一种基于金字塔L-K光流与多视角几何约束的动态SLAM稠密地图构建方法
本发明适用于移动机器人领域,具体涉及到fast特征点提取,基于金字塔l-k(lucas-kanade)光流法与多视角几何约束的动态对象剔除,基于深度残差的静态深度图像获取,sdf(signed destance function)误差函数以及tsdf(truncated signed distancefunction)稠密地图重建,其优越性在于弥补了在高动态场景或先验动态信息缺失的场景中大多数方案不能有效避免运动物体对slam(simultaneous localization and mapping,同步定位与地图构建)系统性能的影响的问题,能够有效提高相机位姿估计精度,实现稠密地图的更新,在提升系统鲁棒性的同时也提升了环境重构的准确性。
背景技术:
1、slam在动态环境中具有挑战性,因为机器人必须同时估计环境中静态和运动部分的状态才能构建一致性地图。然而,在存在动态物体的情况下,错误的匹配可能会降低机器人正确估计位置的能力并破坏地图的准确性。传统的视觉slam方法都假设相机处于静态场景,但实际场景中运动物体不可避免存在,这将对slam系统位姿估计精度和地图构建准确性产生影响。因此,在动态环境下构建高精度的slam系统是近年来许多研究的重点,解决这个问题的关键在于如何有效地处理动态对象。
2、图像金字塔l-k光流法是在l-k光流法的基础上改进的。l-k光流法在求解过程中应用了泰勒展开,泰勒展开只有在变量变化很小的情况下才能使用,如果帧间的像素运动比较大,泰勒展开便不适用了。而在实际场景中是很难满足l-k光流法的3条假设的。因此为防止像素运动太快,无法使用泰勒展开,在计算时采用金字塔l-k光流法。其基本思想是:将整张图片进行缩小,降低其分辨率,对于运动较快的像素点,总能在图像分辨率降到一定程度时,其运动变得足够小,满足泰勒展开的条件。其核心思想在于构建一个多尺度的图像金字塔,通过对自顶向下的图像进行l-k光流跟踪迭代,从而提高关键点跟踪准确性和鲁棒性。
3、多视角几何约束利用了多个相机视角下的信息来增强对动态物体的识别和剔除能力,可以通过比较视差、运动向量或三维结构等信息来保持一致性,有效地处理复杂场景中的遮挡、投影和透明度等问题,提高动态物体的识别和剔除精度。此外,多视角几何约束还有助于降低误匹配率,通过将多个视角的观察结果进行比较和整合,可以减少单一视角下的误差和噪声,并提高算法的鲁棒性。
4、tsdf是一种用于三维重建和深度感知的技术,将场景中每个点的距离信息编码为有符号的函数,表示该点与物体表面之间的距离。tsdf通常应用于基于体素(voxel)的三维重建方法中,实现三维场景稠密重建。tsdf可以提供对场景中物体的准确距离估计,并能够重建出较为精细的三维结构。通过体素网格的方式,可以实现对整个场景的密集三维采样,从而获取更详细的几何信息。tsdf不受物体形状、大小或复杂度的限制,可以处理各种类型的场景,并且对于动态场景也有一定的鲁棒性。
技术实现思路
1、针对现有的动态slam方法仅解决了轻度动态环境中运动物体的部分干扰,在高动态场景或先验动态信息缺失的场景中,大多数方案不能有效避免运动物体对slam系统性能的影响,并且现有视觉slam方案大多构建稀疏点云地图,在运动物体占图像大部分画面时,所构建地图不能真实表达机器人周围环境,实用效果将会下降等问题。本发明提出了一种基于金字塔l-k光流与多视角几何约束的动态slam稠密地图构建方法,结合金字塔l-k光流法与多视角几何约束算法进行动态对象剔除,提供了一种鲁棒、精确和高效的解决方案来获得图像静态特征。将基础矩阵分解为旋转矩阵与平移向量,带入最小化sdf误差函数来实现对相机位姿的估计,充分融合两种互补信息,增加了位姿估计的鲁棒性和精度。结合静态深度图像信息和优化的相机位姿,使用基于体素的tsdf方法来生成静态三维稠密地图,实现对动态环境的鲁棒建模。
2、具体
技术实现要素:
为:
3、一种基于金字塔l-k光流与多视角几何约束的动态slam稠密地图构建方法,其特征在于包括以下步骤:
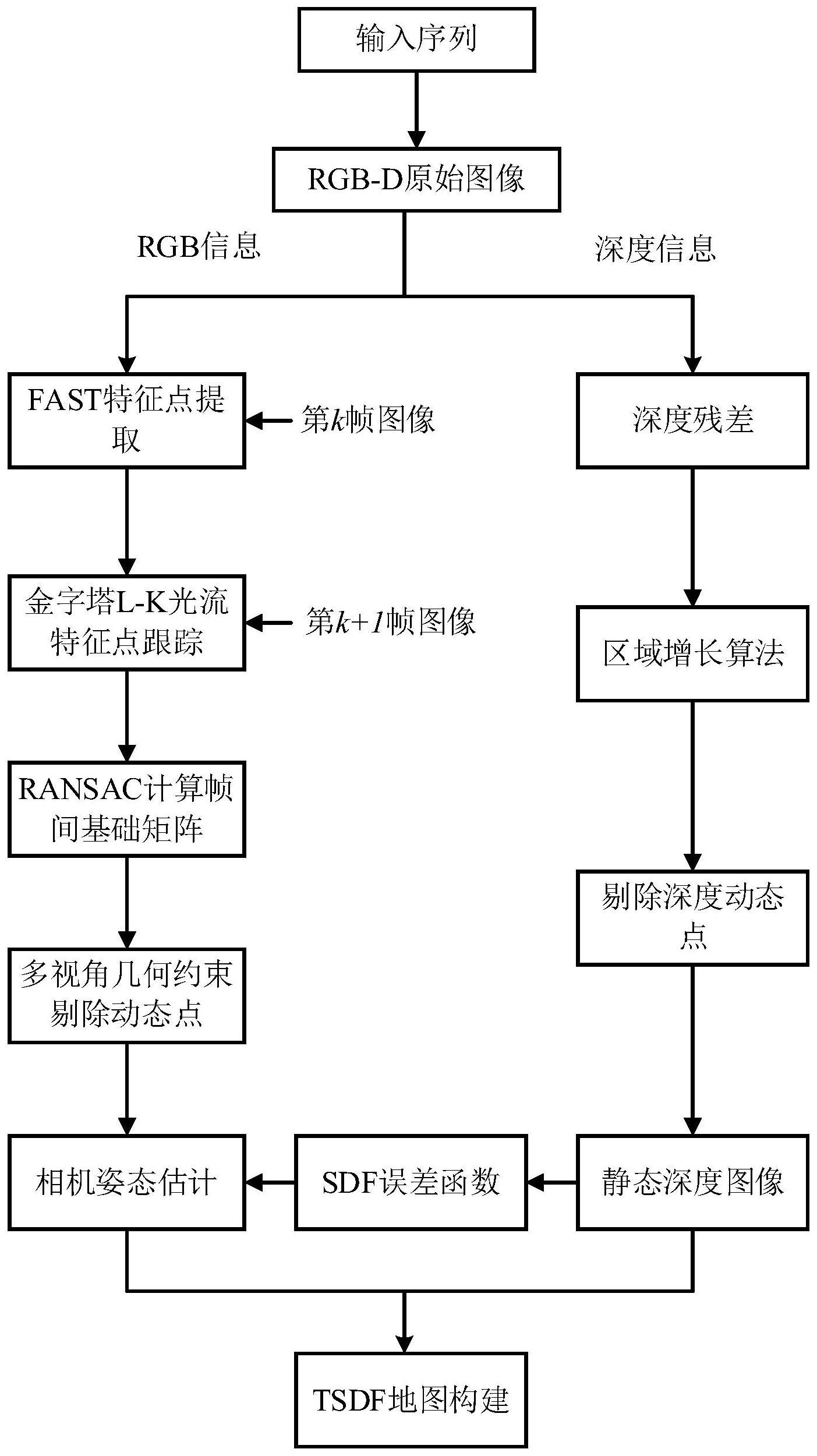
4、步骤1)通过结合金字塔l-k光流与多视角几何约束方法来检测并剔除场景中的动态对象,包括以下步骤:
5、步骤1.1)将来自rgb-d相机的数据图像做预处理,获取图像rgb信息和深度信息,对第k帧图像进行fast特征点提取;
6、步骤1.2)采用金字塔l-k光流法对第k帧与第k+1帧图像进行特征点跟踪,给出对应像素点的速度计算公式:
7、
8、其中,vx、vy为像素在x轴和y轴上运动速度;
9、
10、
11、[ix iy]k为图像在k点处x和y方向的灰度梯度;itk为点k处图像灰度对时间的变量;
12、步骤1.3)采用ransac算法计算相机变换的基础矩阵以更好的滤除误匹配;基础矩阵的求解具体步骤如下:第一步,从匹配点对中随机选出4组用来求解基础矩阵f;第二步,计算其余特征点到矩阵f所对应极线的距离d,将该距离与事先设定好的阈值dn比较,当d<dn时,判定该点为内点,当d>dn,判定该点为外点;记下内点的数目为n;第三步,重复执行上述两步并迭代n次,选取其中内点数目最多的一次,将该次所求得的基础矩阵作为最终的基础矩阵;
13、步骤1.4)添加多视角几何约束来增强对动态物体的识别和剔除能力,通过分析多视角下的视差信息,提高误匹配精度和系统定位的鲁棒性;
14、步骤2)将基础矩阵分解为旋转矩阵与平移向量,带入最小化sdf误差函数并使其最小化来实现对相机位姿的估计;包括以下步骤:
15、步骤2.1)利用ransac算法迭代计算的基础矩阵分解出旋转矩阵与平移向量;
16、步骤2.2)利用深度残差和区域增长算法去除深度图像中的动态物体,获得静态深度图像并生成sdf;选择一个阈值t来将残差分成动态和静态部分;阈值的计算方式为:
17、t=γτ2
18、其中τ是tsdf表示中使用的截断距离,是0到1之间的值;超过阈值t的像素点被视为动态对象的一部分;
19、步骤2.3)利用sdf建立误差函数,将旋转矩阵与平移向量带入sdf误差函数,并采用levenberg-marquardt算法对误差进行归一化来实现相机位姿估计;假设所采用的针孔相机模型具有内参矩阵k=diag(fx,fy,1)和畸变系数0,其中fx、fy分别表示焦距在水平和竖直方向上的大小,对应着相机光心在图像平面上的投影坐标(cx,cy);基于该模型,一个三维点x=(x,y,z)t在图像平面上的投影可以表示为:
20、
21、而对于深度值为z=id(i,j)的像素点(i,j)t∈r3,则可以通过以下公式计算其对应的三维坐标:
22、
23、sdf的含义是返回从x到曲面的带符号距离,基于此,直接使用sdf来建立一个误差函数,以描述深度图像与sdf之间的匹配程度;针对每个像素(i,j),可以通过上一个公式在相机的局部坐标系中重建相应的3d点xij;利用以下公式,可以将该点转换到全局坐标系中:
24、
25、为了简化后续计算,本文采用负对数并定义误差函数:
26、
27、其中,i、j遍历深度图像中的所有像素;为了最小化误差函数,本文采用levenberg-marquardt算法对误差进行归一化,以加快收敛速度;
28、步骤3)根据上述步骤得出的静态深度图像信息和优化的相机位姿,使用基于体素的tsdf方法来生成静态三维稠密地图,并采用动态体素分配和空间哈希技术进行索引;包括以下步骤:
29、步骤3.1)建立一个世界坐标系下由网格组成的空间模型;
30、步骤3.2)在一个全局三维坐标中建立格式化体素立方体,每一个立方体都包括值与权重两个量,根据不同关键帧的深度图来不断更新网格模型中tsdf值,进行融合处理来减小深度信息的噪声造成的不一致性;tsdf遍历深度图,根据像素点坐标、深度值及相机内参与位姿得到每个像素点对应的体素立方体坐标,并根据以下三个公式计算该立方体的权重与值;
31、wi(x,y,z)=min(wmax,wi-1(x,y,z)+1)
32、di(x,y,z)=min(1,sdfi/tmax)
33、
34、其中:下标i为当前帧;i-1为上一帧;wi(x,y,z)为体素立方体的权重;wmax为最大权重;sdfi为根据深度数据计算得到的体素立方体到物体表面的真实距离;tmax为截断范围;di(x,y,z)为到物体表面的真实距离除以截断范围的体素值;di(x,y,z)为带有权重信息的最终体素立方体的值;
35、步骤3.3)计算得到wi(x,y,z)与di(x,y,z)后,提取体素立方体中wi(x,y,z)大于体素权重阈值wmin,且di(x,y,z)等于0的等势面,即可得到重建的网格模型。
36、本发明具有如下优点和有益效果:
37、利用金字塔l-k光流法与多视角几何约束算法进行动态对象剔除,构建一个多尺度的图像金字塔,对自顶向下的图像进行l-k光流跟踪迭代,从而提高关键点跟踪准确性和鲁棒性;同时通过比较视差、运动向量或三维结构等信息来保持一致性,有效地处理复杂场景中的遮挡、投影和透明度等问题,将多个视角的观察结果进行比较和整合,还可以减少单一视角下的误差和噪声,降低误匹配率并提高算法的鲁棒性。
38、tsdf可以提供对场景中物体的准确距离估计,并能够重建出较为精细的三维结构。tsdf不受物体形状、大小或复杂度的限制,可以处理各种类型的场景,并且对于动态场景也有一定的鲁棒性。弥补了在高动态场景或先验动态信息缺失的场景中大多数方案不能有效避免运动物体对slam系统性能的影响的问题。
- 还没有人留言评论。精彩留言会获得点赞!