一种基于融合DAE-Bi-LSTM的SOC估计方法与流程
本发明涉及电池管理系统(bms),具体涉及一种基于融合dae-bi-lstm的soc估计方法。
背景技术:
1、soc(state of charge)即电池荷电状态,用于反映电池的剩余容量,其在数值上定义为当前时刻剩余电量和电池充满电时电量的比值。在电池管理系统中,soc的准确估计是对电池进行管理的前提,对电池稳定、安全运行具有十分重要的意义。
2、soc易受温度和负载等外部环境等影响,且soc的估算是非线性的,因此,准确估计soc具备较大难度。安时积分法、电池模型法和数据驱动法是常用的soc估计方法。其中,安时积分法在电池充放电过程中,通过累积充进或放出的电量来估算电池的soc,同时根据充电过程中电池达到满充条件,或者电池达到一定时间的静态条件后对电池soc进行校正。电池模型法将电池单体等效为电阻、电容、电压源等等效电路模型,利用状态观测器闭环控制理论,通过调整状态参数使单体电压估计值不断逼近单体电压测量值,从而得到电池内部状态变量真实soc。相比之下,数据驱动法不关注电池的电化学特性,而是通过机器学习方法根据大量数据进行模型训练,得到满意精度后再用训练好的模型进行soc估计。
3、在上述方法中,安时积分法会产生累计误差,开路电压法需要电池静置一段时间,无法直接用于soc估计;结合电池模型和观测器(滤波器)如自适应观测器、卡尔曼滤波器的方法计算复杂,且模型结构和参数泛化性不足,难以满足实际需要。数据驱动方法利用测量的电池数据训练估计模型,数据本身的质量和对测量数据和soc的拟合方法决定了估计的精度,导致该方法存在鲁棒性差的问题。
技术实现思路
1、有鉴于此,本发明要解决的问题是提供一种基于融合dae-bi-lstm的soc估计方法。
2、为解决上述技术问题,本发明采用的技术方案是:一种基于融合dae-bi-lstm的soc估计方法,包括以下步骤:
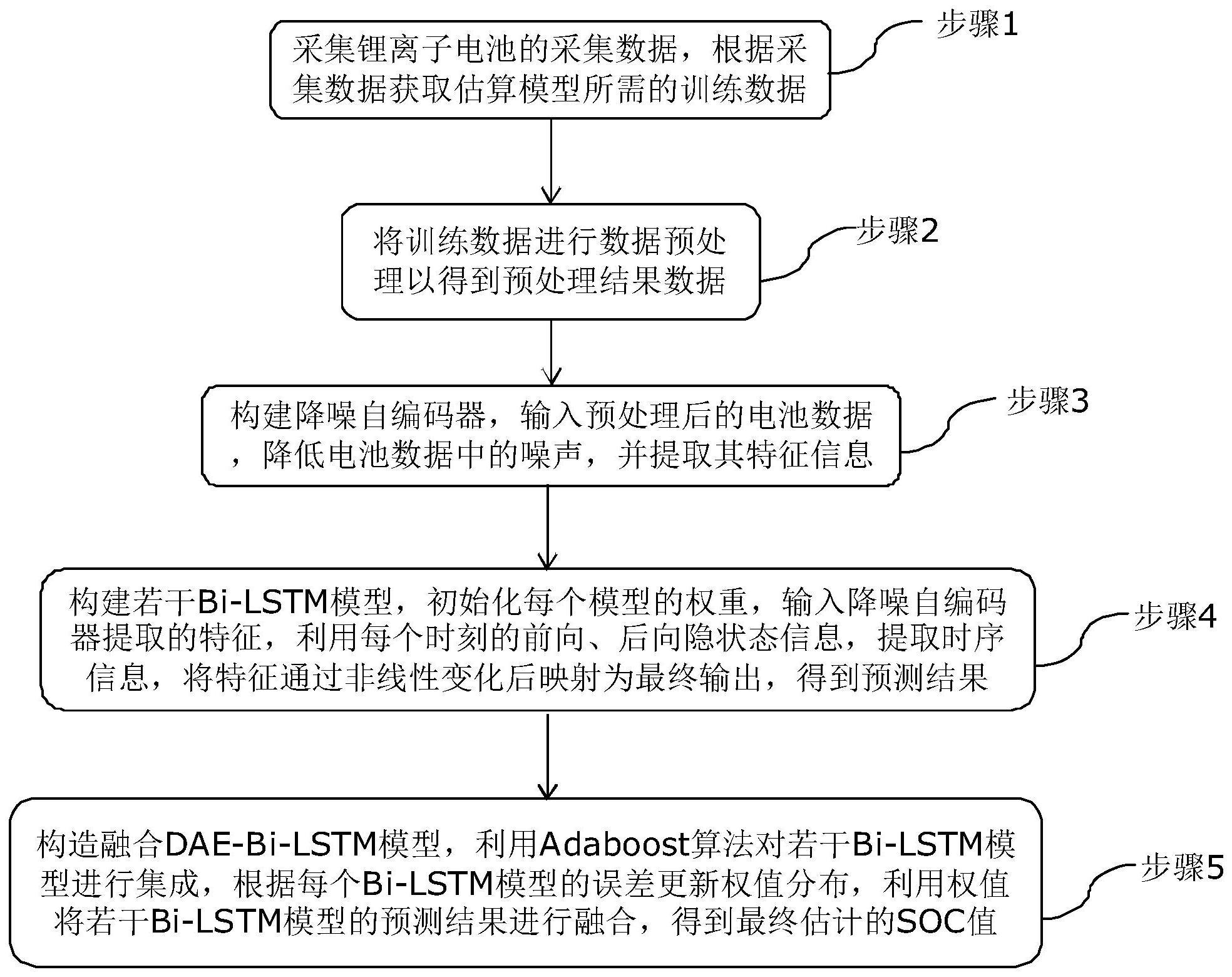
3、步骤1,采集锂离子电池的采集数据,根据采集数据获取估算模型所需的训练数据;
4、步骤2,将训练数据进行数据预处理以得到预处理结果数据;
5、步骤3,构建降噪自编码器,输入预处理后的电池数据,降低电池数据中的噪声,并提取其特征信息;
6、步骤4,构建若干bi-lstm模型,初始化每个模型的权重,输入降噪自编码器提取的特征,利用每个时刻的前向、后向隐状态信息,提取时序信息,将特征通过非线性变化后映射为最终输出,得到预测结果;
7、步骤5,构造融合dae-bi-lstm模型,利用adaboost算法对若干bi-lstm模型进行集成,根据每个bi-lstm模型的误差更新权值分布,利用权值将若干bi-lstm模型的预测结果进行融合,得到最终估计的soc值。
8、在本发明中,优选地,步骤1具体为对锂离子电池在不同温度下进行通放电实验,对不同时刻锂离子电池的放电电流、放电电压、电池表面温度进行采集得到采集数据,将采集数据根据安时积分法计算得到电池的放电容量和真实soc值,将电池的放电容量和真实soc值根据时间整理得到训练数据。
9、在本发明中,优选地,步骤2具体为对训练数据中存在的数据缺失值和异常值采用最小二乘法进行拟合后进行插值填补,然后进行min-max归一化,具体为
10、
11、式中,x为待归一化的数据,xnew为归一化后的数据,xmin为数据的最小值,xmax为数据的最大值。
12、在本发明中,优选地,步骤3中的所述降噪自编码器包括输入层、处理层、隐藏层和重构层,通过对输入数据进行降噪处理,按照一定概率对输入数据的维度节点清零,调整模型参数以最小化损失函数得到最优模型,损失函数具体为:式中,x为输入的原始样本数据,为降噪自编码器生成的重构样本数据,a为训练数据集,为单个样本的重构误差,用输入层和重构层间的均方误差表示,具体为:
13、在本发明中,优选地,步骤4具体为:构建若干bi-lstm模型,每个bi-lstm模型作为弱学习器结构设置相同,均包括两个传播方向相反的lstm,每个lstm均包括输入门、遗忘门和输出门,其中,遗忘门用于对过去的信息进行筛选,输入门用于对当前时刻信息进行筛选,输出门用于对当前时刻记忆单元的信息进行筛选,计算过程表示为:
14、ft=σ(wxfxt+whfht-1+bf)
15、it=σ(wxixt+whiht-1+bi)
16、
17、ot=σ(wxoxt+whoht-1+bo)
18、式中,ft、it、ot分别为遗忘门、输入门和输出门在t时刻的状态值;为t时刻的候选记忆状态;xt为t时刻的输入值;ht-1为t-1时刻lstm的输出值;wxf、whf、wxi、whi、wxc、whc、wxo、who为每一条路径对应的权重,bf、bi、bc、bo为每一条路径对应的偏置量。
19、在本发明中,优选地,每个lstm经过计算得到当前时刻记忆单元姿态和输出值的过程为:
20、
21、ht=ot⊙tanh(ct),
22、式中,⊙表示矩阵中对应元素相乘;ct-1为t-1时刻lstm的记忆单元状态;ht为t时刻lstm的输出值。
23、在本发明中,优选地,bi-lstm模型拼接两个相反的lstm输出值的过程为:
24、式中,表示向量拼接;ht为bi-lstm模型的输出值;为传播方向为正向的lstm的输出值;为传播方向为负向的lstm的输出值。
25、在本发明中,优选地,步骤5具体为:构建融合dae-bi-lstm模型,先将bi-lstm模型进行编号,将权值进行初始化,具体为:
26、d1(w11,w12,…,w1i)
27、
28、式中,w1i为第i个bi-lstm模型的权值,n为所有bi-lstm模型的个数。
29、在本发明中,优选地,按照所编号的bi-lstm模型的顺序,依次计算每个bi-lstm模型的误差,根据误差更新权值,具体为:
30、
31、
32、式中,n为训练集样本个数,为第i个样本的均方误差,εt为在第t次迭代训练过程后的误差,βt为学习器权值;
33、训练完毕后,根据最优的权值将所有bi-lstm模型进行融合,获得融合dae-bi-lstm模型,其输出即为估计的soc结果。
34、本发明具有的优点和积极效果是:提供一种基于融合dae-bi-lstm的soc估计方法,包括对数据集进行缺失值和异常值的拟合后插补,以及归一化处理;构建dae网络对输入数据进行深层特征提取,并降低数据中噪声的影响;构造多个bi-lstm对dae提取的特征进行学习,获取初步估计结果;利用adaboost算法对每个bi-lstm的权值根据其误差进行更新迭代,最终根据训练好的权值融合所有bi-lstm,最终实现soc的估计。通过利用dae网络对数据进行深层特征提取,降低噪声的影响,提高了整体模型的鲁棒性和准确度;利用多个bi-lstm从正向和反向读取特征参数,学习电池soc在过去、未来的信息和当前信息之间的时序关系,增强模型的特征提取能力,有效提高估计的准确度;利用adaboost算法将多个bi-lstm模型进行融合,进一步提升soc估计的准确度。
- 还没有人留言评论。精彩留言会获得点赞!