一种无人机航迹规划方法
本发明属于无人机飞行控制,涉及一种无人机航迹规划方法,特别是一种基于改进蜣螂算法优化奖励的无人机航迹规划方法。
背景技术:
1、无人机因体积小、机动性高等优势,在军事和民用等多个领域应用广泛。航迹规划是无人机控制系统的重要一环,形成可靠的航迹是确保无人机完成飞行任务的前提。
2、近年来,以机器学习为代表的人工智能技术飞速发展,实现与多种航迹规划场景的深度融合。其中,深度强化学习算法具有较强的感知能力,运算速度快、实时性强,通过训练能够实现端到端的航迹规划映射,广泛应用于规划领域,但其奖励函数主要依靠人为设计,往往存在局部奖励设计不够全面,各局部奖励占比分配不佳,进而导致模型应用场景有限、收敛速度慢的问题。以上问题可以通过综合考虑实际环境中的各方面因素,进而构建各项局部奖励函数,用以全面描述环境对智能体交互的反馈,用以提高模型应用场景范围,并通过优化各局部奖励函数的占比来提高收敛速度。群智能优化算法通过模拟大自然的某种现象或生物群体的自组织行为,在优化参数方面具有出色的效果,能够用于对局部奖励函数的占比进行优化。
3、通过对现有技术文献的检索发现,池海红等人在《控制理论与应用》(2022.39(05):847-856)上发表的“融合强化学习和进化算法的高超声速飞行器航迹规划”,提出了一种利用交叉熵提高强化学习模型在航迹规划前期探索速度的算法,但其构建的场景以及设定的奖励函数,仅能在二维平面进行航迹规划,无法扩展至三维。谭志平等人在发明(专利号:cn202211195962.8)中发明的“一种基于强化学习差分算法的无人机动态航迹规划方法”,将差分进化算法融入到强化学习模型的动作和奖励中,提高了模型收敛速度,但规划的路线由多个离散区域构成,奖励函数由离散的差分算法收敛效果决定,仅能保证在训练的环境下,实现有效的无人机航迹规划,并不适用于动态可变的环境。本人在发明(专利号:cn202110632549.2)中发明的“一种基于联合优化的无人机航迹规划方法”,考虑实际环境中自然干扰因素的影响,建立了应用场景更广泛的模型,但并未考虑如何加快模型的收敛速度。已有文献的检索结果表明,全面考虑影响航迹规划的重要因素,构建复杂、动态的模型,设计更加客观、全面的奖励函数,是提高航迹规划模型应用场景范围,使其更贴近实际环境的关键,但与此同时,改善奖励函数的构成,会减缓模型收敛速度。
技术实现思路
1、针对上述现有技术,本发明要解决的技术问题是提供一种基于改进蜣螂算法优化奖励的无人机航迹规划方法,在构建环境时考虑多方面影响因素,并将其设定在奖励函数中,结合群智能优化算法对各局部奖励函数的占比进行优化,在有效提高模型应用场景范围的基础上,加快模型收敛速度。
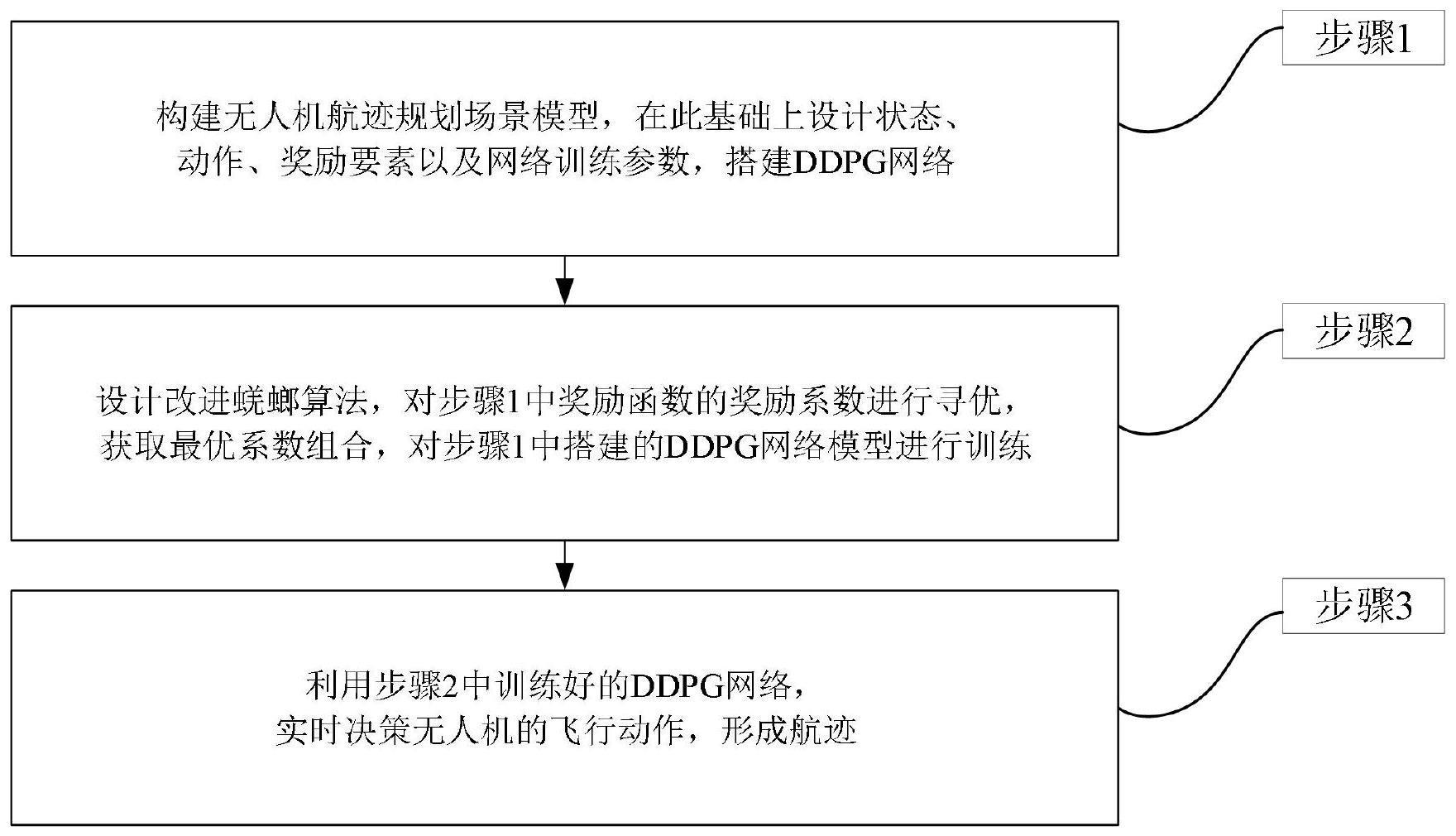
2、为解决上述技术问题,本发明的一种无人机航迹规划方法,包括:
3、无人机获取自身和目标信息,获取每个时刻状态s,将每个时刻状态s分别输入至预先训练好的ddpg网络,所述ddpg网络包括actor网络和critic网络,利用actor在线网络决策每个时刻无人机飞行动作a,形成最终航迹;所述ddpg网络的训练过程包括:
4、步骤1:对无人机航迹规划场景进行建模,设计无人机航迹规划模型的状态空间、动作空间、奖励函数以及网络训练参数,所述网络训练参数包括actor网络学习率ηactor,critic网络学习率ηcritic,软更新系数ηsoft,折扣因子ηdis,记忆池尺寸χme,采集经验数据的批量尺寸χexp,训练回合数i,每个回合的时间步总数;所述奖励函数为:
5、
6、其中,rdis为到达奖励,rangle为航偏奖励,robs为威胁奖励,rs为时间奖励,λ1、λ2、λ3和λ4分别为到达奖励、航偏奖励、威胁奖励和时间奖励的奖励系数,计为λ=[λ1,λ2,λ3,λ4],λ1+λ2+λ3+λ4=4,其中:
7、
8、
9、
10、rs=-0.2·d4
11、其中,d1为距离因子,nor(·)表示归一化处理,d2为航偏因子,dissafe为无人机与威胁障碍物之间的安全距离,dismin为无人机与最近威胁之间的距离,d3为威胁因子,d4为时间因子;
12、设置回合奖励集合sri:
13、sri=[r1,r2,...,ri,...,ri]
14、其中,为第i个回合的回合奖励;
15、步骤2:采用融合沙丘噪声灵敏度和萤火因子的改进蜣螂算法优化步骤1中奖励函数的各项奖励系数,获取最优系数组合,根据最优系数组合和网络训练参数对ddpg网络进行训练,获得无人机从飞行状态到飞行动作端到端的决策映射。
16、进一步的,步骤1所述状态空间为:
17、
18、其中,(x,y,z)为无人机在场景坐标系的位置信息,(x′,y′,z′)为目标在场景坐标系的位置信息,(vx,vy,vz)为速度分量,β为行为角,为无人机与目标之间的直线距离,μ=[μ1,μ2,…,μq,…,μq]为q个传感器的射线长度,ρ=[ρ1,ρ2,...,ρq,...,ρq]为对μ的独热编码;第q个传感器的独热编码ρq为:其中,dishit为无人机与传感器探测点之间的距离,lasar为无人机可探测到的最大距离,q∈[1,q]且q为正整数。
19、进一步的,步骤1所述动作空间为:
20、
21、其中,fforward为前倾力,表示无人机在x方向上受到的力,fright为侧倾力,控制无人机在y方向移动,fup为起降力,使无人机沿z方向进行垂直起降运动,frotation为航向力,控制无人机沿z轴旋转角度的变化,f∑表示前倾力、侧倾力、起降力和航向力的合力,为无人机连续飞行过程中的最大加速度,max{·}为求取最大值,g为重力加速度,hf为水平过载、hp为径向过载,m为无人机的质量。
22、进一步的,步骤2所述采用融合沙丘噪声灵敏度和萤火因子的改进蜣螂算法优化步骤1中奖励函数的各项奖励系数,获取最优系数组合包括:
23、步骤2.1、设置改进蜣螂算法的适应度函数fitness为:
24、
25、其中,ir为收敛回合,ir∈[1,i]且ir为正整数,var为收敛方差,rm为最大回合奖励值;
26、ir=index[rm-0.2·(rm-rw)]
27、其中,rw为最小回合奖励值,index[r*]表示最接近r*的回合,r*∈[rw,rm];
28、
29、其中,rτ表示第τ个回合的回合奖励;
30、rw=min[sri]
31、rm=max[sri]
32、其中,min[·]表示求取最小值,max[·]表示求取最大值,sri为回合奖励集合;
33、步骤2.2、设定最大迭代次数n,优化空间维数d,优化区间最小值l,优化区间最大值u,种群大小p,包括雄性蜣螂p1个、雌性蜣螂p2个、沙丘蜣螂p3个、萤火蜣螂p4个,p=p1+p2+p3+p4,初始化种群位置信息为:
34、θj=l+ξ·(u-l)
35、其中,θj表示第j个蜣螂个体位置信息,j∈[1,p]且j为正整数,蜣螂个体按雄性蜣螂、雌性蜣螂、沙丘蜣螂、萤火蜣螂的顺序进行排列,ξ∈(0,1),表示0至1之间的随机数,每次使用ξ均会产生新的随机数;
36、步骤2.3、获取蜣螂种群的位置信息对应的奖励系数[λ1,λ2,...,λj,...,λp],其中,λj=[λ1,λ2,λ3,λ4]j表示第j个蜣螂个体位置信息对应的奖励系数,将其并行输入至p个步骤1中搭建的ddpg网络,进行训练,获得每个蜣螂个体对应的回合奖励集合根据步骤2.1,计算每个蜣螂位置对应的适应度值,获取蜣螂个体的局部最优位置θ*、全局最优位置θm和全局最差位置θw;
37、步骤2.4、更新雄性蜣螂位置信息且j1为正整数:
38、
39、其中,表示第j1只雄性蜣螂在第n次迭代时的位置信息,n∈[1,n]且n为正整数,θ(0)=0,ω表示雄性蜣螂的探索方向,为-π/2至π/2之间的随机数,tan(·)为正切函数,α为自然因子:
40、
41、步骤2.5、更新雌性蜣螂位置信息且j2为正整数:
42、
43、其中,表示第j2只雌性蜣螂在第n次迭代时的位置信息,l′表示雌性蜣螂位置探索下限,u′表示雌性蜣螂位置探索上限:
44、
45、
46、步骤2.6、更新沙丘蜣螂位置信息且j3为正整数:
47、
48、其中,表示第j3只沙丘蜣螂在第n次迭代时的位置信息,表示沙丘噪声灵敏度;
49、步骤2.7、更新萤火蜣螂位置信息且j4为正整数:
50、
51、其中,表示第j4只萤火蜣螂在第n次迭代时的位置信息,表示萤火因子;
52、步骤2.8、重复步骤2.3至步骤2.7,直至当前迭代次数到达最大迭代次数n时结束,得到全局最优位置θm及其对应的奖励系数λm。
53、本发明有益效果:本发明针对现有无人机采用深度强化学习进行航迹规划时,构建模型以及设计奖励函数存在缺陷,使得适用场景受限且进一步导致模型收敛速度降低的问题,提出了一种新的基于改进蜣螂算法优化奖励的无人机航迹规划方法。本发明综合考虑了无人机在三维空间中飞行时长、方向、加速度、受力以及潜在威胁等多方面因素,设计适用于多种场景的状态空间、动作空间以及奖励函数,解决了模型适配场景有限的问题。改进蜣螂算法,将沙丘噪声灵敏度与种群位置更新机制相融合,加入萤火因子为个体增添吸引性,进一步优化深度强化学习奖励系数,解决了模型收敛效果不佳问题,提高了航迹规划可靠性。
- 还没有人留言评论。精彩留言会获得点赞!