一种基于注意力和循环PPO实现的导航决策方法
本发明涉及图像处理,具体涉及一种基于注意力和循环ppo实现的导航决策方法。
背景技术:
1、路径规划是机器人导航必不可少的技术,该技术旨在让机器人以最小代价在所处环境中找到最短且无碰撞障碍物的路径。传统的路径规划技术有a*算法、粒子群优化算法、模拟退火算法等。但上述算法仅适用于完全可观测环境的路径规划,现实中的环境大多是部分可观测的,存在着状态信息不完整、稀疏奖励等困难情景,大大提高了智能体的探索难度。
2、得益于深度学习与强化学习的技术发展,大多学者开始考虑将深度学习的感知能力与强化学习的决策能力进行结合,为智能体在复杂环境的路径规划问题提供了解决方案。申请公布号为cn115469683a的专利文献公开了一种基于ppo算法的无人机编队飞行方法及系统,该方法基于深度强化学习ppo算法对每架无人机将收集的周围物体与其的距离和方向信息进行分析然后做出决策,实现了无人机自主编队飞行训练,经过训练的无人机能够形成编队,精确避开周围障碍物与其他无人机,顺利达到指点地点。申请公布号为cn113255890a的专利文献公开了一种基于ppo算法的强化学习智能体训练方法,该方法能解析环境的关键信息,提供自动模型生成功能。但上述方法都没有能力解决部分可观测环境的探索与避障问题或仅能解决受视野观察影响较小的部分可观测探索问题。
3、随着深度学习与强化学习的发展,引入循环神经网络算法的记忆功能可以很好地解决部分可观测环境的探索任务,同时具有一定的泛化能力,但存在这训练速度较慢这一问题。同样注意力机制的提出,能更好地提取环境中的重要关键信息,在部分可观测环境中获取高价值信息无疑是提高了训练的速度。循环神经网络与注意力机制在部分可观测环境探索任务中有着巨大优势。
4、因此,本专利提出一种基于注意力和循环ppo实现的导航决策方法。
技术实现思路
1、本发明的目的是为了解决现有技术存在的对于部分可观测环境探索任务中的状态信息分析能力差、依赖较多状态信息数据、且无法仅用ppo算法解决较为复杂的部分可观测环境探索任务的技术问题,而提供的一种基于注意力和循环ppo实现的导航决策方法。
2、为了解决上述技术问题,本发明采用的技术方案为:
3、一种基于注意力和循环ppo实现的导航决策方法,它包括以下步骤:
4、步骤1:智能体与环境交互获取环境图像数据信息;
5、步骤2:对获取的图像信息进行编码,压缩状态信息,提高训练效率;
6、步骤3:构建多核卷积神经网络模块对环境信息进行初步特征提取;
7、步骤4:构建注意力模块与lstm的结合网络对特征信息进行筛选与压缩,获取重要且关键的信息;
8、步骤5:将经过模型提取的重要历史信息输入到actor网络获取动作,输入到critic网络评估价值;
9、步骤6:智能体根据actor网络所得概率矩阵选取动作,与环境交互一定次数后,数据存入经验池;
10、步骤7:随机抽取batch_size大小的数据进行训练,计算损失函数,进行梯度裁剪,最终通过反向传播进行参数更新。
11、步骤2具体包括以下子步骤:
12、步骤2-1)将由步骤1获取到的环境数据中的图像信息进行整体编码处理;
13、步骤2-2)根据图像中目标单位的颜色、状态这些信息进行编码设计;
14、步骤2-3)整合状态信息,将图像数据信息最终压缩成编码信息,提高训练效率。
15、在步骤3中,构建两层cnn卷积网层,使用多个卷积核对环境编码信息进行特征处理,采用的cnn卷积网络公式为:
16、xt=σcnn(wcnn⊙xt+bcnn)
17、xt表示当前的环境状态特征,wcnn表示过滤器的权重矩阵,bcnn表示偏置向量,σcnn是激活函数。
18、在步骤4中,具体包括以下子步骤:
19、步骤4-1)卷积网络模块提取的特征输入到注意力网络模块,其中多头注意力网络能够使模型在多个位置上共同关注不同子空间的信息,最后将各空间所得信息进行拼接,能够更好地对重要信息增加权重,多头注意力网络公式为:
20、q=xwq
21、k=xwk
22、v=xwv
23、
24、
25、multi(q,k,v)=concat(headi,…,headi)wo
26、公式中q表示查询矩阵,k表示键矩阵,v表示值矩阵,它们由输入的特征向量x分别与对应的权重矩阵wq,wk,wv相乘所得,attention(q,k,v)表示注意力公式,由矩阵q与矩阵k的转秩相乘的结果除以矩阵q,k,v维数的平方根,然后乘以矩阵v所得,softmax表示激活函数,headi表示第i个头部的注意力信息,表示第i个头部对应q的权重矩阵,表示第i个头部对应k的权重矩阵,表示第i个头部对应v的权重矩阵,multi(q,k,v)表示通过conact连接函数整合各头部重要信息的多头注意力特征信息,wo表示计算头部注意力实例线性变换的矩阵;
27、4-2)将注意力模块的输出结果输入到lstm网络;lstm神经网络通过引入3个门控结构和1个长期记忆单元,来控制信息的流通和损失,其计算公式为:
28、ft=σ(wfxt+ufht-1+bf)
29、it=σ(wixt+uiht-1+bi)
30、ot=σ(woxt+uoht-1+bo)
31、
32、
33、其中ft表示t时刻遗忘门信息,it表示t时刻输入门信息,ot表示t时刻输出门信息,ct表示t时刻记忆细胞状态,前一时间的隐状态ht-1与序列xt输入到网络中,同时更新隐状态和记忆细胞状态,wf,wi,wo,uf,ui,uo表示对应各门控结构的权重矩阵,bf,bi,bo,bc表示偏置向量,wc与uc表示记忆细胞内的权重矩阵,σ代表sigmoid激活函数,表示哈达玛积,tanh为双曲正切函数。
34、在步骤5中,构建基于actor-critic的网络层,actor网络使用全连接层对特征信息进行压缩,生成动作概率分布矩阵,critic网络使用全连接层获取当前状态的评估值;
35、在步骤6中,智能体依概率选取动作,将选择的动作输入到环境的step函数中,获取当前选择的reward等数据,每交互后一定次数后,将所得的数据存入经验池。
36、在步骤7中,包括以下子步骤:
37、随机选取batch_size大小的样本数据进行训练,使用重要性采样评估新旧策略的差距,重要性采样公式为:
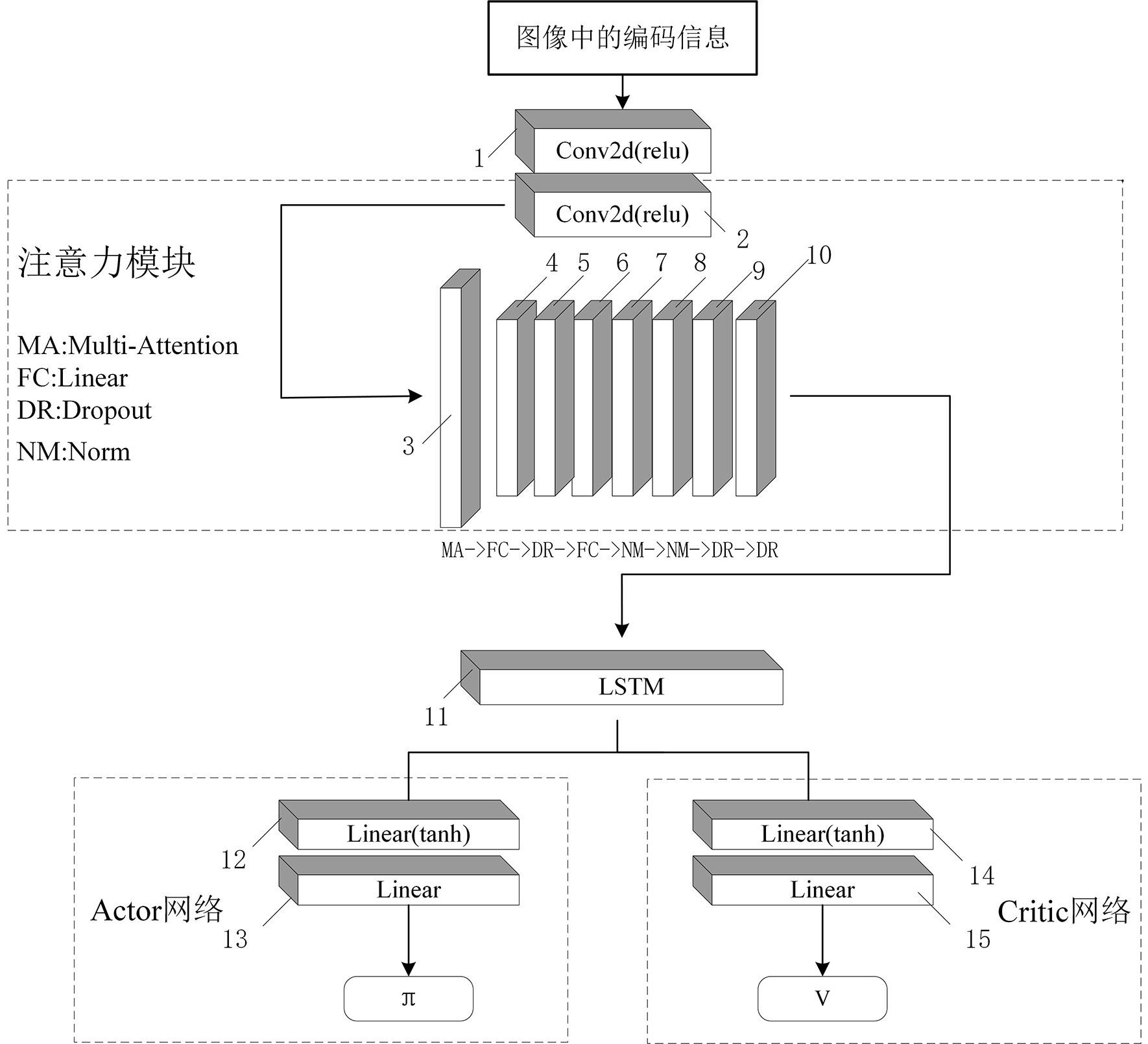
38、
39、πθold(a|s)表示的在s状态下采取动作a后的旧策略,πθ(a|s)表示在s状态下采取动作a后的新策略,通过梯度裁剪,限制策略参数的更新幅度,其公式如:
40、a=q(s,a)-v(s,a)
41、lclip(θ)=e[min(r(θ)a,clip(r(θ),1-ε,1+ε)a]
42、其中ε为超参数,a为优势函数,q(s,a)代表在状态s下采取动作a的累积奖励值,v(s,a)为状态估计值,当优势函数a>0时,说明该动作比平均动作好,需要增大该动作选择概率,当a<0时,则需要减少该动作的选择概率,e表示期望函数,min为取最小值函数,r(θ)为上述公式所求的重要性采样比,clip为截断函数,ppo算法较其他深度强化学习算法更保守,设置了上限为1+ε,下限为1-ε的区间限制策略参数更新幅度,保证新策略与旧策略相差不大,更新策略参数,策略梯度参数更新公式为:
43、
44、上述所使用的θ均表示策略参数,而策略参数更新的实质就是找到使得截断损失函数lclip(θ)期望值最大的策略参数,argmax为求使得函数取最大值的求参函数。
45、一种基于注意力与循环神经网络的arppo模型,它的结构为:
46、编码特征提取卷积模块的第一卷积层→编码特征提取卷积模块的第二卷积层→编码特征提取注意力模块的多头注意力层→编码特征提取注意力模块的第一全连接层→编码特征提取注意力模块的第一丢弃层→编码特征提取注意力模块的第二全连接层→编码特征提取注意力模块的第一标准化层→编码特征提取注意力模块的第二标准化层→编码特征提取注意力模块的第二丢弃层→编码特征提取注意力模块的第三丢弃层→编码特征提取循环神经网络模块的lstm层;
47、编码特征提取循环神经网络模块的lstm层→策略选择actor网络模块的第一全连接层→策略选择actor网络模块的第二全连接层;
48、编码特征提取循环神经网络模块的lstm层→状态价值评估critic网络模块的第一全连接层→动作价值评估critic网络模块的第二全连接层。
49、该模型在工作时,采用以下步骤:
50、1)从环境中获取的初始状态信息,使用卷积网络模块对图像编码信息进行初步特征提取,通过第一卷积网络层与第二卷积网络层,提取数据的深层多维信息;
51、2)将提取出的深层多维信息输入到注意力模块中;首先输入至多头注意力网络中捕捉信息的关联性,在多个不同位置上提取特征信息中重要且关键的信息并拼接,然后通过第一全连接层、第一丢弃层进行特征处理并选择丢弃一部分数据防止出现过拟合现象,接着第二全连接层实现上一层全连接层的残差连接,使用第一标准化层、第二标准化层进行层归一化处理,解决层与层之间梯度的稳定性问题,最终再通过第二丢弃层、第三丢弃层丢弃部分数据,防止过拟合;
52、3)将注意力模块输出的特征信息输入到循环神经网络模块的lstm层,通过引入lstm网络提取数据的时域特性,使得智能体在探索过程中形成长时记忆;
53、4)最后将循环神经网络模块的输出特征输入到actor网络模块与critic网络模块,actor网络模块通过第一全连接层进行特征信息综合,接着通过第二全连接层获取智能体所采取的动作及其概率分布,critic网络模块使用第一全连接层综合特征信息,最后使用第二全连接层对智能体所处当前状态进行价值评分。
54、与现有技术相比,本发明具有如下技术效果:
55、1)本发明使用基于注意力网络与循环神经网络结合的深度强化学习ppo算法有利用使智能体获取更多有价值的信息,在部分可观测环境中使智能体能够形成长时记忆,且训练收敛速度很快,有助于指导智能体能够快速完成无地图的探索任务;
56、2)本发明通过添加lstm网络为样本数据建立时序依赖关系,而引入注意力机制则强化了长距离中重要且关键的样本数据之间的依赖关系,使得智能体能形成长时记忆,能够解决动态随机性强的pomdp探索任务;
57、3)本发明无需要依赖过多的样本数据信息进行决策,智能体每回合根据时间步保留记忆信息,避免出现反复的无效探索动作,提高了探索效率,加快了算法的收敛速度,且通过记忆信息能达到精确避开障碍物,完成探索任务。
- 还没有人留言评论。精彩留言会获得点赞!