一种锂电池健康状态的估计方法
本发明涉及锂电池,特别涉及一种锂电池健康状态的估计方法。
背景技术:
1、随着电力行业高速发展,各个领域对稳定储能系统需求不断增长。锂电池因其循环寿命长、工作温度范围宽、能量密度高、绿色环保的优点成为了定制储能的首选系统。据分析师推测,全球对锂电池的需求会进一步提高,到2030年,将达到3太瓦时以上。但随着锂电池使用循环次数增加和自放电性等因素,锂电池会出现可用容量减少下降的老化现象。当锂电池老化到某种程度,就无法继续正常运行,这个时候锂电池很容易发生故障,会产生高昂的维修成本,暗藏巨大的安全风险,甚至产生毁灭性的后果,因此应该及时更换锂电池。
2、为了衡量锂电池的老化程度,电池健康状态被提出,并为老化锂电池的更换提供重要依据。精确的健康状态预测有利于了解到电池组或电池单体的剩余寿命情况,从而安全可靠的使用锂电池。因此无论在储存、使用还是运输中,健康状态都是评估电池寿命不可或缺的参数,准确的健康状态估算对锂电池发挥最佳性能和安全运行有重大意义。健康状态通常定义为实际容量和标称容量的比例。
3、近年来,锂电池耐久性研究已成为一个具有实际应用价值的重大热点课题,估算健康状态的方法主要分为三类,分别是基于电化学模型的方法和基于等效电路模型的方法以及基于数据驱动的方法。基于电化学模型的方法是通过建立电池内部化学反应的模型来解释电池的老化机理。但是电化学模型通常包含多个复杂的方程和高度耦合的模型参数,主要应用于电池内部电化学反应的研究。等效电路模型的基本原理是通过使用锂电池在循环过程中表现出来的特征参数等,通过滤波算法建立特征参数与健康状态的关系,进一步估计锂电池的健康状态。使用等效电路模型估算的方法虽能较准确的估计电池健康状态,但过度依赖模型与参数的精准度,需要建立不同的模型来应对不同的情况,泛化能力较弱。基于数据驱动的预测方法不需要考虑复杂的电化学特性,因此在建模时可被视为一个“黑盒系统”,这类方法需要从电池历史退化数据和状态监测数据(电流、电压、温度等)中挖掘信息,并仿真建立能够反映电池退化的统计模型,来预测电池的健康状态。数据驱动方法通过分析电池的充放电循环退化数据,基于统计分析的方法,找到数据中隐藏的输入输出映射关系,并建立能够反映电池退化的统计模型,相比于使用单个模型进行预测,模型融合的思想是将多个模型按照一定方式进行组合,以期望得到比单个模型更好的效果。
技术实现思路
1、发明目的:针对现有技术存在的问题,本发明提供一种锂电池健康状态估计方法,能提高锂电池健康状态估计模型精度。
2、技术方案:本发明提出一种锂离子电池健康状态估计方法,包括以下步骤:
3、步骤1:收集不同工况下锂离子电池单体充放电的电压、电流、温度、容量数据,利用离群因子检测lof方法对异常数据进行剔除;
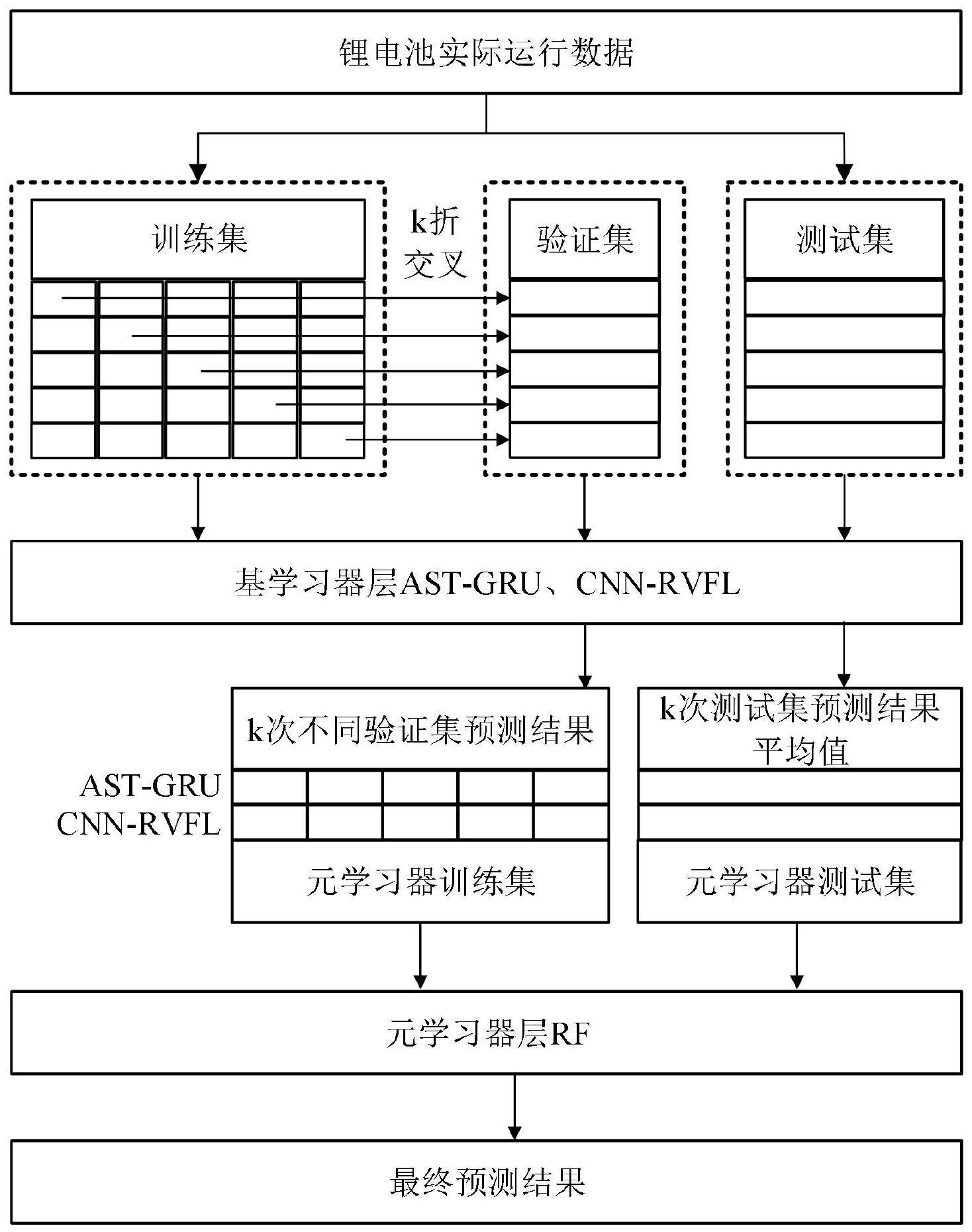
4、步骤2:使用k折交叉法对数据进行划分,构建stacking集成模型训练的数据集合;
5、步骤3:构建堆叠集成学习模型,并搭建基学习器和元学习器双层结构,将ast-gru和cnn-rvfl作为基学习器,随机森林作为元学习器,把训练基学习器产生的元特征数据,输入到元学习器中进行学习;
6、步骤4:对堆优化算法hbo进行改进,采用singer混沌映射方法对种群进行初始化,引入维度学习的方法增强间接层的信息交互,得到ihbo算法;
7、步骤5:利用ihbo算法对步骤3中基学习器和元学习器的超参数进行优化,获得最优超参数,利用优化后的的堆叠集成学习模型对电池健康状态进行估计,得到锂电池健康状态的估计结果。
8、进一步地,所述步骤1中采用离群因子检测lof方法对采集到的原始数据进行处理,包括以下步骤:
9、步骤1.1:计算每个数据点的第k距离邻域内各点的第k可达距离,其公式为:
10、reach_distk(o,p)=max{dk(o),d(o,p)} (1)
11、其中,dk(o)为领域点o的第k距离,d(o,p)为邻域点o到点p的距离;
12、步骤1.2:计算每个点的局部第k局部可达密度,其公式为:
13、
14、其中,nk(p)为p点的第k距离邻域;
15、步骤1.3:计算每个数据点的第k局部离群因子:
16、
17、步骤1.4:根据步骤1.3中计算得到的每个数据点的局部离群因子lofk(p),对最大的n个局部离群因子所述的数据点进行判断,如果数据点的lofk(p)远大于1,表明该数据点跟其它数据点疏远,为一个异常点,并将异常点剔除。
18、进一步地,所述步骤2中采用k折交叉法对数据进行划分,构建堆叠模型训练的数据集合,包括以下步骤:
19、步骤2.1:利用步骤1处理后的数据,建立电池健康状态数据集,并按照7:3的比例划分为训练集和测试集;
20、步骤2.2:将训练集均分为k份互斥的子数据集{train_1,train_2,…,train_k};
21、步骤2.3:将第i份子数据集train_i作为验证集,剩余k-1个子数据集作为新训练集ntrain_i。
22、进一步地,所述步骤3中构建堆叠集成学习模型,搭建基学习器和元学习器双层结构,包括以下步骤:
23、步骤3.1:使用步骤2.3中处理好的ntrain_i对基学习器层的两个模型ast-gru和cnn-rvfl进行训练,将train_i作为验证集输入到经过ntrain_i训练好的模型中得到估计结果pi,将步骤2.1中的测试集输入到ntrain_i训练好的模型得到估计结果yi;
24、步骤3.2:重复步骤3.1,直到i>k结束此操作,得到每个基学习器层模型对验证集的结果{p1,p2,…,pk}和对测试集的结果{y1,y2,…,yk},将两个基学习器层模型对测试集的结果{y1,y2,…,yk}进行加权平均分别生成集合t1和t2;
25、步骤3.3:将步骤3.2中得到的{p1,p2,…,pk}合并成为元学习器的训练集xtrain此时xtrain为一个包含两个特征值的集合,将{t1,t2}组合成集合xtest输入到训练好的元学习器中得到预测值。
26、进一步地,所述步骤4中对堆优化算法hbo进行改进,包括以下步骤:
27、步骤4.1:设置hbo算法的种群大小和迭代次数,以及搜索空间的上下限;
28、步骤4.2:采用singer混沌映射策略初始化算法的种群位置,改进后的公式如下所示:
29、wh+1=φ(7.86wh-23.31wh2+28.75wh3-13.302875wh4), φ∈(0.9,1.08) (4)
30、步骤4.3:hbo算法的在进行堆更新时,位置更新公式如下所示:
31、
32、其中,z是当前迭代次数,h是一个解向量的第h个分量,e是当前个体的直接领导,n1,n2,n3被定义为:
33、
34、步骤4.4:在维度学习的搜索策略中,首先通过常规的堆优化搜索策略,将计算出的个体位置作为候选位置whbo(h+1),建立个体的当前位置的邻域ni(t),其公式如下:
35、ni(t)={wj(h)|li(wi(h),wj(h))≤si(h),wj(h)∈pop} (7)
36、其中,li为wi(h)到wj(h)的欧氏距离,si(t)为个体当前位置与whbo(h+1)之间的欧式距离;
37、步骤4.5:利用维度学习搜索策略计算出维度学习位置wdl(h+1),公式如下所示:
38、wdl,d(h+1)=wi,d(h)+rand×(wn,d(h)-wr,d(h)) (8)
39、其中,wi,d(h)是步骤4.4得到的邻域ni(t)中的随机个体位置,wr,d(h)是个体矩阵内随机个体位置;
40、步骤4.6:通过加入维度学习的搜索策略,对堆优化算法位置更新进行改进,改进后的位置更新公式如下:
41、
42、进一步地,所述步骤5中对利用ihbo算法对步骤3中构建的基学习器和元学习器的超参数进行优化,包括以下步骤:
43、步骤5.1:初始化堆优化算法的相关参数,包括个体种群、维度、最大迭代次数、搜索空间的上下限和当前迭代次数;
44、步骤5.2:计算经过堆叠集成学习模型训练的预测值ypi和样本实际值ovi间的均方根误差,将其作为堆优化算法中每个个体的适应度值fit:
45、
46、步骤5.3:根据随机数n确定个体更新策略,并计算出每个个体位置,利用公式(5)计算出个体的适应度值,并对其进行排序;
47、步骤5.4:利用维度学习策略重新对个体位置进行计算,使用公式(6)计算个体适应位置,将其与步骤5.3得到的个体适应度值进行比较,选出最优适应度值对应的最优位置;
48、步骤5.5:判断是否达到最大迭代次数,若达到,则输出最优解,并从中提取出基学习器和元学习器的超参数,否则返回步骤5.2;
49、步骤5.6:将元特征数据输入到优化后的堆叠集成模型中进行估计,得到最终的锂电池健康状态估计结果。
50、有益效果:
51、本发明基于stacking集成学习和ast-gru、cnn-rvfl、随机森林建立模型,同时采用改进的hbo算法优化模型超参数,能够有效地估计锂电池健康状态变化趋势,提高预测精度。
52、本发明针对单模型在锂电池健康状态估计中泛化性差的问题,利用lof方法对异常数据进行剔除,消除误差对特征量规律性的影响,保留锂电池健康状态变化过程中物理化学特征。针对单个模型估计锂电池健康状态泛化性差,容易受到噪声影响。提出将多个模型按照stacking方法进行组合,利用结合注意力机制的ast-gru网络,通过注意力机制增加关键时间步的权重,减少次要信息的干扰。使用cnn-rvfl网络收集锂电池充放电时局部时序特征。使用随机森林作为元学习器层对基学习器提取的元特征进行学习。针对模型过拟合问题,采用k折交叉的方法划分数据集。能够有效提升模型的准确率。针对堆优化算法缺少间接层之间的信息交互导致的搜索能力不足的问题,采用singer混沌映射对种群进行初始化操作,避免初始化个体集中分布,在更新阶段增加维度学习的更新方式,增加个体对间接层信息的利用能力,提高搜索效率。
- 还没有人留言评论。精彩留言会获得点赞!