt与所有候选匹配点之间的匹配误差,得到候选匹配误差集合dp,最后,计算候选匹配误差集合dp的相对标准差并作为当前匹配点pt的相对标准差。
57、本发明方法使用激光主导融合策略设计了一个视觉增强激光里程计网络,通过球面投影将原始激光雷达三维点云投影成顶点图,并用对应彩色图像着色得到顶点着色图,实现了视觉-激光模态数据的稠密表示。视觉增强激光里程计网络以连续顶点图和顶点着色图作为输入,以自监督的方式进行训练。在测试阶段,本发明固定视觉增强激光里程计网络的网络参数,通过位姿在线校正模块迭代更新视觉增强激光里程计网络预测的帧间位姿。
58、本发明首先构建一个视觉-激光里程计数据集,其包括连续的彩色图像、顶点图、法向量图和顶点着色图序列;将待训练数据以小批次训练的方式用于训练视觉增强激光里程计网络;将训练好的视觉增强激光里程计网络参数固定,通过位姿在线校正模块进一步优化视觉增强激光里程计网络的预测帧间位姿。
59、本发明可以在不引入任何全局优化与闭环模块的情况下,可以取得和带有全局优化或闭环模块的方法接近甚至更好的性能,在平移性能和旋转性能上处于领域前列。
60、本发明具有以下有益效果:
61、1、相较于视觉主导融合策略的里程计方法,本发明将输入的视觉-激光模态数据都处理成稠密2d图像,可以促进视觉-激光模态融合的效果,更充分地利用视觉-激光模态的互补特性。
62、2、相较于采用在线优化的视觉主导里程计方法,本发明不需要额外预测稠密深度图,极大地降低了优化的复杂度,避免了预测深度的噪声干扰,有更好的优化效果
63、3、本发明在整个训练过程中都不需要额外的真值标签,故有较好的通用性和普适性。
- 还没有人留言评论。精彩留言会获得点赞!